基于改进YOLOv4的消防设施检测算法
2024-04-03耿鹏志吴富起王瑞叶向阳刘炜达王海
耿鹏志 吴富起 王瑞 叶向阳 刘炜达 王海


关键词:目标检测;消防设施;卷积神经网络;YOLOv4
0 引言
近年来,随着我国经济的增长,城市人口和建筑的持续增长,火灾预控愈发重要,但在发展的同时,火灾隐患增量却在逐步上升,部分火灾危害大、风险高[1]。消防安全作为政府、企事业单位以及居民生活的重要管理部分,加强消防工程的建设显得尤为重要。尽管如设立微型消防站、远程监控系统网格化管理等智慧消防工作建设如火如荼地开展,但在某些方面仍然存在欠缺,如专业人员匮乏、日常巡检巡查不到位、消防设施误报漏报及监管统计等问题[2],如何提升消防安全管理建设成为当下研究热点。
随着深度学习的发展,目标检测技术[3]已经得到了广泛应用,可以从图像中识别物体,获取图像区域内的信息数据,替代了枯燥乏味的工作[4]。目标检测在早期因受计算机资源限制,需基于滑动窗口或手工构建特征,但检测精度低,鲁棒性弱,代表作为尺度不变特征[5]、局部二值模式[6]、Viola-Jones检测器[7]或HOG 行人检测算法[8]。然而随着深度学习的发展,该技术取得了质的突破,由传统的人工特征转为数据驱动,不仅成了学术界的研究热点,还为工业界带来了巨大的利润。目前目标检测按照是否存在顯式区域可主要分为两种,即One-stage 和Two-stage 两类,Onestage方法是一种基于回归目标检测算法,对整幅图片直接进行检测,不生成区域,代表性算法有YOLO[9]和SSD[10]等。Two-stage方法是将检测问题转化为对目标局部区域内容的分类,代表性算法主要有R-CNN[11]、Fast R-CNN[12]和SPP-Net[13]等。
目前我国的消防安全管理仍有很大的不足,如检测统计仍采用手工等方法,缺乏智能化辅助功能。2017年公安部消防局印发《关于全面推进“智慧消防”建设的指导意见》[14]提出,要加速推进现代科技与消防工作的深度融合。在此背景下,提升消防管理能力迫在眉睫,针对于建筑图纸中消防设施自动识别算法应运而生。
本文的主要贡献如下:
1) 构建建筑图纸消防中设施数据集,用于图纸中消防设施识别等研究工作。
2) 将目标检测应用于建筑图纸中消防设施的检测,提出一种基于YOLOv4[15]的检测算法,实现了自动检测和识别功能。
3) 对模型进行了改进,使其适合当前任务检测。首先通过实验选取合适的特征提取层,其次采用ASPP[16]扩大模型感受野,提升模型的特征提取能力,最后对Mosaic数据增强算法进行了超参数实验,使模型学习到更多鲁棒性特征。
1 基于改进YOLOv4 的消防设施检测算法
目标检测作为计算机视觉领域的基本任务,可从图像和视频中提取出所需要的信息,在学术和工业领域中得到了广泛应用。YOLO作为该领域内的著名模型,是一种单阶段目标检测算法,能够直接对图像进行计算并完成分类(Classification) 和定位(Localization) 两类任务。
1.1 YOLOv4模型
YOLOv4 是基于 YOLOv3 改进的一种单阶段目标检测网络模型,由Alexey Bochkovskiy于2020年提出。作为对YOLOv3 的改进,该模型融合了Weighted-Residual-Connections(WRC)、Self-adversarial-training(SAT)和Cross-Stage-Partial-connection(CSP)[16]等多种深度学习技巧,作者又进行了大量实验,在输入网络分辨率、卷积层数量等参数量之间找到了最佳平衡,该网络由Backbone、Neck和Head三部分组成:即CSP?Darknet53 作为 Backbone, SPP[17]模块用于增大感受野;PANet作为Neck用于生成不同空间分辨率的特征图;Head仍沿袭YOLOv3,对Neck输出的特征图进行结果预测,确定先验框有无目标以及目标种类。然后根据位置参数对先验框调整得到预测框,最后筛选出置信度高于设定阈值的预测框,并通过非极大抑制获得分数最高的预测框作为最后检测结果,网络结构如图1所示。
1.2 本文所使用的算法
YOLOv4 的先验框和检测层的选择都是基于COCO[18]和PASCAL VOC[19]等公开数据集。但建筑图纸中的消防设施目标较小,且大小相对固定,在经过降采样后会出现语义信息的损失,所以原模型并不适用于该物体的检测。为了更好地对消防设施进行检测,提升特征表达。一方面需调整模型的先验框设置,另一方面需能力对网络结构进行调整,达到良好的检测效果。
1.2.1 先验框尺寸的设置
先验框的数量在一定程度上会影响模型性能,先验框数量不足时会无法匹配到目标,造成漏检的情况的出现,但数量过多时,又会影响模型的推理速度,降低检测效率,所以合适的先验框选取至关重要。为了准确地检测公开数据集中物体,原始YOLOv4模型对先验框进行了聚类统计,主要是针对于不同尺寸和种类的物体。而本文检测目标形状相对固定,目标单一,所以不适宜使用先验框的默认参数设置,为此使用Kmeans聚类算法对图纸中的消防设施进行计算,根据统计结果将先验框尺寸设置为[11,23]、[21,23]和[17,40]。
1.2.2 金字塔池化
特征金字塔作为目前在目标检测领域中一个比较重要的部分,可以在不同尺度下拥有不同的分辨率,不仅可避免将图片裁剪为模型的固定输入大小,能让小目标拥有合适的特征表示,还能通过融合多尺度信息提升对小目标的检测性能。
空洞卷积(Atrous Convolution) [20]是在卷积核元素之间填充空格来扩大卷积核的一种方法,使用扩张率(Dilation rate) 来调节,可在不损失信息的前提下增加大感受野,以此来捕捉上下文信息,如图2所示,扩张率从左往右分别为: dilation rate=1、dilation rate=2 和dilation rate=3。
SPP(Spatial pyramid pooling) 是由三个最大池化层组成,其步长和滑窗大小要做自适应调整,经过特征映射的特征层再进行拼接,得到相应的特征向量,这样不仅可以将不同尺寸的特征图输出为固定大小向量,还可以提取不同尺寸的空间特征信息。但因为感受野较小,在面对低分辨率图形的情况下,容易丢失许多细节信息。
ASPP很好地解决了这一问题,将卷积层改为了空洞卷积,其结构由一个1×1卷积层、三个3×3的空洞卷积和一个全局池化层构成,共4个分支机构,之后将这4个分支机构融合在一起,进行特征提取,这样既不丢失分辨,也可通过扩大卷积核的感受野,提升模型的检测性能,如图3所示。
1.2.3 网络结构设计
原YOLOv4模型是对不同尺寸的物体进行检测,尽管融合多种深度学习技巧,也有不错检测性能,但是对于固定的目标检测信息有些冗余,模型参数量较大。为此本文对原模型进行了改进,通过对不同特征层提取的特征信息进行实验,选取合适的特征层进行检测,同时为减少模型参数量,删去了其余的检测头,得到模型YOLOv4_shallow。
文献[15]提到,在CSPDarknet53上添加SPP块可极大地增加感受野,分离出最显著的上下文特征,但由于其感受野有限,会存在无法学习到目标有效的特征信息的问题。为进一步提升模型的检测效果,获得精确的定位信息和丰富的语义信息,以满足实际检测需求,本文对模型进行了改进,将SPP 模块替换为ASPP,得到模型YOLOv4_fire-equiment,如图4所示。
2 实验及结果分析
2.1 消防设施数据集的构建
本文实验数据来自消防疏散图等建筑图纸,为保证实验数据的多样性,使用ACDSEE等软件,对图纸进行模糊、亮度以及噪声等处理,最终得到消防疏散图558张。
本文检测建筑图纸中消防设施,为单类别检测任务。在标注过程中使用 LabelImg软件对消防疏散图进行手工标注,并使标注框紧密覆盖消防设施且不能框到疏散图边界,最后制成PACAL VOC数据集的格式并保存到指定的文件夹中,标签命名为“fire equipment”,所以共标记消防设施3 552个,标注过程如图5所示。
2.2 实验环境的配置
本文实验平台为Ubuntu操作系统,开发环境为:ML-Ubuntu16.04-Desktop-v2.6,cuda11.0,GPU为1块RTX3090 显卡,搭配Intel(R)Xeon(R)CPUE5-2650v4@2.20GHz 处理器。代码均在 PyTorch1.2 框架下实现。为提高训练效果,所用算法均使用迁移学习策略。
实际训练中的超参数设置为:Epoch =150,前50 个Epoch的训练方式为冻结网络,后100个epoch将其解冻,学习率分别设置为l=0.001和l=0.000 1,学习率调整策略均为 Adam,Batchsize=32。
2.3 评价指标
目标检测领域中最常见的评价指标是Map和参数量Param,用于衡量模型检测能力的强弱的大小。Map是由精确度P(precision) 、召回率R(recall) 和平均精度AP(Average Precision) 计算而来,AP值为PR曲线下面的面积,AP的值越大,则说明模型的平均准确率越高。但由于本文检测任务为单类别检测任务,所以评价指标MAP与AP值相等,故使用AP作为精度评价指标,计算如下:
2.4 实验结果分析
2.4.1 不同特征层对于检测结果的影响
由于不同特征层的感受野不同,对于模型检测性能有一定影响,为此本文根据模型特征提取网络CSP?darknet53的特点,共设置了3组不同深度特征提取网络,分别选用特征图大小为304×304、76×76和38×38 的特征图作为检测层,由浅到深分别命名为YOLO_p1、YOLO_p2和YOLO_p3,实验结果如表1所示。
从实验结果中可以发现,当特征图为304x304时,尽管参数量较小,但由于网络層数过浅,无法学习到目标有效的特征信息,存在严重的信息损失,不能有效地提取消防设施的图像特征。而当特征图为38×38检测效果最好,AP值为72.61。所以根据实验结果最终选取38×38作为本文模型的特征提取层,命名为YOLOv4_basline,设为本文基线的模型。
2.4.2 特征金字塔对于检测结果的影响
Spp-Net 是一种可以不考虑图像大小,可输出固定长度的网络结构,可让目标在不同尺度下都能相应的特征表示,性能效果也在不同数据集上得到了验证。但由于其感受野有限,丢失了较多的全局信息和局部语义信息,所以在面对低分辨率时,效果并不好。而ASPP采用空洞卷积对输入图像以不同的采样率进行采样,之后为整合空间上下文信息将多支路特征融合,进而很好地提升模型的性能,为此本文进行了对比实验,如表2所示。
从表2中可以看出,ASPP的检测精度高达77.82,比SPP要高5.43个百分点,说明对于消防设施这类小目标物体,ASPP中的空洞卷积由于拥有的不同感受野,可以有效地从低分辨率图像中提取有效信息,使检测模型获得更丰富的特征。
2.4.3 模型的优化实验
数据增强作为深度学习的重要驱动力,可以在不改变参数和网络结构的情况下进行训练,有效地缓解了过拟合情况的出现。Mosaic是一种拼接类数据增强方法,主要思想是将4张图片进行随机缩放,再随机地拼接为1张图片进行训练,随机缩放可以增加很多小目标,丰富数据集的多样性,同时由于其可以一次性处理4张照片,也减少了训练时数据的处理时间,提升了处理速度,如图6所示。
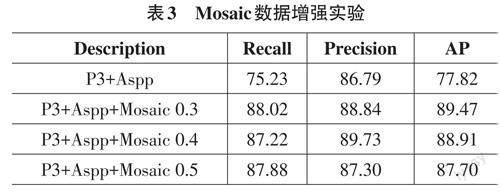
由于不同的缩放比例对目标的大小有很大的影响。所以本文也对Mosaic的缩放比例的超参数进行了对比实验,共设置0.3、0.4和0.5三组实验,结果如表3所示。
从实验结果中可以看出,Mosaic对于模型性能有着显著提升,检测精度提升约有11.65个百分点,这主要是由于,图片的缩放和裁剪操作缩小了消防设施的大小,迫使模型去学习更小的目标,学习到更多的鲁棒性特征,提升了模型的检测性能。同时,当超参数p 为0.3时比p=0.4和p=0.5分别要高0.56和1.77个百分点,猜测可能是P=0.3的目标大小较p=0.5更小,丰富了检测数据集,让模型学习到更多消防设施特征。
综上所述,设计的YOLOv4_fire-equipment 模型在测试集上最终的AP值达0.894 7,检测结果优于基线模型YOLOv4_baseline,检测精度提高16.86个百分点,图7为实验检测结果。
3 结论
本文提出一种YOLOv4 模型进行改进的YO?LOv4_fire-equipment,通过聚类方法设置先验框、选取合适的特征检测层、使用ASPP扩大模型感受野以及对Mosaic参数进行实验,有效地增强了网络对建筑图纸中的消防设施的检测性能,对消防监督统计效率有一定提升作用。
未来将进一步考虑优化YOLOv4_fire-equipment 模型,加入不同的特征融合模块,在提升检测精度前提下,进一步降低模型的参数量。同时扩充实验数据集,提升样本的多样性,以此来更贴近于复杂实战场景。