基于YOLOv5_4layers的PCB小目标缺陷识别方法
2024-04-30杨萍萍白艳茹
杨萍萍,白艳茹
北京科技大学高等工程师学院
0 引言
印制电路板(printed circuit board,PCB)作为集成各种电子元器件的信息载体,提供了电子元器件之间的连接和支持结构。及时准确地检测和识别PCB表面缺陷对确保电子设备的正常运行、质量控制和功能实现至关重要[1-6]。
深度学习技术的飞速发展,有效地克服了数据采集过程中外界干扰对目标检测的不利影响,在PCB缺陷识别方面取得了初步成效[7-8]。典型的YOLO系列模型因其相较于卷积神经网络(convolutional neural network,CNN)在特征提取实时性和精确性方面的优势,在PCB缺陷识别领域得到了广泛关注和认可。例如,利用YOLOv4目标检测算法,设计了PCB缺陷检测模型,并对模型性能进行评估[9];基于YOLOv5目标检测算法,设计了全新的PANet多特征融合结构,实现了高效的双向跨尺度连接和加权特征层融合[10];针对缺陷特性去除大目标检测尺度,保留中小目标检测尺度,改进了YOLOv5s网络,实现了PCB缺陷检测[11];对于小目标PCB表面缺陷检测能力较弱的情况,提出SPDYOLOv5模型,以SPDConv取代模型中各阶段的降采样卷积,提高模型对细节信息的关注度[12];将YOLOv5轻量化用于PCB缺陷检测,用GhostNet替换了原模型的特征提取网络,提升了模型对PCB缺陷检测的识别效果[13];在YOLOv5目标检测算法的基础上,设计了加强特征网路,实现了特征信息融合,引入注意力机制和Transformer结构,增强了模型捕捉全局信息能力,提升了模型准确率[14]等。这些探索与尝试对于提高PCB制造质量、降低成本、提高生产效率具有重要意义,但在小目标检测方面仍然存在不足。虽然采用多个预测尺度等方法来识别不同大小的目标,但可能无法在低分辨率的预测尺度上获得足够的特征信息,导致目标识别不准确。
为改善小目标的识别效果,本文基于传统深度学习YOLOv5架构的网络模型,通过新增采样层的方式添加了小目标检测层,优化特征金字塔模型,使其能够对更小的目标进行识别,在调整合适的锚框规格后,使其满足PCB表面缺陷识别的要求,提升整体识别性能,满足PCB生产制造的高标准、高效率、高精度要求。
1 基于YOLOv5架构的缺陷识别方法
1.1 YOLOv5网络结构及算法
YOLOv5是一种基于CNN的目标检测算法,具有训练速度快、检测精度高和模型权重小等优点。YOLOv5的网络结构主要分为输入端、Backbone、Neck、Prediction 4部分。其中,输入端用于接收图像并对其进行预处理;骨干网络Backbone负责对其进行特征提取;颈部Neck通过不同层级之间的特征融合形成特征金字塔;Head根据预定义锚框的大小处理不同层级的特征并输出对应的结果[15-17]。
YOLOv5训练过程中的正反向传播通过不断迭代传播过程,逐渐优化模型性能,提高目标检测的准确性和鲁棒性,使模型能够更准确地检测目标。实验使用的源码为官方发布的YOLOv5_5.0版本,使用Python语言编程,基于Pytorch环境实现,采用的数据集是由北京大学计算机视觉与模式识别实验室开发的用于缺陷识别与检测的数据集。该数据集包含1 386张PCB图像样本,每张图像上都标注了不同类型的瑕疵区域,共计6种瑕疵类型:缺失孔(missing_hole)、鼠标咬伤(mouse_bite)、开路(open_circuit)、短路(short)、杂散(spur)和伪铜(spurious_copper)。该数据集规模较大且瑕疵类型多样,标注精准,为算法的训练和评估提供了准确参考。
由于所提供的数据集将数据按照对应类别划分,且格式属于YOLOv5能够使用的VOC数据集格式,需要对其进一步整理。将其按照图片和标注划分为2个数据集,按照4:1的比例随机抽取划分为训练集及验证集。然后,对标注中.xml格式的数据进行解析,解析为.txt的格式,目的是将5类标签信息class、x_center、y_center、width、height转换为能够被YOLOv5使用的格式;最后,建立.txt文件作为训练集和验证集的路径指导。
1.2 评价指标
训练过程中,采用的评价指标为精确率(Precision)、召回率(Recall)、平均精度map@0.5和map@0.5:0.95。其中,Precision的表达式为
(1)
式中TP为正确目标检测个数;FP为错误目标检测个数。
Recall的表达式为
(2)
式中FN为漏检目标个数。
对于目标检测任务,每个分类都可以得到一条精度-召回率曲线PR Curve,即精确率与召回率的关系曲线,在不同阈值下计算,检测精度是曲线下面积AP的值。AP值越高,检测精度越高。map@0.5是将IoU设置为0.5时,计算每个类别中所有图像的AP并求平均值;map@0.5:0.95是步长为0.05时不同IoU阈值下的平均map,范围是0.5~0.95。
上述4个评价指标全面地关注模型的预测准确性、目标检测能力和泛化能力,在评估和比较不同模型或不同训练设置时提供了全面的评价,能够有效地评估神经网络的训练结果。通过分析这些指标,了解模型的性能优劣,从而对模型优化与改进。
1.3 训练结果与分析
在YOLOv5算法的基础上,使用相同的迭代次数100,设置了多种输入图像的大小作为实验参照。实验结果如表1所示。
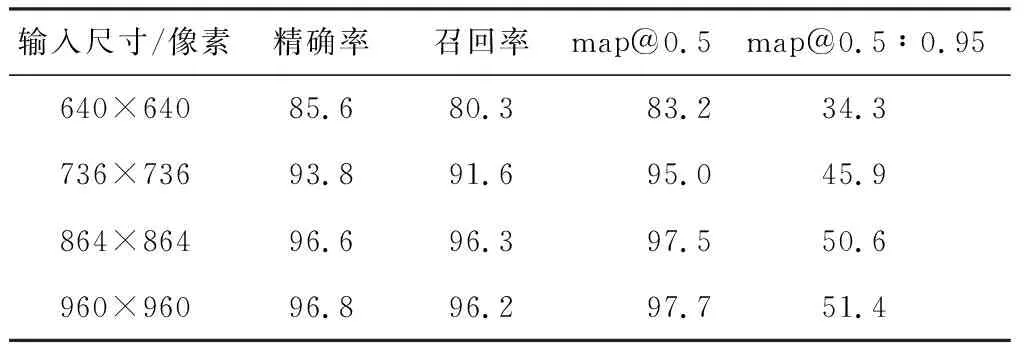
表1 基于YOLOv5的不同输入图像大小实验结果 %
输入图像的尺寸对模型的训练效果有一定影响,且随着图像尺寸的增大,模型的性能有所提升。尺寸由640像素×640像素提升为736像素×736像素时,性能提升效果显著,精确率提升了8.2%,召回率提升了11.3%。然而,将图像尺寸由736像素×736像素增加到864像素×864像素时,模型性能有所提升,但提升幅度有限,精确率提升了2.8%,召回率提升了4.7%。通过进一步观察可以发现,增加图像尺寸,性能提升效果有限,随着输入图像大小增加到960像素×960像素,精确率仅提升了0.2%,召回率出现下降。可以看出,增加输入图像的尺寸可以提升模型的性能,但提升效果逐渐减弱。因此,在选择图像尺寸时需要权衡计算资源和性能提升之间的关系,避免过度增加图像尺寸导致性能提升不明显或资源浪费。
选取最具有代表性的640像素×640像素和864像素×864像素输入图像尺寸的混淆矩阵,如图1(a)、图1(b)所示,可以看出针对不同分类,网络模型的性能有所提升。在输入图像尺寸为864像素×864像素时,观察其精确率和召回率图像,如图1(c)、图1(d)所示,可以看出虽然迭代次数设置为100,但迭代次数为70时已经趋近于稳定。
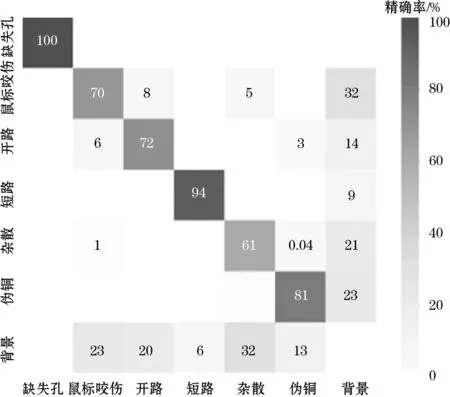
(a)混淆矩阵640像素×640像素
2 基于YOLOv5_4layers的小目标缺陷识别算法
2.1 YOLOv5_4layers网络结构
PCB表面缺陷特征比较微弱,且边缘通常比较模糊,容易被周围背景淹没。传统的YOLOv5网络采用多个预测尺度检测不同大小的目标,可能无法在低分辨率的预测尺度上获得足够的特征信息,导致目标识别不准确。为改善小目标缺陷的识别效果,在传统YOLOv5网络结构的基础上,增加1个小目标检测层,结构如图2所示。通过引入更细致的特征提取和更精确的定位机制,优化小目标缺陷的识别性能,使模型更好地适应小目标的特征和尺寸,减少漏检和误检的情况,提高整体的目标识别质量。

图2 YOLOv4_4layers结构图
具体实现过程如下:在网络模型中,增加一个预定义锚框[5,6,8,14,15,11],这些锚框的大小和长宽比能够更好地适应小目标缺陷的识别需求;在Neck(颈部)引入一个上采样层,对特征图进行上采样处理,使得原本较小的特征图扩大至160像素×160像素,增加特征图的分辨率;将上采样后的特征图与Backbone对应大小的底层特征图融合,构建多尺度的目标识别网络来获取更丰富的特征信息,以更准确地定位和识别小目标缺陷,提高召回率和准确率等性能指标。
2.2 实验与结果分析
在添加了小目标检测层后,将其与传统YOLOv5方法的运行结果进行对比,输入图像的大小为640像素×640像素。从表2可以看出,通过增加小目标检测层,网络模型的识别性能有所改善,精确率提升了7.5%,召回率提升了5.9%。同时,通过对比两者的混淆矩阵(如图3所示),可以看出在图像输入尺寸不变的情况下,鼠标咬伤、开路、短路、杂散和伪铜的识别精确度分别提升了17%、15%、5%、10%、12%。

图3 混淆矩阵640像素×640像素
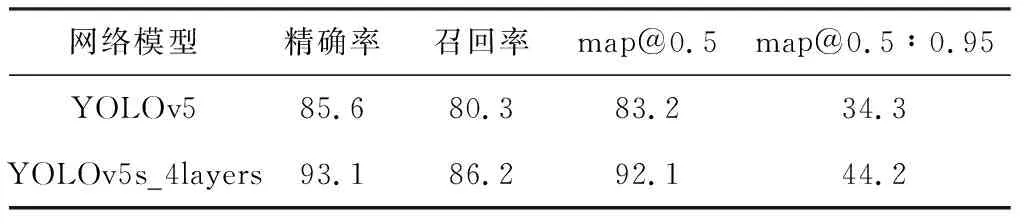
表2 640像素×640像素实验结果对比 %
进一步设置为736像素×736像素与传统YOLOv5方法的缺陷识别结果进行对比,如表3所示。可见召回率以及map@0.5有所下降,但精确率和map@0.5:0.95却有所上升。由于map@0.5:0.95考虑了不同IoU阈值的平均精度,表示模型在较高的IoU阈值下能够更好地定位目标,模型的边界框预测更加准确,且相对较大目标的识别准确率有所提升。

表3 736像素×736像素实验结果 %
考虑到可能由于输入图像的大小改变导致预设锚框与其不匹配的原因,通过改变不同锚框的大小进行实验。将[5,6,8,14,15,11]标记为Ⅰ;[7,8,10,13,16,30]标记为Ⅱ;[9,10,12,24,20,39]标记为Ⅲ;[10,13,16,30,33,23]标记为Ⅳ。实验结果如表4所示,可以看出新增预设锚框的大小对模型性能有影响,当预设锚框的大小为[9,10,12,24,20,39]时,模型整体性能相较Ⅰ均有较大提升,且精确率较传统YOLOv5方法也有所提升。
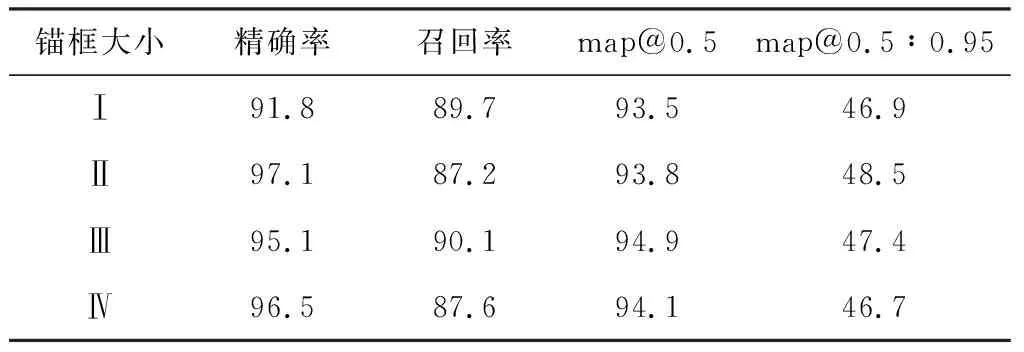
表4 锚框大小实验结果 %
2.3 目标识别结果可视化与分析
利用上述2种模型,对不同参数设置YOLOv5-640像素×640像素、YOLOv5-736像素×736像素、YOLOv5_4layers-640像素×640像素-[5,6,8,14,15,11]、YOLOv5_4layers-640像素×640像素-[9,10,12,24,20,39]的识别结果进行对比,如图4(a)、图4(b)所示,可以看出仅在增大图片输入尺寸的情况下,模型对PCB缺陷的识别能力有所提升。在增加小目标检测层后,如图4(c)所示,当锚框大小设置不符合所使用的数据集特征时,不能很好地捕捉图像的特征。当通过实验调整合适的锚框大小后,如图4(d)所示,模型对图像中缺陷的识别性能达到最佳,能够很好地通过多层特征金字塔对目标特征进行提取。
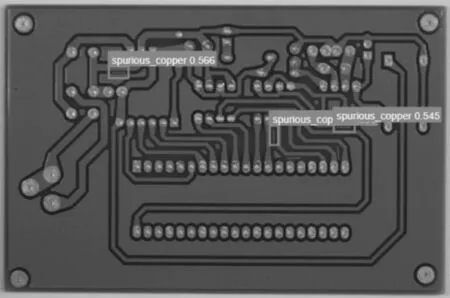
(a)YOLOv5-640像素×640像素
3 结束语
为了提高PCB表面缺陷识别分辨率和精准率,本文在传统YOLOv5架构的基础上,通过新增采样层的方式添加了小目标检测层,优化特征金字塔模型,提出了基于深度学习YOLOv5_4layers架构的PCB表面缺陷识别方法。以北京大学公开的PCB数据集为测试与验证对象,将YOLOv5_4layers与传统的YOLOv5进行对比分析。结果表明:本文所提出的方法在精确率、召回率、平均精度map@0.5和map@0.5∶0.95等方面有了较大改善,具有良好的缺陷识别性能。
