煤矿工业物联网设备识别模型
2024-04-22郝秦霞李慧敏
郝秦霞,李慧敏
(西安科技大学 通信与信息工程学院,陕西 西安 710054)
0 引言
随着工业智能科学技术的不断推进,工业物联网(Industrial Internet of Things,IIoT)作为新一代信息通信技术与现代工业技术深度融合的产物,已成为全球新一轮产业竞争的制高点[1]。国家发展改革委等八部委联合印发《关于加快煤矿智能化发展的指导意见》,带头大力推动煤矿网络安全与智能化信息建设,加快IIoT 在煤矿行业的应用。然而煤矿IIoT 由于其自身环境、生产条件等因素约束,煤矿IIoT 设备存在严重安全隐患。煤矿IIoT 设备受自身设计和性质限制,通常为计算与存储资源受限设备,难以采用强密码协议与复杂的认证机制进行安全防护[2-4],攻击者通过分析网络通信流量,对特定漏洞设备发起针对性网络攻击,可能造成敏感数据泄露或恶意篡改,严重威胁煤矿IIoT 的安全稳定。精准识别煤矿IIoT 设备可完善煤矿设备资产信息库,有效管理并维护设备正常运转,为提高设备的安全防护能力提供依据,对保障煤矿安全稳定生产具有重要意义。
现有设备识别研究主要集中在物联网(Internet of Things,IoT)设备识别算法。M.Miettinen 等[5]提出了IoT Sentinel,利用随机森林构建分类模型识别IoT 设备,对潜在易受攻击设备采取必要防护措施。A.Sivanathan 等[6]开发了一种多阶段机器学习(Machine Learning,ML)[7]分类算法模型,基于网络流量分组和统计特征,精准识别各类设备。但上述2 种模型均需手动提取流量特征,IoT 设备类型众多,特征构造复杂,不适用于具有复杂巨系统的煤矿IIoT 环境。深度学习(Deep Learning,DL)将输入数据映射至特定标签[8],自动学习数据特征。J.Ortiz等[9]提出了概率框架DeviceMien,采用堆叠的长短期记忆网络(Long Short Term Memory,LSTM)自动编码器学习流量特征,利用聚类方法建模各类设备,可精准区别IoT 与Non-IoT 设备,并有效识别未知设备。Yin Feihong 等[10]采用端到端的IoT 设备识别方法,对设备流量执行向量化操作,输入到卷积神经网络(Convolutional Neural Network,CNN)、LSTM/门控循环单元、CNN+双向LSTM 这3 类模型中识别IoT 设备。J.Kotak 等[11]将原始流量有效载荷预处理为灰度图像,利用多层感知机(Multilayer Perceptron,MLP)自动提取流量特征、分类设备并识别未处于白名单的IoT 设备。DL 虽解决了人工提取特征困难的问题,但随之带来的密集内存与高计算需求使其难以部署在计算能力有限的IoT 设备中。
轻量化神经网络方法(如组卷积[12]、深度可分离卷积(Depthwise Separable Convolution,DSC)[13]、神经网络结构搜索[14]、权值共享[15]与量化[16]等)能够在资源受限设备上保持良好网络性能的同时,避免存储空间和能耗对传统神经网络的限制[17]。因此,本文提出了一种煤矿IIoT 设备识别模型,主要创新如下:
1)为避免煤矿IIoT 海量数据包引发的处理瓶颈问题,对网络出口节点处采集的原始流量进行切分及截取操作。
2)为降低煤矿IIoT 流量数据复杂度,采用DSC 与卷积块注意力模块(Convolutional Block Attention Module,CBAM)[18]搭建复合卷积层,从而构建DSC-CBAM 模型以过滤Non-IIoT 设备。
3)为避免煤矿IIoT 设备传输流量不平衡导致的设备误识别问题,利用带有阶段惩罚的Wasserstein生成对抗网络(Wasserstein Generative Adversarial Network with Gradient Penalty,WGAN-GP)[19]对流量较少的IIoT 设备进行数据扩充,达到平衡偏移流量数据的目的。
4)为捕获IIoT 设备内部细微的流量行为模式,引入多尺度特征融合(Multi-scale Feature Fusion,MFF)技术与Mish 激活函数[20]优化DSC-CBAM 模型,构建优化混合模态识别(MFF-DSC-CBAM-Mish,MDCM)模型,从而精确识别煤矿IIoT 设备。
1 煤矿IIoT 设备识别模型
煤矿IIoT 设备识别模型分为原始流量切分与截取、Non-IIoT 设备过滤、偏移流量数据平衡、煤矿IIoT 设备识别4 个部分,如图1 所示。
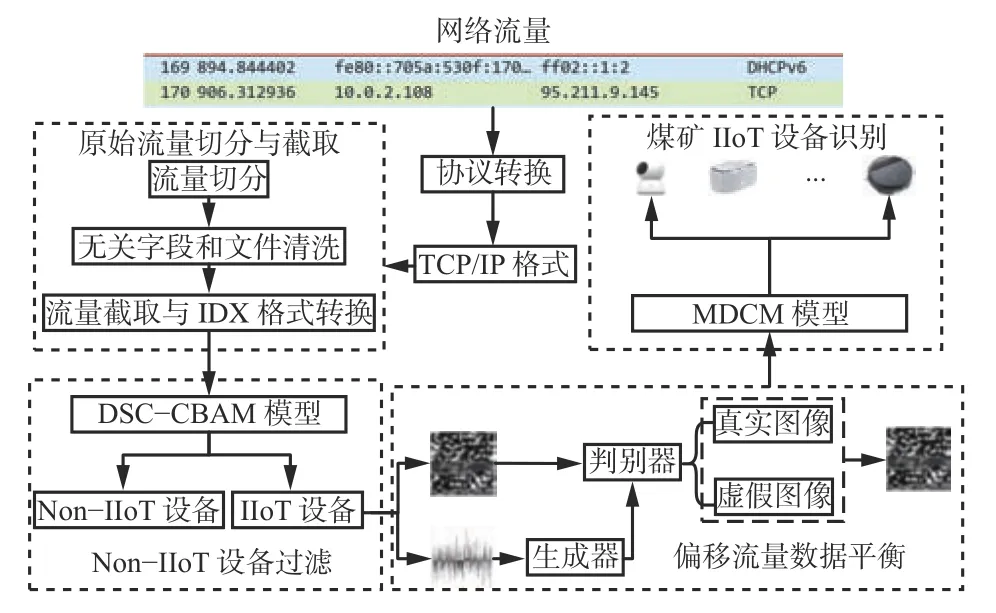
图1 煤矿IIoT 设备识别模型结构Fig.1 Structure of coal mine IIoT equipment recognition model
1)原始流量切分与截取。将支持TCP/IP 协议传输的流量数据切分为双向会话流,去除会话流中无关MAC/IP 地址字段,并删除会话流中应用层空/重复文件,将每个会话流截取定长字段后转为IDX[21]格式进行存储。
2)Non-IIoT 设备过滤。利用轻量级DSC 替代传统卷积提取流量特征,结合CBAM 校正通道、空间权重,搭建DSC-CBAM 模型过滤Non-IIoT 设备。
3)偏移流量数据平衡。采用WGAN-GP 模型平衡流量较少类煤矿IIoT 设备流量数据,将平衡后数据并入原有设备数据集中共同作为煤矿IIoT 设备增强数据集。
4)煤矿IIoT 设备识别。将经过平衡后的数据输入MDCM 模型,实现煤矿IIoT 设备精准识别。
1.1 原始流量切分与截取
定义煤矿IIoT 网络接口处采集到的支持TCP/IP协议传输的流量数据为原始流量P,是数据包pi(i=1,2,…,Q,Q为数据包个数)的集合。
pi包含五元组信息ai、数据包长度li等不同字段。
ai包括源IP 地址、目的IP 地址、源端口、目的端口及传输层协议,可唯一标志一条网络通信连接,了解网络数据流传输规律及特性。拥有相同ai的所有pi称为一个单向流f j(j=1,2,…,n,n为单向流个数)[22],即将P划分为包含f j的集合F,每个f j内数据包pi按时间排序。
五元组ai源、目的互换即为双向流,双向流组成的所有pi称为一个会话流。
结合上述流量信息,原始流量切分与截取步骤如下:
1)流量切分。利用SplitCap 工具将P按单向流/会话流粒度切分,每个单向流/会话流由若干个pi组成,包含更丰富的设备通信流量行为特征(如pi间字节的紧密关系程度、pi大小及个数、pi内信息的空间关系等),能有效提高设备识别准确率,实现精准防控。切分默认保留pi中OSI 模型所有层信息。本文选择文献[23]中流量切分的最佳表示组合,即将P切分为会话,保留pi所有层信息。
2)无关字段和文件清洗。鉴于网络层IP 地址和数据链路层MAC 地址字段在DL 模型中会占据较大权重,干扰特征提取与模型分类,对字段执行流量匿名化[24]。煤矿IIoT 设备同一时刻可能传输大量相同数据,为降低数据量,避免模型识别偏移,对相同流量予以去重。
3)流量截取和IDX 格式转换。流量数据需保持相同维度输入DL 模型,将所有流量截取固定的L个字节,若长度大于L,仅截取前L个字节,若小于L,则在其后补充0x00 至L个字节。文献[25]对比了不同数据集的流量截取长度,认为选取600~800 byte时实验效果良好。因此本文将流量截取长度定义为784 byte,将截取后相同格式的流量数据转换为IDX文件格式进行存储。
1.2 Non-IIoT 设备过滤
煤矿IIoT 环境下设备类型复杂多样,为降低流量数据复杂度,应剔除无关的Non-IIoT 设备[26]。为降低模型复杂度,以轻量级神经网络为基础,搭建DSC-CBAM 模型以实现Non-IIoT 设备过滤,如图2所示。
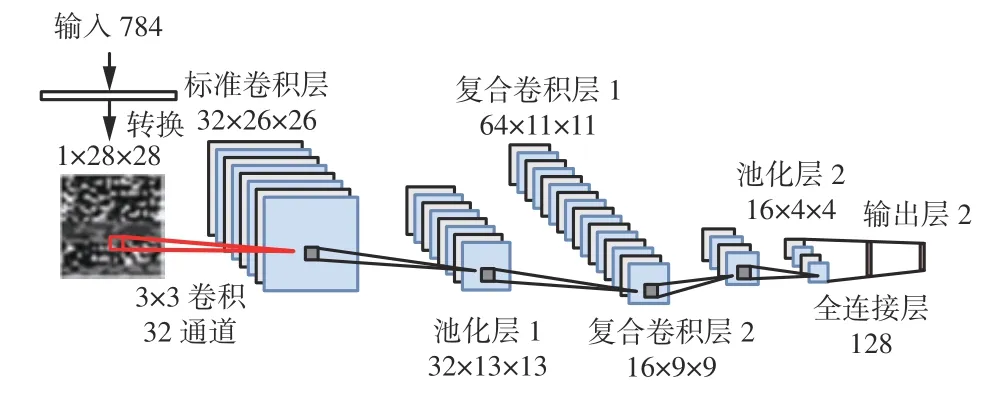
图2 DSC-CBAM 模型结构Fig.2 Structure of DSC-CBAM model
DSC-CBAM 模型网络架构如下:
1)标准卷积层。为保证全局特征的提取精度,使用标准卷积层捕获输入数据浅层特征。
式中:Fk为第k层特征图;σ(·)为ReLU 激活函数;Wk为第k层权重;bk为第k层偏置。
设置标准卷积层的通道为32、卷积核大小为3×3。
2)池化层1。利用最大池化层(卷积核大小为2×2,步长为2)进行下采样,将特征图压缩减半,去除冗余信息,降低参数量。
式中maxpool(·)为最大池化操作。
3)复合卷积层1。复合卷积层为DSC-CBAM模型的核心,其结构如图3 所示。
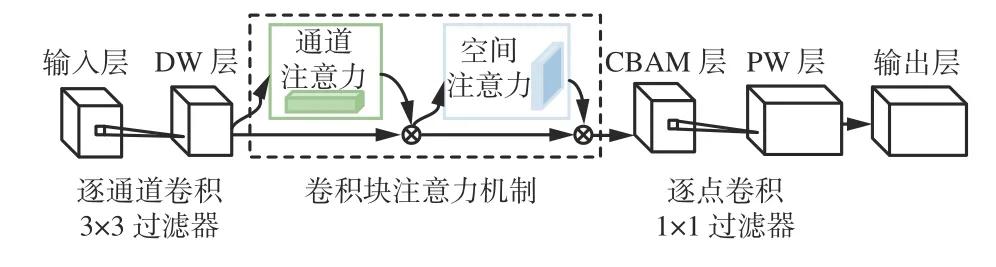
图3 复合卷积层结构Fig.3 Structure of composite convolutional layer
复合卷积层由DSC 与注意力机制2 个部分组成。DSC 将标准卷积分解为逐通道(Depthwise,DW)与逐点(Pointwise,PW)卷积。DW 卷积将单个卷积滤波器应用于输入的单个通道,PW 卷积采用多个1×1 大小卷积核收割DW 卷积不同通道的输出信息,通过线性组合构建新特征,可有效弥补标准卷积带来的参数多、计算量庞大问题,显著降低模型大小。但DSC 降低参数量的同时会破坏输出通道与卷积核的相互作用[27],造成模型性能下降,因此本文在DW 卷积后引入注意力机制校正输出特征权重,捕获重要特征信息。
常用注意力机制包括压缩和激励网络(Squeezeand-Excitation Networks,SENet)[28]、深度卷积神经网络的高效通道注意力模块(Efficient Channel Attention for Deep Convolutional Neural Networks,ECANet)[29]、GENet[30]、选择性内核网络(Selective Kernel Network,SKNet)[31]、CBAM 等。SENet 利用挤压激励模块收集全局信息,捕获通道之间关系,ECANet 在此基础上对激励模块进行改进,降低模型复杂性,但两者均未考虑复杂的全局特征信息;GENet 从特征图中提取更有效的空间信息并对其进行调控,但忽略了通道对特征提取的贡献;SKNet 允许神经元根据输入信息自适应调整感受野大小,但使用SK 卷积替换标准卷积时,精度提升较小;CBAM 将通道注意力模块与空间注意力模块进行级联,顺序捕获输入特征通道、空间信息,模型训练稳定且精度提升较大。综上,选择CBAM 注意力机制调整流量特征权重,同时引入Hard Sigmoid 激活函数替换Sigmoid 激活函数,可在硬件受限设备上保持较高识别准确率的同时,减少计算成本。
CBAM 中通道注意力模块采用全局平均、最大池化层收集目标对象区域独特信息,输入共享网络MLP 生成通道注意力图,经Hard Sigmoid 激活函数合并输出特征向量。空间注意力模块对通道输出特征图采用全局平均、最大池化操作,沿通道维度合并,采用7×7 大小卷积核与Hard Sigmoid 激活函数得到最终细化的注意力输出。
师资的安排:中韩结合。由专任教师承担基础词句语法讲授,由韩籍教师承担听说教学,以夯实基础,强化听说技能综合运用。
复合卷积层1 使用DW 卷积提取池化层输出特征,并引入CBAM 自适应调整DW 层输出特征权重大小,将校正后特征图送入由64 个1×1 大小卷积核组成的PW 卷积层中,通过线性组合生成高维特征图。
4)复合卷积层2。网络结构设置与复合卷积层1 相同。为进一步降低内存占用,引入线性瓶颈层[32]将高维特征投影回具有线性卷积的低维表示,即使用卷积核大小为1×1 的PW 卷积线性组合成低维特征。线性激活函数可避免折叠通道时丢失部分特征信息,保留特征多样性。
5)池化层2。参数设置与池化层1 相同。
6)全连接层。全连接层神经元与上一层所有神经元相连,将池化层2 的卷积结果转换为一维向量以用于最终分类。
7)输出层。使用Softmax 激活函数,输出IIoT/Non-IIoT 二分类结果。
1.3 偏移流量数据平衡
煤矿生产涉及人-机-环-管多方面因素,造成煤矿IIoT 设备流量数据存在严重不平衡。为有效平衡流量数据,将流量较少的IIoT 设备流量数据转为二维灰度图,引入在图像生成、偏移数据补齐方面具有极大优势的生成对抗网络,采用其变体WGAN-GP平衡偏移流量数据。
使用DSC-CBAM 模型精准分离Non-IIoT 设备后,只需对流量较少的IIoT 设备进行数据扩充,偏移数据平衡后可有效避免煤矿IIoT设备误识别、漏识别问题。
使用WGAN-GP 扩充煤矿IIoT 设备流量数据集流程如下:
1)输入流量较少的煤矿IIoT 设备灰度图像,图像大小为28×28,共784 维,作为真实数据分布Ddata。
3)构建判别器,均匀采样Ddata与Dfake间数据,计算正则化项Gradient Penalize,惩罚系数 λ=10,添加到判别器目标函数中,强制约束判别器满足1-Lipschitz 分布。
4)将Ddata与Dfake分别输入判别器中,辅以正则化项,计算损失函数,执行梯度反向传播,更新判别器参数。
5)将判别器训练ncritic次(ncritic为每更新1 次生成器时判别器需迭代的次数)后,再次将100 维高斯随机噪声输入生成器中,将生成的虚假数据分布输入判别器中,计算损失函数并更新生成器参数。
6)生成器和判别器经过多次训练博弈达到均衡后,将平衡后数据扩充至原有设备数据集,转换为IDX格式数据输入MDCM 模型中。
1.4 煤矿IIoT 设备识别
煤矿IIoT 设备各自采用不同协议与服务器开放端口交互信息,传输流量呈相异的行为模式。为直观展示设备内部行为特征,将设备流量数据转为二维灰度图形式,如图4 所示,其中设备名称均采用缩写。图4(a)中显示Nws 设备内部流量模式完全一致,LBLSB、IC 设备虽呈2 种流量模式,但内部仍保持较高一致性。图4(b)中显示异类IIoT 设备灰度图纹理大多各不相同,内部呈相异的流量模式,可以肉眼方式有效区分,但部分设备差别细微,难以通过人眼视觉方式捕捉。

图4 IIoT 设备灰度图Fig.4 Grayscale image of IIoT equipment
为捕捉异类煤矿IIoT 设备内部细微的流量模式,引入MFF 替换DSC-CBAM 模型中的标准卷积层,捕获输入流量数据不同感受野特征信息,如图5所示。
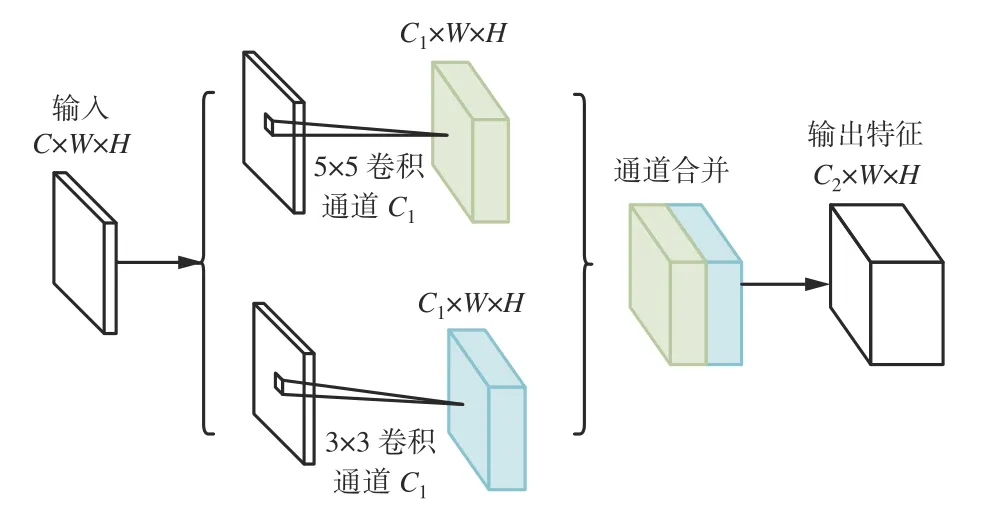
图5 多尺度特征融合Fig.5 Multi-scale feature fusion
将C×W×H(通道数×宽×高)大小的输入特征图送入通道数为C1、卷积核大小为5×5 和3×3 的标准卷积中,并行执行多个卷积运算,将卷积结果合并成大小为C2×W×H(C2为输出特征图通道数)的高维输出特征图,可有效提高网络内部计算资源利用率。
由于DSC 卷积核较小,极易在非线性激活函数作用下使输出趋近于0,以致卷积核失活。复合卷积层所用ReLU 激活函数过于脆弱且对异常值敏感,若接收的输入不在常值范围内,更新参数时梯度将被置0,神经元出现永久性死亡,无法良好适用于DSC 中。Mish 激活函数保留少量负权重,可在神经元负输入状态具有非零梯度,从而允许参数更新,保证信息流不丢失,具有良好的泛化能力。因此,本文使用Mish 激活函数替换DSC-CBAM 模型复合卷积层中ReLU 激活函数,从而构建MDCM 模型以实现煤矿IIoT 设备精准识别。
MDCM 模型网络结构见表1。
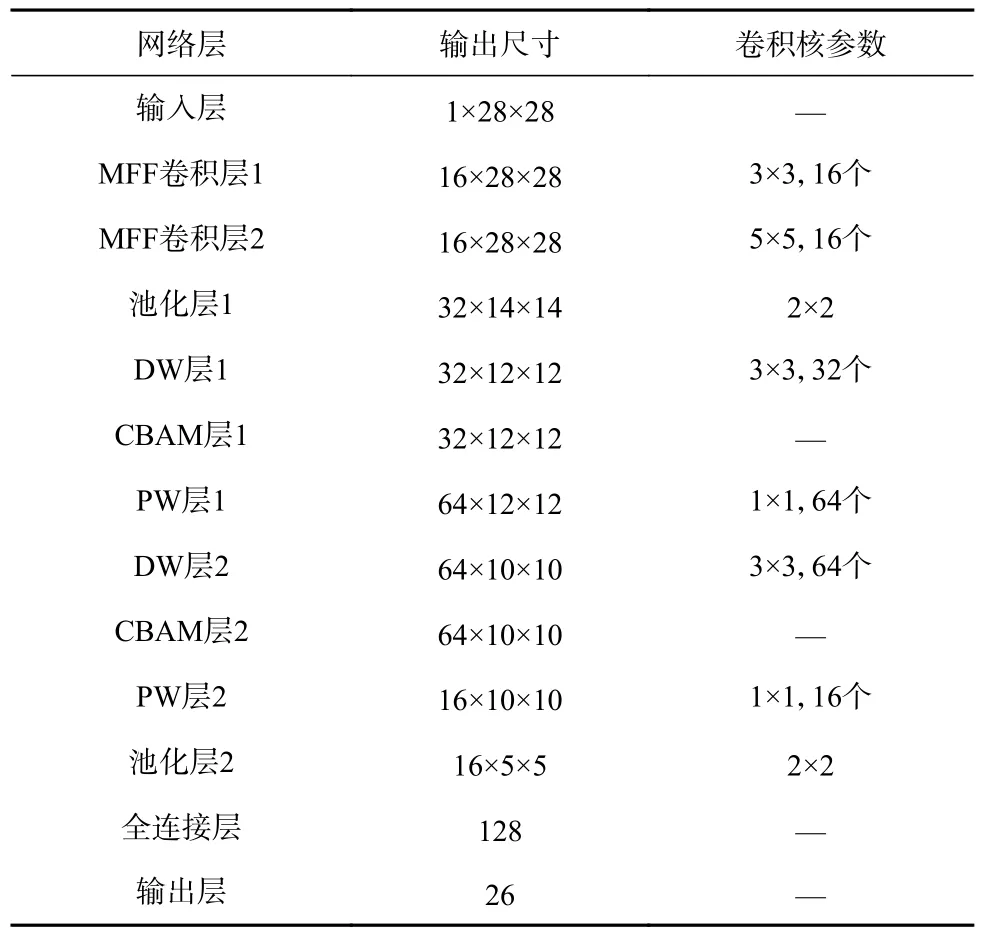
表1 MDCM 模型网络结构Table 1 Network structure of MDCM model
2 实验与结果分析
2.1 数据集
煤矿IIoT 中包含支持WiFi、ZigBee、低功耗蓝牙等自组网络协议传输的流量数据。为有效解决流量数据协议异构、设备互联互通困难等问题,将流量数据转换为支持TCP/IP 协议传输的数据格式。但目前没有公开的煤矿设备流量数据集,为保证数据的有效性和真实性,选用IoT Sentinel[5]和UNSW[6]数据集及陕西某煤矿部分工作现场流量数据组成本文实验数据集。
2.2 Non-IIoT 设备过滤结果
将DSC-CBAM 模型与现有表现较好的设备过滤模型进行对比,结果见表2。其中,文献[11]仅采用全连接层构建MLP 网络区分2 类设备;文献[33]对流量数据进行卷积、池化、展平操作后,输入多隐层神经网络中以获取最佳分类结果。从表2 可看出,文献[11]和文献[33]所提模型均可准确过滤Non-IIoT 设备,但文献[11]模型参数量大,文献[33]模型本身规模庞大;而DSC-CBAM 模型具有最高的准确率、精确率、召回率、F1-score 及最低的参数量,可快速、精准过滤Non-IIoT 设备。这是由于DSC-CBAM 模型引入的DSC 可显著降低模型复杂度,减轻网络训练负担,且CBAM 可有效校正特征权重,提高模型表征能力。
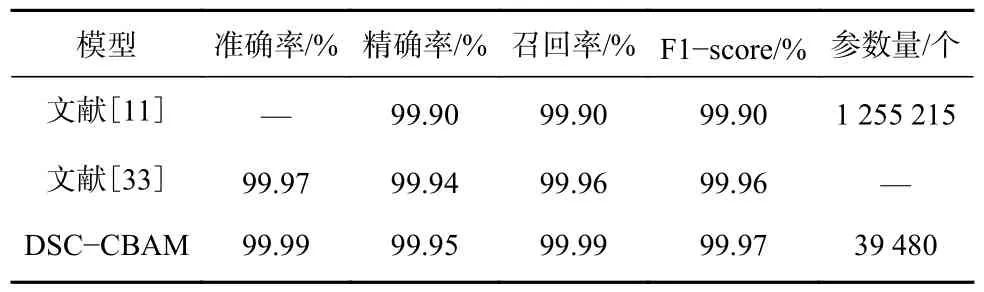
表2 Non-IIoT 设备过滤结果对比Table 2 Comparison of filtering results of Non-IIoT equipment
2.3 偏移流量数据平衡效果
为验证偏移流量数据平衡对识别IIoT 设备的必要性,将经WGAN-GP 平衡前后的IIoT 设备数据集分别输入MDCM 模型中,对比结果见表3,其中设备HB 和HC 支持ZigBee 自组网络协议,设备DLDS 为支持Z-Ware 协议的D-Link 门窗传感器,上述设备流量数据经协议转换操作后转为支持TCP/IP 协议传输的流量数据,其余设备流量数据均支持TCP/IP 协议。
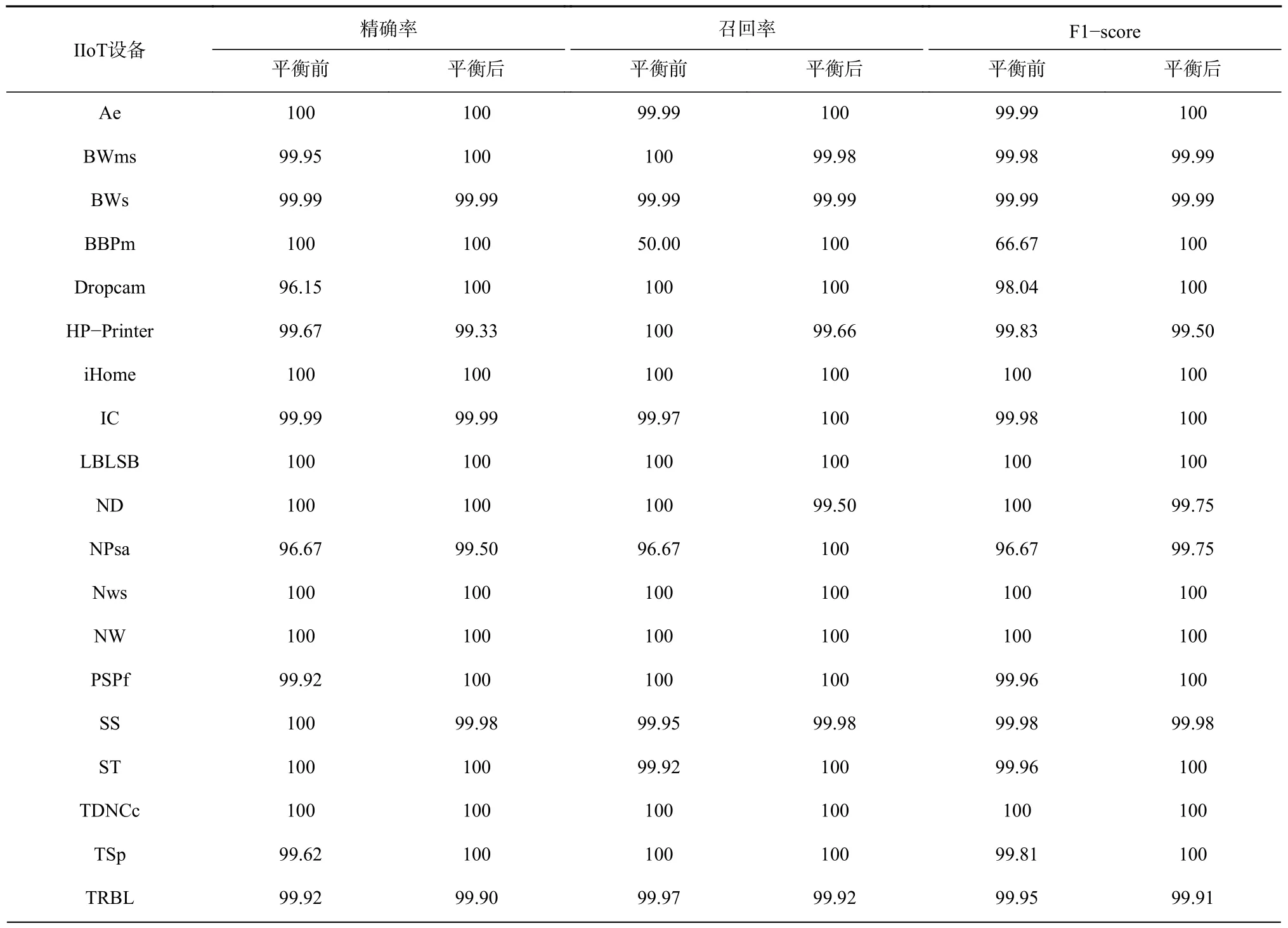
表3 偏移流量数据平衡前后设备识别指标对比Table 3 Comparison of equipment recognition indicators before and after offset flow data balancing %
从表3 可看出,设备WAsss 和WSBM 由于样本数目过小,在偏移流量数据平衡前全部被误识别为其他设备,但经偏移流量数据平衡后,WAsss 和WSBM 均可被正确识别;偏移流量数据平衡后,大多煤矿IIoT 设备识别指标相较于平衡前得到有效提升,其中各类煤矿IIoT 设备识别精确率、F1-score 均高于99%,部分设备召回率较未平衡前提升100%。
2.4 消融实验
通过消融实验验证MDCM 模型中DSC,CBAM,MFF,Mish 对优化煤矿IIoT 设备识别效果的有效性。CNN 模型基础网络架构由标准卷积组成,其中包括32 个5×5 与64 个3×3 大小的卷积核,辅以池化层降低维度,经全连接层分类输出;DSC 模型将CNN 模型第2 个标准卷积替换为DSC;DSC-CBAM模型在DSC 模型基础上添加CBAM;MDC 模型在DSC-CBAM 模型基础上引入MFF;MDCM 模型在MDC 模型基础上增加Mish 激活函数。所有模型共训练15 轮,从模型损失、准确率、精确率、召回率、F1-score 及参数量6 个维度进行对比,结果如图6所示。

图6 消融实验结果Fig.6 Ablation experiment results
从图6 可看出,CNN 模型收敛速度中等,各评价指标保持在99.960%左右,但参数量高达228 318 个,模型复杂度较高;DSC 模型参数量显著降低到CNN 模型的16.6%,精确率、召回率等评价指标略有损失,表明DSC 确实会破坏卷积核与输出通道的相互作用,但各项评价指标仍能保持在99.955%以上;DSC-CBAM 模型收敛速度慢于CNN 模型,除参数量略增大外,其他各项评价指标均优于上述模型,表明采用CBAM 校正特征权重可极大提升模型识别性能;MDC 模型收敛速度进一步加快,各项评价指标显著提升至99.970%以上;MDCM 模型收敛速度最快,准确率、召回率、精确率与F1-score 指标均最优,高达99.975%以上,而参数增加量几乎可忽略不计。
2.5 模型对比
为验证本文所提设备识别模型的优越性,在UNSW 数据集上与文献[6]、文献[10]、文献[11]、文献[34]中所提模型进行对比,结果见表4。
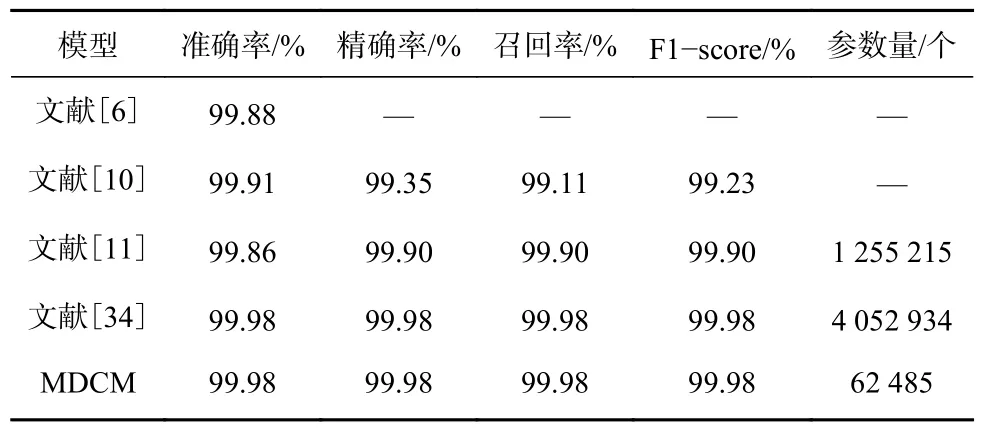
表4 不同模型对比实验结果Table 4 Comparison of experimental results of different models
从表4 可看出,文献[6]构建ML 模型识别设备类型,准确率达99.88%,但人工手动提取流量特征耗费人力物力,成本较高,不适用于大规模IIoT 数据处理;文献[10]将流量截取2 500 byte 长度,采用CNN+双向LSTM 提取设备时间与空间特征,识别准确率高达99.91%,但流量截取字节长度过长,且模型复杂度过高,难以部署;文献[11]仅将流量数据切分至应用层,忽略了数据包OSI 模型其他层特征信息,识别结果不够精确,且模型参数量较多;文献[34]采用128 个5×5 与64 个3×3 大小的卷积核提取流量特征,虽达到最高识别精度,但模型参数量最大;本文所提MDCM 模型准确率、精确率、召回率与F1-score 指标均达到最优,且参数量最小。
3 结论
1)提出了一种煤矿IIoT 设备识别模型:将网络接口处采集的原始流量切分为多个子流集合,获取更丰富的设备通信流量行为特征;在此基础上通过DSC-CBAM 模型过滤Non-IIoT 设备,降低煤矿生产流量数据复杂度;使用WGAN-GP 模型对流量较少的IIoT 设备进行数据扩充,平衡偏移流量数据;将平衡后的数据输入MDCM 模型,实现煤矿IIoT 设备精准识别。
2)实验结果表明,该模型收敛速度快,准确率、召回率、精确率与F1-score 指标均最优,高达99.98%,且参数量最小,能精准、高效识别煤矿IIoT 设备。
3)但该模型仅提取、分析设备流量的空间特征,下一步工作将考虑提取流量时序特征,以实现更精确的设备识别。
