基于真实场景的情绪识别研究
2024-03-27熊昆洪贾贞超文虹茜卿粼波
熊昆洪,贾贞超,高 峰,文虹茜,卿粼波,高 励
(1. 四川大学电子信息学院,成都 610065;2. 四川大学望江医院,成都 610065;3. 成都市第三人民医院神经内科,成都 610031)
0 引言
自动情绪识别[1-3]研究旨在基于机器自动感知和分析人类的情绪,在人机交互[4]、场景理解[5]、智能监测[6]和医疗养老[7]等很多领域都有潜在的应用空间。但与实验室条件下的数据集中光照条件良好、经过裁剪和对齐的面部图像不同,在真实场景中,受个体活动性强、活动范围大、角度偏转、移动等问题的影响,较难获取个体的面部细节。如实验室环境下的面部表情数据集CK+[8]和面部、姿态双模态情绪数据集FABO[9],具有清晰的面部信息;而真实场景数据集PLPS[10],由于空间开阔、人流大且活动不受限,面部信息存在缺失,音频、生理数据难以获取。在这种真实场景下,即使面部表情作为人机交互最重要的部分,面部表情特征也迫切需要其它情绪线索的辅助。
其他情绪线索中,心理学研究揭示了身体姿态[11]在情绪表达中的重要性,并且由于个体姿态信息在真实场景中更容易获取,受方向、偏转等因素的干扰也比较小,因此在真实场景中通过人体骨架[12]及人体姿态[13]可以进行更加稳健的个体情绪识别。此外,除了个体特征外,场景中可能包含辅助识别的情绪线索[14]。特别是在真实场景中,背景复杂且包含丰富的信息,充分利用背景关键信息可以更好地识别个体情绪。但是场景中还包含很多无效信息,需要对场景信息进行筛选和处理。
为此,针对真实场景中采集的数据质量偏低、背景复杂、变化复杂、人流量大且存在遮挡等问题,本文提出了一种面向真实场景的多模态深度融合网络,通过挖掘真实场景中面部、姿态、骨架和场景信息,进行深度推理融合,实现稳健的个体情绪识别。该方法设计了局部-全局面部特征模块(local-global facial feature block, LGB)、骨架特征模块(skeleton feature block, SFB)、姿态特征模块(pose feature block,PFB)、场景特征模块(context feature block,CFB)分别提取面部、人体骨架、人体姿态及场景情绪特征;最后通过设计的融合模块(fusion block,FB)进行特征深度融合,并进一步分类得到情绪结果。
1 算法设计
如图1 所示,本文模型包含五个模块:局部-全局面部特征模块(LGB)、骨架特征模块(SFB)、姿态特征模块(PFB)、场景特征模块(CFB)、融合模块(FB)。首先,对视频数据进行处理,依次得到所需要的数据形式:人脸序列、骨架序列、人体图像序列,以及图像帧序列。由LGB、SFB、PFB、CFB 分别提取情绪特征,并由融合模块FB进行特征过滤及深度融合。
在视频情绪识别分析中,面部表情[15]是情绪表达的主要途径,因此设计了LGB 模块,通过融合通道注意力(channel attention,CA)[16]、空间注意力(spatial attention, SA)[16]以及多头注意力机制(multi-headed self-attention, MHSA)[17]来提取面部局部-全局融合的情绪特征。此外,考虑到在真实场景中个体活动性较强,运动与外观等与个体姿态相关的信息更易获取,本文还设计了SFB 模块和PFB 模块以关注个体的运动、外观等信息。SFB 对骨架数据进行时空图建模,基于双流时空图卷积对骨架序列XS和骨架位移差值序列XS∆t提取骨架特征。而SFB 以骨架关键点作为输入,损失了像素视觉信息,因此,PFB基于ViT(vision transformer)[18]设计了多尺度视觉Transformer,以提取基于视觉的外观运动信息,即姿态特征。此外,鉴于场景有助于嵌入新的信息层,设计了CFB 模块,通过嵌入了注意力机制的Resnet 网络,对视频帧序列提取场景特征。最后,为了过滤冗余或无效的特征,关注各模态特征间的联系,融合不同模态情绪特征,设计了FB 模块。FB 首先通过门控循环单元(gated recurrent unit,GRU)[19]捕捉特征间的相关性,学习有效特征并进行更新;然后采用低秩矩阵分解(low-rank matrix factorization,LMF)[20]的方法进一步通过张量融合来捕获各模态之间的交互信息,实现特征深度融合。
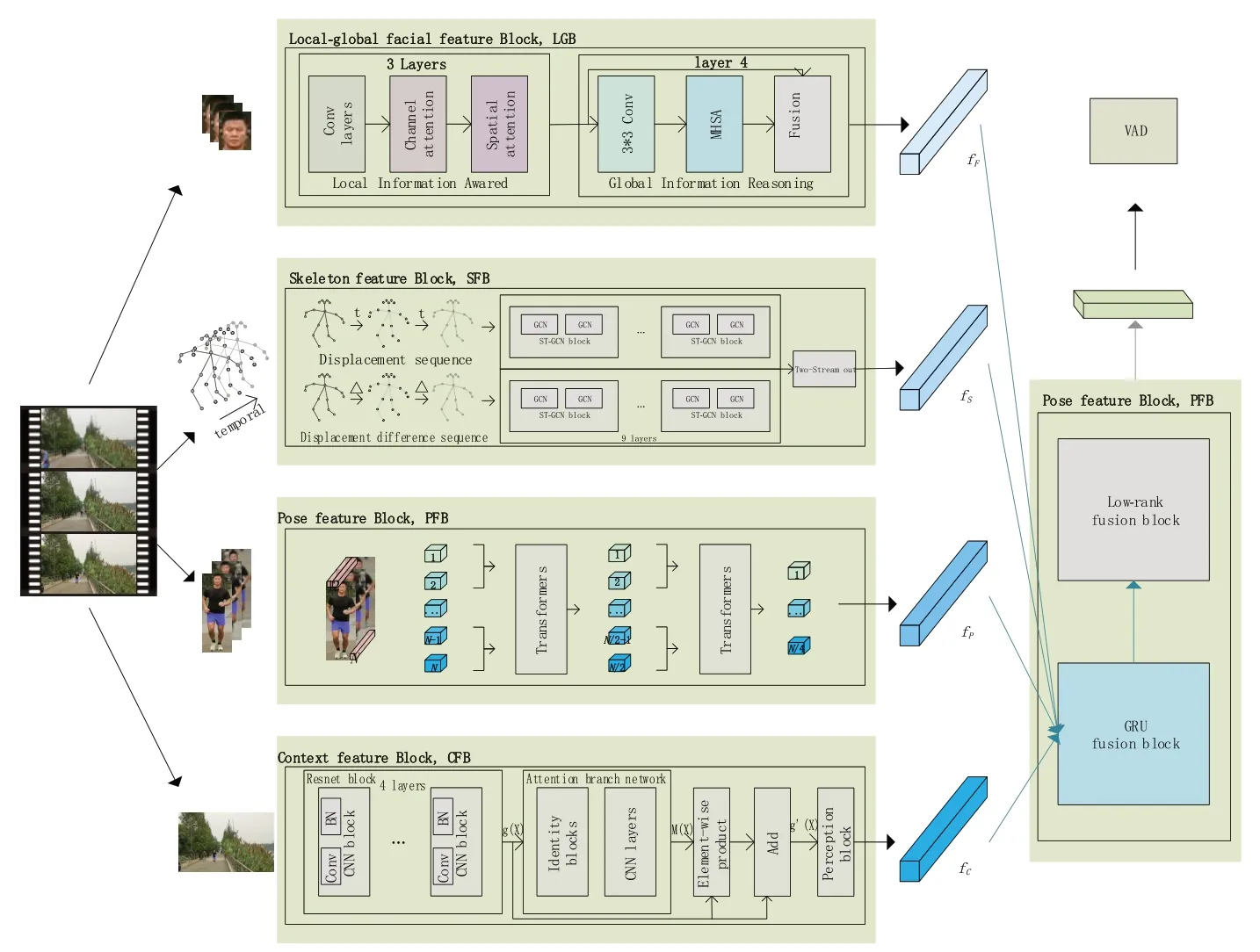
图1 模型结构
1.1 局部-全局面部特征模块LGB
面部表情作为情绪的主要表达方式,许多研究者不断推陈出新,获得了相当多的面部表情识别性能[13,19-20]。然而,这些方法对于面部的局部特征和全局特征很少能够兼顾,导致出现偏差。现有方法对局部-全局特征的处理大多采用了分离提取的方法,例如双通道网络,其忽略了局部特征与全局特征之间的相关性。因此,本文基于Resnet-18 网络,利用CA、SA[16]以及MHSA[17]设计了一个局部-全局信息推理模块LGB,以提取密切相关的全局特征与局部特征,其结构见图1 LGB模块。
在Resnet-18 中,每一层包含多个卷积核,可以提取不同的局部特征作为多通道特征图。LGB 模块在Resnet-18 前三层中嵌入了CA 和SA,以进一步增强提取效果。在此基础上,利用MHSA 的全局信息提取能力,将局部特征整合为全局特征。此外,使用3×3 卷积层代替Transformer中的1×1卷积层,以获得更大的感受野,最后残差连接融合了局部和全局特征,并作为LGB输出的局部-全局面部特征。
1.2 骨架特征模块SFB
作为身体语言之一的骨架数据,在真实场景中容易获取且具有可靠的情绪信息,因此,本文设计了SFB模块提供骨架情绪特征。
关节之间存在依赖关系,直接编码关节位置会丢失依赖信息。因此,SFB 基于关节之间的自然连接来建模;此外,视频数据在时序上也蕴含了个体的运动特征。因此,将输入的骨架序列构建成一个具有自然连通性的无向时空图,骨架时空图建模如图2所示。
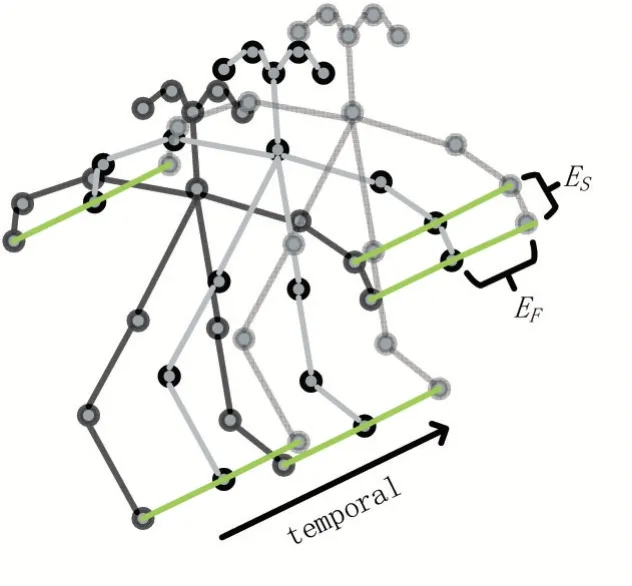
图2 骨架时空建模示意图
骨架数据是非欧式结构的图数据,常常使用图卷积神经网络(graph convolutional network,GCN)来进行特征提取。而由于骨架数据还具有时空信息,SFB 采用了能够挖掘时空信息的ST-GCN(spatio-temporal GCN)[21]来提取特征。而对于挖掘视频数据中的时序信息和运动信息,双流(Two-Stream)类的方法取得了比三维卷积类的方法更好的效果。因此,SFB 模块构建了双流时空图卷积来提取骨架序列的运动特征,输入分别为16帧的骨架序列XS和16帧的骨架位移差值序列XS∆t,其中,XS是对视频样本随机抽取的第1 帧到第16 帧,XS∆t是与XS一起抽取的第1帧到第17帧的两帧之间对应关键点的位移。
1.3 姿态特征模块PFB
骨架数据虽然包含丰富的运动特征,但是损失了基于视觉的外观姿态信息。因此,本文设计了基于多尺度视觉Transformer[17]的PFB 模块(见表1)提取基于视觉的姿态特征。

表1 多尺度视觉Transformer的结构
本文PFB 设计的多尺度视觉Transformer 在ViT(vision transformer)[18]的基础上,拓展了对输入图片序列的分块操作,增加了时间维度上的处理,并且结合CNN 架构中成熟的多尺度分层建模理论关注低阶和高阶的视觉信息,充分学习并提取个体姿态序列的情绪特征fP。PFB 模块包含4阶段的多尺度Transformer,多尺度视觉Transformer 和ViT 一样首先将输入数据进行变换。为了降低空间分辨率(patch 数量减少),多尺度视觉Transformer在Transformer的Multi-Head Attention 模块中加入了池化操作(multi-head pooling attention, MHPA);为了提高通道数(patch 体积变大),在每个阶段最后一层MLP 中通过全连接对向量维度进行映射,从而建立了基于Transformer的多尺度特征模型。
1.4 场景特征模块CFB
场景信息也能够反映个体情绪,但真实场景的背景比较复杂,存在无关信息。为了关注与情绪特征有关的关键区域,本文设计了基于注意力机制的CFB模块来提取场景情绪特征。
真实场景中人流量较大且个体共享相似的场景信息。为了避免过拟合,CFB 使用18 层的残差网络作为特征提取的主干网络。为了判别复杂背景中的有效信息,CFB 引入了视觉注意力机制Attention Branch Network(ABN)[22]。具体地,如图1 CFB 所示,特征提取阶段获取的场景情绪特征图g(X)将与从注意力分支获取的注意力图M(X)交互,输出新的特征图g'(X)用于预测最终的情绪结果。
1.5 融合模块FB
许多研究表明,结合多种模态的特征可以提高情绪识别性能。为了更好地关联多种模态特征,学习特征之间有用的联系,本文设计了一个特征深度融合模块FB 进行特征融合。如图3 所示,FB 模块的输入为来自不同模态信息的情绪特征fF、fS、fP、fC, 首先以门控循环单元GRU[19]捕捉这些特征之间的相关性,学习有效特征并进行更新,得到更新优化后的特征FF、FS、FP、FC。
通过GRU 模块过滤冗余、无效特征后,采用低秩矩阵分解LMF 方法[20]获得各模态的低秩矩阵因子。然后通过特征与因子相乘获得单模态特征的类线性变换特征,最后将特征进行元素积实现融合。LMF 融合模块利用低秩矩阵分解实现张量融合,捕获各模态的交互信息,实现特征深度融合。
2 实验结果与分析
2.1 实验设置及数据集
本文采用维度模型进行情绪建模。维度模型以连续坐标表示情绪,包括效价(valence,V)、唤醒度(arousal,A)和支配度(dominance,D)等维度。维度空间理论上可以描述无限多的情绪,基本情绪类别也对应于维度空间中的一点,本文采用5个等级的维度空间。
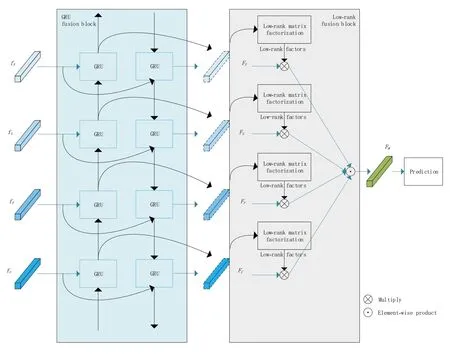
图3 FB模块结构图
在数据处理中,对PLPS-E 数据集利用个体边界框提取个体的图片序列,并统一尺寸为224×224。对FABE 数据集,直接统一尺寸为224×224。此外,使用Dlib 库进行人脸和关键点检测,以及OpenPose 算法[23]检测个体,得到包含18个关键点的人体骨架数据。
实验使用Adam 优化器,初始的学习率为0.0001,学习策略为余弦退火。迭代次数在PLPS-E数据集上为150轮,在FABE 数据集上为100轮,每批送入数据的大小为8。
PLPS(public life in public space)数据集[10]是面向公共空间的多任务数据集,包括情绪、行为、社会关系等关于人的研究。PLPS-E 是包含个体完整姿态和环境背景的情绪数据集,一共有253个视频,每个视频中有多个个体。数据集使用维度情绪模型中的效价(V)、唤醒度(A)、支配度(D)三个维度进行标注,基于五点标记法将每个维度记为-2、-1、0、1、2。评价指标为准确率(accuracy, ACC)。由于数据集包含三个维度,为了更好地判断算法的综合识别性能,本文增加平均识别准确率指标(average accuracy,Avg.ACC),用三个维度的识别准确率的平均数表示。
FABE 数据集[24]是真实场景个体情绪数据集,由摄像机在校园拍摄的人们的运动记录组成,每个视频片段包含一个个体,总共包括993个序列。数据集使用效价(V)维度描述真实场景中个体的情绪状态,将V 划分为积极(1)、中性(0)、消极(-1)三个等级进行注释,评价指标为准确率。
2.2 实验结果
2.2.1 对比实验
在PLPS-E数据集和FABE数据集上分别进行了对比实验,实验结果见表2、表3。BaseNet[10]关注动态信息,同时挖掘个体和场景中的情绪线索,使用预训练的三维残差网络进行特征提取,通过拼接完成模态的融合。PLPSNet[25]包含个体外观特征提取和场景特征提取双支路,基于注意力机制融合特征,实现开放空间中的个体情绪识别。BCENet[26]同样从姿态和场景中提取情绪特征,使用全连接层直接拼接不同分支的情绪特征并进行最终的识别。TSNet[27]通过双流网络深入挖掘个体序列中的相关特征,使用光流图对三维卷积网络进行补充、FABNet[24]通过双流网络提取了面部信息和姿态信息中的情感特征,MFNet[28]通过三通道网络提取了面部信息、骨架信息和姿态信息中的情感特征。

表2 不同方法在PLPS-E数据集上的实验结果(%)
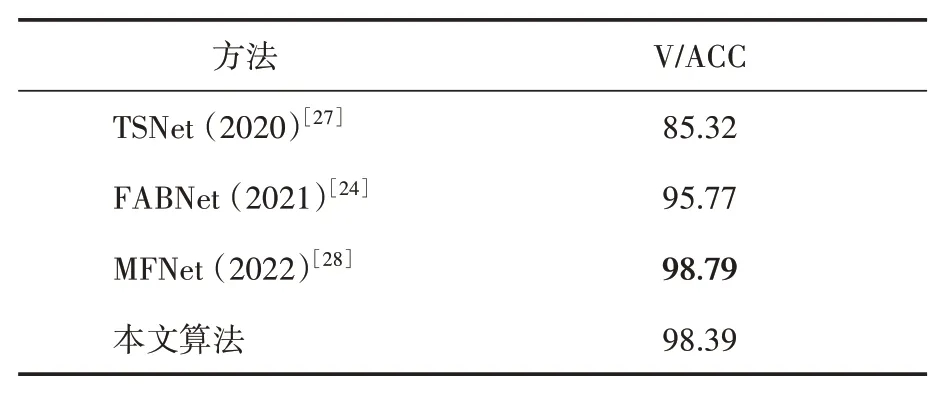
表3 不同方法在FABE数据集上的实验结果(%)
表2 表明,在PLPS-E 数据集上,本文算法在VAD 维度和平均识别准确率上都取得了最好的结果,分别为74.62%、79.15%、87.94%和80.57%。BaseNet 和PLPSNet 都没有考虑骨骼信息,对个体中蕴含的情绪特征提取不够充分,平均识别准确率分别为59.82% 和71.03%。BCENet 挖掘了骨架信息,并通过五层卷积网络挖掘了场景信息,取得了74.87%的平均识别准确率,但是对于场景中冗余的无用信息没有进行过滤,特征融合方式比较直接。
与本文算法相比,其他方法对于多种信息的特征提取不够充分和细致,也没有进一步给出各模态特征间的相关性,没有考虑并处理冗余信息。进一步地,因为维度V 是代表个体情绪的极性,与面部表情的联系最为紧密,在面部可能存在缺失的情况下,本文算法在维度V的提升效果相对维度A 和维度D 偏低,提升了2.03%。维度A 和维度D 代表了个体的活跃程度和强势程度,与运动时序信息和周围人境信息更加相关。本文算法充分提取骨架运动特征和姿态时空特征,并且更加精细地挖掘场景信息中的有效特征,在维度A、D 上分别提升了8.12%和6.94%的识别准确率,最终平均识别准确率提升了5.70%。
在FABE 数据集上的实验结果见表3,本文算法达到了98.39% 的识别准确率,超过了TSNet 与FABNet,并且与MFNet 相当。TSNet 利用光流与三维卷积提取时空信息,取得了不错的结果,但个体姿态中还有其他与外观无关的运动信息可以进一步挖掘。由于FABE数据集质量更高,个体序列更清晰,MFNet 专门设计了面部特征通道,单模态下达到96.57%的准确率,并在加权融合后达到98.79%的准确率。然而,本文算法面向真实场景,面部信息可能缺失,因此不偏向于挖掘面部特征。但本文算法通过有效的特征提取和融合,在不以面部为主导的情况下实现了与MFNet 可比的识别结果,证明了其有效性。
2.2.2 消融实验
为验证本文算法的有效性,进一步进行了五个模块的消融实验。实验设置如下:
(1)LGB:仅使用LGB模块提取人脸序列特征。在PLPS-E 数据集中,由于人脸序列存在缺失,准确率只计算了基于分类准确样本数量与人脸序列检测到的总量的比值;
(2)LGB+SFB:输入人脸序列和骨架序列,通过LGB 和SFB 模块提取特征,并进行等比权重融合;
(3)LGB+SFB+PFB:输入人脸序列、骨架序列和人体外观序列,通过LGB、SFB和PFB模块提取特征,并进行等比权重融合;
(4)LGB+SFB+PFB+CFB:输入人脸序列、骨架序列、人体外观序列和视频帧序列,通过LGB、SFB、PFB 和CFB 模块提取特征,并进行等比权重融合;
(5)LGB+SFB+PFB+CFB+FB:即本文算法,输入人脸序列、骨架序列、人体外观序列和视频帧序列,通过LGB、SFB、PFB 和CFB 模块提取特征,并通过FB模块深度融合特征。
在PLPS-E 数据集上的消融实验结果见表4。逐步叠加各模块,VAD 维度准确率和平均准确率总体上都逐步提升,并最终达到最佳性能,说明各个模块在整个网络中都有效。值得注意的是,在LGB 模块上叠加SFB 模块后,维度V的识别准确率下降。这是因为单独使用LGB 模块时,只计算了分类准确的样本数量与检测到的人脸序列样本总量,即计算了部分样本;而在叠加SFB 模块后,样本量变为原数据集的数据量,且实际上以SFB 模块为主,LGB 提供辅助信息。骨架信息与运动特征有关,与情绪维度模型的维度AD 契合,因此维度AD 识别准确率提高。面部表情能直接表现个体的愉悦程度(维度V),相比之下骨架信息逊色不少,因此维度V 识别准确率下降。在最终的算法中,使用了FB 模块后,维度V 准确率下降了0.75%,但维度AD 的准确率都有不错的提升(分别提升了5.79% 与1.51%),平均准确率也提升至80.57%。因此FB 也是有效的,其带来的并不仅仅是负面影响。
在FABE 数据集上的消融结果见表4 最后一列。逐步叠加各模块,准确率不断提高,证明各个模块有效。由于FABE数据集只关注维度V,且采用三点分值,个体情绪更为粗略,类间差距较大,同时该数据集具有清晰的人脸序列及人脸表情,因此整体准确率较高。由于运动趋势简单,SFB模块和PFB模块提取的运动特征相似,叠加SFB 模块后再叠加PFB 模块时,准确率提升不明显。此外,场景简单且图像清晰,在提取场景特征时容易获取到面部或人体外观序列上的特征,因此叠加CFB 模块后,性能提升有限。然而,在叠加融合模块FB 后,保留了特征间的相关信息,去除了冗余和无用信息,最终准确率明显提升。
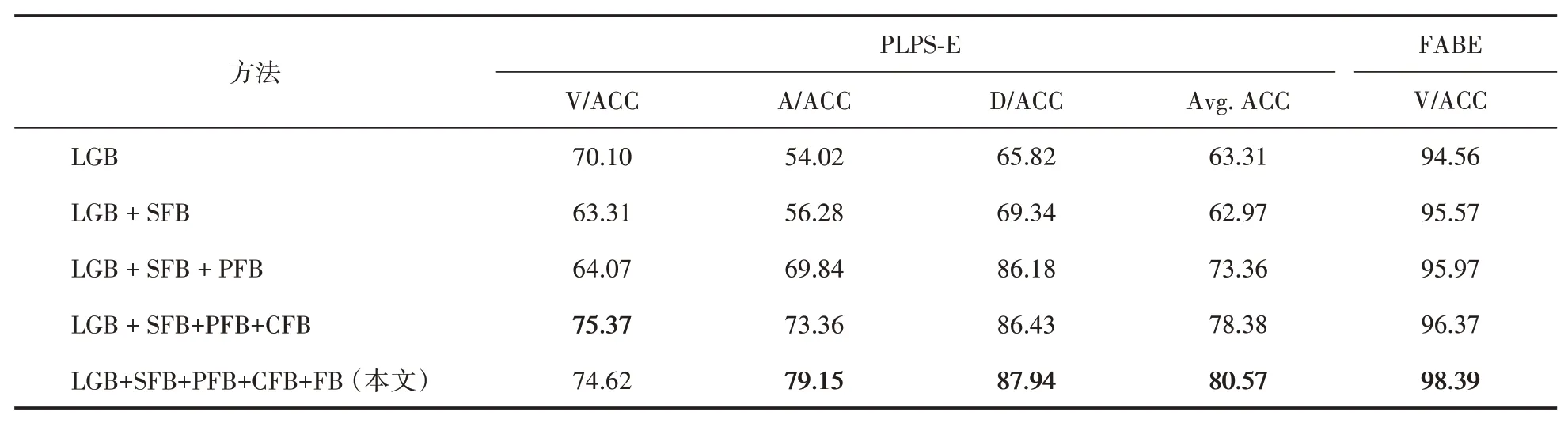
表4 在PLPS-E及FABE数据集上的消融实验结果(%)
3 结语
本文从真实场景的实际情况出发,针对真实场景的稳定情绪识别,提出了深度融合多模态特征的识别算法,充分挖掘在真实的环境中的人脸序列、个体姿态序列、骨架关键点序列、场景信息等数据中的情绪特征,并使用特征级的深度融合方法进行个体情绪识别。所提出的算法在PLPS-E 和FABE 数据集上进行了验证,通过与其他算法的对比以及对网络模块进行消融,证明了本文提出算法的有效性。在未来的研究中,将继续研究更加精准的特征提取及融合方式,进一步优化识别性能。
