基于跨通道融合与注意力机制的轻量化目标检测模型*
2024-04-16曹瑞颖赵志诚谢新林
曹瑞颖,赵志诚,谢新林,刘 宁
(1.太原科技大学电子信息工程学院,太原 030024;2.山西省信息产业技术研究院有限公司,太原 030012)
0 引言
目标检测技术在交通、工业和军事领域一直有广泛的需求,例如自动驾驶、移动机器人视觉处理和大数据监控等场景[1-2]。但是模型复杂度高极大地限制了算法部署,因此,如何平衡精度和模型参数量成为一个重要的研究方向。早期的目标检测使用传统图像处理方法,多在支持向量机(support vector machine,SVM)和方向梯度直方图(histogram of oriented gradient,HOG)的基础上改进,易于部署,但面对小目标和复杂背景难以达到良好的效果检测。文献[3]首先对图像进行去噪、形态学处理等预处理操作后,对二值图像进行分析法特征提取,再利用灰狼算法优化后的SVM 分类器识别图像。该过程需要进行大量的数据预处理,识别速率慢,不满足实时性要求。
近十年来,由于计算机视觉发展迅速,研究人员将目光放在融合数字信息处理、计算机视觉和人工智能为一体的目标检测算法上[4]。基于深度学习的识别方式一般可分为两类:基于回归的一阶段方式和基于区域候选的二阶段方式。其中,二阶段算法被较早地提出,最具代表性的有R-CNN(re gion-conventional neural network)、Fast R-CNN、Faster R-CNN 和Mask R-CNN[5-8]。该类算法将回归和分类任务分开进行,需要提前产生区域候选框,精度较高但检测速度慢,难以满足实时性要求。而一阶段算法跳过区域候选,直接得到目标的位置概率和坐标值,有着较快的检测速度,容易训练,因此,更适合移动端的部署。代表算法如YOLO(you only look once)系列和SSD(single shot multi-box detector)[9-10]。
近年来,目标检测算法更加关注功能模块的使用[11],在增加少量推理成本的基础上优化模型结构。文献[12]使用深度摄像头进行障碍物检测和工件检测。首先采用超宽带(ultra wide band,UWB)将自动导引车导航到工作位置附近,将基于TensorFlow框架的改进YOLOv3 模型与深度摄像机应用程序界面相结合,得到目标的位置,从而建立一种高精度的自定位方法。文献[13]将研究重点放在了重叠物体上,配备EMD Loss(earth mover’s distance loss)和非极大值抑制等技术,该检测器更适用于复杂背景下多物体重叠的情况,尤其大物体更容易重叠的情况,但实验不能反映对小物体的检测效果。文献[14]提出广义焦点损失函数(generalized focal loss),通过对损失函数的修改,将焦点损失从离散形式推广到连续版本,实现损失函数的优化,但模型参数量并未减小,不适合移动端的部署。综上所述,一阶段YOLO 系列的检测速度还有待提高,通过模型的轻量化,在不影响小目标和遮挡问题的情况下优化模型。
因此,针对以上不足,本文提出一种基于YOLOv4 的跳跃连接扩尺度特征融合模型,主要贡献如下:首先,原YOLOv4 的主干网络采用CSPDarkNet53,模型参数量大。为了提升检测速度,本文利用MobileNet 模块改造主干特征,提取网络命名为MV1,同时借鉴MobileNet 骨架的思想,重新构建网络中所有3 次卷积块和5 次卷积块,提出一种基于深度可分离卷积的轻量化目标检测模型,实验结果表明整体参数量降低了80.8%。其次,模型压缩很可能导致精度下降,为了提升网络的检测能力,在网络的颈部构建了跨通道跳跃连接特征融合结构。一方面将原来的3 尺度改为4 尺度,额外融合一层浅层信息,相应的上采样、下采样环节也增加一次;另一方面增加两层跨通道路径融合深浅层信息,以此提高模型识别多尺度目标的性能。最后为了进一步提升改进算法应对复杂背景和小目标的特征提取能力,引入ECA 注意力机制,通过实验证明ECA的提取能力要优于CBAM、SE 和CA 机制,算法更关注图像中的目标信息。
1 相关背景
1.1 YOLOv4 目标检测算法
YOLOv4 网络是Alexey Bochkovskiy 等提出的典型一阶段目标检测算法[15],在原有YOLOv3 的基础上,从骨干网络架构、激活函数、损失函数和训练方式等方面进行优化[16]。运行速度明显加快,但并没有给网络带来太多计算量,精度也有一定提升,在速度和精度的平衡上表现良好。YOLOv4 的网络结构大致可分为4 个部分:输入端、主干Backbone、颈部Neck 和输出端(预测端Prediction),图像分成不同尺度的网格进行特征提取,通过回归预测框实现目标的位置定位和分类。YOLOv4 最大的贡献在于构建了一个高效的目标检测模型,降低了训练门槛,使普通研究人员也可以用1080Ti 或2080Ti 的GPU 来训练模型,推动了目标检测算法的进步。
1.2 深度可分离卷积
深度可分离卷积(depthwise separable convolution,DSC)是由CHOLLET 等提出的一种卷积块[17],被人们熟知主要是因为两个著名模型Xception 和MobileNet[18],在这两个模型结构中均起到关键作用。DSC 由逐通道卷积(depthwise convolution)和逐点卷积(pointwise convolution)两部分构成,在保留卷积操作的基本表征学习能力的同时减少权重系数的个数,相比普通卷积,运算量和运算成本要小很多。卷积主要是用来提取特征,普通的卷积会实现通道和空间的联合关系,而DSC 则先执行空间方向的卷积,保持通道分离的状态,随后进行1*1 的逐点卷积。
若对于某个卷积层而言,输入的张量深度为Cin,输出的张量深度为Cout,则对于高宽为h、w 的卷积来说,逐通道卷积后的尺寸为h*w*Cin,接着用尺寸为1*1*Cin*Cout的卷积核进行逐点卷积,卷积步长Stride 为1,则深度可分离卷积的参数量为:
同样的卷积核大小采用标准卷积的参数量为:
因此,两者的参数量比值为:
2 改进的轻量化目标检测模型
2.1 整体结构
改进后的整体网络结构如图1 所示,y1~y4分别为4 尺度特征提取的输出端。CBL 模块为YOLOv4的基本模块,由标准卷积层(CONV)、批量标准化层(Batch_Normalization)和ReLU 激活函数组成。全程使用Concat 向量拼接操作,将MobileNet 模块的中间层和深层网络的上采样特征向量进行拼接,下采样得到的特征向量与深层特征向量同样使用Concat堆叠。图像尺寸固定为416*416,输入Backbone 先经过普通卷积CBR,由标准卷积层(CONV)、批量标准化层(Batch_Normalization)和ReLU6 激活函数组成。改良后的MobileNet 模块MV1 其基本组件是DW 深度可分离卷积,由3×3 逐通道卷积和1×1逐点卷积组成,步长stride 为1、2 交替连接。借鉴MobileNet 的思想,在原来YOLOv4 的基础上,将所有3*3 卷积块和5*5 卷积块改造成含DW 卷积的“夹心”形式,如下页图2 所示,将3*3 卷积的第2层替换为DW 卷积,命名为CDC 模块;将5*5 卷积的第2、4 层替换为DW 卷积,命名为CDCDC 模块。下采样是卷积核为3 的普通卷积CBL。
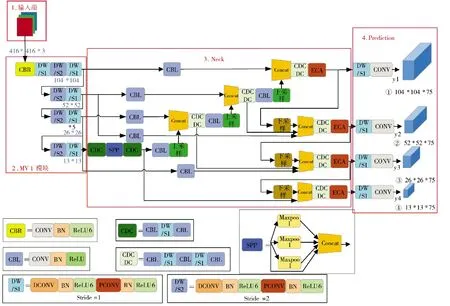
图1 改进后的整体结构Fig.1 Improved overall structure
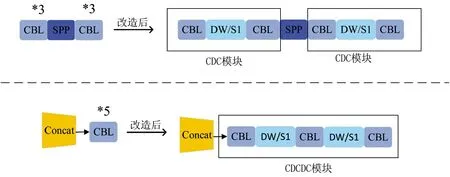
图2 改造3*3 卷积块和5*5 卷积块Fig.2 Transformed 3*3 convolution block and 5*5 convolution block
2.2 MV1 模块构建的主干特征提取网络
虽然YOLOv4 在精度和速度上都达到一个很好的平衡,但不适用于算力有限的移动端部署,所以本文借鉴MobileNet 的思想设计了新的主干网络来压缩模型,命名为MV1。MobileNet 模块是Google 团队提出的轻量级深度神经网络,它的核心思想是深度可分离卷积,这一改进有效地减少了模型参数量,便于移动设备或嵌入式设备的算法快速部署和实时运行。
本文算法设计了一种基于深度可分离卷积的主干特征提取网络,不同于原MobileNet 结构,第1层设置一个步长为2 的普通卷积,中间层去掉普通卷积,只保留DW 卷积,尾端使用自适应平均池化(adaptive avg pool)和一个全连接层(linear)。最后为了配合颈部的扩尺度改造,MobileNet 模块的Stage层需要加一,保持原本的模型深度不变。如图3 所示,基础卷积conv_bn 即CBL 模块,conv_dw 即深度可分离卷积块DW。实验结果表明这一改进有效降低了网络参数量,但精度会有所下降,在后续的加强特征提取部分弥补。
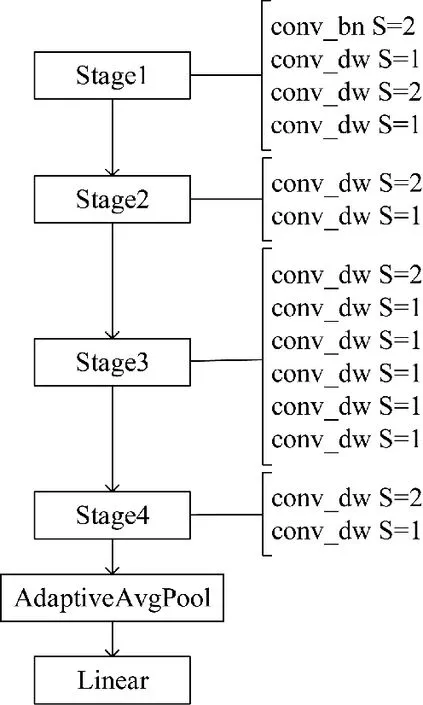
图3 MV1 模块的结构示意图Fig.3 Structure schematic diagram of MV1 module
2.3 Neck 部分的多尺度特征提取
在实际场景中,为了满足不同大小物体的检测需求,往往需要获取不同的尺度特征。一般来说,大目标在图片中所占面积大,特征较为丰富,所以检测较为简单。但小目标在图中所含特征信息较少,经过Backbone 的不断特征提取,导致特征图丢失信息严重,检测难度增大。为了解决小目标物体的检测难题,通过利用较大特征图的输出特征获得较小的感受野,来提高物体检测能力。本文算法正是在原有Neck 的基础上,增加一浅层特征图,如图4 的蓝色部分所示,3 尺度扩展成4 尺度,同时配备卷积和上采样层。在输入图像尺寸416*416 的前提下,得到4 种检测分支分别为13*13,26*26,52*52,104*104,并将52*52 的特征层2 倍上采样与新添加的104*104 层堆叠,104*104 的输出特征下采样与52*52 层特征进行堆叠,以此来充分利用浅层特征信息。
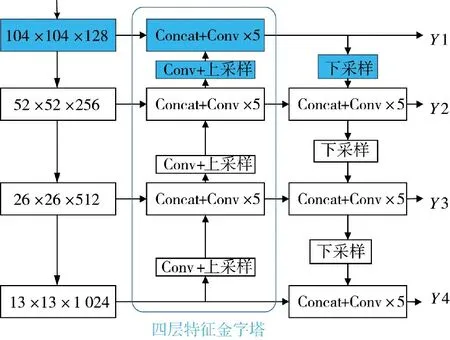
图4 3 尺度扩展为4 尺度的Neck 结构示意图Fig.4 Schematic diagram of Neck structure with 3 scales expanded to 4 scales
此外在PANet 结构中,下采样的输入端是经过FPN 特征金字塔处理的信息,缺少原始主干特征信息,影响检测精度。所以本文借鉴加权特征金字塔网络(BiFPN)的思想[19],在特征传递过程中增加两层普通卷积,改进的网络结构如下页图5 的红色部分所示,将Backbone 获得的原始信息跨层输出,与4 层特征金字塔得到的特征堆叠,使原始信息持续参与特征提取过程。为了匹配额外增加的路径通道数,需要一个普通1*1 卷积调整通道数。
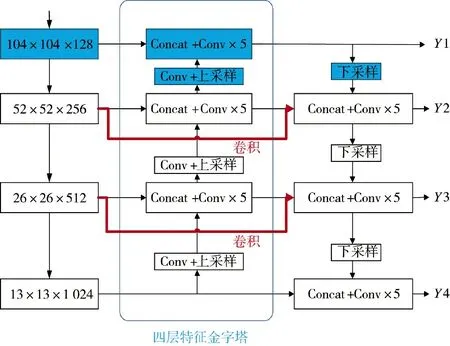
图5 Neck 的最终改进示意图Fig.5 Schematic diagram of final improvement of Neck
2.4 融合ECA 通道注意力机制
近年来,由于注意力机制具有可操作性强,有效聚焦关键信息和自适应调整权重的优良特性,融合注意力机制在改善深度卷积神经网络的结构上展现了很大的潜能。本文为了进一步提升算法的特征提取能力,在Neck 加强特征提取部位的最后,即YOLOv4 网络的预测端之前,将参数量很小的ECA模块插在4 层尺度中,不仅能有效增强模型的性能,同时对模型大小的影响几乎可以忽略不计。
ECA 注意力机制把重点放在跨信道交互上,避免一味地降维压缩影响学习通道间的依赖关系[20],结构如图6 所示,H、W 表示通道的高宽。首先在输入特征图上进行空间特征压缩,使用全局平均池化得到1*1*C 的特征图,随后用动态卷积核1*1 卷积自适应学习通道特征,并经过Sigmoid 激活函数处理得到各通道的权重系数,将权重与原始输入图像的对应元素相乘即可得到最终输出特征。其中,自适应卷积核的计算公式为:
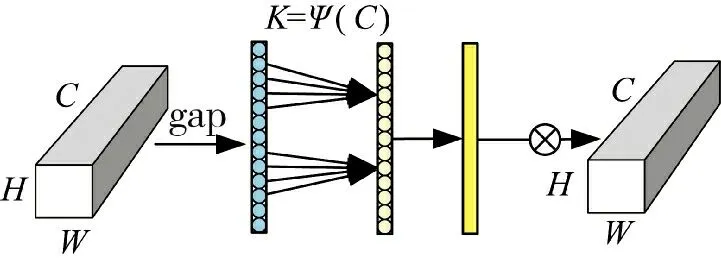
图6 ECA 模块示意图Fig.6 Schematic diagram of ECA module
式中,γ=2,b=1,C 是通道数。
3 实验设计和结果分析
3.1 数据集
为了验证本文改进的目标检测算法能否满足复杂背景下的检测,采用Pascal VOC 07+12 数据集进行实验研究。Pascal VOC 数据集是目标检测领域最常用的标准数据集之一,很多优秀的计算机视觉模型如分类、定位、检测、分割和动作识别都基于Pascal VOC 挑战赛及其提供的数据集推出。本文选择的数据集是Pascal VOC 2007 和Pascal VOC 2012,包含了日常生活场景中最常见的20 个类别。本文将两组数据集整合得到21 503 张图片,划分情况如下:训练和验证占全部数据集的90%,共19 352 张,在此基础上训练集占90%,共17 416 张,测试占10%,共2 151 张。20 个类别所含目标信息如图7 所示。

图7 Pascal VOC 07+12 数据集的数据分布情况Fig.7 Data distribution status of datasets of Pascal VOC 07+12
3.2 实验平台与环境配置
本文全部实验结果都是基于深度学习框架Pytorch 进行的,实验环境配置如下:操作系统为Linux,GPU 为GeForce RTX 2080 Ti,16 核处理器,内存为64 GB,网络镜像为torch 1.2.0、torchvision0.4.0,数据处理为Python 3.7,GPU 加速软件为CUDA10.1、CUDNN10.1.105。
3.3 训练过程
在深度学习的训练过程中,从0 开始初始权重过于随机往往效果不好,且耗费大量时间成本。为了节约计算机资源,采用迁移学习策略,利用多次迭代获得的初始权重进行训练,提高模型的泛化能力。图片输入尺寸为416*416,将训练过程分为冻结和解冻阶段,共训练100 轮,前50 轮冻结主干特征提取网络所占显存较小,批次设置为16,随后解冻训练,批次缩小为8。模型最大学习率1e-2,最小学习率1e-4,使用余弦退火方式调整,选择SGD 优化器。由于输出特征图变成4 尺度,先验框的尺寸和数量要与之对应,使用K-Means 聚类的方式得到4尺度共12 个Anchor Box[21],聚类结果如表1 所示,该方法获得的先验框更接近数据集。

表1 K-Means 聚类结果Table 1 K-Means clustering results
3.4 评价指标
评价指标用来衡量算法检测的好坏,本文主要用到IoU(交并比)、precision(精确度)、recall(召回率)、AP(平均精度)、mAP(平均类别精度),具体计算方式如下:
其中,TP 表示预测为正样本且实际为正样本的数量,FP 表示预测为负样本但实际为正样本的数量,FN 表示预测为负样本实际也是负样本的数量,precision 为单类别的检测精度,recall 为召回率,即全部预测正样本里正确结果占的比率,N 表示检测目标的类别数为20,FrameNum 表示处理的图像数量,ElapsedTime 表示处理图像消耗的时间。此外,检测时非极大值抑制设置的iou 为0.5,置信度Confidence 为0.001,只有得分大于置信度的预测框才会被保留。
3.5 结果分析
3.5.1 改造主干特征提取网络的实验验证
为了选取最合适的主干替换网络,验证MV1 模块的合理性,本文以YOLOv4 原始网络为基础,选取常见的轻量化网络GhostNet、MobileNetv1(改造后的MV1 模块)、MobileNetv2、MobileNetv3、DenseNet 121、ResNet50、VGG 替换YOLOv4 的Backbone,包含数据增强等预处理环节,同时调整所有3*3 卷积为DW 卷积,其他部分不变。改动后的算法分别称为YOLOv4-G、YOLOv4-MV1、YOLOv4-MV2、YOLOv4-MV3、YOLOv4-D121、YOLOv4-R50、YOLOv4-VGG,将以上7 种算法与YOLOv4 在Pascal VOC 07+12 上进行对比实验,实验结果如表2 所示。

表2 替换Backbone 的实验结果Table 2 Experimental results of replacing Backbone
从表2 可以看出,GhostNet 和MobileNet 系列在参数量的降低方面都达到80%以上,表现优异。要移动端的使用需要得到尽可能大的FPS,即每秒传输帧数(Frames Per Second),视频流畅度越好,所以表现最好的是MobileNet 模块,同时还兼顾最高的精度,与YOLOv4 原算法的mAP 相比只差0.51%。从算法检测精度来说,蓝色字体标注的算法是精度最高的前3 种,最优的替换网络是YOLOv4-MV1 和YOLOv4-R50,后者精度更高甚至超越YOLOv4,但模型大小只降低了一半,而MobileNetv1 降低了80.7%。所以综合来看YOLOv4-MV1 在Pascal VOC 07+12 表现最好,本文采用基于MobileNet 块设计的主干特征提取网络。
3.5.2 改进Neck 部分的实验验证
为了验证Neck 部分两个创新点的合理性,首先增加1 层浅层信息,3 尺度扩展为4 尺度,称为YOLOv4-MV1-F;其次在YOLOv4-MV1-F 的基础上调整特征金字塔结构,连接主干网络与下采样结构,增强信息融合,称为YOLOv4-MV1-FB。对比结果如表3 所示。
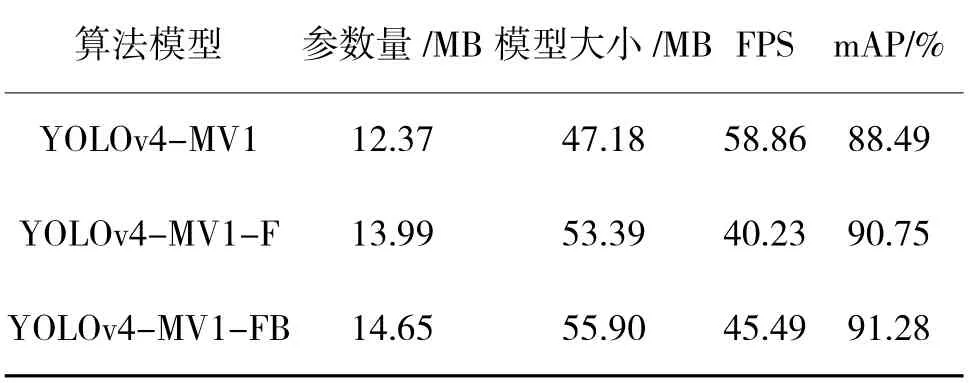
表3 改进Neck 部分的实验结果Table 3 The experimental results of improving the Neck section
从表3 可以看出,增加1 层浅层信息,并增强尺度融合都会使算法的参数量和模型大小少量增加,FPS 也有所降低,但模型的改进对算法精度分别提高了2.26%和2.79%,依然保持着较好的实时性,因此,证明了该改进方法的有效性。
3.5.3 融合注意力模块的实验分析
为了验证融合注意力机制的有效性,并探究哪种注意力模块对精度的提升效果更好,本文在YOLOv4-MV1-FB 网络的基础上设计实验,选取4种最常用的注意力机制CBAM、ECA、CA、SE 插到Neck 的最后,其他部分不做改动,实验结果如表4所示。
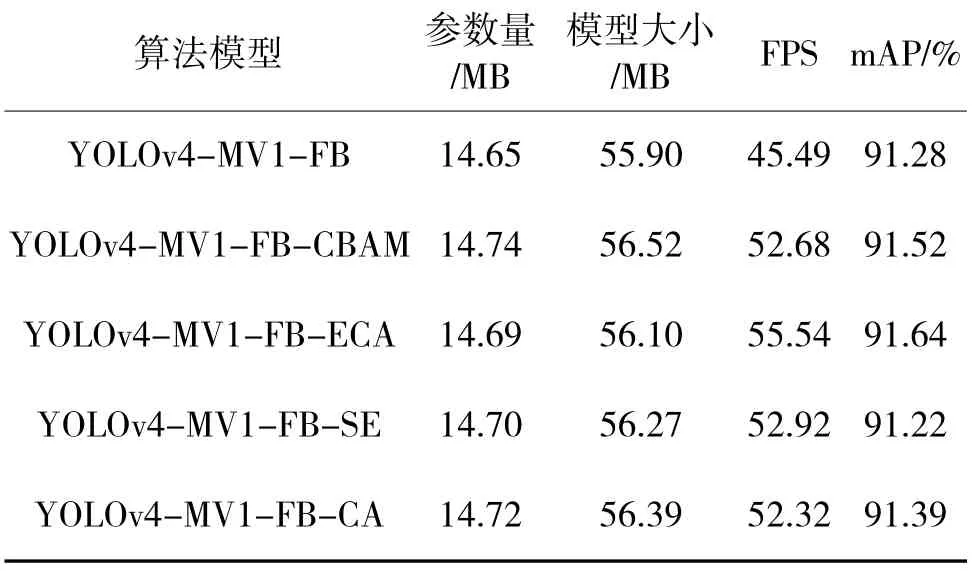
表4 融合注意力模块的实验结果Table 4 The experimental results of fusing attention module
从表4 中可以看出,在网络的检测头前分别加入4 种注意力机制带来的参数变化并不大,在参数量的增加上几乎可以忽略不计;从平均类别精度mAP 来看,ECA 表现更好,增加了0.36%;同时ECA具有更好的FPS,更能满足实时性要求。因此,本文在Neck 的最后引入ECA 注意力机制更有效,实现运行速度和精度的统一。
3.5.4 消融实验
为了更全面地分析YOLOv4-MV1-FB-ECA 中各个模块的改进效果,在YOLOv4 的基础上设计消融实验。4 种改进策略分别命名MV1(MobileNet 块构建主干特征网络,并将所有3*3 卷积换成深度可分离卷积)、F(3 尺度变4 尺度)、B(调整特征金字塔结构)、ECA(注意力机制)。在原始YOLOv4 的基础上分别加入各个模块,在Pascal VOC 07+12 数据集上进行试验,实验结果如表5 所示。
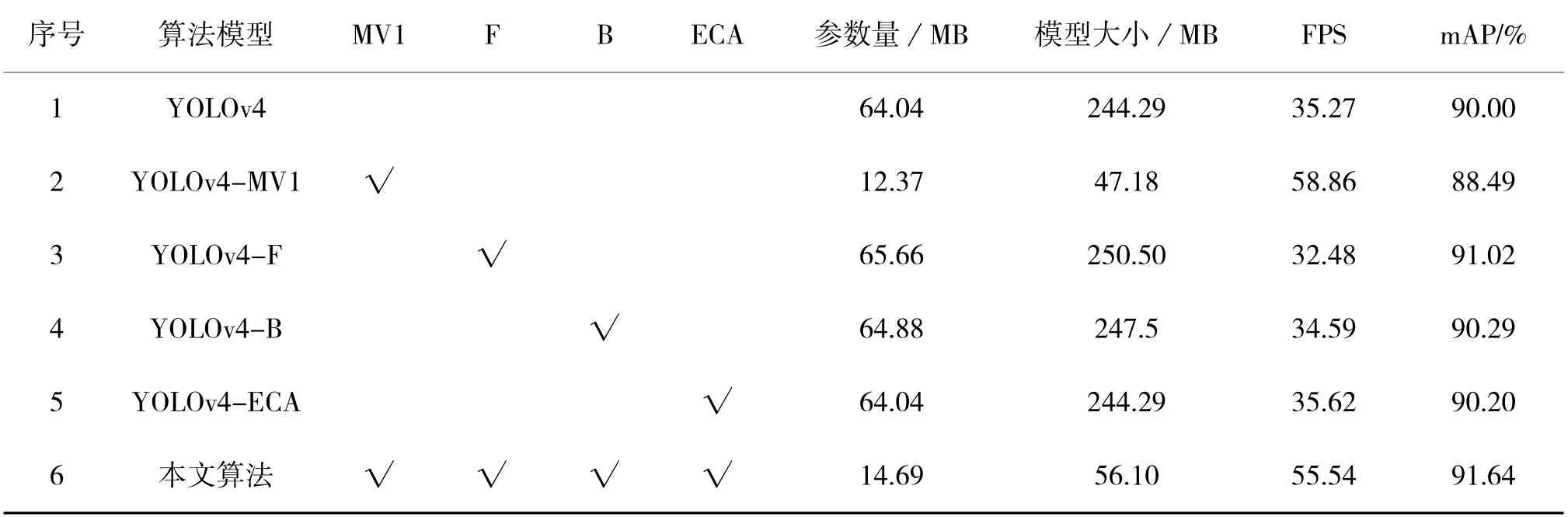
表5 消融实验结果Table 5 Results of ablation experiment
实验结果表明,引入MobileNet 块并替换DW卷积对模型参数量的影响很大,有效地提升了FPS,模型精度下降了1.51%,说明整体网络结构使用深度可分离卷积能带来积极的正效应。其他改进的3个模块中,3 尺度改为4 尺度对模型的提升效果最大,mAP 增加了1.02%,模型参数量增加了1.62 MB;模块B 的精度提升较小,模型参数量增加了0.84 MB;而注意力机制ECA 的模型参数量对YOLOv4 的数量级来说几乎为0,模型精度提升了0.20%。
3.5.5 不同网络的性能对比实验
在Pascal VOC 07+12 数据集上,对比分析目前流行的目标检测算法,除二阶段模型Faster-RCNN、SSD 输入图片大小设置为600*600、300*300,其他一阶段模型的输入图片均设置为416*416,检测结果如下页表6 所示。
由表6 可知,本文算法的mAP 为91.64%,除略小于YOLOX 以外,超越其他目标检测算法,但模型的参数量只有YOLOX 的27.12%。这主要是由于两者的主干特征提取网络不同,DarkNet53 有较好的提取能力,但模型参数量很大;而本文采用MobileNet 降低了参数量,并通过其他方式加强特征提取,弥补了精度上的不足。FPS 表现也处在中上游,YOLOv3 和YOLOv5s 的处理速度更快,但精度远小于本文算法。此外与最新的YOLOv7 相比,mAP 提高了0.74%,模型参数量降低了60%。综上所述,本文算法YOLOv4-MV1-FB-ECA 在速度和精度的平衡上达到了较好的统一,证明算法的有效性。
3.5.6 检测结果可视化
图8 为利用Grad-CAM 算法对改进前后的检测算法进行了热力图可视化,这是一种不需要修改模型结构,并且可以适应多种任务的可视化方法。它是利用反向传播过程计算梯度,从而得到特征图每个通道的权重,通过计算得到热力图来解释卷积神经网络关注的重点地区。图8(a)为融合前原始网络的模型热力图,图8(b)为融合后本文算法的模型热力图。从图中可以看出改进算法更关注能检测到的单个目标本身,对物体的检测效果更集中,因此,检测效果更好。

图8 算法改进前后的模型热力图Fig.8 Model heat map before and after the improvement of the algorithm
4 结论
本文设计出一种基于YOLOV4 的目标检测算法YOLOv4-MV1-FB-ECA。通过重新构建主干特征提取网络,使用深度可分离卷积的方法有效地降低了模型参数量;通过对Neck 的特征提取部分进行改进,融合ECA 注意力机制进一步提升模型的检测精度。实验结果分析表明,改进后的算法在公开数据集Pascal VOC 07+12 的检测精度提高了1.64%,模型参数量降低了77%,检测速度达到了55.54 FPS。改进模型在算法速度和精度上实现了统一和平衡,优于其他主流的目标检测算法,较小的模型参数量和较高的FPS 为其他现实场景提供了模型基础。后续工作将在进一步提高精度的同时提高泛化能力,聚焦交通场景,尤其是使用率较高的车辆和行人检测,增强算法在复杂场景和多干扰情况下的鲁棒性。
