融合BERT和多重注意力的方面级情感分析
2024-03-27王擎宇
雷 蓉,王擎宇
(贵州财经大学信息学院,贵阳 550025)
0 引言
情感分析分为粗粒度情感分析和细粒度情感分析。粗粒度情感分析假设句子只包含一种情感,但在实际场景中句子往往针对不同的方面有不同的情感。例如,在评论“great food but the service was dreadful!”中,评论者对“food”的情感极性是积极的,对“service”的情感极性则是消极的[1]。方面级情感分析是一种细粒度的情感分析任务,可以出于各种目的挖掘出更详细的用户情感表达,近年来已成为自然语言处理领域的研究热点之一[2]。
在方面级情感分析领域,模型需要提取不同方面的特征信息,因此模型应当高度关注句子中的特定方面。Wang 等[3]使用LSTM(long short-term menory)从文本中提取情感特征,然后使用注意力机制让模型关注句子不同方面的情感极性。Chen 等[4]将两种注意力机制集成到网络模型中,模型使用内容注意力机制挖掘与特定方面相关的特征,同时通过位置注意力机制丰富情感特征的语义信息。
随着预训练模型逐渐兴起,BERT、GPT 等模型被广泛应用于方面级情感分析领域。Sun等[5]基于BERT 使用方面信息构建辅助句,将方面级情感分析任务转化为句子对匹配任务。Gao等[6]将构造的辅助疑问句与原始句子相结合,并使用特定的位置编码来增加对特定方面的注意力,实验结果表明BERT向量化的文本表示拥有更强的表征能力,可以提高模型情感分析的效果。
然而,上述模型仅是对BERT最后一层隐藏层的输出进行后续操作,忽略了BERT中间隐藏层输出的不同粒度的语义特征。因此,应综合考虑BERT 所有隐藏层的输出,挖掘BERT 隐藏层之间的相互联系,以提高模型的分类效果。
基于上述工作,提出一种融合BERT和多重注意力的方面级情感分析模型。模型使用多尺度卷积神经网络从所有BERT隐藏层输出的词向量矩阵提取不同粒度的情感特征,然后通过内容注意力机制和隐藏层注意力机制优化情感特征向量,使模型在训练时关注与特定方面相关的特征,更深层地挖掘与提取隐藏的情感特征,提高模型识别文本中不同方面情感信息的能力。
1 融合BERT和多重注意力的方面级情感分析模型
本节介绍 BC-MAT(BERT+CNN+Mutil-Attention,BC-MAT)网络模型及其各个模块的结构,模型整体结构如图1所示。
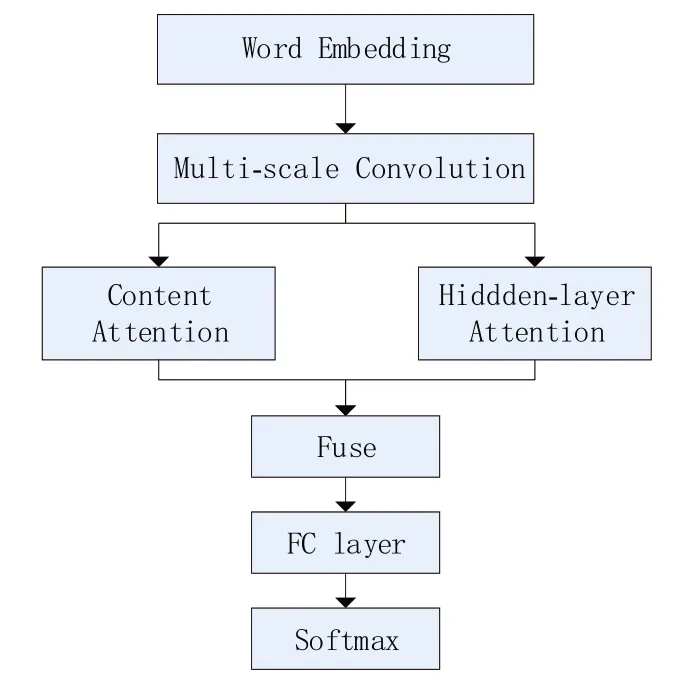
图1 融合BERT和多重注意力的方面级情感分析模型
BC-MAT模型的结构流程如下:①使用多尺度卷积神经网络对BERT所有隐藏输出的词向量矩阵进行情感特征提取;②根据输入的情感特征向量计算内容注意力特征向量,加强方面信息与上下文的交互;③根据输入的情感特征向量计算隐藏层注意力特征向量,挖掘方面信息在BERT隐藏层之间的关联;④融合内容注意力特征向量和隐藏层注意力特征向量,校准输入的情感特征;⑤通过全连接层和Softmax 层对情感特征进行分类。
1.1 输入层
输入层将句子Sentence 与方面词Aspect 组合拼接成句子对,之后通过BERT进行文本向量化,组合方式如公式(1)所示。
BERT 向量化后的词向量矩阵为Xi∈Rn,d,i∈[1,c],其中,n是经过BERT 分词器后的文本长度,d是词向量的维度,c是BERT 隐藏层的数量。
1.2 多尺度卷积层
由于仅从BERT 的最后一层隐藏层提取的情感特征较为单一,存在语义不足问题,本文使用textCNN[7]对BERT 所有隐藏层输出的词向量矩阵Xi∈Rn,d进行多尺度卷积(multi-scale convolution,MSC)运算,提取BERT 所有隐藏层的情感特征,之后将同一隐藏层提取到的情感特征进行拼接,计算过程如公式(2)~(4)所示。
其中,Conv为卷积运算(TextCNN),Ws为卷积核,将其设置为不同尺寸,用以提取不同粒度的情感特征,bs为偏置;Si j为BERT 第i层隐藏层特定尺寸卷积核产生的特征向量,max为最大池化操作,⊕为拼接操作;n为TextCNN 从BERT 第i层隐藏层提取的特征向量的数量,c为BERT隐藏层数目。
1.3 多重注意力层
多重注意力层(mutil-attention,MAT)的输入Sa∈Rc×H是BERT所有隐藏层提取的附带方面信息的情感特征,代表BERT不同隐藏层对于同一文本不同侧重的理解。BERT 单层隐藏层提取的情感特征代表整个文本的情感特征,内容注意力机制使得模型高度关注与特定方面相关的情感特征,获取特定方面在句子内部的依赖关系。隐藏层注意力机制可以挖掘句子中特定方面在BERT 隐藏层之间的相互关联,融合来自不同隐藏层的特征,得到语义丰富的特征向量。因此本文通过多重注意力机制让模型从句子层面和BERT 隐藏层层面关注特定方面的情感特征,多重注意力模型结构如图2所示。
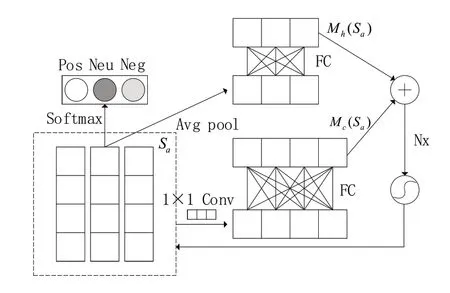
图2 多重注意力网络模型
隐藏层注意力特征向量Mh(Sa) ∈Rc×1是输入Sa经过全局平均池化和一个全连接层得到的;全连接层可以获取隐藏层与隐藏层注意力权重的直接对应关系。在计算内容注意力特征向量过程中,先使用逐点卷积对情感特征Sa压缩聚合,之后通过单个全连接层得到内容注意力特征向量Mc(Sa) ∈R1×H。逐点卷积可以使用少量参数对不同隐藏层提取的情感特征进行融合,降低特征向量的维度。最后将两种注意力特征向量融合并对输入情感特征Sa进行校准,融合、校准的方式如公式(5)~(6)所示。
其中,σ为Sigmoid 非线性激活函数,M(Sa)为融合后的注意力特征向量,⊗为向量点乘,为校准后的情感特征向量,将其通过全连接层和Softmax函数得到待分类句子的情感极性。
2 实验
2.1 实验数据集
本文实验采用SemEval2014 Task4[8]中的Restaurant 和Restaurant-Large(Rest-Large)以及ARTS[9](AspectRobustnessTestSet)中的Restaurant-ARTS(Rest-ARTS)和Laptop-ARTS(Lapt-ARTS),共四个数据集进行实验,实验数据统计见表1。
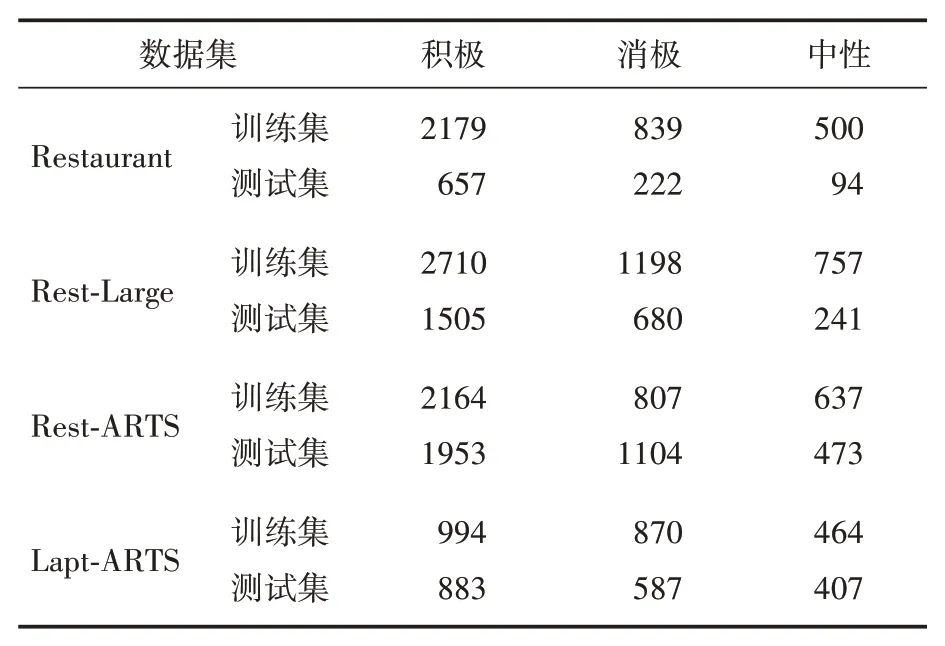
表1 数据集统计
2.2 参数设置和对比模型
本文实验环境为Window10 操作系统,PyTorch 框架,学习率设置为5e-5,卷积窗口大小为2、3、4,卷积核数目为32,批次大小为32,epoch为12。
为测试BC-MAT 模型的有效性,本文使用以下模型为基准进行实验:
(1)ATAE-LSTM[3]:融合注意力机制的LSTM 网络,模型将方面词词向量与句子中所有词的词向量拼接作为LSTM 的输入,并在LSTM后添加一层注意力层,让模型关注与特定方面相关的特征。
(2)TD-LSTM[10]:模型使用两个LSTM 对方面词的前后语境进行建模,提高模型的分类准确率。
(3)TC-LSTM[10]:将方面词词向量与句子中所有词的词向量拼接,之后使用两个LSTM 模型对方面词的前后语境进行建模。
(4)GCAE[11]:门控卷积网络模型,模型使用两种卷积网络分别提取方面信息和情感信息,使用门控机制输出与特定方面相关的情感特征。
(5)BERT-CNN:数据集通过BERT 进行文本向量化,使用卷积滤波器从BERT最后一层隐藏层输出的词向量矩阵中提取不同粒度的特征,通过最大池化和拼接操作后送入全连接层得到分类结果。
(6)BERT-LSTM:数据集通过BERT 进行文本向量化,使用双向LSTM 对BERT 最后一层隐藏层输出的词向量矩阵提取情感特征,将提取到的情感特征送入全连接层得到分类结果。
2.3 结果与分析
2.3.1 对比实验
基于上述模型在数据集上进行实验,采用准确率来衡量模型性能,不同模型的准确率见表2。
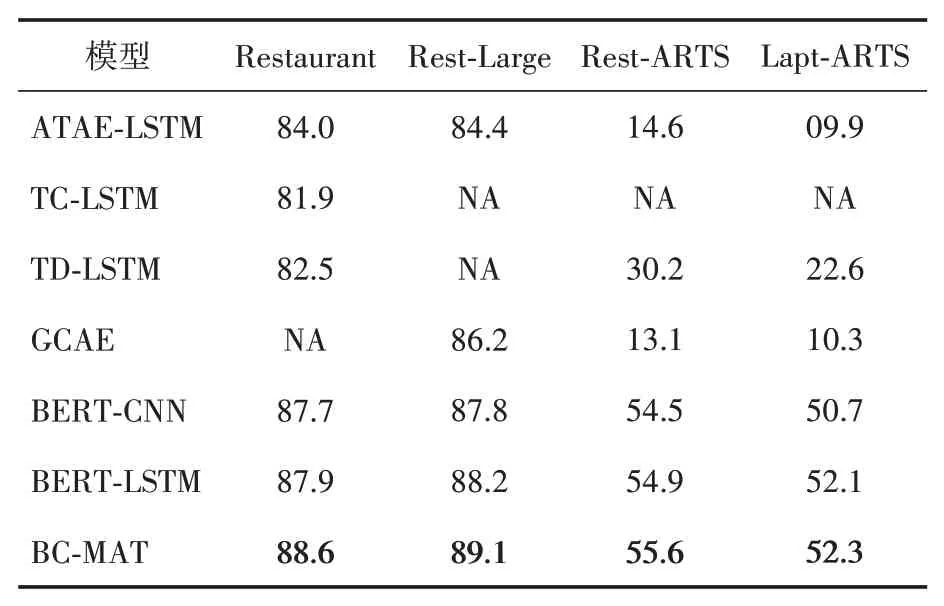
表2 不同模型的分类准确率(%)
从表2 所示的实验结果可以看出,本文模型比其他模型取得了更好的分类结果,其在Restaurant、Rest-Large、Rest-ARTS和Lapt-ARTS数据集上的准确率分别为88.6%、89.1%、55.6%和52.3%,与仅从BERT 最后一层隐藏层提取特征的BERT-LSTM 模型相比,准确率分别提高了0.7、0.9、0.7 和0.2 个百分点。这是因为本文模型使用多重注意力网络可以更深入地挖掘方面词在句子内部和隐藏层之间的依赖关系,充分利用BERT输出的语义信息,提高模型的抗干扰能力。其他模型由于忽略BERT中间隐藏层的语义信息而存在信息利用不足的问题,从而导致分类效果不理想。
2.3.2 消融实验
为验证本文加入多重注意力机制的有效性,构建了以下模型,用于在四个数据集上进行消融实验。实验结果见表3。
(1)BC-HAT(BERT+CNN+Hidden-Layer-Attention):移除内容注意力机制。
(2)BC-CAT(BERT+CNN+Context-Attention):移除隐藏层注意力机制。
(3)BC(BERT+CNN):移除多重注意力机制。

表3 消融实验结果(%)
由表3所示实验结果可知,与BC-HAT、BC-CAT相比,融合多重注意力机制的模型(BC-MAT)在性能表现上更出色,其在Restaurant、Rest-Large、Rest-ARTS 和Lapt-ARTS 四个数据集上的准确率分别为88.6%、89.1%、55.6%和52.3%,这是因为BC-MAT 模型可以从不同层面挖掘与特定方面相关的特征,提高了模型识别不同方面情感极性的能力,因此取得更好的分类效果。
2.4 注意力机制可视化
为更好地理解内容注意力机制和隐藏层注意力机制,本文以Restaurant 数据集中的一条数据“good food but the service is dreadful!”为例,可视化文本样例中单词的权重以及BERT隐藏层的权重,如图3所示。

图3 内容注意力可视化
图3展示了选定样本中单词权重的可视化结果,注意力权重的大小与颜色深度成正比。由图3可知,内容注意力机制能够密切关注与特定方面相关的情感词汇,有效识别不同方面的情感极性。
图4 展示了选定样例的BERT 隐藏层注意力可视化结果,在同一句子的不同方面,BERT 的隐藏层权重也不相同。一般来说,模型为深层隐藏层分配的权重更大,但当方面词为“food”时,BERT 第一层隐藏层的权重与最后一层隐藏层的权重近似,这表明模型使用BERT所有隐藏层进行特定方面的特征提取。通过使用隐藏层注意机制,模型可以动态地侦测出BERT不同隐藏层与给定方面最相关的情感特征,充分利用BERT输出的语义信息。
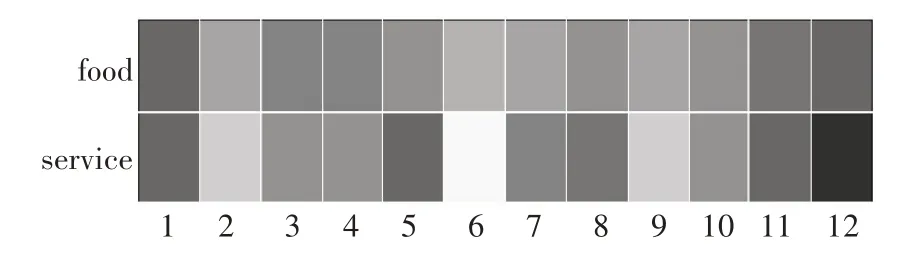
图4 隐藏层注意力可视化
3 结语
现有的方面级情感分析模型往往无法充分利用BERT预训练模型的输出信息。本文提出融合BERT 和多重注意力的方面级情感分析模型,模型的主要思想是通过多尺度卷积神经网络和多重注意力机制对BERT所有隐藏层输出的语义信息进行互补融合,可以获得语义丰富的特征向量,更深入地挖掘方面词在上下文和BERT隐藏层之间的语义关系。在四个公开数据集上的实验结果验证了本文模型的有效性。目前网络上不仅有文本还包含图片、视频等多模态数据,因此未来可以结合多模态进行方面级情感分析。
