基于改进Q-learning 算法的移动机器人路径规划
2024-04-16井征淼刘宏杰周永录
井征淼,刘宏杰,周永录
(云南大学信息学院,昆明 650504)
0 引言
随着计算机技术的高速发展,人工智能应用在近年来已成为研究热点,而其中备受关注的就是移动机器人应用。在对移动机器人的研究里,路径规划是极其重要的核心部分,能够直接反映出移动机器人的智能程度[1]。路径规划是指在给定的区域范围内,让移动机器人在不碰到障碍物的情况下,发现起点与终点之间的一条无碰撞的通路[2]。根据障碍物的类别,可将其分为静态障碍物与动态障碍物,本文将重点探寻静态障碍物环境下移动机器人的路径规划问题。
现今的路径规划算法按照特点可以分为基于传统方式的方法和基于人工智能的方法,基于传统方式的方法包括A*算法、遗传算法、粒子群算法、人工势场法等,基于人工智能的方法包括Q-learning 算法、Sarsa 算法等[3-5]。作为机器学习算法的分支,Q-learning 算法在移动机器人路径规划领域有了十分显著的成果[6,10],但是该算法在应用中仍然存在许多问题,如算法收敛速度慢、学习时间长、花费代价高等。因此,如何解决这些问题,是当前人工智能领域里学者重点关注的内容。徐晓苏等在Q 值初始化的过程中引入了人工势场法中的引力势场,从而使收敛速度加快,再通过在状态集中增加了方向因素,使规划路线的精度得以提高[6]。杨秀霞等在环境建模时设置每个阶段的搜索步长,设置奖励池与奖励阈值,使路径规划为全局最优路径[7]。毛国君等引入了动态搜索因子,根据环境的反馈来动态调整贪婪因子,降低了算法搜索代价[8]。王付宇等利用萤火虫算法初始化Q 值,设计了贪婪搜索和玻尔兹曼搜索结合的混合选择搜索,使算法学习时间减少,且在路径平滑度等方面有了进一步提升[9]。由此可见,虽然Q-learning 算法在路径规划领域已研究许久,但如何加快收敛速度、减少学习时间、降低花费代价等依然是目前移动机器人路径规划研究的重点和热点问题[10-11]。
1 Q-learning 算法
作为机器学习领域的一种极其重要的学习方法,强化学习在移动机器人进行路径规划的领域受到了更多的关注和应用[12],主要是针对机器人进行的研究,以解决机器人在环境中不断学习后,能得出一个合理决策,即获得最大奖励的问题。
1.1 马尔科夫决策过程
马尔科夫决策过程多数应用于一定量的动作和不同模式的决策分析模型中,MDP 模型即具有决策状态的马尔可夫奖励过程。而马尔可夫决策过程定义为MDP={S,A,P,R,γ},其中:S 为所用可行状态的空间,A 为所有可行动作的空间,P 为预判可能动作的概率矩阵,R 为获得的正负向奖励,γ 为折扣系数。马尔可夫属性表示下一状态的内容只取决于当前状态的决策而不受之前状态决策的影响。
1.2 传统Q-learning 算法
Q-learning 算法是强化学习中较为经典的算法之一,其特性是value-based 的算法,也是一种时间差分更新方法[5]。它的基本内容包括机器人、动作、状态、奖励、环境。Q-learning 算法将机器人与环境之间的交互过程看成是一个马尔科夫决策过程。Q-learning 的学习过程为:机器人在当前状态s 下,选择某一策略进行动作的选择,该策略通常为ε-greedy 策略,在可行动作空间中选择动作a 去执行,再根据此动作后获得的奖励以及新状态s'对Q表进行更新,更新公式为:
式中,α 表示学习率,γ 表示折扣系数,α 与γ 的取值范围在(0,1)之间。ε-greedy 策略是一种贪心选择策略,ε 表示贪心度,取值范围在(0,1)之间,表示系统有ε 的概率在可行动作空间中选择Q 值最大的动作执行,有1-ε 的概率在可行动作空间内任意地选择一个动作执行。
2 人工势场法
人工势场法的基本原理为构造出一个虚拟的类似于物理学中电磁场的一个势场[13],该势场包括两部分:1)在障碍物附近构造斥力势场,2)在目标点附近构建引力势场,而机器人则在这两种势场作用下去探索一条无碰撞的运动路径。
2.1 引力函数
引力场应满足随着距离目标点越近而呈现单调递增的性质。
2.2 斥力函数
斥力场应满足随着距离障碍物越远而呈现单调递减的性质。
式中,η 为斥力增益系数,ρ(q-q0)表示当前点和机器人附件障碍物区域中离机器人较近的点q0之间的距离,ρ0表示在机器人周围障碍物区域对机器人产生的最大距离。
3 改进Q-learning 算法
传统的Q-learning 算法对于在栅格地图中的路径规划是把每一个栅格归于可行状态空间中,每个状态的可行动作空间为上、下、左、右,并且每个动作的步长为一个栅格的大小。其在栅格地图路径规划中存在收敛速度慢、花费代价高、运行时间长的缺陷。
针对这些缺陷,本文在传统Q-learning 算法的基础上结合人工势场法对其进行了一些改进,主要思想是引入人工势场法的引力函数与斥力函数。首先用引力函数对奖励函数进行改进,从而起到启发式作用,明确机器人前进的方向。其次用斥力函数创造一个值对Q 表的更新公式进行改进,使机器人运动时会选择向离障碍物更远的位置移动。
3.1 动态选择奖励值
检查目前状态是否为终点状态或障碍物状态,若为否,则计算目前状态的引力函数Uatt与前一状态的引力函数Uatt',判断Uatt、Uatt'之间的大小关系,如果目前状态的引力函数大于前一状态的引力函数,说明移动机器人在进行状态改变之后距离终点状态越来越远。根据目前状态的引力函数与前一状态的引力函数的对比,动态地选择奖励值,这就使移动机器人在前进时可以保持向终点方向,达到具有目的性地去选择下一个状态的位置,从而避免了盲目地去探索每个位置。为使机器人能尽快学会避开障碍物和到达终点,故对到达终点取较高奖励值,对到达障碍物取较低奖励值。根据上述的奖励值函数为:
3.2 计算值后更新Q 值
检查目前状态是否为终点状态或障碍物状态,若为否,则计算目前状态的斥力函数Urep与前一状态的斥力函数Urep',判断Urep、Urep'的大小关系以及目前状态的斥力函数是否大于设定值1,如果当前状态的斥力函数大于前一状态的斥力函数,说明移动机器人在进行状态改变之后距离障碍物越来越远。而目前状态的斥力函数小于1,则表示移动机器人的位置距离障碍物较远,值较小,可以忽略不计。所以当目前状态的斥力函数大于前一状态的斥力函数,且目前状态的斥力函数大于设定值1 时,动态计算值,并将值代入Q 表更新公式中,使移动机器人在Q 表更新后更倾向于选择距离障碍物更远的状态位置,从而在很大程度上提升机器人避开障碍物的能力。计算值的公式如下:
改进后的Q 表更新公式:
3.3 改进Q-learning 算法的步骤
根据上述内容,给出改进Q-learning 算法的详细步骤如下:
Step 1 初始化环境、参数。确定栅格环境的大小,确定起点位置、终点位置、障碍物位置确定起点位置、终点位置、障碍物位置,选择合适的学习率α,折扣系数γ,选择合适的ε-greedy 策略中的epsilon值,以及设置最大迭代次数episode。
Step 2 对Q 表进行初始化。令Q(s,a)=0。
Step 3 初始化状态s。回到起点位置,初始化状态s。
Step 4 判断是否为终点。若为是,选择奖励值,更新Q 值,Q(s,a)更新为然后执行Step 10;若为否,则执行Step 5。
Step 5 选择动作a。机器人在目前状态s 下使用ε-greedy 策略进行动作选择并执行,根据动作a更新状态s 为s'。
Step 6 判断s'是否为障碍物状态。若为是,更新Q 值,Q(s,a)更新为返回上一步状态s,执行Step 5;若为否,执行Step 7。
Step 7 计算引力函数数值,动态选择奖励值。对状态s'进行检查,判断s'的状态,若s'不为障碍物状态,则计算上一个状态的引力函数Uatt及更新后状态的引力函数Uatt',对比两个引力函数数值,动态选择奖励值。
Step 9 计算Q 值,更新Q 表。Q(s,a)更新为,后执行Step 4。
Step 10 判断迭代次数episode 是否达到设置的最大迭代次数,若判断结果为是,则结束整个学习过程,若为否,则回到Step 3。
根据上述算法过程,可得改进Q-learning 算法的流程图如图1 所示。
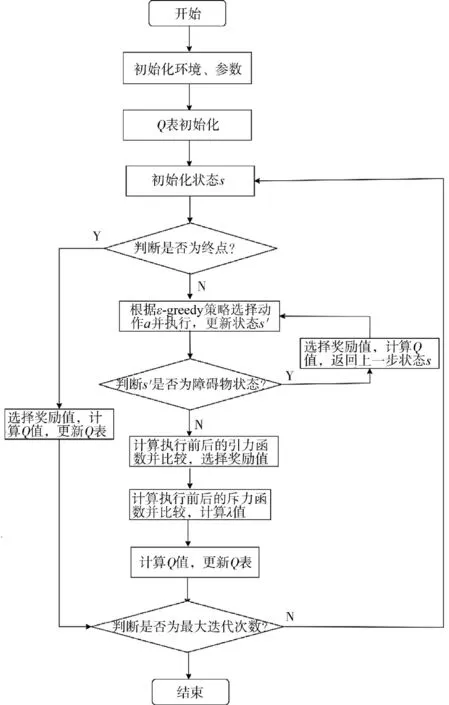
图1 改进Q-learning 算法流程图Fig.1 Flow chart of improved Q-learning algorithm
4 实验仿真
4.1 仿真条件
仿真实验在Pycharm2022.1.3 的环境下进行。操作系统为windows11 x64,使用的编译工具包为python3.10.5,设备参数为Intel i7-12700H、DDR5 16GB和RTX 3060。
4.2 仿真参数
使用如图2 所示Pycharm 构造的20×20 栅格地图下进行仿真实验,红色的格子代表移动机器人所在的起点位置,黄色的格子代表移动机器人的目标终点位置,黑色的图形代表障碍物,移动机器人的可行动作空间包括:上、下、左、右4 个动作。
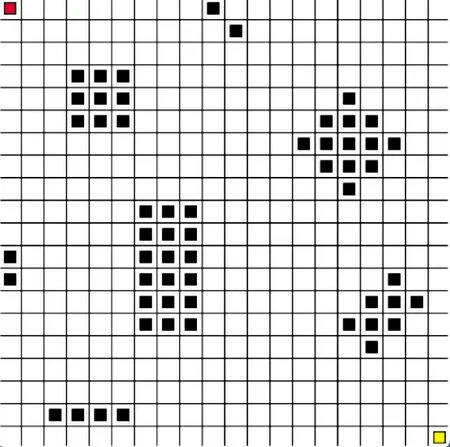
图2 路径规划栅格地图示意图IFig.2 Schematic diagram I of path planning grid map
在仿真实验中,3 种算法所使用的实验参数如表1 所示。
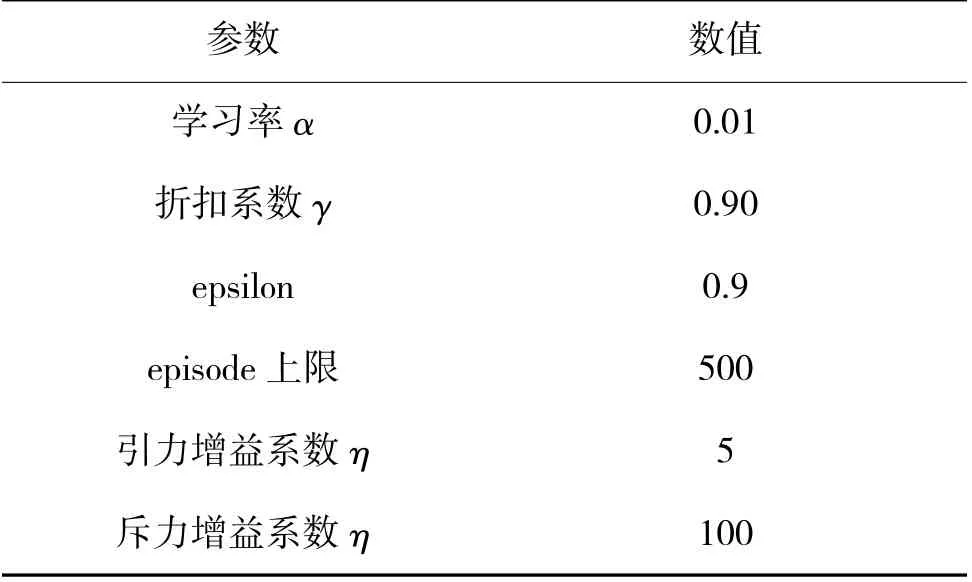
表1 算法实验参数Table 1 Experimental parameters of the algorithm
4.3 仿真实验验证及分析
根据上述的实验环境和实验参数,在图2 所示的栅格地图下进行传统Q-learning 算法、引入引力场的算法与本文算法的实验仿真。将3 种算法分别进行了连续150 次迭代实验,实验结果如下页图3~图8 及第140 页表2 所示。由图3 可得,传统Q-learning 算法在迭代次数为101 次时趋于收敛,由图4 可得,引入引力场的算法在迭代次数为60 次时趋于收敛,由图5 可得,本研究的改进Q-learning 算法在迭代次数为21 次时趋于收敛。对比图3~图5 可以看出,在收敛之前,传统Q-learning 算法和引入引力场的算法使用了较多的步数去探索,而本文改进Q-learning 算法使用的步数很少,证明了在相同的仿真环境情况下,本研究改进的Q-learning 算法在探索期间具有更强的目的性找到下一位置,从而使探索的步数大为降低,且能更快地达到收敛。

表2 3 种算法仿真数据ITable 2 Simulation data 1 of three kinds of algorithms

图3 传统Q learning 算法迭代收敛图IFig.3 Iterative convergence diagram of traditional Q learning algorithm I
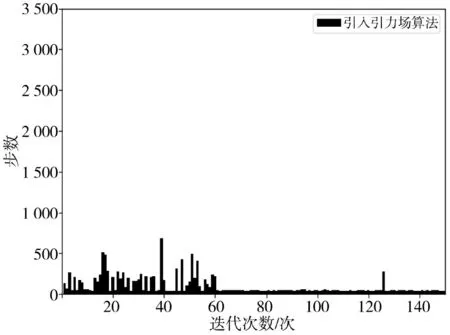
图4 引入引力场算法IFig.4 Algorithm I for introduction of gravitational field
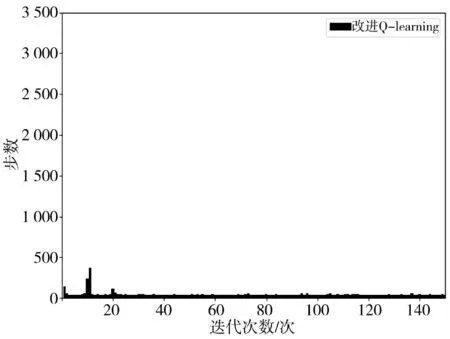
图5 本文算法迭代收敛图IFig.5 Iterative convergence diagram I of the studied algorithm
图6~图8 为3 种算法在栅格地图示意图1 中所得到的路径规划路线图,红色为起点位置,黄色是终点位置,灰色为移动机器人的避障路径。

图6 传统Q-learning 算法路径规划路线图IFig.6 Path planning roadmap I with traditional Q-learning algorithm
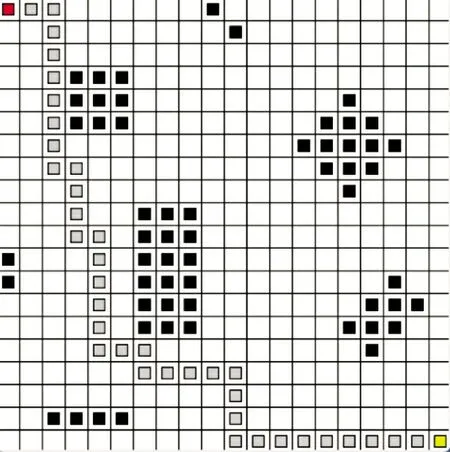
图8 改进Q-learning 算法路径规划路线图IFig.8 Path planning roadmap I with Improved Q-learning algorithm
下页表2 是3 种算法在进行了150 次迭代的仿真数据对比。根据图6~图8 及表2 可以看出,本文算法较之其他算法具有更高的效率,并且能花更少的代价完成学习,以及更不易与障碍物相撞,能够快速地使移动机器人找到一条无碰撞的通路。
接下来在障碍物摆放更为复杂的环境中对3种算法进行仿真实验验证,实验参数与上相同,环境栅格地图如图9 所示。

图9 路径规划栅格地图示意图IIFig.9 Schematic diagram II of path planning grid map
在图9 的栅格地图中进行实验仿真,仿真结果如图10~图12、图13~图15 和表3 所示。

表3 3 种算法仿真数据ⅡTable 3 Simulation data II of three kinds of algorithms

图10 传统Q-learning 算法收敛图ⅡFig.10 Convergence diagram II of traditional Q-learning algorithm
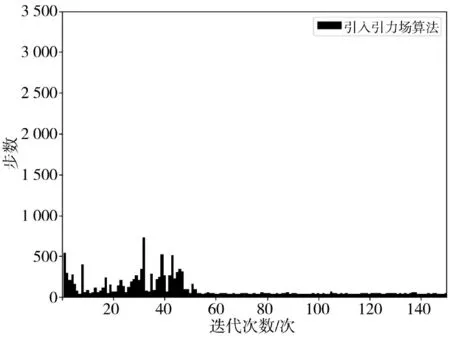
图11 引入引力场算法ⅡFig.11 Introduction of gravity field algorithm II
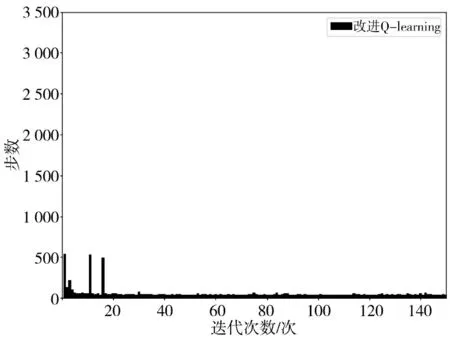
图12 本研究算法收敛图ⅡFig.12 Convergence diagram II of the studied algorithm

图13 传统Q-learning 算法路径规划路线图ⅡFig.13 Path planning roadmap II with traditional Q-learning algorithm

图14 引入引力场算法路径规划路线图ⅡFig.14 Path planning roadmap II WithiIntroduction of gravitational field algorithm

图15 改进Q-learning 算法路径规划路线图ⅡFig.15 Path planning roadmap II with improved Q-learning algorithm
图13~图15 为3 种算法在栅格地图示意图2中所得到的路径规划路线图。
根据以上的仿真结果可得,本研究的改进Q-learning 算法在障碍物更复杂的环境中,依然具有较少的探索步数和较快收敛的能力,并且撞到障碍物的概率较之其他算法更低。
5 结论
针对传统的Q-learning 算法在移动机器人路径规划时存在收敛速度慢、花费代价高、运行时间长的缺陷,本文提出了将人工势场法与传统Q-learning算法结合的一种改进Q-learning 算法,利用引力函数来动态地选择奖励值,使移动机器人在探索时就明确了方向,避免了盲目探索;利用斥力函数来动态地更新Q 值,达到远离障碍物的目的,从而能够更快速、更准确地到达终点位置。实验表明,改进后的Q-learning 算法收敛速度明显加快,所需代价降低,运行效率提高,并且更加不易与障碍物相撞,更有利于移动机器人在路径规划方面的实际应用。
