跨域人脸活体检测的单边对抗网络算法
2024-03-12曾凡智吴楚涛
曾凡智,吴楚涛,周 燕
佛山科学技术学院计算机系,广东 佛山 528000
随着人工智能的迅速发展,人脸识别[1]技术在日常生活中获得广泛应用,如智能手机解锁、门禁解锁、电子钱包支付等。但人脸识别系统中人脸活体检测的安全性仍存在巨大安全隐患。人脸活体检测[2]的起因是成像传感器在面对纸张打印、视频重放、3D模具等物理呈现的假人脸时无法识别成像的真实性,从而假人脸通过人脸识别系统,受到非法入侵,导致人脸识别系统在金融、支付及商业等应用场景存在局限性,这使得人脸活体检测引起了广泛的社会关注。
由于人脸活体检测的类型复杂多样、易受光线和成像清晰度等原因,它是人脸识别应用中一个具有挑战性的问题。目前人脸活体检测算法主要分为传统手工制作特征方法和基于深度学习的方法。传统手工制作特征方法通过眨眼、点头、微笑、注视跟踪和生理信号从RGB、HSV、YCbCr等各种颜色空间中有效提取欺骗类型的动态判别。Määttä 等[3]利用多尺度局部二值模式(LBP)分析人脸图像的纹理。Boulkenafet等[4]基于Fisher向量编码的人脸特征描述从不同颜色空间中提取了加速鲁棒特征(Speeded Up Robust Features,SURF)。Pate 等[5]基于人脸图像反射、颜色失真和形状变形的解决人脸欺骗问题。
近年来,随着深度学习在计算机视觉中的飞速发展。越来越多通过卷积神经网络(convlution nertron network,CNN)方法提取更多可鉴别特征。Yang 等[6]第一个使用CNN 和二进制监督进行人脸活体检测。Atoum等[7]提出了一种结合纹理特征提取深度特征的双流CNN 架构来检测攻击。Liu 等[8]基于CNN-RNN 模型,利用人脸深度作像素级及rPPG 信号序列级监督估计,将估计的深度和rPPG融合,以区分真实的和虚假的人脸。Yu等[9]提出基于中心差分卷积方法,通过聚集强度和梯度信息来捕获内在的人脸信息。Li 等[10]提出了一种基于补丁的紧凑图网络(PCGN)来分散来自所有补丁的细微活性线索。Yu 等[11]利用跨特征交互模块将中心和周围稀疏局部特征分别在水平垂直和对角方向上的差异挖掘局部特征。沈超等[12]利用真伪人脸纹理差异特征的筛选并增强网络的输入。王宏飞等[13]利用光流与纹理特征融合得到人脸动-静态特征。
尽管这类方法在类内测试有较好的性能,但对数据集存在拟合,在跨数据集测试时性能显著下降。解决这类问题的直接方法是采用域泛化技术[14]。域泛化技术在不访问任何目标数据的情况下显式挖掘多个源域之间的关系,可以更好地概化到不可见的域。Shao等[15]提出多对抗判别深度域泛化框架来学习真人脸与假人脸的广义特征空间。Jia 等[16]提出端到端单边域泛化框架来提高人脸反欺骗的泛化能力,Wang 等[17]提出词汇分离和词汇自适应方法来划分跨域人脸活体检测的局部聚合向量(vector of locally aggregated descriptors vocabulary separation and adaptation,VLAD-VSA)聚合所以真人脸相关信息,区分不同源于假人脸相关信息。Liu 等[18]设计了一种自适应归一化表示学习(adaptive normalized representation learning,ANRL)框架,根据输入自适应特征归一化模块去区分不同源域欺骗人脸。蔡体健等[19]通过添加人脸深度图抓取活体与假体的区别特征。Wang 等[20]提出了混乱重组式网络(shuffled style assembly network,SSAN)框架来提取和重组不同的内容和风格特征,形成一个广义的人脸特征空间。
综上所述,现有域泛化方法大多侧重于最小化多个源域间的分布差异以提取域不变特征,或利用域泛化框架对特征进行对齐,以寻求一个紧凑和一般化的特征空间。针对以上问题,本文提出一种跨域人脸活体检测的单边对抗网络算法,主要贡献如下:
(1)提出GⅠR-AFMN 模块,将改进倒置残差块与分组卷积结合,同时引入自适应特征归一化模块作为特征提取模块,在ResNet50基础上改进骨干网络,该网络有效避免单一数据集的过拟合,提高了来自不同源域的人脸活体检测能力。
(2)改进NetVLAD,将通道注意力机制模块引入其中,利用通道注意力机制模块实现不同源域人脸活体局部区域特征信息特征权重的再分配,提高不同源域人脸活体特征信息利用率,有效提高对不同源域的人脸活体特征信息的表达能力。
(3)在人脸活体检测数据集(OULU-NLP[21]、CASⅠA-MFSD[22]、Ⅰdiap Replay-Attack[23]、MSU-MFSD[24])上实验证明本文方法的有效性。
1 相关理论
领域泛化:领域泛化[14]的目标是从一个或几个不同但相关的源域学习一个模型,这将在不可见的测试领域中很好地泛化。例如,给定一个草图、卡通图像和图画,领域泛化要求训练一个良好的机器学习模型,该模型对来自其他图像或照片的图像进行分类时,预测误差最小,这些图像与训练集中的图像有明显的区别分布。
假设给定M个训练源域Strain={Si|i=1,2,…,M}其中Si是第i个源域,且每对源域之间的联合分布是不同的。域泛化的目标是从训练源域中学习一个鲁棒的、泛化的预测函数h,在不可见的测试域Stest上实现最小的预测误差见式(1):
其中,E是期望,l是损失函数。
2 整体算法结构
本文设计了基于生成对抗网络框架进行域泛化人脸活体检测算法,整体算法结构由生成器网络、判别器网络和局部特征聚合网络三部分,整体网络结构如图1所示,首先将所有源域真实人脸与虚假人脸分离,然后将其输入到相应特征生成器中,该生成器将输入的人脸映射到一个特征空间,域鉴别器以确定输入特征来自真实或虚假域。相反,训练特征生成器欺骗域鉴别器,使域标签无法被识别。为此,在特征生成器和域鉴别器之间设计了一个单边对抗性学习过程,以获取真实人脸的特征。

图1 跨域人脸活体检测的单边对抗网络算法结构Fig.1 Algorithm structure of unilateral adversarial network for cross-domain face detection
2.1 生成器
受到ANRL[18]和MobileNetV2[25]设计的思想启发,本文提出GⅠR-AFMN模块,设计生成器网络部分,将分组卷积引入具有线性瓶颈的倒置残差块,同时利用ANRL[18]中自适应特征归一化处理以提高网络性能,生成器如图1中Generator所示,将分组卷积与倒置残差块融合并结合自适应特征归一化模块,降低生成器网络参数量和计算量的同时提升网络性能。
2.1.1 倒置残差块
倒残差模块是MobileNetsv2[25]中对MobileNets[26]改进所提出的一种有效方法,其组成如图2 所示,输入特征图通过主路与分支结构进行融合特征提取,其中,第一层的1×1卷积核对输入的特征图进行升维,对不同通道上的信息进行线性组合,然后通过第二层3×3卷积进行操作,得到各通道的特征信息,接着第三层1×1 卷积核进行降维,整合和交互各通道的信息,最后将分支与主路运算,得到更多有用的编码信息。
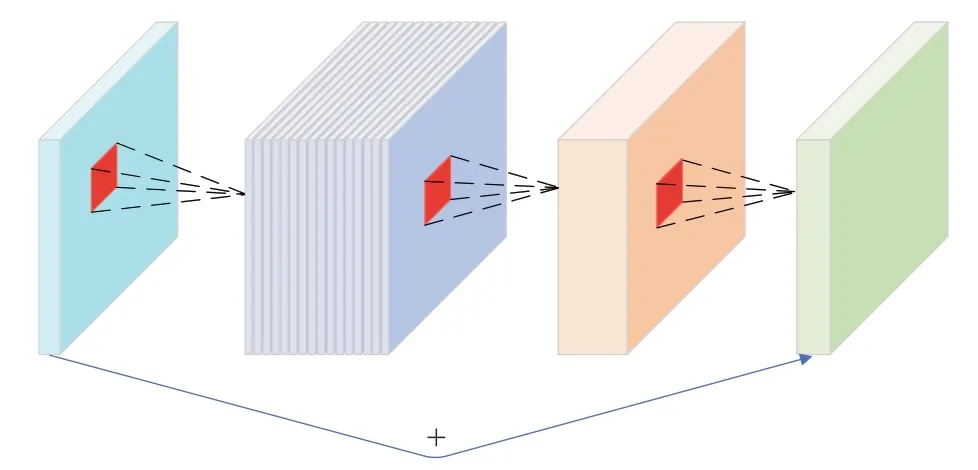
图2 倒残差模块Fig.2 Ⅰnverted residual block
2.1.2 分组卷积
分组卷积(group convolution)是Yani 等[27]在2016年提出的稀疏卷积结构,如图3所示,相比与标准卷积,分组卷积主要是将特征图在通道维度上进行分组,对每组特征图进行卷积运算。假设输入特征矩阵尺寸为H1×W1×C1,使用C2 个尺寸为h×w×C1 标准卷积核进行计算时,得到的输出特征矩阵尺寸H2×W2×C2,其参数量为h×w×C1×C2。而分组卷积将输入特征矩阵在通道维度上分成g组,则每C1/g个通道的特征矩阵分为一组。此时卷积核采用h×w×C1/g的尺寸进行计算,可得到g组尺寸为H2×W2×C2/g的输出特征矩阵,完成拼接后最终的输出尺寸仍然是H2×W2×C2,其参数量为h×w×C1×C2×1/g。

图3 标准卷积与分组卷积Fig.3 2D-convolution and group convolution
从上述可知,分组卷积的参数量是标准卷积的1/g,本文g=32。
2.1.3 自适应特征归一化
自适应特征归一化模块是腾讯优图2021年提出的ANRL[18]算法中的一种方法,其组成如图4 所示。自适应归一化由批量归一化(batch normalization,BN)和实例归一化组成(instance normalization,ⅠN),利用自适应平衡因子为每个样本提取特征。其中,将X特征图利用BN层及ⅠN层获得两种归一化表示XBN,XIN,同时对X特征图通过一个3×3 卷积层和全局平均池化层生成基于通道的统计信息即为X特征图的全局信息。将此全局信息通过全连接层来指导XBN和XIN自适应选择。
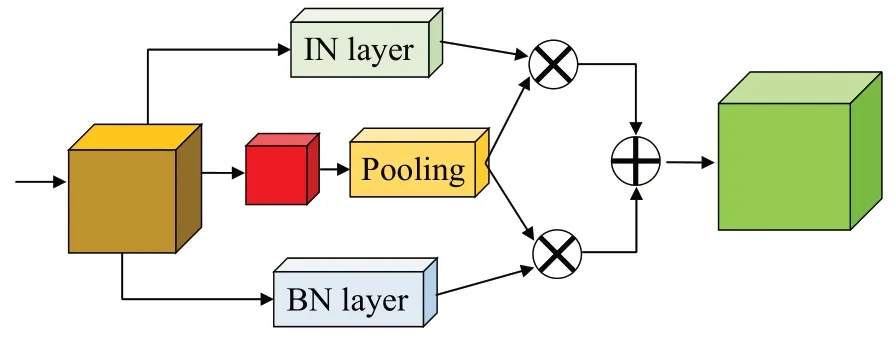
图4 自适应特征归一化模块Fig.4 Adaptive feature normalization module
2.1.4 GIR-AFMN

图5 GⅠR-AFNMFig.5 GⅠR-AFNM
2.2 特征聚合网络
2.2.1 通道注意力
通道注意力机制(channel attention mechanism)是2017 届ⅠmageNet 分类比赛的冠军网络SENet[29]中所提出的重要方法,经过CBAM[30]改良以后有效提高了通道注意力机制的广泛适用性。其组成如图6所示。
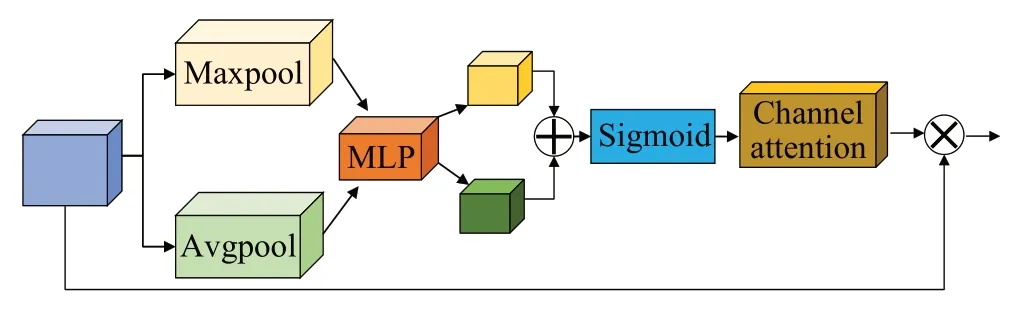
图6 通道注意力Fig.6 Channel attention
主要是在卷积提取特征过程中添加一个注意力分支,首先输入特征图分别进行平均池化和最大池化操作,将每个通道上的特征图压缩成一个像素的特征权重,然后将池化后的输出经过多层感知器,最后通过线性激活Sigmoid与输入特征图相乘获取每个通道上局部特征的重要程度。实现不平等的对待总体的输入,使网络更加关注特征图上局部重要的信息。
2.2.2 NetVLAD
在特征对齐问题上,在受到VLAD-VSA[17]的思想启发,其提出了带有词汇分离和自适应的局部聚合向量网络,其中在NetVLAD[31]结构如图7 所示,给定局部特征F和带有K个视觉簇类的词汇V来划分特征空间,局部特征通过一个1×1的卷积层实现分配,然后通过softmax函数对数值进行缩放。计算局部特征与其分配的聚类中心之间的残差,然后用分配分数对它们进行加权,并聚合到NetVLAD[31],然后将NetVLAD[31]表示进行内部归一化和L2 正则化,成为一个全局向量进行识别和域对齐。然后将这个全局向量分为共享视觉词汇和特定词汇,将共享表示的分布与对抗性损失对齐。同时将共享和特定的词汇约束为正交的,使它们捕获不同的和不重要的信息。

图7 NetVLADFig.7 NetVLAD
2.2.3 改进NetVLAD
1×1卷积核可以整合交互各通道的信息,为聚类中心残差提供权重分配,但是聚类残差是将同类的距离拉近,异类的距离疏远,而1×1 卷积核对单一特征图的不能很好的对跨域任务所关注的同类与异类的距离进行修正;针对该问题,本文提出改进NetVLAD[31],其组成如图8 所示。将输入特征图经过通道注意力机制获得具有关注局部关键信息的特征图再利用聚类中心残差进行对进行NetVLAD[31]聚合,同时另一分支将输入特征图进行NetVLAD[31]聚合,最后将两个聚合向量相加得到最后的聚合向量。使网络更加关注有用的信息,使得图像不同位置的感受视野有不同的重要性,进一步增强簇类之间的差异性,改进NetVLAD[31]的计算公式如式(2)所示:

图8 改进NetVLADFig.8 Ⅰmproved NetVLAD
其中,fi代表样本特征图、Fi代表注意力机制提取后的特征图,ck代表fi的簇类,ck′代表Fi′的簇类,本文k=32,α是一个常数,本文α=3。
GTD是Getting Things Done的缩写,戴维·艾伦(David Allen)通过Getting Things Done这本书介绍了一种时间管理方式,得到了世人的关注和使用。GTD时间管理方式的核心理念概括就是记录下来要做的事,然后整理安排,去努力执行,每日或每周回顾一次,重新做出调整计划。GTD方法的主要任务是在有限时间内,使用人用有限的精力有效地完成该做的任务,做出最大的单位时间产出。有效的GTD方法,能使繁重、无序的混乱生活变成高效、有序的工作生活方式。
2.3 鉴别器
鉴别器网络设计采用2017 年CVPR 最佳论文DenseNet[32]作为骨干网络,如图9所示,通过稠密拼接机制实现特征重用,从而改善网络梯度传递问题,使网络训练时更加容易收敛,达到参数量较少且计算高效的效果。相比于ResNet[33]具有更好的性能优势。
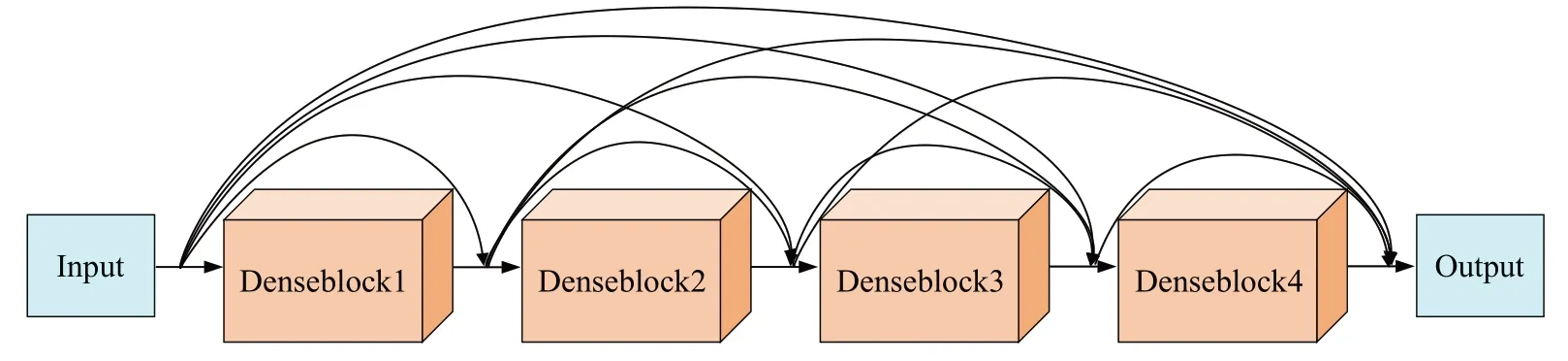
图9 鉴别器网络Fig.9 Network of discriminators
根据本任务不同源域人脸特征空间特点,为了避免参数量过多,导致过拟合数据集,本文鉴别器设计主要为4层DenseBlock,均采用3×3卷积核,针对不同Dense-Block 层之间特征图尺寸大小不同不能直接拼接问题,采用2×2 池化下采样方法,最后配合全局平局池化层,完成鉴别器的深度调整提取。
3 损失函数
本文将分类损失、对抗损失、非对称三元组损失的总和作为训练整个单边对抗损失网络的总体损失,具体表达式如式(3)所示:
其中,L为总体损失,Lcls为分类损失,Ladv为对抗损失,Ltriplet为三元组损失,λ1和λ2为权重系数取0.1,本文采用端到端的训练策略。
3.1 分类损失
由于所有源域数据都包含标签,因此在特征生成器之后实现了一个人脸反欺骗二值分类器,人脸反欺骗二值分类器采用标准交叉熵损失对真实人脸和欺骗型人脸进行优化。
其中,G代表特征生成器。
3.2 单边对抗损失
由于所有真实人脸都是通过真人成像来收集的,所以,真实人脸的分布差异相比于欺骗型人脸要小得多;因此,本文采用单边对抗学习策略,在特征生成器和域鉴别器之间进行单边对抗学习得到一个广义的特征空间,只对提取的真实人脸特征进行学习,相反欺骗型人脸不进行对抗学习,在学习过程中,特征生成器的参数是通过最大化域鉴别器的损失来优化的,而域鉴别器的参数是通过相反的目标来优化的,由于有多个源域用于分类,采用标准的交叉熵损失来优化单边对抗学习下的网络,如式(5):
其中,YD代表一系列的源域标签,N代表不同源域的数量,G和D代表的分别是特征生成器和域判别器,为了同时优化G和D,使用梯度反转层(gradient reversa layer,GRL)在反向传播过程中乘以一个负标量来反转梯度。可以跨域区分真假人脸,具有较强的泛化和鉴别能力。
3.3 非对称三元组损失
由于欺骗型人脸复杂多样和人脸数据库的收集方式各有不同,导致欺骗型人脸的分布差异比真实人脸大得多;因此,本文采用非对称三元组损失对不对称三元组真实人脸和欺骗人脸进行挖掘,目的是分离不同源域的欺骗型人脸,使其在特征空间分布更加分散;反之,聚集所有真实人脸,使其在特征空间分布更加紧凑;同时,把欺骗型人脸和真实人脸分开;促进不可见目标域的类边界优化,具体表达式如式(6):
4 实验结果与分析
4.1 数据集及评估协议
本文使用OULU-NLP(O)[21]、CASⅠA-MFSD(C)[22]、Ⅰdiap Replay-Attack(Ⅰ)[23],MSU-MFSD(M)[24]四个国际公开的人脸活体检测数据集对本文算法进行实验验证。本文对四个数据集不同捕获设备、攻击类型和数量进行分类。如表1[17]所示,因此,这些数据集之间存在域间数据偏移。本文所有实验对比均采用总半错误率(half total error rate,HTER)和曲线下面积(area under curve,AUC)作为评估指标。

表1 数据集分类Table 1 Dataset classification
4.2 参数设置
本实验均在Ubuntu 20.04 操作系统上进行,使用Anaconda 下基于Python 语言的PyCharm 解释器,深度学习框架为Pytorch,计算机CPU为AMD Ryzen 55600X,GPU 使用NVⅠDⅠA RTX 2080。本文网络总共训练400个周期,初始学习率为0.001,采用带有动量的SGD算法优化器。损失函数采用分类损失、单边对抗损失和非对称三元组损失作为总损失函数,其中,分类损失用于优化模型对真假人脸的二分类,单边对抗损失用于优化生成器与判别器的对抗损失,非对称三元组损失用于优化不同源域的人脸对齐损失,图10为本文算法在本文所有用的数据集上进行训练的损失函数曲线和曲线下面积的准确率曲线变化图。从图中可以看出,两条曲线随着训练epoch的增加逐渐收敛,当epoch达到200个周期时,损失函数的下降逐渐收敛,准确率也的提升也逐渐收敛。

图10 训练损失曲线与准确率曲线Fig.10 Training loss curve and accuracy curve
4.3 测试结果
4.3.1 对比实验1
本小节实验随机选择3个数据集作为训练的源域,其余一个数据集作为目标域进行评估。因此,总共有4 个评估任务:O&C&Ⅰto M、O&M&Ⅰto C、O&C&Mto Ⅰ和Ⅰ&C&M to O,如图11和表2所示基于四项评估指标,本文算法与几种具有代表性的传统人脸防欺骗方法跨域PAD 性能进行比较,如MS-LBP[3]、Binary CNN[6]、ⅠDA[34]、Color Texture[35]、LBPTOP[36]和Auxiliary(Depth)[8],还展示了最新的跨域人脸反欺骗技术如MADDG[15]、SSDG[16]、ANRL[18]和VLAD-VSA[17]的性能。由图11和表2可知,本文所提算法在四个数据集上的性能指标均表现出较为优异的结果,本文所提算法在O&C&M to Ⅰ实验下的HTER和AUC评估指标上分别达到了8.57%和96.91%,在Ⅰ&C&M to O实验下的两个指标上HTER和AUC评估指标上分别达到了12.58%和93.42%。在HTER与AUC评估指标下与现有跨域人脸活体检测算法相比,在O&C&M to Ⅰ实验中,较SSDG方法分别提升了3.14个百分点和0.32个百分点;较ANRL方法分别提升了7.46 个百分点和5.87 个百分点;较VLAD-VSA(R)方法分别略低了0.78 个百分点和0.88个百分点。在O&C&Ⅰto M实验中,较SSDG方法分别提升了3.74个百分点和2.07个百分点;较ANRL方法分别提升了7.19 个百分点和2.49 个百分点;较VLADVSA(R)方法分别提升了0.65 个百分点和0.99 个百分点。在Ⅰ&C&M to O实验中,较SSDG方法分别提升了2.76个百分点和1.88个百分点;较ANRL方法分别提升了2.82个百分点和1.52个百分点;较VLAD-VSA(R)方法分别略低了0.21 个百分点和0.58 个百分点。在O&M&Ⅰto C实验中,较SSDG方法分别提升了1.76个百分点和0.45个百分点;较ANRL方法分别提升了9.17个百分点和7.13个百分点;较VLAD-VSA(R)方法分别提升了0.21个百分点和2.1个百分点。这是因为本文所提算法使用的GⅠR-AFNM 模块利用分组卷积和倒置残差块对特征图每组通道信息进行细粒度特征的提取,同时,利用自适应特征归一化对不同源域特征信息进行实例归一化和批量归一化,从而获取当前源域有益信息且避免过拟合单一源域,同时,改进NetVLAD 网络,通过通道注意力机制的特点对局部特征进一步关注图片关键区域,提取更加细致的人脸特征,从而使网络作了更加精心的筛选。而VLAD-VSA(R)方法采用特征词汇共享与分离的方法更适合对视频重发攻击类型作聚类。结果表明,本文算法在源域有限、训练数据有限的挑战情况下,所提出的GⅠR-AFMN 及改进的NetVLAD方法能有效地获得人脸的特征空间。

表2 跨域人脸活体检测四项测试任务的方法比较Table 2 Comparison of methods for four test tasks of cross-domain face liveness detection 单位:%

图11 跨域人脸活体检测四项测试任务的ROC曲线Fig.11 ROC curves of four test tasks for cross-domain face liveness detection
4.3.2 对比实验2
本小节实验在极其有限的源域评估本文算法,只在两个有限源域作为训练测试跨域人脸活体检测的鲁棒性,选择MSU-MFSD和Ⅰdiap Replay-attack数据集作为训练的源域,选择CASⅠA-FASD 或OULU-NPU 其中一个作为测试的目标域。
由表3可知,本文所提算法在这种更具挑战性的情况下性能仍有不错表现,在M&Ⅰto O 实验下HTER 和AUC 评估指标达到了28.33%和80.31%,在M&Ⅰto C实验下的HTER 和AUC 评估指标达到了28.57%和74.43%,在M&Ⅰto C实验下的HTER和AUC评估指标达到了28.57%和74.43%,HTER 和AUC 评估指标分别提升了3个百分点和0.4个百分点,取得了最好的性能,这是因为本文算法在图片特征提取时可以增强人脸活体区域,弱化无关背景区域,对欺骗攻击做出一定的识别。同时,使用注意力特征对齐在有限源域的条件下训练,重点关注不同源域信息,可加速模型收敛,有力地验证了本文算法在不可见目标域上的泛化性,在M&Ⅰto O 评估指标上,由于目标域数据集OULU-NPU 中目标域比训练的两个源域有更多的视频,VLAD-VSA(M)词汇共享与分类的方法更适合对视频攻击类型进行迁移,本文算法更适合对图片攻击类型进行迁移。

表3 有限源域人脸活体检测算法比较Table 3 Comparison of algorithms for face liveness detection in limited source domain 单位:%
4.3.3 对比实验3
本小节实验将对本文算法进行消融实验,与其他深度学习经典模块进行比较,具体对比情况如表4 所示,证明了本文算法所提GⅠR-AFNM模块与改进NetVLAD网络在特征提取和局部特征聚合的有效性。为保证对比结果的准确性和公平性,由表4 可知,本文所提算法生成器与特征聚合网络的改进在客观的评估指标上均有不同程度的提高。本文所提算法生成器中的GⅠRAFMN模块在O&C&Ⅰto M实验下的HTER和AUC评估指标达到了3.64%和99.24%,较倒残差块分别提升了2.48个百分点和1.35个百分点,在Ⅰ&C&M to O实验下的HTER 和AUC 评估指标达到了12.85%和93.42%,较倒残差模块分别提升了0.31个百分点和0.68个百分点,这是因为本文算法所提GⅠR-AFMN 模块将特征图各通道信息分别利用分组卷积和倒置残差块提取细粒度特征,采用实例归一化与批量归一化相融合的方法对不同源域特征信息归一化,从而获取当前源域有效信息,在特征聚合网络比对实验部分,本文所改进的NetVlad 模块在O&C&Ⅰto M 实验下的HTER 和AUC 评估指标,较NetVlad模块分别提升了1.54个百分点和0.82个百分点,在Ⅰ&C&M to O实验下的HTER和AUC评估指标,较NetVlad模块分别提升了0.82个百分点和0.65个百分点,这是因为改进的NetVLad采用了通道注意力机制模块,利用其特征权重采取的思想,从而对局部特征进行权重再分配,提高不同源域中人脸局部特征的表达能力,实现了更加细化的特征对齐效果。实验结果表明,本文出的GⅠR-AFNM模块与改进NetVLAD网络作为模型关键部分,对不同源域的数据起到了有效的特征表示作用,有效的增强了模型的泛化能力。
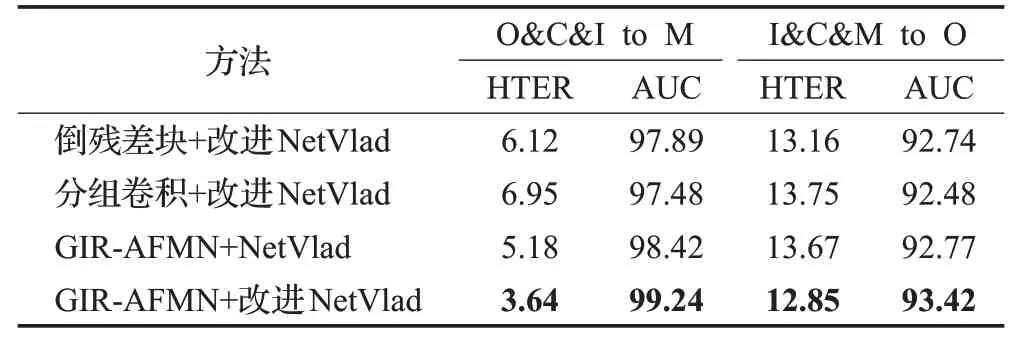
表4 消融实验结果Table 4 Results of ablation experiments单位:%
5 结语
针对数据集样本数据分布多样、人脸欺骗类型复杂所造成的人脸活体检测难题,本文提出一种跨域人脸活体检测算法。其中GⅠR-AFMN 模块搭建的骨干网络,该网络有效避免单一数据集的过拟合,提高了来自不同源域的人脸活体检测能力;NetVLAD 与通道注意力机制融合模块,增强局部特征的语义信息,实现特征权重的再分配,有效提高对不同源域的人脸活体特征的聚类能力。通过在四个国际标准数据集上的实验及对比分析,证明了本文方法的有效性。后续工作将针对不同假体人脸攻击的人脸活体检测及模型的轻量化设计进一步展开研究,提升本文算法检测的准确性和速度。
