面向反制无人机集群的多目标连续鲁棒跟踪算法
2024-05-09王传云苏阳王琳霖王田王静静高骞
王传云,苏阳,王琳霖,王田,王静静,高骞,*
1.沈阳航空航天大学 人工智能学院,沈阳 110136
2.沈阳航空航天大学 计算机学院,沈阳 110136
3.北京航空航天大学 人工智能研究院,北京 100191
4.中国电子科技集团公司 电子科学研究院,北京 100041
随着现代战争形态向信息化、无人化、智能化的转变,无人机(Unmanned Aerial Vehicle,UAV)已被广泛应用于军事领域中的情报、侦察、监视、干扰、诱饵、精确打击、毁伤评估等作战任务。由于战场环境复杂多变,强对抗的作战任务对单架无人机的战时生存能力、执行任务能力提出了新的挑战。因此,由成百上千架小尺寸、低成本的无人机构成集群,以自组网的方式遂行复杂作战任务的作战样式正引起高度关注和广泛研究。无人机集群作战利用多架无人机协同作战,通过行动协调,突破敌方的严密防空圈,完成复杂的情报和侦察任务,以及协同攻击与毁伤评估等任务,表现出高度的协同能力和智能化水平[1]。无人机集群作战具有智能化和灵活多变等特点,具有更快速的侦查效率,使得传统的防御体系很难对目标进行有效的打击,即便能够对其进行有效的反击,也会因为其庞大的数量而加重防空体系的负荷,最终影响到整个防御体系的效力。此外,当集群内的某些个体被破坏或失去功能时,无人机集群的合作网络可以重新构建出新的攻击结构[2]。
由于无人机集群具有数量多、分布式、无中心、自组织、成本低、机动灵活、协同突防和协同攻击等特点。低空空域反制无人机集群研究面临着极大的挑战。目前,低空空域反制无人机集群方法主要包括探测识别类、平台摧毁类、载荷毁伤类、航程消耗类、链路干扰类、综合防护类和主动反制类[3]。探测识别类方法的隐蔽性极强,主要包括雷达探测技术、无线电探测技术和光电探测技术;平台摧毁类方法的机动性能较差,主要包括传统弹炮系统和新型弹药技术;载荷毁伤类方法的自身防护较弱,主要包括电子器件毁伤和辐射毁伤;航程消耗类方法的作战航程较短,主要包括摧毁蜂巢、伪装遮障和诱饵欺骗;链路干扰类方法对通信依赖较多,主要包括指控链路干扰和导航链路干扰;综合防护类方法的毁伤能力较弱,主要包括低成本防护技术、立体防护技术和关键点防护;主动反制类方法主要包括格斗型无人机和无人机集群对抗。然而,进行上述反制无人机集群方法的前提是对入侵的无人机集群进行有效的识别、跟踪和定位。
反无人机集群系统依靠各种技术来探测、跟踪和识别无人机,其中最常见的是雷达、光学传感器和声传感器。但是,无人机具有较低的雷达散射截面(Radar Cross Section,RCS)和相对较低的速度,这些特点使得探测任务具有挑战性。雷达探测器以其较远的探测距离、较高的灵敏度和全天候适应能力等优势,已被广泛应用于无人机探测与跟踪。但是,雷达探测器的价格昂贵、灵活性差、隐蔽性不好等问题,严重制约了其应用场景和作战效能。与此相对,近年来,低成本、高分辨率的视觉传感器技术发展日新月异,红外、可见光等视觉探测技术在无人机探测与跟踪方面表现出优异的性能,受到越来越多的研究人员关注[4]。视觉探测技术的主要优点包括探测结果直观、系统成本低、探测距离远、适用场景高等,这些优点决定了视觉探测技术是低空空域探测预警无人机集群技术不可或缺的一部分。
由于无人机具有几何尺寸小、雷达散射面小等特点,所以普通防空系统很难及时发现和截获目标。近年来,研究人员主要依靠红外和可见光探测系统等进行探测与跟踪,基于计算机视觉的多目标跟踪(Multiple Object Tracking,MOT)技术成为反无人机集群系统中关键探测技术之一。MOT 主要研究目的是对视频中多个感兴趣目标定位的同时,维持目标各自的身份识别号(Identification,ID),并记录连续的运动轨迹,因此MOT亦可视为一个数据关联问题[5-6]。CTrackerV1[7]模型是一个端到端的MOT 模型,通过输入相邻两帧的信息,在一个单一的回归模型中进行联合检测和跟踪,同时对相邻两帧对中同时出现的成对边界框进行回归,大大提高了跟踪准确性并降低了跟踪耗时;SORT(Simple Online and Realtime Tracking)[8]模型重点解决了跟踪的实时性问题,通过提供给跟踪器过去帧和当前帧的信息,在视频序列帧之间关联检测结果;Deep-SORT(Deep Learning-based SORT)[9]模型是针对SORT 模型的一次改进,在数据关联方面引入外观模型的信息,从而提高关联的鲁棒性。ByteTrack[10]模型提出了一种简单、有效和通用的关联方法,通过关联几乎所有检测框而不是只关联高分的检测框来进行跟踪,对于低分检测框,利用与轨迹的相似性来恢复真实对象并过滤掉背景检测框。FairMOT[11]模型属于一阶段MOT 模型,采用无锚点框(Anchor-Free)目标检测方法,检测模型和重识别(Re-ID)模型同时进行训练,提升了运行速率。
本文主要在无人机集群的运动场景下进行研究,相较于传统的以行人为目标的MOT 研究方向,以无人机为目标的MOT 研究应更加倾向于解决无人机尺寸小、飞行速度快、目标之间互相重叠遮挡及复杂背景等问题。现有的基于卷积神经网络(Convolutional Neural Network,CNN )的目标检测模型依赖有锚点框(Anchor-Based),此类模型易导致被小目标漏识别,并且当2 个目标相距过近时,存在将2 个目标误识别为同一个ID 的现象。因此,为了提高模型的识别精度,本文采用“点即是目标”的思路。具体来说,通过基于Anchor-Free 的目标检测模型来缓解对齐问题与误识别问题,同时降低Re-ID学习特征的维数,通过多层特征聚合来进一步优化网络的识别速度。综合考虑下,选择Fair-MOT 模型的多分支Anchor-Free 预测结构展开研究。
结合无人机目标相较于行人目标尺寸更小、运动速度更快、背景更复杂等问题,提出了UAVS-MOT 多目标跟踪模型,具体创新点如下所示。
1)针对无人机目标尺寸小、背景与目标易混淆等难点,在主干网络引入坐标注意力(Coordinate Attention,CA)[12],将位置信息嵌入到通道注意力中,同时考虑了通道间关系和位置信息,有助于算法更好地定位和识别目标。
2)针对无人机之间互相遮挡导致ID 频繁切换、关联错误ID 等难点。本文将Re-ID 分支的损失函数替换为ArcFace Loss[13]进行训练,使其能提取更精确的表观特征,增强判别能力。
3)针对无人机飞行速度快、频繁飞入飞出导致轨迹不连续等难点。本文将数据关联部分更换为BYTE 数据关联方法,利用检测框和跟踪轨迹之间的相似性,在保留高分检测结果的同时,从低分检测结果中去除背景,挖掘出真正的物体(遮挡、模糊等困难样本),从而降低漏检并提高轨迹的连贯性。
1 UAVS-MOT 多目标跟踪模型
MOT 模型主要分为一阶段模型和两阶段模型,其中一阶段模型是将目标检测和Re-ID 这2 个部分共享在同一个网络中,2 个任务同时进行,加速推理。本文提出的UAVS-MOT 多目标跟踪模型是基于Anchor-Free 的一阶段MOT 模型,可以有效解决以无人机集群为探测目标的漏检、误检和跟踪精度下降等问题。
1.1 模型框架
UAVS-MOT 模型是从提取更精确的外观特征、使用更具有判别能力的损失函数与替换更加优质的数据关联方法3 个方面对FairMOT 模型进行改进,整体模型框架如图1 所示。

图1 UAVS-MOT 模型框架图Fig.1 Diagram of UAVS-MOT model framework
在本模型框架中,输入的图像首先经过添加CA 注意力的编码器-解码器来提取特征,然后将得到的嵌入特征分别经过检测分支和Re-ID 分支,最终通过BYTE 关联策略来跟踪目标。其中检测分支分别输出heatmap、box size和offset,各分支通过hm_loss、wh_loss和offset_loss 来进行优化。对于Re-ID 分支,将嵌入特征进一步进行特征提取,然后通过ArcFace_loss 进行优化。需要注意的是,CA 注意力添加在编码器的Level 0 层和Level 1层,并且训练时跟踪器并不参与训练。
1.2 主干网络模块
UAVS-MOT 采用ResNet-34 作为主干网络,以便在准确性和速度之间取得良好的平衡。为了容纳不同规模的目标,在主干网络上应用了深度聚合网络(Deep Layer Aggregation,DLA)[14]的增强版本DLA-34。相较于 初始版本,DLA-34 在低级特征和高级特征之间增加了更多的跳跃连接,类似于特征金字塔网络(Feature Pyramid Network,FPN)[15]结构,并且把上采样模块中的所有卷积层替换为可变形卷积层,使其能够根据目标尺寸和姿态动态的调整感受野。
输入图像的尺寸为Himage×Wimage,输出特征图的形状为C×H×W。其中,H=Himage/4,W=Wimage/4。
为了使UAVS-MOT 的主干网络能更准确地进行特征提取,本文在编码器的Level 0 层和Level 1 层中引入CA 注意力机制,使其能更准确地定位感兴趣目标的确切位置,从而帮助整个模型更好地识别。另外,CA 注意力的引入方式非常灵活,几乎没有计算开销。
一些经典的注意力通常会忽略位置信息,而位置信息对于生成空间选择性注意力图是非常重要的。CA 注意力将位置信息嵌入到通道注意力中,并且将通道注意力分解为2 个1D 特征编码过程,分别沿2 个空间方向聚合特征。通过这种方式捕获长期依赖关系,既可以获取一个空间方向上的远程依赖关系,又可以保留另一个空间方向上的精确位置信息。然后,生成的特征图被分别编码成方向感知和位置感知的注意力图,这对注意力图可以互补地应用于输入特征图,以增加感兴趣对象的表示。与SE(Squeeze-and-Excitation)注意力[16]和CBAM(Convolutional Block Attention Module)注意力[17]一样,CA 注意力可以看作是一个模块,方便嵌入到其他网络型中,旨在增强移动网络学习特征的表达能力。它可以采用任何中间特征张量X=[x1x2… xc]∈RC×H×W作为输入,并输出 具有与相同大小的增广表示Y=[y1y2… yc]的变换张量。CA 注意力通过坐标信息嵌入和坐标注意力生成两个步骤来编码通道注意力关系和远程依赖关系,用X Avg Pool和Y Avg Pool 分别表示1D 水平全局池化和1D 垂直全局池化,CA 注意力模块的示意图如图2 所示。

图2 CA 注意力模块示意图Fig.2 Schematic diagram of CA attention module
CA 注意力模块具体实现步骤如下所示:
步骤1坐标信息嵌入
为了使注意力在空间上捕捉精确的位置信息,CA 注意力分解式(1)中的全局池化变为一对一维的特征向量。CA 注意力将全局池化操作分解为沿着输入特征图的水平方向(kernel(H,1))和垂直方向(kernel(1,W))分别进行池化操作,从而获得输入特征图的H,W 相关的位置信息。
式中:水平方向得到的一维特征定义如式(2)所示,垂直方向得到的一维特征定义如式(3)所示:
式(2)和式(3)所述2 种变换分别沿2 个空间方向聚合特征,生成一对方向感知的特征映射。这2 种转换还可以让CA 注意力在一个空间方向上获取长期依赖关系,并在另一个空间方向上保存精确的位置信息,这有助于网络更准确地定位感兴趣的对象。
步骤2坐标注意力生成
坐标嵌入过程中,式(2)和式(3)获得输入特征的全局感受野和编码精确的位置信息。利用生成的坐标信息,CA 注意力利用该坐标信息生成坐标注意力图。生成注意力图有以下3 个标准:①对于移动环境中的应用来说,这种转换应该尽可能简单高效;② 可以充分利用捕获到的位置信息,精确定位感兴趣区域;③能够有效地捕捉通道之间的关系。
将水平和垂直的池化结果连接到一起,并送入一个1×1 卷积获得注意力图,定义为式(4):
式中:F1表示为将水平和垂直池化结果的连接操作;f ∈RC/r×(H+W);r 是控制模块大小的一个超参数,经过激活函数获得非线性的数据之后,再将输出的结果重新按照水平和垂直方向分为2 组特征图,定义为式(5)和式(6):
再分别经过1×1 卷积之后,利用激活函数获得注意力的权重数据。最后,再将输入的特征图数据与水平和垂直权重相乘获得CA 注意力输出特征图,定义为式(7):
1.3 检测分支模块
UAVS-MOT 的检测分支建立在Center-Net[18]的基础上,检测分支中包含Heatmap head、Center offset head和Box size head。3 个平行 头部被附加到DLA-34上,每个头部由一个256 通道的卷积层和一个1×1 卷积层组成。
1)Heatmap head
Heatmap head 负责估计目标中心的位置。heatmap 的尺寸为1×H×W,图像中的每个GT box 为bi=目标中 心点为通过划分步幅来获得目标在特征图上的位置。在 点(x,y)处的heatmap 响应定 义为式(8):
式中:N 表示图像中的目标个数,σc表示标准偏差。
损失函数定义如式(9):
2)Center offset head和Box size head
式中:λs表示加权参数,并且设置为0.1。
1.4 Re-ID 分支模块
UAVS-MOT 中Re-ID 分支负责提取能够区分不同目标对象的身份特征,本文使用Arc-Face Loss 进行训练,使其能提取更精确的表观特征,增强判别能力。
Softmax 损失函数在训练过程中占主导地位,因为基于整数的乘法角余量使目标逻辑回归曲线非常陡峭,从而阻碍了收敛。Deng等[13]提出了ArcFace Loss,以进一步提高模型的判别力并稳定训练过程。
最广泛使用的分类损失函数Softmax Loss:
式中:xi∈Rd表示第i 个样本的深度特征,属于第yi类,将嵌入特征维度d 设置为512;Wj∈Rd表示权重W ∈Rd×N的第j列,bj∈Rd是偏置项;批量大小和类数分别为N和n。
为了简单起见,ArcFace Loss修正了偏差bj=0,将逻辑回归转换为=‖Wj‖‖xi‖cos θj,其中θj是权重Wj和特征xi之间的角度。然后,通过l2归一化来固定单个权重‖Wj‖=1,还通过l2归一化来固定嵌入特征‖xi‖,并将其重新缩放到s,特征和权重的归一化步骤使预测仅取决于特征和权重之间的角度。因此,学习的嵌入特征分布在半径为s 的超球面上,如式(12)所述:
由于嵌入特征分布在超球面上的每个特征中心周围,所以在xi和之间添加了一个附加角余量惩罚m,这样可以同时增强类内相关性和类间差异性。由于提出的附加角余量惩罚等于归一化超球面中的测地距离余量惩罚,所以Arc-Face Loss 定义如式(13)所述:
本文实验中ArcFace Loss 的超参数s 设置为32,m 设置为0.5。通过Lheat、Lbox和LArcFace一起训练检测分支和Re-ID 分支,并通过不确定损失[19]来自动平衡这2 个分支任务。损失函数如式(14)和式(15)所述:
式中:w1和w2表示平衡2 个分支任务的可学习参数。
1.5 数据关联模块
UAVS-MOT 模型的数据关联部分使用BYTE 数据关联方法,使其从低分检测结果中去除背景,挖掘出真正的物体(遮挡、模糊等困难样本),从而降低漏检并提高轨迹的连贯性。BYTE数据关联方法保留每个检测框,并将其分为高分检测框和低分检测框。首先,将高分检测框与轨迹相关联(当目标之间相互遮挡、运动模糊或尺度变换时,有些轨迹和检测框不匹配)。然后,将低分数检测框和这些不匹配的轨迹相关联,这样可以恢复低分数检测框中的目标,并且可以过滤掉背景。BYTE 数据关联方法具体流程如下所示:
1)BYTE 数据关联方法的输入是视频序列V、目标检测器Det和卡尔曼滤波器KF。设置3 个阈值Thigh=0.6、Tlow=0.1和∈=0.7,Thigh和Tlow是检测分数阈值,∈是跟踪分数阈值。输出轨迹集合T,T 中每个轨迹都包含每个帧中的目标的边界框和ID。对于视频中的每一帧,通过目标检测器Det 得到检测框和检测分数,对于检测分数高于Thigh的检测框,将它们保留到Dhigh中;对于检测分数处于Thigh和Tlow之间的检测框,将它们保留到Dlow中。把检测框分离成2 部分之后,使用KF 来预测T 中每个轨迹的新位置。
2)在Dhigh和T(包括丢失的轨迹Tlost)之间执行第一次关联。首先,通过Dhigh和T 的预测框之间的交并比(Intersectionover Union,IoU)来计算相似性。然后,使用匈牙利算法来完成基于相似度的匹配,如果检测框和轨迹框之间的IoU<0.2,则拒绝匹配。最后,将不匹配的检测框保留到Dremain,将不匹配的轨迹保留到Tremain。其中,Re-ID 特征被添加到第1 次关联中。
3)在Dlow和Tremain之间执行第2 次关联,将不匹配的轨迹保留到Tre-remain,删除所有不匹配的低分检测框(被视为背景)。在第2 次匹配中,仅仅使用IoU 作为相似性。因为低得分检测框通常包含严重的遮挡或运动模糊,外观特征是不可靠的。因此,将BYTE 应用于UAVS-MOT时,在第2 次关联中不使用外观相似性。
4)在2 次关联完成后,对于仍无法匹配的轨迹Tre-remain,将它们保留到Tlost中。对于Tlost中的每个轨迹,只有当它存在超过30 帧时,才将其从T 中删除。否则,将Tlost保留在T中。
5)最后,从第一次关联之后保留的不匹配高分检测框Dremain中初始化新的轨迹。对于Dremain中的每个检测框,如果其检测得分高于∈,并且存在于2 个连续帧,则初始化一个新的轨迹。BYTE 数据关联算法如算法1 所示。

2 实验结果与分析
2.1 实验环境及参数
在Linux 系统上进行实验,所用的编程语言为Python,具体实验配置如表1 所述。

表1 实验配置Table 1 Experimental configuration
2.2 数据集和评估准则
使用UAVSwarm Dataset[20](https:∥github.com/UAVSwarm/UAVSwarm-dataset/)进行试验,共有12 598 张图像,其中训练集有6 844张,测试集有5 754张。选择UAVSwarm Dataset 训练集的全部样本进行训练,UAVSwarm Dataset测试集的全部样本进行测试。
MOT 算法需同时兼顾目标定位和时序关联问题,往往较难用单一指标来评测整个算法的性能。在MOT Challenge[21]中提供了一套学术届公认的指标来评价多目标跟踪算法性能,其主要由CLEAR MOT 指标[22]和ID 指标[23-24]构成。本文选择MOT Challenge 指标作为评分标准。各指标含义如表2 所述。

表2 多目标跟踪评价指标含义Table 2 Meanings of multi-object tracking evaluation indicators
2.3 实施细节
UAVS-MOT 模型使用FairMOT 模型作为基本框架并进行3 点改进,在主干网络引入CA注意力,将Re-ID 分支的损失函数替换为Arc-Face Loss 进行训练,并在数据关联部分使用BYTE 关联策略。本文通过Lheat、Lbox和LArcFace同时训练检测分支和Re-ID 分支,并通过Ltotal自动平衡这2 项任务。UAVS-MOT 仅使用单个图像作为输入,并且为每一个边界框分配唯一的ID,把数据集上每一个目标实例都看作单独的类。UAVS-MOT 不使用预训练参数初始化模型,使用Adam 优化器在UAVSwarm Dataset 的训练集上进行30 轮训练,batch size 设置为2。UAVSMOT 使用标准的HSV 增强技术,包括旋转、缩放、平移、剪切和颜色抖动。输入图像大小调整为1 088 pixel×608 pixel,特征图分辨率为272 pixel×152 pixel。
2.4 消融实验
在本实验中,对提出的多目标跟踪模型进行消融验证。本实验主要针对FairMOT(模型A)、增加CA 注意力的FairMOT(模型B)、增加CA 注意力和ArcFace Loss 的FairMOT(模型C)、增加CA 注意力和ArcFace Loss 以及BYTE 的Fair-MOT(模型D)的消融实验对比。如图3 所示,4 种消融模型的召回率(Recall)、IDF1和MOTA 的精度曲线呈上升趋势,可以看出本文的3 种改进模型中,模型D 的相关评价指标最高,实验结果最好。
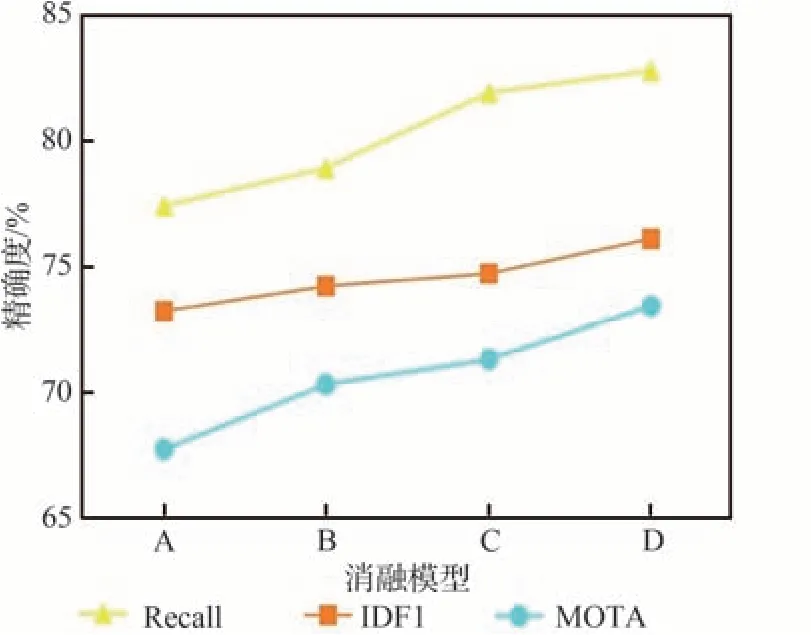
图3 消融模型的Recall、IDF1和MOTA 的精度曲线Fig.3 Accuracy curves of Recall,IDF1,and MOTA for ablation models
详细消融实验结果如表3 所述。其中,引入CA 注意力的B 模型的MOTA 提升了2.6%,IDF1提升了1.0%,可见CA 注意力能更准确地定位感兴趣目标的确切位置,从而帮助整个模型更好地识别;C 模型在B 模型的基础上增加了ArcFace Loss,MOTA 提升了3.6%,IDF1 提升了1.5%,MT 有所升高,可见ArcFace Loss 对Re-ID 分支的优化效果较好,能提取更精确的表观特征,增强其判别能力;D 模型在C 模型的结构上增加了BYTE数据关联方法,MOTA 较Baseline 提升了5.7%,IDF1 提升了2.9%,FN(漏检总数)有所下降,ML(低于20%的帧数被正确跟踪的轨迹数量或百分比)有所下降,Recall达到了最高,可见BYTE 数据关联方法较原关联方法更能降低漏检数并提高轨迹的连贯性。综上所述,D 模型为最优改进方案。

表3 消融实验结果Table 3 Results of ablation experiments
图4~图6展示了4种消融模型在UAVSwarm Dataset 训练集上的部分测试可视化结果。图4中模型A 在第0 帧共跟踪到6 个目标,直到第16 帧才跟踪到7 个目标;模型B 从第0 帧开始便已跟踪到7 个目标,并一直跟踪到序列结束。由此看出,模型B 相较于模型A 能更准确地识别出目标并进行持续定位。图5 中模型A 在第0 帧共跟踪到13 个目标,在第17 帧中ID 为126 的目标因为频繁遮挡导致跟踪丢失,在第28 帧依然未恢复跟踪;模型C 在第0 帧共跟踪到13 个目标,在第17 帧中ID 为111 的目标切换ID 为133,在第28 帧中ID 为133 的目标切换ID 为141。由此看出,模型C 对比模型A 增加了目标识别的准确性,但同时也增加了ID 切换次数。图6 中模型A在第38 帧共跟踪到7 个目标,在第64 帧共跟踪到13 个目标,存在许多漏检目标;模型D 在第38 帧共跟踪到10 个目标,在第51 帧中ID 为144 的目标和背景重合无法跟踪到,在第64 帧中ID 为144的目标被重新跟踪到,且ID 号保持不变。由此看出,模型D 相较于模型A 不仅可以对目标进行准确的识别和跟踪,又能保证目标轨迹的连续性。

图4 模型A和模型B 在UAVSwarm-10 序列上可视化结果(从左到右依次为第0、16和57 帧)Fig.4 Visualization results of Model A and Model B on UAVSwarm-10 sequence(Frame 0,16,and 57 from left to right)

图5 模型A和模型C 在UAVSwarm-14 序列上可视化结果(从左到右依次为第0、17、28 帧)Fig.5 Visualization results of Model A and Model C on UAVSwarm-14 sequence(Frame 0,17,and 28 from left to right)

图6 模型A和模型D 在UAVSwarm-16 序列上可视化结果(从左到右依次为第38、51和64 帧)Fig.6 Visualization results of Model A and Model D on UAVSwarm-16 sequence(Frame 38,51,and 64 from left to right)
2.5 对比实验
为了证明本文所提模型的有效性,在同等实验环境下,将UAVS-MOT 模型与CTrackerV1模型、SORT 模型、DeepSORT 模型、ByteTrack模型、FairMOT 模型进行对比。图7 展示了本文模型与其他5 种多目标跟踪模型的MOTA 指标与IDF1 指标对比情况,结果显示UAVS-MOT模型的MOTA 精确度均高于其他5 种模型,IDF1 精确度略低于ByteTrack 模型。详细对比结果如表4 所述。

表4 对比试验结果Table 4 Results of comparative tests
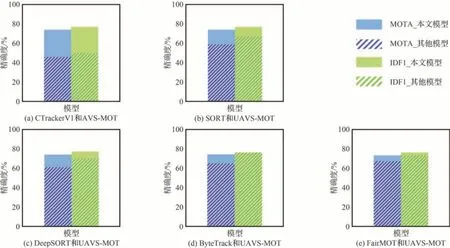
图7 对比模型的MOTA 与IDF1 精确度Fig.7 MOTA and IDF1 of models in comparison
从表4 中可以看出,本文所提出的UAVSMOT 模型在MOTA、FN、MT、ML和Recall 指标上明显优于其他5 种模型。在UAVSwarm Dataset 测试集上,UAVS-MOT 模型的MOTA比基准模型高出5.7%,IDF1 高出2.9%。由此可见,改进后的UAVS-MOT 模型能更准确的提取目标的表观特征,大幅提高目标间互相关联的准确度,提高模型跟踪精度。通过实验数据的对比,可以发现本文所提出的UAVS-MOT 在MOTA 指标表现出色,相较于其他5 种多目标跟踪模型具有显著优势。但是,IDS 指标和FP 指标略低于其他模型,解决目标ID 切换频繁和误检的问题仍有很大的进步空间。
图8 展示了UAVS-MOT 模型与其他5 种多目标跟踪模型的可视化跟踪对比,可以看出本文模型能更稳定的检测运动中的目标,并抗背景杂波干扰,从复杂背景中挖掘真正的目标,减少漏检和误检数量。例如,在第74 帧中,CTrackerV1 模型和SORT 模型都存在漏识别现象,而本文模型检测效果稳定;在第95 帧中,DeepSORT 模型和ByteTrack 模型都将路灯误识别为无人机,而本文模型识别准确。

图8 其他多目标跟踪模型与本文模型跟踪效果对比(从左到右依次为第74、95和104 帧)Fig.8 Comparison of tracking performance between other multi-objective tracking models and this model(Frame 74,95,and 104 from left to right)
图9 展示了在远距离探测背景下,UAVSMOT 模型相较于FairMOT 模型检测效果更好。例如,在第13 帧中,FairMOT 模型只检测到了5 个目标,漏检情况严重,而UAVS-MOT 模型检测到了9个目标;在第66帧中,UAVS-MOT 模型检测到了6 个目标,并且ID 与第39 帧中检测到的目标ID 连续,而FairMOT 模型检测的目标ID显示不连续。

图9 FairMOT 模型与UAVS-MOT 模型远距离检测效果对比(从左到右依次为第13、39和66 帧)Fig.9 Comparison of long range detection performance between FairMOT model and UAVS-MOT model(Frame 13,39,and 66 from left to right)
3 结论
从反制无人机集群的角度出发,对低空空域探测和跟踪无人机集群展开研究。针对在复杂场景及远距离探测条件下无人机集群目标之间相互遮挡、无人机为弱小目标等原因造成的检测精度降低和跟踪精度降低问题,提出了UAVSMOT 多目标跟踪模型。
1)针对无人机目标尺寸小、背景与目标易混淆等难点,在DLA-34 主干网络引入坐标注意力,将位置信息嵌入到通道注意力中,同时考虑了通道间关系和位置信息,有助于算法更好地定位和识别目标。
2)针对无人机之间互相遮挡导致ID 频繁切换、关联错误ID 等难点,将Re-ID 分支的损失函数替换为ArcFace Loss 进行训练,使其能提取更精确的表观特征,增强判别能力。
3)针对无人机飞行速度快、频繁飞入飞出导致轨迹不连续等难点,将数据关联部分更换为BYTE 数据关联方法,利用检测框和跟踪轨迹之间的相似性,在保留高分检测结果的同时,从低分检测结果中去除背景,挖掘出真正的物体。
