自适应特征融合的多模态实体对齐研究
2024-04-30李欣奕唐九阳郭延明
郭 浩 李欣奕 唐九阳 郭延明 赵 翔
近年来,以三元组形式表示现实世界知识或事件的知识图谱逐渐成为一种主流的结构化数据的表示方式,并广泛应用于各类人工智能的下游任务,如知识问答[1]、信息抽取[2]、推荐系统[3]等.相比于传统的知识图谱,多模态知识图谱[4-5]将多媒体信息融合到知识图谱中,从而更好地满足多种模态数据之间的交互式任务,例如图像和视频检索[6]、视频摘要[7]、视觉常识推理[8]和视觉问答[9]等,并在近年来受到了学界及工业界的广泛关注.
现有的多模态知识图谱往往从有限的数据源构建而来,存在信息缺失、覆盖率低的问题,导致知识利用率不高.考虑到人工补全知识图谱开销大且效率低,为提高知识图谱的覆盖程度,一种可行的方法[10-12]是自动地整合来自其他知识图谱的有用知识,而实体作为链接不同知识图谱的枢纽,对于多模态知识图谱融合至关重要.识别不同的多模态知识图谱中表达同一含义的实体的过程,称为多模态实体对齐[5,13].
与一般的实体对齐方法不同[11,14],多模态实体对齐需要利用和融合多个模态的信息.当前主流的多模态实体对齐方法[5,13]首先利用图卷积神经网络学习知识图谱的结构信息表示;然后利用预训练的图片分类模型,生成实体的视觉信息表示(利用VGG16[15]、ResNet[16]生成多张图片向量并加和),得到实体的视觉信息表示;最后以特定权重将这两种模态的信息结合.不难发现,这类方法存在以下3 个明显缺陷:
1) 图谱结构差异性难以处理.不同知识图谱中对等的实体通常具有相似的邻接信息,基于这一假设,目前的主流实体对齐方法主要依赖知识图谱的结构信息[14,17-18]来实现对齐.然而真实世界中,由于构建方式的不同,不同知识图谱可能存在着较大结构差异,这不利于找到潜在的对齐实体.如图1所示,实体 [The dark knight] 在 DBpedia 和 Free-Base 中邻接实体数量存在巨大差异,虽然包含相同的实体[Nolan]、[Bale],然而在FreeBase 还包含额外6 个实体.因此,DBpedia 中的实体 [Bale]容易错误地匹配到 FreeBase 中的实体 [Gary oldman],因为它们都是[The dark knight]的邻居实体且度数为 1.真实世界中不同知识图谱的结构性差异问题比图中的示例更为严峻,以数据集MMKG[5]为例,基于FreeBase 抽取得到的图谱 (FB15K)有接近60 万的三元组,而基于DBpedia 抽取得到的图谱(DB15K)中三元组数量不足10 万.以实体[Nolan]为例,在FB15K 中有成百的邻居实体;而DB15K中其邻居实体数量不足10 个.针对此类问题,可基于链接预测生成三元组以丰富结构信息.这虽然在一定程度上缓和了结构差异性,但所生成的三元组的可靠性有待考量.此外,在三元组数量相差多倍的情况下补全难度很大.

图1 知识图谱FreeBase 和DBpedia 的结构差异性表现Fig.1 Structural differences between knowledge graphs FreeBase and DBpedia
2) 视觉信息利用差.当前自动化构建多模态知识图谱的方法通常基于现有知识图谱补充其他模态的信息,为获取视觉信息,通常利用爬虫从互联网爬取实体的相关图片以获取其视觉信息.然而获取的结果中不可避免地存在部分相关程度较低的图片,即噪声图片.现有方法[5,13,19]忽略了噪声图片的影响,使得基于视觉信息对齐实体的准确率受限.因此,实体的视觉信息中混有部分噪声,进而降低了利用视觉信息进行实体对齐的准确率.
3) 多模态融合权重固定.当前的主流多模态实体对齐方法[5,13]以固定的权重结合多个模态.这类方法假设多种模态信息对实体对齐的贡献率始终为一固定值,并多依赖于多模态知识图谱的结构信息,然而其忽略了不同模态信息的互补性.此外,由于实体相关联的实体数量以及实体在图谱中分布不同,导致不同实体的结构信息有效性存在一定的差异,进一步影响不同模态信息的贡献率权重.事实上,知识图谱中超过半数实体都是长尾实体[20],这些实体仅有不足5 个相连的实体,结构信息相对匮乏.而实体的视觉信息却不受结构影响,因此在结构信息匮乏的情况下应赋予视觉信息更高的权重.总而言之,以固定的权重结合多模态信息无法动态调节各个模态信息的贡献率权重,导致大量长尾实体错误匹配,进一步影响实体对齐效果.
为解决上述缺陷,本文创新性地提出自适应特征融合的多模态实体对齐方法(Adaptive feature fusion for multi-modal entity alignment,AF2MEA).在不失一般性的前提下,本文从多模态知识图谱中的结构模态和视觉模态两方面出发: 一方面为解决缺陷 1),提出三元组筛选机制,通过无监督方法,结合关系PageRank 得分以及实体度,为三元组打分,并过滤掉无效三元组,缓和结构差异性;另一方面,针对缺陷 2),利用图像-文本匹配模型,计算实体-图片的相似度得分,设置相似度阈值以过滤噪声图片,并基于相似度赋予图片不同权重,生成更高质量的实体视觉特征表示.此外,为捕获结构信息动态变化的置信度并充分利用不同模态信息的互补性以应对缺陷 3),本文设计自适应特征融合机制,基于实体节点的度数以及实体与种子实体之间的距离,动态融合实体的结构信息和视觉信息.这种机制能够有效应对长尾实体数量占比大且结构信息相对匮乏的现实问题.本文在多模态实体对齐数据集上进行了充分的实验及分析,表明AF2MEA取得了最优的实体对齐效果并证实了提出的各个模块的有效性.本文的主要贡献可总结为以下3 个方面:
1) 设计创新的三元组筛选模块,基于关系PageRank 评分和实体度生成三元组得分,过滤三元组,缓和不同知识图谱的结构差异性;
2)针对视觉信息利用差的问题,本工作基于预训练图像-文本匹配模型,计算实体-图片的相似度得分,过滤噪声图片,并基于相似度得分获得更准确的实体视觉特征表示;
3)设计自适应特征融合模块,以可变注意力融合实体的结构特征和视觉特征,充分利用不同模态信息之间的互补性,进一步提升对齐效果.
本文第1 节简要介绍相关工作;第2 节介绍问题定义和整体框架;第3 节具体介绍本文提出的多模态实体对齐模型;第4 节明确实验设置,进行实验并分析结果;第5 节为结束语.
1 相关工作
1.1 实体对齐
实体对齐任务旨在寻找两个知识图谱中描述同一真实世界对象的实体对,以便链接不同知识图谱.实体对齐作为整合不同知识图谱中知识的关键步骤,在近年来得到广泛研究.
传统的实体对齐方法[21]多依赖本体模式对齐,利用字符串相似度或者规则挖掘等复杂的特征工程方法[22]实现对齐,但在大规模数据下准确率及效率显著下降.而当前实体对齐方法[14,17,23]大多依赖知识图谱向量,因为向量表示具有简洁性、通用性以及处理大规模数据的能力.基于不同知识图谱中等效实体具有相似的邻接结构这一假设,即等效的实体通常具有等效的邻居实体,这些工作具有相似框架: 首先利用基于翻译的表示学习方法 (Translating embedding,TransE)[17,24-25],图卷积神经网络(Graph convolutional network,GCN)[9,14]等知识图谱表示方法编码知识图谱结构信息,并将不同知识图谱中的元素投射到各自低维向量空间中.接着设计映射函数,利用已知实体对以对齐不同向量空间.考虑到GCN 在学习知识图谱表示上存在忽略关系类型、平均聚合相邻节点特征的缺陷,一些方法[26-27]利用基于注意力机制的图神经网络模型来为不同的相邻节点分配不同的权重.文献[28]通过学习知识图谱的关系表示以辅助生成实体表示.
除生成并优化结构表示之外,部分方法[14,26,29]提出引入属性信息以补充结构信息.文献[29]提出利用属性类型生成属性向量;而文献[14]则将属性表示成最常见属性名的One-hot 向量.这类工作均假设图谱中存在大量属性三元组.但文献[30]指出,在大多数知识图谱中,69%~ 99%的实体至少缺乏1 个同类别实体具有的属性.这种情况限制了此类方法的通用性.
1.2 多模态实体对齐
多数知识图谱的构建工作都倾向以结构化形式来组织和发现文本知识,而很少关注网络上的其他类型的资源[4,31].近年来,不同模态数据之间交互式任务大量涌现,如图像和视频检索[6]、视频摘要生成[7]、视觉实体消歧[8]和视觉问答[9]等.为满足跨模态数据交互式任务的需求,知识图谱需要融合多媒体信息,多模态知识图谱应运而生.
为提高多模态知识图谱的覆盖程度,多模态实体对齐是关键的一步.与实体对齐相似,多模态实体对齐任务旨在识别不同的多模态知识图谱中表达同一含义的实体对[13,19].相关的多模态知识表示方法可用于多模态实体对齐任务,其中基于图像的知识表示模型 (Image-embodied knowledge representation learning,IKRL)[32]通过三元组和图像学习知识表示,首先使用神经图像编码器为实体的所有图像构建表示,然后通过基于注意力的方法将这些图像表示聚合到实体基于图像的集成表示中.文献[33]提出一种基于多模态翻译的方法,将知识图谱中三元组的损失函数定义为结构表示、视觉表示和语言知识表示的子损失函数的总和.
总的来说,多模态实体对齐是一个新颖的问题,目前直接针对该任务的研究相对较少.其中,文献[5]利用专家乘积模型 (Product of experiment,PoE),综合结构、属性和视觉特征的相似度得分以找到潜在对齐的实体.文献[13]注意到欧几里得空间中知识图谱的结构表示存在失真问题,利用双曲图卷积神经网络 (Hyperbolic graph convolutional network,HGCN) 学习实体结构特征和视觉特征,并在双曲空间中结合不同模态特征以寻找潜在的对齐实体.文献[19]提出一种创新的多模态知识表示方法,分别设计了多模态知识表示模块和知识融合模块,融合实体结构特征、属性特征和视觉特征到同一个向量空间中以对齐实体.该模型取得较好的对齐效果,但结构设计较为复杂,视觉特征的利用率不高.
2 问题定义与整体框架
本节主要介绍多模态实体对齐任务的定义以及本文提出的整体模型框架.
2.1 任务定义
多模态知识图谱通常包含多个模态的信息.鉴于大多数知识图谱中属性信息的缺失[30],在不失一般性的前提下,本工作关注知识图谱的结构信息和视觉信息.给定2 个多模态知识图谱MG1和MG2:MG1=(E1,R1,T1,I1),MG2=(E2,R2,T2,I2).其中,E代表实体集合;R代表关系集合;T代表三元组集合,三元组表示为 〈E,R,E〉 的子集;I代表实体相关联的图片集合.种子实体对集合S=表示用于训练的对齐的实体对集合.多模态实体对齐任务旨在利用种子实体对,发现潜在对齐的实体对,其中等号代表两个实体指代真实世界中同一实体.
给定某一实体,寻找其在另一知识图谱中对应实体的过程可视为排序问题.即在某一特征空间下,计算给定实体与另一知识图谱中所有实体的相似程度(距离) 并给出排序,而相似程度最高(距离最小)的实体可视为对齐结果.
2.2 模型框架
本工作提出的自适应特征融合的多模态实体对齐框架如图2 所示.首先利用图卷积神经网络学习实体的结构向量,生成实体结构特征;设计视觉特征处理模块,生成实体视觉特征;接着基于自适应特征融合机制,结合2 种模态的信息进行实体对齐.此外,为缓和知识图谱的结构差异性,本工作设计三元组筛选机制,融合关系评分及实体的度,过滤部分三元组.图2 中MG1和MG2分别表示不同的多模态知识图谱;KG1、KG2表示知识图谱;KG′1表示三元组筛选模块处理后的知识图谱.

图2 自适应特征融合的多模态实体对齐框架Fig.2 Multi-modal entity alignment framework based on adaptive feature fusion
3 多模态实体对齐模型
本节介绍提出的多模态实体对齐框架的各个子模块,包括视觉特征处理模块、结构特征学习模块、三元组筛选模块以及自适应特征融合模块.
3.1 视觉特征处理模块
当前多模态知识图谱的视觉信息图片来源于互联网搜索引擎,不可避免地存在噪声图片,不加区分地使用这些图片信息会导致视觉信息利用率差.而图像-文本匹配模型[34-35]可以计算图像与文本的相似性程度.受此启发,为解决视觉信息利用率差的问题,本工作设计了视觉特征处理模块,为实体生成更精确的视觉特征以帮助实体对齐.图3 详细描述了实体视觉特征的生成过程.在缺乏监督数据的情况下,本文采用预训练的图像-文本匹配模型,生成图片与实体相似度;接下来设置相似度阈值过滤噪声图片;最后基于相似度得分赋予图片相应的权重,最终生成实体的视觉特征表示,具体步骤如下:
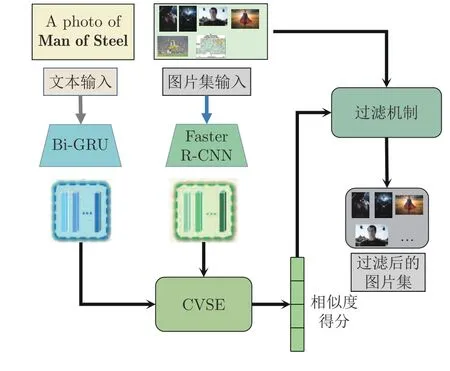
图3 视觉特征处理模块Fig.3 Visual feature processing module
1) 计算图片-实体相似度得分.本步骤使用预训练的文本图像匹配模型-共识感知的视觉语义嵌入模型(Consensus-aware visual semantic embedding,CVSE)[36]计算实体图片集中各个图片的相似度得分.CVSE 模型将不同模态间共享的常识知识结合到图像-文本匹配任务中,并在数据集MSCOCO[37]和Flickr30k[38]上进行模型训练,取得先进的图文匹配效果.本文基于CVSE 模型及其训练的参数计算图片-实体相似度得分.
视觉特征处理模块的输入为实体的名称和实体相应的图片集,见图3 左侧.首先生成实体图片集的图片嵌入pi ∈Rn×36×2048,n为实体对应图片集中图片的数量.本文利用目标检测算法Faster RCNN[39]为每幅图片生成36×2 048 维的特征向量.然后将实体名[Entity Name]拓展为句子{A photo of Entity Name},再送入双向门控循环单元(Bidirectional gated recurrent unit,Bi-GRU)[40]以生成实体的文本信息ti.
接着将图片嵌入pi和文本信息ti送入CVSE模型中,本文移除CVSE 模型的 S oftmax 层,以获取实体图像集中图片的相似度得分:
其中,CVSE表示共识感知的视觉语义嵌入模型,其运算结果Rn表示图片集与文本的相似度得分.
2)过滤噪声图片.考虑到实体的图片集中存在部分相似度很低的图片,影响视觉信息的精度.鉴于此,设置相似度阈值α,以过滤噪声图片:
其中,set(i) 代表初始图片集,set′(i) 表示过滤掉噪声图片后的图片集,α是相似度阈值超参数.
3)实体视觉特征表示生成.对于set′(i) 中的图片,本文基于其相似度得分赋予权重,为实体ei生成更精确的视觉特征表示Vi:
其中,Vi ∈R2048表示实体i的视觉特征;R2048×n′为ResNet 模型生成的图像特征,n′为去除噪声后的图片数量;atti表示图片注意力权重:
3.2 结构特征学习模块
本文采用图卷积神经网络 (GCN)[41-42]捕捉实体邻接结构信息并生成实体结构表示向量.GCN是一种直接作用在图结构数据上的卷积网络,通过捕捉节点周围的结构信息生成相应的节点结构向量:
其中,Hl,Hl+1分别表示l层和l+1 层节点的特征矩阵;Wl表示可训练的参数;=D1/21/2表示标准化的邻接矩阵,其中D为度矩阵;=A+I,A表示邻接矩阵,若实体和实体之间存在关系,则Aij=1;I表示单位矩阵.激活函数σ设为 ReLU.
由于不同知识图谱的实体结构向量并不在同一空间中,因此需要利用已知实体对集合S将不同知识图谱中的实体映射到同一空间中.具体的训练目标为最小化下述损失函数:
其中,(x)+=max{0,x};S′代表负样本集合,基于已知的种子实体对 (e1,e2),以随机实体替换e1或者e2生成.he代表实体e的结构向量,代表实体e1和e2之间的曼哈顿距离;超参数γ代表正负例样本分隔的距离.
3.3 三元组筛选模块
知识图谱的结构特征以三元组形式表示: (h,r,t),其中,h代表头实体,t代表尾实体,r代表关系.不同知识图谱三元组的数量差异较大,导致基于结构信息进行实体对齐的效果大打折扣.为缓和不同知识图谱的结构差异性,本工作设计三元组筛选模块,评估三元组重要性,并基于重要性得分过滤部分无效三元组.筛选流程如图4 所示,其中三元组重要性得分结合关系r的PageRank 得分,以及实体h和t的度.
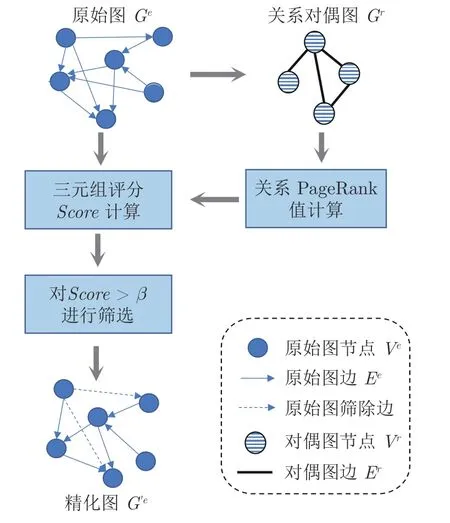
图4 三元组筛选模块Fig.4 Triples filtering module
1)关系PageRank 评分计算.首先构建以关系为节点、实体为边的关系-实体图,也称知识图谱的关系对偶图[43].定义知识图谱为Ge=(V e,Ee),其中V e为实体集合,Ee为关系集合.而关系对偶图Gr=(V r,Er)以关系为节点,若两个不同的关系由同一个头实体 (尾实体) 连接,则这两个关系节点间存在一条边.Vr为关系节点的集合,Er为边的集合.
基于上述生成的关系对偶图,本文使用Page-Rank[44]算法计算关系得分.PageRank 算法是图结构数据上链接分析的代表性算法,属于无监督学习方法.其基本思想是在有向图上定义一个随机游走模型,描述随机游走者沿着有向图随机访问各个结点的行为.在一定条件下,极限情况访问每个结点的概率收敛到平稳分布,这时各个结点的平稳概率值就是其PageRank 值,表示结点的重要度.受该算法的启发,基于知识图谱关系对偶图,计算关系的PageRank 值以表示关系的重要性:
其中,PR(r) 为关系的PageRank 评分;关系v ∈Br,Br表示关系r的邻居关系集合;L(v) 代表与关系v连接的关系数量 (即关系节点的度数).
2)三元组评分机制.对三元组的筛选,一方面要过滤掉冗余或无效的关系;另一方面要保护知识图谱的结构特征.由于结构信息缺乏的长尾实体仅有少量相关三元组,若基于关系重要性评分直接过滤一种关系可能会加剧长尾实体的结构信息匮乏问题.为此,本工作结合关系的PageRank 评分和头尾实体的度,设计三元组评分函数:
其中,dh和dt分别表示头实体和尾实体的度,即实体相关联的边的数量.基于三元组评分Score,并设置阈值β,保留Score(h,r,t)>β的三元组,以精化知识图谱.值得注意的是,阈值β的取值由筛选的三元组数量决定.
3.4 自适应特征融合模块
多模态知识图谱包含至少2 个模态的信息,多模态实体对齐需要融合不同模态的信息.已有的方法将不同的嵌入合并到一个统一的表示空间中[45],这需要额外的训练来统一表示不相关的特征.更可取的策略是首先计算不同模态特征在其特定空间内的相似度,然后组合各个模态特征的相似度得分以寻找匹配的实体对[14,46].
形式上,给定结构特征向量表示S,视觉特征表示V.计算每个实体对 (e1,e2) 中实体之间的相似度得分,然后利用该相似度得分来预测潜在的对齐实体.为计算总体相似度,当前方法首先计算e1和e2之间的视觉特征向量相似度得分Simv(e1,e2)和结构特征向量的特征相似度得分Sims(e1,e2).相似度得分一般用向量的余弦相似度或曼哈顿距离表示.接下来,以固定权重结合上述相似度得分:
其中,Atts和Attv分别代表结构信息和视觉信息的贡献率权重;Sim(e1,e2) 表示最终的实体相似度得分.
不同模态的特征从不同视角表征实体,具有一定相关性和互补性[47-49].当前多模态实体对齐方法以固定的权重结合结构信息和视觉信息,认为多种模态信息对实体对齐的贡献率始终为一定值,忽略了不同实体之间结构信息的有效性差异.基于度感知的长尾实体对齐方法[10]首次提出动态赋予不同特征重要性权重的方法,设计了基于度感知的联合注意力网络,提升了长尾实体的对齐准确率.这证明实体结构信息的有效性与实体度的数量呈正相关,并且不同知识图谱中对等的实体通常具有对等的邻居实体,实体与种子实体关联的密切程度与其结构特征的有效性也呈正相关.而实体的视觉信息的有效性不受此类影响,对于结构信息匮乏的实体,应更多地信任视觉信息.
基于此,为捕捉不同模态信息的贡献率动态变化,本工作基于实体度的数量,并进一步结合实体与种子实体关联的密切程度,设计自适应特征融合机制:
其中,K,b,a均为超参数,degree表示该实体的度数,Nhop表示实体与种子实体关联密切程度:
其中,n1-hop和n2-hop分别表示距离种子实体1 跳和2 跳的实体数量;w1和w2为超参数.
4 实验
本节首先介绍实验的基本设置,包括参数设置、数据集、对比方法以及评价指标.接着展示在多模态实体对齐任务上的实验结果,并进行消融分析以验证各个模块的有效性.此外,对各个模块进行分析,验证设计的合理性及有效性.
4.1 数据集和评价指标
在实验中,我们使用文献[5]构建的多模态实体对齐数据集MMKG.数据集MMKG 从知识库FreeBase、DBpedia 和Yago 中抽取得到,包含两对多模态数据集FB15K-DB15K 和FB15K-Yago15K.表1 描述了数据集的详细信息.SameAs 表示等效实体.在实验中,等效实体以一定比例划分,分别用于模型训练和测试.

表1 多模态知识图谱数据集数据统计Table 1 Statistic of the MMKGs datasets
由于数据集不提供图片,为获取实体相关图片,本文基于数据集MMKG 创建URI (Uniform resource identifier)数据,并设计网络爬虫,解析来自图像搜索引擎 (即Google Images、Bing Images 和Yahoo Image Search) 的查询结果.然后,将不同搜索引擎获取的图片分配给不同的MMKG.为模拟真实世界多模态知识图谱的构建过程,去除等效实体图像集中相似度过高的图片,并引入一定数量的噪声图片.
本文实验使用Hits@k(k=1, 10) 和平均倒数排名 (Mean reciprocal rank,MRR) 作为评价指标.对于测试集中每个实体,另一个图谱中的实体根据它们与该实体的相似度得分以降序排列.Hits@k表示前k个实体中包含正确的实体的数量占总数量的百分比;另一方面,MRR 表示正确对齐实体的倒数排序的平均值.MRR 是信息检索领域常用的评价指标之一,表示目标实体在模型预测的实体相关性排序中排名的倒数的平均值.注意,Hits@k和 MRR数值越高表示性能越好,Hits@k的结果以百分比表示.表2 和表3 中以粗体标注最好的效果.Hits@1代表对齐的准确率,通常视为最重要的评价指标.
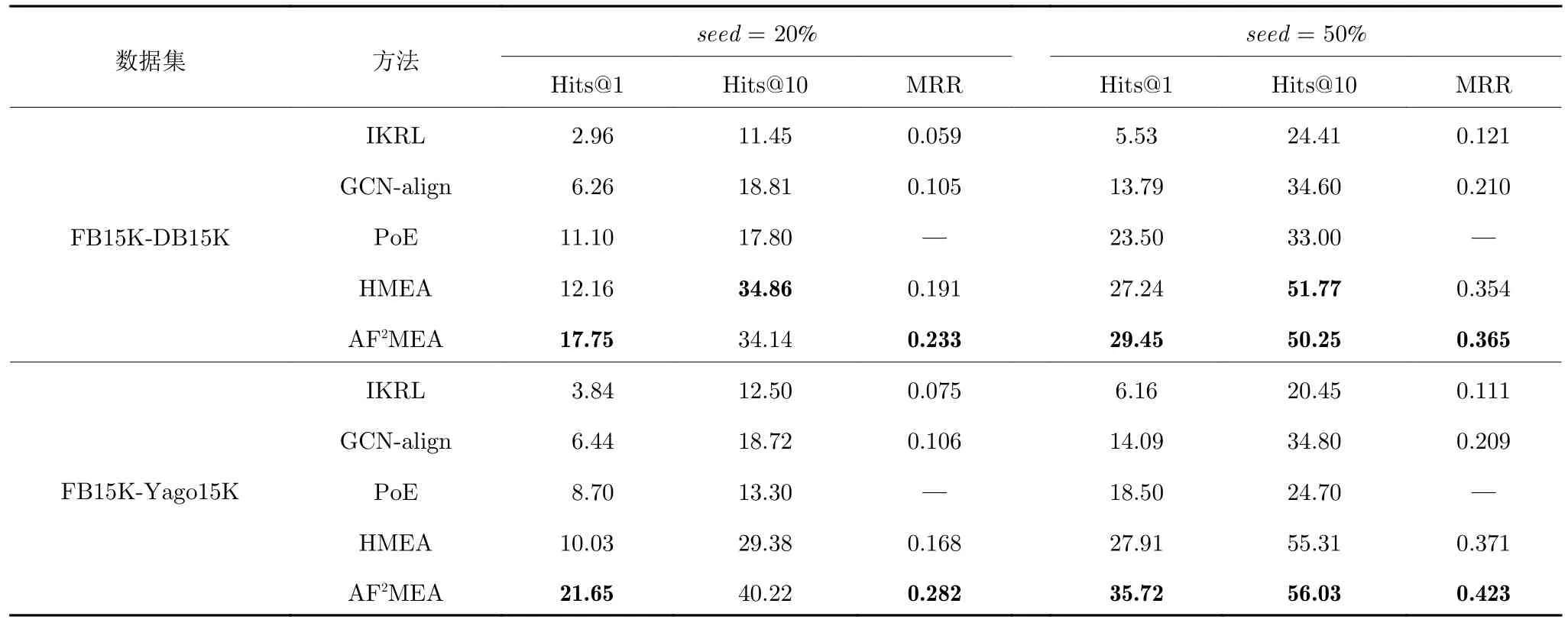
表2 多模态实体对齐结果Table 2 Results of multi-modal entity alignment

表3 消融实验实体对齐结果Table 3 Entity alignment results of ablation study
4.2 参数设置和对比方法
实体结构特征由图卷积神经网络生成,负例数量设定为15,边缘超参数γ=3,训练400 轮,维度ds=300.视觉特征由第3.1 节中提出的视觉特征处理模块生成,维度dv=2 048;相似度阈值α的值是基于比例确定的,对于每个实体的图片集,保留相似度前50%的图片,过滤其余50%的噪声图片.基于文献[5,13]的实验设置,将种子实体的比例设置为20%和50%,并且选取10%的实体作为验证集,用于调整式(10) 和式(12) 中超参数,其中,b=1.5,a=1.参数K的取值与种子实体的比例相关,实验中设定的种子实体比例seed不同,则K取值也不同,当seed=20% 时,K取值为0.6;当seed=50%时,K取值为0.8.式(12)中超参数w1和w2分别取0.8 和0.1.三元组筛选模块中的阈值β也是基于验证集调整得来,取值为0.3,将FB15K 的三元组量筛选至约30 万.
此外,将本文提出的模型 (AF2MEA) 与以下4 种方法进行对比.
1) IKRL 方法[32].通过基于注意力的方法,将实体的图像表示与三元组知识聚合到实体的集成表示中以对齐实体.
2) GCN-align 方法[14].利用GCN 生成实体结构和视觉特征矩阵,以固定权重结合两种特征以对齐实体.
3) PoE 方法[5].基于提取的结构、属性和视觉特征,综合各个特征的相似度得分以找到潜在对齐的实体.
4) HMEA (Hyperbolic multi-modal entity alignment)方法[13].利用双曲图卷积神经网络HGCN生成实体的结构和视觉特征矩阵,并在双曲空间中以权重结合结构特征和视觉特征,进行实体对齐.
4.3 主实验
通过表2 可以明显看出,与IKRL、GCN-align、PoE 以及HMEA 方法相比,本文提出的方法取得最好的实验结果.在数据集FB15K-DB15K 上,本文提出的方法AF2MEA 的Hits@1 值显著高于当前最优方法HMEA,尤其在种子实体比例为20%条件下,Hits@1 指标的提升超过5%,MRR 也取得大幅提升.此外,在各项指标上,本文所提AF2MEA均大幅领先IKRL、GCN-align 以及PoE.
在数据集FB15K-Yago15K 上,与其他4 种模型相比,AF2MEA 在全部指标上均有大幅提升,进一步验证了本文提出的模型的有效性.其中,在种子实体比例为20%和50%的条件下,AF2MEA 的Hits@1 指标较HMEA 分别提升约11%和8%.
4.4 消融实验
本文创新性地设计了模型的3 个模块,分别是视觉特征处理模块、三元组筛选模块和自适应特征融合模块.为验证各模块对于多模态实体对齐任务的有效性,本节进一步设计了消融实验.其中,AF2MEA-Adaptive、AF2MEA-Visual和AF2MEA-Filter分别表示去除特征融合模块的模型、去除视觉特征处理模块的模型和去除三元组筛选模块的模型,通过与本文提出的完整模型AF2MEA 进行对比来检测各模块的有效性.
本文消融实验分别在数据集FB15K-DB15K和FB15K-Yago15K 上进行,并分别基于20%和50%种子实体比例进行实验对比.表3 展示了消融实验的结果,完整模型在所有情况下均取得最好的实体对齐效果,去除各个子模块都使得对齐准确率出现一定程度的下降.
对表3 进行具体分析可知,三元组筛选模块对实体对齐影响最大: 在种子实体占比20%的条件下,去除该模块导致Hits@1 指标在数据集FB15KDB15K 和FB15K-Yago15K 上分别下降3.6%和6.8%;在种子实体占比50%的条件下,去除三元组筛选模块导致的性能下降更多,约为7%和8%.此外,去除视觉特征处理模块和自适应特征融合模块也对实体对齐效果产生了一定程度的影响.在数据集FB15K-DB15K 上,去除视觉特征处理模块和去除自适应特征融合模块导致近似相同程度的Hits@1指标的下降,在种子实体占比为20%时下降1.5%以上,在种子实体占比为50%时下降超过3%.
4.5 各子模块分析
1)视觉特征处理模块.视觉特征处理模块包含基于相似度注意力的图片特征融合机制和基于相似度的图片过滤机制.为验证上述两种机制的有效性,本节设计了对比实验,其中Att、Filter 分别表示基于相似度注意力的图片特征融合机制和基于相似度的图片过滤机制.Att+Filter 表示结合两种机制,即本文提出的视觉特征处理模块.HMEA-v 表示文献[13]提出的视觉特征处理方法.
由表4 可知,本文提出的基于相似度注意力的图片特征融合机制与HMEA-v 相比,在所有指标上均有较大提升,在种子实体占比20%的情况下,Hits@1 提升超过6%,MRR 也取得很大提升.此外,两个模块Att、Filter 结合取得了最好的对齐效果,相比单纯使用注意力模块有了小幅的提升.

表4 实体视觉特征的对齐结果Table 4 Entity alignment results of visual feature
2)三元组筛选模块.为验证本文提出的三元组筛选模块的有效性,本文对比了 FPageRank、Frandom和 Four三种筛选机制,分别代表基于PageRank 评分筛选机制、随机筛选机制以及本文设计的筛选机制.为控制实验变量,本实验使用上述三种筛选机制筛选了相同数量的三元组,约30 万,并基于图卷积神经网络学习结构特征,保持各参数一致.
实验结果表明,随机筛选 Frandom相较于保留所有三元组的基线,其Hits@1 在seed=20%和seed=50%的情况下分别提升约1.5%和2.5%,表明图谱结构差异性对于实体对齐存在一定的影响.基于PageRank 评分的筛选机制相比于随机筛选,在种子实体比例为50%的情况下,提升3%左右.由表5可知,本文提出的三元组筛选机制取得了最优对齐结果,在FB15K-DB15K 上与基线对比,Hits@1 指标在不同种子实体比例下分别提升约3% 和8%;在FB15K-Yago15K 上,Hits@1 指标分别提升约5%和9%.

表5 不同三元组筛选机制下实体结构特征对齐结果Table 5 Entity alignment results of structure feature in different filtering mechanism
3)自适应特征融合模块.本文提出的自适应特征融合,结合实体度以及实体与种子实体的关联程度,赋予不同模态信息动态的贡献率权重.第4.4 节中消融实验结果已证明自适应特征融合机制的有效性,为进一步验证该机制对结构信息匮乏的实体的对齐效果,本节对比自适应特征融合机制和固定权重特征融合两种方法.
由于结构信息的丰富程度与实体的度相关,我们按照实体度的数量将实体划分为3 类,在这3 类实体上分别测试本文提出的自适应融合机制和固定权重机制下多模态实体对齐的准确率.本实验种子实体比例设置为20%,分别在数据集FB15K-DB15K与FB15K-Yago15K 上进行,相关参数与第4.4 节中消融实验保持一致.
表6 展示了自适应特征融合与固定权重融合的多模态实体对齐结果.其中Fixed 和Adaptive 分别代表固定权重融合机制和自适应特征融合机制;Group 1、Group 2 和Group 3 分别表示前1/3、中间1/3 和后1/3 部分实体,基于实体度从小到大划分.由表6 可知,自适应特征融合机制相比固定权重融合,在各类实体上均取得更好的实体对齐效果.图5 表示自适应特征融合与固定权重融合的实体对齐Hits@1 对比,可以清晰地看出,在Group 1 上提升显著高于Group 2 和Group 3,证明本文提出的自适应特征融合机制可显著提升结构信息匮乏的实体即长尾实体的对齐准确率.

表6 自适应特征融合与固定权重融合多模态实体对齐结果Table 6 Multi-modal entity alignment results of fixed feature fusion and adaptive feature fusion
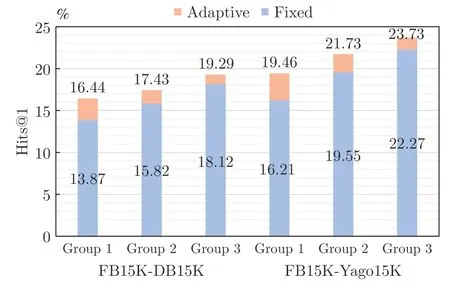
图5 自适应特征融合与固定权重融合的实体对齐Hits@1 对比Fig.5 Entity alignment Hits@1's comparison of adaptive feature fusion and fixed feature fusion
4.6 补充实验
本工作旨在结合知识图谱中普遍存在的结构信息和不同模态的视觉信息,并提升视觉信息的有效利用.MMEA (Multi-modal entity alignment)[19]模型取得了较好的实验结果,但本文使用的数据集与其使用的数据集存在一定差异,因此没有将MMEA 作为主实验中的对比模型.为证明本文提出方法的有效性,我们在AF2MEA 原有的结构信息和视觉信息的基础上,添加属性信息,并在数据集FB15K-Yago15K 上进行对比实验.我们对属性信息进行简单处理: 首先基于种子实体找到对应属性,利用对应属性的数值对实体对进行相似度打分.由于实体属性值不受实体结构的影响,我们再次使用自适应特征融合模块以融合属性信息,寻找潜在的对齐实体.
如表7 所示,基于相同实验条件,本文提出的模型AF2MEA 的效果显著优于PoE 模型及MMEA模型.在种子实体比例为20%的情况下,与MMEA相比,本文提出的方法在Hits@1 指标上取得5%以上的提升.在种子实体比例为50% 的情况下,AF2MEA 的Hits@1 值达到48.25%,高出MMEA约8%.在指标Hits@10 以及MRR 上,AF2MEA也有较大的提升.这进一步证明了本文提出框架的有效性和可扩展性.

表7 补充实验多模态实体对齐结果Table 7 Multi-modal entity alignment results of additional experiment
5 结束语
为解决多模态知识图谱不完整的问题,本文提出自适应特征融合的多模态实体对齐方法AF2MEA,设计自适应特征融合机制实现多种模态信息有效融合,充分利用多模态信息间的互补性.并且,当前多模态知识图谱中视觉信息利用率不高,本文基于预训练的图像-文本匹配模型,设计了视觉特征处理模块,为实体生成更精确的视觉特征表示.此外,注意到不同知识图谱之间存在较大的结构差异限制实体对齐的效果,本文设计三元组筛选机制,缓和结构差异.该模型在多模态实体对齐数据集上取得最好的效果,并显著提升实体对齐准确率.
后续工作将进一步研究多模态特征联合表示、预训练实体对齐模型等多模态实体对齐的相关问题,构建高效可行的多模态知识图谱融合系统.
