一种基于认证文件的双方验证模型水印方案*
2024-04-23郑洪英
吴 瑕,郑洪英,肖 迪
(重庆大学计算机学院,重庆 401331)
1 引言
训练一个成功的深度学习DL(Deep Learning)模型,需要大量的时间、资源和人力。因此,需要采取措施来保护模型免受非法复制、重新分发或滥用,以确保模型版权得到保护。神经网络水印是一个有效的模型保护措施,借鉴传统的数字水印[1]方法,由负责训练的模型发送方在模型训练中添加一个额外的训练目标来嵌入水印,且不影响模型的原任务功能。在发生版权纠纷时,通过提取出嵌入水印,验证模型版权的归属,从而保护模型版权,避免受到非法用户的威胁。
但是,在现有的模型版权保护工作中,模型水印的嵌入与验证通常都由模型发送方完成。在模型发送方,如云端,由于同时具备模型结构、数据集和计算资源,所以能够较好地完成模型的训练与水印嵌入工作。然而,在端-边-云联邦学习系统[2]中,如图1所示,模型结构、数据集和计算资源是分布式的,而非中心化。数据不离开本地,边缘节点作为服务器通过聚合本地模型更新来学习公共模型[3]。当对接收到的模型的可信度存在疑虑时,为接收方添加一次模型验证工作就显得十分必要。目前已有大量研究表明[4,5],存在恶意用户试图获取模型而不做出贡献,甚至有恶意用户通过向数据集中引入恶意样本来降低模型的性能。因此,一次成功的模型验证工作不仅有助于接收方追溯模型的发送来源,筛选掉来源不明的模型,而且还可以防止恶意发送方的搭便车和投毒行为。

Figure 1 Client-edge-cloud hierarchical federated learning system
因此,急需一个可供端-边-云联邦学习系统中模型收发双方进行版权验证工作的模型水印方案。受文献[6]启发,本文针对上述问题提出了一种基于认证文件的双方验证模型水印方案,本文工作如下所示:
(1)为了确保模型的发送和接收双方都持有相同的认证文件,并且要求认证文件具备信息隐藏功能,同时不对模型训练造成干扰,本文方案添加了一个认证文件生成步骤,引入了基于小波变换的盲水印嵌入方法,用于将版权标识符嵌入认证文件。此外,本文方案还结合了高级加密标准AES(Advanced Encryption Standard)和安全散列算法SHA-3(Secure Hash Algorithm 3)进行加密及验证,以保护版权标识符信息的隐私性和完整性。
(2)为了提高水印嵌入速率,本文方案引入了基于均方误差MSE(Mean Square Error)的损失函数使模型快速收敛,并添加了L2范数正则化项以预防过拟合。
(3)为了实现模型接收方的验证功能,抵御恶意行为威胁。本文方案以模型的结构调整来进行所有权验证,成功检测嵌入的版权标识字符串以验证所有权,并添加了保真度评估过程对恶意行为进行抵御。
2 相关工作
DL模型通过在训练阶段嵌入数字水印实现模型版权IP(Intellectual Property)保护。现有的水印嵌入方法可以分为2类:(1)基于特征的方法,即通过附加正则化项,将指定的水印嵌入深度神经网络DNN(Deep Neural Network)权重[7];(2)基于后门的方法,依赖于带有特定标签的对抗训练样本(即后门触发器集)[8]。Uchida等人[9]首次尝试将水印嵌入到模型中,使用参数正则化器在模型参数中嵌入水印。虽然这项工作没有损害模型在Cifar10数据集上的性能和推理速度,但它仅适用于待验证的模型内部参数是公开的,即白盒验证情况下。然而,在实际应用中,DL模型通常作为在线服务,通过远程应用程序编程接口API(Application Programming Interface)提供服务。针对这种场景,Rouhani等人[10]提出了DeepSigns,这是一个端到端的IP保护框架,允许开发人员在相关的深度学习模型中系统地插入数字水印。该方法对于模型的删除攻击具有一定的鲁棒性。然而,由于水印的可逆性,它无法抵御模糊攻击。因此,Fan等人[6]提出了一种基于护照的模型所有权验证方案,该方案对删除攻击具有较强的鲁棒性,并能够有效抵御模糊攻击。
为了克服白盒验证的限制,文献[11]提出在触发器集中的对抗示例分类标签中嵌入水印,以便通过API服务远程提取水印,而无需访问网络权重,该方法只需要输入和输出接口来验证所有权。Guo等人[12]提出了一种适用于嵌入式应用程序的黑盒水印方法,其中版权所有者的签名被嵌入到数据集中,用于训练带有水印标记的DNN。Shafieinejad等人[13]提出了一种通过后门方式向DNN嵌入水印的方法,并证明了嵌入水印对于微调和修剪等删除攻击具有相对的鲁棒性。文献[14-16]还提出了如何嵌入对白盒和黑盒验证都适用且对各种类型的攻击都鲁棒的水印(或指纹)。
此外,基于硬件的DNN IP保护工作也逐渐受到关注。文献[17]设计了一种名为AutoDNN芯片的DNN芯片生成器,它可以根据指定应用程序和数据集的DNN自动产生基于现场可编程门阵列FPGA(Field Programmable Gate Array)和专用集成芯片ASIC(Application Specific Integrated Circuit)的DNN芯片,为物联网终端设备提供高效的DNN推理能力。而文献[18]则针对资源受限的边缘设备,考虑到参数加密方法的高功耗问题,提出了一种名为ChaoPIM(Chao Processing In Memory)框架的高效的解决方案。该框架利用混沌加密和内存处理技术来保护DNN模型的安全性。
在联邦学习系统中,也有关于模型版权保护的研究被提出。文献[19]针对协作学习环境中保护有价值的训练数据的需求,考虑到半诚实的对手可能试图监视参与者的隐私信息,提出了一个安全联邦学习框架,以协作训练联邦深度神经网络FedDNN(Federal Deep Neural Network),从而不泄露隐私训练数据和数据特征分布。文献[20]研究了在联邦学习情况下的深度学习模型知识产权保护,并提出在联邦学习环境中每个参与方应能独立验证其对模型的所有权,同时不侵犯其他所有者的隐私。文献[21]引入了一种名为WAFFLE(WAtermarking in FEderated LEarning)水印架构,每次将本地模型聚合到全局模型之后引入一个再训练步骤为模型生成后门,通过后门对模型进行所有权验证。文献[22]考虑到为客户端提供经过训练的模型所有权验证,提出了一种FedDNN所有权验证框架FedIPR(Federated Iearning model intellectual Property Rights)。该框架允许客户端对模型嵌入私有水印并进行验证,从而获得FedDNN模型的合法知识产权。
尽管近些年模型水印的研究工作越来越多,但已有模型都是针对模型发送者验证版权设计的,本文研究的模型水印将扩展到可由接收方辨别模型版权。为此,本文设计了一种基于认证文件的双方验证模型水印方案,为模型接收方添加一次模型验证工作,帮助接收方追溯发送来源,筛除来源不明的模型。
3 基于认证文件的双方验证模型水印方案
本文提出了一种基于认证文件的双方验证模型水印方案,如图2所示,云端将版权标识字符串不可见地嵌入认证文件中,本地设备群使用认证文件参与模型训练,使模型的性能与认证文件强相关。边缘节点以归一化层作为模型验证的必要结构,通过检测模型权重中嵌入的版权标识字符串与认证文件中的版权标识字符串的相似度来验证模型版权。为了便于阐述,本文定义了用于表示方案中主要流程的元组V=(C,G,E,V,F),即认证文件生成过程C、模型签名生成过程G、模型水印嵌入过程E、水印验证过程V和保真度评估过程F。结合端-边-云联邦学习系统模型,方案3个部分的功能表示如下:
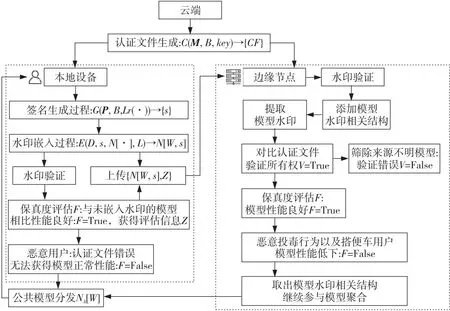
Figure 2 Dual-verification model watermarking scheme based on certification files
(1)云端:考虑到由本地设备群向边缘节点发送认证文件可能会带来额外的成本,以及增加边缘节点处理认证文件的工作负担,本文方案采用云端作为一个客观公正的第三方,负责生成认证文件并将其发送至边缘节点和本地设备群。这一方法确保了认证文件的一致性和可用性,同时维护了版权标识符信息的隐私性和完整性。
认证文件生成C:C(M,B,key)→{CF}。认证文件是达到双方可验证的必要条件。以云端作为客观公正的第三方来完成认证文件生成。方案采用盲水印方法生成认证文件,其中,M为云端选取的一张载体图像,通常为个人标识图片或企业标识,B为需嵌入的版权标识字符串,key为AES加密过程所需的密钥。认证文件CF的生成过程如图3所示。图3中,P为生成的认证文件图像,h表示SHA-3哈希值。

Figure 3 Generation process of certification file
为了确保盲水印具有较高的隐蔽性、鲁棒性和提取精度,本文方案对载体图像进行了一次基于小波变换的盲水印嵌入,将版权标识符隐匿地嵌入到图像中,得到盲水印嵌入图像。随后,本文方案采用AES加密来提升图像的隐私性,同时引入SHA-3哈希验证过程,以确保图像的完整性得到有效保护。
认证文件生成后,云端将其发送至模型收发双方,即边缘节点和本地设备群。在边缘节点和本地设备群完成AES解密与SHA-3完整性验证后,认证文件将继续参与后续工作流程,如图4所示。本地设备群将认证文件输入到DL模型架构,收集输出的特征图pi,其中i表示层数,在后续使用训练数据集进行训练时,以特征图作为每层的认证参数参与训练。边缘节点通过检测模型权重中嵌入的版权标识字符串和认证文件中的版权标识字符串进行相似度对比来验证模型版权。

Figure 4 Certification file participation process
(2)本地设备群:作为本地模型的发送方,本地设备群从边缘节点下载公共模型,在训练中添加一个额外的训练目标来嵌入水印,且不影响模型的主任务功能。模型水印方案一般分为生成、嵌入、验证和评估过程。方案采用了多任务学习方法,通过交替最小化2个目标来实现。首先,训练致力于最小化主任务的损失;其次,同时寻求最小化组合损失函数的损失,即主任务损失和水印损失。
①模型签名生成过程G:G(P,B,Lγ(·))→{s}。其中,s={s1,…,sk}为生成的k比特签名字符串,Lγ(·)是与可训练参数γ相关的水印损失函数。通过联合主任务损失函数和式(1)所示的水印损失函数Lγ(·),使归一化层的可训练参数γ按照认证文件中B的二进制组成取指定的正或负号(1为“+”/0为“-”),从而以γ的符号形成一个独特的签名字符串s,来完成签名生成过程。本文方案中所使用的水印损失函数Lγ(·)是在基于MSE的损失函数中添加了L2范数正则化项,δ0为控制参数,δ为控制规模因子,α为设定常数。水印损失函数如式(1)所示:
Lγ(γ,P,s)=
(1)


过程1 水印损失计算伪代码1.fori≤n do//对卷积结果进行平均池化2. γi←Average Pooling F(WC*Piγ);//使用激活函数对si的取值进行调整3. si←ReLU(δ0-γi*si)控制参数δ0=0.1,α=0.000014. Lr_loss +←α*si+δ*(γi)2;5.end for6.returnLr_loss
②水印嵌入过程E:E(D,s,N[·],L)→N[W,s]。其中,D是训练数据集,L为联合损失函数,N[·]表示预训练模型或模型架构,W为经过训练的模型权重。在模型签名生成后,将以γ的符号形成的签名字符串嵌入模型归一化层权重,以形成模型水印。本文方案采用批归一化对归一化层的可训练参数γ、β进行学习,如式(2)所示:
(2)


算法1 水印嵌入算法输入:{WC,XC,Piγ,Piβ}。输出:YC。1.fori≤n do2. γi←Average Pooling F(WC*Piγ);3. βi←Average Pooling F(WC*Piβ);//XC表示卷积层的输入4. XiP←WC*XiC;//可训练参数γ、β进行学习5. YiP←γi*O(XiP)+βi;6.end for7.return YiP
③水印验证过程V:V(N[W,s],εV)={True,False}。其中,N[W,s]为给定模型,εV为检测误差阈值。水印验证过程用于检查给定的模型N[W,s]是否成功验证了嵌入的签名s。本文方案采用汉明距离来衡量二进制字符串的相似度,当相似度大于1-εV时,水印验证返回True,表示验证成功;否则,返回False,表示验证失败。
模型发送方,即本地设备群,拥有经过训练的模型,模型所有权将由认证文件自动验证。
④保真度评估过程F:F(N[W,s],N[W],εF)={True,False}。其中,N[W,s]是嵌入水印的模型,N[W]是未嵌入水印的模型,εF是一个预定义的阈值。保真度评估过程用于评估嵌入水印的模型N[W,s]与未嵌入水印的模型N[W]之间的性能差异是否小于预定义的阈值εF。评估的判断依据是通过计算2个模型的性能差的绝对值是否小于或等于阈值εF,即|N[W,s]-N[W]|≤εF。如果不等式成立,则表示通过了保真度评估。
本地设备群的保真度评估不仅考察了水印对模型性能的影响,也为边缘节点进行保真度评估提供了协助。本地设备在完成保真度评估后,将包含发送方署名与模型性能表现的评估信息Z与模型N[W,s]一同发送至边缘节点。
(3)边缘节点:本文方案在边缘节点设立了2道防线,以抵御搭便车攻击和投毒攻击,即水印验证过程V和保真度评估过程F。搭便车攻击指存在恶意攻击者想从全局模型中获益而又不想参与学习过程,主要分为基于前一轮模型与基于高斯噪声2种类型。投毒攻击主要指数据投毒,以破坏全局模型性能为目的。水印验证过程V与保真度评估过程F对这2种攻击都具有一定的防范作用。
①水印验证过程V:V(N[W,s],P,εV)={True,False}。边缘节点以归一化层作为模型验证的必要结构,取出归一化层,模型可以继续参加训练而不影响性能,添加归一化层,模型成功检测嵌入的版权标识字符串,以验证所有权。
模型的版权验证通过检测模型权重中嵌入的版权标识字符串B′与认证文件中的版权标识字符串B的相似度来进行。水印的验证过程能够很好地避免搭便车攻击和部分投毒行为,没有正确水印的模型将会首先被边缘节点筛除。即使恶意用户为模型嵌入了正确的水印,方案也可以通过后续保真度评估过程将性能不良的模型筛除,达到抵御攻击的效果。
②保真度评估过程F:F(N[W,s],Z,εF)={True,False}。边缘节点的保真度评估过程是抵御搭便车攻击和投毒攻击的最后防线。在进行水印验证后,查验发送方的评估信息,筛除来源不明、性能不良的模型,对搭便车攻击和投毒攻击都具有抵御效果。如果存在恶意用户发送的模型既通过了水印验证过程也通过了保真度评估过程,则本文认为恶意攻击者的攻击行为是不必要的。
4 实验与结果分析
本节阐述了基于认证文件的双方验证模型水印方案的实验与结果分析,以下简称为认证方案。本文实验包括3方面考察:(1)认证方案在端-边-云分层联邦学习系统中应用的可行性考察,包括接收方模型所有权验证并抵御搭便车行为和投毒攻击的可行性,以及模型继续训练的可行性。(2)考察认证方案对抗删除攻击、抗歧义攻击和抗翻转攻击的鲁棒性。(3)考察引入基于MSE的水印损失函数对模型嵌入水印的速率影响。实验的网络包括AlexNet和ResNet-18,使用3个公共数据集Cifar10、Cifar100和ImageNet2012。
4.1 可行性
本文实验将从2方面对认证方案在端-边-云分层联邦学习系统的可行性进行考察。其一考察边缘节点上接收的模型继续参加训练的可行性;其二考察边缘节点对模型进行所有权验证以及抵御搭便车行为和投毒攻击的可行性,包括模型水印的提取正确率及模型性能评估。
4.1.1 接收方模型继续训练可行性
在端-边-云分层联邦学习系统中,边缘节点作为服务器通过聚合本地模型更新来学习公共模型。为了考察模型在边缘节点上是否能满足继续参与模型聚合的需求,本文对后续公共模型的性能进行了考察。在不同本地设备数量下考察公共模型的主任务精确度,以FedAvg作为聚合算法[23],以未嵌入水印的模型聚合为基线(括号内为基线),实验结果如表1所示。公共模型性能依然可用,与基线性能相比较,模型性能仅仅下降2%以内,表明本文方案不影响模型继续参与联邦学习训练。这是因为模型的推理与水印嵌入的结构并不关联,取出模型中与嵌入水印相关的网络结构(即嵌入了水印的归一化层),模型依然可以获得良好的推理性能。
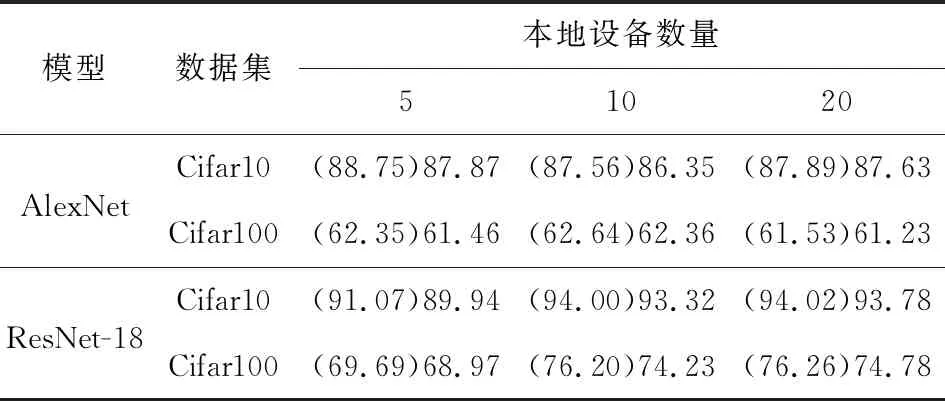
Table 1 Average main tasks accuracy of common models
4.1.2 接收方模型抵御攻击可行性
当对接收到的模型的可信度存在疑虑时,有必要让接收方对模型进行验证。本文方案为接收方增加模型的所有权验证和保真度评估过程,有助于抵御搭便车行为,即恶意参与者不提供任何贡献而获取资源;也有助于抵抗投毒攻击,防止公共模型被恶意污染,导致模型性能下降。
实验考察了边缘节点将归一化层添加到模型中后,模型水印的提取正确率,以及对比认证文件中提取的版权标识字符串二进制相似度。实验结果如表2所示,结果表明模型的水印提取正确率与对比相似度均高达100%,模型的水印可验证性依然良好,有助于边缘节点对模型进行筛选。
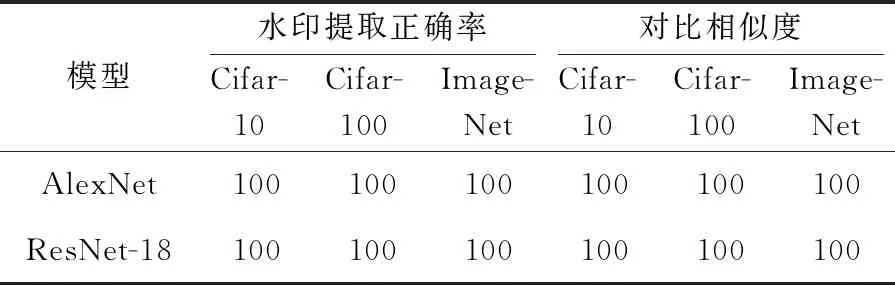
Table 2 Extraction correct rate and contrast similarity of model watermarks
在此基础上,本文实验对搭便车行为和投毒攻击行为进行了模型性能对比和水印提取正确率检测,实验结果如表3和表4所示。将搭便车攻击记为FA(Free-riding Attack),FA1表示无数据搭便车的攻击行为,FA2表示使用之前模型进行搭便车的行为,投毒攻击行为记为PA(Poisoning Attack),基于对方法的鲁棒性分析,实验将水印验证过程V中水印正确提取率的误差阈值设置为εV=0.05,保真度评估过程F中性能差阈值设置为εF=0.05。

Table 3 Resisting free-riding behavior表3 抗搭便车行为
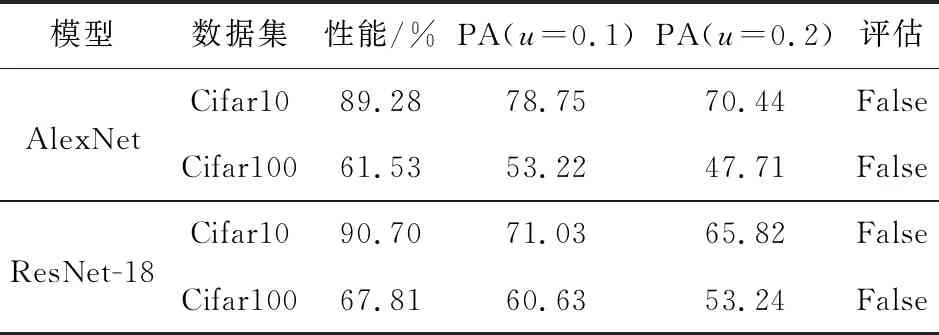
Table 4 Resisting poisoning attack
对于FA1,通常不涉及对模型本身的修改或植入,而是攻击者试图获取已部署模型的性能和功能,而不提供有效或真实的数据,FA1无法通过边缘节点的水印验证过程。对于FA2,使用随机认证文件训练本地模型作为恶意模型,边缘节点对此类模型的水印提取正确率取决于训练中认证文件的相似度,因此具有极大的随机性,当设置每一轮认证文件使其相似度远低于检测误差阈值时,边缘节点能够对这类搭便车攻击进行有效防御。
本文实验采用恶意数据对本地模型进行投毒攻击,修改训练数据标签使其取随机值,并设置修改比例为u=0.1和u=0.2这2种情况,其主任务精确度量化如表4所示,被投毒模型与正常模型的性能差绝对值大于阈值,无法通过方案的保真度评估过程。
4.2 鲁棒性
认证方案不仅是为了帮助接收方验证模型所有权,也是为了保护模型版权。因此,水印的鲁棒性考察十分必要。在本文实验中,将对本地设备经过训练的模型从删除攻击、歧义攻击和翻转攻击3方面进行鲁棒性考察。
4.2.1 抗删除攻击
删除攻击是指对模型水印进行删除,使所有权验证无法进行。删除攻击包括剪枝攻击和微调。
剪枝攻击的目的是在不影响模型推理性能的情况下,减少冗余参数,降低网络复杂度,从而提高网络泛化能力,并防止过拟合。攻击者也可以使用模型剪枝来破坏模型嵌入的水印,使模型的所有权验证受到影响。本文采用类盲修剪方案,在不同剪枝率的情况下测试方案中的水印提取正确率,并对剪枝后的模型进行主任务保真度评估。实验结果如表5所示,括号内为水印提取正确率,括号外为主任务精确度,以ResNet-18为例,在剪枝率60%的情况下,水印提取正确率均保持在90%以上,能够较好地抵抗剪枝攻击。
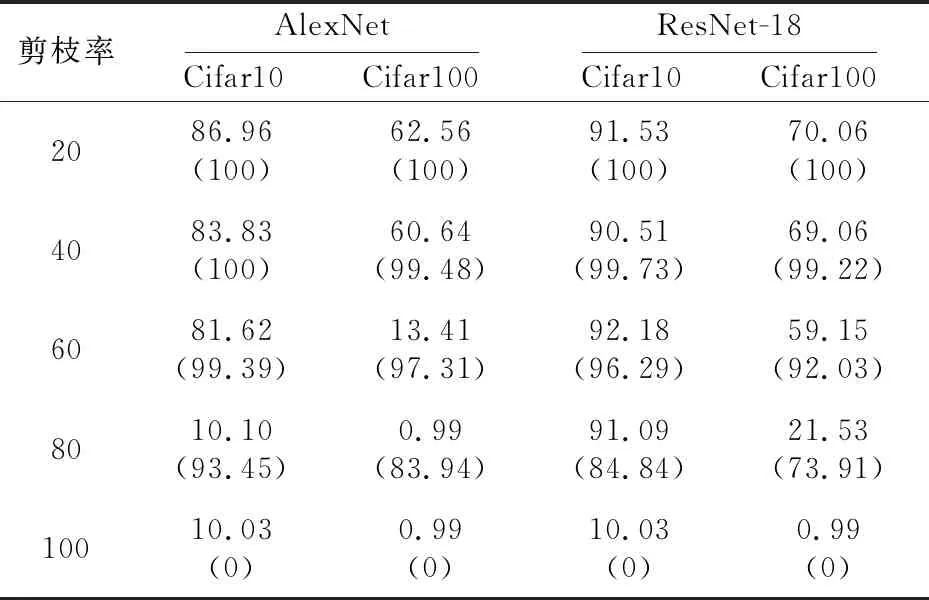
Table 5 Resisting pruning attack
微调是指将预训练好的模型在其他数据集上进行使用。本文实验采用重新训练最后一层的微调方法,分别对2种模型在不同数据集中微调后水印的提取正确率进行考察。实验证明,即使在新任务对模型进行微调后,水印的提取正确率依然很高,能够提供所有权验证。表6为增加实验对比之后的结果,实验使用新数据集Caltech-101对模型进行微调,水印的提取正确率依然为100%。推测水印对抗删除攻击的良好鲁棒性来源于水印的嵌入位置,即可训练参数γ中,若可训练参数γ值降低到0,输出值也将接近于0。

Table 6 Comparison of watermark extraction correct rate after fine tuning
4.2.2 抗歧义攻击
歧义攻击是指攻击者使用伪造的认证文件图像对模型进行攻击,分为随机攻击和逆向工程攻击。随机攻击是指认证文件图像是随机获得的;逆向工程攻击是指假设对手可以访问原始数据集,并试图通过固定模型权重,逆向工程获得认证文件图像,并使用其对模型进行攻击。
水印抗歧义攻击结果如图5所示,纵轴表示主任务精确度,横轴表示攻击轮次。以AlexNet为例,对于随机攻击伪造的认证文件图像,模型具有较好的鲁棒性,在50次攻击中,模型的性能均不佳,即便使用逆向工程伪造的认证文件图像,模型的主任务精确度也不超过70%。在Cifar10训练集下,逆向工程攻击使主任务精确度下降33%,模型性能下降到不可用的地步。在Cifar100训练集下,对比主任务原始精确度(基线)下降30%,模型性能仍不可用。因此,模型水印对歧义攻击具有鲁棒性。推测模型水印抗歧义攻击的良好鲁棒性来源于可训练参数与模型权重的强依赖性,当认证参数发生变化,可训练参数γ也发生变化,导致模型的推理结果发生极大改变。
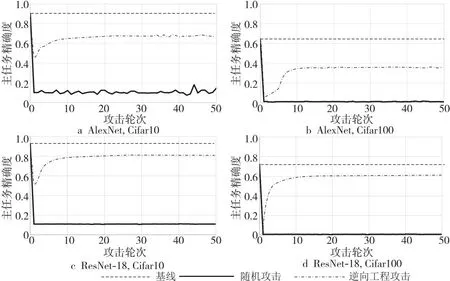
Figure 5 Experimental comparison results of resist ambiguous attack
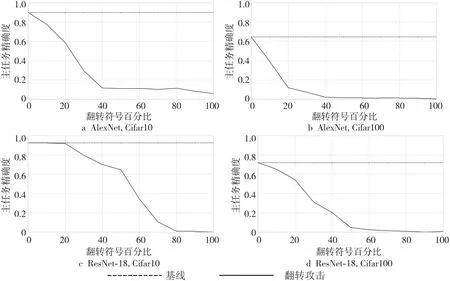
Figure 6 Experimental comparison results of resist flipping attack
4.2.3 抗翻转攻击
由于模型水印的嵌入位置在归一化层的可训练参数γ的符号中,因此针对可训练参数γ的符号进行翻转,以达到攻击模型水印的效果。在实验中,通过随机翻转可训练参数的符号来模拟随机攻击,分别对翻转10%~100%可训练参数符号进行实验,并对模型进行保真度评估。抗翻转攻击实验对比结果如图6所示,横轴表示翻转符号百分比,纵轴表示主任务精确度。在符号翻转40%的情况下,模型主任务精确度下降到20%以下,此时模型性能不可用,达到模型版权保护的目的。因此,本文方案抗翻转攻击效果良好。
4.3 速率改进
在模型的水印嵌入工作中,水印损失函数应该与模型的主要任务无关,以避免对模型性能造成不必要的干扰。因此,本文方案引入了基于MSE的水印损失函数并添加L2范数正则化项以预防过拟合,使模型水印信息被嵌入到模型参数中,而不干扰模型的正常任务学习。
基于MSE的水印损失函数具有连续、处处可导的优点,配合使用梯度下降算法,有利于快速收敛,有效地找到最优解。对比原文献[4]方案中所采用的损失函数,本文方案所引入的模型水印损失函数有明确的全局最小值,不存在多个局部最小值问题,因此更利于任务迅速找到最优解,推测方案改进后的精度提升也源于此。其次,MSE损失的计算仅涉及平方差和平均值,而原文献[4]方案所采用损失函数涉及到了非线性部分,因此在同样硬件和算法的条件下,使用MSE损失使得模型水印嵌入的速率得到提升。
通过实验对比,记录每一轮训练与测试的起始时间,可以由时间差体现引入的模型水印损失函数对比原文献[6]方案带来的速率提升。从表7中可知,对比原文献[6]方案中所采用的模型水印损失函数,认证方案在保持模型水印的提取正确率不变,主任务精确度上升约3%~8%(AlexNet)和6%~12%(ResNet-18)的情况下,对于每轮次的平均训练时长缩短约40%,测试时长缩短约20%~40%。认证方案几乎不影响主任务精确度和水印提取正确率,并训练速度获得极大的提升。
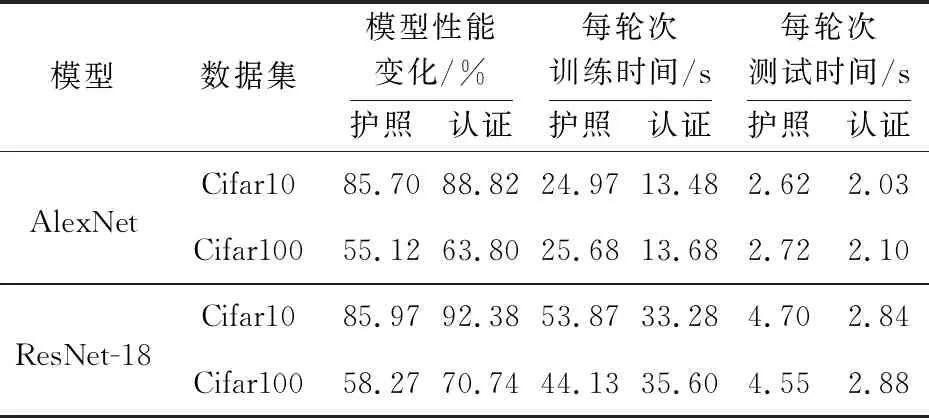
Table 7 Comparison of average rate improvement
5 结束语
为了在端-边-云分层联邦学习系统中保护模型版权,并为模型收发双方的模型版权验证工作提供帮助,本文提出了一种基于认证文件的双方验证模型水印方案。通过实验验证了本文方案水印的良好可验证性以及抵御搭便车行为、投毒攻击的可行性;并分析验证了本文方案水印不影响模型继续参与接收端的模型训练;大量的实验验证了本文方案水印的鲁棒性以及速率改进的优势。
