基于投资者情绪的创业板股票收益率预测研究
2024-03-09奉静
奉 静
(兰州财经大学统计与数据科学学院, 兰州 730000)
随着中国国民经济的发展和金融市场体系的不断完善,越来越多人选择将余钱进行金融投资而非简单的储蓄。作为金融市场的重要投资工具——股票也逐渐走进人们的视线中。相较于国外成熟的股票投资市场,中国股市中包含大量个人投资者,股票走势受个人投资者行为的影响较大[1]。因此,如何利用已有信息对相关股市运行趋势进行把握并进行相应的交易操作是投资决策者能否从中获利的关键因素。随着互联网的发展投资者获取股票信息的来源也更加丰富。投资者信息来源主要有公司财务报表、新闻媒体报道、投资者评论三个方面。
大量事实表明,投资者情绪会对股票市场产生一定影响。例如,2018年受金融“去杠杆”政策对流动性冲击以及中美贸易关系紧张的影响,投资者对市场信心偏低,A股市场估值全面下跌。2020年受到新冠肺炎疫情影响,全球股市集体大跌,全球经济增长率创第二次世界大战以来最低值,金融恐慌迅速蔓延。但由于中国及时高效地应对疫情,A股市场自我调节功能有效发挥,投资者数量不断增加,首次突破1.6亿,随即成为投资者的避风港[2]。由于中国股票市场中散户数量较多且存在“追涨杀跌”的特性,因此极具主观色彩与时效性的投资者评论在投资者进行交易操作时受到高度关注。
现有研究主要聚焦于投资者情绪与沪深主板市场的关系,对创业板市场的研究较少。创业板又称二板市场,是对主板市场的重要补充,在中国资本市场中占有极其重要的位置。它的设立在推动经济发展、完善中国资本市场层次与结构、带动民间投资、促进产业升级、为成长型创业企业提供资本市场服务等方面具有重要意义。同时创业板“高风险、高回报”的投资风格吸引了更多的个人和私人投资者。因此,研究投资者情绪对创业板市场的影响,有助于创业板股票市场投资者制定更加理性的投资策略,警示上市公司完善自身信息披露制度,完善市场监督部门对创业板市场的交易机制,对推动市场稳定健康发展、丰富中国资本主义市场结构具有重要作用。
通信技术的飞速发展,带来了文本信息的海量增长,使互联网随之成为一个数据量庞大的语料库。互联网已经成为舆论发布、传播、接受的重要渠道。而这些舆论也在一定程度上影响着投资者的行为与市场的发展。目前,国内外已经有很多学者进行了网络舆情对金融市场影响的相关研究。本文主要从文本情感分析方法和投资者情绪的计量方法两方面进行阐述。
目前,在金融领域的文本情感分析方法,根据其使用的方法不同,可以分为三大类。第一类是采用情感词典的文本情感分析方法,根据不同情感词典所提供的情感词的情感极性,来统计待分析文本中包含的正向情感词和负向情感词的数目,通过两者的差值来判断文本的情感极性。现有的使用频率较高的中文词典包括中国知网词库(HowNet)、大连理工大学情感词汇本体库、台湾大学简体中文情感极性词典(NTSUSD)、清华大学开放中文词库(THUOCL)等,这些词典的构成大多基于文献、新闻报道、输入法词库等方面,其构成来源导致了这些词库对“较日常化、口语化”的文本分类效果很好,但对于某些专业性较强的领域文本分类效果较差。很多学者根据所分析的文本所在领域对词典进行扩充。例如,韦婷婷等[3]利用HowNet提供的情感词集加入句法规则对电商评论文本真实数据计算不同评价维度的观点综合得分以分析其情感;王晓丹等[4]在NTUSD的基础上加入股票市场特殊词汇对得到的新闻样本进行情感标注,构建情感指标、舆情指数对上证指数进行分析。以上两篇文章均以一个词典为基础,而王娜等[5]将HowNet与NTSUSD两个词典相结合,构建出初始情感词典语料词库并以此对金融市场进行分析,使得预测准确率大幅提升。吴杰胜和陆奎[6]整合多部情感词典并添加文本句间和句型等语义信息,以提升微博情感分析的效率和准确性。尽管有很多学者不断地对词典法进行改进,使词典法的应用范围更广、实验结果更准确,但截至目前无论该方法如何完善,仍无法突破情感词典的限制,只能编纂词典或者在原有词典基础上进行完善;同时,词典法的情感分析关键在于所用词典的内容而不能联系上下文对文本语义进行分析,使得词典法在进行文本情感分析方面存在一定缺陷。而情感分析的第二类是传统机器学习法,在使用时可以避免词典法所遇到的一些问题,进而对情感分析法进行完善。传统的机器学习法包含有监督学习、半监督学习和无监督学习三类。其中有监督学习应用最为广泛,该方法先对文本进行人工标记,再通过相应的机器学习方法利用给定带有情感极性的样本集进行学习,以对未分类的文本划分类别。常用的有监督机器学习分类算法有朴素贝叶斯[7]、支持向量机[8]、最大熵模型[9]等。传统机器学习方法的运用在一定程度上突破了情感词典对领域的限制,使情感分析实现跨领域,但传统机器学习方法在情感特征提取方面的优势又在一定程度上反映了其在进行情感分析时存在忽略上下文语义的问题。
Hinton和Salakhutdinov[10]正式提出深度学习的概念,深度学习首先在计算机图像等方面取得进展,从21世纪初深度学习开始应用于自然语言处理领域。深度学习在自然语言处理领域的不断发展与完善使之成为情感分析的第三类。随着深度学习在自然语言处理领域的持续应用,其情感分析技术不断更新。随着数据规模的增大,深度学习技术相较于其他情感分析方法的优势不断凸显,但与优势如影而随的是如何妥善处理大规模的数据,尤其在情感分析领域,如何解决大量的文本数据带来的维度问题是深度学习首先应考虑的问题。Bengio等[11]提出利用神经网络通过学习单词的分布式表示来解决维度问题;词袋模型、word2vec工具的应用将上下文语义更好地结合使情感分析得到进一步发展。提及深度学习不可避免的是其各种具备良好性能的神经网络,其中较为著名的循环神经网络(recurrent neural network,RNN)[12]和卷积神经网络(convolutional neural networks,CNN)[13],以及在RNN基础上提出的长短期记忆(long short-term memory,LSTM)[14],这些神经网络的引入使深度学习在自然语言处理领域的分析更加深入;2018年谷歌人工智能研究院提出的基于变压器的双向编码器表示(bidirectional encoder representation form transformers,BERT)预训练模型,具有强大的语言表征和特征提取能力,成为自然语言处理发展史上的里程碑式的模型[15]。各类情感分析方法仍在不断地完善,不同的组合方式、不同的优化算法都会促使情感分析方法进一步发展。
对于投资者情绪的计量方法,国内外学者尚未达成一致观点。通过梳理国内外有关投资者情绪的相关文献,可将投资者情绪的计量方法大致分为三类:第一类为直接计量法,利用市场调查得到的直接调查指标来替代投资者情绪;第二类为间接计量法,采用市场中经济变量作为投资者情绪的代理变量进行间接度量;第三类在大数据与互联网背景下,基于互联网搜索引擎和文本信息挖掘方法对社交媒体中的文本信息进行提取,并构造出适宜的投资者情绪指数,以此来衡量投资者情绪[16]。
投资者情绪的直接计量方法是用通过市场调查得到的直接调查指标来替代投资者情绪,该指数表达了投资者对市场未来发展的预期和认识。常见的投资者情绪指数,一般包括投资者智能指数 (investors intelligence)、美国个体投资者协会指数(American Association of Individual Investors)、央视看盘指数、好淡指数等。投资者情绪的间接计量方法是利用市场中经济变量作为投资者情绪的代理变量。可用于对投资者情绪进行度量的间接指标有很多,目前使用较多的有封闭式基金折价、交易量、共同基金净赎回、IPO发行量及首日收益、波动率指数(volatility index,VIX)等指标。在以单一经济变量度量投资者情绪[17]的基础上,学者们逐渐尝试将经济变量进行整合,建立投资者情绪的综合指标。Wurgler和Baker[18]运用主成分分析法对封闭式基金折价率、首次公开发行股票(initial public offerings,IPO)发行数量、股票市场换手率、分红溢价、IPO首日平均收益率以及股票占融资份额6项指标进行整合分析,得到投资者情绪指标。卢米雪[19]、苗怡霖[20]利用主成分分析法基于新增开户数、成交量、流通市值等指标构建综合投资者情绪指数,并将构建得到的投资者情绪指数引入金融市场进行分析。
随着互联网的不断发展,社交媒体成为舆论发布、传播、接受的重要平台,从社交媒体上获取数据以此来构建市场投资者情绪的方法已被大量学者采用。Afkhami等[21]通过谷歌趋势关键词构建投资者情绪指数,发现了该指数与能源价格波动性的关系。Ranco等[22]从推特上获取信息构建投资者情绪,分析了所构建的指数与股票回报率之间的关系。崔炎炎和刘立新[23]、王晓丹等[4]分别从微博博文和百度搜索指数来衡量投资者情绪,发现投资者情绪从不同方面对股票市场产生影响。除了谷歌、推特、微博、百度,东方财富股吧[24]也被用于挖掘投资者情绪。目前的研究不再局限于判断投资者情绪能否对股票市场进行预测,如何从海量的数据中提取出有价值的信息并将其运用到投资者指数的构建中成为研究的重点。
目前基于投资者情绪对股票市场的研究存在两点不足:首先,现有研究主要聚焦于沪深两个主板市场,对创业板市场的研究较少;其次,国内尚未有通用型词典以对文本信息进行分类,HowNet、NTSUSD等中文词典在金融研究的适用性还存在疑问。
综上所述,研究以创业板为立足点,以创业板股票市场交易的量化指标数据和创业板股票的投资者评论为研究对象,利用词典法对股评进行情感分类,根据分类结果构建投资者情绪指数,探究投资者情绪对创业板股票收益率的预测作用。为提升预测的准确率,本文提出使用粒子群优化的支持向量回归模型,并与其他预测模型进行对比分析。在进行情感分析时选用姚加权等[25]构造的应用于股票论坛的非正式用语情绪词典,该词典解决了现有词典在金融邻域适用性不强的问题。
本文采用PSO-SVM模型并结合情感分析方法对股票收益率进行预测,有助于推动将机器学习和情感分析运用到金融领域的研究进展,为后续情感分析和金融预测研究做好铺垫。从目前研究较少的创业板股票进行分析,丰富了该领域的研究文献;其次,在进行情感分析时采用了目前适用性较高的金融领域非正式词典对文本进行分析;最后将优化算法引入机器学习模型中,提升了预测的准确率。
1 研究方法
1.1 投资者情绪指标的构建
本文以Gabriel等[26]构造的归一化差异情绪指数为基础构建投资者情绪指数。与此不同的是,对归一化差异情绪指数进行对数化处理。具体的计算公式为
(1)
式中:∑pos为第t日包含的股评中情感类别为积极的总情感得分总数;∑neg为第t日包含的股评中情感类别为消极的总情感得分总数;1和-1分别为每条股评的积极、消极情感得分。
1.2 预测方法
1.2.1 多元线性回归模型
采用多元线性回归(multivariable linear regression,MR)模型对股票对数收益率进行预测。多元回归模型是一种在金融领域应用广泛的方法。尽管对非线性关系的解释能力有限,但该模型易于解释,不需要调优超参数。在引入情感指标时估计方程如下:
RETi,t+k=βio+βi1RETi,t+βi2SIi,t+εit+k
(2)
式中:RETi,t+k为第t+k天、第i只股票的对数收益率;SIi,t为第t天、第i只股票的情感指标;βi0、βi1、βi2分别为线性回归模型的系数;εit+k为扰动项;k=1,2,3。
除了传统方法,还使用机器学习方法和加入优化算法的机器学习方法来分析收益率预测。
1.2.2 随机森林模型
Leo Breiman和Adele Cutler发展推导出随机森林算法(random forests,RF)[27]。随机森林是机器学习中最常用也是最强大的监督学习算法之一,包含很多决策树,将多棵决策树进行集成。它既可以解决分类和回归问题,也适用于降维问题,同时解决了决策树泛化能力弱的缺点,具有更好的分类和预测性能。
随机森林回归是随机森林的一个重要分支,基于集成学习(ensemble learning),通过构建多个决策树并将它们的预测结果进行集成来进行回归任务。随机森林的名称中包含两个关键词,一个是“随机”,一个是“森林”。“随机”是指样本选择具有随机性,随机选择特征,即每一棵决策树利用自主抽样法(bootstrap)从训练样本集中随机选取固定数量的样本集与特征集。“森林”是指模型中包含很多棵决策树。为了降低模型过拟合的风险,随机森林中决策树互不关联,独立地随机选择子样本并进行训练,通过并行的方式获得预测结果。将多个决策树的预测结果进行平均或加权平均,从而得到整个森林最终的回归结果。
1.2.3 支持向量回归模型
为了更好地预测创业板股票的收益率,首先选择支持向量回归(support vector regression,SVR)模型作为预测模型。
支持向量机是由Cortes和Vapnik等[28]于1995年提出的,之后随着统计理论的发展,支持向量回归也逐渐受到各领域研究者的关注,在很短的时间就得到广泛的应用。
理论上,SVR模型是一种基于支持向量机的回归方法,作为其分支而被提出。与传统的回归方法不同,SVR采用非线性方式建模,且其计算复杂度不依赖于输入空间的维度,运用非线性映射将原始数据映射到高维数据特征空间中,使得在高维数据特征空间中自变量与因变量有较好的线性回归特征,在高维数据特征空间中进行拟合后再返回原始空间,其目标为在高维特征空间中找到一个最好地拟合数据的超平面。SVR以训练集为对象,通过分析值型输出变量与输入变量数之间的数量关系,最小化预测结果与实际数值的偏差,找到最大的边界回归平面以实现对新观测输出变量值的稳健预测。考虑最小化损失并引入松弛变量后支持向量回归的目标函数与约束条件如下:
(3)
(4)
式中:ω为超平面的系数变量;b为超平面的常数项;N为N个约束条件;Xi为样本观测点;yi为样本观测点对应的输出变量;ε为一个较小的可调参数;ξ*为回归超平面上方样本观测点的松弛变量;ξ为下方样本观测点的松弛变量;C为惩罚系数。
SVR基本思想在于通过寻找最佳拟合线来进行模型拟合,其目标函数在扩大超平面,使尽可能多的点落入超平面的同时考虑了扩大超平面带来的预测误差变化;约束条件则是对训练残差上限进行限定。扩大回归的超平面与减小预测误差无法同时实现,因此支持向量回归希望找到两者之和最小下的回归超平面。此外,支持向量回归具有出色的泛化能力、很高的预测精度。
支持向量机的惩罚系数C和核函数系数g对其回归性能影响很大,这些参数通常需要通过人工进行设定,然而,很难人为预先确定合适的参数值。因此,利用粒子群优化算法[29](particle swarm optimization,PSO)对支持向量回归的参数,以达到较高回归准确率的目的。
2 实证分析
2.1 数据的选择及来源
数据集包括两个部分:来自创业板宁德时代的股票交易数据以及对应的股评文本数据,数据区间为2021年4月20日至2023年4月20日,共487个交易日数据。按照8:2的比例将数据划分为训练集和测试集两个部分。文本数据以相同的方式划分。数据集的具体统计信息如表1所示。

表1 宁德时代股票数据集的统计信息
2.2 数据处理
根据需要获取股票交易的数据和相关的股评文本数据。因此,数据预处理包括对股票交易数据的预处理和对文本数据的预处理两方面。
2.2.1 股票交易数据的预处理
在对股票交易数据进行处理时,首先考虑对创业板股票的选取,根据肖勇[30]的分析结果得到流通市值小的股票更易受到噪声交易者交易行为的冲击。因此,为了降低噪声交易者带来的影响,将创业板中所有股票的流通市值按从大到小进行排序,选取其中流通市值较大的股票,再剔除数据缺失相对严重的股票,将满足条件的股票作为样本股进行研究。选择的创业板股票的具体信息如表2所示。
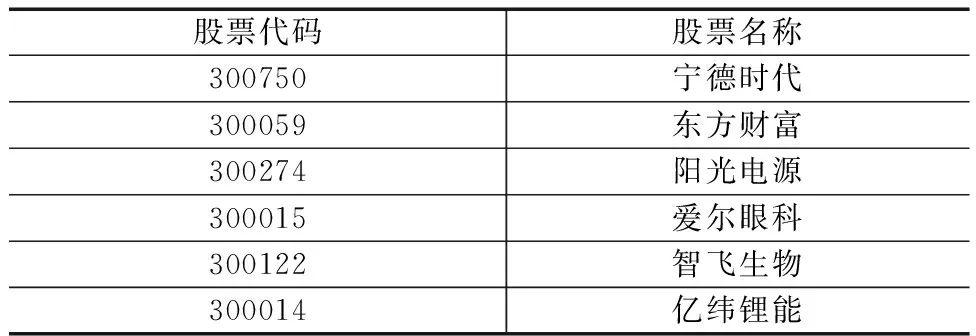
表2 创业板股票
针对创业板市场,从创业板所有股票中选取四只样本股来进行分析。其中基本技术分析数据使用的是四只样本股的每日收盘价,数据来源于Wind数据库。对收集到的收盘价进行对数化处理,得到收益率数据,具体公式如下:
(5)
式中:xt为第t日的股票收盘价;xt-1为第t-1日的股票收盘价;RETt为经过对数化处理后第t日的股票收益率。
2.2.2 文本数据的预处理
采用的文本数据为创业板中流通市值最大的股票——宁德时代的股评,利用Python从东方财富股吧中爬取该股票2021年4月20日至2023年4月20日,共225 986条评论数据。为了对文本进行情感分类和建立相应的情绪指数,采用情感词典的方法。
第一步,爬取文本:使用Python爬取东方财富股吧创业板中宁德时代每条股评的评论内容、阅读量和发帖时间等信息。
第二步,清洗数据:删除重复值和无效符号,最终得到202 333条有效文本数据。将所得文本数据进行分词、去停用词处理,并根据创业板股票市场交易时间,对文本数据进行匹配。具体而言,从上一交易日结束起,直至当前交易日结束为止,其间所有的股评均被划分为当前交易日的股评,与当前交易日的股票表现进行对应。
第三步,补充词典:以姚加权等[19]所构造的应用于股票论坛的非正式用语情绪词典为基础,在一定程度上对词典进行补充。将第二步的分词后得到的结果进行词频统计,按词频统计的结果按从大到小进行排序。根据词频高的分词结果在股票市场的含义划分为积极、中立或者消极类别,再分别加入词典中,补充原有词典。
第四步,文本分类:根据第三步得到的词典对每条股评中不同类型情感词汇出现次数进行统计,以频次反映该条股评的情感差异,分为积极、中立、消极三类,分别用1、0、-1表示。
2.3 评价指标
为了有效地评估预测模型的性能,选取均方根误差(root mean square error,RMSE)、平均绝对误差(mean absolute error,MAE)作为预测效果的评价指标。均方根误差反映的是模型预测值与样本真实值之间的偏差;平均绝对误差用于评估模型预测与样本真实值之间距离,其计算公式是求预测值与真实值之差的绝对值的平均值。
(6)
(7)
2.4 实验结果与分析
实验有以下两大目的:一是评估引入来自股评的投资者情绪能否导致预测模型准确性的显著提高;二是提出的PSO-SVR能否提升预测模型的准确性。因此,首先在仅引入股票交易数据的情况下分别使用MR、RF、SVR及PSO-SVR模型对宁德时代进行预测分析;最后将构造的情绪指标与股票交易数据均作为影响变量引入上述四种模型进行分析。表3显示了投资者情绪变量存在与否对模型结果的影响。
由表3可知,投资者情绪的引入提升了模型整体预测效果。具体分析,提出的四种预测模型中RMSE值和MAE值最小的均为PSO-SVR模型,其值分别为0.019 3、0.014 9。这一结果表明本文所提出的优化模型与三种基础模型相比,其预测效果更好;同时,随着情绪指标的引入,各模型评价指标的值均有所下降,反映构建的情绪指标在一定程度上提高了模型预测的准确性。

表3 宁德时代收益率预测结果
为了更清楚地反映引入情感指标以及使用PSO-SVR预测模型带来的优越性,引入改进率指标(improvement rate,IR)。通过计算IR来量化情感指标以及PSO-SVR模型的额外解释力。具体来说,IR定义为
(8)
(9)
式中:RMSEA为使用A方法进行预测的均方根误差;RMSEB为使用B方法进行预测的均方根误差;IRRMSE为方法B相对于方法A的均方根误差带来的变化。当IRRMSE值为负时,表明用方法B的预测效果优于方法A的预测效果;当IRRMSE值为正时对应相反的情况。
表4给出了引入情绪指标所带来的IR值的变化,以体现情绪指标的引入对预测的影响。同时,分别以MR、RF、SVR模型为基础,探究PSO-SVR相对于基础模型所导致的IR值的变化,具体情况如表5所示。
通过进一步的分析,可以清晰地看到,情感指数的引入提升了股票收益率的整体预测性能。综合表4和表5的数据可得,引入情感指数后各模型的预测效果均得到不同程度提升,其中变化幅度最大的是RF模型,其RMSE和MAE值分别降低了6.10%、9.12%。同时,通过四种模型的对比分析可以发现,情感指数的引入使RMSE和MAE值基本都呈现下降趋势。再一次证明了引入情感指数可以在一定程度上提升模型的预测性能。
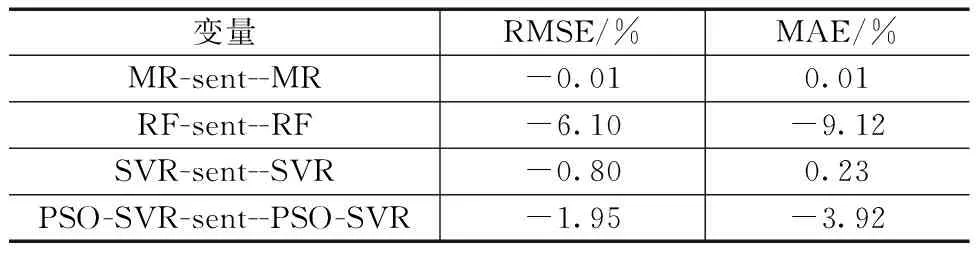
表4 宁德时代情绪指标导致的IR值变化

表5 宁德时代PSO-SVR相对于基础模型导致的IR值变化
探究PSO-SVR模型相对于基础模型所导致的IR值的变化。如表5所示,不引入情感指标时,将PSO-SVR模型分别与MR、RF以及SVR模型进行比较分析,发现PSO-SVR模型与MR模型的IR值的变化最大。而模型间IR值随着比较的顺序逐渐降低,表明在未引入情感指标时,PSO-SVR相较于其他三种模型,其预测性能更好。另一方面,将引入情感指标的PSO-SVR-sent模型分别与MR-sent、RF-sent及SVR-sent模型进行比较分析,可以看到,RMSE和MAE值降低最多的同样是PSO-SVR-sent与MR-sent进行比较的情况。同时模型间改进率指标(IR)随着比较的顺序逐渐降低,表明在引入情感指标时,PSO-SVR-sent相较于其他三种模型,其预测性能更好。结合以上两种情况可知,在影响变量一致的情况下,PSO-SVR模型预测效果明显优于基础模型。模型间预测准确率差异最大的是PSO-SVR模型与MR模型,无论影响变量中是否存在情感指数,PSO-SVR模型的预测准确率相比于MR模型均提升了30%以上。
综合以上分析可以得到,引入情感指标能在一定程度上提升模型预测的准确率,表明投资者情绪在对股票收益率进行预测时起到了积极的作用。另外,提出的粒子群算法优化支持向量回归与本文提出的基础模型相比其预测性能更佳。
3 稳健性分析
为进一步确保研究结果的稳健性,选取创业板市场的三只股票(东方财富、阳光电源及爱尔眼科)进行稳健性分析。各股票的文本数据与股票交易数据时间范围与前文保持一致并对其进行同样的处理。各股票文本数据信息如表6所示。

表6 各股票文本数据信息
抓取三只股票在“东方财富股吧”的股评,构建与上文相同的情感指数,并使用与上文相同的预测模型进行分析,表7给出了对应的收益率预测结果。表8和表9分别展示了引入情绪指标所带来的IR变化,以体现情绪指标的引入对预测的影响,探究PSO-SVR模型相对于基础模型所导致的IR变化,具体情况如表8所示。
由表7可知,股票收益率预测RMSE值最小的都是PSO-SVR_sent模型;而“东方财富”的预测模型中RMSE值最小的是MR-sent模型即加入情感指标的多元回归预测模型,其值为0.030 8;同样,在“阳光电源”和“爱尔眼科”的所有预测模型中预测效果最好的均为PSO-SVR-sent模型,其RMSE值分别为0.028 2和0.017 9。经过以上分析可以发现除了“东方财富”,其余股票的RMSE值最小的都是PSO-SVR-sent模型,这一结果在一定程度上反映了所提出的模型预测效果更好,进一步确保了实证结果的稳健性。在分析“东方财富”的预测模型中效果最好的是MR-sent模型而非PSO-SVR-sent模型时,考虑可能存在的原因是,所选取的文本数据均来自“东方财富股吧”,而该股吧中包含各种股票,因此“东方财富”的股评可能掺杂了其他股民对股吧整体的评价,从而导致“东方财富”股评的噪声过多,使预测结果产生偏差。
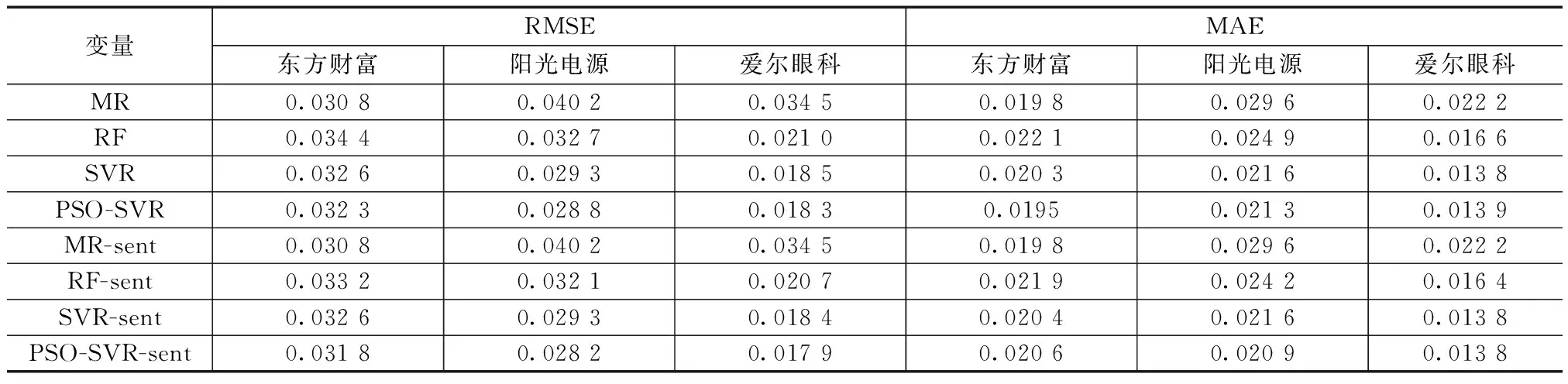
表7 收益率预测结果
通过表8与表9是否引入情感指标和模型之间的比较导致的RMSE和MAE值变化可以得出与上文一致的分析结果。情感指标的引入在一定程度上能提升模型预测的准确率,而提出的PSO-SVR模型与基础模型相比预测性能更好。进一步验证了所构建的预测模型,以及从“东方财富股吧”中提取投资者情绪的稳健性。

表8 情绪指标导致的IR值变化

表9 PSO-SVR相对于基础模型导致的IR值变化
4 结论与展望
从东方财富股吧中提取了表达投资者情绪的股评文本信息,利用词典法将清洗后文本数据进行分类以构造恰当的情感指标,结合所选的样本股的交易数据,探讨了投资者情绪对股票收益率带来的影响,并构建了股票收益率的预测模型。得出以下主要结论:①投资者情绪对样本股的收益率的预测具有重要作用;②与多元回归模型、随机森林模型和支持向量回归模型相比,构造的粒子群算法优化支持向量回归模型在预测效果和模型稳健性上来看均为最佳模型。
综合以上分析,该研究对创业板股票市场投资者制定适宜的投资策略有一定的意义。投资者情绪的引入在一定程度上提升了创业板样本股收益率的预测性能,投资者可以利用股评信息预测创业板股票收益率的变化,从而制定相应的投资策略。最后,通过扩充现有词典来进行情感分类,该法尚不完善,效果也有待提高。此外本文只考虑了来自东方财富股吧的投资者情绪,尽管这个社交媒体平台在投资者中非常受欢迎,但其他来源的投资者情绪的文本信息也可能与创业板股票相关。未来的研究可以考虑使用深度学习提取文本特征,同时增加文本信息的来源,以提升投资者情绪在预测中的作用。
