基于M-Unet 的混凝土裂缝实时分割算法
2024-04-11孟庆成李明健万达胡垒吴浩杰齐欣
孟庆成 ,李明健 ,万达 ,胡垒 ,吴浩杰 ,齐欣
(1.西南石油大学 土木工程与测绘学院,成都 610500;2.西南交通大学 土木工程学院,成都 610031)
在混凝土自身材料特性影响及多重因素作用下,混凝土结构服役期间会不可避免地产生裂缝。裂缝是混凝土结构病害的一种初期表现,若初期裂缝得不到即时修补,在外力的作用下,裂缝的长度、宽度、深度会不断地增加,使得混凝土构件的有效截面面积减小,承载力降低,继而可能会导致事故的发生[1]。早期的裂缝检测主要是人工检测方法,人工检测可以直接对裂缝的特征进行判断,较为简便灵活,但人工检测的结果受限于主观判断,依赖检测人员的经验储备,且人力物力消耗大,容易发生安全事故,导致人工检测难以完成大量的裂缝检测任务[2]。后来出现了基于传统图像处理技术的裂缝检测方法,常见的有基于阈值的裂缝图像分割方法和边缘检测方法[3]。传统图像处理技术促进了混凝土裂缝检测技术的发展,取得了一定的成就,但在解决复杂裂缝以及背景噪声多的图像时,传统图像处理技术存在较多的局限性,使其无法获得稳定的检测结果,无法适应复杂的实际场景[4]。
深度学习(Deep Learning,DL)算法具有强大的特征提取能力,早期受限于计算机硬件设备的性能而没有得到普遍的应用[5]。随着计算机硬件设备性能的提升和现代科技的飞速发展,深度学习算法的应用得到了普及并促进了图像识别技术的发展。深度学习算法是一种包含多隐含层和多感知层的网络结构,相比于传统算法能更好地描述物体抽象的和深层次的信息,在图像识别领域表现突出,因此越来越多的科研人员将其应用于结构损伤检测任务中[6]。胡文魁等[7]针对传统方法去除裂缝图像噪声不明显以及输出结果中裂缝不连续的问题提出一种BCI-AS 方法,在像素级水平上的裂缝分割精度达到了94.45%。李良福等[8]先利用滑动窗口算法对裂缝图像切割成多个区域,再用卷积神经网络(Convolutional Neural Network,CNN)对切割后图像分类,最后用改进的滑动窗口算法检测裂缝,取得良好的检测效果。Liu 等[9]采用U-Net 方法识别混凝土裂缝,与全卷积网络(Fully Convolutional Networks,FCN)相比,该方法的效率更高、准确性更好,但存在边缘平滑、细节丢失的问题。Ren 等[10]提出了一种改进的深度全卷积网络 CrackSegNet,可有效地消除噪声的干扰,可从复杂背景的裂缝图像中执行端到端的裂缝分割。Xue 等[11]提出基于RFCN 的隧道衬砌裂缝图像检测方法,获得了比GoogLeNet 和VGG 等模型更好的检测效果。王森等[12]提出一种深度全卷积神经网络用于裂缝图像的分割,该算法准确率达92.46%,但没有用其他数据对算法的有效性进行测试,缺乏对模型泛化能力的验证。
上述网络模型均取得了较好的裂缝分割效果,但所需的计算量大、缺乏对裂缝分割速度的考虑,在裂缝检测量巨大和设备计算资源有限的前提下,难以满足裂缝检测实时性的要求。提出一种结合改进的MobileNet_V2 轻量网络和U-Net 网络的裂缝语义分割模型M-Unet,利用改进的MobileNet_V2 网络替换U-Net 网络的下采样部分,减少参数量,达到网络轻量化的效果,并设置多组对比实验以验证方法的有效性。
1 数据集的制作
1.1 采集裂缝图像
图像采集于已投入使用的包括桥梁、挡土墙、大坝和隧道等各种混凝土结构,经过一周的采集,共计采集到1 226 张分辨率为4 032×3 024 的三通道RGB 原始混凝土裂缝图像。为了让网络学习到更多不同背景噪声条件下的裂缝特征,反映混凝土结构在服役期间所处的真实环境,采集到的裂缝图像包含了不同时间段、不同光照条件、不同污渍情况、不同清晰度等情况的图像,采集到的部分裂缝图像如图1 所示。

图1 混凝土裂缝图像Fig.1 Image of concrete cracks
1.2 图像标注及增强
从1 226 张裂缝图像中挑选出250 张效果较好的裂缝图像,利用语义分割标注软件Labelme 对250张裂缝图像进行标注,标注过程如图2 所示,不同于目标检测任务中的数据标注,在目标检测中对图像数据的标注仅需用矩形框将目标区域框住,而在语义分割任务的图像标注过程中,需要将裂缝图像放大,并沿着目标的轮廓逐点标注,实现亚像素级别的裂缝标注,标注点间的线宽与裂缝尺寸相比是微不足道的,不会对裂缝几何尺寸测量造成影响。将所有标注点闭合成环即完成对裂缝的标注,闭合区域以外的其他区域为背景区域。

图2 混凝土裂缝标注过程Fig.2 Labeling process of concrete cracks
对标注后的裂缝图像进行切分,将每一张裂缝图像切分成分辨率大小为512×512 的不重叠区域,并从中剔除缺乏裂缝特征的图像。使用Labelme 标注的图像会生成记录标注过程中关键点位置信息的json 文件,但json 文件并不能作为裂缝语义分割网络训练所需的直接数据,为了将其用于训练,通过编写的Python 脚本将json 文件中的位置信息转换为可直接训练的掩码位图GroundTruth 图像,图3为转换后的部分图像。
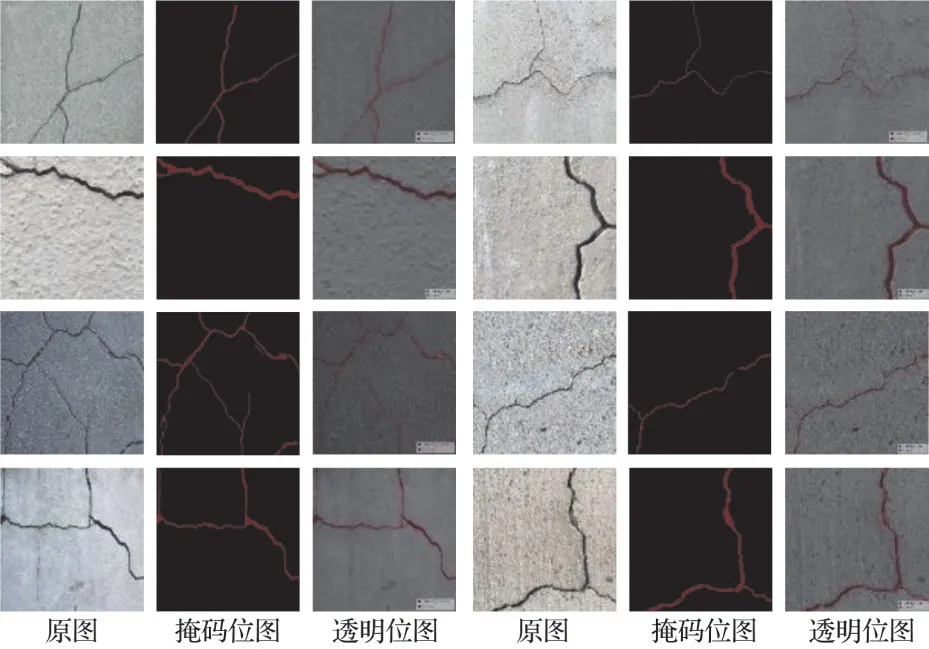
图3 已标注的裂缝图像Fig.3 Labeled crack images
对标注好的裂缝图像进行数据增强,使用数据扩增工具Augmentor 对裂缝数据集扩增操作,如旋转、放大、扭曲等,最终得到5 160 张带有掩码位图的裂缝图像,将数据集命名为SegCracks,将SegCracks 按7∶2∶1 划分成训练集、验证集和 测试集。
2 M-Unet 裂缝语义分割网络
2.1 改进的MobileNet_V2 网络
MobileNet_V2[13]是一种适用于移动设备的轻量级的卷积神经网络,其核心是采用反向残差的深度可分卷积代替了普通卷积,使用深度可分卷积可显著降低网络计算复杂度,减少参数量。MobileNet_V2 在网络训练中使用的激活函数为ReLU6,并采用批量标准化Batch Normalization 和Dropout 操作,以达到加快网络收敛速度和防止过拟合现象。对MobileNet_V2 的改进主要有以下两方面。
一是对网络结构层进行修剪,减少线性瓶颈结构bottleneck 的重复次数,以减少网络复杂度并且进一步轻量化模型,改进后的MobileNet_V2 网络结构如表1 所示。

表1 改进后的MobileNet_V2 网络结构Table 1 Network structure of improved MobileNet_V2
二是优化了原始网络的激活函数。激活函数是神经网络处理非线性问题的关键,在MobileNet_V2 网络中使用的是ReLU6 激活函数,函数图像如图4(a)所示,虽然ReLU6 激活函数可以显著提高网络非线性映射能力,但由其函数图象也可看出,当x<0 时,激活函数的梯度为零,并且在其后面的神经元梯度也将变为零,神经元坏死后不会对传入的数据响应,参数也得不到更新。因此,对原网络激活函数进行优化,引入LeakeyReLU 激活函数,其表达式如式(1)所示,其函数图像如图4(b)所示。与ReLU6 激活函数相比,使用LeakeyReLU 不仅能有效解决ReLU6 梯度消失和神经元坏死等问题,而且因其函数图象左侧的软饱和性使其具备更强的噪声干扰抵抗能力。

图4 原激活函数和改进的激活函数Fig.4 Original and improved activation function
式中:α 为偏移量,默认值为0.01。
2.2 M-Unet 网络
U-Net[14]网络主要是由左边的压缩路径和右边的扩展路径两部分组成,是一种典型的编码-解码结构,如图5 所示。压缩路径由3×3 的卷积层和2×2的池化层组成,主要用于对裂缝图像特征信息的逐层提取和压缩,而扩展路径由卷积层和反卷积层组成,用于还原裂缝图像特征的位置信息,从而实现端到端的裂缝检测。U-Net 网络的压缩路径在池化操作前都会自动保存裂缝特征图像,并以跳跃连接的方式将裂缝图像特征传输给对应的扩展路径部分,这样可以有效弥补因池化操作而丢失的裂缝特征信息。
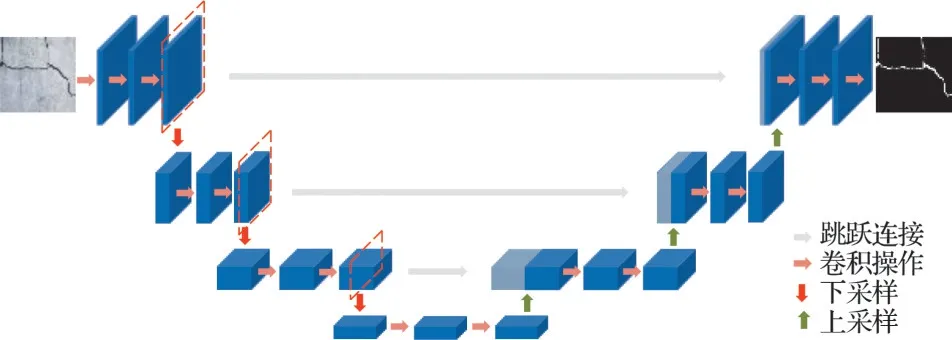
图5 U-Net 网络结构Fig.5 Network structure of U-Net
U-Net 网络的下采样部分通常是参数量很大的VGG16 网络,在裂缝分割任务中会消耗大量的计算资源,难以满足在实际工程应用中的实时性要求。轻量级卷积神经网络MobileNet_V2 的模型参数量仅为VGG16 网络的1/41,为了进一步降低对设备性能的要求和提高裂缝语义分割速度,对U-Net 网络进行优化,采用改进后MobileNet_V2 网络替换U-Net 网络的下采样部分,以实现模型的轻量化、减少计算复杂度并提高裂缝的语义分割效果,将优化后的轻量级语义分割网络命名为M-Unet。
3 实验与结果分析
3.1 实验环境与实验设置
实验硬件环境为第10 代英特尔处理器i7-10700,32 GB 的运行内存,NVIDIA GeForce RTX 2060 显卡,显存为6 GB。软件环境为64 位Windows 10 操作系统,使用高级程序设计语言Python,在深度学习框架Pytorch 下运行。
实验使用的数据集为SegCracks 数据集,经过超参数的调优,最终选取批量大小为4、Adam 自适应学习率优化器和指数衰减学习率的组合。共设置4 组实验:第1 组实验为对比3 种损失函数,选取1种最适用于裂缝语义分割任务的损失函数;第2 组实验是对提出的M-Unet 网络进行迭代训练,通过多种指标对网络的性能进行分析;第3 组实验是将M-Unet 网络与3 种主流的深度学习语义分割网络和传统图像处理方法的裂缝分割结果进行对比分析,以验证提出方法的有效性;第4 组实验是为验证网络的泛化能力,在CFD[15]、CRACK500[16]、GAPS384[17]3 个开源数据集进行交叉验证。
3.2 模型性能评价指标
通常情况下,单一的准确率评判标准不一定能全面反映网络的裂缝分割效果,为更加全面准确地评估网络性能而引入混淆矩阵。混淆矩阵是一种可视化工具,其中每一行表示网络预测值,每一列表示真实值,通过将网络的预测结果和真实结果放在同一个表中,混淆矩阵能清楚地表示出每个类别识别正确和错误的数量,如表2 所示。

表2 混淆矩阵Table 2 Confusion matrix
由混淆矩阵可以定义裂缝语义分割网络的重要评价指标,包括交并比(IoU)、精确率(Precision)、召回率(Recall)和F1_Score,其值越高,表示网络的裂缝语义分割越好、综合性能越优,计算公式如式(2)~式(5)。
式中:TP、FP、FN分别为表2 中的TP、FP、FN;I为模型的预测窗口与原来标记窗口的交叠率,是语义分割中常用的一种度量标准;Pr为正确预测为裂缝占全部预测为裂缝的比值;R为正确预测为裂缝占全部实际为裂缝的比值;F1为精确率和召回率的调和指标。
3.3 损失函数的选取
损失函数用于衡量预测值和真实值之间的误差,其决定了网络的训练方法,在网络训练优化过程中起指导性作用,可通过损失函数的反馈来调整和改进模型的权重系数。第1 组实验是对比语义分割领域常用的Dice Loss、BCE Loss 和BCEWithLogits Loss 损失函数的性能,在其余参数相同的情况下,经过10 轮的迭代,3 种损失函数的训练集损失曲线如图6 所示、验证集损失曲线如7 所示。可以看出,在训练集损失曲线图中,选用不同损失函数的损失值随着迭代次数不断增加而逐渐降低,网络逐渐收敛。在验证集损失曲线图中,选用Dice Loss 损失函数的模型损失值明显小于其余两种,对网络的优化有更好的指导作用。因此,选用Dice Loss 作为搭建网络的损失函数。
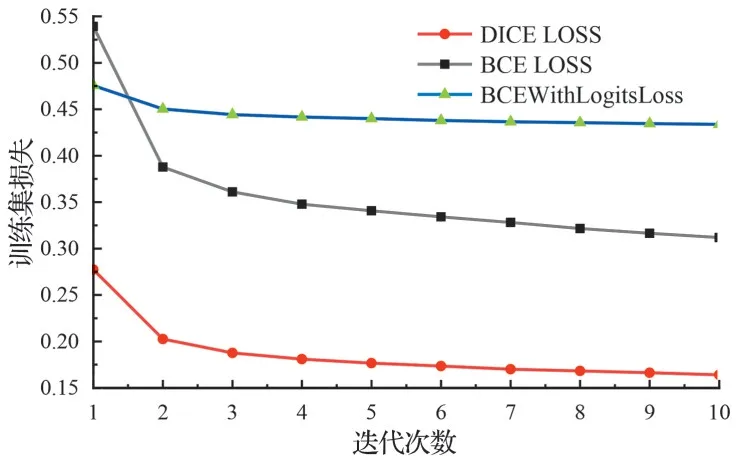
图6 训练集损失曲线Fig.6 Loss curves of training set
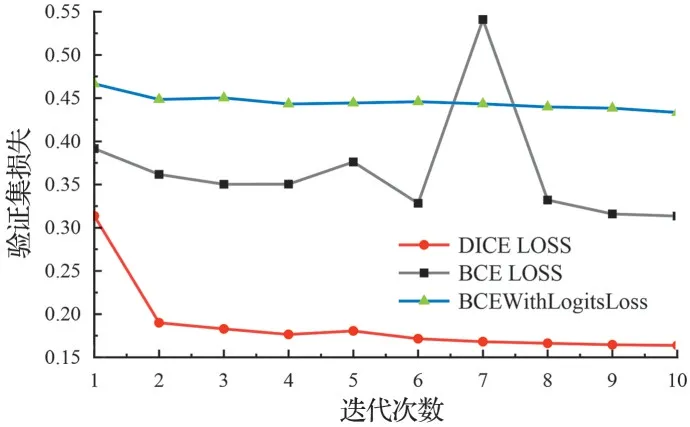
图7 验证集损失曲线Fig.7 Loss curves of verification set
3.4 测试模型性能
采用构建的SegCracks 数据集对搭建的MUnet 网络进行训练,经过50 次迭代后,网络损失值变化曲线如图8 所示,可以看出,迭代35 次以后损失值变化波动趋于稳定,网络开始收敛,且验证集准确率小于训练集准确率,未产生过拟合现象。IoU_Score 变化曲线和F1_Score 变化曲线如图9 和图10 所示,量化结果如表3 所示,提出的网络在训练集和验证集上获得的IoU_Score 分别为97.34%和96.10%,F1_Score 分别为98.65% 和97.99%,在SegCracks 数据集上取得了较好的裂缝分割结果,表明所提出的网络模型具有良好的性能。使用完成训练后保存的最优网络权重对测试集进行测试,结果表明分割一张裂缝图像所需时间为0.211 s,满足了实际工程应用中对实时性的要求。

表3 网络评价指标结果Table 3 Results of network evaluation indicators

图8 损失值变化曲线Fig.8 Variation curves of loss value
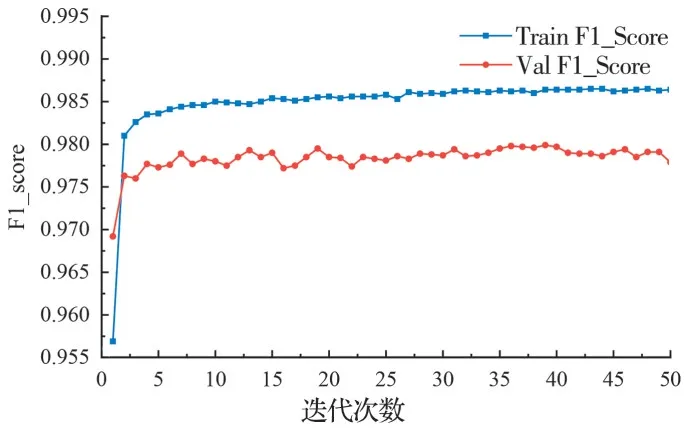
图10 F1_Score 变化曲线Fig.10 Variation curves of F1_Score
3.5 不同模型性能对比
将搭建的M-Unet 网络与U-Net、FCN8 和SegNet 主流语义分割网络模型进行对比分析,采用建立的数据集进行训练,经过50 次迭代后4 种网络的评价指标如表4 所示,模型权重文件大小和每轮迭代所需时间如图11 所示。由图11 可知,FCN8 网络模型权重文件较大且运行时间长,难以应用于现场检测移动端平台并满足实时检测的需求,SegNet网络虽然权重文件最小,但其迭代时间和预测时间均比M-Unet 网络长,且裂缝分割效果不如U-Net 网络和M-Unet 网络。搭建的网络迭代时间最短,相比于U-Net 网络,由于M-Unet 网络采用改进后的MobileNet_V2 替换了原U-Net 网络中参数量巨大的下采样部分,使得权重文件大小减少了7%,迭代时间缩短63.3%。
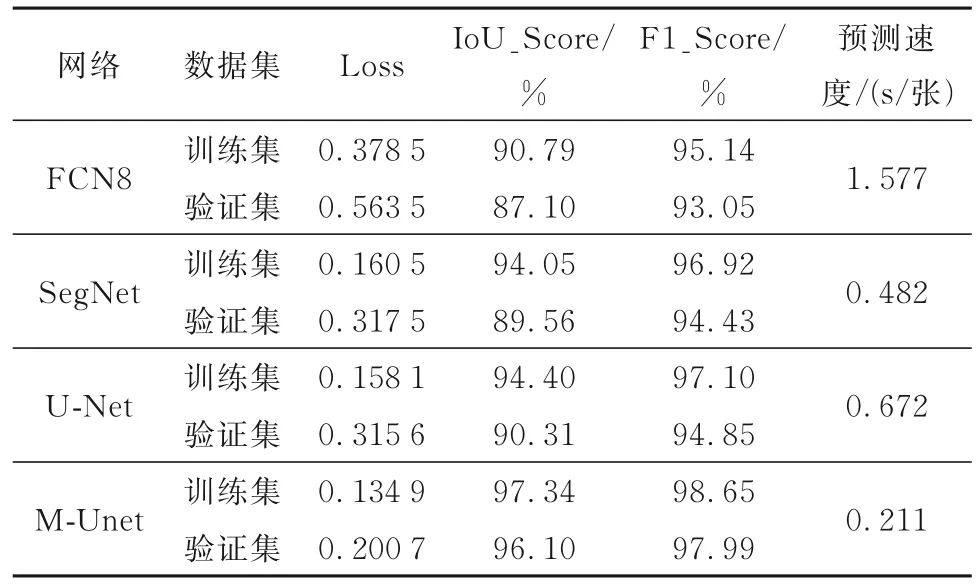
表4 不同网络结果对比Table 4 Comparison of results for different networks
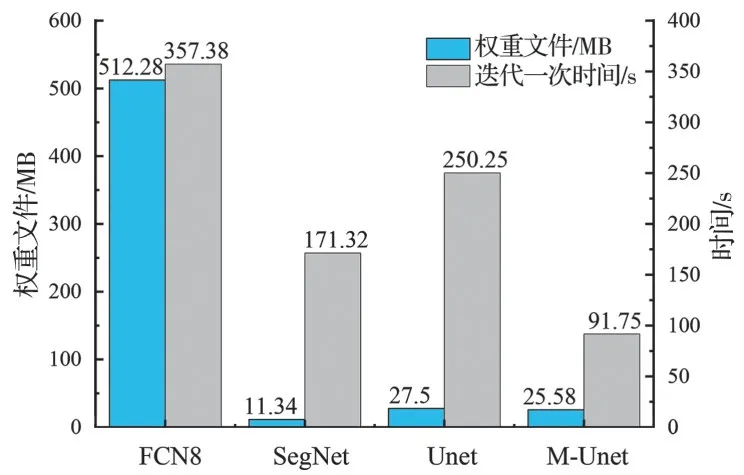
图11 权重文件大小及迭代时间Fig.11 Weight file size and iteration time
由表4 可以看出,在4 个网络模型中,M-Unet网络在训练集和验证集上的IoU_Score 和F1_Score均最高,网络损失值最小,对裂缝的语义分割效果最好,且对裂缝的预测时间最短,分割一张裂缝的时间仅为SegNet 的43.88%、U-Net 的31.40%、FCN8 的13.38%。与未改进的U-Net 网络相比,M-Unet 网络在测试集上分割一张裂缝图像时间仅需0.211 s,比U-Net 缩短了68.6%,且IoU_Score和F1_Score 有较大的提升,在训练集上分别提升2.94%和1.55%,在验证集上分别提升5.79%和3.14%。综上,M-Unet 网络在实现模型轻量化的同时提升了对裂缝的分割精度,验证了改进方法的有效性。
除与几种主流深度学习语义分割网络进行对比外,还将传统图像处理方法中基于Prewitt 算子、Canny 算子、Sobel 算子3 种边缘检测方法[18]以及大津阈值法Otsu[19]与网络分割结果进行对比分析,不同方法的裂缝分割效果如图12 所示。由图12 可以看出,传统图像处理方法受噪声影响较大,分割结果中噪声干扰点较多,其中大津阈值法Otsu 受噪声和光照不均的影响最大,只能分割出部分裂缝,漏检问题较严重,难以满足实际需求。基于边缘检测方法能分割出裂缝大致形状,分割效果优于大津阈值法,但抵抗噪声能力差,分割结果中也存在较多噪声点,裂缝分割效果一般。其中基于Canny 算子在分割细小的裂缝时难以保证裂缝边缘的连续性,存在部分漏检问题。相比于以上4 种传统图像处理裂缝分割方法,基于深度学习的M-Unet 网络通过堆叠多层卷积层,可更好地提取裂缝更抽象的和更高层的特征,能够获得丰富的裂缝信息,且具有较强的去噪能力,提出的M-Unet 网络分割结果中仅有极少量的噪声干扰点,且裂缝的连续性好,边缘分割结果清晰,表明该方法具有比传统图像处理方法更好的裂缝语义分割效果。

图12 不同方法语义分割结果Fig.12 Semantic segmentation results of different methods
3.6 不同数据集上交叉验证
为进一步验证网络的性能,在 CFD、CRACK500 和GAPS384 三个开源数据集上进行交叉验证。3 个数据集上包含多种不同背景,不同噪声和不同形态特征的裂缝,契合混凝土结构服役运营期间所处的实际环境。M-Unet 网络在3 种不同数据集上的模型评价指标如表5 所示,其中IoU_Score 均达到了97%以上,F1_Score 均达到了98%以上,表明优化后的M-Unet 网络在新的数据集上也能获得很高的裂缝分割精度,具有良好的鲁棒性和泛化能力,可满足实际工程对裂缝检测的需求。

表5 交叉验证结果Table 5 Results of cross validation
4 结论
针对混凝土结构裂缝检测量大、噪声干扰多和检测时间较长等问题,提出M-Unet 轻量级裂缝语义分割网络,实现了对混凝土裂缝图像在像素级上的分类,并进行多组对比实验,得出以下结论:
1)构建包含5 160 张裂缝图像的SegCracks 数据集,并基于此训练集对M-Unet 网络迭代优化,优化后的M-Unet 网络获得IoU_Score 为96.10%,F1_Score 为97.99%,对裂缝的分割效果优于主流语义分割网络U-Net、FCN8 和SegNet,且在保持高检测精度的同时大幅降低模型权重文件体量和减少裂缝分割时间。
2)M-Unet 通过将改进MobileNet_V2 轻量级网络替换U-Net 的编码器部分,与原始U-Net 相比,在实现模型轻量化的同时提高裂缝的分割精度,使得权重文件大小减少了7%,迭代一轮时间缩短63.3%,预测时间缩短68.6%,在验证集上获得的IoU_Score 和F1_Score 分别提升5.79%和3.14%,证明了改进方法的有效性。
3)与传统的图像处理方法相比,提出的M-Unet网络对混凝土裂缝语义分割具有更强的抗噪性,且裂缝分割结果连续性好,边缘清晰,很好地契合了裂缝的实际走向和形状。
4)将M-Unet 网络在CFD、CRACK500 和GAPS384 三个开源数据集上进行交叉验证,获得的IoU_Score 均达到了97%以上,F1_Score 均达到了98%以上,表明搭建的网络具有精度高、鲁棒性好和泛化能力强等优点。
