基于高级语义特征蒸馏的增量式连续目标检测方法 *
2024-03-18康梦雪张金鹏马喆黄旭辉刘雅婷宋子壮
康梦雪,张金鹏,马喆*,黄旭辉,刘雅婷,宋子壮
(1. 中国航天科工集团智能科技研究院有限公司,北京 100043;2. 航天防务智能系统与技术科研重点实验室,北京 100043)
0 引言
现代防御环境错综复杂,呈现出高动态强开放的特点,对防御体系的目标感知和检测能力提出严峻挑战。威胁目标种类多更新快,高价值信息隐蔽难获取,导致历史数据无法涵盖所有潜在威胁目标,不能动态反映实时环境状况。因此,基于大规模历史数据和传统深度学习方法所训练的智能系统存在动态开放环境适应能力差的局限性。这要求新型智能系统应能够在动态开放场景下进行增量式持续自主学习,将历史数据与实况数据进行增量式融合,持续提升环境生存能力和对抗能力,从而自主应对环境态势变化,形成高水平智能化防御能力。
传统目标感知算法不具备对未知新类型目标的持续感知能力,当应用场景从静态封闭扩展到动态开放时,感知性能发生显著退化。因此,对新类型威胁目标进行增量式连续学习,迅速确定其数量、种类与威胁程度,是防御场景下持续自主感知能力的关键。近年来,增量式连续学习被提出用于动态开放场景下的目标感知,通常根据是否呈现任务标签,将增量式连续学习分为3 种类型:任务增量、域增量和类增量。本文关注类增量连续学习与目标检测任务的结合,即增量式连续目标检测任务。
现有的增量式连续学习方法在分类任务上取得了较好的进展[1-5],但在检测识别任务上难度较大进展较少。分类任务中单帧图像一般只包含单一类别的单个目标物体,因此只需要确定该物体的类别信息,也即分类模型只预测输出一个类别标签。检测任务中单帧图像上可能出现若干类别不同、且数量可变的目标物体,因此需要同时确定多个物体的类别信息和位置信息,即检测模型预测输出数量不定的类别标签和位置坐标。因此,增量式连续分类任务只需避免分类知识的遗忘,而增量式连续检测任务需要同时避免分类知识和定位知识的知识遗忘,因此增量式连续检测任务往往难度更大。但防御场景下必然面对多目标情形,因此准确检出来袭目标的数量、类别、方位是基本要求,因此必须开展增量式连续检测方法的研究。
传统目标检测模型通过已知数据进行训练。微调模型以适应新加入的数据,会导致模型在旧数据上的性能急剧下降,该现象被称为灾难性遗忘,是增量式连续学习的关键挑战。
在分类任务的增量式连续学习方面,研究人员已经提出较多方法以缓解灾难性遗忘,例如参数隔离[6]、正则化[7]和样本回放[8]。文献[1]阐述了增量式连续分类算法的最新进展。
在目标检测任务的增量式连续学习方面,有基于样本回放[9]、元学习[10]、知识蒸馏[11]、关系建模[12]等众多方法,其中知识蒸馏被证明是减少灾难性遗忘的有效方法之一[11,13-15]。该方法的基本思路是通过知识蒸馏将旧数据的知识从教师模型传递给学生模型,知识的来源可以是关键样本、重要特征、分类响应或定位响应等。在知识蒸馏框架下,旧类别目标的监督信息由教师模型的预测提供,而新类别目标的监督信息由新增数据的标注基准来提供,从而能够有效应对增量学习过程中旧类别标注信息缺失的问题。
但现有特征蒸馏方法大都在较低层或较浅层的特征层进行方法设计而忽略了对高级语义特征的开发利用。高级语义特征具有更好的语义抽象性和变换稳定性,是对图片类别信息的鲁棒表示[1]。而知识蒸馏的目的也在于向学生模型传递各个类别的特征鲁棒性和语义不变性。因此,高级语义特征可用以更好指导基于特征蒸馏的知识传递。
受此启发,本文提出一种全新的基于高级语义特征的知识蒸馏方法,以更好选择重要知识进行传递,从而缓解灾难遗忘,并提升增量式连续目标检测算法的性能。本文将首先简述增量式连续目标检测识别,接着详述本文所提出的基于高级语义特征蒸馏的增量式连续目标检测方法,然后基于公开数据集MSCOCO2017 进行算法验证,并结合分离实验分析蒸馏不同特征区域对算法性能的影响,最后对增量式连续目标检测进行总结和展望。
1 增量式连续目标检测
1.1 增量式连续目标检测任务及模型
原始数据集包含多类别样本,根据增量式连续学习的一般设定,需要将数据依照不同场景设定分为旧类别数据与新类别数据。图1 为知识蒸馏框架下增量式连续目标检测模型的示意图。
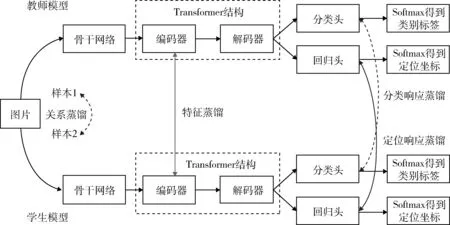
图1 增量式连续目标检测模型(本方法仅使用特征蒸馏,其他蒸馏方法以虚线示意作为对比)Fig. 1 Incremental continuous target detection model (only feature distillation is used in this method,other distillation methods are shown as dashed lines for comparison)
如图1 所示,首先进行旧类别数据训练。模型基于旧类别训练图像数据集与旧类别标签,训练神经网络得到教师模型。其中,训练、验证与测试部分数据集均为旧类别目标的标注数据。模型包括利用骨干网络提取图像特征,将深层特征和浅层特征拼接生成多尺度特征图。特征图通过包含编码器和解码器的特征提取网络得到最终特征向量。通过分类输出层与回归输出层得到分类软标签与回归软标签。最终经过Softmax 等激活函数得到类别标签与回归坐标。
其次进行新类别数据训练。模型基于新类别训练图像数据集与新类别标签,再次训练神经网络得到学生模型。其中,训练和验证数据集仅包含新类别标签,测试数据集包含新类别标签与旧类别标签。学生模型需要在仅学习新类别标签的情况下,在测试数据集上同时识别出新类别与旧类别目标。
为缓解学生模型对于旧类别知识的遗忘,提高学生模型在测试数据集上旧类别目标识别准确率,学生模型应接受教师模型输出信息,以保存相应的旧类别知识。教师模型输出信息可包含类别标签信息,类别软标签,以及特征信息等。该模型信息传递过程被称为知识蒸馏。
1.2 增量式连续目标检测中的知识蒸馏
现有应用于增量式目标检测的知识蒸馏方法主要包含3 种类型,包括基于特征的知识蒸馏[11]、基于响应的知识蒸馏[15]和基于关系的知识蒸馏[14]。图1 示意了不同知识蒸馏在模型中的出现位置。
基于特征的知识蒸馏方法都是通过精心选择特定网络层特征来实现旧知识提取和传递。文献[16]提出细粒度特征蒸馏法和多视图相关蒸馏法选择性地利用模型中间层来保留旧类别的模式。文献[13]提出保留教师和学生特征图之间的通道式、点式和实例式关联。文献[11]根据图片底层特征的统计信息弹性选择蒸馏区域。文献[14,16-17]提出了其他提取模型中间层特征并加以蒸馏的方法。
基于响应的蒸馏方法直接对教师模型与学生模型的分类输出和定位输出进行蒸馏,去掉了待蒸馏特征的选择与设计。例如,LwF(learning without forgetting)是首个利用知识蒸馏方法的增量式连续检测模型,它将教师模型产生的旧类别预测标签与新类别标签混合进行训练,以保存模型对于旧类别的记忆能力[13]。文献[18]提出了一种完全基于响应的蒸馏方法,根据教师模型输出响应的均值与方差进行知识的自适应选择与过滤,从而提升知识传递的质量。文献[11]将检测模型的最终输出响应与RPN(region proposal network)输出响应相结合进行知识蒸馏。
基于关系的蒸馏方法通过度量学习等方式挖掘样本之间的关系实现知识的传递。文献[14]通过对于输出层、中间层和不同实例之间关系的相关蒸馏,讨论模型蒸馏的合适位置。
因为响应知识的形成依赖于特征知识,而样本关系挖掘又效率较低。因此在上述3 种蒸馏类型中,基于特征蒸馏的增量式连续目标检测方法得到更为广泛的研究。然而,目前特征蒸馏方法在很大程度上依赖于底层细节特征的选择,而对高级语义特征的重要性探索不足。
2 基于高级语义特征蒸馏的连续目标检测
在深度神经网络模型中,特征向量包括高层语义特征与底层细节特征。高层语义特征位于深层网络,富含深层抽象信息,例如目标类别语义信息与边界框定位信息等。底层细节特征位于浅层网络,富含空间细节信息,例如轮廓、边缘、颜色、纹理和形状等。高级语义特征与底层细节特征均在教师模型的目标信息与背景信息中进行表达。新类别目标在教师模型中被错误地表达为背景信息,而学生模型需要将其重新识别为有效目标。因此区分有效目标、正确背景、错误背景是正确利用高层语义特征与底层细节特征的关键。本文提出一种注意力掩码方法来区分3 种信息:①教师模型中的目标信息;②学生模型中的目标信息;③教师模型中的正确背景信息。
教师模型中的目标信息中包含了旧任务所有的前景信息。以往的工作通常直接使用前景信息中的所有特征,并平等地对待每个位置。但是实际情况是,即使在每个前景框中,特征也是不完全一致的。因此本文提出,在分离出前景背景信息之后,仍然需要对前景框提取里面的有价值区域进行蒸馏。为了解决这个问题,需要模型首先通过计算教师模型经过解码器之后所生成的语义信息与学生模型经过解码器之后所生成的语义信息差异,选出差异大的区域作为需要重点关注的重要特征位置。将重要特征位置信息以掩码的形式加到对应的特征图上,之后再进行相应位置的特征蒸馏损失。将待检测的图像(包括新类别目标与旧类别目标)输入到训练好的学生模型进行目标检测。
根据上述描述这里提出了一种结构化特征提取方案,包括3 个步骤:首先,计算教师和学生之间高层语义表示的差异,如式(1)所示。然后,计算低层特征表示的差异,如式(2)所示。接着,在高层语义差异的指导下最小化底层特征差异,如式(3)所示。由于前景与背景包含信息不同,因此需要使用注意力掩码分离前景与背景。语义引导的特征提取仅添加到前景,因为前景具有更为重要的语义信息。最后,计算各项差异之和作为最终的蒸馏损失,如式(4)所示。
将本文方法的详细步骤整理如下:
step 1:计算高级语义特征的差异
式中:Steacher为老师模型高级语义特征;Sstudent为学生模型高级语义特征。
step 2:计算浅层特征的差异
式中:Fteacher为老师模型浅层(或底层)特征图;Fstudent为学生模型浅层(或底层)特征图。
step 3:计算前背景分离掩码
式中:Hold和Wold为老师模型检测框的长和宽。
step 4:计算整体蒸馏损失
式中:Lossdist为教师与学生模型蒸馏损失函数。
本方法无需对原始检测器进行“侵入式”的结构改进和设计,因此对各类具体的Query-based Transformer 检测器都有好的适配能力。此外,本方法还具有简化增量式连续目标检测方法设计复杂性的优点,主要体现在以下2 个方面:(1)本方法采用Transformer 检测器构建;其高级语义特征采用查询特征(query feature,QF)的方式生成,查询特征的数量一般在100~300 之间。但传统CNN 检测器,其高级语义特征大多采用锚点特征(anchor feature,AF)的方式生成,且锚点数量一般不少于2 000 个。每个QF 或AF 对应一个潜在目标物体,但事实上单张图像上的有效目标数量一般不超过20 个,因此QF 比AF 提供了更有效率的高级语义特征生成方式。基于此,Transformer 检测器无需对输出结果使用非极大值抑制(non-maximum suppression,NMS),在输出筛选上更加简洁。所以Transformer 检测器有效简化了高级语义特征的生成和筛选方式,进而为基于高级语义特征的知识蒸馏带来便利。
最后,现有方法基本都组合使用多种知识蒸馏以缓解灾难遗忘,图1 示意了不同知识蒸馏在神经网络模型中的位置。例如近期的最优模型ERD[11]同时使用了分类和定位2 种知识蒸馏。而本文方法仅使用了特征蒸馏,进而无需在教师和学生之间设置多组蒸馏损失函数。这一优势进一步简化了增量式连续检测方法的设计复杂性。
3 增量式连续目标检测实验结果
3.1 增量式连续目标检测实验设置及评估方法
为验证所提出的算法性能,本文进行了2 个实验:一个是在不同连续学习场景对于算法进行连续学习能力验证,另一个通过对于不同有价值区域进行蒸馏讨论语义特征引导的意义。
实验1 的设置包括基于公开数据集MS COCO的单步连续学习场景(40 类+40 类、50 类+30 类、60类+20 类和70 类+10 类)与多步连续学习场景(40 类+20 类+20 类)。其中40 类+40 类场景是指模型首先学习前40 类数据作为旧样本,在此基础上再学习后40 类数据作为新样本。其余场景设置同理。实验2的设置为40 类+40 类连续学习场景。通过比较不同有价值区域的蒸馏结果,讨论语义特征引导的意义。
增量式连续目标检测的评价一般通过与相对应的整体学习方法进行比较来确定[13]。具体的评价指标包括绝对差异(absolute gap,AbsGap)与相对差异(relative gap,RelGap),其定义分别如式(5)和式(6)所示:
式中:mAPcontinual为增量式连续学习下的目标检测精度;mAPoverall为对应数据类别下整体学习的目标检测精度,后者一般被认为是前者的上界。AbsGap和RelGap都衡量增量连续学习与整体学习之间的性能差距,进而反映出各自的增量式连续学习能力。特别地,RelGap去除不同检测器基线的影响,衡量增量连续学习与整体学习之间的相对性能差距。
3.2 不同特征蒸馏区域的比较实验
本文首先讨论不同有价值区域的蒸馏结果。如表1 所示,添加完整特征蒸馏与基线模型差异较小。但是如果将特征拆分为前景与背景信息,则性能有所提升。之后将高级语义特征用于引导前景信息蒸馏,则最终性能得到显著提升。
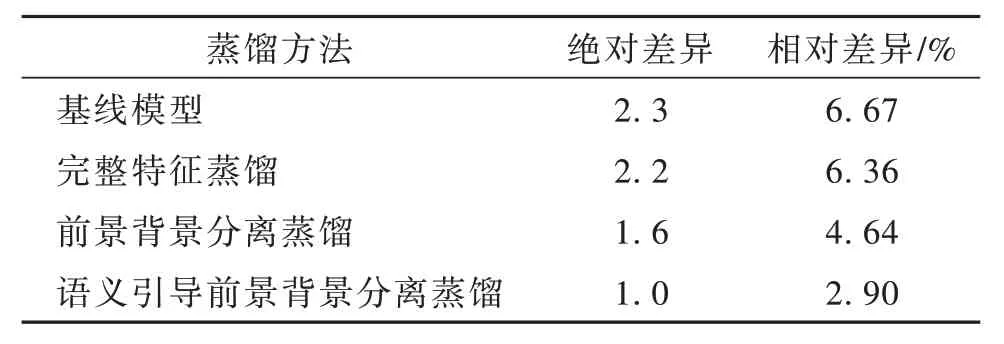
表1 分离实验结果Table 1 Separation experiment results
如表1 所示,通过在基线模型上添加不同类型的特征蒸馏方法,逐步证明了完整特征蒸馏、前背景分离特征蒸馏、语义引导前景背景分离蒸馏的性能提升效果,进而综合性说明了不同蒸馏区域的选择在特征蒸馏中的重要性。表1 的实验证明,前景信息与背景信息存在显著信息差,以及高级语义信息对于关键信息选取有重要作用。
3.3 增量式连续目标检测实验结果
表2 显示了本文方法与先前典型方法的增量学习性能比较结果。其中,LwF[13]是基于分类响应的的蒸馏方法,RILOD[15]是基于特征和分类响应相结合的蒸馏方法,SID[14]是基于特征和关系相结合的蒸馏方法,ERD[11]是基于分类响应和定位响应相结合的蒸馏方法。本文方法为基于特征的蒸馏方法,通过对比多种不同蒸馏方式下的增量学习方法,从而充分揭示其在缓解灾难性知识遗忘、提升增量式连续目标检测性能方面的显著性。
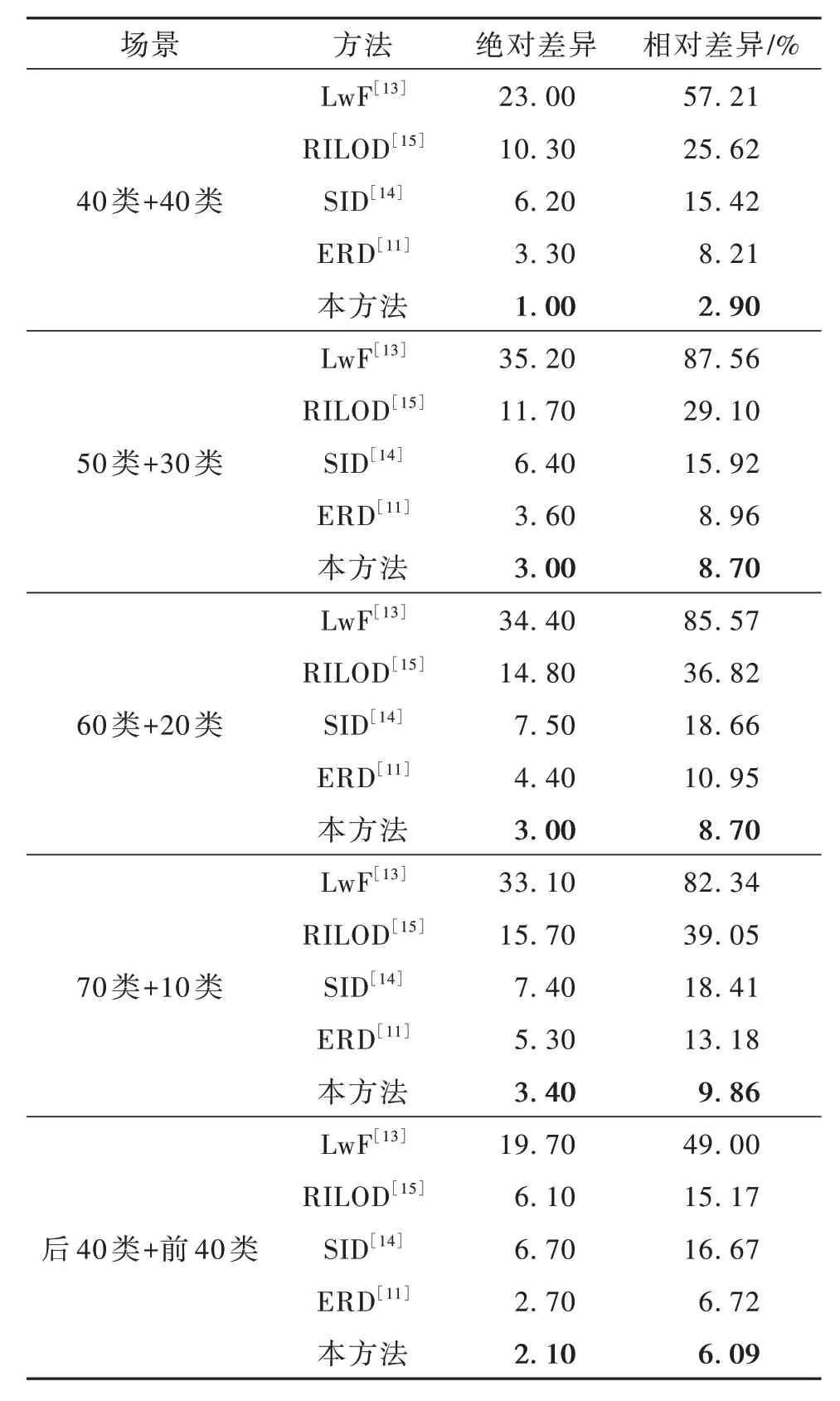
表2 单步连续学习目标检测实验结果Table 2 Results for one-step IOD
表2 中显示40 类+40 类、50 类+30 类、60 类+20类和70 类+10 类场景下的连续学习性能。如40 类+40 类任务所示,与先前方法LwF,RILOD,SID 和ERD 相比,本方法与基于整体学习的上限差距更小,证明本方法的有效性。同时,在后40 类+前40类场景下性能也有显著提高,这表明该方法可以在不受类别顺序影响的情况下缓解灾难性遗忘。对于所有其他场景(50 类+30 类、60 类+20 类和70 类+10 类),该方法也超越了当前最好水平。
本文还讨论了多步连续学习目标检测场景下不同方法的性能差异,实验结果如表3 所示。表3中A 代表在首批数据下的整体式正常学习阶段,B 代表在后续增量数据下的连续学习阶段。A(第1 类~第40 类)表示首批数据包括第1 类到第40 类。B(第41 类~第60 类)表示增量数据包括第41 类到第60类。从A 到B,模型需要连续学习多个步骤,以适应多步增量数据划分。表3 显示本方法与完整训练的差距显著小于其他模型,这表明了它在多步场景下缓解灾难性遗忘的出色能力。

表3 多步连续学习目标检测实验结果Table 3 Results for multi-step IOD
综合表2,3 结果可见,本文所提出方法具有更好的增量式连续目标检测识别能力,其性能提升有以下3 个方面的内在原因。
(1)传统特征蒸馏方法直接计算浅层特征差异进行知识传递,其工作原理如式(2)所示。由于浅层特征往往强于对图像物理层面的细节信息(如边缘、轮廓、纹理等)进行表达而缺乏更强的鲁棒性,因此在此层面的学习使得学生模型更倾向于拟合和模仿教师模型中旧类别的欠鲁棒特征。这些欠鲁棒特征易于受到新类别知识的冲击而劣化,从而导致旧类别知识的遗忘。
(2)本文的知识蒸馏方法额外计算了高层语义特征之间的差异,其工作原理如式(1)所示。由于高层语义特征存在于检测器头部网络之中,是最接近分类输出端和定位输出端的特征,因而具有更强的变换不变性和稳定的语义表示能力。因此,在此层面的学习使得学生模型更倾向于拟合和模仿教师模型中旧类别的稳定语义表示,从而提升新类别学习过程中旧类别知识的稳定性。
(3)本文还计算了高级语义与浅层特征之间的交互作用,其工作原理如式(4)所示,这使得鲁棒特征学习与稳定语义学习产生有效交互,实现语义引导下的特征学习,从而进一步缓解灾难遗忘,提升增量式连续目标检测能力。
4 结束语
针对基于深度学习方法的目标检测器采用整体学习范式,在新类别数据增量出现时无法有效进行连续学习的问题,本文创新性地提出一种基于高级语义特征蒸馏的增量式连续目标检测方法。不同于现有方法仅依赖浅层特征蒸馏,该方法首次引入高级语义特征蒸馏,并通过高级语义特征动态选择浅层特征,实现高价值特征知识的传递,有效提升了增量式连续目标检测任务的性能。同时,该方法充分利用了Transformer 检测器的优势,简化了现有增量学习方法中组合式知识蒸馏的复杂设计,创新性地仅使用特征蒸馏即实现了更好的增量式连续目标检测性能。
本研究在目标感知领域具有广泛的应用前景,可促进检测识别方法从静态封闭的有限应用场景向动态开放场景发展,同时可推广至红外以及多模态场景下的各类增量式连续目标识别任务中。本研究有助于增强各类智能系统的持续自主学习能力,提升在高动态强开放场景下的任务遂行能力,推动智能感认知技术和智能感认知系统的深入发展。
