基于改进YOLOv5s的车辆检测研究
2024-04-15肖的成李艳生
肖的成 李艳生


摘 要:【目的】针对目标检测算法在车辆检测领域中应用时存在模型复杂、检测精度较低的问题,基于改进YOLOv5s算法开展车辆检测研究。【方法】以Ghost模块来替换YOLOv5s中的主干网络,以达到模型剪枝的目的,改进后的网络模型复杂度有所降低,从而解决了网络模型较大的问题。同时,可引入挤压—激励注意力机制来提取更重要的特征信息,达到提高检测精度的目的。本研究所用到的数据集均为汽车图像,车辆检测数据集共有12 786张图片,将该数据集按照8∶1∶1的比例进行划分。其中,训练集为10 228张,测试集和验证集均为1 279张,采用对比试验法进行研究。【结果】试验结果表明,与原有的YOLOv5s相比,改进后的网络模型在车辆检测数据集上的平均准确率均值提升3%,查准率和召回率分别提升1.9%和3.2%,模型大小下降42%。【结论】改进后的网络模型有效降低了模型的复杂度,提高了检测精度,并节约成本。
关键词:深度学习;目标检测;注意力机制;YOLOv5s
中图分类号:TP391 文献标志码:A 文章编号:1003-5168(2024)04-0026-06
DOI:10.19968/j.cnki.hnkj.1003-5168.2024.04.005
Research on Vehicle Detection Based on Improved YOLOv5s
XIAO Dicheng LI Yansheng
(College of Physics and Electronics, Hubei Normal University, Huangshi 435002, China)
Abstract: [Purposes] Aiming at the problems of complex model and low detection accuracy of the current object detection algorithm in the field of vehicle detection, a vehicle detection research based on improved YOLOv5s is carried out. [Methods] The Ghost module was replaced with the original YOLOv5s backbone network to achieve the purpose of model pruning, which reduced the complexity of the improved network model and solved the problem of large network model; Then the Squeeze and Excitation attention mechanism is introduced to extract more important feature information to improve detection accuracy. The data sets used in this study are all images of cars, and on the vehicle detection dataset, a total of 12 786 pictures, the dataset is divided into 8∶1∶1.And among them, the training set is 10 228 pictures, the test set and verification set are 1 279 pictures and the method of comparative experiment was used in this study. [Findings] Experimental results show that compared with the original YOLOv5s, the average accuracy of the improved network model is increased by 3%, the accuracy and recall rate are increased by 1.9% and 3.2%, respectively, and the model size is reduced by 42%.[Conclusions] The improved network model effectively reduces the complexity of the model, saves costs and improves the detection accuracy.
Keywords: deep learning; object detection; attention mechanism; YOLOv5s
0 引言
隨着我国科技的蓬勃发展,汽车也日益普及。汽车普及在给人们带来极大便利的同时,也带来了交通路况拥堵、交通事故频发等需要解决的难题,这些难题一直困扰着人们。因此,对交通目标识别系统进行研究是非常必要的。传统检测方法包括梯度直方图、支持向量机,主要以滑动窗口来检测目标,缺点是冗余时间长、手工设计的特征没有鲁棒性[1]。2012年,基于深度卷积神经网络的Alex Net[2]以显著优势夺得ImageNet图像识别比赛的冠军,从此深度学习的检测方法开始受到学者们的广泛关注[3],目标检测也步入以深度学习为基础的新纪元。在当前计算机视觉领域研究中,以深度学习与目标检测算法相结合的方式为主流研究方法。由于实际交通路况复杂、目标种类多,使目标检测模型的参数过大,导致目标检测精确度不高,且速度缓慢。本研究以YOLOv5s[4]为基础进行优化改进,从而提高目标检测的精度与速度。
YOLO[5]算法在确保检测精度高的同时,还能提高检测速度,因此,其在车辆交通检测领域中的应用十分广泛。周晴等[6]用更轻量化的主干网络模型进行替换,在特征提取中采用加权双向特征金字塔,并优化损失函数,以达到算法模型小、精确度高的目的;章程军等[7]针对目标检测算法在自动驾驶等领域车辆目标检测中存在检测精度不高、实时性和鲁棒性较差等问题,在算法中引入一次性聚合模块,并采用非局部注意力机制,同時利用加权非极大值抑制法,使平均准确率均值和平均准确率均得到有效提升,且检测速度满足实时性的要求。YOLOv5s作为当前YOLO系列最轻量化的模型之一,其参数量和模型复杂度仍较高[8]。华为公司于2020年提出一种轻量化模块——Ghost模块[9],能有效降低网络模型的参数量和计算复杂度。本研究采用Ghost模块来替换YOLOv5s的主干网络,实现降低网络参数量且提高检测速度的目的,并在网络中引入注意力机制(Squeeze and Excitation attention,SE)[10],使网络提取出更加重要的特征信息。
1 YOLOv5s目标检测算法
YOLO模型采用预定义预测区域法来完成目标检测,将原始输入图像划分为S×S个网格,每个网格允许预测出X个边界框及一个类别信息,其中,边界框涵盖该目标位置信息和置信度信息。YOLOv5s网络基于上述检测方式,每个网格可预测3个边界框(Bounding box),每个边界框预测涵盖(x,y,w,h,c)这5个元素,分别表示边界框的位置、大小与置信度[11]。
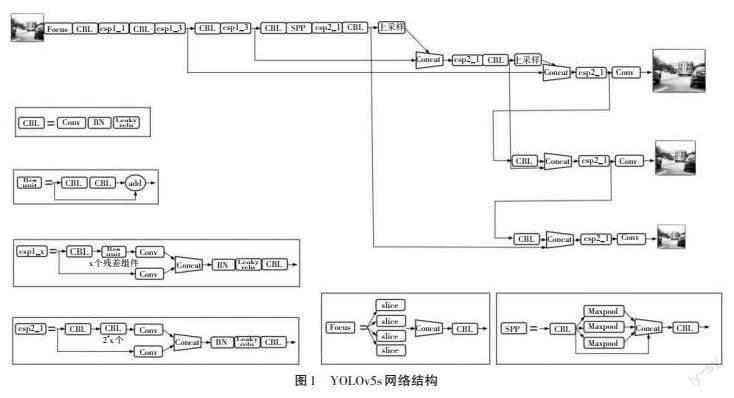
YOLOv5s网络结构主要由输入端、主干网络Backbone、颈部网络Neck和输出端组成,如图1所示。输入端要求输入图片大小是32的倍数,当输入图片不满足要求时,输入端会按照标准尺寸来自适应填充或缩放图片大小。其中,Mosaic[12]数据增强法是通过随机选取4张图片进行缩放、旋转等操作,经过上述操作后,会随机拼接成新的训练数据,不仅丰富了数据集,还使网络模型在推理阶段减少计算量,提高目标检测速度。Mosaic数据增强效果如图2所示。主干网络由四部分组成,分别为Focus、CBL、CSP和SPP。对输入的图像进行Focus操作,即对图像进行切片操作,图像经过2倍下采样得到4张特征图,该方法不丢失图像的特征信息,并使网络提取到更加充分的特征信息。跨阶段局部(Cross Stage Partial,CSP)模块会构建更深的网络,用于跨通道融合,通过融合每层的特征信息来获得更丰富的特征图像。Neck网络结合上采样层和CSP模块,使高层语义信息与底层位置信息融合,得到预测的特征图像,并将其送到输出端。输出端中的3个检测头分别对原图像进行8倍、16倍和32倍的下采样,从而生成3个不同尺寸的特征向量,可用来预测图像特征,并生成边界框坐标和返回目标类别的概率和置信度。
YOLOv5s在目标检测领域中具有很强的检测性能,但其不是专门对车辆目标进行检测的,故存在检测效果差等问题,尤其当车辆目标较为密集时,检测效果并不理想。为满足对车辆目标检测时具有实时精确性、网络轻量化的需求,本研究对YOLOv5s网络进行改进,旨在提高对车辆目标检测的精度和速度。
2 改进的YOLOv5s目标检测算法
2.1 主干网络的改进
卷积神经网络(Convolutional Neural Networks,CNN)是一类包含卷积计算且具有深度结构的前馈神经网络[13],目标检测模型作为主干网络多用来提取目标特征。本研究在YOLOv5s模型的基础上,将采用Ghost模块来替换YOLOv5s模型主干网络中的2个CSP模块,以达到模型剪枝效果。
GhostNet以普通卷积和线性运算的方式,将线性变换作用于普通卷积特征图上,可获得相似的特征图,通过结合这两种方式,能有效减少模型参数和计算次数,Ghost模块如图3所示。Y的固有特征图由普通卷积生成,Y′的冗余特征图由线性运算生成。Ghost模块表示见式(1)。
Y=X*f+b (1)
式中:[X∈Rc×w×h]为输入特征图;c为其通道数;h为其高度;w为其宽度;*为卷积操作;b为偏置项。
需要使用卷积核大小为[k×k]的卷积块,可得到通道数为[n]的输出特征图[Y∈Rn×w′×h′],即[f∈Rc×k×k×n]。运用该方法进行一次特征提取需要的运算量见式(2)
[cost=h′×w′×n×k×k×c] (2)
由此可知,大多数特征图是相似的,部分卷积操作得到冗余的特征图。多余的网络计算会浪费大量的算力和存储资源。针对该问题,Ghost模块通过普通卷积运算得到固有特征图,见式(3)。
[Y′=X*f ′+b] (3)
式中:[Y′∈Rm×w′×h′];[f ′∈Rc×k×k×m];m为通道数。
为了获得与原输出特征图相同数量的n维通道,Ghost模块将m维固有特征图进行一系列线性变换,见式(4)。
[yij=?ij(yi′)?i=1,...,m;j=1,...,s] (4)
式中:[yi′]为第i个固有特征图;[?ij]为第i个特征图进行的第j个线性变换的函数。
若提取前n个作为最终输出,则获得的特征图数量与原输出特征图Y相同,即Ghost模块完成一次特征提取需要的运算量见式(5)。
[cost′=h′×w′×ns×k×k×c+(s-1)×h′×w′× ns×k×k] (5)
将前后两个运算量相比,因为s?c,则运算量参数比见式(6)。
[r=ccs+s-1s=s×cc+s-1≈s] (6)
由此可知,用Ghost模块来替代原主干网络,可有效降低参数量及计算量,能获得更好的特征提取效果。
2.2 引入注意力机制
对于输入的一张图像信息,需要关注的是图像上下文全局信息。随着网络的不断加深,深层特征信息往往会被损失,为了解决这个问题,本研究引入挤压—激励注意力机制(Squeeze-and-Excitation,SE)模块。SE模块是从特征的通道关系切入,经全连接层和Sigmoid激活函数来获取图像特征通道的权重,根据权重的不同能抑制一些无用的通道特征,从而提取更加关键的特征信息,使得检测效果更好。SE模块如图4所示。其中,Ftr为传统卷积操作,以X为输入,U为Ftr的输出,C′、H′、W′分别为图像的通道数及高度和宽度,C、H、W分别为图像经过卷积操作后得到的图像通道数及高度和宽度,Fsq(·)为对图像特征做全局平均池化操作。
SE注意力机制先将输入大小为[H×W×C]的特征Uc,进行全局平均池化,得到[1×1×C]的特征Zc,本质上是将整体空间特征编码为一个富含全局信息的特征,见式(7)。
[Zc=Fsq(Uc)=1H×Wi=1Hj=1W Uc(i, j)] (7)
先将全局大小的特征信息经过Excitation操作,即Fex(·,W),获得特征通道之间的联系,并获得各通道的权重。再通过ReLU激活函数,并经过全连接层恢复输入时的通道数。最后经过Sigmoid函数得到权重,见式(8)。
[S=Fexz,W=σgz,W=σW2δW1z] (8)
式中:z為全局特征,即式(7)中的Zc先经过全连接层降维;W1为降维系数。
将式(8)中的S与特征Uc相乘,得到权重Sc,生成最终的目标特征见式(9)。
[Xc=FscaleUc , Sc=ScUc] (9)
3 试验结果与分析
3.1 数据集
试验的数据集是从coco[14]数据集中提取的,包含一万两千多张图片及相应的标注文件,图片信息较为丰富,且涵盖了不同地理、环境等条件因素下的图片数据。数据集中只包含车辆类别car,将该数据集按照8∶1∶1的比例划分为训练集、验证集、测试集,其中,训练集有10 228幅图片、验证集有1 279幅图片、测试集有1 279幅图片。
3.2 试验环境及评价指标
试验的硬件配置如下:CPU为Intel(R) Core(TM) i5-12500H;GPU为NVIDIA GeForce RTX 3050Ti;内存为16 G。软件环境为:Windows操作系统;python 3.8;Torch 1.13.0 cuda 10.1。设置网络训练超参数见表1。
本研究的主要评价指标是精确率(precision)、召回率(recall)、平均准确率(AP)、平均准确率均值(mAP)及推理时间。精确率和召回率的计算见式(10)、式(11)。
[precision=TPTP+FP] (10)
[recall=TPTP+FN] (11)
式中:TP(True Positives)为正样本数据中与真实框交并比大于阈值的检测框的个数,即被正确识别的车辆目标;FP(False Positives)为正样本数据中与真实框交并比小于阈值的检测框的个数,即误检的车辆目标;FN(False Negatives)为正样本中未检测到的真实框的数量,即漏检的车辆目标。
平均准确率(AP)和平均准确率均值(mAP)是目标分类和定位性能的主要衡量指标计算见式(12)、式(13)。
[AP=01PRdR] (12)
[mAP=1Ni=1NAPi] (13)
3.3 模块改进对比分析
本研究通过逐步修改每个改进模块,来验证改进模块对网络整体性能的影响,并验证是否能提升网络性能。试验结果见表2。
只对主干网络进行改进,用Ghost模块来替换YOLOv5s主干网络中的两个CSP模块,得到I-YOLOv5s。与YOLOv5s网络相比,I-YOLOv5s的mAP.5从0.678提升至0.685,提高了0.7%,而模型大小由14.4 MB减少至7.8 MB。II-YOLOv5s是在I-YOLOv5s的基础上,引入挤压—激励注意力机制。相比较I-YOLOv5s网络,II-YOLOv5s网络的mAP.5值从0.685提升至0.708,提高了2.3%,模型大小没有显著变化。
由表2可知,对网络每个模块进行改进后,其mAP.5和mAP.5∶.95值均逐步提升,且推理时间没有显著增加。
3.4 改进前后YOLOv5s对比分析
为了研究II-YOLOv5s性能与原网络的差异,对两个模型的训练结果进行对比分析,结果见表3。
由表3可知,改进模型II-YOLOv5s的平均准确率均值(mAP)为70.8%,比原网络模型的mAP值提升3%,查准率和召回率分别提升1.9%和3.2%,推理时间变化不大,但仍满足实时性的要求。YOLOv5s与II-YOLOv5s的损失值和mAP对比如图5所示。
由图5可知,随着训练批次逐步递增,位置损失值不断下降,在训练批次为60次左右时,曲线趋于稳定,II-YOLOv5s模型位置损失值明显低于YOLOv5s模型位置损失值。从YOLOv5s与II-YOLOv5s的mAP值对比曲线得出,模型趋于稳定后,II-YOLOv5s的mAP值优于YOLOv5s模型。
4 结语
本研究在YOLOv5s网络模型基础上,对其功能进行了改进,并将其应用于交通目标识别系统中。II-YOLOv5s网络模型在主干网络中使用Ghost模块,减少了网络模型参数量和计算量,提高了平均准确率均值。通过引入SE注意力机制,根据不同权重来抑制无用的通道特征,并有效提取了更加关键的特征信息,使得检测精度更高。试验结果表明,改进后的网络模型平均准确率均值较原网络模型有所提升,位置损失值有一定程度的降低,可作为移植到移动端设备的网络模型,且改进后的模型更符合网络检测速度的实时性要求。后续研究将改进后的网络模型嵌入到移动设备中,做进一步验证。
参考文献:
[1]肖雨晴,杨慧敏.目标检测算法在交通场景中应用综述[J].计算机工程与应用,2021(6):30-41.
[2]KRIZHEVSKY A,SUTSKEVER I,HINTON G E.ImageNetclassification with deep convolutional neural networks[J].Advances in Neural Information Processing Systems,2017(6)84-90.
[3]LECUN Y,BENGIO Y,HINTON G.Deep learning[J].Nature,2015(7553):436-444.
[4]董延华,李佳澳.改进YOLOv5s遥感图像识别算法研究[J].吉林师范大學学报(自然科学版),2023(2):117-123.
[5]REDMON J,DIVVALA K S,GIRSHICK B R,et al.You only look once: unified,real-time object detection[C]//Computer Vision & Pattern Recognition.IEEE,2016:779-788.
[6]周晴,谭功全,尹宋麟,等.改进YOLOv5s的道路目标检测算法[J].液晶与显示,2023(5):680-690.
[7]章程军,胡晓兵,牛洪超.基于改进YOLOv5的车辆目标检测研究[J].四川大学学报(自然科学版),2022(5):79-87.
[8]蒋超,张豪,章恩泽,等.基于改进YOLOv5s的行人车辆目标检测算法[J].扬州大学学报(自然科学版),2022(6):45-49.
[9]HAN K,WANG Y,TIAN Q,et al.GhostNet:more features from cheap operations[J].Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition,2020:1577-1586.
[10]HU J,SHEN L,SUN G.Squeeze-and-excitation networks[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).IEEE,2018:7132-7141.
[11]邵延华,张铎,楚红雨,等.基于深度学习的YOLO目标检测综述[J].电子与信息学报,2022(10):3697-3708.
[12]YUN S,HAN D,OH S J,et al.CutMix:regularization strategy to train strong classifiers with localizable features[J].CoRR,2019:1-14.
[13]李炳臻,刘克,顾佼佼,等.卷积神经网络研究综述[J].计算机时代,2021(4):8-12,17.
[14]LIN T Y,MAIRE M,BELONGIE J S,et al.Microsoft coco:common objects in context[J].CoRR,2014,8693:740-755.
