融合瓶颈注意力模块的改进YOLOv7 织物疵点检测算法
2024-03-16孙丽丽孟洪兵杨安迪孙文彬
陈 军 孙丽丽 孟洪兵 杨安迪 孙文彬
[1.塔里木大学,新疆阿拉尔,843300;2.塔里木绿洲农业教育部重点实验室(塔里木大学),新疆阿拉尔,843300]
当前,人工视觉检测仍是主要的织物质量检验方式,但人工检测容易产生主观误判和漏检,影响生产效率和产品质量[1-3]。随着深度学习在图像特征提取和目标定位上取得优异效果,深度学习算法逐步应用于织物疵点检测领域中。
基于深度学习的检测算法,以基于单阶段检测算法(One-stage)和基于两阶段检测算法(Twostage)为代表。后者首先生成目标候选框,然后再对候选框进行分类和位置回归,以Faster RCNN 系列和Mask RCNN 系列算法为代表[4-5],对目标的检测精度高,但检测速度较慢,计算量和时间复杂度高,难以适应工业检测实时性要求。前者直接使用卷积神经网络(CNN)预测目标的类别和位置,不需要生成候选区域,以SSD、YOLO 系列等算法为代表[6-7],计算速度快,实时性好,因此易满足工业实时检测的需求。如蔡兆信等提出改进Faster RCNN 网络的RPN 结构来融合多层不同尺度特征图,增加图像细节提取的能力[8];陈梦琦等将注意力机制与Faster RCNN 模型相结合,优化网络模型,提高网络对疵点图像的检测精度和速度[9];黄汉林等利用MobileNet 的深度可分离卷积取代SSD 主干网络中的普通卷积,加快网络的检测速度,提高检测准确率[10];石玉文等改进YOLOv5-Eff,将EfficientNet-B1 网络作为主干特征提取网络,引入ACmix 注意力模块提高网络对小尺度目标的敏感度,将SiLU 与Swish 激活函数结合,根据目标数量和密度动态调整阈值,提高算法灵活性[11]。
基于上述算法,疵点检测取得较好成果,但在实际应用中,针对多尺度、微小目标的疵点检测精度和速度依然是行业应用的瓶颈问题,但随着YOLOv7 提出高效长程注意力网络架构,目标检测算法的精度和速度有了进一步提升,YOLOv7相同体量下比YOLOv5 精度更高,速度快120%。为了提升疵点检测精度和速度,本研究针对疵点尺度不一、目标微小、形状多变的特点,提出了一种改进YOLOv7 模型的织物疵点检测算法,以期提升检测精度和速度。本研究首先采用可形变卷积(DConv)[12]替换YOLOv7 网络中的标准卷积模块,融合更多感受野,在采样时更贴近疵点的形状和尺寸特征,更具有鲁棒性;其次,在网络中嵌入颈部注意力模块(Bottleneck Attention Module,BAM)[13],捕获更多疵点的特征信息,强化对微小疵点目标的敏感度;最后,构建包含扎洞、擦洞、织稀、吊经、跳花、污渍6 种疵点类型的织物疵点数据集,通过对样本集进行预处理送入模型训练,在织物疵点数据集进行消融和对比试验,验证本研究改进算法对织物疵点检测的有效性和鲁棒性。
1 YOLOv7 网络结构
YOLOv7 是目前YOLO 系列最为先进的检测算法之一,提出了高效聚合网络(ELAN)、重参数化卷积、辅助头检测、模型缩放、动态标签分配等策略。YOLOv7 首先对输入的图片调整大小后再将其输入到特征提取网络(Backbone)中进行特征提取,然后送入检测头(Head)进行特征融合网络处理,经过RepConv 结构输出预测结果。YOLOv7 网络结构图如图1 所示。
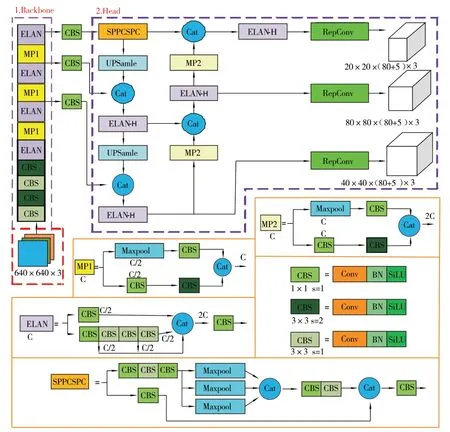
图1 YOLOv7 网络结构图
YOLOv7 网络模型的Backbone 部分主要由标准卷积、ELAN 模块、MP 模块构成50 层网络。其中ELAN 模块的高效网络结构可以控制最短和最长的梯度路径,学习到更多的特征,它的优势是保持特征大小不变,仅在最后一个CBS 输出为需要的通道数;MP 模块中两个分支完成空间降采样后进行合并,得到通道数相等但空间分辨率缩小2 倍的特征图,重复堆叠ELAN 模块和MP模块即可输出包含主要信息的3 个特征层,再利用特征金字塔(Feature Pyramid Networks,FPN)[14]对3 个特征层进行特征再提取获得3 个加强特征层,采用FPN+PAN(PANet)结构,对特征进行上、下采样实现特征融合;SPPCSPC 模块经过并行多次的MaxPool 操作,避免图像失真、训练梯度消失等问题。
2 改进的YOLOv7 疵点检测算法
YOLOv7 中有限的感受野设计对图像中的微小目标检测能力有限,缺乏特征重用限制了其捕捉物体之间空间关系的能力。因此针对疵点检测中尺度不一、目标微小、形状多变的特点,本研究从替换标准卷积块和嵌入瓶颈注意力模块改进YOLOv7,优化疵点检测算法。
2.1 采用可变形卷积提取特征信息
标准卷积进行卷积操作时,将卷积核权重与输入特征图对应位置元素相乘并求和得到输出特征图元素,滑动窗口计算输出特征图,对形状规则的物体效果较好,但疵点形状、大小不规则时,模型适应性差,泛化能力弱,因此采用可变形卷积实现自动调整尺度或者感受野。可变形卷积[15]是在标准卷积操作中采样位置增加了一个调整卷积核的偏移量(offset),使得卷积核的形态更贴近特征物,集中于目标区域。可变形卷积示意图如图2所示。

图2 可变形卷积示意图
可变形卷积对应的卷积采样区域为正方形卷积核表示的点向各方向偏移的点,因此采用可变形卷积在采样时可以更贴近疵点的形状和尺寸,感受野更大。
2.2 嵌入瓶颈注意力模块
注意力机制主要通过嵌入额外网络结构加强学习输入数据对输出数据贡献,过滤掉与目标相比不太关注的背景信息,着重于感兴趣的目标信息。在疵点检测中,本研究建立疵点特征提取工程融合注意力机制,让模型有效且精准地提取特征,让下游任务更聚焦与任务关系更密切的信号。常用的注意力模块是卷积块注意力模块(Convolutional Block Attention Module,CBAM),融合了通道注意力和空间注意力机制,通过最大池化和平均池化增加通道注意力的语义丰富性,提升了图片的全局信息关注,但在注意力加权计算时没有残差结构,计算量稍大,同时通过标准卷积操作提取特征,对微小目标的关注不够。因此本研究提出采用颈部注意力模块(Bottleneck Attention Module,BAM),BAM 是融合通道和空间注意力的混合注意力机制,网络结构如图3 所示,上面分支为通道注意力机制,先经过全局平均池化层,减少参数量,增强模型的准确性和稳定性,抑制网络中的过拟合,然后是两层全连接层,最后是批量标准化模块BN 层进行归一化,无激活函数;下面分支为空间注意力,先将特征层通过1×1 的卷积将输入通道数量压缩,再经过两个3×3的膨胀卷积做特征融合,加强模型对图像每个像素与周围关系的理解,通道数不变,最后通过一个1×1 的卷积将通道数变成1。将通道注意力机制与空间注意力机制生成的特征图MC(F)、MS(F)融合成和输入特征尺寸大小相同的特征图,再与原始输入图做跳层连接后输出尺寸大小不变的特征图。

图3 BAM 网络结构
由于BAM 模块中参考了ResNet 网络中的残差结构,采用BN 层,因此训练效率更高,同时使用了膨胀卷积,对目标细节建模效果更好。利用梯度加权类激活映射(Gradient-weighted Class Activation Mapping,Grad-CAM)[16]对BAM 注意力机制效果进行可视化,如图4 所示。

图4 BAM 注意力机制效果图
可以发现,引入BAM 后,特征覆盖到了待识别物体的更多部位,这表明BAM 注意力机制让网络学会了关注重点信息,可以提高目标检测和物体分类的精度。
2.3 改进后的YOLOv7 模型
改进后的YOLOv7 模型网络结构如图5 所示,在特征提取网络中采用可形变卷积替换标准卷积模块,融合更多感受野,在采样时更贴近疵点的形状和尺寸特征;在特征网络3 个特征输出层前嵌入颈部注意力模块,捕获更多疵点的特征信息以提高对微小疵点目标的敏感度,具体改进点如图5 中红色标记块。
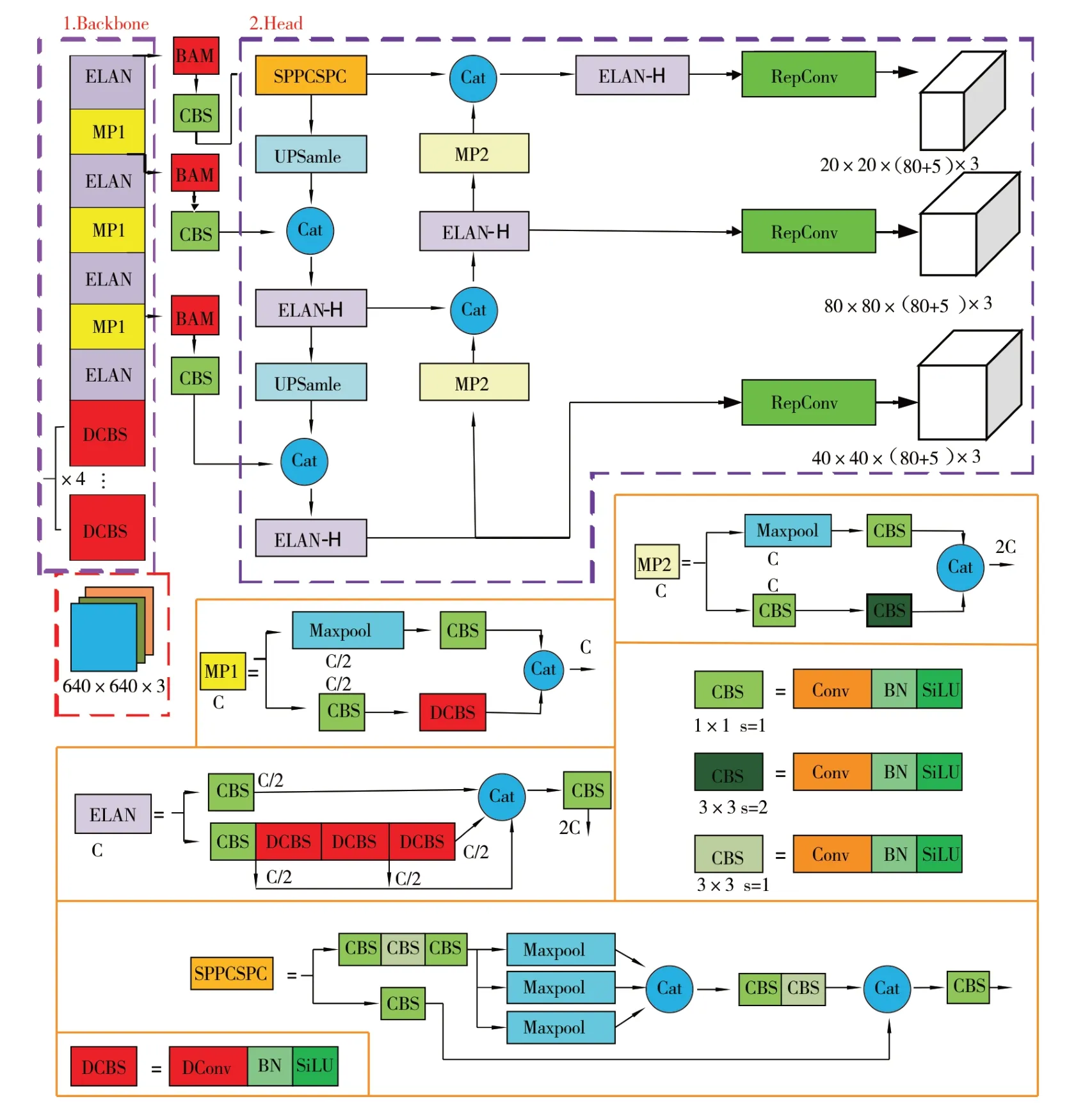
图5 改进后的YOLOv7 模型网络结构
3 试验结果与分析
3.1 数据集
本研究使用的织物疵点数据集是来自于江苏阳光集团公开的织物图像数据集[17]和阿克苏纺织工业园区3 家纺织科技公司真实生产场景下采集的织物数据。经过筛选可用于模型训练的数据包含扎洞、擦洞、织稀、吊经、跳花、污渍6 种疵点类型,样本数量分别为1 260 张、480 张、510 张、532张、335 张、1 421 张,共计4 538 张,图6 为不同类型的疵点图像示例。此外,没有包含任何疵点的正常图像作为背景类,样本数量为4 000 张。样本集原始图像分辨率为2 560 pixel×1 920 pixel,图像特征细节清晰,数据标注前全部经过经验丰富的验布工人确认疵点类型。

图6 不同类型的疵点图像
3.2 数据预处理
原始数据集中图像存在3 个问题:一是样本类别不均衡,如正常样本与跳花样本比例超过12∶1,扎洞与跳花样本比例超过3∶1;二是疵点区域占比很小,疵点占比不到1%的样本超过82%;三是疵点尺度变化大,疵点尺寸长度小到100 pixel、大到2 500 pixel。数据样本的问题会导致模型训练过拟合、精度差、泛化能力弱,除此之外,原始图像分辨率较大,YOLOv7 采用640 pixel×640 pixel 大小输入,直接调整会牺牲微小疵点目标的图像细节特征,降低图像所带的信息量,所以需要对训练数据进行预处理。针对上述问题,本研究首先以滑动窗口为640 pixel×640 pixel 大小,滑动步长为320 pixel 进行移动裁剪,将每张原始图像切割成48 张图像细节不变的小尺寸图像,原尺寸图像则直接缩小为640 pixel×640 pixel 大小,达到增加带疵点图像的样本和增加小尺度疵点样本数量的目的;然后再针对处理后疵点图像进行数据增强,从现有的疵点样本中利用多种能够生成可信图像的随机变换来增加样本以提升模型泛化能力,本研究中所有数据增强使用Mosaic、Mixup、cutout、HSV、随机抖动和几何变换等方法[18-20]。最终,模型训练样本集经过筛选最终选择无疵点图像4 000 张和扎洞2 680 张、擦洞1 980 张、织稀2 126 张、吊经2 230 张、跳花1 870张、污渍2 960 张,共计17 846 张作为训练样本。
3.3 试验环境
本试验运行环境基于64 位Win10 操作系统,CPU 为Intel(R) Core(TM) i9-12900K,GPU 为NVIDIA GeForce RTX 3080 Ti 12 G,GPU 加速为CUDA11.0,编译语言Python3.10.9,深度学习框架为PyTorch2.0.1,数据集按8∶1∶1 的比例划分为训练集、验证集和测试集。模型训练前设置训练参数:选用官方提供的YOLOv7. pt 预训练权重进行,输入图像尺寸为640 pixel×640 pixel,标签格式为YOLO 格式,Batchsize 大小为8,以最大限度地提高GPU 设备的内存使用率,优化器为Adam 优化器并设置初始学习率为0.01,迭代次数Epoch 为200。
3.4 评价指标
为了评价模型对疵点识别检测结果的优劣,评价标准选用精确率(Precision,P)、召回率(Recall,R)、平均精度(Average Precision,AP)、平均精度均值(Mean Average Precision,mAP)与检测速度(Frames Per Second,FPS)[21],计算公式如式(1)~式(5)所示。
式中:TP为正确识别的数目,即样本预测标签为正且实际的标签也为正;FP为错误识别的数目,即样本预测标签为正但实际的标签为负;FN为未检测到的正确目标的数目,即样本预测标签为负而实际标签为正;AP是以召回率R为横坐标,精确率P为纵坐标绘制P-R曲线,曲线与坐标轴围成的面积,P-R曲线可以直观地显示出样本的精确率和召回率在总体数据上的关系,衡量模型对某类疵点识别的效果;mAP为各类平均精度;FPS即每秒内检测图片数量,采用“帧/s”表示,其数值越大,表明模型的检测速度越快,检测速度是实现实时检测的基础;n为模型处理图片张数;T为所消耗时间。
3.5 消融试验
为验证本研究提出的YOLOv7 改进算法有效性,在数据集上进行了8 组消融试验,结果如表1 所示。mAP@0.5 为所有类别的识别平均准确率均值(IoU阈值为0.5),均在输入图像大小为640 pixel×640 pixel 时计算得出。
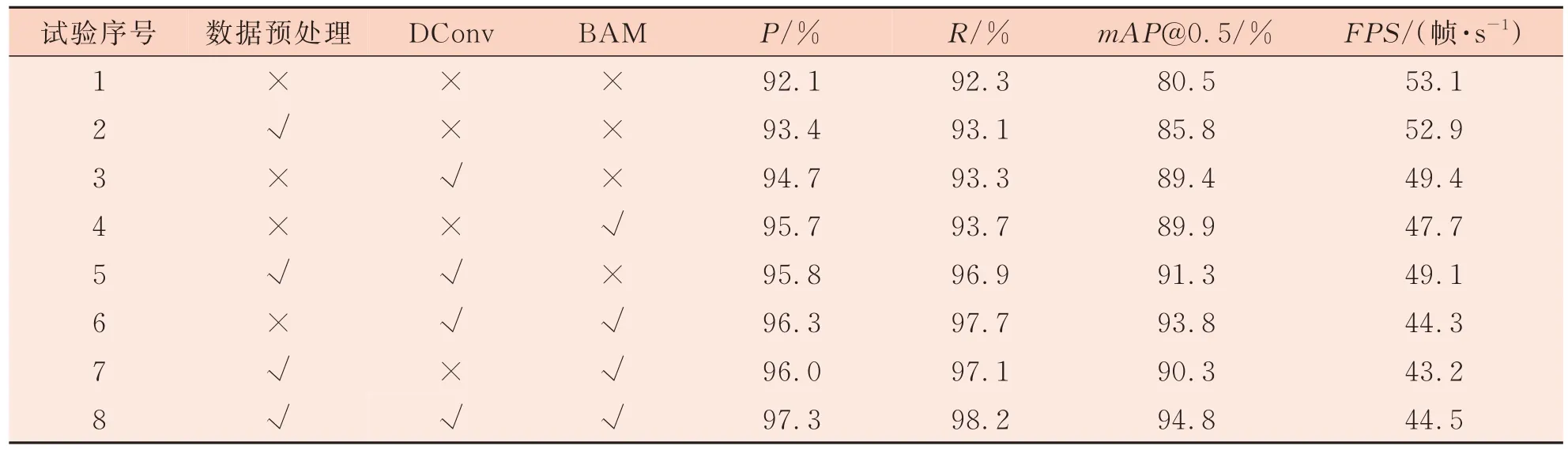
表1 消融试验
从表1 可以看出,试验1 仅采用YOLOv7 模型,其检测精确率为92.1%,检测速度为53.1 帧/s。试验2 对数据样本进行预处理后,检测精确率提高1.3 个百分点,说明预处理对提升模型检测精度具有积极作用,有效提升了疵点图像特征信息量;检测速度降低了0.2 帧/s,模型整体性能有所提升。试验3 只优化了特征提取网络,将标准卷积块替换为可形变卷积,检测精确率提升了2.6 个百分点,说明可形变卷积扩大感受野,对疵点的特征信息学习效果更好,但同时检测速度下降了3.7 帧/s,因为在特征提取网络中增加了偏移量的计算;试验4 在特征网络3 个特征输出层前嵌入了BAM 注意力机制,检测精确率提升了3.6个百分点,效果明显,说明注意力机制使得模型对疵点关注更高,降低了背景信息的干扰,更好地进行特征信息提取;试验5 加入数据预处理和可形变卷积,使得检测精确率提升了3.7 个百分点,说明优化组合效果优于单一处理优化的效果;试验6 加入可形变卷积和BAM 注意力机制,检测精确率提升了4.2 个百分点,说明可形变卷积+BAM的组合效果优于数据预处理+可形变卷积;试验7 加入数据预处理和BAM 注意力机制,检测精确率提升了3.9 个百分点,说明数据预处理+BAM组合效果优于数据预处理+可形变卷积组合,但效果不如可形变卷积+BAM 的组合;试验8 是融合本研究提出的优化方式,检测精度提升了5.2个百分点,mAP@0.5 增加了14.3 个百分点,提升效果最优,但同时检测速度降低了8.6 帧/s,因为在网络中参数量提升带来了计算量的增加。由消融试验可得,模型加入BAM 作用最有效其次是加入可形变卷积,两者组合处理优于单一处理,三者组合优于两者组合,数据预处理、DConv、BAM对疵点识别的性能整体提升具有积极作用。本研究改进算法检测结果如图7 所示。

图7 本研究提出的改进YOLOv7 模型检测效果图
3.6 注意力机制对比试验
为了进一步验证本研究BAM 注意力机制针对疵点微小目标的有效性,在本研究改进的YOLOv7 特征提取网络的同样位置分别嵌入scSE、CBAM、SCNet 和BAM 共4 种注意力机制做对比试验,然后在相同的配置下使用同一测试集进行网络性能测试,结果如表2 所示。可以看出,在网络中分别嵌入4 种注意力机制,都能实现对模型检测性能的提升,其中BAM 注意力机制对网络性能的提升较大,原因在于scSE 只是增强有意义的特征,抑制无用特征,没有重点采样微小目标,CBAM 和SCNet 扩大了空间位置的感受野,提升了全局注意力,但对微小目标的关注不够,通过对比试验证明了BAM 注意力机制对微小目标检测的先进性。
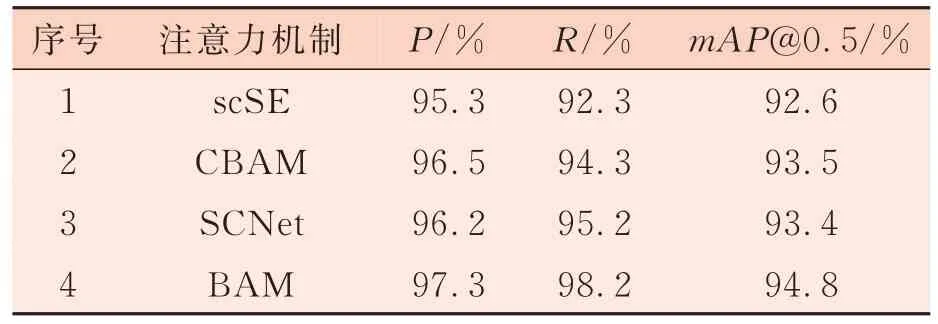
表2 不同注意力机制对比试验
3.7 主流算法对比试验
为验证本研究提出方法的有效性与先进性,将近年来基于机器视觉的目标检测主流算法[22]与本研究方法在同一试验环境下进行性能对比,结果如表3 所示。
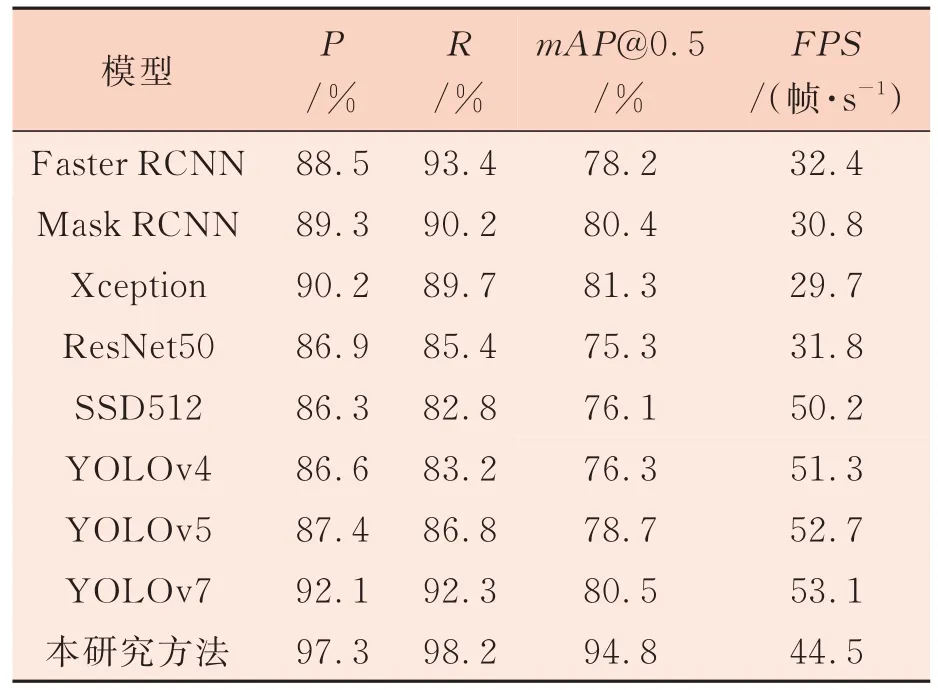
表3 主流算法性能对比
由表3 可知,本研究改进的YOLOv7 疵点检测算法在保持较快检测速度的同时对疵点目标的检测效果更好。通过试验发现,两阶段目标检测算法对目标检测定位更准确,可以检测多尺度的物体,但检测速度慢,需要更强的算力。YOLO系列和SDD 同为单阶段目标检测算法,最明显的优势是快速和高效,易于训练,适用于实时疵点目标检测,缺点是对微小目标检测能力不足,容易出现漏检情况。YOLOv7 相比于其他算法在检测速度和精度之间达到了良好的平衡,同时通过改进的YOLOv7 不仅提高了网络的mAP,而且弥补了原始模型在微小疵点目标检测方面的不足,提升了全局信息获取能力和强化了对微小目标的敏感度,使得模型适应能力更好,鲁棒性更强。
4 结语
在疵点图像检测识别中,因疵点目标尺度不一、微小目标特征难以捕获,检测效率低、容易漏检等问题,本研究基于YOLOv7 算法提出改进特征提取网络中的卷积块以扩展感受野,丰富提取的特征信息和嵌入颈部注意力机制强化对微小目标的敏感度,同时对数据集进行预处理,扩充有效数据集以提升模型性能,提高泛化能力。相比于原始YOLOv7 算法,本研究改进的YOLOv7 算法的检测精确率提升了5.2 个百分点,mAP@0.5 提高了14.3 个百分点。通过消融试验证明了本研究改进方法的有效性,同时与Faster RCNN、YOLO 系列等模型检测对比,采用精确率、召回率、mAP@0.5 值、FPS值进行定量分析,结果显示改进的YOLOv7 在检测精度和速度方面具有较好的性能,基本满足织物疵点检测需求。但由于疵点种类繁多,疵点样本收集受限,在今后的工作中需要进一步加强织物疵点图像种类和数量的扩充,尝试更多性能提升方法,以提高疵点检测模型的检测精度和速度。
