基于全局互补注意力机制的双目图像超分辨率
2024-03-08鹿存建杨进华
鹿存建,杨进华
(长春理工大学 光电工程学院,长春 130022)
随着双目相机[1]和3D 成像设备的迅速发展,双目图像超分辨率(Binocular Image Super-Resolution,BISR)在计算机视觉领域引起了广泛的关注。BISR 旨在从一对低分辨率(Low Resolution,LR)图像恢复高分辨率(High Resolution,HR)图像。传统方法通常针对左视图和右视图分别进行单目图像超分辨率(Single Image Super-Resolution,SISR)处理。近年来,深度学习领域[2]取得了巨大的进展,其中开创性的工作之一的SRCNN(Super-Resolution Convolutional Neural Network)[3],仅通过三层卷积神经网络就超越了传统方法。随后的SISR 方法采用先进的卷积神经网络(Convolutional Neural Networks,CNN)来提升超分辨率(Super-Resolution,SR)性能。最近,Liang等人[4]基于Swin-transformer 提出了一种图像恢复方法SwinIR,在SISR 领域实现了最先进的性能。然而,将双目图像作为两个单独的输入并不能充分利用跨视图的信息。相比于仅利用单个视图内的上下文信息,BISR 能够利用跨视图信息,从而获得更多的纹理细节。Jeon 等人[5]提出了StereoSR 方法,通过联合训练两个级联子网络来学习视差先验,并通过串联具有不同视差定义的左视图和右视图堆叠来整合跨视图信息。Wang 等人[6]引入了视差注意力机制,有效捕捉了大视差变化下的对应信息,从而改善超分辨率性能。Dai 等人[7]在统一的框架中提出SSRDE-FNet 同时处理双目图像超分辨率和视差估计,并以相互促进的方式交互两个任务。此外,Chu 等人[8]设计了一种基于NAFNet 的骨干网络NAFSSR,并引入了立体交叉注意模块(Stereo Cross Attention Module,SCAM)作为视差融合块。
尽管新提出的BISR 方法在性能方面取得了较大的提升,但对于视图内和视图间信息的学习仍有所欠缺。视图内信息方面,单目视图内的上下文信息是SR 的基础,目前的特征提取方法对于提取关注块的特征相对单一,影响了重建结果的效果。视图间信息方面,跨视图信息是BISR 区别于SISR 的关键,现有的交叉模块通常按照横向极线方向进行视差匹配,忽略了数据集标定引起的纵向误差,同时对视图间相似的图案和纹理缺乏关注。
为了解决上述问题,本文提出了一种基于全局互补注意力的BISR 网络GCAN(Global Complementary Attention Networks),该网络在特征提取阶段能够获取更多的高频信息,改善视图内信息的学习。在交叉提取阶段,充分利用视图间的全局信息,对沿横向极线方向的特征进行互补,从而提高双目图像超分辨率的性能。具体而言,本文设计了多注意力提取模块MAEM(Multi-Attention Extraction Module),该模块能够充分探索特征在空间和通道维度上的相关性,提取更多的信息和内容,以便为下一步的图像重建提供更完善的特征。同时,还设计了全局互补注意力模块GCAM(Global Complementary Attention Module),用于捕获来自两个不同视图的不同空间层次的特征,并利用全局细节来补充局部细节。GCAN 方法在几个基准公共数据集上优于iPASSR[6]等BISR 方法。
1 本文网络结构
1.1 网络结构
本节将详细介绍基于全局互补注意力机制的双目图像超分辨率网络的结构。该网络结构如图1 所示,由特征提取模块(Feature Extraction Module,FEM)、跨视图交互特征融合模块(Cross-View Module,CVM)和超分辨率重建模块(Reconstruction Module,RM)组成。
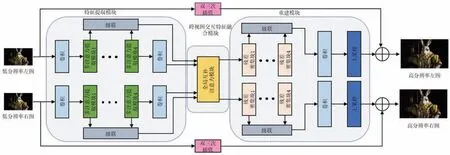
图1 全局互补注意力网络结构
给定、和、作为本文网络的输入和输出。特征提取模块分为浅层特征提取(Shallow Features Extraction,SFE)和深层特征提取(Deep Features Extraction,DFE)。浅层特征提取主要通过一个卷积层来提取LR 输入图像的低频信息:
其中,HSFE(·) 表示一个卷积核为3 × 3 的卷积操作。
其中,F0为左右视图的浅层特征;,,…,表示由多注意力提取模块MAEM 提取的深度特征;HCat(·) 表示级联操作;HConv(·) 表示一个卷积核为1 × 1 的卷积层。最后将所得到的特征送到全局互补注意力模块GCAM 进行交叉视图信息提取:
在重建模块中,经过GCAM 进行视图间的交叉信息提取后,与特征提取模块不同的是,网络采用四个级联的残差密集块(Residual Dense Block,RDB)作为重建模块的基本块。同时利用亚像素卷积(Pixel Shuffle,PS)进行上采样操作,并将双三次上采样(Bicubic Upsampling,BU)的结果作为补充:
1.2 多注意力提取模块
MAEM 由多个重复的多注意力提取块(Multi-Attention Extraction Block,MAEB)组成,用于增强特征的表示能力,构成深度特征提取的基础组成部分如图2 上方所示。单个MAEM 可以表示为:

图2 多注意力提取模块结构图
其中,F0为浅层提取特征或上一层MAEM 的输出结果。网络中引入了跳过连接,以在训练过程中绕过丰富的低频信息,同时充分利用低分辨率(LR)输入和中间特征的丰富信息。
多注意提取块MAEB 的结构如图2 左下所示。在Hu 等人[9]的工作中,注意力模块在网络结构设计中起到了关键作用,一方面告诉网络需要关注的特征,另一方面改善感兴趣特征的表示能力,将注意力集中在更有信息量的特征上,抑制不必要的特征。为了进一步提高网络的区分学习能力,受RCAN(Residual Channel Attention Network)[10]和CBAM(Convolutional Block Attention Module)[11]的启发,设计了一种同时利用空间特征和通道特征相关性的注意力模块。
通道注意力模块(Channel Attention Module,CAM)是一种用于利用特征通道之间关系的注意力机制。与空间注意力模块关注特征的空间内关系不同,通道注意力模块旨在利用特征的通道间关系。通道注意力图的计算过程中,首先通过对特征F∈RH×W×C平均池化来聚合特征的空间信息,生成通道向量FC∈R1×1×C。然后将通道特征FC作为输入来估计通道注意力图,该过程使用一个缩减比率r来减少通道数,缩减后为R1×1×C/r,可以减少计算量、模型复杂度与参数开销的同时,保留了关键的通道信息。最后得到通道注意力图MC∈R1×1×C。
空间注意力模块(Spatial Attention Module,SAM)是一种利用特征的空间关系来生成空间注意力图的方法。其主要目标是确定更具有信息性的空间位置。实现过程中,模块需要利用上下文信息来确定强调的空间位置,并且较大的感受野有助于提取更多的上下文信息。本文使用扩张卷积来增加接受场的大小。采用残差结构可以减少参数量并促进网络训练。
具体而言,输入特征F∈RH×W×C通过投影到具有1 × 1 卷积的较低维度RH×W×C/r中,该特征表示具有较小的通道数。在进行通道压缩后,本文使用两个3 × 3 的扩张卷积来有效获取上下文信息。最后,将这些特征投影到空间注意力图RH×W×1中,进行1 × 1 卷积操作,得到最终的空间注意力图MS∈RH×W×1。
给定第m个MAEM 的中间特征图F∈RH×W×C作为输入,MAEB 依次推导出通道注意力图MC∈R1×1×C和空间注意力图MS∈RH×W×1,MAEB可以表示为:
其中,Res(·)代表残差块;⊗表示逐元素乘法;F′0代表上一模块的输出结果。图2 中展示了通道注意模块(CAM)和空间注意模块(SAM)的计算顺序,在后文消融实验章节中将对这一设计选择进行详细说明。
1.3 全局互补注意力模块
现有的双目图像超分辨率方法主要依赖于沿着极线的左视图和右视图之间的局部特征对应,这将丢失双目图像中的全局信息,来自交叉视图的全局上下文信息也可以用于增强双目图像的超分辨率质量,如图3(a)红色标注所示。为了充分利用视图间的信息,本文提出了全局互补注意力模块(GCAM)并探索沿着极线和全局背景下其他信息的相关性。GCAM 的设计旨在同时考虑全局和局部特征,实现视图间信息的充分交互和融合,如图3(b)蓝色标注所示。

图3 视图间融合方法
本文改进了沿着极线方向的方法iPASSR[6]来进行左右视图特征的融合,如图4 左侧所示。该方法有助于在双目图像中对应的局部特征进行匹配和对齐。受到非局部注意力[12]的启发,进一步从左右视角的相似区域和纹理出发,对沿极线的单一性进行全局信息的互相补充,如图4 右侧所示。

图4 全局互补注意力模块
给定经过深度提取后的特征F∈RH×W×C,首先在极线方向进行纠正,以确保左右视图在横向极线上进行匹配。通过层归一化、残差块和1 × 1 卷积层进行预处理,得到特征F′Left∈RW×C、F′Right∈RC×W。值得注意的是,在这一步中省略了纵向维度,并进行了预处理,可以避免训练过程中可能出现的冲突。然后,通过矩阵运算就可以得到指导左图的视差注意力图:
其中,MR→L∈RW×W表示右视图与左视图沿着极线的相似性矩阵。类似地,可以对相似性矩阵进行转置得到ML→R∈RW×W。
同时采用iPASSR 的遮挡方案(Occlusion Scheme,OS)VL和VR来规避左右视图的遮挡问题,则极线方向的纠正结果为:
其次,为了充分利用来自交叉视图图像的全局上下文特征,并寻找相似的纹理和细节来对左视图进行补充,网络引入了全局互补注意力机制。该机制能够有效地建立长距离的依赖关系,并提供对非局部块的简化处理,以降低模型的计算复杂度。具体而言,该机制将特征FRight∈RH×W×C通过一个1 × 1 卷积层投影到较低维度的特征空间R(H×W)×1×1上,并对该特征进行归一化softmax 操作,得到特征的自相关矩阵。该自相关矩阵捕捉了特征之间的相互关系和相似性。
然而,直接利用自相关矩阵可能导致嵌入过多来自横向视图图像的无关信息,而限制了性能的提升。除了跨极线的对应关系外,图像的某些部分可能与目标区域共享相似的纹理,但是交叉视图图像中的大多数其他部分对该区域的超分辨率并没有贡献。因此,为了消除那些与目标位置具有较低相似性的特征,以提高模型的准确性,本文引入了一个掩码来过滤掉交叉视图中低相似度的特征:
其中掩码的值只有0 和1,如果值大于阈值,则将其设置为1,否则设置为0,本文按照经验将阈值设为0.01。通过使用掩码进行特征过滤,能够提高模型对关键特征的关注度,改善双目图像超分辨率的性能。
通过将掩码应用于自相关矩阵和特征向量FLeft∈RH×W×C,进行矩阵运算,可以得到右图对左图有用的互补信息。为了提高模型的泛化能力,本文在两个1 × 1 卷积层之间添加了层归一化层作为正则化器,以有利于模型的训练和推广能力。通过上述操作得到了包含跨视图全局信息的全局互补特征,最终获得交叉提取特征:
1.4 损失函数
根据Wang 等人[6]设计,采用了以下损失函数来帮助网络充分利用左右图像之间的对应关系。网络的总体损失函数定义为:
其中,LSR、分别表示SR 损耗、剩余光度损耗、剩余循环损耗、平滑度损耗和剩余立体一致性损耗。λ表示正则化项的权重,在本文中设置为0.1。
2 实验结果与分析
2.1 实验设置
为了进行公平比较,并与先前的工作保持一致,本文采用了与Wang 等人[6]相同的数据集。具体而言,使用了60 张Middlebury 图像和800 张来自Flickr1024 数据集的图像作为训练数据集。对于来自Middlebury 数据集的图像,对其进行了2 倍的双三次下采样,以生成与Flickr1024 数据集的空间分辨率匹配的高分辨率地面真实图像。对860 张HR 图像进行了2 倍和4 倍的双三次下采样生成低分辨率LR 图像,并以20 的步幅裁剪30×90 的块作为输入样本。本文所提出的网络使用Pytorch 框架实现,并在NVIDIA GeForce RTX 3070ti 8g 内存上运行。所有的模型都使用Adam 优化器进行训练,其中β1= 0.9 和β2= 0.999。批量大小设置为16,初始学习率设置为2 × 10-4,并且学习率每30 个Epochs 减少一半。训练过程在80 个Epochs 后结束。
本研究选择多样性景物、灵活的视差变化和可比较的景深作为测试集的重要条件来评估超分辨率的结果。从不同数据集中选取了测试图像,包括来自KITTI2012 的20 张图像、KITTI2015的20 张图像、Middlebury 的5 张图像以及Flickr 1024 的112 张图像。为了进行公平比较,本文按照先前的方法计算了左视图的峰值信噪比(Peak Signal-to-Noise Ratio,PSNR)和结构相似度(Structural Similarity Index Measure,SSIM)指标。计算过程中,裁剪了左边界的64 像素,并且这些度量在RGB 颜色空间上计算。此外,本文报告了未进行任何边界裁剪的双目图像对的平均PSNR 和SSIM 指标(Left + Right)/2,用于全面评估重建的双目超分辨率图像的质量
2.2 定量分析
本文与几种先进方法进行比较,包括四种单图像超分辨率方法(VDSR、EDSR、RDN 和RCAN)以及五种双目图像超分辨率方法(StereoSR、PASSRnet、SRResNet+SAM、IMSSRne和iPASSR)。为了公平比较,本研究在相同数据集上进行重新训练。
表1 列出了不同方法在2 倍和4 倍尺度上的参数量与PSNR/SSIM 结果,黑体为最优结果,下划线为次优结果。显然,本文方法在所有数据集和上采样因子上取得了最佳结果。以Middlebury测试集裁剪的左图为例,在2 倍尺度下,PSNR 和SSIM 分别比最优方法高出0.34 dB 和0.002 2 dB;在4 倍尺度下,PSNR 和SSIM 分别比最优方法高出0.04 dB 和0.002 2 dB。结果表明,本文所提出的方法能够有效增强立体图像的细节和清晰度,并在多个尺度上取得较好性能。

表1 缩放因子为2/4 时在基准测试集下的PSNR/SSIM 指标对比
2.3 定性分析
图5~8 展示了本文方法与EDSR、RDN、RCAN、StereoSR、PASSRnet、iPASSR 等方法在2 倍和4 倍尺度下的视觉效果可视化图片。图5 中本文算法能够恢复Attentional 文字的具体纹理,其他算法无法捕获相应的信息。图6 中本文算法重建出的车牌照更贴近于真实图片,在线条细节方面优于其他算法。图7 中其他算法重建的摩托车灯模糊或明显变形,而本文算法还原了更多的边缘细节并呈现出清晰度,接近真实图像。图8 中其他算法重建的车轮纹理信息丢失严重,而本文算法获得了更好的视觉效果。可视化结果直观地展示了本文算法在图像细节和边缘恢复方面的优势,证明了其在提高图像质量和视觉效果方面的重要作用,进一步验证了本文方法的有效性。

图5 Flickr1024 在2 倍尺度上的可视化图片

图6 KITTI2015 在2 倍尺度上的可视化图片

图7 Middlebury 在4 倍尺度上的可视化图片

图8 KITTI2012 在4 倍尺度上的可视化图片
2.4 消融实验
本节用消融实验验证所提出方法的有效性。在测试数据集KITTI2012 上进行了4 倍尺度的对比实验,并仅计算了裁剪左图的结果。实验结果如表2 所示。
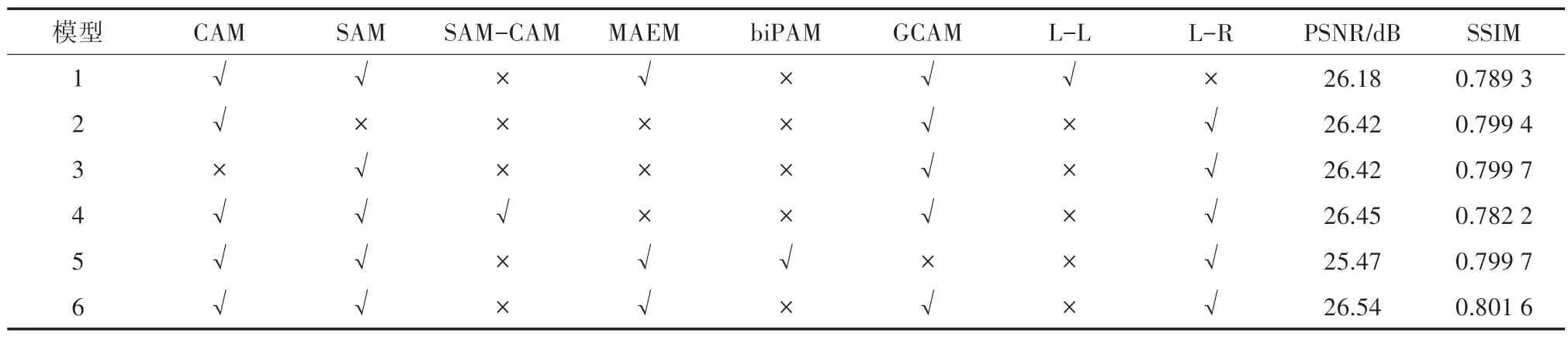
表2 各模块在数据集KITTI2012 上的消融实验
为了验证双目图像相较于单目图像能够提供更多信息,使用两张相同的左图和双目图像进行比较。模型6 相较于模型1 在PSNR 值上提高了0.36 dB,证明了双目图像能够提供比单目图像更多的信息。模型2、模型3 和模型4 分别比模型6 的PSNR 值降低了0.12 dB、0.12 dB 和0.09 dB,证明了模块选择和计算顺序的合理性。模型5 采用iPASSR 的biPAM 作为交叉提取模块,其PSNR 值比模型6 降低了0.07 dB,证明了全局互补注意力模块进行交叉提取的优越性。消融实验结果,进一步验证了本文所提方法的有效性和模块设计的合理性。
3 结论
本文提出了一种基于全局互补注意力机制的双目图像超分辨率网络,并设计了多注意力提取模块和全局互补注意力模块。通过消融实验证明,本文所提出的模块对网络的性能有明显的增益。在峰值信噪比和结构相似度两个客观评价指标上都获得了提高,2 倍尺度上,未裁剪双目图像的平均结构相似度在Middlebury、KITTI2012、KITTI2015 和Flickr1024 等基准数据集上比iPASSR 等双目方法分别提高了0.004 7、0.002 4、0.003 2 和0.005 8。实验结果表明,本文所提出的网络在双目图像超分辨率任务中实现了优秀的重建效果。
