后疫情时代网络舆情情感分析和主题识别
2024-04-03李敏项朝辉
李敏 项朝辉


关键词: 后疫情时代;网络舆情;文本挖掘;LDA主题聚类;情感分析
0 引言
随着移动互联网的快速发展,网络已成为人们表达民意和交流情感的重要载体,推动了舆论和信息传播的网络化发展。网络舆情传播的特点在于速度快、意见集中等,近年来,各种突发公共卫生事件频发,舆论引导工作面临前所未有的挑战。其中,微博这一重要的社交媒体平台,涵盖了海量的用户观点和情感信息。用户在微博上的情感表达不仅能够影响微博内容本身的传播,还能够迅速感染其他用户,甚至可以在短时间内引爆话题,影响公众情感,如涉及人身安全、社会公平和性别对立等问题。
利用计算机技术自动快速地从海量微博文本数据中挖掘舆论热点和情感倾向,并能够快速地推断出事件的趋势和影响程度,对舆情研判和舆论引导具有重要的意义。因此,利用计算机技术进行微博情感分析对于社会舆情管理和研究而言,具有重要的意义和价值,可以为人们提供更全面、准确的情感信息,从而更好地了解公众的态度和情感倾向,做出针对性的决策和措施。
在社交媒体中,用户对舆情事件发表了大量的相关话题数据,为挖掘舆情演化提供了可能。主题挖掘技术和情感分析方法已经成为常用的文本挖掘手段。主题挖掘技术是指通过分析一系列文本数据,自动发现隐含在文本中的主题、词汇、情感以及其他有关内容的关联和模式的方法。经常被应用于分析社交媒体、新闻报道和其他类型的文本数据,可以帮助研究人员和企业了解人们的需求、偏好和态度等信息。Pu[1]提出了一种新的方法TDCS(Topic Distilling withCompressive Sensing),利用无监督方法和迭代法对少量文档关键词中隐含的主题进行建模和分析。曾莉等[2]通过LDA-Attention-BiLSTM模型分析微博某单位招聘热点事件的舆情演变过程,挖掘舆论热点和情感倾向。庄穆妮等[3]将LDA模型和Bert融合,改进后的模型精确度更高,能够有效地运用于大规模网络舆情演化仿真。张柳等[4]利用LDA构建新冠肺炎疫情事件下微博用户转发评论关系构建微博用户主题聚类图谱,提出网络社群间主题传播路径分析方法,发现衍生的舆情话题。
情感分析是文本挖掘领域的一个重要研究方向,旨在从文本数据中提取、分析、归纳和推理涵盖的主观信息,如观点、情感、评价和态度。这一领域始于21 世纪,并逐渐成为自然语言处理、机器学习等多个领域的研究热点。情感分析的研究对于理解和解释人们在文本中表达的情感和情绪具有重要意义。在情感分析中,常见的方法主要有以下3种:基于情感词典的情感分析、基于机器学习的情感分析和基于深度学习的情感分析。基于情感词典的方法通过匹配文本中出现的情感词与预定义的情感词典进行分析,从而获得文本的情感倾向。基于机器学习的方法依靠训练模型从大量标注数据中学习情感分类的规律,从而对未知文本进行情感分析。而基于深度学习的方法则通过构建深度神经网络模型,可以更准确地从文本中捕捉情感信息。因此,情感分析的研究和应用对于深入理解人们在文本中表达的情感,以及在舆情研判、社交媒体分析、品牌管理等方面具有重要意义。林伟[5]通过基于Bert多特征融合网络舆情情感识别模型,模型的精确率达到92.7%,有效地提升了舆情情感识别的性能。陈兴蜀等[6]用SnowNLP情感分析模型以及KMeans文本聚类算法等方法分析疫情事件中网络舆情的时空演化过程。吴小华等[7]提出了基于字向量表示方法并结合Selfattention和BiLSTM的中文短文本情感分析算法,在COAE 2014微博數据集和酒店评论数据集的情感分类效果有所提升。王彤等[8]基于SnowNLP模型对突发公共卫生事件发生后政务媒体的相关评论信息进行情感分析,将网民情感划分为形成期、爆发期和衰退期,并通过LDA主题模型,得出每个阶段的主题分类。
针对突发公共卫生事件发生后,社交媒体情绪识别和舆论热点的研究相对较少,本文以后疫情时代微博数据为研究对象,采用大数据技术对新浪微博用户发布的文本数据进行采集和分析,可以实时感知网民的情绪变化和关注热点,从而及时发现问题、深入分析原因。这种实时舆情监测为公共卫生事件管理和社会舆情管理提供了重要科学依据。
1 研究框架和模型构建
本文通过研究LDA模型、情感分析等方法对微博短文本数据进行分析,挖掘网民对后疫情时代情感态度的变化和舆情焦点。
1.1 情感分析
文本情感分析最初是针对带有情感色彩的词语的分析,也称为意见挖掘,是自然语言研究领域的一个重要方向。本文使用Python中的SnowNLP库对中文文本进行情感得分计算。SnowNLP库是基于Text?Blob开发的专门针对中文文本内容进行情感识别的方法。该库提供了一系列功能,包括情感分析、文本分类、文本摘要和关键词提取等。它使用贝叶斯分类器和隐马尔科夫模型,基于中文语料库进行训练和预测。该方法能够处理大量中文文本数据,并具有高准确性和高效率,经常用于舆情监控、评论分析和舆情分析等任务。
1.2 TF-IDF 模型
TF-IDF(Term Frequency-Inverse Document Fre?quency,词频-逆文档频率)是一种用于评估文档中词语重要程度的统计方法。它基于两个核心概念:词频(Term Frequency,TF)和逆文档频率(Inverse DocumentFrequency,IDF)。TF表示一个词语在文档中出现的频率,它将一个文档看作是一个词语的集合,TF可以帮助找出文档中重要的词语,因为频繁出现的词语往往具有更高的重要性。IDF表示一个词语在整个文档集合中的重要程度。IDF可以帮助找出在整个文档集合中唯一或者罕见的词语,因为这些词语往往能提供更多独特的信息。TF-IDF的计算公式如下:
其中,w 表示一个词语,D 表示一篇文档,N 表示文档总数,df (w) 表示包含词语w 的文档数,nw,D 表示词语w 在文档D 中出现的次数。TF-IDF值就越高,说明这个词在文本中的重要程度越高,TF-IDF模型能够帮助对文本进行特征提取、关键词提取等,从而有效地处理和分析大量的文本数据。
1.3 LDA 主题模型
Blei等[9]在2003年提出了潜在狄利克雷分布(La?tent Dirichlet Allocation,LDA) ,该方法是一种无监督学习模型,可以从一组文档中发现潜在的主题。LDA 模型假设每个文档是由多个主题混合而成的,而每个主题又由多个单词组成。LDA 模型中文档-主题和主题-词都服从多项分布,其先验概率是 Dirichlet 分布。通过观察文档来推断出这些潜在的主题和单词分布。运用机器学习方法统计词频生成主题单词和评论主题后构成的多层概率分布,进而实现文本聚类。
利用LDA模型进行文本主题聚类时,需要确定最优的主题数。困惑度(Perplexity) 常被用作评估聚类效果的指标,进而帮助调整主题数目,以达到最佳聚类效果。其计算公式如下:
其中,D 表示文档中所有词的集合,M 表示文档的数量,Wd 表示文档d 中的词,Nd 表示每个文档中d 的词数,P (Wd )表示文档中词出现的概率。通过计算困惑度,可以量化LDA模型的表现,并对主题数进行逐步调整,以获得最佳的主题聚类结果。它的数值越小,表示该主题模型的生成能力越强,即模型对于文本数据的拟合度越高。在确定LDA模型的最优参数时,可以选择困惑度较小且主题数相对较少的值作为最佳参数。通过这种方式,可以找到一个相对准确的主题聚类结果,避免了过多的主题数对于聚类结果的干扰。
1.4 本文研究框架
本文的研究框架主要包括数据采集、数据清洗、TF-IDF计算、主题聚类、情感分析这5个部分。
本文提出的主题提取与情感分析框架,如图1所示,具体包括5个部分:
1) 数据采集,利用Python采集新浪微博“疫情”相关话题数据;
2) 数据预处理,对采集的文本数据进行清洗,包括去重、分词以及去除停用词等;
3) 情感分析,使用SnowNLP进行计算情感得分;
4) TF-IDF 计算,找出文本数据中相对重要的词语;
5) 主题识别,使用LDA主题模型对文本数据进行主题聚类,并提取出每个主题的关键词。
2 实证分析
2.1 数据采集
本文以后疫情时代网民的情感和话题为研究背景,在新浪微博的“高级搜索”中以“疫情”为搜索关键词,爬取了2022年12月7日0时至2023年6月7日23 时相关微博数据。为了使数据样本尽量均匀分布,爬虫以小时为单位,对每小时微博搜索数据结果的前2 页进行采集,累计共获取73 229条,包含微博id、发布时间和微博文本。通过Python和Excel工具对数据去重和错误数据清洗,经过初步预处理后共得到72 492 条微博文本数据。
2.2 数据预处理
在微博文本分析中,由于存在大量的噪声数据,如表情符号、微博标签、语气词等,这些词语会对情感倾向判别和主题模型聚类效果。为解决这些问题,本文采用了Jieba工具进行分词,并融合了百度停用词库、哈尔滨工业大学停用词库以及新建的自定义停用词库,对分词后的文本进行清洗。通过对文本分词和停用词处理,消除一些没有实际语义意义的词语干扰,可以减少模型处理的数据量,提高情感倾向判别和主题模型效果的可靠性。
2.3 情感得分
本文采用SnowNLP库对去除特殊标点符号后的微博评论数据进行情感倾向分析,并按月份统计2022 年12月至2023年8月期间情感得分的平均值。情感得分的值介于0~1,越接近1表示情感越积极,越接近0则情感越消极。首先,利用SnowNLP方法计算所有评论数据的情感得分。随后,按月份对微博数据进行加权平均,计算每个月的情感分数。这样,能够了解整个时间段内网民情感的趋势和变化,结果如图2 所示。
根据对网民情感的观察,可以发现,整体上网民的情感波动较大,但总体呈现出正向积极的情绪倾向。在2022年12月,随着疫情的放开,网民情感得分达到最低点,情绪相对较低落。然而,随着时间的推移以及媒体在网络平台上发布有关疫情的相关知识,网民对疫情的认识逐渐加强,总体情绪呈现积极向上的趋势。然而,在2023年4月和5月,由于对小长假聚集、复阳等情况的担忧,网民的情绪值呈现出相对走低的趋势。
2.4 TF-IDF 模型
本文使用sklearn 中的TfidfVectorizer 方法,对词袋向量进行训练,并得到每个词语对应的TF-IDF值。通过对所有词语的TF-IDF值排序,可以得到词语的重要程度排名,从而帮助确定文本中关键的词语或者特征。表1是微博文本分词后统计TF-IDF的值排名前20的词语。
可以大致看出网民对于后疫情时代的主要关注点包括疫情发展和防控情况、复工复学、经济发展、未来生活期望等。为了能挖掘出更多有用信息,接下来利用 LDA 主题模型对微博文本聚类。
2.5 LDA 主题聚类
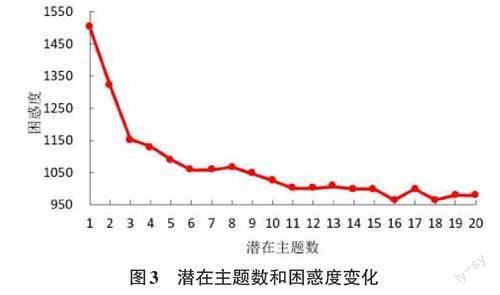
本文使用了基于sklearn开源的LDA模型,并采用Gibbs(Gibbs sampling)采样方法训练模型参数。在确定最优参数时,采用Perplexity方法,让主题数在区间[1,20]内进行迭代,计算困惑度的变化状况,以寻找最优的主题数。困惑度越低,表示模型的聚类效果越好。如图3所示,随着主题数的增加,总体困惑度呈波动下降的趋势。笔者发现,困惑度的局部极小值点出现在主题数为11时。随着主题数的增加,主题分析变得更加复杂,可能会导致模型过拟合,从而影响结果的准确性。通过选择一个适中的主题数,我们可以得到更合理和可靠的聚类结果。因此,本文将聚类主题数设置为11个,以获得更为稳健的聚类结果。
使用LDA模型聚类,得到不同主题的关键词,并概括主题关键词的内容,表2展现了不同主题下概率最高的前12个关键词。
从关键词看出,在后疫情时代,网民关注的焦点除了疫情发展情况外,还包括疫情防护和健康问题。随着疫情的进一步缓解,网民的关注重点逐渐转移到复工复产、旅游、校园生活和经济发展情况等方面。此外,社会热点问题也是网民关注的焦点。这些关注点反映了社会对于疫情后重建和恢复正常生活的渴望,以及对于各种社会问题的关切。
3 研究结论
本研究基于SnowNLP算法对后疫情时代网民的情绪倾向进行识别,并结合TF-IDF方法提取微博话题的关键词。通过应用LDA模型分析后疫情时代微博的舆论焦点,并利用困惑度評价指标确定最优的主题数。研究结果显示,随着2022年12月疫情放开,网民的情感得分达到最低。然而随着时间的推移,媒体在网络平台发布疫情相关的信息,网民的情绪总体呈现积极向上的趋势。此外,研究利用LDA模型提取了11个网民关注的话题,有助于政府部门进行舆情监管和舆情引导。当前,舆情情感分析的研究日益增多。本文中情感分类的方法仅将舆情评论的情感倾向划分为正向和负向,为了提高情感倾向识别的精确度,未来工作中可以使用深度学习方法,引入更多情感类别如中性情感或复杂情感。