三阶段自适应采样和增量克里金辅助的昂贵高维优化算法
2024-03-12顾清华刘思含骆家乐
顾清华,刘思含,王 倩,骆家乐,刘 迪
1.西安建筑科技大学管理学院,西安 710000
2.西安建筑科技大学西安市智慧工业感知计算与决策重点实验室,西安 710000
3.西安建筑科技大学资源工程学院,西安 710000
在过去的几十年里,进化算法逐渐应用于解决多目标工程优化问题,各种多目标进化算法也被相继提出[1]。然而,在现实生活的优化问题中,大多数问题目标函数的计算代价成本昂贵[2],即昂贵的多目标优化问题,例如创伤系统设计[3]和熔炉优化[4],多目标进化算法在评估次数有限时求解昂贵问题面临很大的挑战。因此,代理辅助的进化算法(surrogate-assisted evolutionary algorithms,SAEAs)应运而生,并成为求解昂贵的多目标优化问题的流行方法[5]。
SAEAs使用代理模型的输出来评估解,以减少昂贵的函数评估次数,根据代理模型的不同输出结果,可以将SAEAs分为两类。第一类是基于分类的SAEAs,其代理模型的输出是解决方案的合理类型,即好解或坏解。利用k-最近邻模型[6]、前馈神经网络模型[7]或装袋集成模型[8]等作为分类器来判断解的类型。第二类是基于近似的SAEAs,是最常见的一类,其代理模型的输出是解的预测值,例如:ParEGO(Pareto optimization efficient global optimization)[9]使用克里金模型作为代理模型来近似目标函数的聚合函数;在K-RVEA(Kriging-assisted reference vector guided evolutionary algorithm)[10]中,构建克里金模型来逼近每个目标函数,以提高收敛性和多样性;HSMEA(hybrid surrogate-assisted multi-objective evolutionary algorithm)[11]、HE-OMOPSO(heterogeneous ensemble-optimal multi-objective particle swarm optimization algorithm)[12]利用几种机器学习技术的异质集成来提高对不确定性估计的准确性,其中HE-OMOPSO通过加权平均法将克里金模型和径向基函数网络模型结合起来有效的逼近目标函数;CBSAEA[13]对种群进行聚类分析,使用径向基函数作为代理模型来辅助差分进化算法对个体进行选择。此类SAEAs使用模型输出的预测值或不确定性对候选解进行排序,具有较好的预筛选能力。
许多机器学习技术已用在SAEAs 中建立代理模型,其中,克里金模型应用最为广泛,它能够在得到预测值的同时提供预测的不确定性,然而,当求解决策变量高维的多目标进化问题时,在低维中表现良好的克里金辅助的SAEAs 将变的难以计算,主要是由于训练克里金模型的计算复杂度高,为O(n3),其中n是训练样本数[14],而且在每次面对新样本时,都需要重新构建模型[15]。针对上述困难,相关学者尝试将增量学习理论加入克里金模型,使模型在更新时利用上一个模型的信息来降低计算成本,并在单目标优化问题上取得了一定的进展[16],但仅考虑了单目标优化且模型超参数固定,因此仍存在局限。本文提出了一个基于三阶段自适应采样策略的增量克里金辅助进化算法(incremental Krigingassisted evolutionary algorithm with a three-stage adaptive sampling strategy,TS-ⅠKEA)来求解决策变量高维的昂贵多目标优化问题。本文的主要贡献可归纳如下:(1)将改进的增量克里金模型应用于SAEA,能够基于每代种群的不确定性自适应的决定是否更新超参数,在控制计算量的前提下保证模型的精度;(2)设计了一种三阶段自适应采样进行模型管理,将算法的优化状态分为三种,并根据所处状态采用不同的策略。
1 基础知识
1.1 昂贵高维多目标优化算法
在这项工作中,研究问题为以下形式的昂贵高维多目标优化问题:
其中,x是具有d个决策变量的决策向量,X表示决策空间,fm(x)是目标向量F的第m个目标。多目标是指目标的数量m大于2。目标函数是黑盒,要通过耗时的数值模拟或昂贵的物理实验来评估,因此,为解决此问题,必须基于模拟实验收集的数据来构建代理[2]。在代理辅助进化优化的背景下,d>20 的问题被称为高维问题,现有的大多数SAEA仅可以解决决策变量少于20个的问题。除此之外,对于多目标优化问题,通常没有唯一的理想解来达到所有目标的最优值,而是存在一组折衷的帕累托最优解,称为帕累托集(Pareto set,PS),PS在目标空间中的投影称为帕累托前沿(Pareto front,PF)。
1.2 基于前景区域的进化算法
本算法选择PREA(promising-region-based evolutionary multi-objective optimization algorithm)[17]作为优化器,其一PREA 能够很好的适应各种PF,保证TS-ⅠKEA 对具有不同PF 的问题都有更强的鲁棒性,其二PREA 是基于指标的多目标进化算法且其指标Ir∞的计算复杂度仅为O(n2),计算复杂度低更适用于求解高维多目标优化问题。PREA 在目标空间识别出有希望的区域,再使用基于平行距离的多样性维护机制在有希望的区域内选择个体,两个主要组成部分为:(1)有希望区域:使用指标Ir∞来表示每个个体的适应度值并去除种群异常点:
其中,x和y是目标空间Rm中的解,xq和yq分别表示其第q维的目标函数值,Z(x,y)=(max(0,[y1/x1]-1),max(0,[y2/x2]-1),…,max(0,[ym/xm]-1))。根据个体的适应度值标记种群中最好的N个个体,据此在目标空间定义一个有希望区域Rm:
其中,和分别表示N个最好解中第i个目标的最大值和最小值。有希望区域Rm至少包含N个个体,该区域之外的个体被认为是收敛性不足且需要被删除的解。(2)多样性维护机制:将候选个体垂直投影到一个由指定的超平面上,平行距离dij是任意两个个体垂直投影之间的距离,每个个体的拥挤距离Di由平行距离来表示:
依次从Rm中选择拥挤距离最小的两个个体并将适应度值较小的个体删除,重复进行直到种群规模达到N。
2 基于三阶段自适应采样策略的增量克里金辅助进化算法
2.1 算法整体框架
算法构建自适应更新超参数的增量克里金模型作为代理模型,使用PREA 作为优化器,并提出一种三阶段自适应采样准则进行模型管理,整体流程图如图1所示。TS-ⅠKEA 每十代输出由交叉变异操作产生的后代种群Ps,并根据代理模型的预测值进行预选。在每一轮的输出群体Ps中选择T个解进行真实函数评估,这些解用来更新种群P和代理模型。以下六个重要步骤组成了TS-ⅠKEA。

图1 TS-ⅠKEA算法流程图Fig.1 Flowchart of TS-ⅠKEA algorithm
(1)初始化:使用拉丁超立方体采样生成大小为N的初始种群P,并使用真实函数对其进行评估。使用种群P对每个目标函数建立原始增量克里金模型。
(2)运行优化器:使用PREA进行种群进化,其中函数评估替换为使用自适应更新超参数的增量克里金模型。在用于采样之前,将经过10代的演化。
(3)填充采样:采用三阶段自适应采样策略,分别考虑当前种群的收敛性、多样性和不确定性,将算法的优化状态分为三种,并根据所处状态采用有针对性的采样策略,详细过程见2.3节。
(4)更新种群:与PREA 中的思想一致,对于新样本,P种群由具有无限范数的基于比率的指标Ir∞和基于平行距离的多样性维护机制来进行更新。
(5)重建自适应更新超参数的增量克里金模型:利用所有训练数据重建每个目标函数的模型,并根据最大不确定性决定是否更新超参数,详细说明见2.2节。
(6)重复进行步骤(2)~(5)直到真实函数评估次数耗尽。
2.2 自适应更新超参数增量克里金模型
克里金模型(也被称为高斯过程)是全局性的近似模型,它提供预测值和预测的不确定性信息。原始克里金模型假设多目标优化问题的目标函数采用以下形式:
其中,μ(x)是高斯过程的预测值,ε(x)是一个平均值为零、标准差为δ的高斯分布。图2显示了由四个训练数据(x(1),y(1))、(x(2),y(2))、(x(3),y(3))、(x(4),y(4))构建的一维克里金模型,图中阴影部分表示置信范围。尽管克里金是理想的代理模型,但正如前文中所提到的,对决策变量高维的问题建模非常困难,为了应对这个问题,在克里金模型中引入增量学习,将时间复杂度降低到O(n2)。
假设建立了一个有n个样本的克里金模型,此时需要用q个新样本来更新它。增量克里金模型[16]是利用从先前模型获得的信息来更新模型,并采用θ调整策略[18]来学习初始超参数,而不像原始的克里金模型从头开始训练。由于广泛调整简化的超参数的效果要优于调整不准确但完整的超参数集,所以θ调整策略将所有的超参数调到相同的值,在一维空间中只优化一个θ值,从而将超参数学习问题的维度降低到一维。
用U表示训练数据之间的相关矩阵,由旧模型的U-1计算新的Û-1 是建立增量克里金模型最具挑战性的部分。由于增量模型的超参数是从以前的模型中沿袭的,所以Û-1 的前n行和前n列由U-1组成。新的相关矩阵表示为:
根据分区矩阵的逆向计算,可以得到:
其中,C=B-ATB-1A,是一个q×q矩阵。新样本的数量q比训练样本的数量n小得多,所以公式(10)的整个复杂度为O(n2)。当使用Cholesky 分解时,构建增量克里金模型最困难的部分是由先前克里金模型的E计算新的Ê,以满足Û=ÊÊT。由于Ê是一个下三角矩阵,Ê可以写为:
其中,E11和E22也是下三角矩阵。因此可得:
比较公式(9)和(12),可以得到:
由于Cholesky分解是独一无二的,可以从公式(13)中得到E11=E。根据公式(14),计算出ET21=E-1A和E21=AT(ET)-1,将它们代入公式(15),即可得到E22=Chol(B-AT(ET)-1E-1A)。最后,新的相关矩阵Ê可以写为:
其中,(B-AT(ET)-1E-1A)是q×q的矩阵,Cholesky 分解复杂度为O(q3),q远小于训练样本数n,因此可忽略不计,公式(16)的整体复杂度也是O(n2)。
与仅调整一次超参数的模型相比,在整个更新过程中对超参数进行某种形式的再评估可有效利用现有的计算预算[18];另一方面,更新超参数是克里金模型的主要计算成本。根据上述因素,本算法采用包含两个基本思想的自适应更新超参数策略,以更好地平衡计算成本和模型精度:(1)克里金模型输出的不确定性被用来衡量模型的准确性,不确定性越大表明模型的准确性越差。因此,如果此时种群中个体的最大不确定性大于本轮出现的最大不确定性值,超参数就会更新,将每次更新视为新的一轮。(2)为了加快优化过程,此策略在大多数情况下使用增量克里金建立模型,而不更新超参数,将旧模型的超参数视为新模型的起点。
2.3 三阶段自适应采样策略
对于SAEAs 来说,选择合适的训练数据来更新代理模型是至关重要的。选取收敛性和多样性好的有希望解可以提高这两方面的性能,而选取不确定解则可以提高代理模型的全局精度。为了充分利用有限的函数评估次数更有针对性的进行采样,本文提出了一种基于优化状态评估的三阶段自适应采样策略。优化状态如图3所示。

图3 三阶段采样策略流程图Fig.3 Flowchart of three-stage sampling strategy
优化状态分为三种情况,若此时增量克里金模型更新超参数,按照更新要求则此时模型预测的不确定性较大,应探索未开发区域以提高模型的精度,则为不确定性需求状态;若种群Pt的收敛性与上轮的种群Pt-1收敛性有明显差异,则表明仍有收敛空间,为收敛性需求状态,反之则为多样性需求状态,注意此处使用种群中解到估计理想点的距离来衡量收敛性。
针于每种优化状态,采用相对照的特制抽样策略来选择T个新样本用于昂贵的函数评估。
(1)收敛性采样策略:选择T个适应度值最大的个体,此处的适应度值用指标来衡量,与PREA中一致。
(2)多样性采样策略:依次计算每个个体对种群多样性的贡献值,多样性用纯多样性(pure diversity,PD)指标来衡量,选择贡献值最大的T个个体。
(3)不确定性采样策略:首先对当前种群个体的每个目标依次进行不确定性的排序,不确定性为增量克里金模型的对应输出值,随后对每个个体每个目标上的排序序号取均值,作为其不确定性排序号码,选择排序号码最大的T个个体进行真实目标函数评价。
由上述三种优化状态的区分以及三种有针对性的策略的制定,可以看出三阶段自适应采样策略能够首先保证算法收敛性,且在模型精度较低时,通过选择不确定性大的解进行再评估,对未开发区域加强探索,避免了模型误差的累加,同时对多样性的探索使算法降低陷入局部最优的可能性。
3 实验与分析
为了验证所提出的算法TS-ⅠKEA和策略的有效性,本章分别在DTLZ[19]和MaF[20]上进行了数值实验,并在实例上进行了仿真,验证了所提出算法的实际意义。
3.1 对比算法
选择八种最先进的算法进行对比,简要介绍如下:
(1)NSGA-ⅠⅠⅠ[21]是经典的多目标进化算法,它引入了广泛分布的参考点以保持种群的多样性。
(2)PREA[17]是基于指标的多目标进化算法,它首先在目标空间中识别有希望的区域,并采用基于平行距离的多样性保护策略来选择有希望区域内的个体。
(3)REMO[22]是代理辅助进化算法,它提出了一种新的基于三类分类器的关系模型来预测候选解与已评估解之间的关系。
(4)ABSAEA[23]使用自适应贝叶斯作为代理模型解决昂贵多目标优化问题,采样标准在优化过程中自适应切换,以实现勘探和开采之间的平衡。
(5)EDN-ARMOEA[24]提出一种高效辍学神经网络作为代理模型,在训练和测试阶段都采用退出策略。
(6)HeE-MOEA[25]使用不同机器学习技术的集成作为模型管理和填充标准的代理模型,以有效近似目标函数。
(7)CPS-MOEA[6]使用两个外部解集来训练k-最近邻模型,并以此作为分类器来过滤新生成的个体。
(8)KTA2[26]提出了影响点不敏感模型作为代理模型,并设计了分别考虑收敛性、多样性和模型不确定性要求的自适应采样策略。
3.2 参数设置
TS-ⅠKEA中的参数设置如下:
(1)种群大小为N=100。
(2)每个算法在每个测试问题上独立运行20次。
(3)更新代理模型之前,优化器迭代次数为wmax=10,每次更新代理模型时选择T=5 个解进行真实函数评估。
下面列出所有比较算法的通用参数设置:
(1)本文使用目标为3,决策变量分别为20、40、60和100的DTLZ和MaF测试集来验证算法有效性,每个算法的停止条件是达到最大评估次数FEmax,由于评估是昂贵的,当决策变量为20,40,60 时设置为500,决策变量为100时设置为1 000。
(2)在DTLZ 和MaF 测试集中,使用ⅠGD 指标进行评估,ⅠGD 值越小算法的综合性能越好;在实际工程优化问题中,由于不存在真实的PF,因此,采用HV指标比较优化结果,HV越大则得到的优化结果越好。
(3)初始训练样本设置为N1=100。
(4)所有程序均在Matlab R2021b 中编码,使用进化多目标优化平台PlatEMO[27]进行对比实验,每个算法独立运行20 次,通过置信度为0.05 的Wilcoxon 秩和检验比较所提出算法和比较算法的实验结果,符号“+”和“-”分别表示对比算法显著优于和劣于TS-ⅠKEA,符号“=”则表示没有显著差异;为了保证公平性,所有对比实验的特定参数设置都严格遵循原始文献中的设置。
3.3 策略有效性实验
为验证所提出的两种策略的有效性,本节设计TS-ⅠKEA 算法的两个变体,称为TS-ⅠKEA1 和TS-ⅠKEA2,其中TS-ⅠKEA1除不使用三阶段自适应采样策略来管理代理模型以外,与TS-ⅠKEA保持一致,TS-ⅠKEA2使用增量克里金模型作为代理模型,此模型的超参数不随算法的更新进行自适应调整,其余与TS-ⅠKEA保持一致。对NSGA-ⅠⅠⅠ、PREA、变体TS-ⅠKEA1、变体TS-ⅠKEA2 以及TS-ⅠKEA五个算法在三个目标和20、40、60、100个决策变量的DTLZ问题上进行20次独立运行实验,表1为得到的相应ⅠGD值,并用灰色阴影突出了最佳结果。从实验结果可看出TS-ⅠKEA取得了最佳的结果。首先,代理模型辅助的TS-ⅠKEA1和TS-ⅠKEA2明显优于多目标进化算法NSGA-ⅠⅠⅠ和PREA,这表明在有限次函数评估下,代理辅助具有优势;其次,可观察到TS-ⅠKEA2 在部分测试实例上与TS-ⅠKEA 取得了相似的性能,但在DTLZ1、DTLZ3和DTLZ6上仍差于TS-ⅠKEA,这是由于变体2舍弃了在运行过程中自适应更新模型超参数,使得算法难以在模型预测产生偏差时及时调整,则模型误差随着数据的不断更新逐渐累加,尤其是针对DTLZ1、DTLZ3 这类多模态难以收敛的问题时,算法精度更加无法保证,因此变体2的算法效果比所提算法差;最后,从TS-ⅠKEA和TS-ⅠKEA1的实验结果中看出,所提算法在大多数测试问题上优于变体1,变体1 保留了自适应更新超参数的增量克里金模型,保证了代理模型的预测精度,但又因为没有使用三阶段自适应采样策略来管理代理模型,无法有针对性的选择更适合算法当前所处状态的个体,不能有效利用有限计算资源。综合以上分析,自适应更新模型超参数的增量克里金模型和三阶段自适应采样策略在TS-ⅠKEA算法中缺一不可,求解昂贵的高维多目标优化问题时,该模型和模型管理策略形成的协作机制可以有效平衡种群的收敛性和多样性。
3.4 DTLZ和MaF上数值实验
3.4.1 DTLZ测试集上实验与分析
将六种算法在DTLZ测试集上独立运行20次,得到的ⅠGD 结果如表2 所示,其最佳平均ⅠGD 值由灰色背景突出显示。实验结果显示,REMO、EDN-ARMOEA、ABSAEA、HeE-MOEA、CPS-MOEA、TS-ⅠKEA 在DTLZ测试集上取得的最佳结果数量分别为10、0、0、0、3、15,其中TS-ⅠKEA表现最优,下面结合每个测试问题的特性进行综合分析。

表2 算法在三目标不同决策变量的DTLZ上的ⅠGD值Table 2 ⅠGD values of algorithms on DTLZ with different decision variables for three objectives
DTLZ1 和DTLZ3 具有多模态的特性,很难在有限函数评估下收敛到真实PF。REMO在DTLZ1和DTLZ3上效果最好,其次是TS-ⅠKEA。TS-ⅠKEA未能取得最佳结果的原因在于,多模态问题具有多个全局或局部最优解,TS-ⅠKEA 的三阶段自适应采样策略首先保证收敛,但局部最优的出现对算法采样策略的状态评估产生了影响,算法错把寻找到的局部最优当作全局最优进而转向加强多样性,从而忽略对其他最优区域的探索。从表2 可以看出六种算法在这两个测试问题的ⅠGD 值都非常大,说明算法得到的非支配解集都离真实PF 很远。因此,解决这些问题需要进行更多的函数评估。
DTLZ2 和DTLZ4 相对容易收敛,但它们的困难在于保持种群的多样性,通常用来检验算法保持解决方案均匀分布的能力。DTLZ2是一个具有凹形椭圆的测试问题,TS-ⅠKEA在DTLZ2问题上取得了最好的结果,其次是REMO 和HeE-MOEA、TS-ⅠKEA 的三阶段采样策略对三个状态的评估和针对性的策略保证了算法的收敛性和多样性以及模型预测的准确性。DTLZ4是具有偏好特点的测试问题,可以观察到REMO、ABSAEA 和EDN-ARMOEA均在低维时表现良好,但随着决策变量维数的增加其性能变差,其中EDN-ARMOEA的代理模型EDN在适应度预测和不确定性估计方面的准确性较低,而且在解决高维问题方面的性能略差,REMO 提出的关系模型更适用于中低规模的决策空间,而本算法TS-ⅠKEA 的自适应更新超参数的增量克里金模型能够很好的适应高维决策变量。
DTLZ5 问题具有退化的特点,用来测试算法在一条曲线上收敛的能力。从表2可以看出,TS-ⅠKEA在这个问题的每个决策变量上都取得了最好的结果。DTLZ6也具有退化和偏向的特性,CPS-MOEA 在这个问题上取得了最佳结果,其次是REMO和TS-ⅠKEA,CPS-MOEA使用分类器来探索未知区域,在解决这类问题上有较大的优势,而TS-ⅠKEA利用代理模型输出的预测值和不确定性进行搜索,在搜索过程中可能被误导,从而在这一问题上表现较差,虽然TS-ⅠKEA 在DTLZ6 问题上没有取得最好的结果,但其竞争力也得到了体现。
DTLZ7 测试问题有一组不相连的帕累托最优区域。观察图4 可看出TS-ⅠKEA 的ⅠGD 值变化趋势更快且持续下降,并且图5可视化了六个算法在三个目标20个决策变量的DTLZ7 上得到的非支配解集,可以看到只有TS-ⅠKEA找到了所有四个不相连的PF且获得了具有保证收敛和分布的子种群,其余的算法都不能取得满意的结果,不适合处理这种不连续的问题。这是由于三阶段自适应采样策略在仍有收敛空间时重点保证收敛,使得TS-ⅠKEA 的ⅠGD 变化曲线能够在初始阶段迅速下降,又通过对多样性和未开发区域的探索以及代理模型在预测精度不高时适时调整超参数,使得ⅠGD能够稳步持续下降,并最终找到分布均匀的全局最优解。

图4 在DTLZ7上获得的ⅠGD变化曲线Fig.4 ⅠGD variation curves obtained on DTLZ7
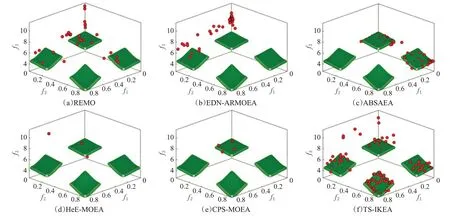
图5 在20个决策变量DTLZ7上取得的非支配解Fig.5 Nondominant solutions obtained on 20 decision variables DTLZ7
从DTLZ测试问题实验结果可以看到,TS-ⅠKEA在处理退化和不连续问题上具有极强的优势,虽然没有在每一类问题上都表现的最好,但综合而言,TS-ⅠKEA 表现出了自身的竞争力。
3.4.2 MaF测试集实验与分析
六种算法独立运行MaF基准测试问题20次的ⅠGD统计结果如表3所示,其中将最好的结果进行了灰色阴影突出显示。实验结果显示,REMO、EDN-ARMOEA、ABSAEA、HeE-MOEA、CPS-MOEA、TS-ⅠKEA 在MaF测试集上取得的最佳结果数量分别为7、0、1、0、0、20,可以看出TS-ⅠKEA明显优于其他算法且整体表现最好。
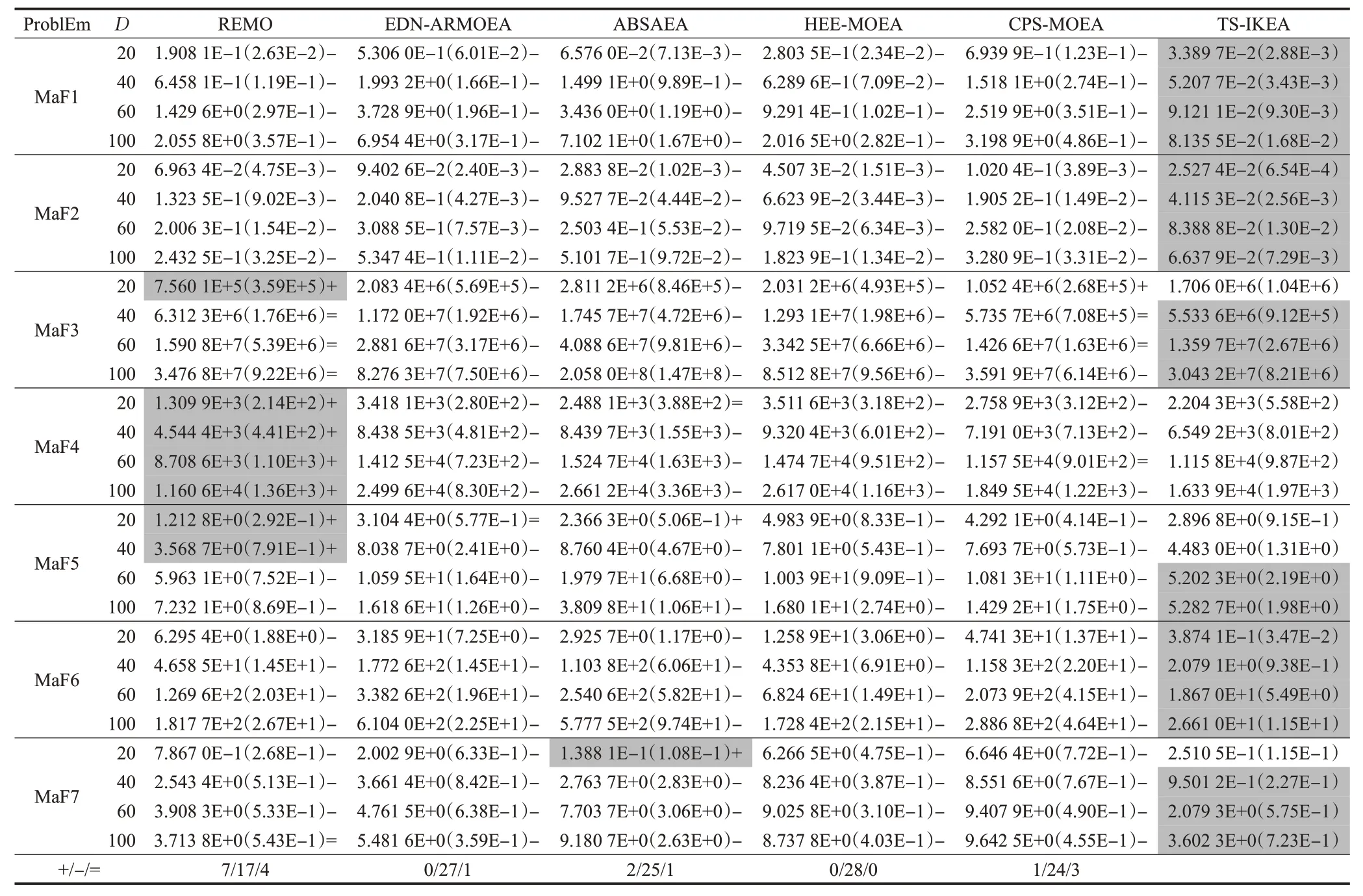
表3 算法在三目标不同决策变量的MaF上的ⅠGD值Table 3 ⅠGD values of algorithms on MaF with different decision variables for three objectives
在具有反转PF的MaF1和凹PF的MaF2上,TS-ⅠKEA表现最佳。从ⅠGD 值可以看出,在20、40、60、100 的决策变量上,TS-ⅠKEA 全都具有绝对优势,通过图6 算法在MaF1 上ⅠGD 的变化曲线可以明显看出,TS-ⅠKEA 的ⅠGD下降速度最快,这归因于三阶段采样策略对于优化状态的评估中,优先保证种群的收敛,使种群能够更快速的收敛,且更新模型超参数时对未知区域的探索使算法避免陷入局部最优。
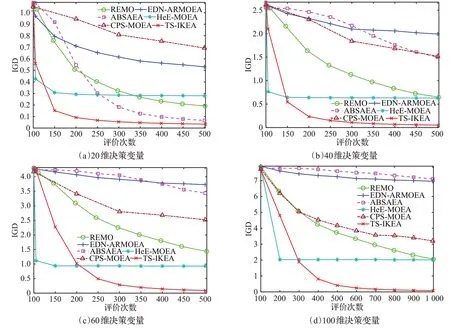
图6 在MaF1上获得的ⅠGD变化曲线Fig.6 ⅠGD variation curves obtained on MaF1
对于MaF3和MaF4具有多模态特征的问题,TS-ⅠKEA没有取得最令人满意的结果,次于REMO。但是可以从表3 中看出,这两类问题的ⅠGD 统计结果都很大,说明算法得到的非支配解离真实PF 很远,只有进行更多的真实函数评估才能解决这类问题。MaF5 是凸PF 的有偏问题,在决策变量为20和40时,REMO取得了最好的结果,但随着决策变量变大,TS-ⅠKEA优势凸显出来,这可能的原因是本算法提出的自适应更新超参数的增量克里金模型在高决策变量时对维持模型精度具有优势。MaF6 和MaF7 的效果以ⅠK-PREA 最佳,ABSAEA次之。其中,MaF6 具有退化的PF,图7 可视化了20 个决策变量时MaF6六个算法得到的非支配解与真实PF,可以直观的看出在有限的函数评估下只有TS-ⅠKEA 找到了真实PF 并取得了一定程度的分布性,ABSAEA 靠近了真实PF但仍没有找到,其余算法离真实PF还有很远的距离。TS-ⅠKEA 的采样策略在未收敛时首先重点保证收敛,因此能够成为唯一一个找到真实PF 的算法。再次证明了TS-ⅠKEA 在处理退化问题上具有独有的优势。
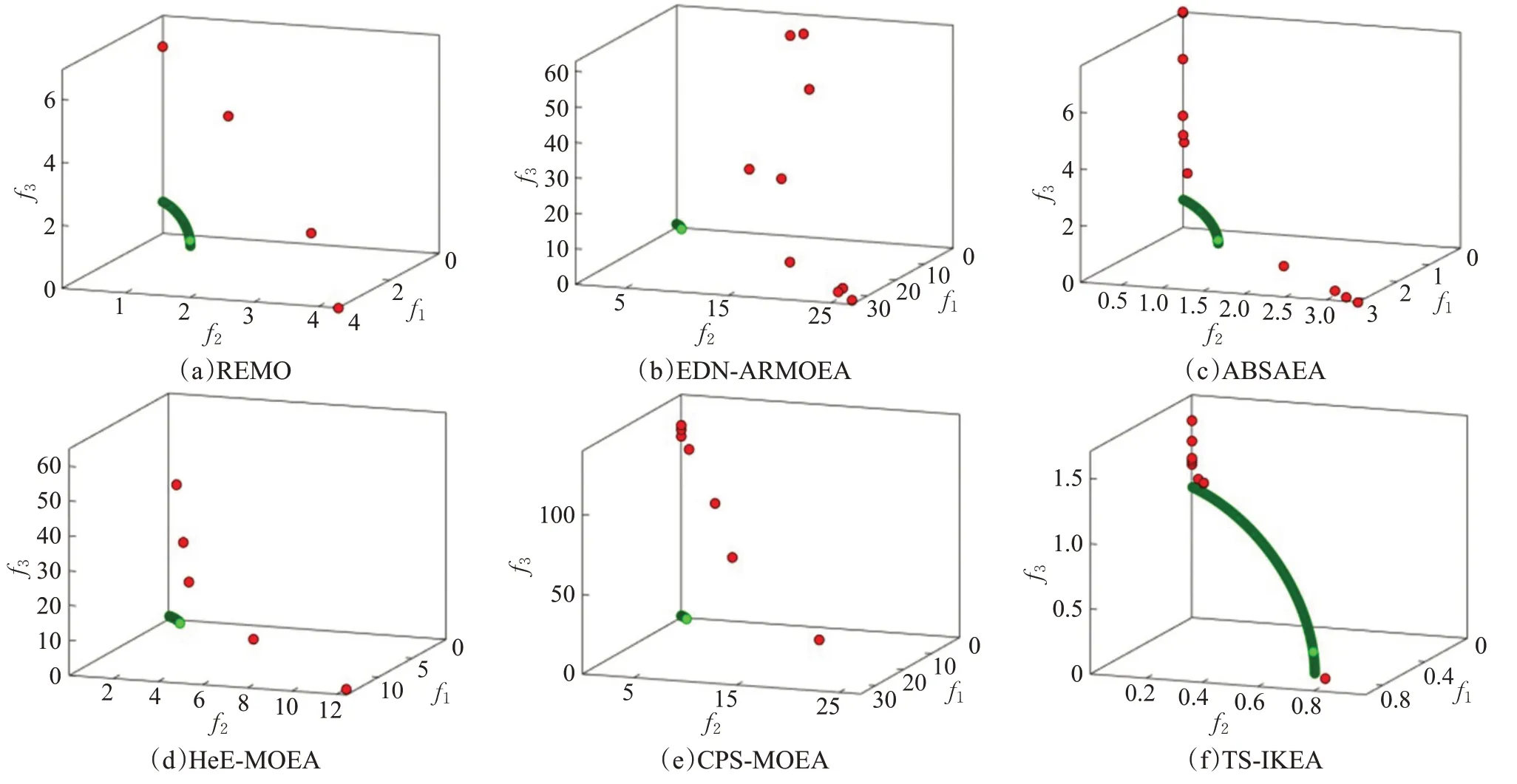
图7 在20个决策变量MaF6上取得的非支配解Fig.7 Nondominant solutions obtained on 20 decision variables MaF6
3.4.3 算法运行时间对比分析
本小节给出算法的时间对比分析,图8(a)和(b)分别显示了六个算法在DTLZ 和MaF 系列测试问题的四个不同决策变量上的平均运行时间,可以看出TS-ⅠKEA时间消耗仅次于CPS-MOEA,显著优于其他四个对比算法。尽管CPS-MOEA 时间消耗最小,但在56 个测试实例的44 个上性能都差于TS-ⅠKEA,其模型的分类精度比较差;使用原始克里金作为代理模型的ABSAEA,随着决策变量维度的增高,运行时间成倍激增,而TS-ⅠKEA 使用的增量克里金模型自适应更新超参数,保证模型精度的同时大幅降低算法的时间复杂度,具有实用价值。综合算法性能和运行时间分析,TS-ⅠKEA具有很强的竞争力。

图8 各算法在DTLZ和MaF上的运行时间Fig.8 Running time of all algorithms on DTLZ and MaF
3.5 实际工程优化案例
为了验证算法TS-ⅠKEA在实际问题上的有效性,本节在路径规划实际工程[28]案例上进行了仿真实验,并与多个最先进的算法进行了对比。路径规划优化问题是在图形G=(V,E)中寻找一组最佳路径P*={p1,p2,…,pL},路径N由G=(V,E)中的一组相邻节点组成,从初始节点nS∈V到预定义端点nEnd∈V,即N=(ni,ni+1,…,nk)=pi,ni=ns,nk=nEnd,该问题包含27 个决策变量,需要在欧氏距离、预期延迟、上升高度、路程时间和路径平滑度五个目标中寻找最佳结果。用上述五个目标来评估解决方案,解决方案为固定长度的路径N。七种最新的SAEAs 在500 次评估后得到的HV 和运行时间如表4 所示,其中最佳结果用深灰色标出,排名第二的用浅灰色标出。通过实验结果可以看出TS-ⅠKEA 获得的解综合性能HV最好,运行时间仅次于CPS-MOEA。其原因在于CPS-MOEA 是基于分类的SAEAs,在一次运行后即能筛选出种群大小的“好”解,因此能够更快达到算法终止条件,但由于选解的粗糙,得到的解的性能较差;本算法采用的自适应更新超参数的增量克里金模型使得算法相比其他SAEAs 运行时间大幅度减少,尤其是与使用原始克里金模型代理的算法相比,例如KTA2、ABSAEA,又有三阶段采样的模型管理策略来保证模型的精度和种群的性能,算法取得了最优的结果。因此,性能的提高和时间的缩短使得TS-ⅠKEA 在实际工程中具有实用价值。

表4 七个算法在实际问题上的HV和运行时间Table 4 HV and runtime of seven algorithms in practical problems
4 结论
本文提出了一种新的可用于求解决策变量高维的SAEA,称为TS-ⅠKEA。该算法使用根据模型预测精度自适应更新超参数的增量克里金模型作为代理模型,降低时间复杂度的同时保证了模型在高维度时的准确度,并提出了基于优化状态的三阶段采样策略来自适应的选择更合适的解进行函数重评估。在DTLZ、MaF两组测试集以及路径规划实际工程案例上与近年提出的最先进的算法进行对比实验,验证了所提出算法的竞争力,特别是在处理一些退化和不连续问题上具有独特优势,且具有实际应用价值能够大幅减少优化时间,在解决高维昂贵多目标优化问题具有广阔的应用前景。
在未来的工作中,将继续探索更有效的模型管理策略,使用更加精准的优化状态评估方案来进一步提高模型精度,此外,将TS-ⅠKEA 扩展到解决具有约束的复杂现实问题也是值得研究的。
