融合多结构信息的代码注释生成模型*
2024-04-23余天赐
余天赐,高 尚
(江苏科技大学计算机学院,江苏 镇江 212100)
1 引言
代码注释用于描述程序中关键代码的功能、注意事项和约束条件等,帮助开发人员更好地理解代码的实现意图和工作原理,在软件开发和维护过程中起到重要作用。现如今,随着软件规模不断增大,很多软件项目存在着代码注释缺失、描述不清晰等情况,导致开发人员需要花费更多的时间和精力去阅读和理解代码,从而降低了开发和维护效率。代码注释自动生成通过机器学习的方法构建编程语言到自然语言注释的映射模型,训练好的模型可以分析代码的语法结构、标识符名称、函数参数和返回值等元素,自动生成高质量的代码注释,不仅可以提高开发人员的编码效率,还提高了代码的可读性、可维护性和可重用性。
代码注释生成研究中存在2个主要问题,一是代码的表示,二是注释生成。不同的源代码表示将直接影响抽取源代码信息的质量,从而影响生成注释的质量。现有的研究方法主要用抽象语法树AST(Abstract Syntax Tree)一种结构信息表示代码,没有考虑代码其他类型的结构信息,例如数据流和控制流,使得模型生成的注释存在准确率低和可读性差的问题。
为了提升模型生成注释的质量,本文提出一种融合多结构信息的代码注释生成模型,模型先将AST处理为特定格式的序列,使用Transformer编码器对AST序列进行编码,捕获全局信息。使用图神经网络GNN(Graph Neural Network)[1]对数据流图进行特征提取,提供变量之间的计算依赖关系等信息,然后使用跨模态注意力机制(Crossmodal Attention)融合抽象语法树和数据流2种特征,经过Transformer解码器生成相应的注释。通过使用Java和Python编程语言的代码-注释数据集验证了本文模型性能优于6种主流对比模型,消融实验也验证了融合抽象语法树和数据流图2种特征的有效性。
2 相关工作
近年来,研究人员设计出不同的基于深度学习的代码注释生成模型,这些模型采用了不同的代码表示方法和不同的神经网络结构,但它们普遍使用序列到序列(Sequence-to-Sequence)的框架。在代码注释生成模型中有2个重要环节:代码表示和注释生成。代码注释生成过程通常可以分为3个阶段:数据处理阶段、模型训练阶段和模型测试阶段。代码表示模型是代码注释自动生成中的核心问题,根据代码的不同表现形式,可将现有的代码表示模型分为3类。
第1类是基于词元(token)序列的代码表示模型。在这些模型中,代码的变量名、方法名和标识符被看作普通文本。Haiduc等[2]采用信息检索技术对源代码进行分析处理,从中找出合适的词语,生成由关键词组成的代码注释。Zheng等[3]提出的模型利用注意力机制配合编码器获取代码语义信息,模型识别代码中的循环、选择等重要结构,并将其中的关键字嵌入表示为词向量,作为编码器的输入。Hu等[4]利用应用程序编程接口API(Application Programming Interface)序列辅助模型生成代码注释。
第2类是基于抽象语法树的代码表示模型。Alon等[5]提出的模型将代码表示为AST的多条路径集,利用LSTM对每个路径序列进行编码,在注意力机制的配合下解码生成代码注释。Zhang等[6]将AST拆分成一系列小型语句树,并通过捕获代码语句的词汇和语法知识将语句树编码为向量。该方法解决了AST结构复杂的问题,提高了计算性能。Hu等[7]利用2种编码器分别编码代码序列和AST序列,在注意力机制的帮助下融合2种特征,最后使用解码器生成代码注释。
第3类是基于图的代码表示模型。这类模型利用图结构表征程序的AST、数据流和控制流等信息。戎珂瑶等[8]利用异质图结构和图神经网络,将源代码的抽象语法树、控制流图和数据流图等融合并构建为具有多种节点和边的异质表示图,提出了基于多维度异质图结构的代码注释自动生成模型。LeClair等[9]使用图卷积神经网络处理图结构表征的AST,并将基于图卷积神经网络的编码器输出与基于代码token序列编码器的输出相结合。模型可以学习到代码结构与序列间的关系。Allamanis等[10]设计了一种基于门控图神经网络的代码表示模型。模型使用图表示代码的AST和数据流信息。训练好的模型可以为给定代码段预测变量名。与前2类代码表示模型相比,基于图的代码表示模型更适合表示源代码的结构信息。
本文利用抽象语法树和数据流图可以表示代码中不同类型的结构信息,提出一种融合多结构信息的代码注释生成模型。
3 本文模型
3.1 问题定义
代码注释生成任务可以形式化为有监督机器学习问题。本文使用C={c1,…,ci}表示代码片段,S={s1,…,si}表示与代码对应的注释句子,构建由(C,S)对组成的训练集,通过对模型训练,得到注释生成模型f,当输入代码片段ci时,模型f可以自动生成注释si。
3.2 模型结构
本文提出的融合多结构信息的代码注释生成模型结构如图1所示,模型主要包含以下3部分:抽象语法树编码器、数据流图编码器和解码器。抽象语法树编码器将原始的AST序列转换为一个固定维度的向量,以捕捉AST中的语义和结构信息。数据流图编码器使用图神经网络将代码数据流图转换成固定维度的向量,以捕捉代码数据流中的变量依赖关系等关键信息。解码器接收跨模态注意力机制生成的中间向量表示,然后将其解码为代码注释序列。其中,抽象语法树编码器由N个相同的编码器层堆叠而成,解码器由N个相同解码器层堆叠而成。
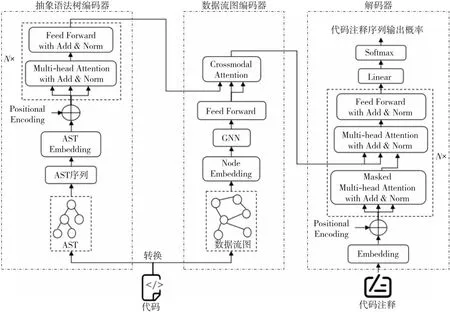
Figure 1 Structure of the proposed model
3.3 编码器
3.3.1 抽象语法树编码器
抽象语法树AST是由节点和边组成的树状结构,每个节点表示代码中的一个语法结构。AST的非叶节点主要表示代码中的各种语句,例如循环、判断语句以及声明语句。而叶子节点表示标识符等,例如变量名、参数名和函数名。本文使用Transformer[11]的编码器来提取代码抽象语法树的上下文信息。为了使AST能够作为编码器的输入,需要将AST转换为特定格式的序列,本文参考文献[12]的方法,处理过程如下:从根节点开始,首先使用一对括号来表示树结构,并将根节点本身放在右括号后面。然后,遍历根节点的子树,并将子树的所有根节点放入括号中。如此递归遍历,直到遍历完所有节点,得到最终序列。
图2表示一段Java代码,其对应的抽象语法树如图3所示。

Figure 2 Java code
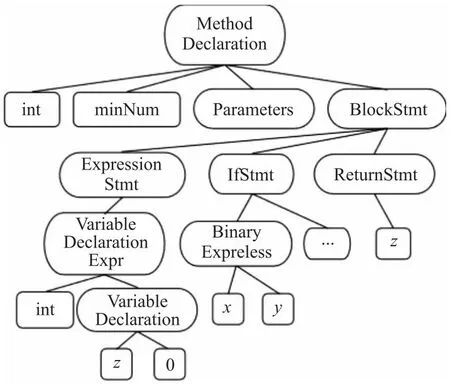
Figure 3 Abstract syntax tree of Java code in figure 2
将如图3抽象语法树转换成序列可以表示为:(MethodDeclaration(int)int(minNum)minNum(parameters)parameters(BlockStmt(…))BlockStmt)MethodDeclaration。使用这种格式的序列,可以使模型从AST中学习到代码的语义和语法信息。
抽象语法树编码器使用X={x1,…,xl}表示某一代码片段的AST序列,l表示序列长度,X∈Rl×dAST,dAST表示嵌入的维度。获得AST序列嵌入表示后,利用位置编码捕获序列的位置信息。
PE(i,2m)=sin(i/100002m/dAST)
(1)
PE(i,2m+1)=cos(i/100002m/dAST)
(2)
其中,i表示序列X中token的位置,m是位置编码的维度索引,2m表示偶数维度,2m+1表示奇数维度,当位置编码维度为偶数时使用式(1)计算,当位置编码维度为奇数时使用式(2)计算。
将序列嵌入向量和位置编码相加后,可以得到AST序列的输入特征Xinput,如式(3)所示:
Xinput=X+PE
(3)
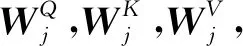
(4)
A=[a1,a2,…,ah]
(5)
Z=LayerNorm(Xinput+AWO)
(6)
XAST=LayerNorm(Z+FFN(Z))
(7)
其中,dr表示矩阵Qj和Kj的维度,h表示注意力头的个数。LayerNorm(·)表示归一化操作,WO表示权重矩阵,FFN(·)表示前馈神经网络。抽象语法树编码器由N个相同编码器层堆叠而成。
3.3.2 数据流图编码器
数据流图DFG(Data Flow Graph)以图的形式记录了代码段中变量的赋值和传播过程。其中,图的节点表示变量,边表示变量的来源。这种图结构为代码理解提供了关键的代码语义信息。图4表示图2中Java代码的数据流图。

Figure 4 Data flow graph of Java code in figure 2
数据流图编码器使用图神经网络GNN[1]提取数据流图特征,GNN通过聚合邻居节点的信息来更新节点的特征表示,最终得到数据流图的嵌入表示。数据流图是一种有向图,为了使图神经网络在处理有向图时不丢失方向信息,需要同时从节点的传入和传出方向进行消息传递。数据流图编码器具体计算过程如下:使用G=(V,E)表示数据流图,V表示变量节点的集合,E表示边的集合。图中节点的连接关系使用邻接矩阵A∈RN×N表示,N表示节点个数。vi∈V表示节点,(vi,vj)∈E表示从节点vi指向vj的一条有向边,1≤i,j≤N。用N├(v)={u∈V|(v,u)∈E}表示节点v所有前向邻居的集合,即v指向的节点。用N┤(v)={u∈V|(u,v)∈E}表示节点v所有后向邻居的集合,即指向v的节点。使用xv表示节点v经过嵌入后的文本特征向量,矩阵Xnode∈RN×dnode存储所有节点的文本特征向量,其中dnode表示特征向量的维度。图4中变量x1的一阶前向邻居为x5和x8,二阶前向邻居为z7,z7的一阶后向邻居为x8。图神经网络主要通过聚合节点K阶邻居的信息来更新节点特征。图神经网络主要计算过程如下:对所有节点,先初始化节点的前向表示和后向表示为其文本特征向量,如式(8)所示:
(8)

(9)
其中,AGGREGATE(·)表示聚合操作。

(10)
其中,σ(·)表示非线性激活函数,Wk表示权重矩阵。
同理,将相同的过程应用于后向表示。
(11)
(12)
本文使用均值聚合方法。
(13)
经过K次聚合过程,拼接节点最终的前向表示和后向表示得到向量Zv,作为节点v的特征向量。
(14)
最后将节点的特征向量传入一个前馈神经网络,并使用最大池化方法得到数据流图的特征向量XDFG,如式(15)所示:
XDFG=max({σ(WZv+b),v∈V})
(15)
其中,W表示权重矩阵,b表示偏置向量。
3.4 特征融合
本文使用一个跨模态注意力模块Crossmodal attention[13]来融合抽象语法树特征和数据流图特征,这样可以使抽象语法树编码器接收数据流图编码器的信息。
本文使用XAST∈RTα×dα表示抽象语法树特征,XDFG∈RTβ×dβ表示数据流图特征,其中,T(·)表示特征序列长度,d(·)表示特征的维度。分别定义查询矩阵Qα,索引矩阵Kβ和值矩阵Vβ。经过下列计算可得融合后的特征ZFusion。
Qα=XASTWQα
(16)
Kβ=XDFGWKβ
(17)
Vβ=XDFGWVβ
(18)
(19)
其中,WQα∈Rdα×ds,WKβ∈Rdβ×ds,WVβ∈Rdβ×dv为权重矩阵。其中,ds和dv分别表示权重矩阵对应的维度。
3.5 解码器
本文使用Transformer的解码器来生成代码注释。解码器部分由N个解码器层堆叠而成,每个解码器层由3个子层连接组成,第1个子层包括带掩码的多头自注意力机制、残差连接以及规范化层。使用带掩码的多头自注意力机制可以确保预测仅依赖于已生成的输出词元。第2个子层包括连接融合特征和解码器的多头注意力机制、残差连接以及规范化层。其中的多头注意力机制与之前抽象语法树编码器中多头注意力机制不同,查询来自前一个解码器层的输出,而键和值来自于融合特征,这样能够使解码器捕获到抽象语法树序列和数据流图特征信息。第3个子层包括前馈神经网络、残差连接以及规范化层。经过N个解码器层的计算后,使用线性层得到指定维度的向量。最后经过softmax层得到概率向量,模型选择具有最高概率的单词作为输出。
本文使用交叉熵损失函数来训练模型,损失函数如式(20)所示:
(20)
其中,n表示整个输出序列的长度,yt表示模型预测第t时间步的token。训练过程中,通过最小化损失函数得到模型参数。
4 实验与结果分析
4.1 数据集
为了有效评估本文模型,实验数据集采用CodeXGLUE(General Language Understanding Evaluation benchmark for Code)中Java和Python语言代码-注释数据集[14]。Java语言数据集包含181 061对代码-注释对。其中,164 923对数据用于训练模型,10 955对数据用于测试模型,5 183对数据作为验证集。Python语言数据集包含280 652对代码-注释对。其中,251 820对数据用于训练模型,14 918对数据用于测试模型,13 914对数据作为验证集。
4.2 数据预处理
在模型训练之前,需要对代码和注释数据进行预处理,将其转换为可以作为模型输入的数据结构。
本文使用开源工具tree-sitter为Java和Python代码构建抽象语法树。tree-sitter是一个生成解析器的工具。它可以为多种语言的代码构建语法树。生成抽象语法树的主要步骤如下:首先,对代码进行词法分析,将其分割成多个词法单元,例如关键字、标识符和操作符等。然后进入语法分析阶段,语法分析器按照不同编程语言的语法规则,对词法单元进行分析和组织,最后构建出一棵抽象语法树。为了方便模型训练,在构建抽象语法树的过程中,需要删除节点数超过1 000以及因语法错误导致构建抽象语法树失败的数据集,最后将处理好的数据存储在JSONL格式文件中。
数据流图的构建主要参考文献[15]中使用的方法,具体构建步骤如下:根据抽象语法树中的叶子节点来识别变量序列,这些变量序列中的每一个元素都会成为数据流图中的一个节点。然后根据抽象语法树中变量之间的依赖关系,生成数据流图的有向边。以集合形式存储变量节点,使用邻接矩阵表示节点间的连接关系。
4.3 参数设置
实验包含基本参数设置。抽象语法树编码器中编码器层数N为6,多头注意力机制头的个数h为8,嵌入维度dAST为512。数据流图编码器中节点嵌入维度dnode为512,聚合节点邻居阶数K为2。解码器中解码器层数N为6,带掩码的多头注意力机制头的个数为8。使用Adam优化器训练模型,初始学习率设置为0.001。
4.4 评估指标
实验采用BLEU(BiLingual Evaluation Understudy)[16]、METEOR(Metric for Evaluation of Translation with Explicit ORdering)[17]和ROUGE(Recall-Oriented Understudy for Gisting Evaluation)[18]3种评估指标来评估模型生成代码注释的质量。
BLEU是一种基于n-gram精确度的评估指标,可以自动分析模型生成注释与参考注释之间的相似度。BLEU分数的取值范围是0到1,越接近1表示模型生成注释的质量越好。
METEOR在评估中加入召回率来反映模型生成注释与参考注释的相似程度。分数越高表示模型生成注释越接近参考注释。与BLEU不同的是,METEOR将模型生成注释与参考注释进行对齐,以便更好地评估模型生成注释的质量。
ROUGE是一种基于召回率的文本摘要质量评估指标。它含有4种指标:ROUGE-L、ROUGE-S、ROUGE-N以及ROUGE-W。在代码注释质量评估中常使用ROUGE-L,它是基于最长公共子序列的召回率和精确度来计算的。
4.5 对比模型
为了验证模型有效性,本文选用以下几种相关代码注释生成模型进行对比分析。
(1)Tree2Seq[19]:使用基于树的LSTM作为编码器捕获AST的结构信息。
(2)code2seq[20]:使用AST的多条随机路径集表示代码片段,通过LSTM编码AST路径,在注意力机制的配合下解码生成代码注释。
(3)Code-NN[21]:将代码表示为token序列,然后利用LSTM和注意力机制生成代码注释。
(4)DeepCom[11]:对代码AST进行结构遍历得到可以作为模型输入的特定格式序列,这种序列可以更好地表示代码的结构信息。
(5)CodeGNN[8]:包含2个编码器,一个使用GRU编码源代码序列,另一个使用图神经网络编码代码的AST。
(6)Transformer[22]:使用多头注意力机制编码输入和解码输出,并利用位置编码学习代码序列中token的位置关系。
4.6 实验结果
4.6.1 对比实验
表1展示了本文模型和对比模型在CodeXGLUE中Java和Python语言代码-注释数据集上的实验结果。通过表1可以看出,本文提出的融合多结构信息的代码注释生成模型在2个数据集上的BLEU-4、METEOR和ROUGE-L 指标均优于对比模型。
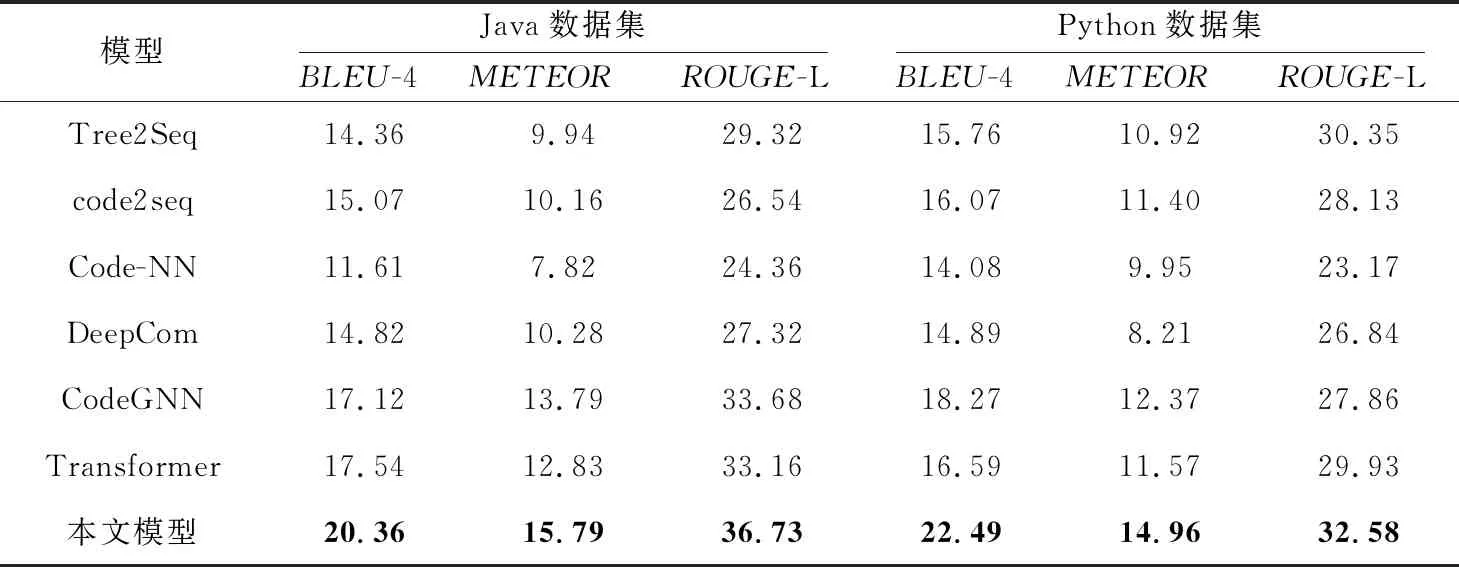
Table 1 Results of different models on Java and Python datasets
具体地,基于代码token序列的Code-NN模型,仅考虑了代码的语义信息,从代码中抽取关键字,没有充分利用代码结构特征,因此模型生成的注释质量较低。基于抽象语法树的代码注释生成模型,例如Tree2Seq、code2seq和DeepCom,这类模型通常用AST的节点序列、路径集合来表示源代码。因为抽象语法树可以表示代码的抽象句法结构,所以这类模型可以学习到代码的结构信息,生成的注释质量也比基于代码token序列的注释生成模型要高。使用图神经网络的注释生成模型CodeGNN利用图结构表征代码的AST。由于图更适合表示代码的结构信息,所以CodeGNN与基于AST序列的模型相比,BLEU、METEOR和ROUGE-L的得分更高。Transformer能捕获长距离依赖关系,因此使用Transformer的注释生成模型3种指标分数要高于Code-NN模型。本文模型利用Transformer和图神经网络的优点,融合抽象语法树和数据流图2种特征来表示代码,能更全面地覆盖代码所包含的语义和结构等信息。模型生成的注释的BLEU、METEOR和ROUGE-L分数均高于对比模型。
4.6.2 消融实验
为了进一步分析抽象语法树编码器和数据流图编码器的作用,以及图神经网络中聚合节点邻居阶数和特征融合方式对模型性能的影响,本文设计了消融实验。在Java和Python数据集上的消融实验结果如表2所示,加粗表示最优的结果。AST only表示只有抽象语法树编码器,DFG only表示只有数据流图编码器。其中,K表示聚合节点邻居阶数,concat表示在特征融合时使用拼接操作,CM attention表示在特征融合时使用跨模态注意力机制。

Table 2 Results of ablation experiments on Java and Python datasets
由表2中结果可知,图神经网络聚合数据流图节点邻居阶数会影响模型性能。在只有数据流图编码器的实验中,当K=2时,模型在Java和Python数据集上BLEU-4、METEOR和ROUGE-L 3种评估指标分数最高,增加聚合节点邻居阶数会出现过平滑问题,即经过多次邻居节点特征的聚合,所有节点的特征会变得相似,模型不易学习到节点的特征,从而导致模型性能下降。在特征融合时,不同的融合方式也会影响模型性能,从表2中数据可知,使用跨模态注意力机制的模型在Java和Python数据集上BLEU-4、METEOR和ROUGE-L 3种评估指标分数都要高于使用拼接操作融合2种特征的模型,验证了跨模态注意力机制的有效性。另外,只使用抽象语法树编码器或者数据流图编码器会降低注释生成模型的性能。抽象语法树和数据流图都是代码的结构化表示形式,将2种特征融合可以帮助模型更全面地理解代码的结构和行为。具体来说,AST中含有代码的语法结构信息,而DFG可以描述代码中的数据流和计算依赖关系,其中包含变量的定义、使用以及传递过程。使用跨模态注意力机制融合AST和DFG 2种特征的注释生成模型在Java数据集上BLEU-4、METEOR和ROUGE-L 3种指标得分分别为20.36%,15.79%和36.73%,在Python数据集上3种指标得分分别为22.49%,14.96%和32.58%。
消融实验结果表明,融合代码的抽象语法树和数据流图2种特征可以提升模型生成注释的质量。
4.6.3 案例展示
本节主要展示模型生成注释的案例。从数据集中随机抽取2段Java和Python代码,其参考注释和模型生成的注释如表3所示。从表3中可以看出,模型生成的注释可以准确描述代码功能,且具有良好的可读性。

Table 3 Cases of code summarization
5 结束语
本文提出了一种融合多结构信息的代码注释生成模型,模型在代码抽象语法树的基础上,增加了数据流图结构信息来表示代码。模型使用Transformer编码器对AST序列进行编码,捕获代码全局信息。使用图神经网络对数据流图进行特征提取,提供变量之间的计算依赖关系等信息,然后使用跨模态注意力机制融合抽象语法树和数据流2种特征,最后经过Transformer解码器生成相应的注释。对比实验结果表明,本文模型的性能要优于6种主流注释生成模型。消融实验也验证了融合抽象语法树和数据流2种特征的有效性。在未来工作中,一是需要设计更适合抽取代码结构信息的模型,提高模型学习能力。二是需要探究多种方法融合的注释生成算法。三是提升模型的泛化能力,可以将注释生成模型应用到不同的代码语言中。
