基于XGboost模型的农业供应链金融信用风险测度研究
2024-03-09吕慧如吴凯诗吴宇章
吕慧如, 吴凯诗, 吴宇章
(仲恺农业工程学院经贸学院, 广州 510225)
供应链金融在中国乃至全球都呈现巨大的发展潜力,可有效地解决中小微企业融资难、融资贵、融资慢等问题。[1-2]作为一种创新的融资模式,银行可以实现围绕核心企业,管理上下游中小企业的资金流、物流和信息流,将传统风险管理模式中单个企业的不可控风险转变为供应链企业的整体可控风险。核心企业主导的供应链金融模式的参与主体包括核心企业、金融机构、融资企业。[3]该模式对于解决供应链上下游企业融资难、拓展银行深度业务具有重要意义。近年来,随着中国支持供应链金融发展政策的落实,供应链金融得到了快速发展,拓展了中小企业融资渠道,促进了中小企业的发展。但在其快速发展的过程中,也遭遇着重大的挑战和阻碍,最为突出的便是供应链企业的信用风险问题。因此,研究供应链金融信用风险问题具有十分重要的现实意义。
1 文献综述
在供应链金融发展的重要关口,本文从以下两个角度对供应链金融信用风险评估的研究现状进行梳理和评述。
在供应链金融风险评估指标的选择上,赵忠和李波[4]根据供应链金融信用风险的特点构建了评价指标体系,并运用模糊层次分析法确定了各指标在评价体系中的权重.为银行对供应链金融信用风险的评价提供科学依据。汪小华[5]从不同的角度揭示了农业供应链金融的信用风险特征,完善了农业供应链企业的信用评价体系。郑志远[6]利用主成分分析法从初始指标体系中筛选出对企业信用风险影响较大的五个指标,基于此指标构建了Logistic回归模型。匡海波等[7]综合考虑了全链条面临的整体风险,构建了符合金融界普遍认可的5C原则的指标体系,其判别的正确率高达90.53%,判别效果显著。顾天下等[8]以传统信用评价方法中的5C指标作为指标选取的依据,基于XGBoost特征重要度进行特征筛选,建立供应链金融信用评价指标体系。
在供应链金融风险评估方法上,陈钦等[9]采用41家纺织类企业为实证样本基于Logistic模型进行分析,通过实证研究对供应链金融视角下该行业中小企业的信用风险进行了评估。陈琪和施丽娟[10]结合因子分析构建二元Logistic回归模型对影响农业供应链金融中核心企业信用风险的因素进行分析。逯宇铎和金艳玲[11]用Lasso-logistic模型得出企业的营业利润率、总资产周转率、流动比率对、企业所处的行业状况及供应链的合作关系强度对供应链金融的信用风险有很大的影响。杨军和房姿含[12]证实了Logistic模型在预测农业中小企业信用风险方面的准确性,并得出融资企业偿债和现金流情况、获利能力以及供应链运作情况与其履约概率呈正相关,与银行所承担的信用风险呈负相关。徐勇戈和李冉[13]基于供应链金融信用风险理论,结合房地产企业行业特征,建立Lasso-SVM(support vector machine,支持向量机)模型,用于识别供应链金融中房地产企业的违约风险,为银行信贷融资提供了新的思路。田琨等[14]以汽车制造业中62家上市公式为研究样本,通过因子分析和Logistic回归得出了较高的评估准确率。陈湘州和陶李红[15]建立指标体系并基于多层感知器(multi-layer perceptron,MLP)模型构建了中小企业供应链金融信用风险模型。胡海青等[16]构建了全新的中小企业信用风险评估指标体系,并基于此对比分析了BP(back propagation)神经网络和SVM分类模型,得出后者模型准确率较高,是进行中小企业信用风险评估的较优选择。刘平山和曾梓铭[17],结合医药行业特征构建指标体系,通过与与支持向量机、Logistic回归模型和BP神经网络对比,验证了梯度提升树(gradiennt boosting decision tree,GBDT)模型在供应链金融模式下对于医药行业信用风险评估具有更高的预测准确率和分类真实性。祝由等[18]通过知识图谱技术从大量文献总提取知识进行可视化分析,提出可以运用深度学习方法来提升供应链金融风险评估模型的整体性能。
综上所述,众多学者对供应链金融信用风险的评估开展了多方面研究,其研究领域主要集中在汽车、制造业和医药领域,关于农业领域的研究较少。此外在农业供应链金融信用风险评估上,大多学者仍然采用Logistic模型。近年来,随着信息技术的发展,机器学习算法在信用风险评估方面取得了良好效果。鉴于此,本文构建基于农业行业的信用风险评估体系,并通过对比分析Logistic回归模型和XGboost模型的信用风险评估效果,以进一步完善供应链金融视角下农业企业信用风险评估方面的研究。
2 指标体系和算法模型
2.1 指标体系
当前,供应链金融信用风险测度的指标体系并尚无统一标准,对以往相关文献进行归纳和总结,并结合供应链金融特点和农业行业发展状况,在传统信贷模式信用评级方式的基础上构建农业行业的信用风险指标体系。选取企业基本状况、盈利能力、营运能力、资金周转能力4个一级指标。企业基本情况可以从企业规模、财务披露质量2个二级指标来分析;企业盈利能力可以从每股收益、每股净资产、主营业务利润率、净资产收益率、销售净利率5个二级指标来分析;企业营运能力可以从流动比率、速动比率、产权比率、现金流量比率、资产负债率5个二级指标来分析;企业资金周转能力可以从应收账款周转率、存货周转率、流动资产周转率、总资产周转率4个二级指标来分析。选取的16个指标如表1所示。
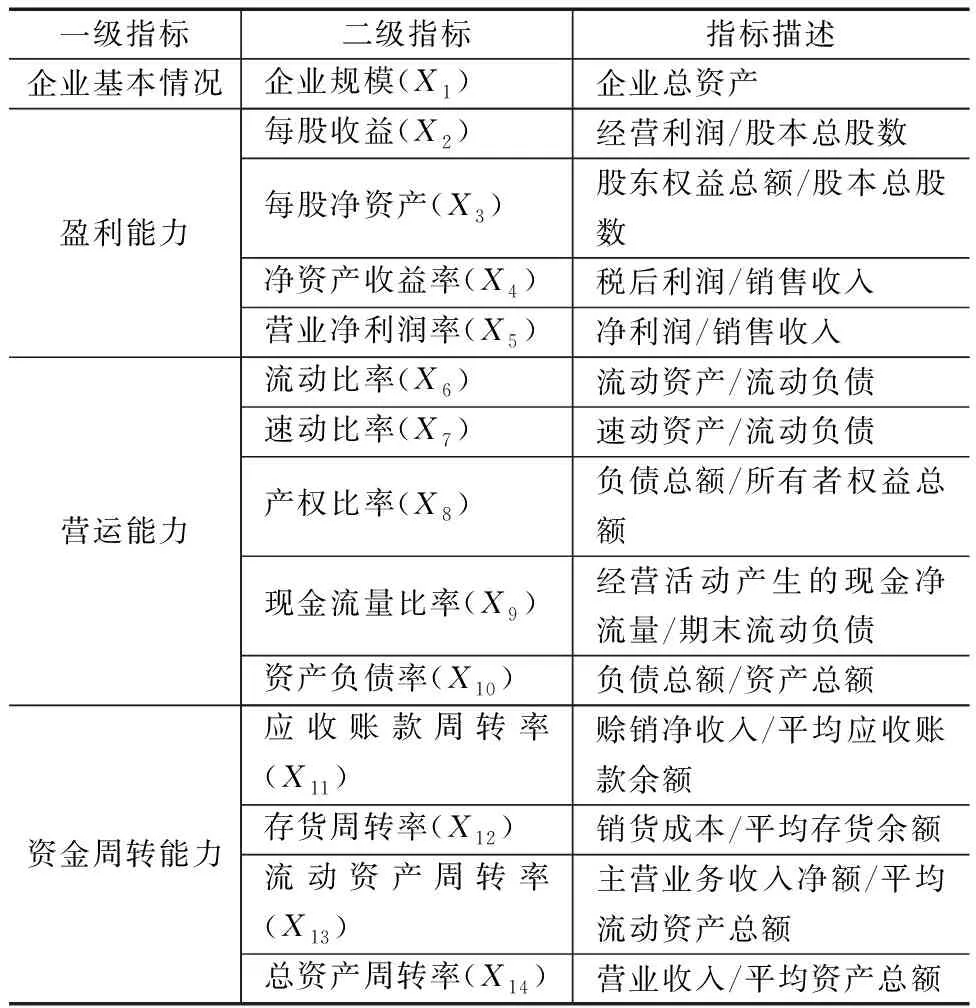
表1 决定企业信用评价的财务因子特征变量
由于初始变量过多,维数较高,存在着模型指标的高相关性和高危型,可能会导致模型过度拟合、参数无效等后果,需要采用因子分析法提出具有主要解释能力的变量,再利用提取出的变量进行实证分析。
2.2 算法说明
2.2.1 Logistic模型
Logistic模型(LR)又称为逻辑回归模型,该模型利用最大似然估计法进行参数估计,是一种广泛应用于分类问题的统计学习方法,其输出值是概率值而非实数。LR模型通过将线性回归模型的输出通过一个非线性函数(称为“逻辑函数”)进行映射,将连续的输出转化为概率值。
(1)
式中:Z=β0+β1x1+β2x2+…+βnxn,为回归模型的输出;β0为常数项,即待估计系数;β1,β2,…,βn为信用风险评价时的影响因子;被解释变量P为企业信用情况,其取值范围为[0,1],且具有单调递增性质。P=0时表示违约,P=1时表示不违约。
2.2.2 XGboost模型
XGBoost(extreme gradient boosting)是一种基于梯度提升树(gradient boosting tree)算法的机器学习模型。由陈天奇博士在2014年提出,是一种boosting型树类算法,能进行多线程并行计算,通过迭代优化的方式去提高模型的预测能力,既把许多性能较低的弱学习器组合提升为一个准确率高的强学习器。
XGBoost具有高效性、预测能力强和可解释性等优势,具体算法步骤如下:
(2)
式中:F为所有回归树的集合;xi为第i个输入样本;yi为经过映射关系fk计算得出的预测值;每个f是树空间F的一棵树,每棵树fk通过一系列的决策节点和叶子节点来构建。此时需要引入目标函数:
Obj(Θ)=L(Θ)+Ω(Θ)
(3)
由式(3)可知,目标函数是由损失函数L(Θ)和正则项Ω(Θ)构成,Ω(Θ)是为了防止过拟合所设置树模型的复杂度,Obj(Θ)的分数越小表示生成的树的结构越好。
(4)
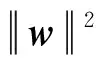
(5)

将目标函数进行泰勒二阶展开可得
(6)
式中:gi、hi分别为一阶和二阶导数。
树的类型确定下来以后需要进行树的分裂,XGBoost采用了一种近似的贪心算法来选择特征子集,遍历所有特征结点,找出最佳分裂结点,以最大限度地减少损失函数。
3 实证分析
3.1 数据来源与因子分析
考虑到研究的时效性,研究期间定为2021—2022年,选取80家上市农业企业为研究对象,剔除9家数据不齐全以及样本不具代表性的公司,剩余71家公司。财务数据均来源于RESSET数据库。参考《企业绩效评价标准值》以及现有针对企业信用风险等级划分的文献,通过企业利息保障倍数来定义企业信用状况正常与否。在142个样本中,正常组为117个,取值为0;非正常组为25个,取值为1。
在做因子分析之前,首先需要检验各变量之间的关联度,判断变量是否适合做因子分析。利用SPSS软件做KMO和Bartlett检验得出表2结果,KMO取值为0~1,KMO越接近于1,说明变量之间的相关性越强,适合进行因子分析,反之则不适合。得出KMO为0.660,说明可以对以上变量进行因子分析。利用最大方差旋转分析法,得到前4个因子的累计方差贡献率为72.883%,表明这4个因子能够较好地反映所有变量信息。因此,选取前4个因子作为初始变量,进行实证分析。

表2 KMO和Bartlett检验
3.2 信用风险评估
3.2.1 Logistic模型的信用风险评估
运用Logistic模型,将上述因子分析得到的4个主因子作为自变量,企业信用风险等级作为因变量进行回归分析,得到回归结果如表3,可得最终筛选出F1、F2、F3和F4这四个变量。
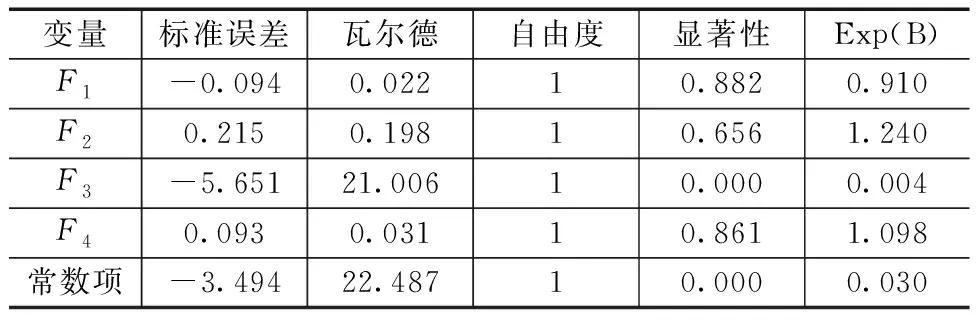
表3 方程中的变量
如表4所示,模型对违约企业判别的准确率为80%;对无违约企业判别的准确率为94.9%,模型的总体评估准确率为92.3%。经进一步计算,Logistic模型的第一类错误率为20%,第二类错误率为5.1%。

表4 Logistic模型分类
3.2.2 XGboost模型的信用风险评估
XGBoost的超参数可以分为三个核心部分,分别是通用参数、Booster参数和任务参数。[12]通用参数与整体功能和行为有关,包括目标函数(objective)、评估指标(eval_metric)等;Booster参数与弱学习器(树)的参数有关,包括树的个数(n_estimators)、学习率(eta)、子样本的比例(subsample)、列采样比例(colsample_bytree)、树的最大深度(max_depth)等;任务参数与特定的学习任务相关,包括回归问题(reg:linear)或二分类问题(binary:logistic)的参数,以及多分类问题(multi:softmax)的参数。对XGboost超参数的具体选择如表5所示。
采用交叉验证网格搜索得到的最优超参数为:eta=0.1,min_child_weight=1,gamma=0.1,max_depth=3,使用该参数组合的XGBoost机器学习模型对训练数据和测试数据进行效果评价,得到的结果如表6所示。
采用AUC、KS、Recall和Accuracy 4个指标衡量模型效果。根据模型预测结果,AUC=0.9,较高的AUC表明模型具有较好的分类性能,可以作为判断企业债务违约风险的参考指标;KS=0.8,KS 统计量是衡量二分类模型预测能力的指标之一,其值越接近于1,表示模型的性能越好;Recall为0.85,较高Recall分数表示模型能够较好地捕捉到真正面临债务违约风险的企业;准确率Accuracy为93%,较高的准确率表明模型有较高的整体分类准确性,即在所有样本中有93%被正确分类。综上所述,XGboost模型在判断企业信用风险方面表现良好。AUC值高表示较好的分类性能,KS值高表示模型具有较好的区分度或鉴别能力,Recall分数高表示模型能够较好地捕捉到正例,而高准确率表明模型整体分类准确性较高。这些指标的组合表明该模型在判别企业信用风险方面是一个有效的工具。
3.2.3 模型评估结果对比
根据上文的实证分析,将Logistic回归模型和XGboost模型进行比较。如表7所示,两个模型的预测效果都很好,Logistic模型的总体预测准确率为92.3%,XGboost模型的总体预测准确率为93%;第一类错误率后者模型稍低于前者模型,这意味着该模型更少地将实际为负例的样本错误地预测为正例;第二类错误率后者模型明显低于前者模型,这表示该模型更少地将实际为正例的样本错误地预测为负例,具有更好的区分能力。
4 结论与展望
以供应链农业企业为研究样本,构建农业供应链金融信用风险评估体系,并分别运用Logistic模型和XGboost模型进行信用风险评估。结果表明,XGboost模型的总体评估准确率比Logistic模型高了5.2%,第二类分类错误率低了6%,证明了在农业供应链金融下XGboost模型的优越性和有效性,为农业供应链金融信用风险评估提供了新方法。
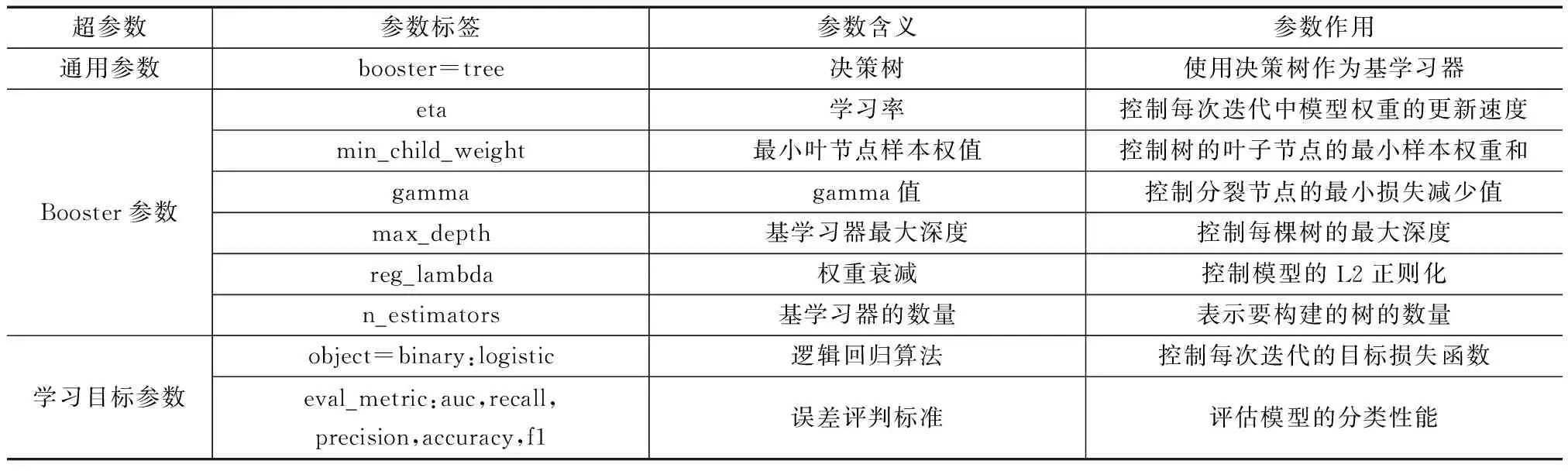
表5 XGBoost的调参参数

表6 XGboost建模精度效果

表7 预测模型效果比较
