支持场景表观差异的无人机图像视觉定位方法
2024-03-12王骞仟
王骞仟, 熊 源, 姜 涵, 周 忠*
1. 北京航空航天大学, 北京 100191
2. 虚拟现实技术与系统全国重点实验室, 北京 100191
0 引 言
计算拍摄图像相对于三维场景模型的六自由度相机位姿是无人机自主导航的关键步骤.全球卫星导航系统(global navigation satellite system, GNSS)拒止条件下,在现有的三维地图中进行视觉定位是许多自主和半自主智能体工作的基础.无人机在同步定位与测绘、结构检测、环境监测与军事安防等应用领域发挥着越来越重要的作用[1-3],这也带来了对视觉定位的鲁棒性和精度的更高要求.当前主流的视觉定位方法倾向于利用场景的三维信息[4-6],首先在二维待查询图像和三维场景之间建立2D-3D匹配点对,然后使用这些点对的对应关系计算相机位姿[7].在上述过程中,位姿计算高度依赖足够多数量的正确匹配点对,所以特征点匹配是关键因素.然而,在实际工作中,无人机拍摄往往面临着和场景模型不同的季节、天气与时段,使得拍摄的图像和场景模型的已有纹理表观差异很大[8],特别在近地面时,由于常用的特征检测器对光照条件的变化十分敏感[9],光照和纹理的变化会导致特征点无法匹配,对视觉定位技术带来了很大挑战.
本文提出使用视角合成的方法来克服不同季节、光照、视角条件下场景表观差异大的问题.在该方法框架中,对传统视觉定位方法的流程进行扩展,使用少量的跨季节图像进行视角合成,扩充跨季节图像检索数据库,解决传统方法场景光照和纹理差异大而引起的图像检索和特征匹配困难等问题.上述过程的一个主要难题是如何使用有限的离散图像生成连续的新视角图像.传统的方法倾向于直接使用二维的图像进行图像合成,但这类方法并不能有效利用原始场景的深度信息,导致生成错误的视角合成结果,进而影响后续视觉定位的精度.针对这个问题,提出一个将待合成具有表观差异的图像与原始场景三维模型进行融合的图像合成方法,该方法基于阴影映射的思想,结合空洞填补技术,利用原始场景的几何信息和跨季节图像的纹理信息,生成了与待定位图像光照更一致、视角更相近的合成图像,提升了传统视觉定位方法的精度.
本文的主要贡献可以分为以下3部分:
1)提出了一个扩展的视觉定位方法框架,解决了大表观差异下图像特征匹配困难的问题;
2)提出了一个基于阴影映射的图像合成方法,综合利用了待合成图像的纹理和原始三维场景的几何信息,解决图像表观差异和大视差问题;
3)提出深度卷积神经网络的空洞填补算法对合成图像进行优化,进一步提升特征匹配的准确率.
本文通过图像合成质量对比实验和视觉定位实验阐明了所提出的方法对比现有二维图像合成算法的优越性,表明了图像合成技术可以解决图像表观差异带来的定位精度下降问题.
1 相关工作
1.1 无人机图像定位技术
近年来,随着无人机技术在各个领域的广泛应用,无人机图像的视觉定位已成为一个备受研究者关注的热门课题.常见的无人机图像定位方法主要包含基于惯性导航系统(inertial navigation system,GNSS-INS)的无人机定位方法和基于视觉的无人机定位方法[10].
(1)基于GNSS-INS的无人机定位
基于GNSS-INS的无人机定位方法是无人机定位领域的早期方法,这类方法通常结合GNSS和INS来进行无人机的位姿估计[11],如使用GPS、加速度计、陀螺仪和磁力计组成的定位系统,既可在通常情况下提供高精度的定位服务,又可在GNSS信号不稳定或不可用时,通过惯性导航系统提供的数据来实现无缝导航和定位.该类方法常常使用卡尔曼滤波方法[12-13]和扩展卡尔曼滤波方法[14]融合两个系统的数据,减少GNSS-INS系统的噪声和误差,以获得更加准确的位姿估计结果.尽管基于GNSS-INS的定位方法在早期是十分高效,但它面临着严重的可靠性和精度问题.因为GNSS的工作原理是测量无线电信号的飞行时间,无人机和发射卫星之间的通讯障碍或者延迟可能影响的定位精度[15].甚至,在某些紧急特殊情况下,卫星信号可能会被人为屏蔽.另外,在室内、山区和森林等GNSS拒止的特殊环境[16-17],该类方法可能会失效.
(2)基于视觉的无人机定位
基于视觉或视觉辅助的定位是近年主流的无人机定位方法,可进一步划分为基于二维图像的定位、基于三维结构的定位、分层定位、基于图像序列的定位和基于深度学习的定位方法[18].基于二维图像的定位方法主要在二维图像检索数据库中寻找与查询图像最相似的图像进行无人机的相对位姿估计[19-20].基于三维结构的方法通过描述符匹配建立查询图像的二维特征和三维数据库中包含几何信息的特征点之间对应关系,然后使用这些匹配点的对应信息估计查询图像的位姿[21-22].分层定位方法以分层的方式进行相机位姿估计,这类方法首先使用图像检索技术进行相机位姿的粗标定,然后将标定结果作为基于三维结构的相机位姿估计方法的初值来将定位问题约束到一个更小的三维模型空间内,解决了原始基于三维结构的相机标定方法在复杂场景中描述符匹配模糊的问题[23-24].基于图像序列的定位方法利用有序的图片序列进行图像检索,相较于单张图像检索的方法显著地降低了误识别率,但这类方法常用于SLAM中的回环检测,很少被用于大环境差异场景下的位姿估计[25].基于深度学习的定位方法训练分类器来学习场景中稳定的外观特征以建立相机与场景之间的关系,然后使用卷积神经网络(convolutional neural network, CNN)对相机位姿进行回归计算[26].综上所述,当前的视觉定位方法普遍依赖于图像检索和特征提取与定位.然而,传统的特征描述子,如SIFT[27]、SURF[28]和BRIEF[29]虽然具有较好的旋转和尺度不变性,对轻微的视角变化鲁棒性良好,但大多数都无法适应光照变化剧烈的图像,尤其是跨季节表观差异大的图像.
(3)其他定位方法
除上述定位方法以外,针对不同的使用环境,无人机定位方法还包含磁性定位、超声波定位和激光雷达定位等,它们分别利用地球的磁场、超声波测距仪和激光雷达在难以获取GNSS信息与视觉信息的环境中提供精确的导航和定位服务.但上述方法相较于视觉定位而言更容易受到环境因素的影响,且灵活性和鲁棒性往往较差.
本无人机图像定位方法基于视觉定位方法中分层定位方法的管线,结合图像合成技术,与之前的方法相比,生成了新视角的跨季节图像,减少了视角差异,扩展了跨季节图像数据集,改善了图像特征提取与匹配的结果,进而提升表观差异条件下无人机图像定位的精度.
1.2 图像合成技术
图像合成是使用已有图像生成新图像的技术.可以通过合成连续的新视角图像克服有限跨季节图像的视角限制,来进行数据扩充与增强.常见的合成方法包含图像拼接和视角合成.
(1)图像拼接
图像拼接通过图像配准、图像变换和融合重构等步骤,从一系列已知视角的图像构建宽视角的图像[30].根据图像配准环节所用技术的不同,图像拼接分为基于像素和基于特征的方法.基于像素的方法通过直接最小化像素间的差异来配准图像[31-33],精度高但预处理和计算复杂.基于特征的方法采用稀疏特征描述符和按某种次序实现的特征匹配进行配准[34-35],相较于基于像素的方法计算量更小,但对视角的要求更为严格.虽然图像拼接算法在标准数据集上表现良好,但它们在实际应用中对低纹理、宽基线和大视察图像的拼接效果差,而且图像拼接由于无法有效利用图像隐含的深度信息,其生成的图像用于视觉标定时精度较差.
(2)视角合成
视角合成相对于图像拼接方法更好地结合了场景的深度信息,以利用一组已知视角的图像生成新视角的图像.早期视角合成的研究主要为基于模型和基于图像的渲染方法[36-38],通过计算机辅助设计软件建立对象的三维模型或对已知图像进行深度估计的方式来还原场景的一部分的三维信息再进行渲染来生成新视角的图像.近年来随着人工智能技术的发展,基于神经辐射场的方法利用神经网络的强大学习能力,将场景模型隐式表示为神经辐射场再结合体渲染技术,能够生成具有高质量和真实感的新视角图像[39].在视角合成方法中,由于图像中的物体存在着复杂的遮挡关系,深度的获取与利用仍是难题.因此利用原始场景模型的几何先验信息,使用透视纹理映射的方法将待合成图像投影到三维模型表面再进行合成,提高视角合成结果的准确性.
2 方 法
2.1 视觉定位方法框架设计
传统的视觉定位方法在图像检索数据库中检索与待定位图像相似的图像,然后再经过特征匹配和相机位姿计算的步骤计算六自由度的相机位姿.然而,当待定位图像和检索数据库中的图像存在着较大的光照、季节差异或图像检索数据库中仅存在少量离散的大视差图像,就会导致检索结果图像与待定位图像存在较大的表观差异,降低特征匹配步骤提取匹配点的数量和准确率,导致视觉定位方法精度大幅度下降.
本视觉定位方法使用图像合成技术,通过使用跨季节图像更新模型纹理并在稀疏图像视角附近建立连续的虚拟视角来解决待定位图像和检索结果图像存在的大场景表观差异问题.框架如图1所示,主要包含图像生成与位姿计算两个阶段.图像生成阶段主要利用原始的粗粒度场景模型和少量带有位姿信息的跨季节图像序列,通过视角合成和空洞填补技术,在跨季节图像序列附近生成连续的新视角合成图像.图像生成的目的是为接下来的位姿计算阶段提供更加丰富且视差相对较小的检索图像,以获得可靠性更高的匹配点对.该步骤可以有效地解决季节变化对相机标定的影响,提高视觉定位的精度和可靠性.该视觉定位方法的另一个阶段是相机位姿计算阶段,其目的是计算跨季节待标定图像的六自由度相机位姿.该阶段的方法包括以下步骤:使用图像检索技术在跨季节图像检索数据库中查询与待定位图像视角相近的图像;使用特征匹配技术获取一系列2D-3D匹配点对;在这些点对的基础上使用RANSAC-PnP[40]方法进行相机位姿计算.通过这些步骤,可以计算出待标定图像的相机位姿,从而完成高精度和高鲁棒性的跨季节图像视觉定位.
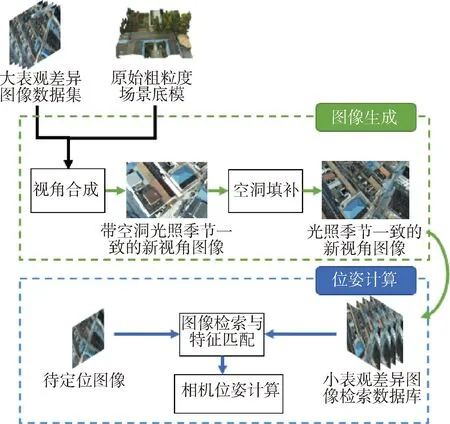
图1 支持场景表观差异的无人机视觉定位方法Fig.1 Visual localization method for UAV images supporting scene appearance changes.
上述过程的图像合成阶段在整个视觉定位流程中发挥了重要的作用.视角合成技术采用基于阴影映射的方法,很好地模拟了季节变化下光照条件的变化,从而提高生成图像的真实感和准确度.然而,阴影映射也会导致图像中出现一些空洞,影响后续位姿计算阶段的准确度.为了解决这个问题,需要搭建并训练空洞填补网络,该网络根据全局图像信息预测空洞区域的像素值,进行空洞填补,保证了生成图像的完整性,如图1所示.
2.2 基于阴影映射的图像合成
(1)
其中,wi表示第i张输入图像Ii对新视角贡献的权重,M∈R4×4表示目标相机位姿矩阵,相机位姿矩阵和场景中某一空间点x的关系为
(2)
式中,R∈R3×3为相机的旋转矩阵,t∈R3为相机相对于世界坐标原点的平移向量,x与x′分别为世界坐标系和相机坐标系下的空间点坐标.
由针孔相机模型的原理,为了将着色点投影到像素坐标系中,需要进行如下变换:
(3)
式中,K为相机内参矩阵,fx、fy为相机焦距,cx、cy为相机光心相对于像素坐标系原点在x轴与y轴方向上的偏移量,[uv]T为成像平面投影点的投影坐标.
支持场景表观差异的无人机图像视觉定位方法结合基于模型和基于图像渲染的思想,算法示意图如图2所示,分为两个阶段:第一阶段使用阴影映射算法将多张待合成图像向粗粒度原始场景模型进行投影,融合多个输入视角的信息;第二阶段根据投影后的纹理信息,利用渲染技术生成新视角的图像.
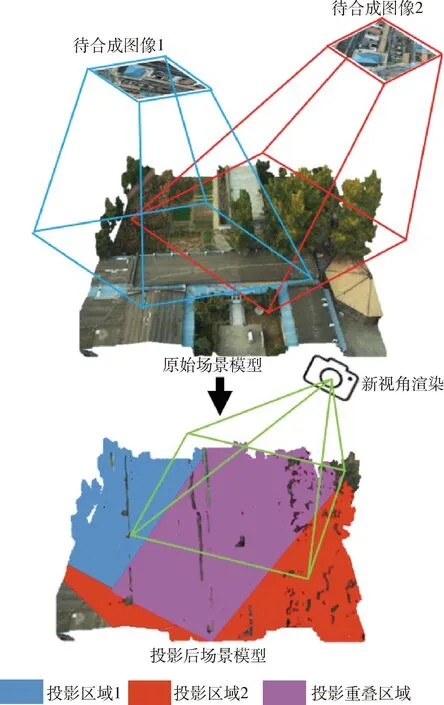
图2 基于阴影映射的视角合成Fig.2 Shadow mapping-based view synthesis.
在上述过程中,阴影映射技术能高效地在高复杂度场景进行纹理映射并具有较快的运算速度,为原始场景模型赋予场景高精度的跨季节纹理信息.阴影映射分为深度图的生成和投影纹理映射两个步骤,其中深度图生成的目的是获取场景中物体在当前视角下正确的遮挡关系,是否正确使用深度信息进行阴影映射的结果如图3所示,通过两幅图像的对比得出,采用阴影映射算法的3(b)有效地解决了未使用阴影映射算法的3(a)中出现的伪影问题.

图3 是否使用阴影映射的投影结果对比Fig.3 Comparison of Shadow Mapping Projection Results
为了避免深度测试时由于深度精度问题出现的Z-Fighting现象,需对深度值进行微小的偏移,因此使用如下的深度偏差公式:
b=max(α(1.0-n·l),β)
(4)
式中,n为着色点法向量、l为投影仪到着色点的方向向量,b为计算获取的深度偏差值,α和β为用于计算深度偏差的常量,它们的取值分别为0.05与0.005.
为了从新视角对原始场景模型进行投影,需要对图2的投影重叠区域进行视角合成,在投影重叠区域的合成方法如下:
(5)
式中,(x,y)为投影重叠区域的像素在屏幕空间的坐标,W和H分别为图像的宽和高,Co(x,y)表示合成后的像素值,n表示待合成图像的数量,fi(x,y)为表示第i张图像投影后是否有像素落在当前位置的指示函数,Ci(x,y)表示第i张图像经过投影后在(x,y)坐标位置的颜色值.
使用上述视角合成方法从新视角合成的跨季节图像如图4所示.
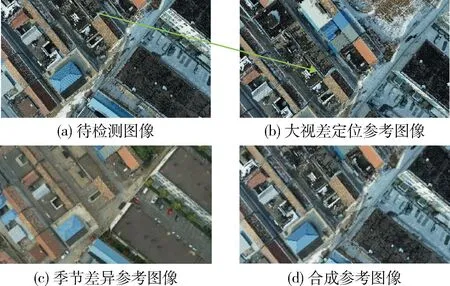
图4 使用合成图像提升大视差和表观差异图像的定位精度Fig.4 Improving localization accuracy for images with large parallax and apparent changes using synthetic images
从图4中可以看出,使用该合成方法可以合成与目标视角更为相近的图像,也可以赋予跨季节图像与当前待检索图像更为近似的表观特征.该步骤既解决了图像检索数据库中的图像与待检测图像视差大的问题,又解决了由季节变化带来的场景表观差异大的问题,为后续视觉定位的特征匹配等步骤提取更鲁棒的匹配点对提供了保证.
2.3 空洞填补
由于图像采集的场景往往存在着复杂的遮挡关系,使用待合成图像向场景模型投影后再从新的视角进行渲染往往会由于缺失像素值而产生空洞.为了获得更完整和准确的图像合成结果,需要对新视角的空洞区域进行填补,空洞填补问题的形式化表达形式如下:
(6)
式中,I′是输出图像,I是输入图像,L(I′,I)是衡量输出和输入图像之间的差异的损失函数, R(I′,M)是衡量I′和掩码M之间的差异的正则化项.空洞填补的损失函数L(I′,I)使用最小均方误差衡量指标,该指标的定义如下:
L(I′,I)=M⊙(C(I,M)-I)2
(7)
式中,⊙代表逐像素乘法,C(I,M)为函数形式的填补神经网络.
空洞填补流程如图5所示,主要分为训练图像生成、待填补图像处理和网络的训练与预测等步骤. 在训练图像数据集的生成方面,采用基于渲染的方法生成训练图像数据集,该方法首先通过生成随机平移向量和旋转矩阵再进行组合的方式生成虚拟相机位姿,然后从这些虚拟相机位姿对原始场景模型进行渲染,获得3通道的无洞图像.最后,该图像与使用随机生成方法生成的遮罩分别作为空洞填补网络的输入和输出来对整个空洞填补网络进行训练.上述过程中,提前计算了场景包围盒来限制平移向量和旋转矩阵的范围,在渲染过程中及时丢弃具有0透明度像素的图像来对随机生成的位姿矩阵进行约束.
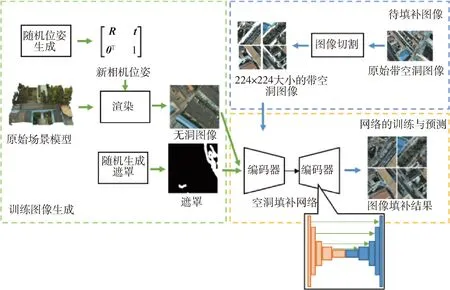
图5 空洞填补网络模型的搭建与使用Fig.5 Building and using a model for image inpainting.
在神经网络的设计与训练方面,该网络使用基于Segnet[41]骨干网络的编码-解码卷积神经网络,该网络以一张大小为4×224×224的彩色图像作为输入,通过具有5个卷积层的编码器网络进行5次下采样操作,将输入图像转化为512×7×7大小的高层级特征向量;该网络的解码器为5个与编码器对应层级残差连接的反卷积层,它将解码器生成的高层级特征信息进行还原,得到填补后的图像.由于输入图像的尺寸通常大于Segnet的输入图像大小,因而需要对其进行分块和剪裁,然后把剪裁子图作为输入.所有神经网络的层与层之间都采用了ReLU激活函数以提高网络的非线性表达能力和加速梯度下降的收敛速度.在损失函数的选择上,使用均方误差衡量空洞部分像素预测值与真实值之间的差异;在优化器的选择上,选择了适合大规模数据和参数的Adam自适应优化算法作为优化器,初始学习率设置为lr=0.001,梯度一阶矩估计和二阶矩估计的指数衰减率分别设置为β1=0.9,β2=0.999,使用分批次训练的方法,每个批次包含300个样本,训练40轮.
2.4 视觉定位
使用经过图像合成和空洞填补扩充后的跨季节图像数据库对待定位图像进行视觉定位,视觉定位流程如图6所示. 在图6中,首先通过图像检索在图像检索数据库中获取与待定位图像相似度高的检索图像,然后使用Superglue[42]特征匹配算法获取待定位图像和检索结果图像之间的二维匹配点对,在此基础上,结合模型先验的深度信息获得多对二维与三维匹配点对,最后使用RANSAC-PnP[40]算法进行坏点剔除与相机位姿的计算.
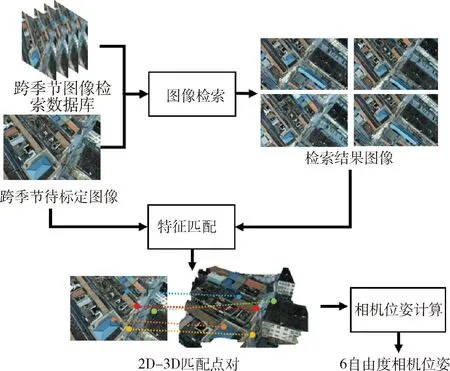
图6 基于图像特征匹配的相机标定过程示意图Fig.6 Diagram of the feature mapping-based camera calibration
3 实验结果与分析
3.1 实验环境设置
硬件环境方面,使用一台配备了具有8 GB显存的NVIDIA GeForce GTX 2070 Super显卡、Intel(R) Core(TM) i7-10700 CPU以及16GB内存的台式电脑.实验使用的数据集由型号为大疆精灵4 RTK的无人机采集,图像尺寸为5 472×3 648. 数据拍摄于北京市昌平区,共有秋季图像3 607张,冬季图像1 325张. 部分图片会被用于建模,图片的定位真值使用手动控制点加传统匹配点结合的标定过程.定位误差小于0.5 m,视角误差小于0.5°.
在原始模型准备方面,使用Context Capture软件对部分无人机拍摄的航拍图像进行三维模型重建.此过程的输入不仅有航拍图像数据,还包括图像的位置信息、控制点信息与相机参数文件等.在三维建模的过程中,Context Capture软件自动执行图像配准、空中三角化、模型简化和纹理映射等过程,得到的三维重建结果如图7所示.

图7 场景模型重建结果Fig.7 Results of model reconstruction
图7分别展示了对航拍图像进行三维重建过程中的空中三角测量结果和分片场景模型重建结果.左图中黄色的点代表标定后相机的位置,彩色图块代表场景中的稠密点云的分布;右图为部分重建完成后的分片场景三维模型.
3.2 图像合成实验
近年来的视角合成方法虽然可以合成具有较高图像相似度指标的图像,但由于它们往往基于生成对抗网络(generative adversarial network, GAN)或Transformer的网络结构,需要大量的计算资源和存储空间来训练,具有较高人工标注成本,且这类方法由于基于街景或室内公开数据集,很难迁移到大表观差异的场景. 因此,使用泛化性较好的APAP[31]方法、GDB-ICP[32]方法和基于阴影映射的视角合成方法进行对比,对去畸变后分辨率大小为960 pixel×540 pixel像素的村庄雪景图像数据进行图像合成.为了量化不同方法图像合成的结果,计算合成图像与真值图像的相似度指标,包含图像的结构相似度、峰值信噪比、匹配点数量和置信度,如表1所示.其中,结构相似度综合考虑图像的亮度、对比度和结构3个方面的指标,能公正地衡量两幅图像的结构差异程度. 峰值信噪比可以用于度量图像信号的保真性和失真程度,公式如下:
(8)
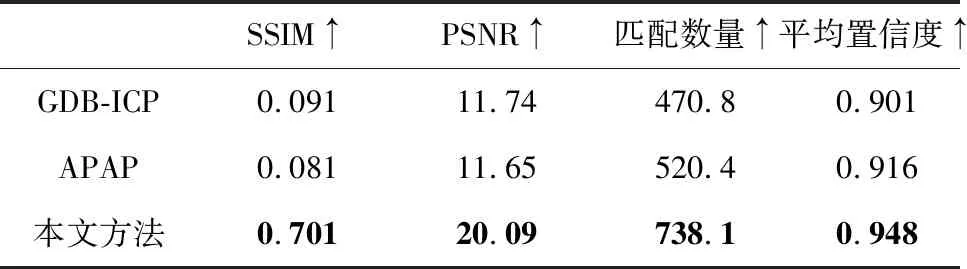
表1 图像合成质量实验结果Tab.1 Results of image composition quality.
(9)

在衡量匹配点的提取效果时,使用目前最主流的Superglue[42]深度神经网络匹配算法,并计算匹配点对的置信度.置信度是通过计算匹配描述符的相似度得到的,具体计算公式如下:
(10)
如表1所示,本图像合成方法相比于传统的GDB-ICP[32]与APAP[31]方法在SSIM、PSNR等图像相似度指标上获得了更好的结果,表明本合成方法的合成质量要好于传统的基于拼接的方法.在特征匹配实验中,本方法的合成图像能获取更多置信度高于0.5的匹配点,且匹配点的平均置信度优于传统的方法.
图像合成过程中由于选取的虚拟视角与原始图像的视角存在差异,且重建得到的场景存在深度差,因此会产生空洞.本网络填补空洞效果如图8所示.

图8 本文空洞填补实验结果图Fig.8 Results of our image inpainting.
在图8中,(a)(b)为包含空洞的图像,空洞区域被红色高亮,(c)(d)为填补网络的填补结果.其中,最左侧的图像为接近地面的合成图像,其空洞的主要成因是由于建筑物底部被严重遮挡,在图像合成时不可见而缺失纹理信息.而右侧的两列图像屋顶的部分由于建模软件的深度估计精度不足产生的微小误差,导致屋顶部分网格凹凸不平,在视角变化的时候产生了自遮挡空洞.对于最左侧图像的大面积空洞,提出的填补网络能充分利用全局图像信息,结合空洞附近场景物体的语义关系进行大面积的填补. 而对于小面积的空洞,该填补网络则更重视空洞附近的局部纹理信息,产生更连续的空洞填补结果.
为了对比不同图像合成算法的效果,在图9中对不同的图像合成方法进行了可视化对比.选取了两张小视差的图像,分别使用传统基于二维图像拼接的方法和本方法进行合成.本方法相较于传统方法的优势在于充分利用了原始模型的深度先验信息,因此在处理有明显遮挡关系和大视差的图像合成时,本方法会比图像拼接方法更具有优势.在对比结果中,本方法相较于其他方法不但在非重叠区域满足透视关系,且在图像重叠区域也没有出现明显的重影、扭曲等问题.在可视化结果上更符合人眼的直觉,也更能满足后续视觉定位步骤的需要.

图9 不同图像合成方法的可视化结果对比Fig.9 visualized comparison of different image synthesis methods
3.3 视觉定位实验
为了验证图像合成对视觉定位的影响,我们对不同的图像合成方法进行了实验对比.实验的量化统计如表2所示,可视化结果如表3所示,所使用的视觉标定过程如图6所示.表3右侧引入Superglue[42]算法用于特征匹配.待检图和参考图的特征点连线越接近绿色,表示匹配置信度越高,作为位姿计算的输入就越可靠.特征点的连线越接近红色,说明匹配置信度更低,使用这种点对进行相机位姿计算的错误率更高. 作为对照,引入基线算法,使用无修改的原始图像进行特征匹配定位. 而基于GDB-ICP[32]和APAP[31]的算法则使用合成图像进行特征匹配定位.
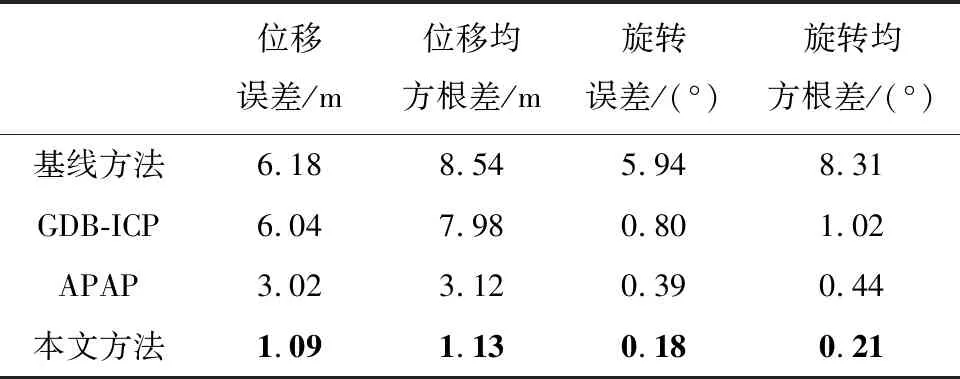
表2 视觉定位量化实验结果Tab.2 Quantitative visual localization results

表3 视觉定位可视化实验结果Tab.3 Visualized localization visualization results
实验发现,冬季和秋季的图像表观差异巨大.可用于匹配的原始参考图像数量较少且包含不同的视差,不足以覆盖整个场景. 从表3中可以看出,本方法相比其他算法获取的匹配点更为密集,平均置信度更高.传统算法在窄基线、小视差图像上可以获得200对以上的特征匹配,而在宽基线、大视差图像上无法获取足够的匹配.本算法的特征匹配结果在不同情况下始终能获得超过400对以上高置信度匹配.从表2的量化结果可以看出,本方法的视觉定位在位移和视角旋转指标上均为最优.
实验分析得出,传统算法合成的图像存在瑕疵,缺少三维先验,破坏了透视规则,使得几何线索与真实场景不符.在特征匹配的过滤过程中,不服从透视的低置信度匹配会被大量剔除.而合成的图像隐含了原始场景的模型三维信息,投影过程中不破坏透视,匹配点对的精确位置、数量和置信度都不受影响. 实验表明,本算法能够解决具有场景表观差异和大视差的无人机图像定位问题.
在执行效率方面,由于使用了参数量较小的Segnet骨干网络,该方法仅需使用0.064 s就可以完成图像合成,与传统的GDB-ICP和APAP方法相比运行开销没有显著增加,且执行时间不会随着视差基线的变化而增大,具有良好的稳定性.
4 结 论
本文提出了一种支持大场景表观差异的无人机图像视觉定位方法,该方法在具有较大天气和光照变化的图像数据上相比传统流程的定位方法取得了更高的定位精度.该方法框架使用基于阴影映射的图像合成方法对不同视角的图像进行合成,然后使用基于Segnet的空洞填补网络对该过程产生的空洞进行了填补,相比于传统基于二维图像的GDB-ICP和APAP方法,本文方法在图像合成质量和特征点的提取效果上均取得了较好的结果,且在大视差图像的合成上具有更高的泛化性.实验结果表明,本文方法相比传统视觉合成与定位方法视觉效果更好,定位精度更高.
