基于边界辅助判别的滚动轴承故障特征增强及诊断方法*
2024-04-24李佰霖鲁大臣付文龙陈禹朋
李佰霖,鲁大臣,付文龙,陈禹朋
(三峡大学 电气与新能源学院,湖北 宜昌 443002)
0 引 言
滚动轴承作为机械设备的关键组成部分[1],一旦发生故障,将对设备运行的安全性和可靠性产生严重影响,甚至会导致设备的故障和损坏[2]。因此,确保滚动轴承故障诊断的准确性对提高设备的性能和延长使用寿命至关重要[3-4]。
传统的轴承故障诊断方法通常依赖大量的人工专家知识,并且需要手动设置规则,这限制了其在大规模和复杂系统中的应用。然而,随着人工智能技术的不断发展,研究人员提出了一系列深度学习(deep learning, DL)[5]的网络模型,为故障诊断领域提供了新方法。
GOODFELLOW I等人[6]采用无监督数据增强方法,提出了基于生成对抗网络(GAN)的方法,发现了生成样本与真实样本具有相同的分布;但其在训练中存在训练不稳定、模式坍塌等问题。为克服这些问题,ODENA A等人[7]通过在生成器和判别器中引入了一个额外的分类器,提出了辅助分类生成对抗网络模型(ACGAN),发现了其在生成图像质量和多样性方面有显著改进;但GAN对样本的平衡性要求较高。杨光友等人[8]采用在损失函数中引入自适应项的方法,提出了一种自适应辅助分类器(self-adaptive auxiliary classifier GAN, SA-ACGAN),有效提高了生成样本的质量;但SA-ACGAN对数据的数量有较高要求。FU W L等人[9]采用特征增强技术使分类器适用于不平衡数据集,提出了一种带有梯度惩罚的自适应辅助分类器(feature-enhanced GAN with an auxiliary classifier, AC-FEGAN),提高了生成样本质量和诊断精确度;但AC-FEGAN注重生成样本的结构特征,一定程度上限制了生成样本的多样性。
目前,基于ACGAN模型的不平衡数据生成方法已经取得了较大进展,但仍然存在一些局限性:1)大部分ACGAN模型均基于单一判别器结构,这容易导致样本边界特征和部分细节信息丢失,从而降低了训练的稳定性;2)如果不同任务的特征表示或优化目标存在冲突,模型可能难以兼顾各个任务的性能要求。
为解决上述问题,笔者提出一种BD-ACGAN模型。首先,采用边界辅助判别器提取样本的边界特征细节,提高生成样本的真实度;其次,引入包含通道注意和空间注意的Shuffle Attention机制,关注图像中的重要区域和关键特征;最后,采用多任务自适应权重损失模块自动调整损失函数的权重,提高模型的诊断能力。
1 理论基础
1.1 连续小波变换
连续小波变换[10](continuous wavelet transform,CWT)是一种基于小波函数的时间-频率分析方法,该方法可以使原始信号在不同尺度和频率范围内进行分解,并生成相应的小波系数图。
CWT的数学公式如下:
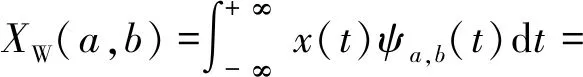
(1)
式中:x(t)为原始信号;ψa,b(t)为小波基函数;a为小波基函数的尺度参数;b为小波基函数的平移参数。
1.2 ACGAN模型
ACGAN[7]是一种生成对抗网络(GAN)的变体。在ACGAN中,生成器的任务是根据输入的随机噪声和标签信息生成逼真的样本。辅助分类器则针对接收生成器生成的样本判断其真实性,并进一步对其所属类别进行分类。
因此,ACGAN模型的损失包括两部分,分别是用于判断样本真假的判别损失LS,以及用于衡量生成样本分类准确性的分类损失LC,其中:
LS=E[logP(S=real|Xreal)]+E[logP(S=G|XG)]
(2)
LC=E[logP(C=c|X=real)]+E[logP(C=c|X=G)]
(3)
式中:S为样本来自真实样本,S=real;S为样本来自生成样本,S=G;C为辅助分类器预测的类别标签;c为真样本的真实类别标签;Xreal为真实样本;XG为生成样本。
1.3 Shuffle Attention模块
Shuffle Attention[11](SA)模块是一种用于增强特征之间交互和协同作用的注意力机制。
SA模块将输入特征图分为多个组,每个组包含一定数量的通道和空间位置。然后,在每个组内计算子特征之间的相似度或相关性,生成注意力权重,以增强重要子特征的影响力,并促进组内特征之间的信息传递。
值得注意的是,SA模块的超参数仅有5个,远小于整个模型的参数数量,因此产生额外计算的影响可以忽略不计。
2 基于边界辅助判别的BD-ACGAN模型
2.1 网络结构
为了提高生成对抗网络的特征学习表达能力和故障诊断能力,笔者提出了一种BD-ACGAN模型。该模型由生成器、主判别器和辅助判别器组成。
在模型中,主判别器用于生成样本的真假判断和样本分类,而辅助判别器则用于检测生成样本的边界信息判断其真实性。
模型以随机噪声向量Z和标签信息作为输入,在生成器的学习迭代过程中生成相应的样本。主判别器将生成样本的主要特征与实际样本进行对比,输出判别及分类结果;辅助判别器对生成样本的边界特征进行提取,并将其与实际样本进行对比,输出判别结果。
BD-ACGAN模型结构如图1所示。
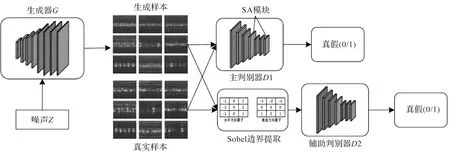
图1 BD-ACGAN模型结构
在BD-ACGAN模型中,使用Sobel算子对样本的边界信息进行提取。Sobel算子是一种常用的图像边缘检测算法,通过计算图像中像素点的灰度值梯度检测图像中的边界。由于图像边界保留了底层纹理信息,因此,通过提取边界特征信息可以生成纹理特征更加丰富的样本。
此外,Sobel算子可以与网络的反向传播过程相结合,使模型能够对边界特征进行有效的学习和优化。
2.2 BD-ACGAN模型训练策略
针对上述BD-ACGAN模型,笔者提出了一种基于数据生成的故障诊断网络训练策略。该训练策略包括四个阶段:生成与分类联合训练、数据集增广、故障分类器训练和推理预测。
BD-ACGAN模型训练策略如图2所示。
2.2.1 生成与分类联合训练
1982年,我和小熊一起考中学,小熊考了数学一百、语文九十一的成绩,当时重点中学分数线为一百九十二分。好在小熊多才多艺,凭特长可以加分,不过,手续自然是繁杂的,陈阿姨跑得几乎断气。等消息的时候,又见到熊老夫人,老夫人皱着眉头说了一番话。
在生成与分类联合训练开始时,笔者对生成器和判别器的参数进行随机初始化。此后,每个迭代过程中,从真实样本中随机选择一批样本用于生成器的训练,并输出相应的生成样本。在判别器的训练过程中采用高斯似然最大化的损失函数计算损失和更新参数,以提高生成样本的质量。在生成器和判别器之间进行交替训练,并采用梯度下降方法不断优化参数。
模型训练的损失包括基于高斯似然最大化的判别器损失函数和基于交叉熵损的辅助分类器损失函数。为使模型的训练过程快速收敛,笔者在损失函数中引入自适应权重损失模块[16],该模块可以根据各任务的特点,采用梯度反向传播更新的方式进行损失权重自我学习调节,进一步提升了BD-ACGAN模型的性能。BD-ACGAN模型的自适应权重损失为:
(4)
式中:W为权重参数;σ为噪声参数。
各项损失参数初始化为1,在训练过程中不断更新参数,从而适应各任务的需求,使网络稳定、快速地收敛。
2.2.2 数据集增广
在数据集增广阶段,笔者采用经过训练的网络对数据集进行增广处理。首先,固定生成器的参数,使生成器生成大量样本。随后,采用数据增强技术对生成样本进行处理,以得到多样化的增强样本。然后,将这些经过增强处理的样本与真实样本融合,形成一个新的融合样本数据集。最后,利用融合样本数据集训练分类器,以提高模型的故障诊断能力及泛化能力。
2.2.3 故障分类器训练
在故障分类器训练阶段,仅对主判别器的分类器支路进行权重调整。在训练开始时,笔者使用联合训练阶段的权重对主判别器的辅助分类器参数进行初始化。
(5)
2.2.4 推理测试
在推理测试阶段,对BD-ACGAN模型而言只需要保留主判别器的编码器及分类支路,并加载故障分类器训练阶段的权重参数。
首先,笔者使用CWT对未知类别的一维故障数据进行预处理,将其转换为二维故障图像;然后,将这些二维图像输入给编码器,由分类支路根据编码特征得到故障类别预测结果[18]。
2.3 BD-ACGAN模型参数
BD-ACGAN模型生成器参数如表1所示。

表1 模型生成器参数
BD-ACGAN模型判别器参数如表2所示。

表2 模型判别器参数
3 实验仿真分析
为验证BD-ACGAN模型的生成能力和故障诊断能力,笔者分别使用美国凯斯西储大学(Case Western Reserve University, CWRU)滚动轴承数据集和西安交通大学滚动轴承数据集[19](XJTU-SY)进行验证分析。
CWRU数据集中所使用的故障滚动轴承由人工使用电火花加工技术制作而成,无法完全准确地模拟真实的故障状况。因此,笔者使用XJTU-SY滚动轴承数据集对模型进行补充验证。XJTU-SY数据集中的故障滚动轴承数据由滚动轴承加速寿命实验对实际使用中的磨损和老化过程进行模拟而获取,能够比较准确地表现真实的轴承故障状况。
仿真运行设备为Intel(R)Xeon(R)CPU E5-2680 v4@ 2.40 GHz+ NVIDIA RTX A2000,内存30 G。笔者使用CMor小波将滚动轴承数据集变换为时频图,然后采用PyTorch深度学习框架和Python3.9编程语言进行模拟仿真实验。
在训练中,笔者采用双时间尺度更新规则(two timescale update rule,TTUR)调整生成器学习率和判别器学习率,加快生成器对判别器的反馈的适应速度,从而提高生成样本的质量,同时保持判别器的稳定性。
其中,生成器学习率设置为0.000 1,判别器学习率设置为0.000 4。
3.1 CWRU滚动轴承数据集实验
CWRU数据集中待测轴承为驱动端轴承,轴承型号为深沟球轴承SKF6205,采样频率为12 kHz。在电机负载为1.5 kW时进行数据采集,包括内圈故障、滚动体故障、外圈故障、正常工况4种情况,每类故障包含3种故障尺寸:0.007 mm、0.014 mm、0.021 mm。
因此,笔者按照故障类型及尺寸将样本依次标记为1至10。
3.1.1 不平衡样本下生成及诊断能力分析
在工程实际中,故障样本数量往往少于正常数据样本数量。因此,为模拟实际轴承故障样本数据不足的情况,笔者对训练集数量进行限制,并设置四种不平衡率的数据集,分别为1 ∶1、2 ∶1、5 ∶1和10 ∶1。
不平衡率下的滚动轴承数据集样本数如表3所示。

表3 不平衡率下的滚动轴承数据集样本数
为验证BD-ACGAN模型的效果,笔者随机选取四种工况下的生成样本与真实样本的图像进行对比,不同不平衡率的数据集生成样本如图3所示。
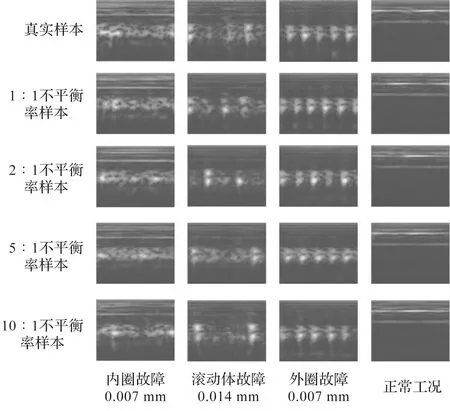
图3 不同不平衡率的数据集生成样本
从图3可以看出,当不平衡率为1 ∶1和2 ∶1时,整体特征呈现出高度的相似性。
然而,与不平衡率为1 ∶1时相比,不平衡率为2 ∶1时生成样本特征表现相对弱化。当不平衡率为5 ∶1和10 ∶1时,生成样本仍保留了明显特征。因此,BD-ACGAN模型能够用于有效学习样本的边界特征。
为客观评价生成器的生成能力,笔者采用三种指标进行生成样本特征分析,包括:频谱内涌隙距离(Fréchet inception distance, FID)、结构相似性指数(structural similarity index, SSIM)和峰值信噪比(peak signal-to-noise ratio, PSNR)。
其中,FID用于衡量生成模型生成样本与真实样本分布之间差异。SSIM用于衡量图像之间在结构、亮度和对比度等方面的相似性程度。PSNR是衡量图像重构质量的指标,其通过比较原始图像与重构图像之间的信噪比来评估图像失真程度。
笔者从各不平衡率中随机选取40个轴承故障样本对,测试模型的诊断精确度并计算三个指标的均值。
不同不平衡率下的分类精确度及生成样本质量如表4所示。
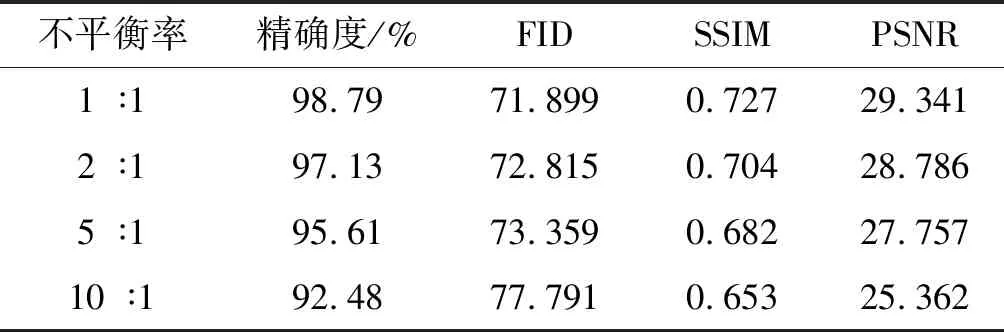
表4 不同不平衡率下的分类精确度及生成样本质量
由表4可以看出:当不平衡率为1 ∶1时,模型的精确度为98.83%,并且生成样本与真实样本的相似度较高;当不平衡率为2 ∶1时,模型的精确度仍保持在97.11%,表明其对于该不平衡的数据集依然保持着较好的诊断性能;当不平衡率为5 ∶1和10 ∶1时,尽管精确度有所下降,但生成样本与真实样本的相似度仍然较好,表明在该不平衡率时,该模型仍具有样本生成能力和诊断能力。
3.1.2 不同模型的生成能力分析
为验证BD-ACGAN模型生成样本的有效性,笔者选择ACGAN、DCGAN模型进行实验对比。三种模型使用相同的网络参数,并且采用不平衡率为1:1的数据集样本。
为避免单次实验结果的偶然性,笔者取10次实验样本质量的平均值作为最终结果。不同模型生成样本质量如表5所示。

表5 不同模型生成样本质量
从表5可以看出:与另外两种模型相比,BD-ACGAN模型的生成样本更接近真实样本,结构相似性更高,并且失真程度较低。这说明BD-ACGAN模型生成样本的特征更接近真实样本,具备更高的样本相似度。
3.1.3 消融实验
为验证BD-ACGAN模型中局部模型的有效性,笔者在BD-ACGAN模型的基础上进行消融实验。
笔者采用不平衡率为1 ∶1的数据集样本;同时为避免单次实验结果的偶然性,取5次实验样本质量的平均值作为最终结果。
消融实验生成样本质量如表6所示。

表6 消融实验生成样本质量
从表6可以看出:AC-SAGAN模型改善了生成样本与真实样本之间的相似性,但在失真程度方面仍有进一步优化的空间;AC-BDGAN模型显著提高了相似性和结构相似性,同时在失真程度方面也有所改善。
与其他三种模型相比,BD-ACGAN模型在生成样本的质量、相似性和失真程度等方面都取得了显著的改进。
3.1.4 诊断能力对比
为验证BD-ACGAN模型的诊断能力,笔者将BD-ACGAN模型与其他模型进行对比。为确保实验的公平性,每个模型均使用经过融合后的相同平衡样本数据集。
不同模型诊断的精确度如图4所示。

图4 不同模型诊断的精确度
从图4可以看出:无论是在1 ∶1、2 ∶1、5 ∶1还是10 ∶1的不平衡率情况下,BD-ACGAN模型都保持较高的准确度。
相比之下,VIT和AlexNet在不平衡率较高时准确度相对较低,GaussianNB模型在较低不平衡率下表现较好,但在不平衡率增加时准确度显著下降。
3.2 XJTU-SY数据集实验
获取XJTU-SY数据集的实验平台由交流电机、电动转速控制器、转轴、支撑轴承、液压加载系统和测试轴承组成,其中,测试轴承为LDK UER204滚动轴承。实验平台能在不同运行条件下对轴承进行加速退化实验,并获得运行至失效的完整数据。
XJTU-SY数据集共包括15组故障数据,包括内圈磨损、保持架断裂、外圈磨损等类型的故障。
为确保实验的完整性,笔者选取外圈、内圈、内圈及外圈、保持架和全故障(内圈、外圈、保持架、滚动体)五种类型数据进行实验,并将故障样本依次标记为0到4。
故障类型及标签如表7所示。

表7 故障类型及标签
3.2.1 生成能力分析
为验证BD-ACGAN模型在处理实际故障数据方面的优势,笔者对XJTU-SY数据集的生成样本进行了分析。
生成样本质量如表8所示。
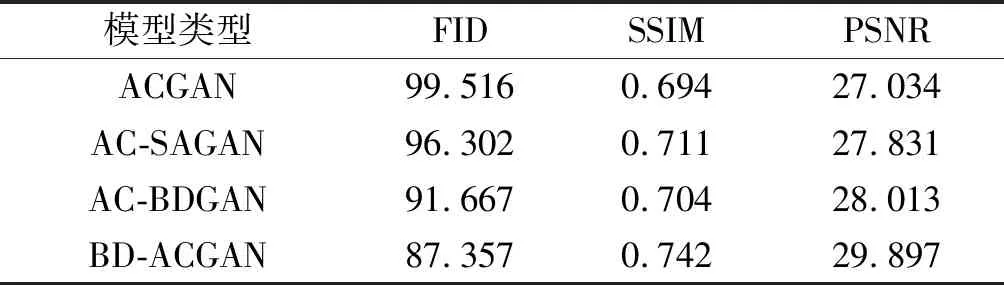
表8 生成样本质量
从表8可以看出:ACGAN模型的生成样本在三项指标上表现较差;AC-SAGAN和AC-BDGAN模型的生成样本在三个指标上有一定程度的改善。
与其他三种模型相比,BD-ACGAN模型在所有模型中表现最佳,生成样本的质量得到了明显的改善。
3.2.2 诊断性能分析
为直观地展示BD-ACGAN模型的故障特征提取能力,笔者使用t-SNE对5类故障的生成样本进行降维,以可视化提取深层特征。其中,选取每种故障训练集样本为340,测试集样本数为60。
t-SNE降维可视化如图5所示。

图5 t-SNE降维可视化
由图5可以看出,不同类别的样本有明显的聚类现象,这说明模型在进行分类时能够有效地区分不同的故障类型。
为验证模型对不同故障类型的诊断能力,笔者绘制了单次实验中测试集诊断结果混淆矩阵。
测试样本标签混淆矩阵如图6所示。
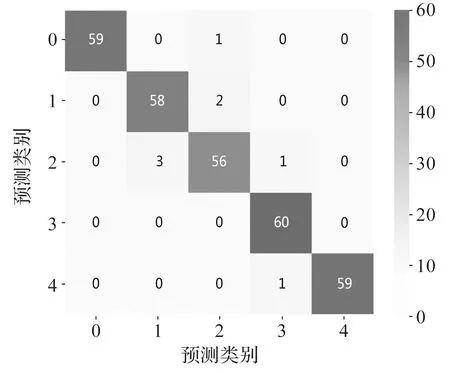
图6 测试样本标签混淆矩阵
从图6可以看出:XJTU轴承数据集的诊断误差主要集中在两个方面,即内圈故障和内圈与外圈混合故障。这是因为在轴承实验时,轴承外圈被固定而内圈进行旋转,当轴承内圈发生故障时,内圈故障信号可能会受到轴承转频调制现象的影响。
4 结束语
为解决滚动轴承故障数据不平衡的问题,笔者提出了一种基于边界辅助判别的辅助分类生成对抗网络模型(BD-ACGAN)。
该方法采用CWT,将一维轴承振动信号转换为具有高时频分辨率的时频图;然后,采用边界辅助判别器和SA模块,以确保训练的稳定性与生成样本的真实性;最后,采用自适应权重损失模块,提高了模型的故障诊断分类能力。
笔者采用CWRU和XJTU-SY数据集进行了实验,实验结果表明:
1)BD-ACGAN模型能够提高生成样本质量,解决故障样本数据不平衡问题;
2)BD-ACGAN模型在各不平衡率下的诊断精度均高于其他模型,并且在不平衡度较高的数据集中仍有较好的诊断效果。
在后续的工作中,笔者将进一步围绕以下两个方面开展相关研究:1)进一步提高故障诊断准确率和效率;2)将多模态数据(如温度、声音等)融入到模型中进行故障诊断,以提高诊断的准确性。
