基于机器学习的高强钢焊接等截面箱型柱整体稳定性预测方法
2024-04-11张营营徐浩陈培见马俊周祎
张营营 ,徐浩 ,陈培见 ,马俊 ,周祎
(1.中国矿业大学 a.力学与土木工程学院;b.江苏省土木工程环境灾变与结构可靠性重点实验室,江苏 徐州 221116;2.中国建筑第八工程局有限公司南方分公司,广东 深圳 518035;3.西南交通大学 土木工程学院,成都 610031)
近年来,随着建筑产业的高速发展,人们开始建造更多大跨度、超高层、大重量的建筑物。高强钢材料具有更高的屈服强度和抗拉强度,能代替普通强度钢作为大跨高层建筑的建筑材料来达到节约钢材、减少造价、提高建筑效率等目的。随着高强钢产量需求的增加,高强钢构件的受力性能需要进一步研究[1]。高强钢轴心受压构件受力性能中的稳定性一直是高强钢应用和研究的重点。近年来,很多学者进行了高强钢构件的整体稳定性研究。薛加烨[2]、邱林波等[3]对460、550、690 MPa 的箱型和H 型截面构件进行轴压试验,并验证了高强钢构件整体稳定承载力相对普通强度钢的优越性;赵金友等[4]对跨中无侧向支撑的3 个双轴对称和6 个单轴对称焊接工字形截面简支梁进行了整体弯扭屈曲试验以研究Q460 高强钢焊接工字形截面简支梁的整体稳定性能并对《高强钢结构设计标准》[5]中的简支梁整体稳定系数计算公式进行修正。Meng 等[6]对结构钢圆形空心截面(CHS)梁柱的整体屈曲性能展开试验与数值模拟研究,并对欧洲规范中拟议的设计方法进行了可靠性评估。学者们在对高强钢构件的整体稳定性进行研究时,大多采用有限元分析或现场试验的研究方法,无论从时间成本还是从人力成本上考虑,这两种方法都在实际研究中都有不便之处。因此,有必要探寻一种高效且准确的高强钢构件整体稳定性能预测方法。
作为人工智能领域分支之一的机器学习方法凭借其优秀的预测精度、便捷的建模流程及可靠的理论支持,在土木领域迅速兴起,并在建筑构件的性能预测问题上表现优异。Limbachiya 等[7]利用人工神经网络(ANN)预测蜂窝梁的腹板屈曲后剪切强度,验证了人工神经网络模型准确性的同时说明了机器学习预测模型与现有的设计规范模型相比性能更优;Wakjira 等[8]对比不同的机器学习预测模型性能以提出织物增强水泥基加固梁的最佳预测模型,并对现有相关规范准则模型进行评价;Sarothi 等[9]首次编制了包含443 个实验数据集组成数据库,结合机器学习预测结构钢双剪螺栓连接的承载强度,并对其特征重要性进行分析,验证了钢材极限屈服强度比和螺栓排数对连接强度的影响显著。机器学习能从海量数据中提取其中特征并寻求特征间的规律来达到数据预测的目的。当遇到的任务非常复杂或者需要通过计算机自动调整时,就需要借助强大的机器学习技术来完成[10]。但用于预测高强钢构件整体稳定性的机器学习预测模型还尚待研究,且针对带有初始缺陷的高强钢构件的整体稳定性问题尚缺乏可靠规范进行指导。
笔者研究开发高强钢焊接等截面箱型柱整体稳定性的机器学习预测模型,对不同强度的高强钢焊接等截面箱型柱,使用纤维模型算法创建数据库,参考现有钢结构设计规范中对钢结构整体稳定性的描述;将构件总宽度、翼缘厚度、计算长度、初始缺陷值、屈服强度、正则化长细比、宽厚比、弹性模量这8 个参数作为输入参数;以构件极限承载力作为输出参数,并对比分析3 种优化后的常用的机器学习模型的预测结果。通过评价指标评选出最优预测模型并验证机器学习模型相较于现有规范中经验模型的优越性。最后,通过解释性算法对机器学习预测模型做出解释,在验证模型准确性的基础上,根据解释内容结合规范及已有研究验证模型的合理性。
1 训练数据库的建立
1.1 纤维模型简介
通常来说,对机器学习预测模型进行训练时需要一个数据可靠且数据容量足够大的数据库,以便机器学习模型进行训练、验证和测试。常见的构建数据库的手段包括有限元模拟、现场试验以及搜集已发表论文中的成果数据。有限元的数值模拟方法虽然得到的数据足够精确,但存在建模困难,耗时较长等问题。现场试验数据获取不仅需要耗费大量人力和时间进行试验,且得到的数据可能会因为试验环境等问题产生噪声数据。由于数据库的数据需求量较大,搜集大量论文中的已有试验成果数据同样费时费力。
纤维模型的基本思想是将构件长度方向的截面划分为网格状的矩形纤维再通过数值积分的方法进行计算。该方法需要分别建立截面内力、外力和变形之间的关系。综合考虑力的平衡与变形的协调来逐步得到荷载-位移曲线及其数值计算结果。该方法存在4 个基本假定:不考虑局部屈曲和横向扭转屈曲、不考虑剪力影响、平截面假定、构件屈曲后变形曲线为正弦曲线的半波[11]。高强钢焊接箱型柱纤维模型的本构模型在相关文献中有所体现[12]。由于残余应力对轴向受压结构的屈曲行为有较大影响,所以纤维模型计算时将考虑班慧勇等[13]提出的焊接箱形截面统一残余应力模型。
根据班慧勇等对于高强钢焊接截面残余应力统一分布模型的研究可知,高强钢焊接箱形截面的残余应力分布存在如下特点:1)板件中心一定区域存在均匀分布的残余压应力,而焊缝附件区域存在残余拉应力。2)焊缝附近区域的最大残余拉应力远小于钢材屈服强度,靠近角部的残余拉应力数值相对偏小。3)板件中部区域的残余压应力随板件宽厚比增大而明显减小。根据班慧勇等[13]的研究结果,钢材焊接箱形截面的残余应力分布可以简化为如图1 所示的阶梯状分布形式在纤维模型中使用。
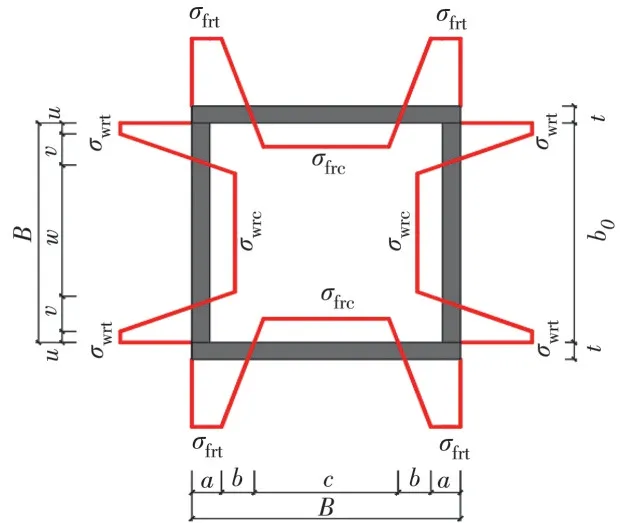
图1 统一残余应力模型Fig.1 Unified residual stress model
考虑到纤维模型在运算速度、建模难度方面的显著优势,很多学者都将纤维模型方法应用于高强钢构件的研究中[14-15]。此外,纤维模型在分析高强钢整体稳定性能方面的适用性与优越性均已经得到了验证,有学者通过对比实验确定了纤维模型对高强钢构件整体稳定性预测结果与实际试验值的平均误差仅为9.49%[16]。纤维模型方法不仅能够快速构建容量足够的数据库,其中的数据质量也能得到保证。因此,采用纤维模型方法作为数据库的主要构建方法,构建了548 组样本数据供模型进行训练。
1.2 参数选取说明
考虑到钢构件的轴心受压承载能力能直观反映构件的整体稳定性,因此,选取构件在荷载作用下的极限承载力作为输出参数。
根据现行《高强钢结构设计标准》(JGJ/T 483—2020)[5]可知,钢构件的极限承载力与构件总宽、总高、翼缘厚度、腹板厚度、计算长度、面积、惯性矩、回转半径、屈服强度、长细比、正则化长细比、宽厚比、弹性模量、初始缺陷等均有关联,因此,将上述参数作为输入参数构建纤维模型数据库。在通过数据库训练数据之前,采用Pearson 相关系数法对输入参数的相关性进行分析,从而筛选掉相关性过大的参数(Pearson 系数大于0.8)。上述涉及参数的相关性分析结果如图2 所示。
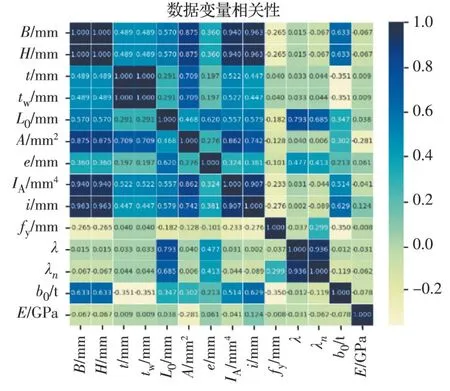
图2 数据变量相关性统计Fig.2 Correlation statistics of data variables
方格颜色越深,数字越接近1,代表数据间的相关性越大。由于是对高强钢焊接等截面箱型柱进行研究,其对称的特征也极大程度体现在部分几何参数和材性参数中,所以相关性分析剔除掉了对称数据中的某一方,例如,构件总高和总宽相等,两者只选构件总宽数据作为输入参数即可。依据相关性分析结果,最终选定构件总宽、腹板厚度、计算长度、初始缺陷值、屈服强度、正则化长细比、宽厚比、弹性模量这8 个参数作为输入参数。
此外,在构建数据库时,还要注意保证训练样本参数数据在一定范围内的离散性,只有训练参数足够离散,才能使得机器学习模型的预测结果是考虑到所有的输入参数得到的。数据集中特征参数的基本信息如表1 所示。
2 基于机器学习和规范准则的模型
2.1 机器学习模型
机器学习(ML)模型是从一些不基于物理定律的数学方程发展而来的。机器学习模型训练、验证所依赖的数据库均为上文提到的纤维模型数据库。借助MATLAB 软件,使用随机森林回归(RF)、高斯过程回归(GPR)和人工神经网络(ANN)这3 种ML 模型进行训练,其中包括两个单一模型和一个集成模型。在之前的研究中,大部分研究者只考虑了一种机器学习算法对于构件性能预测的优越性,主要是人工神经网络[16-18]。然而,所有的ML 模型都有其优点和缺点,面对不同输入参数及不同数据特征的构件性能预测问题,最适用的ML 模型并不唯一。因此,有必要对众多的ML 模型进行择优选取。选择最合适的ML 模型的方法就是基于评价指标的试错过程。选取的3 种机器学习方法在常规机器学习算法中属较新研究成果,且在其他类型构件性能的预测中也有良好表现。其他诸如SVM、线性回归等简单机器学习方法,作者也进行过预训练,但效果远不如所述3 种方法,因此,仅对上述3 种机器学习方法进行分析研究。
模型优化方面,采用k-折叠交叉验证方法以避免训练过程中出现过度拟合的情况。k-折叠交叉验证就是将数据集随机平均分为k份。轮流取其中1份作为测试集,其余数据作为训练集进行试验。k值的选择通常是5 或10[19-20],当数据库内样本足够多时,k取5 即可。超参数调整是模型优化的一项重要工作,其目的是全面搜寻使得模型预测误差最低的超参数或超参数组合。在一些优秀的超参数算法提出之前,超参数只能通过人工调整、不断试错的方法进行调优,但此种方法不仅效率低下,得到的超参数组合也不一定能使得模型性能得到显著提升。目前常见的实现自动化超参数调优的算法有网格搜索、随机搜索和贝叶斯优化。相较其他两种算法,贝叶斯优化算法的迭代次数较少,算法效率也相对较高,因此,使用贝叶斯优化方法进行超参数调优。贝叶斯超参数调优算法流程如图3 所示。图4 展示了模型的均方误差随着贝叶斯优化迭代次数的增加逐步降低,同时模型训练性能逐步提高的趋势。在第10 次迭代之后,模型性能趋于稳定。
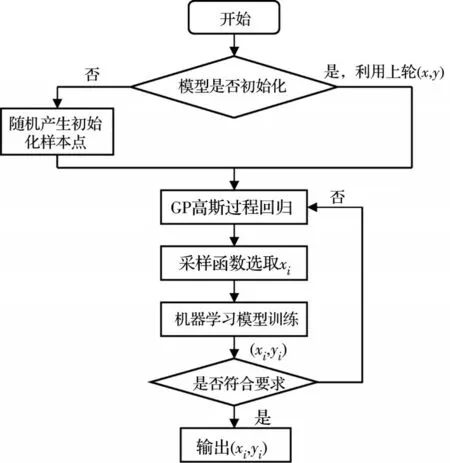
图3 贝叶斯优化超参数原理Fig.3 Bayesian principle of optimizing hyperparameters
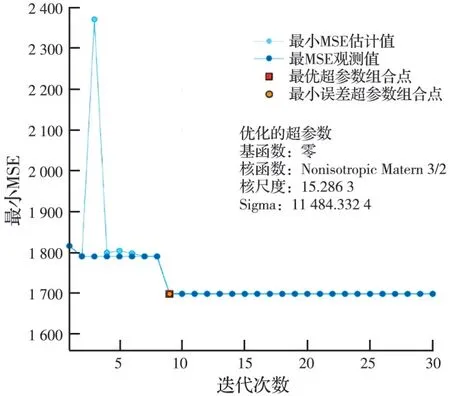
图4 高斯过程回归模型超参数调整过程Fig.4 Super parameter adjustment process of gaussian regression model
2.1.1 高斯过程回归
高斯过程回归(GPR)模型预测步骤如图5 所示。高斯过程属于一种特殊的二阶矩随机过程。通常认为,自变量和因变量在有限维度下的概率分布都满足一维或多维联合高斯正态分布。多维高斯联合分布由它的均值向量E(x)和协方差矩阵cov(x)所决定[21]。GP 模型是服从联合高斯分布的有限个随机变量的集合,确定均值函数和协方差矩阵就能完整地确定一个高斯过程的性质。协方差函数作为衡量数据点相互影响的标准,是统计分析中的重要指标之一,该函数表示两个变量之间的协调变化率。常用协方差函数包括平方指数、Matern、各项同性指数等。该尺度的存在决定了具有一定差异的输入特征是否被视为近似特征。此类超参数同样被贝叶斯优化器所考虑,并进行优化组合。
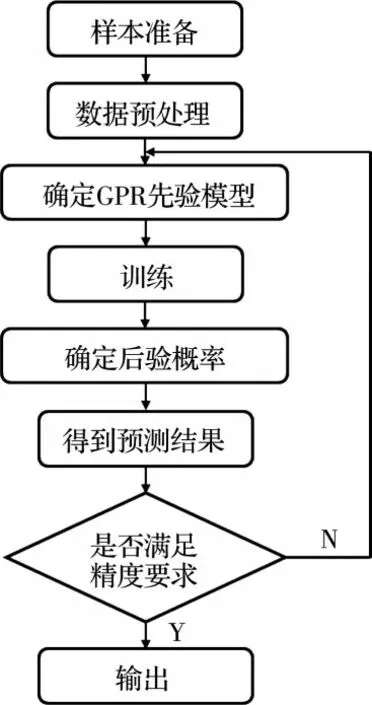
图5 高斯过程回归流程图Fig.5 Gaussian process regression flow chart
2.1.2 人工神经网络
人工神经网络(ANN)是一种模拟生物神经系统的深度学习算法。算法的每个处理节点被称为神经元或节点。单个节点可以接收多个信息的输入,但只返回一个输出信息。从输入到输出的过程需要引入激活函数来提高神经网络的非线性表达能力。在神经网络中,每个神经元都被赋予一个权重值,权重值的变化同样影响着神经网络的性能,通过迭代训练样本可以不断调整神经元的权重值,当预测值与实际值之间的误差达到最小值,则迭代停止。
输入层和输出层之间的层称为隐藏层,图6 即为单层隐藏层神经网络示意图。除此之外,针对不同的数据特征,神经网络中隐藏层与神经元的最优设计数并不一样。这些难以确定的超参数除了采用排列组合的方法试错外,还可以通过超参数调优方法快速找到相对最优解。
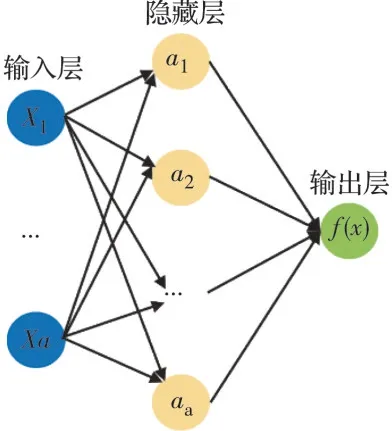
图6 单层隐藏层神经网络示意图Fig.6 Schematic diagram of single hidden layer neural network
2.1.3 随机森林
随机森林是基于决策树模型的一种集成算法,决策树是一种非参数规则的算法,将一组数据点的特征空间进行划分,使得每一小块空间区域都具有相似的响应值。决策树中的内部节点可以针对输入数据的某一特征进行判断,当局部节点无法再根据特征进行分类时,则生成叶节点代表测试后的输出。位于决策树最高处的根节点则代表了数据中最重要的特征。简单决策树模型示意图如图7所示。

图7 简单决策树模型示意图Fig.7 Schematic diagram of simple decision tree model
单一的决策树模型通常会存在过度拟合的情况,且具有较高的方差。为了缓解这个问题,以决策树的分类回归思想为基础,衍生出很多集成算法。集成学习方法将多个训练好的基本学习器通过一定的策略进行结合,最终形成性能可靠的强学习器来进行预测,集成模型框架如图8 所示。
随机森林模型就是以决策树为基本学习器的一个集成学习模型。如图9 所示,它包含多个由Bagging 集成学习技术训练得到的决策树。最终的预测结果由众多具有较大差异的决策树的输出结果共同决定。随机森林中的学习器个数与模型的学习效率和学习效果直接相关,而学习器数量变化对两者的影响呈现相反的表现趋势,此外,叶子节点上应有的最少样例数会决定模型是否更容易遭受噪声数据的影响。诸如此类难以确定又对模型质量有着重要影响的超参数将由贝叶斯优化自动确定,以使得模型性能达到其能力范围内的较高水准。
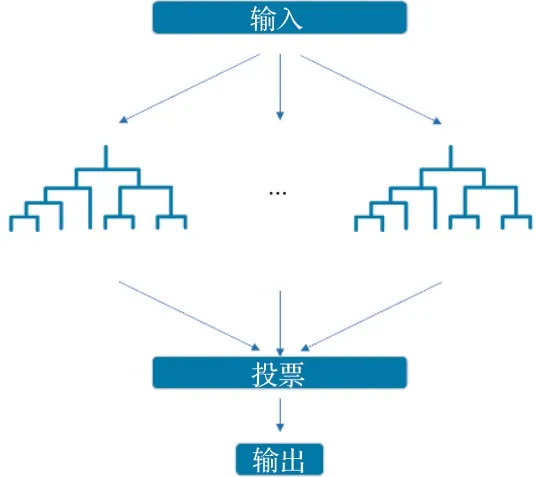
图9 随机森林模型示意图Fig.9 Schematic diagram of random forest model
2.2 中国规范
在中国《高强钢结构设计标准》(JGJ/T 483—2020)[5]中,轴心受压构件的极限承载力可由式(1)计算。
式中:φ为稳定系数。
稳定系数φ可根据截面类型、长细比和钢材屈服强度查询规范中附录表获得。在最新的高强钢设计规范中,箱型截面的高强钢构件在板厚小于40 mm时,统一按b 类截面设计;当板厚不小于40 mm 时,若板件宽厚比大于20,按b 类截面设计,否则按c 类截面设计。截面分类方式的变化也是高强钢设计规范与普通钢设计规范中的主要区别。
3 模型性能评价指标
为了研究开发的ML 模型的预测能力,将使用常见的不同性能指标评估模型的性能,包括决定系数R2、均方误差MSE、均方根误差RMSE 和平均绝对误差MAE。
1)决定系数
决定系数又被称为R2分数。记Sres=∑(Yi-)2,表示真实值与预测值之差的平方和即残差平方和。Stot=∑(Yi-)2表示真实值与其平均值之差的平方和即总离差平方和。
决定系数所展示的是模型的拟合程度。模型拟合程度越高,输入参数对输出参数的解释程度越高,观察点在回归直线附近就越密集。决定系数的取值范围在0~1,越接近于1,说明模型的预测效果越好;越接近0,说明模型的预测效果越差;若决定系数出现负值,说明该模型的效果非常差。
2)均方误差与均方根误差
均方误差(MSE)又被称为L2 范数损失。是用来计算每一个样本的预测值与真实值之差的平方,然后求和再取平均值。其值越小说明拟合效果越好。均方根误差就是在均方误差的基础上再开方。
3)平均绝对误差
平均绝对误差(MAE)又被称为L1 范数损失,用于计算每一个样本的预测值和真实值的差的绝对值,然后求和再取平均值。用于评估预测结果和真实数据集的接近程度,其值越小,则说明预测模型预测性能越好。
4 模型验证与分析
4.1 模型预测结果的对比
选取4 个评价指标,评估中国现有规范中的经验模型和3 种常见机器学习模型对高强钢焊接等截面箱型柱整体稳定性的预测性能,并将相关数据进行汇总。然而,模型在训练时的表现并不能代表其在模型测试时的表现,需要加入模型在测试集上的表现来对模型进行全面的评判。因此,采集了约70组中国学者对高强钢焊接截面柱整体稳定性进行研究的真实试验数据[2,22-24],整理了其中25 组相关数据,见表2,并增加了模型对新的测试集数据的预测情况来进一步验证模型性能与数据集质量的优劣,这些用于测试的数据需要保证未在模型的训练过程中出现。
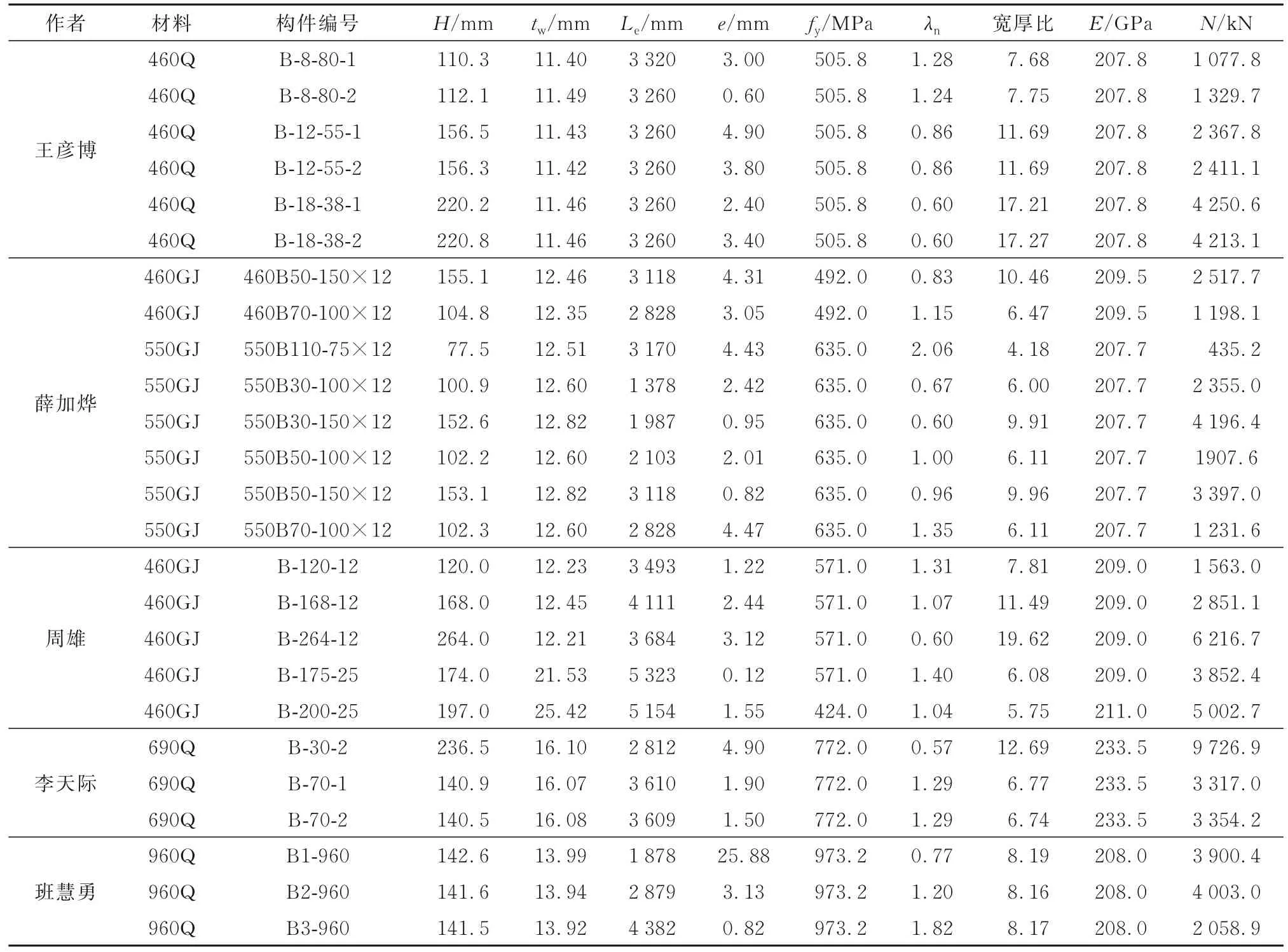
表2 高强钢焊接箱形截面柱轴心受压承载力试验数据Table 2 Test data of axial compression bearing capacity of high strength steel welded box section columns
表3 同时记录了模型训练时的评价指标情况以及机器学习模型或现有规范准则模型在测试集数据上的表现。《高强钢结构设计规范》(JGJ/T 483—2020)[5]所用模型的决定系数为0.83,RMSE 值达到了1 176.6 kN,MAE 也高达861.57 kN。模型预测精度在±861.6 kN,超出了测试集数据中平均极限承载力(3 149.4 kN)的27.3%。随着钢材免屈服强度的增大,设计规范模型逐渐表现出不适用性,且预测结果偏大。通过查阅相关文献,可以对此现象做出解释,部分学者在对高强钢焊接截面柱整体稳定性能的研究中得出以下结论:采用中国规范设计时,对于宽厚比小于20 的Q690 箱形柱,可选取a 类柱子曲线[23];Q890 和Q960 钢材焊接箱形轴压构件板厚小于40 mm 时应按a 类曲线进行设计,区别于规范中建议使用b 类曲线计算[24]。以上结论说明中国现有规范对于高强钢轴心轴压构件的截面分类并不完全准确。且规范公式的提出考虑了设计师们进行设计时的便捷性,通常是有过简化处理的。上述原因导致现行规范在预测时的缺陷。

表3 预测模型性能比对Table 5 Performance comparison of prediction models
反观机器学习预测模型的表现,机器学习预测模型中的高斯过程回归模型整体表现明显要优于现有规范准则模型。其在训练过程中的RMSE 值为41.21 kN,MAE 值为23.59 kN,决定系数为1.0。而在对测试集数据预测过程中,其RMSE 值为265.13 kN,MAE 值为163.17 kN,决定系数高达0.99,平均误差率仅有5.6%。
由表3 可见,机器学习模型对高强钢焊接等截面箱型柱的整体稳定性的预测效果相较现有规范有明显的提升。但随机森林模型在此类问题的预测上表现很差,在训练过程中的决定系数为0.93,在测试集数据预测中决定系数仅有0.75。以决策树为基本学习器的集成算法预测效果较差的原因可能是决策树模型的决策边界可能并不准确且决策树算法对个别数据比较敏感,进而导致其集成模型的效果在回归预测上的表现很差。
对于机器学习预测模型在测试集上的表现相对模型训练时普遍变差的问题,机器学习领域专家认为这是由于机器学习模型泛化能力不佳导致的,可通过调整超参数、使用K 折交叉验证、归一化数据等手段降低其影响,笔者研究中也有所涉及。其他的数据集本身的原因包括:1)纤维模型构建的数据库样本与实际工程情况本就有着10%左右的误差;2)在数据库的构建过程中,初始缺陷考虑得并不全面;3)实际试验数据的部分参数超出了数据库样本参数大小范围约10%。能否对超出训练数据范围的数据进行准确预测也是模型泛化能力强弱的体现。以上原因导致了机器学习模型在预测测试集数据时的性能下降。在后续研究中,将进一步关注数据集和模型的质量来提高机器模型在测试集上进行预测时的表现。尽管如此,以高斯过程回归模型为代表的众多机器学习模型仍然展现出了优于现有规范准则模型及其他种类预测模型的性能。
图10 为数据集在3 个机器学习模型的中的真实值与预测值响应图,其中,蓝色的点表示训练集中已知的输出参数,即轴心受压极限承载力真实值。而黄色的点表示模型经过训练后根据输入参数得出的预测响应值,即轴心受压极限承载力预测值,当两点完全重合时,表示机器学习模型在该点处的预测精度很高,重合的点越多,机器学习模型性能越好。另一种能直观展现出机器学习模型预测效果的图是图11 所展示的残差图,当模型的性能足够优秀时其预测响应与真实值相差无几,在残差图中表现为所有预测点都接近于零线,从任意点到零线的垂直距离即为该点的残差。

图10 训练过程机器学习模型预测响应图Fig.10 Prediction response diagram of machine learning model in the training process
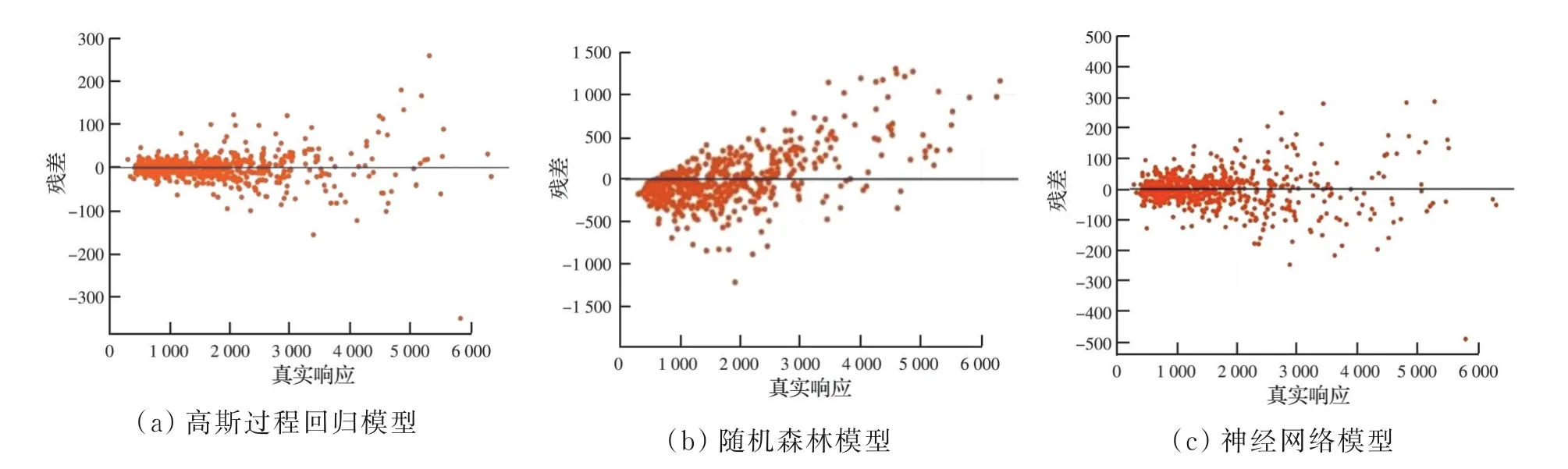
图11 训练过程机器学习模型残差图Fig.11 Residual diagram of machine learning model during training
综合所有ML 模型在模型性能可视化图中的表现可以看出,高斯过程回归模型和神经网络模型表现是这3 种模型中的较优模型。在预测响应图中,两种模型的预测点与真实点重合度很高;在残差图中,两种模型中各样本点的残差绝大多数都在100 kN以内,不超过训练样本平均极限承载力(1 780.75 kN)的6%。说明高斯过程回归模型和神经网络模型在训练过程中的优异性能。但结合表3 可以看出,在预测测试集中新的实际工程数据时,高斯过程回归模型的稳定性要略高于神经网络模型。因此,在高强钢焊接箱形截面柱整体稳定性的研究中,高斯过程回归会是常见机器学习模型中的最优模型,也是优于现有规范经验模型的选择。值得一提的是,高斯过程回归模型预测25 组真实实验数据时,仅耗费0.006 s,这样的计算效率显然要优于更加精细的有限元模拟方法,尽管有限元建模能够使模型的计算结果达到很高的精度,但其繁琐的建模过程和较长的计算时间使得效率更高的机器学习模型成为一种新的选择。
4.2 高斯过程回归模型的可解释性研究
模型可解释性是指对模型工作机制以及对模型预测结果的理解,机器学习模型的可解释性越高,模型的可信任度就越高。诸如支持向量回归等机器学习模型被称为“黑盒”模型,从这些ML 模型中探求输入参数和输出参数之的力学关系是很困难的。近年来,陆续有学者研究并提出了几种方法来提高ML 模型的可解释性。部分依赖图(PDP)和个体条件期望图(ICE)就是用于对ML 模型进行解释的常用可视化工具。
部分依赖图反映了在一个训练好的ML 模型中输入特征参数与输出响应参数之间的关系[25],通常包括线性关系、单调关系或者其他更复杂的关系。某个选定输入特征参数的部分依赖性定义为忽略其他输入变量的影响而获得的平均预测值,或者说部分相关性作为所选输入特征参数的函数,显示了所选输入特征参数对数据集的平均影响。各输入特征的PDP 图如图12 所示。
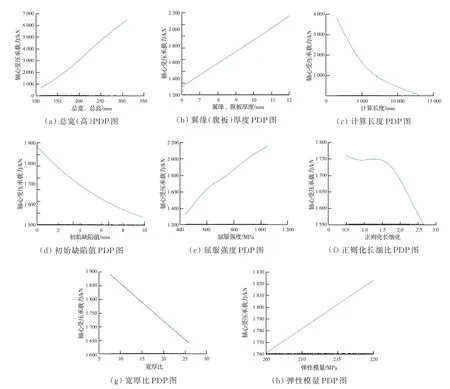
图12 8 种指 标的PDP 图Fig.12 PDP plots for eight indicators.
个体条件期望图作为部分依赖图的一种变体,代表了每个样本的输入特征参数和输出响应值之间的关系。部分相关性显示了输入和输出之间的平均关系,但ICE 图将平均关系信息进行了分解,并显示了每次观测时个体特征的依赖性[26]。
选择在上述研究中表现最好的高斯过程回归模型,计算并绘制该模型的PDP 图,以确定8 个输入特征参数与高强钢焊接等截面箱型柱极限承载力之间的关系。从图12 中的PDP 图可以看出,构件的总高(总宽)、翼缘(腹板)厚度、材料屈服强度、材料弹性模量与高强钢焊接等截面箱型柱的轴压极限承载力在一定范围内呈正相关。构件计算长度、初始缺陷值、正则化长细比、宽厚比与构件轴压极限承载力在一定范围内呈负相关。在对《高强钢结构设计规范》(JGJ/T 483—2020)[5]中关于钢结构轴压构件整体稳定性的相关规范公式进行分析后发现,机器学习模型做出的有关输入参数对输出参数影响趋势的解释均是合理的,这从侧面体现了机器学习模型内部运作的合理性。但大部分趋势都展现出线性或近线性,这与实际情况有所差距,这主要是由于训练样本数据中的输入参数范围有限,如果将数据集参数范围扩大,将会得到更加丰富且贴合实际的部分依赖图。在正则化长细比部分依赖图中可以看到更为明显的趋势特征,当λn小于1时,构件的极限承载力以较大的梯度下降,当λn到达1 时,构件承载力下降速度大大减缓而进入平台期,当λn大于1.5 后,构件承载力又恢复到λn数值较小时的下降梯度。
4.3 神经网络模型的特征重要性研究
使用Shapley Value 方法制作特征参数重要性可视化图像,一个特征的Shapley Value 是该特征在所有的特征序列中的平均边际贡献。使用效果较好的神经网络模型计算8 个输入特征参数的特征重要性,其可视化的表现见图13。然而,神经网络模型的预测结果会受其超参数的影响,因此,获得的特征重要性排序并非绝对,只作为建议来指导进行工程实际。

图13 特征参数重要性Fig.13 Importance of characteristic parameters
特征重要性分析表明,相对于其他输入参数,构件的正则化长细比、总高(总宽)、腹板厚度(翼缘厚度)、屈服强度是影响高强钢焊接等截面箱型柱轴心受压承载力的主要参数。由中国现有规范中对高强钢构件轴心受压的整体稳定性描述公式可知,高强钢构件整体稳定性与构件截面面积和材料屈服强度线性相关,而特征重要性分析中得到的重要参数恰好就包含了屈服强度和面积(面积可由构件总高与腹板厚度求得),这从双向验证了规范与机器学习模型都具备较高的合理性。相比之下,构件的初始缺陷和弹性模量对其极限承载力影响较小,这可能是由于数据库中初始缺陷取值均仅为构件计算长度的千分之一以下,取值偏小导致初始缺陷对构件极限承载力的影响不大。
5 结论
开发了两个单一模型和一个集成模型,用于预测高强钢焊接等截面箱型柱的轴心受压极限承载力以验证其整体稳定性。将3 种机器学习模型的预测性能和现有规范中的经验模型进行比较,并对最优机器学习模型进行可解释性研究。研究结果表明,机器学习技术在预测高强钢构件整体稳定性方面的可行性和高精度,并为将数据驱动模型纳入设计规范的修订和完善提供了重要参考。得到以下主要结论:
1)与其他ML 模型和基于物理的方程相比,高斯过程回归模型预测得到的结果最为准确,该模型对测试集数据预测的RMSE 值为265.13 kN,MAE值为163.17 kN,决定系数高达0.99。与25 组已有试验结果相比,平均绝对误差仅有5.6%。此外,随着未来数据库数据愈加丰富,参数数值包含范围愈加广泛,高斯过程回归模型的性能可以进一步提高。这项工作的结果证明了机器学习技术在预测高强钢构件整体稳定性方面的可行性和高精度,并为将数据驱动模型纳入下一代国际设计规范做出了引导。
2)根据模型的可解释性研究发现,作为最优机器学习预测模型的高斯过程回归模型,其中,输入参数对预测结果的影响趋势与现有规范准则中的经验公式一致,在证明了机器学习模型准确性的基础上又验证了模型的合理性。
3)根据输入特征参数重要性排序可知,正则化长细比、材料屈服强度以及和构件截面面积相关的几何特征是对高强钢轴心受压承载力影响较大的参数。这与中国现有规范准则中所述接近,而在机器学习模型的解释中正则化长细比作为对输出结果影响最大的重要参数参与预测运算。
4)机器学习模型应用于高强钢构件力学性能预测的工作中具有能够快速甄别关键参数与力学性能之间的关系优势,但现阶段其计算精度相较于精细的有限元分析尚有差距,且计算结果的合理性依赖于模型的选取和大量数据的收集,因此,现阶段成果仅作为高强钢构件力学性能分析的参考与借鉴。
