面向微波组件故障文本的知识抽取方法*
2024-03-30高达林周金柱樊国壮甘宇鹏董晓冬
高达林,周金柱,樊国壮,甘宇鹏,董晓冬
(西安电子科技大学高性能电子装备机电集成制造全国重点实验室,陕西 西安 710071)
引 言
电子技术的迅猛发展正在塑造着未来的生活方式。微波技术作为电子领域的前沿科技,在无线通信[1]、雷达探测[2]、医疗设备[3]等众多领域展现出卓越的应用潜力。微波组件作为微波技术的核心,承担着传输、接收和处理微波信号的关键任务。随着微波组件的高度复杂化和精密化,微波组件的装配也愈发困难。装配过程中引起组件性能下降的装调因素是多种多样的,往往发生即使满足装配要求产品性能仍可能不达标的现象,因而产生了大量调试工作[4]。微波组件的调试是确保其正常运行的关键环节,也是保障电子设备正常生产装配不可或缺的一环[5]。
目前,微波产品调试过程面临挑战,调试经验的积累困难,且传承困难。传统的调试方法仍然以口口相传和经验积累为主[6],缺乏系统性的教学与指导,导致初调者在面对微波产品故障时无法迅速获取有效的解决方案。但值得注意的是,当前存在着大量的故障文本数据,这些数据具有潜在的价值,可以为调试工程师提供有效的指导。不过在过去的调试实践中,虽然故障文本存在,但由于缺乏系统性的整理和指导,初调者往往难以从中获得清晰、系统的调试路径。
随着人工智能的发展[7–8],利用知识抽取技术,通过智能算法和模型,能够从海量非结构化数据中提取出有用的信息和知识。知识抽取技术为微波组件装调测带来了全新的可能性,通过充分利用微波组件的历史归零报告、失效案例、故障文本等非结构化数据,将其中蕴含的宝贵知识抽取出来,用以指导微波组件调试工作及对装配过程中的重要装调要素预警,有助于及早发现和解决潜在问题,提高产品质量,降低生产成本。该技术的通用性在生物医疗、法律、金融领域得到了证实[9]。
本文将深入探讨如何运用知识抽取技术,使得历史故障数据不再是信息的简单堆砌,而成为指导调试的宝贵知识资产。探讨知识抽取技术在微波组件调试中的应用,使调试人员更高效地解决微波组件装调测中的复杂问题。在这一新兴领域的探索中,知识抽取技术将为微波组件的装调测带来智能化变革。
1 数据分析与预处理
1.1 数据分析
本文收集了400余条微波组件维修案例、60余篇相关论文和专业领域的书籍,构建了一份详实的实验数据集。其示例如图1所示,其中涉及微波组件失效现象、失效机理、失效模式、针对微波组件失效所采取的调试手段等的具体描述。

图1 微波组件故障文本示例
1.2 模式层定义
通过对全部超16万字的微波组件故障文本语料进行分析统计,得到构建微波组件故障知识图谱所需的微波组件、芯片/无源器件、失效现象、失效模式、失效机理及调试手段6种实体类型(表1)以及组成、发生、伴随、属于、原因及方案6种关系类型(表2)。

表1 实体类型

表2 实体类型
依据规定的实体和关系类型,构建微波组件故障知识图谱的模式层,如图2所示。
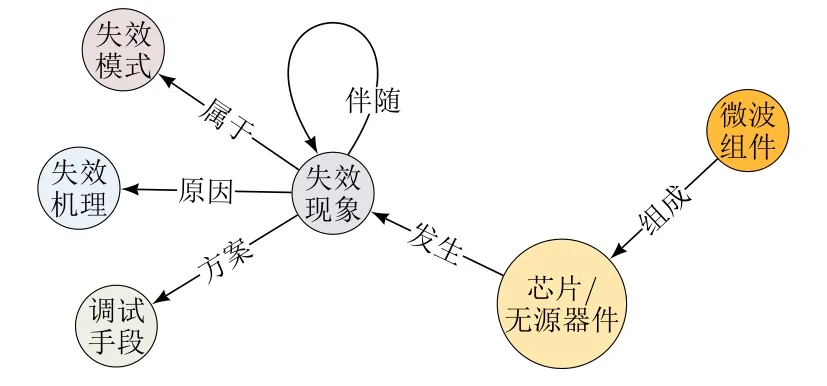
图2 微波组件故障模式层
1.3 数据标注
微波组件故障数据通过非结构化文本的方式描述微波组件故障领域实体及相互关系。相比于图形结构的表达方式,自然语言的表述方式存在关系描述形式多样且涵义模糊不清等问题。
针对微波组件故障领域的特殊性,本文在构建好模式层后,依据6种实体类型和6种关系类型,将故障数据进行数据标注。
本文采用“BIO”策略处理标注的实体,其中“B”表示实体的起始位置(Beginning),“I”表示实体内部的位置(Inside),“O ”表示非实体的位置(Outside)。将文本序列中的每个字符标记为实体的起始位置、内部位置或非实体位置,从而对实体进行准确的定位和识别。
如图3所示,针对句子“微波二极管用于频率合成器,外场使用时锁相环路失锁”一句中,“微波二极管”一词标注为“无源器件”标签,“微”字作为首字母,由“B–”作开头,以其标签的英文简写“DEV”作为后缀;“频率合成器”一词标注为“微波组件”标签,“频”字作为首字母,由“B–”作开头,以其标签的英文简写“COM”作为后缀。

图3 BIO标注示例
BIO策略的设计简单直观,易于理解和实现。通过对微波故障文本数据集进行“BIO”标注,可以轻松地确定实体的起始位置和边界,有利于后续的处理和分析,因较灵活可适用于多种模型。
2 知识抽取模型
2.1 模型框架
为了构建抽取效果更好的微波组件故障知识抽取模型,本文采用CasRel-LN模型。该模型分为3个部分:BERT编码器、主体标记模型(subject tagging model)和特定关系下客体标记模型(relation-specific object tagging model),如图4所示。其中,BERT编码器用于文本编码;主体标记模型用于句子中的主体(Subject)识别;特定关系下客体标记模型根据识别出的主体,寻找可能的关系(Relation)和客体(Object)。

图4 CasRel-LN模型
从总体来看,抽取任务分为3个步骤:1)通过预训练BERT模型对微波组件故障文本进行编码;2)通过主体标记模型得到所有微波组件故障文本中所有可能的实体;3)针对每一个主体,使用特定关系下客体标记模型来同时识别所有可能的关系和特定关系下的客体。
2.2 BERT编码模型
CasRel-LN模型中使用了BERT预训练编码器来获取句子的语义信息、句法结构、位置信息等深层语义信息。其中BERT 编码层包含多层双向“Transformer”结构,在大规模未标注数据上进行预训练,为实体关系抽取任务提供初始化参数时,使用双向自注意力机制,使其可以学到更深层的语法和语义信息。
基于CasRel-LN模型中预训练的BERT编码器对微波组件故障文本进行编码的主要过程如下:1)使用Tokenization分词器将输入的微波组件故障文本分解成基本的单元词向量“Token Embeddings”,并为输入微波组件故障文本的开头添加特殊标记[CLS],结尾添加特殊标记[SEP];2)添加“Segment Embeddings”,用于区分句子对任务中的两个句子;3)添加“Positional Embeddings”用于表征“token”在序列中的相对位置。最终形成的输入由上述3部分组成,如图5所示。

图5 BERT编码层输入示意图
2.3 主体标记模型
用BERT模型为微波组件故障文本编码,输出文本的词向量,用主体及实体类型标记模型标记出每个实体的起始位置和结束位置,如图6所示。

图6 标注实体结果示例
主体标记模型将输出的字符作为主体(Subject)开始和结束位置的概率,表示如下:
模型会为文本中每个“token”计算出一个概率值,并将其转化为二元标记(0或1),标记为1则认定为实体的边界。判断每个概率值是否超过设定的阈值,如果概率值大于阈值,则将对应的token标记为1,否则标记为0。
CasRel模型在主体抽取模块中不支持实体类型解码,而知识抽取时需要对实体的具体类型进行解码,因此需要额外添加一个实体类型分类器,以在实体边界标注的基础上对实体类型进行额外的分类,同时获取实体的边界和类型信息,如图7所示。

图7 实体类型分类示例
2.4 特定关系下客体标记模型
为了抽取特定关系下的客体时融合主体的特征信息,将预训练BERT模型输出的编码数据hN与主体及实体类型标记模型标注出的主体特征信息相加,获得特定关系下客体标记模型的输入向量X:
在模型训练中要防止特征的学习能力降低,确保模型能够更好地捕捉输入数据的信息。本文采用层归一化(Layer Normalization, LN)方法,有助于提高模型的鲁棒性,防止梯度爆炸,加速收敛,表示如下:
式中:xi为输入向量X中对应第i个位置的向量;µ为输入向量的均值;σ是输入向量的标准差;β和γ′分别是尺度参数和偏移参数,是神经网络需要训练的参数;ε为一个很小的常量,用于防止相除时分母为0。
将编码数据hN与实体特征信息融合后得到输入向量X,通过特定关系下客体标记模型标记出所有对应关系下客体的起始和结束位置,如图8所示。

图8 标注关系结果示例
特定关系下客体标记模型将输出的字符作为客体(Object)开始和结束位置的概率,表示如下:
3 实验
3.1 实验环境与参数设置
实验环境使用的是Windows操作系统,GPU选用NVIDIA GeForce GTX2080Ti,基于pytorch框架使用python 3.6版本进行搭建,其中BERT使用的是谷歌提供的中文BERT预训练模型“bert-base-chinese”。设计Focal Loss损失函数的目的之一是解决类别不平衡问题。平衡因子α用于调节正负样本的权重,使模型更关注少数类别样本。选择较大的α值有助于增加少数类别样本的权重,从而提高模型对少数类别的关注度。焦点因子γ用于调节Focal Loss函数中的聚焦程度。设置γ值有助于减轻模型对易分类样本的影响,更加关注难分类的样本,从而提高模型的泛化能力。选择α= 0.96,γ= 2的组合可以取得较好的模型性能。超参数设置见表3。

表3 模型参数表
BERT模型的最大输入长度是512个“token”,因此最大句子长度取512。开始时可以设置较小的迭代次数,再逐步增加,直到模型性能不再提高,最终迭代次数取100。根据经验,批量大小取32。由于微波组件故障文本数据语料库规模较小,为防止过拟合,节省计算资源,词嵌入大小取50,字符嵌入大小取50。根据经验,学习率取0.01。
3.2 对比实验
文中使用精确率P(Precision)、召回率R(Recall)及F1值(F1-score)[10]3个指标来评估模型的性能。在通常情况下,精确率和召回率是相互矛盾的,提高精确率会降低召回率,反之亦然。F1值是一个直观易懂的评价指标,将模型的精确率和召回率综合在一个值中,便于比较不同模型的性能。计算公式如下:
式中:TP为被成功识别到的正确三元组数目;FP为识别到的错误三元组数目;FN为未被成功识别到的正确三元组数目。F1值范围在0到1之间,值越大表示模型的性能越好,同时兼顾了模型的精确性和全面性。本文对来源原文的应用领域进行了扩展,将精确率P、召回率R以及F1值应用在微波组件故障文本的知识抽取上。
为了验证所提模型在微波组件故障数据集上知识抽取的有效性,将其与其他几个较好的知识抽取模型进行比较。其他几个较好的知识抽取模型为NovelTagging[11],CopyRE[12],GraphRel[13]和Cas-Rel[14]。NovelTagging提出了一种新的标注模式,把联合任务转化为标签问题,然后通过双向树结构的长短时记忆神经网络,将每种关系以及主体和客体的序号组合起来进行关系抽取,并根据最后的标注结果进行解码,进而得到关系三元组。CopyRE使用了基于Seq2Seq学习框架的端到端神经网络模型。该模型将关系三元组的抽取问题视为序列到序列的生成问题,模型可以学习从给定的句子中提取实体和关系任务,类似于将其翻译成目标语言,能更好地处理结构化信息的抽取任务。GraphRel提出了一种基于图卷积网络(Graphic Convolutional Nets, GCNs)的端到端关联抽取模型GraphRel,利用图卷积网络联合学习命名实体和关系。通过关系加权的GCN来考虑命名实体和关系之间的相互作用,以更好地提取关系。CasRel是基于参数共享的实体关系联合抽取方法。它首先检测出输入文本中所有可能的主体,然后为预测主体找到关系和对应客体。
为了确保实验的准确性,下面的所有模型都是在相同输入下进行比较的,输入皆为对微波组件故障文本分析与预处理后得到的文本数据集。各模型的对比实验结果见表4。

表4 实验对比结果
本文实体关系抽取使用的CasRel-LN算法成功实现了对测试集文本的实体抽取验证,共抽取了16 586个字符,准确率为63.3%,召回率为51.9%,F1值为61.6%,其性能在较常见的相关模型基础上皆有所提高。与基线模型CasRel相比,CasRel-LN算法加入LN层进行预测后,测试F1值提升了1.2%,表明LN层对标签预测产生了正向约束效果,提升了整体性能。
综上所述,CasRel-LN模型的知识抽取综合性能比其他模型更优,并且可以识别实体类型,证明了CasRel-LN模型对微波组件故障专业领域知识抽取的有效性。
3.3 知识图谱
本文通过知识抽取算法,从微波组件故障文本数据集中抽取出1 568个实体和1 618条三元组,选择使用Neo4j图数据库作为知识图谱的存储引擎,并利用其内置的可视化工具展示图谱结构。图9为微波组件故障知识图谱部分示意图。

图9 微波组件故障知识图谱
4 结束语
本文探讨了知识抽取技术在微波组件故障文本数据中的应用,旨在通过抽取微波组件维修记录、相关论文和领域书籍中的故障文本信息提高微波组件调试的效率与准确性。本文充分考虑微波组件故障文本的特点,针对文本中存在的知识三元组重叠问题,提出了一种基于CasRel-LN模型的知识抽取算法。以真实的微波组件故障文本数据为基础进行实验,得到F1值为61.6%,证明该模型可完成微波组件领域的知识抽取任务。不过,该算法仍存在抽取不精确的问题,在后续研究中需进一步完善数据集,改进模型,使微波组件故障知识抽取更全面。
