深度学习的工人多种不安全行为识别方法综述
2024-03-12苏晨阳武文红牛恒茂王嘉敏汪维泰
苏晨阳,武文红,牛恒茂,石 宝,郝 旭,王嘉敏,高 勒,汪维泰
1.内蒙古工业大学信息工程学院,呼和浩特 010080
2.内蒙古建筑职业技术学院建筑工程测绘学院,呼和浩特 010080
建筑业作为世界上最危险的行业之一,其生产安全事故频发,导致了众多损失,根据中华人民共和国住房和城乡建设部的统计数据,2020年,全国共发生房屋市政工程生产安全事故689起,死亡794人,88%的建筑安全事故是由工人的不安全行为所引起的[1]。所以为了更好地保障工人与环境的安全,需要对不安全行为进行外部条件的监督。
对于传统识别方法,早期通过传感器来判断工人与器材的位置,如在帽壳和帽衬间设置压力传感器[2],并与控制模块连接,检测工人是否佩戴安全帽,但这类方法人员与设备成本投入量大,且定位精度不高。后来发展出利用图像处理技术来进行不安全行为的识别,如用HOG 或基于颜色的手动特征方法提取安全帽的形状、颜色信息,送入分类器中进行识别,使用Kinect 传感器[3-4]将动作活动高频关节构建特征模型。使用HOG特征和人体重心[5]变化建模,利用SVM 进行分类,识别工人的跌倒情况。基于手动特征的传统行为识别方法较为依赖特征的选择和提取,若研究人员对特定领域了解不够,很容易忽略关键的特征点,且识别速度和准确率较低,在复杂施工环境下效果并不出色。
随着技术发展,结合深度学习进行的不安全行为识别逐渐出现,从多种个人防护设备的佩戴情况到各类违规行为,出现了许多研究,刘浩等[6]运用了多种深度学习框架,包括YOLOv3和ST-GCN来识别煤矿井下的工人多种不安全行为,含安全设备的佩戴和摔倒、跌落、疲劳作业等,达到了85.2%的平均准确率。王超等[7]也利用ST-GCN对空管工人伸懒腰、瞌睡、各种姿势入睡的行为进行有效识别。
综上所述,深度学习方法可以方便地对工人多种不安全行为进行识别,成为了目前的主流研究方向。
1 基于深度学习的不安全行为识别方法
对多样的不安全行为来说,不同的施工场地、不同的工种所需要注意的不安全行为并不相同,如高空作业的工人需要关注安全绳是否佩戴,而化工企业的工人不得在禁区吸烟。因此,对于不同种类的不安全行为,针对其特点,需要用不同的深度学习方法来识别,目前来看,深度学习在不安全行为的识别应用上主要有两大方法,目标检测和行为识别。
目标检测输入主要为静态图像,通过学习图像特征,输出目标在图像中的位置及类别。而行为识别输入主要为视频序列,针对具有时间上连续属性的动作进行特征学习,输出行为的对应类别。在需要检测未佩戴安全帽这样单帧图片即可判断的静态状态时,目标检测更为合适,而当需要识别打架等动态的行为时,行为识别的效果更好。据所研究的场景与需要针对的行为不同,选择合适的深度学习方法是目前的主流研究手段,图1为当前不安全行为识别主流方法及其适用行为,表1列举了当前研究方法的优势和局限性分析。

图1 不安全行为识别方法Fig.1 Unsafe behavior identification method
1.1 评价指标
虽然不安全行为识别包含目标检测和行为识别两种方法,但其同属深度学习中的多分类任务,可以引入混淆矩阵来为分类模型建立一套评价标准,以简单的二分类举例,混淆矩阵如表2。各个指标的含义如下:TP,真实为正样本,预测为正样本;FN,真实为正样本,预测为负样本;FP,真实为负样本,预测为正样本;TN,真实为负样本,预测为负样本。
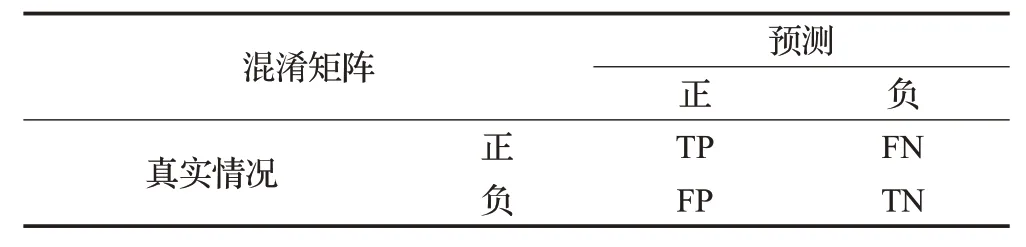
表2 混淆矩阵Table 2 Confusion matrix
基于此矩阵,有以下几种评价指标:
准确率(accuracy),即分类正确的样本占总样本个数的比例,计算公式为:
精确率(precision),指的是预测为正,真实情况也为正的样本占被预测为正的样本的比例,计算公式为:
召回率(recall),指的是实际为正的样本中被预测为正的样本所占实际为正的样本的比例,计算公式为:
平均精度(average precision,AP),即为PR 曲线下的面积,计算公式为:
均值平均精度(mAP),指在多分类任务中,所有类别的AP的平均值。计算公式为:
检测速度(FPS),即每秒可以处理的图片数量。
1.2 目标检测和行为识别的发展
1.2.1 目标检测方法
发展至今,目标检测已形成两大模型,分别为二阶段目标检测和一阶段目标检测。二阶段目标检测先进行区域生成,后通过卷积神经网络分类,常见的有R-CNN[8]、Fast R-CNN[9]、Faster R-CNN[10]、Mask R-CNN[11]等;一阶段目标检测通过一个网络直接提取特征和分类,常见模型有YOLOv1[12]、YOLOv2[13]、YOLOv3[14]、YOLOv4[15]、YOLOv5、YOLOv7[16]、SSD[17]等。
对于二阶段目标检测,Faster R-CNN 是迭代升级的较新版本,其复杂的网络结构和检测步骤带来了较高的精度,但在速度上存在劣势,基于其改进的Mask RCNN可以完成目标检测、实例分割等多种任务,其模型结构如图2 所示,由残差网络提取特征,送入RPN 区域预测网络生成锚框,通过全卷积层FCN 实现像素级别的分割,配合全连接层FC layers 得到分类信息和回归框信息,综合得到输出结果。
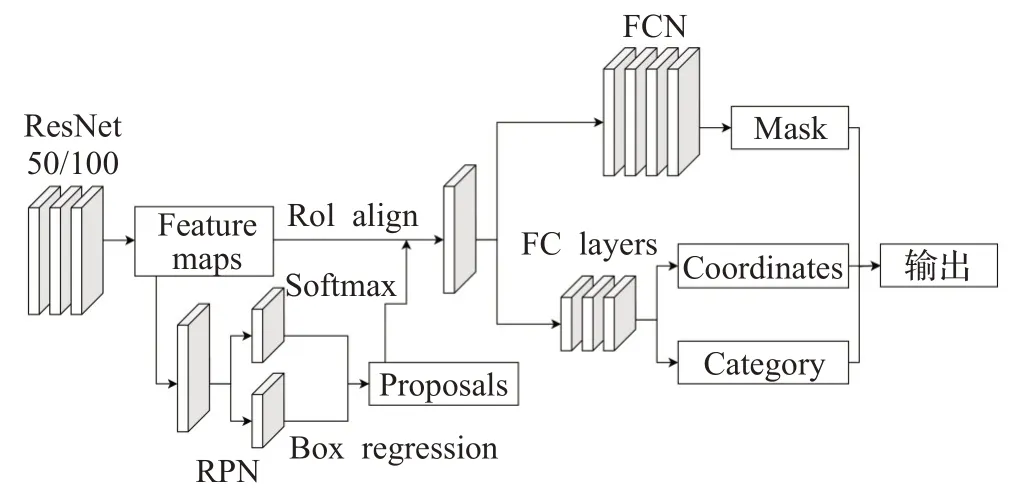
图2 Mask R-CNN模型Fig.2 Mask R-CNN model
Mask R-CNN虽然有着全面的能力和较高的精度,但复杂度较高的网络并不利于算力资源有限的边缘设备使用,而YOLO 系列在复杂度上具有优势,其中的小型网络版本如YOLOv5-n还可进一步减轻资源消耗,成为了许多研究人员的选择,其经典框架分为主干网络BackBone、颈部Neck 和头部Head。其中主干网络负责提取特征,Neck 层负责将浅层简单特征和深层语义特征融合,Head部分为检测头,分别负责大中小目标的检测。而广泛应用的YOLOv5 主要改进之处是在输入端引入了Mosaic数据增强和自适应锚框计算以及图片缩放,并且提出了Focus 结构,其核心在于切片操作,如图3 所示,原始的640×640×3 图像经过切片后,变成320×320×12特征图,随后会经过拼接和卷积操作,成为320×320×64 大小。通过该操作,平面上的信息会存储在通道维度,在使用3×3 卷积核提取时,可以减少下采样带来的信息损失。
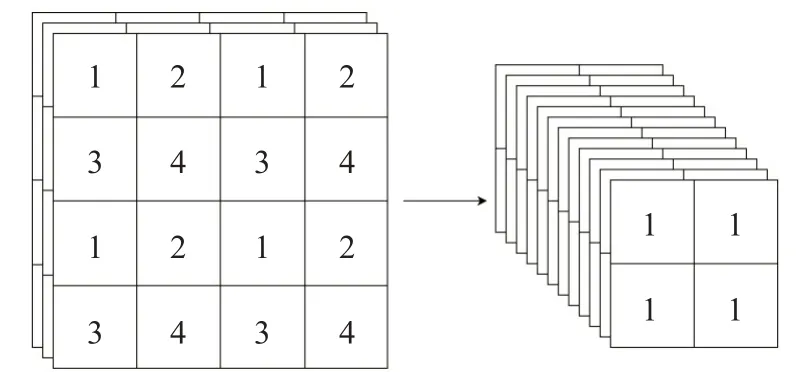
图3 Focus结构Fig.3 Focus structure
以目前的研究内容来看,基于目标检测方法的不安全行为识别研究最常用的模型为Faster R-CNN、Mask R-CNN和YOLO系列。
1.2.2 行为识别方法
与目标检测相比,行为识别会加入时间特征来识别具有上下文联系的动作,或采用人体关键点来建立骨骼模型框架特征体系,因此行为识别常以视频作为输入。目前基于深度学习的行为识别方法可分为基于卷积神经网络的模型如3DCNN[18]、Ⅰ3D[19]、ST-GCN[20]等,基于循环神经网络如LSTM[21]等,基于双流神经网络[22]如SlowFast[23]等,文献[24]介绍了近年来群体行为识别模型的发展。
在不安全行为识别的应用方面,卷积神经网络的优点是通用、易于实现,但在特征提取和表现能力上低于其他网络。其分支图卷积神经网络依据人体姿态来建模识别,如通过OPENPOSE算法对人体骨架进行估计,再利用图卷积神经网络ST-GCN 进行时序上的学习,图4 为ST-GCN 模型的网络流程,引入可学习的权重矩阵,赋予邻接矩阵A中重要节点较大的权重,之后与输入骨骼特征送入GCN 中运算,通过TCN 网络进行时间信息的聚合,得到行为分类。

图4 ST-GCN模型Fig.4 ST-GCN model
这样的方法在动态不安全行为识别中得到了广泛的应用,但在于人体被遮挡时,由于节点关联不清晰,识别效果会明显下降。因此双流模型进入了研究者视野,其提取两路特征的能力可以从更多的角度建立特征模型,尽量避免了实际应用中各种外界因素的干扰,在识别精度上有很高的效果。如图5 所示,双流模型SlowFast设计了两条卷积神经网络线路,一条用来提取较慢的特征信息如颜色等,一条用来提取快速变化的特征信息如时间动作等,其中慢通道还会接受来自快通道的信息进行融合,模型性能出色,但分开处理两路数据也让计算量和训练消耗变得较大,是需要在实际应用时优化的问题。
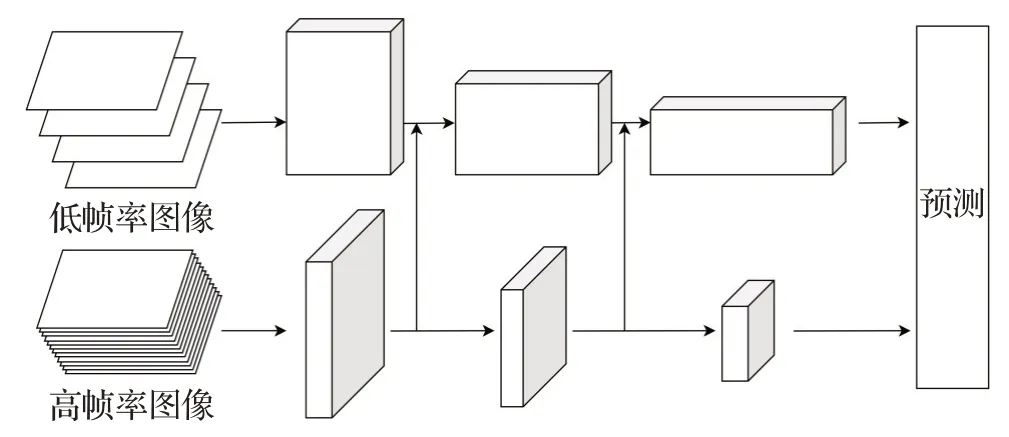
图5 SlowFast模型Fig.5 SlowFast model
此外循环神经网络长短时记忆单元方法LSTM 在更长的时间序列有着更好的表现,因此被众多研究者结合到卷积神经网络和双流卷积神经网络中,不足之处是计算和训练所需要的资源和时间较多。
1.2.3 目标检测和行为识别的模型性能
在不安全行为识别领域,目标检测方法和行为识别方法中都有着很多模型可以使用,通常准确率与精度是研究者需要考虑的因素,除此之外,不安全行为识别的应用场所通常在户外,部署在边缘设备,这就对计算资源和算力有所要求。表3、表4 分别为目标检测和行为识别中部分模型在公开数据集上的性能表现。

表3 目标检测模型性能Table 3 Target detection model performance
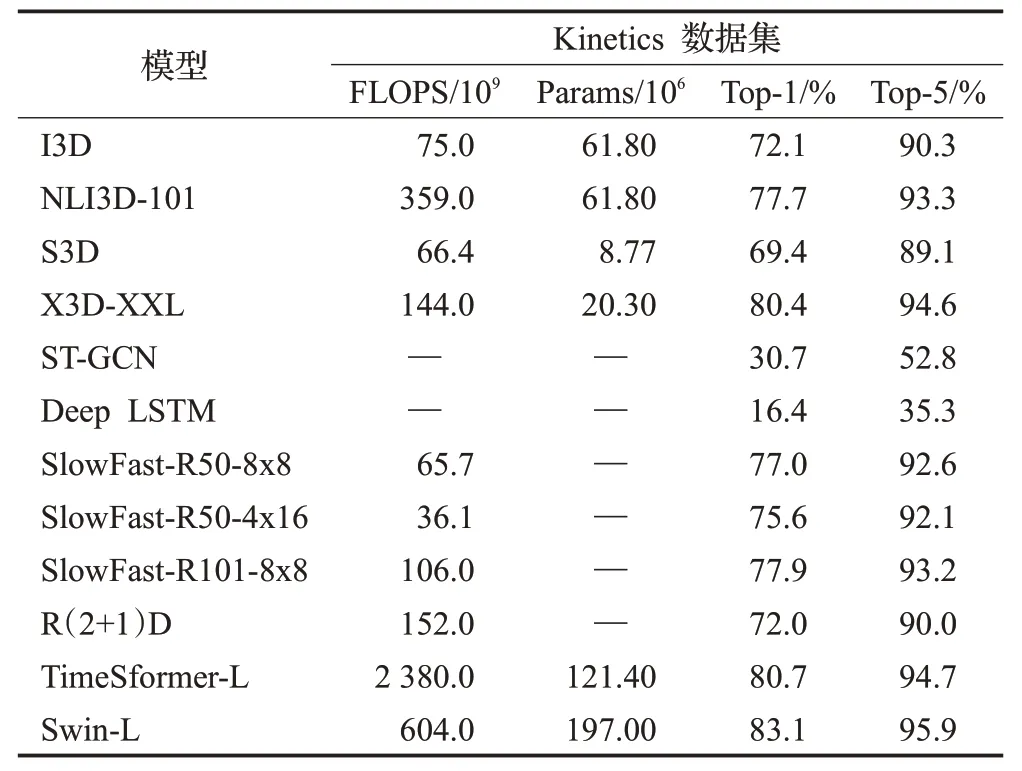
表4 行为识别模型性能Table 4 Behavioral recognition model performance
从上述表格内容可以看出目标检测模型中,YOLO系列在速度和复杂度上具有很大的优势,且可以采用更大的网络结构来牺牲速度换取精度,具有很强的灵活性,适合部署在边缘设备解决实际问题。而在行为识别模型中,3D卷积神经网络类的参数普遍较低,而双流网络和自注意力模型所需计算资源和参数数量较为庞大,符合高复杂度高精度的特点。
然而,在实际应用研究中,因背景、数据集、待识别行为的不同,模型性能会出现与上述分析不同的表现;同时,随着研究者的改进方法不同,效果也会存在差异。因此,对于不同条件下的不安全行为识别应用,分析各种方法与模型的效果,是本文的主要内容。
1.3 基于目标检测和行为识别的应用研究
1.3.1 基于目标检测方法的应用研究
在不安全行为识别的应用中,目标检测方法通常用来识别静态行为,比如人员的位置、是否佩戴安全帽、人与器械间距离等。
孙勇[25]基于Faster R-CNN 构建了建筑工人不安全行为检测系统,实现了对未佩戴安全帽、使用手机、进入危险区域、翻越护栏四类不安全行为的识别,在自建的真实场景数据集下mAP 值达到0.853。该模型的局限性在于精度和检测速度较低,在配置平常的电脑上单帧图片需要3 s左右才能识别。张博等[26]同样将Faster RCNN 用于施工现场防止人车碰撞的危险,检测工人位置,利用工人与卡车间的空间相关性计算碰撞的可能性,模型达到了98.5%的召回率,满足实际应用需求,但其不足之处在于数据为仿真现场拍摄,并未在实地取材,同时在遮挡和光照较差的环境下效果不佳。
可以看出,对包含了多个不安全行为的识别模型,其效果并不理想,平均均值精度较低,这是由于其实验中小样本的不安全行为识别精度严重拉低了整体精度。因此,若想实现包含多类别不安全行为的识别,一定要保证数据集中各行为样本的数量充足、比例稳定。此外,二阶段目标检测的速度有着天生劣势,近年来一阶段目标检测发展较快,在很多数据集上速度,甚至精度都优于二阶段目标检测,因此许多研究者选择使用YOLO为代表的一阶段目标检测来进行研究。
常捷等[27]使用YOLOv3对加油站工人抽烟、打电话进行识别,数据集覆盖了加油站的多个角度,对工作人员与车主的不安全行为进行了统一的识别,平均精度达到了84%,但对香烟这样的小目标检测精度仅有67%。YOLOv4模型增加了自对抗训练,主动添加噪声增强模型的鲁棒性,能够在施工场景图像质量普遍较低的情况下获得不错的性能,此外引入GⅠOU 损失函数,通过最小封闭矩形,避免ⅠOU 等于0 时梯度消失的问题,一定程度上改善了对小目标和复杂背景下的性能。王晨[28]使用YOLOv4 对安全帽是否佩戴、吸烟、使用手机三类行为进行识别,实验的优势在于数据的采集考虑到了环境因素,在多个气候环境下,采集了人群密集与零散的数据,增强了数据的泛化能力,因此识别获得了较好的效果,且对于天气、光照、遮挡的情况有着很好的鲁棒性,达到了0.92 的mAP 和26.2 的FPS,符合实时检测的任务要求,但其局限性在于所需计算资源和配置较高,推理速度较慢,在边缘设备部署具有一定难度。
近年来,其他基于目标检测方法的不安全行为识别研究对比见表5[29-34],分析可得,目标检测方法在识别静态行为时有着更大优势,二阶段目标检测方法中的Faster R-CNN 模型使用RPN 网络生成anchor,经过回归生成偏移量,确定候选框位置,之后RoⅠ-Pooling 收集anchor的proposals(即候选框坐标),再进行分类,精度虽然较高,但由于较为繁琐的网络步骤,在速度上存在劣势,实际应用中通常不能满足实时检测的速度要求。而一阶段目标检测方法如YOLO将目标检测转变为回归问题,将图像整体作为输入,利用NMS 非极大值抑制修正多目标定位,通过一个网络直接输出结果,在复杂度上存在优势,但在小目标和背景复杂、遮挡条件下,效果会下降明显,还需要增强图像的多尺度特征提取能力,才能跟上应用所需的精度要求。
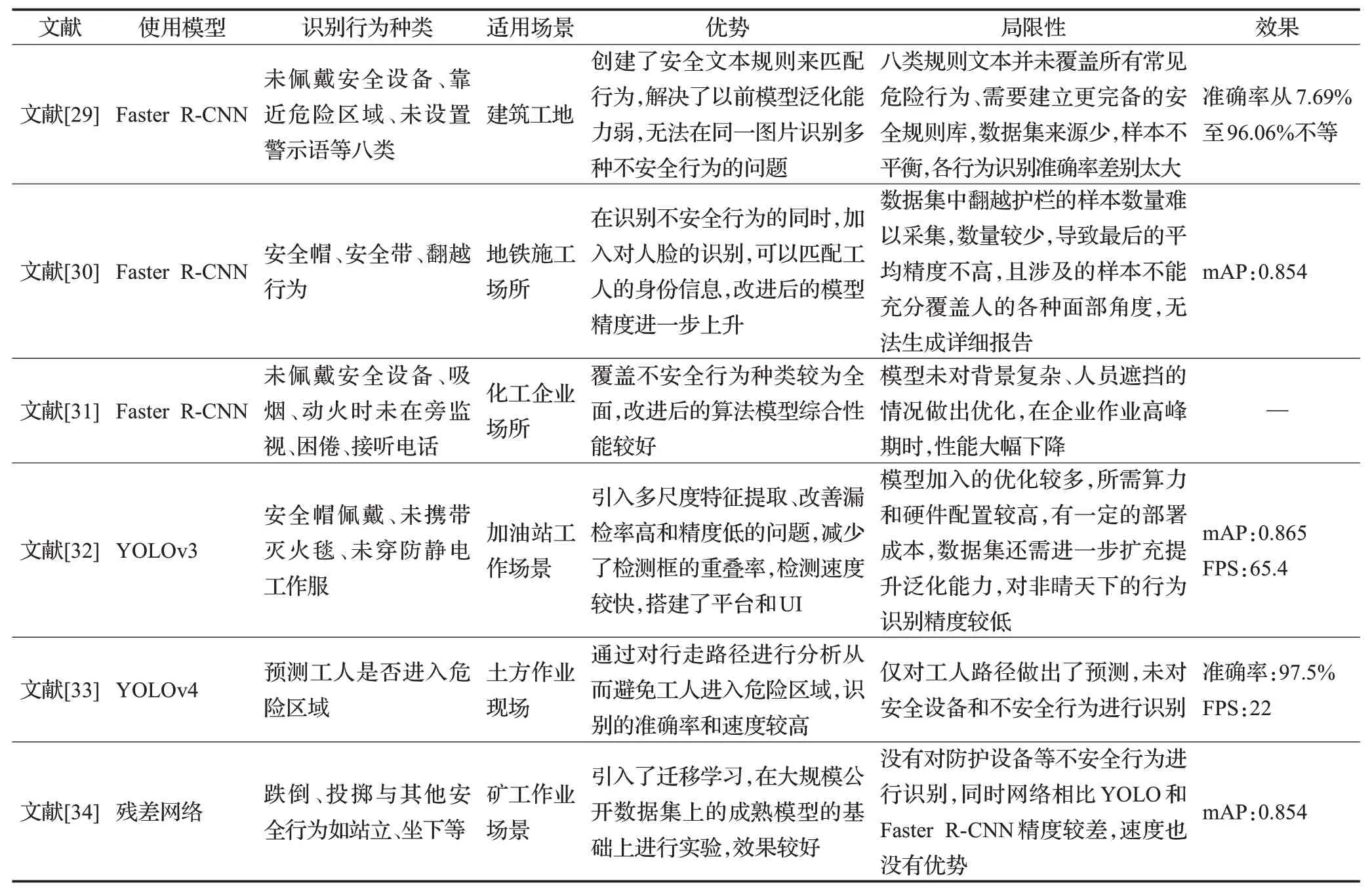
表5 基于目标检测方法的不安全行为识别研究Table 5 Research on unsafe behavior recognition based on target detection methods
1.3.2 基于行为识别方法的应用研究
行为识别模型对具有时间上下文联系特征的动作行为有良好表现,因此在不安全行为识别的研究中,常常用来识别打架、各种器械的操作、身体动作等动态行为。
对基于卷积神经网络的不安全行为识别,张雷等[35]使用门控循环单元(GRU)与CNN结合形成的融合网络对井下工作人员的摘帽子、扔东西、抽烟、跑动、行走、坐下、挥手、睡觉行为进行识别,利用注意力机制的权重分配提升了准确率。实验表明,模型对八种动作识别的平均准确率为97.37%,但模型对于动作相似但节奏不同的动作识别性能较差。
除了提取视频流中的特征,利用人体关键骨骼点形成模型后送入图卷积神经网络学习特征的方法也有很广泛的应用。刘耀等[36]对建筑工人的不安全爬梯行为进行识别研究,包括身体过度倾斜,携带东西,背对梯子,用AlphaPose提取人体骨骼关键点,ST-GCN进行分类识别,达到了98.48%的准确率。较高的准确率表明了基于骨架数据的识别能够更好地克服光照影响。
从上述研究可以看出,基于图卷积神经网络的方法在识别动态行为时有着较高的准确率。但工人被遮挡时,识别效果下降较多,应考虑使用更高级的算法或优化来得到工人被遮挡情况下的三维骨架信息,或采取多个方向的摄像头获取数据,避免某一角度人员密集带来的识别困难问题。
对基于循环神经网络的不安全行为识别,应用最多的是LSTM 网络。Kong 等[37]在研究中使用目标跟踪网络Siammask 追踪施工场地人群,然后利用改进的Social-LSTM 预测人的运动轨迹,实现了在同一画面中追踪多人的效果,对可能出现的碰撞、临边等行为做出预警,但实验并未对安全设备的佩戴等常见行为做出识别。循环神经网络
对基于双流神经网络的不安全行为识别,黄珍珍等[38]提出了一种双流网络,分别使用空洞卷积和自注意力机制来提取特征,后进行融合,对铁路工人的走、跑、上下道以及跌倒进行识别,总体识别率达到了98%。但上道和下道以及走路因动作本身的相似性,易造成误识别,且未对真实情况下的铁路务工人员检测试验。
表6 为近年来其他基于行为识别方法的不安全行为识别研究内容对比[39-42]。从研究来看,行为识别的优势在于准确率较高,但其仍然面临着许多挑战:一是在施工环境下人员背景混乱,遮挡问题严重;二是用于数据的视频图像质量不高,影响识别效果;三是当模型同时处理多目标的定位和动作识别时,由于输入为三维数据,消耗资源较多,工作量很大;四是很多动作本身极为相似,误判概率高,并且缺少对未佩戴安全设备这样的静态行为的识别,因此可以考虑引入目标检测模型为行为识别模型提供效果更好、复杂度更低的人员定位功能。

表6 基于行为识别方法的不安全行为识别研究Table 6 Research on identification of unsafe behaviors based on behavioral recognition methods
1.3.3 基于目标检测和行为识别结合的不安全行为识别方法
为了更全面地识别不安全行为,很多研究者开始使用两种方法结合来研究,即使用目标检测定位工人及检测静态不安全行为,使用行为识别分析动态不安全行为,互相弥补彼此一定的局限性,并且某些行为可以分别用两种方法实现,比如抽烟这一违规动作,既可以用目标检测模型去检测烟头出现在人手中的这一画面,也可以用行为识别来判断是否有将烟拿到嘴边的动作。
对基于二阶段目标检测与行为识别的结合,苏洪超[43]在双流网络的前端引入Faster R-CNN,解决了前者不能在一幅图像中识别多目标的不安全行为问题,进而实现了工人的动静态不安全行为混合识别,输入的视频流一路进入目标检测网络,获取多个目标位置,另一路计算运动历史图像,经过判断动静态情况后送入对应模型进行不安全行为分类,通过引入目标检测方法,解决了同一场景下多目标行为识别问题,实现了多种类的不安全行为识别。但未对模型的速度和精度进行优化,在实际使用中检测速度较慢,需要算力较高,且不支持对双人交互的危险动作识别。
对于性能较强的MaskR-CNN,郁润[44]使用该模型和LSTM网络构建识别方法,其中Mask R-CNN网络负责检测各类实体,如工人、梯子、挖土机等,LSTM 网络负责对工人的行为进行分类。模型选取施工现场两项常见的不安全行为,即在梯子上爬得过高与安全带使用不当来进行检测,实验中发现,对工人、梯子和行走动作的检测精度较高,不足之处在于对安全带的是否佩戴识别效果较差,平均精度为60.4%,这是由于安全带的解挂动作与其他日常动作相似,容易造成误判的效果,并且由于实验所用相机基于红外原理,在室外施工场景使用时存在局限性。
可以看出,Mask R-CNN的优势在于其兼具动静态行为的识别能力,但其特征是从单一视图上提取,特征的多样化程度不够,并且由于较大的网络复杂度,其推理速度和消耗资源不理想,而YOLO系列作为一阶段目标检测模型的优秀代表,在速度与精度上都有良好的表现,可以很方便地与行为识别方法结合应用。
张萌[45]使用改进的YOLOv4为基础,识别建筑工人安全帽和安全带的穿着情况,用ST-GCN识别工人脚手架正常施工、高空探身和攀爬行为,并分别对目标检测和行为识别方法进行了优化,使得检测速度和精度上升,达到动态视频检测的要求,但不足之处在于没有拍摄不利环境下的测试,泛化性有待提高,且对小目标的对象和险态行为的识别精度不高。孟维等[46]使用YOLOv5对人体进行跟踪,用OPENPOSE算法和ST-GCN网络实现人体行为的识别,包括正常行为与摔倒动作,模型部署简单,但未对实际应用中可能出现的各类阻碍因素如光照、粉尘、遮挡等情况做出优化。
近年来,其他基于目标检测和行为识别结合方法的不安全行为识别研究内容对比见表7[47-52],综合上述研究,结合了目标检测的行为识别模型在多人员场景下的定位追踪能力得到了很大的提升,并且能够检测安全设备佩戴问题和多种违规危险动作。但在网络的进一步优化上存在难点,两种方法的输入可能不同,提取的特征种类也有区别,如何协调两方法的内部结构,实现多尺度特征的相互融合以达到更好的效果是挑战性的难题,多种网络的结合也使得训练参数和所需资源变大,若能针对其速度和整体结构进行优化,会在识别种类和性能上成为最优的不安全行为识别方法。
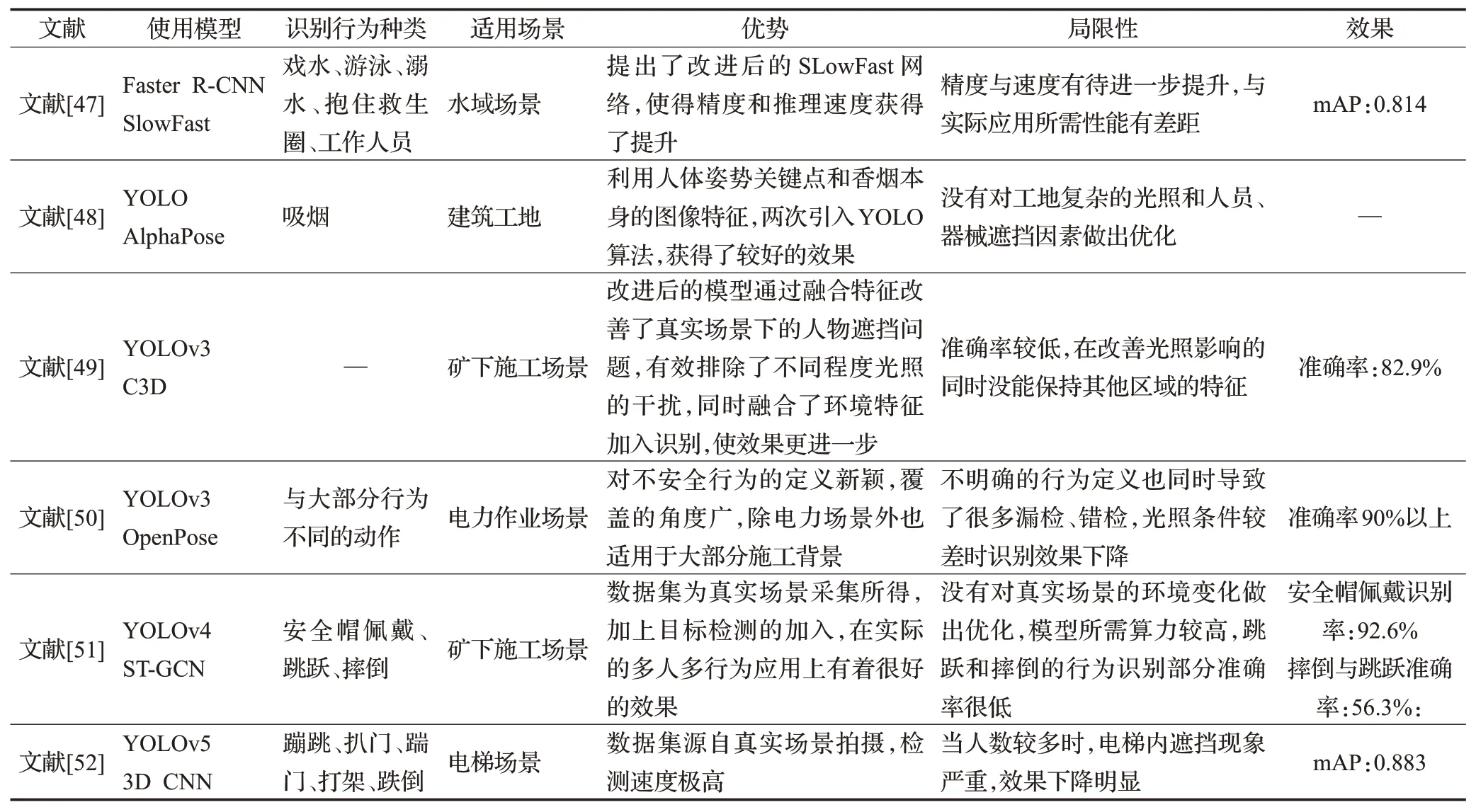
表7 基于目标检测和行为识别结合方法的不安全行为识别研究Table 7 Research on unsafe behavior identification based on combined method of target detection and behavior recognition
2 基于深度学习的不安全行为识别方法优化
2.1 目标检测方法的优化
目标检测方法在不安全行为识别的研究中存在局限性,因其直接学习图片的图像特征,当目标受到环境影响如光照、粉尘,和人员遮挡的情况时,效果会大幅下降,并且许多行为如抽烟、喝酒等,由于香烟和酒瓶目标较小,在实际应用中会经常出现漏检、错检情况,因此许多学者将目光放在了针对特定的研究场景来优化目标检测模型的思路上。
对于二阶段目标检测模型,万子伦[53]针对Faster RCNN 在背景复杂情况下识别效果不佳的问题,制作了一组红外信息数据加入训练,使得模型在昏暗条件下的识别效果上升,并替换了特征提取网络和损失函数,改进单一的RPN识别网络以更好地生成预测框。融合全部改进措施后的模型相比原模型,mAP值提高了11.57%,尽管模型的精度提升明显,但其改进的局限之处是在目标太多的视频样本中FPS下降明显,在光照不好的情况下效果不理想,模型所需的计算次数较多,不利于部署。
对于一阶段目标检测模型,针对复杂背景下模型性能下降的问题,吴海波[54]以YOLO 系列模型为基本框架,提出了一种实力特征预训练方法,构造一个图像拼接模板,将输入图像重新构造为具有复杂背景的图像进行预训练。实验表明采用该方法下的模型所需迭代次数减少为一半,收敛速度也有提升,提升了红外目标的检测精度,解决了小样本下模型训练困难的问题,迭代次数、训练时间都得到了减少,对行人的识别正确率从77.2%提升至88.1%,但其不足之处在于对小目标的检测效果不理想。
另外,源于自然语言处理的Transformer 模型在计算机视觉被证明有着很好的效果,其衍生的模型DETR相比之前的目标检测方法有着更快更好的潜力。王永归[55]基于改进的多尺度单目3D 目标检测模型,提出了DETR 3D 目标检测,引入Transformer 模型获取特征的全局关系,设计了一种显著网络降低模型编码器的计算量,使计算量下降了41.4%。对小目标,背景复杂等常见问题均有良好的表现,但模型不能识别具体车辆类型,精度相较于多视图的检测方法仍有差距,有待继续提升。
综上所述,由于Faster R-CNN 有着更复杂的网络框架,对遮挡和光照不足等问题的鲁棒性较好,因此对其的改进主要是针对检测速度,而YOLO系列的改进策略通常是牺牲小部分的检测速度换取精度的提升。表8为近年来研究目标检测模型优化的方法、优势及其局限性总结[56-64],总体来说,针对目标检测的改进目的为:提升小目标的检测能力,提升背景复杂及遮挡情况下的检测能力或提升模型的运行速度和效率。改进的方法有:压缩模型、引入注意力机制、改进损失函数、改进锚框策略、改进特征的融合策略和数据增强等。

表8 目标检测方法的优化Table 8 Optimization of target detection methods
2.2 行为识别方法的优化
行为识别方法在不安全行为识别研究中的缺点在于网络通常较为复杂,要考虑空间与时间的双重特征,推理速度较慢,所以如何改善行为识别方法的性能成为了一个重要的研究内容。
对于卷积神经网络类型和长短期记忆网络的行为识别方法,金磊[65]针对这类网络时间特征的建模能力不足问题,基于自注意力机制设计了一个时间聚合模块,利用特征间的相关性发掘更多的时间特征,并引入3D ResNet 中改善了其性能,在UCF-101 中达到了91.79%的准确率;同时针对不同行为的动作节奏不同(如跑步和走路),在聚合模块的基础上进一步构建多尺度多样性识别框架,通过不同深度的特征建模多个动作节奏,这一框架在UCF-101 上进一步达到了94.05%的准确率,其缺点在于模型较为冗余,需要大规模的数据库进行预训练,对算力有较高的要求,在未裁剪好的视频和小样本情况下识别效果不佳。对于利用图卷积神经网络的行为识别方法,陈泯融等[66]表示大多基于卷积神经网络的骨架行为识别模型并没有充分获取骨架的隐含的特征。因此在AⅠF-CNN模型的基础上提出了多流融合网络模型MS-CNN,新增了kernel 特征和多运动特征,分别提取几何信息和全局信息,使识别准确率有所提高,但是当人体骨架被遮挡时较难推理出全貌,识别效果下降明显。
从上述优化研究内容来看,卷积神经网络基于其从单一图像上提取特征的特点,模型对相似行为的识别容易出现误判,因此需要增强特征的多样性,更多的特征角度可以更好地保证识别的准确率,但这也意味着更大的网络复杂度。因此,研究人员将目光放在了能够利用人体骨骼关节特征的图卷积神经网络上,增强其节点特征的提取数量和角度,改善相似行为的识别率,但不足在于无法很好地建立遮挡情况下的骨骼模型,在人员密集的场所如生产车间、化工企业等识别效果较差。
对于双流神经网络类型行为识别方法,申军轶[67]选取SlowFast作为待改进网络,在下采样时添加了最大值池化层,使得采样有了依据标准,避免了有效信息的丢失,减少了噪声的出现;同时使用3D-ResNet50 网络提取特征,并对残差块进行了切分,在不提高复杂度情况下提高了学习能力,最后替换了激活函数,提高了模型的准确率,不足之处在于检测速度没有达到实时检测的要求,在人体被遮挡时识别效果下降。
可以看出,双流神经网络优化方向主要是为了改进两路特征的提取能力和融合问题,但双流模型的高复杂度问题无法避免。近年来,Transformer模型被证明在行为识别方面有着很好的表现,其核心的自注意力机制相比传统卷积神经网络等有着网络参数少,性能强的优势。高闻[68]基于Transformer 用四种不同的神经网络层(输入与预处理层、双流编码层、特征聚合层、特征映射与分类层)堆叠搭建模型,其创新之处在于双流编码层相比常规卷积神经网络,参数量大幅减少,训练以及推理速度获得提升,准确率可达96.7%,但模型在面对大规模数据集时效果可能会有所下降,对小目标的识别效果不佳,同时也有着更易于拟合的缺点。
近年来对行为识别模型做出的改进及其局限性总结见表9[69-79],总结可知,行为识别方法优化主要是围绕特征进行,其中卷积神经网络和双流神经网络的优化是为了提升对空间或时间特征的提取能力以及两者的融合效果,而图卷积神经网络的优化通常会改进对人体骨架信息的捕捉能力,加强骨骼节点包含的全局信息,让远距离的节点辅助识别,然而优化后的行为识别方法常常伴随有缺点,即模型变得复杂冗余,计算所需的资源数量上升,训练的时间变长。因此,新兴的基于transformer的注意力模型由于其较低的参数和复杂度有着很大的发挥空间。

表9 行为识别方法的优化Table 9 Optimization of behavioral recognition methods
2.3 不安全行为识别应用中的优化
尽管目前的研究还着重于不安全行为的种类选择和模型方法的搭配,还是有很多研究者针对已经确定的不安全行为对选择的模型进行了各方面的优化尝试,以提升精度或速度。需要注意的是,相似的优化方法,对于不同应用场景和模型的改进效果可能会有很大的差别。根据目前不安全行为识别领域的研究内容,常采用模型轻量化、引入注意力机制或改善网络结构的方法来改进。
2.3.1 模型轻量化
随着目标检测模型不断地更新,在公共数据集上的检测速度和精度纪录不断地被突破,网络的结构和参数也越来越复杂,对于不安全行为识别领域,其模型通常需要部署在边缘设备以被使用,因此需要考虑对已选择的模型进行轻量化处理,在尽可能保证精度的同时降低参数和计算量,以便在计算能力可能不足的边缘设备部署。常见的处理方法有引入轻量化网络结构进行替换,如MobileNet、ShuffleNet、EfficientNet等,这些网络结构通常会采用组卷积等轻量卷积方式代替原有的传统卷积,减少卷积过程的计算量,另一类方法是减少网络本身的参数和复杂度,如利用迁移学习或知识蒸馏等方法来降低训练和推理时间。表10为目前常见的轻量级网络在Cifar10数据集上的性能统计,可以看出,MobileNetv2的精度表现最好,但其他数据较差,综合性能与复杂度来看,ShuffleNetv2 的效果最优。但此结果仅为在Cifar10 数据集上的实验结果,在不同环境和数据下的研究还需实验进行判断。

表10 轻量级网络性能比较Table 10 Comparison of lightweight network performance
屈文谦[80]的研究中就针对YOLOv3 模型进行了此类工作,使用MobileNetV3替换了YOLOv3中的特征提取网络,建立了MoblieNetV3-YOLOv3 模型,替换后网络的效果与替换前对比,检测速度有了极大的提升,从20.48提升为33.94,但是mAP值仅有70.97%,说明轻量化虽然使得参数减少,计算量降低,但是针对不同的数据集和模型很可能会带来不同程度的精度下降,在该文献研究的车辆和安全帽识别问题中尤为明显。然而,文献[81]在使用MobileNetV3 替换了OpenPose 算法中的VGG19 网络前十层后,发现对于摔倒和攀爬两种不安全行为,轻量化后的模型相比原模型不仅速度得到了提升,精确度也提高了6.18%,这可能是由于MobileNetV3中含有SE 注意力模块,对于该问题下的数据集起到了一定程度的精度提升效果,使得轻量化手段在这一问题中达到了精度和速度的双重提升。
综上所述,引入合适的轻量化网络可以较为明显地提升模型速度,但复杂度降低意味着网络上的神经元节点数量减少,深度变浅,在前向推理的过程中网络所承载的信息权重降低,预测所获得的特征表现减弱。因此会对精度产生影响,为应对这样的问题,采取措施对特征进行多角度的强化是关键,增加通道提取特定特征,或在融合区域加入更多尺度信息,这样才能弥补降低复杂度带来的精度损失。
2.3.2 引入注意力机制
人类在观察物体信息时,通常会选择性地集中关注某一点,适当忽略其他的信息,注意力机制正是源于这样的思想,目前常用的注意力机制有SE 注意力模块、CBAM注意力模块、NAM注意力模块等。综合来讲,注意力机制主要贡献两个方面:一是要决定需要关注输入中的哪部分,二是分配计算资源给需要关注的那部分,近些年来各种注意力机制频出,用其提升识别准确率也成为了众多研究人员的选择。
文献[82]使用YOLOv5 进行实验后发现,模型对于焊接等操作行为的检测结果较差,这是因为原始模型的预测结果通常忽略了焊接工具和火花的特征。基于此特点设计了一个特征增强模块以消除大多数无用的特征,最大限度地利用有用特征,即注意力机制,另外还创新性地在目标检测方法中引入时间特征模块,改进后的模型速度有所降低,但仍能达到30 FPS以上,并且mAP值提高了3.8%,其不足之处在于模型对算力有一定要求,推理和检测速度有待进一步提高。
屈文谦[80]的研究中除了轻量化,也引入了SE 注意力机制,在YOLOv3主干网络输出的三个特征层后依次加入SeNet 模块,得到SeNet-YOLOv3 模型。最终使得模型FPS 达到23.45,mAP 值达到95.31%,相比未改进模型精度速度都得到了提高。刘艺超等[83]在不安全行为识别研究中针对YOLOv5引入了CBAM注意力机制,从通道和空间两方面关注特征。实验显示,引入CBAM模块结合对网络结构的优化,使改进后的YOLOv5对小目标的检测效果得到了提升,相比原模型提高了2.7%的检测精度,但未对人员密集和背景嘈杂的情况做出优化,也没有对其他车间常见的作业不规范行为进行识别。
注意力模块因其方便通用的特性,可以加入各个目标检测或行为识别模型中,包括全局注意力、自适应注意力、多层次注意力。从已有的研究改进内容来看,研究者通常会将轻量化和注意力搭配使用来优化模型,一方面用轻量化牺牲一些精度来提高计算速度,另一方面使用注意力结构适当补偿轻量化所带来的精度损失。
2.3.3 网络结构的优化
除上述两个大方向外,还有许多研究人员对于已选择的模型进行了细部的优化尝试,如对损失函数或激活函数进行替换使模型更适合实际数据集的需要,从特征的提取和融合方面改进网络等,经过不断的实验和尝试,都可以提升一定的精度或速度。
余益鸿等[84]针对YOLOv5 进行了网络结构优化的尝试,通过提高网络深度和引入空洞卷积来增大感受野,同时采用增加池化层的方法解决提高深度所增加的大量冗余信息问题。除此之外,还做了在网络中引入残差模块降低特征损失,在不同大小特征图后加入形变卷积融合多尺度特征的工作,最终改进后的YOLOv5模型平均精度相比改进前提升了6%,但模型的缺点是未对安全防护设备进行识别,在人员密集情况下效果下降。
杜俊凤[85]在MASK R-CNN模型中针对临边行为数据的特点,提出了改进锚框的思路,即在模型原始锚框参数的条件下,增加64×64 的锚框尺寸,改善对小目标的检测灵敏度,同时针对防护栏一般为长方形的情况,增加长宽比为3∶1的锚框。同时,引入Bi-FPN代替原模型中的特征金字塔网络,使得该模块可以同时保留自上而下和自下而上的特征采样方法,让高层特征和浅层特征同时得到更好地保留,以增加一定计算量的代价来提高模型的性能,最终改进后的MASK R-CNN平均准确率提高了3.1%,FPS仅降低了0.04,其缺点在于所用数据为RGB图像且为室内拍摄,对光照问题敏感,实际使用时效果会下降,同时场景限于临边场景,泛化能力不足。
表11为近年来的其他优化过的不安全行为识别研究对比[86-90]。综上所述,网络结构的优化涵盖模型各个角落,针对具体数据与问题具有多种方法,包括改进损失函数、优化预测框的定位策略,针对特定数据集选择更合适的激活函数,提升模型的表达能力,与注意力、轻量化相结合,为模型带来各个方面的性能提升。
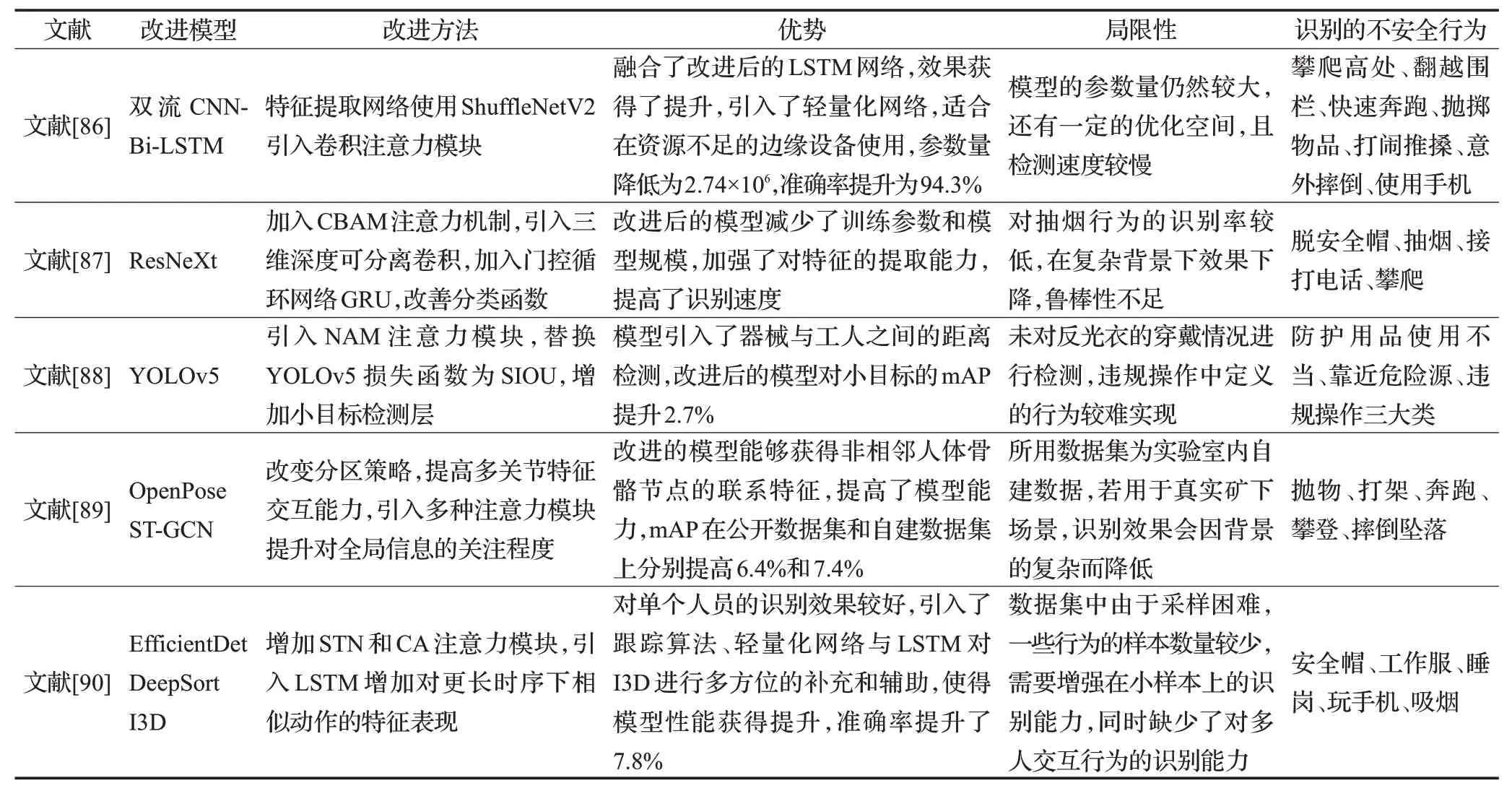
表11 不安全行为识别上的应用优化Table 11 Application optimization on unsafe behavior recognition
3 思考和展望
由于研究中数据集的构建、待检测的场景、对不安全行为的定义等各不相同,并不能简单地评价目标检测和行为识别的方法孰胜孰劣。比如在某高空作业施工场景下,待检测的不安全行为重点放在了安全帽和安全绳的佩戴上,那么显然只使用目标检测模型是更优的选择,也更方便对模型进行优化,若施工场景覆盖面广,待识别不安全行为种类较多,那么结合两种模型可能会有更好的效果。通过分析不安全行为识别的研究现状,给出该领域目前存在的难点与不足:
(1)数据集问题,在不安全行为识别领域,数据集依然面临着种类不全、数量较少的问题,这主要是由于不安全行为的定义没有统一,不同施工场景、不同单位、不同工作人员所需要注意的不安全行为不相同,因此难以出现数量质量双优的公开数据集,研究者需要耗费较大精力寻找、拍摄、制作,才能用于模型训练。目前的数据集情况表现为:部分行为充足、部分行为不足。安全帽、反光衣、口罩等安全设备佩戴的公开数据集数量和质量较高,很容易找到真实施工场景下的正负样本,如在安全帽佩戴领域就有开源数据集SHWD,包括7 581 个不同场景、天气、光照条件、人数、拍摄距离的图像,分为安全帽类和未戴安全帽类,为相关研究提供了支持。同时,也有很多不安全行为存在样本不足的情况,如摔倒、攀爬、打架斗殴、喝酒、翻越栏杆等,这些行为本身的数据数量并不少,但在施工场景下的负样本数据严重缺乏,若采用非施工场景下的数据进行训练,那在真实场景进行预测时,由于复杂的施工环境和光照变化等,效果很可能大打折扣。
综上所述,不安全行为识别研究领域的数据集工作面临一定难点,在各类违规、危险行为的真实施工场景数据上存在空缺,如何在小样本的条件下实现优秀的识别性能是一个难点。
(2)融合多种类不安全行为识别后的性能问题。从目前研究现状来看,针对静态不安全行为的目标检测和针对动态不安全行为的行为识别都各自达到了较高的精度,但当需要同时识别两类不安全行为时,平均精度通常会在90%以下,还有较高的优化空间。
(3)泛化问题。不同于其他目标检测和行为识别的研究领域,工人的不安全行为识别存在着场景多变、行为种类多变和光照角度远近多变的问题,不同工种、施工场景下的不安全行为识别研究都需要针对性的模型、方法和数据集来训练,这就导致后续研究人员很难在变换了场景和模型的情况下,参考前人的相关研究,做出改进和优化。
由于存在以上难点,在此结合目标检测和行为识别的发展,给出未来该领域的研究建议和展望:
(1)对目前的数据集情况而言,研究者可以尝试采用多场地、多角度、多距离的拍摄方法来自建数据集,同时采用数据增强对数据进行一定的模糊、亮度改变等处理,尽可能真实模拟施工场景下的图像,以此获得更好的训练和测试效果。在已有的研究中,研究者受限于条件,多选择在室内模拟场地进行数据集的拍摄构建,在更为复杂的真实场景下识别时就会出现效果下降的问题,如果可以在构建数据集时就利用真实场景建立,一定可以更好地避免此问题。
(2)为了实现更准确的不安全行为识别,可以尝试转变思路来对某些不安全行为获得更高的识别率,比如目标检测通常对远距离工地场景下的抽烟这一行为识别率较低,因为在数据集中只标注香烟的话,目标太小,识别困难,如果连带胳膊抬起这一姿势一同标注,其余胳膊抬起的非抽烟情况也会对预测造成干扰,那么可以尝试使用目标检测检测香烟,加上行为识别去识别“胳膊抬起”这一动作,结合检测抽烟行为,可能会有更好的效果。
(3)为了实现更快速的不安全行为识别,针对边缘设备部署所需要的轻量化研究,可以不局限于减少参数量这一方面,文献[91]指出,各类轻量化网络的工作集中在减少浮点运算数量上,然而这种减少不一定会带来相应的快速,反而可能因为内存访问的增加(轻量化网络所采用的卷积方法导致)而出现负优化。因此为了部署边缘设备,可以从内存访问的减少这一思想入手,达到真正意义上的加速,比如使用文中提出的部分卷积(PConv)和FasterNet轻量网络。
(4)对于未来的工人不安全行为识别研究,会出现基于背景和施工内容的种类划分,即:基于矿洞和隧道等自然背景施工,该分类下识别研究要针对光照和复杂地貌带来的影响做出优化,容易出现与危险区域靠近相关的不安全行为。基于建筑建造的非自然背景施工,该分类下的识别研究要针对灰尘和工程车辆的遮挡影响做出优化,对更多类别的个人防护设备进行识别。基于室内的工厂工人施工等划分,该分类下的识别研究要针对人员密集情况等室内特殊情况做出优化,重点对各种违规操作进行识别。在如此分类下,便可以为相似场景的后续不安全行为识别研究提供更好的参考和改进方向。
