基于超分辨率重建的低分辨率人脸识别
2024-04-16李一洋
赵 骁,陈 勇,李一洋
(北方自动控制技术研究所,太原 030006)
0 引言
人脸识别技术在单兵领域有着广泛的应用,其重要性不言而喻。通过人脸识别技术进行敌我识别,可以获取关键的战术信息,辅助指挥员作出重要决策,实现对战场态势的实时把控。单兵作战时,往往面临着复杂的作战环境,这就导致应用于单兵作战的人脸识别也受到了恶劣环境的影响。在复杂的环境中,采集到的人脸图像往往会存在着低画质、低分辨率的问题。这种情况下,人脸识别的精度受到了很大的影响。
军事场景中,提高低分辨率人脸识别的准确率具有重要意义。随着科技的不断发展,军事情报的收集和作战行动都越来越多地依赖于人脸识别的技术。然而,实际应用中,由于各种条件的限制,低分辨率人脸识别率往往较低,这给军事情报的收集和作战行动带来了诸多困难和挑战。
提高低分辨率人脸识别的准确率,可以帮助军方更加准确地识别敌我双方的人员。在军事情报收集中,敌方人员的身份识别是至关重要的,而敌方往往会采取各种手段来限制情报的获取,其中,包括了对人脸图像进行故意模糊化处理。如果能够提高对低分辨率人脸的识别率,就能够更好地识别敌方人员的身份,为军事情报的收集提供更加准确的数据支持。其次,提高低分辨率人脸识别的准确率可以帮助军方更好地进行目标追踪和监视。在作战行动中,军方往往需要对目标进行追踪和监视,而目标往往会采取各种手段来隐藏身份和行踪。如果能够提高对低分辨率人脸的识别准确率,就能够更好地对目标进行追踪和监视,为作战行动提供更加准确的情报支持。此外,提高低分辨率人脸识别的准确率,还可以帮助军方更好地进行反恐作战和打击犯罪活动。提高军事场景中低分辨率人脸识别的准确率具有非常重大的意义。不仅可以帮助军方更好地进行情报收集、作战行动、反恐作战、打击犯罪活动、边境管控和入境检查,还可以提高国家安全的整体水平。因此,军事科研机构和企业应该加大对低分辨率人脸识别技术的研发投入,不断提高其准确率和可靠性,为军事情报收集和作战行动提供更加强大的技术支持。
由于现实生活中摄像头分辨率的限制或者图像传输过程中的损失,导致获取的人脸图像分辨率较低。低分辨率图像可能会影响人脸识别系统的准确性和性能。因此,研究人员开始关注如何利用超分辨率重建技术来提高人脸图像的质量,从而改善人脸识别的效果。本文的研究内容如图1 所示,利用人脸超分辨率重建技术对低分辨率人脸进行处理。对人脸进行超分辨率重建可以提高识别的准确性,通过提高人脸图像的分辨率和清晰度,可以提高人脸识别系统的准确性和鲁棒性,从而降低误识率;增强细节信息,高分辨率图像能够提供更多的细节信息,有助于更准确地捕捉人脸的特征,提高识别的精确度;改善图像质量,通过超分辨率重建技术,可以改善低分辨率图像的质量,使得图像更加清晰自然,提高用户体验。

图1 研究内容Fig.1 Research contents
超分辨率重建在人脸识别领域的研究主要包括以下几个方面:
基于深度学习的超分辨率重建算法:研究人员正在开发深度卷积神经网络,通过开发深度卷积神经网络来实现超分辨率人脸图像重建,从而研究低分辨率和高分辨率图像之间的关系[1]。结合生成对抗网络的超分辨率重建算法:利用生成对抗网络(GAN)的思想,设计可以生成高质量人脸图像的超分辨率重建模型。融合图像修复和超分辨率重建技术结合图像修复技术,对低分辨率图像中的噪声和失真进行修复,然后再进行超分辨率重建,以提高人脸图像的质量。
超分辨率重建在人脸识别领域的研究仍在不断深入,未来有望通过更加精确的超分辨率重建技术来提高人脸识别系统的性能和效果。
1 超分辨率重建
1.1 方法介绍
超分辨率重建是一种通过使用计算机算法来提高图像或视频分辨率的技术[2]。它可以通过增加像素数量或者利用图像中的信息,来提高图像的清晰度和细节。这种技术在图像处理、视频处理和计算机视觉领域得到了广泛的应用,可以用于提高低分辨率图像的质量,增强图像的细节和清晰度。超分辨率重建的方法包括插值法、深度学习和图像修复等。超分辨率重建在人脸识别领域中的应用非常广泛,其中,基于深度学习的超分辨率重建算法被广泛采用。目前有两种应用较为广泛的算法,SRCNN(super-resolution convolutional neural network)算法:是一种基于卷积神经网络的超分辨率重建算法,其主要思想是利用多层卷积神经网络研究低分辨率和高分辨率图像之间的关系[3]。SRCNN 算法在训练过程中使用了大量的高分辨率图像和对应的低分辨率图像,通过不断迭代优化网络参数,最终可以得到一个能够将低分辨率图像转换为高分辨率图像的模型[4]。在人脸识别领域,SRCNN 算法可以用于将低分辨率的人脸图像转换为高分辨率的图像,从而提高人脸识别的准确率。SRGAN(super-resolution generative adversarial network)算法:是一种基于生成对抗网络的超分辨率重建算法,其主要思想是通过两个神经网络相互博弈来实现图像的超分辨率重建[5]。其中,一个神经网络(生成器)用于将低分辨率图像转换为高分辨率图像,另一个神经网络(判别器)用于判断生成器生成的图像是否与真实的高分辨率图像相似。在训练过程中,生成器和判别器不断交替进行迭代,最终生成一个能够将低分辨率图像转换为高分辨率图像的模型。在人脸识别的领域,SRGAN 算法可以用于增加低分辨率人脸图片的细节,从而使得低分辨率人脸在识别过程能够更加容易地被识别出来[6]。如今,广泛使用的人脸识别算法往往侧重于高质量的人脸捕捉,而对于在复杂作战场景中拍摄的低质量人像,如果在不经过处理的条件下直接进行识别,识别率往往会大打折扣。因此,在真实的作战场景中,获取的低分辨率人脸图像如何实现精准的识别,成为了亟待解决的难点。目前,对于低分辨率人脸识别常用的方法有以下4 种:超分辨率重建的方法、提取低分辨率图像特征的方法、模糊矫正的方法以及统一特征空间的方法[7]。
在现有的方法中,超分辨率重建是比较有效且可行性强的一种方案。人脸超分辨重建(face superresolution reconstruction)属于超分辨率重建的一个部分,对此人们已经做了许多相关的学习与研究。虽然图像的视觉效果与识别率在理论上并不冲突,但在一些研究中发现,重建后图像的视觉效果与实验中指标的表现并不完全一致。然而,现有的大部分算法侧重于研究人脸重建后的视觉效果,而没有将重建后的模型应用于人脸识别的相关工作中。本文引入识别过程,关注重建模型是否能使低分辨率人脸的识别率得到明显提升。
1.2 算法原理
本文提出了图像超分辨率重建算法SRR,核心思想是利用深度学习和生成对抗网络,来学习并重建高分辨率图像,从而在保持图像细节的同时提高图像的清晰度和真实感。SRR 算法的结构如图2 所示。SRR 算法的原理可以分为两个主要部分:生成器和判别器。生成器负责将低分辨率的输入图像转换为高分辨率的输出图像,而判别器则负责评估生成器生成的图像是否真实。
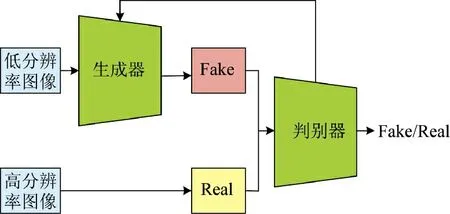
图2 SRR 算法结构Fig.2 Structure of SRR algorithm
SRR 的生成器是基于深度卷积神经网络(CNN)的结构,如图3 所示,它由多个卷积层、反卷积层和残差连接组成。生成器的主要任务是将低分辨率的输入图像转换为高分辨率的输出图像,同时尽可能保留图像的细节和纹理。为了实现这一目标,SRR 采用了残差学习的思想,即通过残差连接将输入图像的细节信息直接传递到输出图像中,从而减少信息丢失和模糊现象。在SRR 的生成器中,首先通过多个卷积层对输入图像进行特征提取和抽象表示,然后通过反卷积层逐步将特征图放大到目标的分辨率。在这个过程中,生成器通过多层的残差连接来学习和保留图像的细节信息,从而使得输出图像更加清晰和真实。此外,为了进一步提高图像的质量,SRR还引入了像素对齐和通道注意力机制,以增强对细节和纹理的学习能力,并减少图像的伪影和失真。
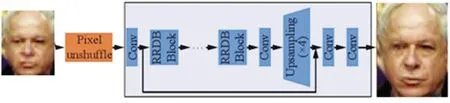
图3 生成器的结构Fig.3 Structure of generator
SRR 的判别器是一个基于CNN 的二分类器,它的主要任务是评估生成器生成的图像是否真实。判别器的输入是高分辨率的真实图像和生成器生成的高分辨率图像,输出则是一个二元值,表示输入图像是真实图像的概率。通过对生成器生成的图像进行评估和反馈,判别器可以指导生成器学习和改进,从而提高图像的真实感和质量。在SRR 的判别器中,通过多个卷积层和池化层对输入图像进行特征提取和抽象表示,然后通过全连接层将特征图映射到二元值输出。判别器通过不断训练和学习,逐渐提高对真实图像和生成图像的识别能力,从而使得生成器生成的图像更加真实和逼真。
SRR 的训练过程是一个基于对抗学习的过程,即生成器和判别器之间的博弈过程。在训练过程中,生成器通过最小化判别器的损失来提高生成图像的真实感,而判别器则通过最大化真实图像和生成图像的差异来指导生成器的学习和改进。通过不断的对抗学习和优化,生成器和判别器可以逐渐达到动态平衡,从而提高图像的超分辨率重建质量和真实感。
2 实验结果及分析
2.1 图像超分辨率重构的评价指标
超高分辨率重建研究的结果的评估通常基于峰值信噪比(PSNR)和结构相似性(SSIM)两个指标,它们可以较为客观地评价重建后图像的质量[8]。峰值信噪比(PSNR)是评估两幅图像相似度的一种指标,通过两幅图像的像素均方误差计算得出。对于两幅相同尺寸的图像P 和Q,PSNR 的计算公式如下:
其中,m,n 分别代表了图像的长度和宽度,MAXI代表了图像颜色点的最大值,每个采样点都使用8 bit的图像,MAXI=225。
结构相似性(SSIM)是一种用于评估图像质量的指标,它考虑了亮度、对比度和结构3 个方面的相似性。SSIM 指数是一种全参考的图像质量评价指标,即需要有原始图像作为参考来计算图像的相似性。SSIM 指数的计算方法基于以下3 个因素:亮度相似性,表示图像的亮度信息的相似程度,即图像的平均亮度和对比度;对比度相似性,表示图像的对比度信息的相似程度,即图像的对比度变化;结构相似性,表示图像的结构信息的相似程度,即图像的结构变化。
对于两幅尺寸一致的图像P 与Q 来说,亮度对比函数、对比度对比函数,以及结构对比函数分别定义如下:
2.2 超分辨率重建实验
本文的训练数据集采用CASIA-WebFace 数据集,测试数据集采用LFW 数据集。CASIA-WebFace数据集中一共包括了494 414 幅图像,其中,包含了10 575 个人[9-10]。在人脸识别的方向,LFW 数据集属于常用的数据集之一,其包含了5 729 人的13 233张图像,创立之初一定程度上解决了非限制的人脸识别问题。LFW 数据集中的图像含有更丰富的变量,其中,包括了光的亮度以及人脸的面部表情等,在之前的研究中,人脸数据集通常是在相对固定的实验环境中采集志愿者的人脸图像得到的。现实情况中,人脸识别更加需要非限制性的条件。本节首先使用PSNR 和SSIM 测试模型重建效果,并与常用的一些重建方法进行了比较。
实验中选取的对比方法包括WaveletNet,SRGAN,VDSR,SICNN,EDSR,SRFBN。利用相同的训练集对选取的方法进行训练,来测试每个模型对于低分辨率人脸图像的重建效果,结果如下页表1 所示。可以看出,SRR 模型的实验结果在SSIM 指标中有较好的表现,而在PSNR 指标中相比其他方法更为领先。
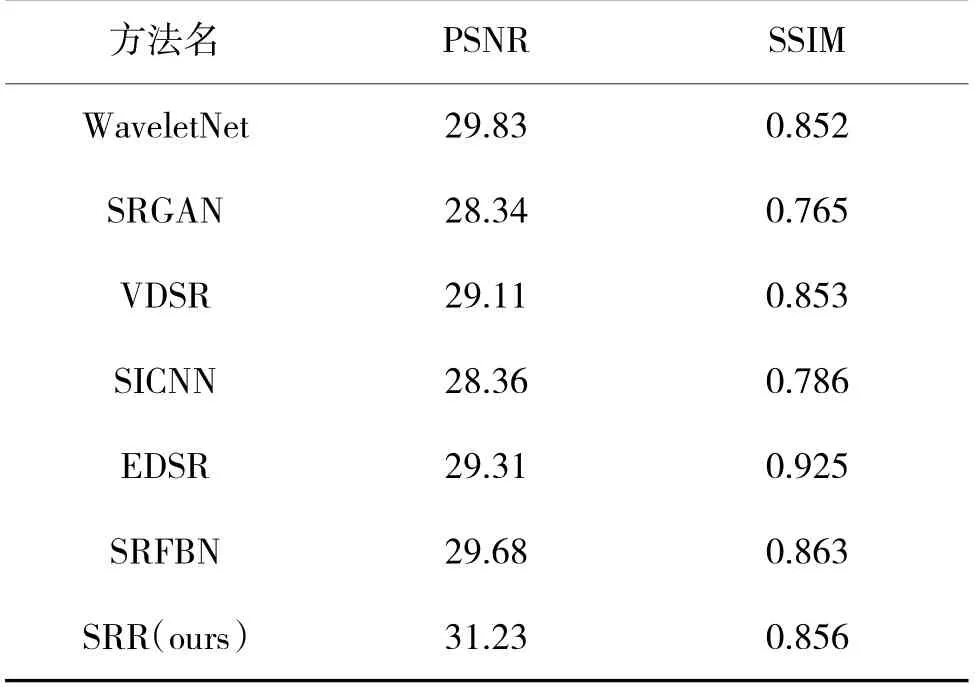
表1 超分辨率重建测试Table 1 Super-resolution reconstruction testing
表1 展示了SRR 模型在超分辨率重建的两个指标中的成果,下页图4 则更为清晰地展现了模型对于低分辨率图片的处理效果。如图4 所示,图4 包含了两行图像,其中,第1 行是未处理的低分辨率人脸图像,而第2 行则是经过SRR 模型处理后得到的较为清晰的人脸图像,可以看出,低分辨率人脸图像经过处理后可以获得清晰的、更便于识别的人脸图像。

图4 模型效果展示Fig.4 Demonstration of model effects
文中提到的PSNR 与SSIM 两个指标都是误差敏感的评价指标,它们主要用来描述图片重建后的视觉效果。而很多研究都已表明,基于误差敏感的评价指标与人眼对于图片的评判并不完全一致。主要原因是人眼对于图片的评判系统是一个非常复杂的系统,具有非线性的特征。现有的研究中,还未能发现与人眼的评价完全一致的图像质量的评价指标。文中主要评述了SRR 模型对于低分辨率人脸的重建效果,为了解决根本的人脸识别问题,验证模型对于人脸识别率的提高效果,需要对重建后的图像进行人脸识别准确率的测试。
LFW 数据集广泛地应用于人脸识别的领域,是一个经典的测试数据集,在人脸识别的测试任务中有一个标准的协议。本文利用LFW 数据集来进行各个模型的人脸识别测试,判别各个模型能否提高低分辨率人脸识别的精度。对比实验的结果如表2所示,可以看出,SRR 模型测试的结果优于大部分的对比模型。
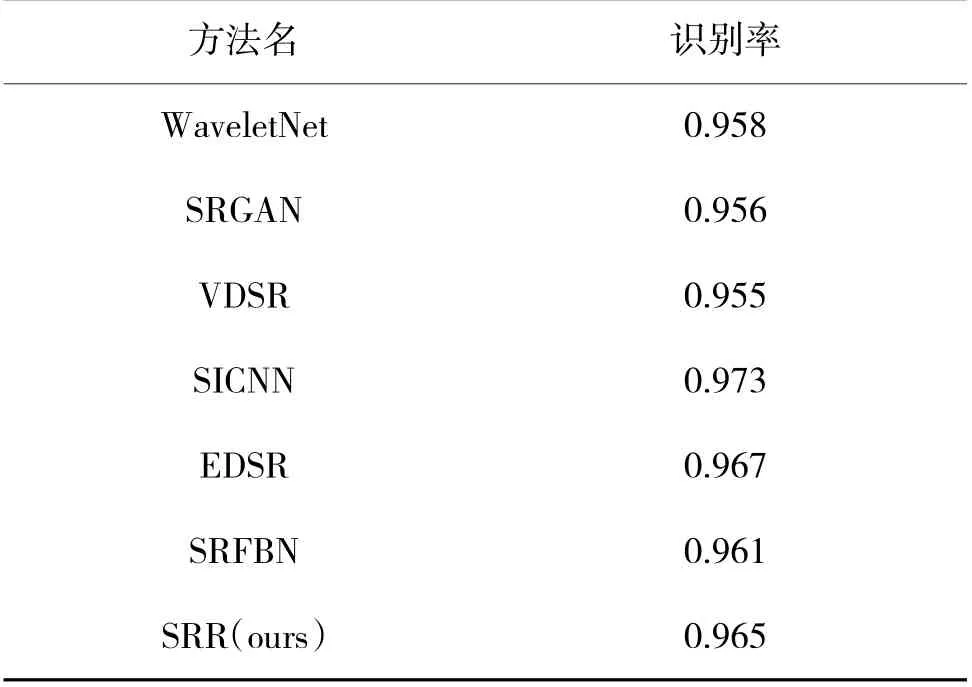
表2 LFW 数据集下的对比实验Table 2 Comparison experiment under LFW data set
3 结论
实际应用的人脸识别研究过程中,低分辨率人脸识别是一个必须要面对的问题。通常只有在实验室等一些苛刻的场景中,才能直接使用高分辨率的图像进行人脸识别。而在复杂的作战场景中,高分辨率的图像难以获取,必须对低分辨率的人脸图像进行处理,来提高实际作战中人脸识别的精度。本文采用超分辨率重建的方法,构建SRR 模型,有效提高低分辨率人脸识别的准确性,最终得到的结果在视觉效果上有良好的表现,一定程度上也提高了低分辨率人脸识别的准确性。
无人机、监控系统等侦察系统在发现和识别目标后,目标信息和坐标就在整个作战平台进行共享。之后,所有情报都会汇入大数据系统进行算法分析,在人工智能系统协助下得出最佳解决方案。最终,对侦察定位的敌方目标进行打击,无人机还会对毁伤效果进行拍摄。通过提高在复杂作战环境下低分辨率人脸识别的精度,可以有效地提高战术末端作战效能。利用较高精度的人脸识别,可以实现对战场中敌军目标的精准识别,给予指挥员关键目标信息,获取敌兵力部署情况、作战意图等重要信息,辅助实现斩首行动、无人机侦察、智能导弹定位打击等一系列军事行动,有效提高我军的战场主动权以及综合实力。
