基于PSO-SVM 的带钢表面缺陷检测
2024-03-08朱嘉骏李英唐志勇
朱嘉骏,李英,唐志勇
(长春理工大学 光电工程学院,长春 130022)
钢铁产业广泛应用于工程器械、交通运输工具、建筑机械、农业机械和其他支柱产业当中,其质量直接影响最终产品的质量和性能[1-2]。但由于生产环境的因素,带钢表面不可避免地存在各种类型的缺陷,从而引发产品的质量问题。例如在汽车制造业中,表面含有缺陷的带钢会严重影响汽车大梁的质量;存在裂纹的带钢可能会引起钢铁的崩坏;斑块、夹杂等表面缺陷也将导致“掉粉”而影响产品的外观,同时还会影响产品的耐磨性、腐蚀性和疲劳强度,这可能导致巨大的经济损失[3]。因此,对表面缺陷进行实时准确检测是一个必要的环节。然而传统的人工视觉检测方法准确率低、实时性差、可信度低等多种缺点,不能满足工业表面缺陷检测精度要求。
随着机器视觉技术的快速发展,如何合理地应用视觉技术来实现带钢表面缺陷高效率检测是一个值得研究的问题。为了实现带钢表面缺陷的有效、快速、鲁棒检测,国内外学者对基于机器视觉技术的表面缺陷检测做了许多研究。Song 等人[4]利用相邻评估完成的局部二进制模式与支持向量机结合的方法完成带钢表面缺陷的识别,然而大量的计算降低了缺陷检测的速度。Chaudhari[5]采用随机森林分类器对灰度特征与纹理特征进行分析,这种方法缺少了对缺陷形状特征的分析,对于特征的选取范围不够广泛,而且单一的分类器已经不够满足现今对于带钢表面缺陷检测的精度要求。
除了传统机器视觉方法,深度学习模型在近几年也逐渐受到重视。Lin 等人[6]结合缺陷可见性、可见性分布和过度曝光的综合评估评分来缩短训练时长,但其评分与精度的关系并没有一个清晰的定义,且适用对象也有局限性。刘浩翰等人[7]利用YoloV3 模型对金属表面缺陷进行检测,但YoloV3 的损失函数设计欠缺考虑中心点和长度的整体性。王冬[8]基于深度残差网络,分析了两种不同的残差块结构,对图像数据集进行分类,但深度残差网络中有大量的冗余信息,且感受野的有效深度不够。虽然深度学习能够自动提取和筛选特征,但是大量的实验样本不仅需要巨大实验成本而且会使得计算时间更长[9-10]。
针对上述问题,本文在NEU 表面缺陷数据库的基础上,为了能够快速、准确地检测带钢表面的缺陷,采用传统机器视觉方法,同时结合粒子群优化算法,将其应用于表面缺陷检测当中,能够利用小样本且准确、快速地对缺陷实现分类。
1 表面缺陷检测系统结构
基于机器视觉的表面缺陷检测方法逐渐成为现今工业中的主流方法,广泛应用于各种领域当中。
图1 显示了表面缺陷自动检测系统的结构[11],其硬件主要由照明设备、工业相机图像处理计算机和服务器组成。CCD 摄像机水平布置在带钢生产线上,保证水平方向和垂直方向的视觉范围。借助照明系统,可以清晰、完整地拍摄带钢表面的缺陷。最后,通过光纤传输将缺陷图传输到计算机进行图像处理和模式识别。该系统具有非接触、高精度、低成本、自动化等优点,在工业生产中得到了广泛的应用。

图1 带钢表面缺陷检测系统示意图
缺陷检测过程如图2 所示。在本实验中,图像采集系统的硬件由照明和摄像机组成。LED有良好的照明,有助于减少噪音、阴影和反射,从而提高后续特征提取的准确性。摄像机采用CCD(电荷耦合器件)摄像机,水平布置,可以清晰地获得缺陷图像。为了节省计算时间,采样图像设置为200 像素×200 像素。对于采集到的原始图像,需要进行对比度拉伸、去噪、阈值分割,为后续缺陷图像特征的提取做准备。

图2 表面缺陷检测过程示意图
特征提取是表面检测系统的重要组成部分,是对图像缺陷进行量化的过程。为了保证缺陷的快速准确识别,本文选取了形状特征、纹理特征、灰度特征共15 个维度,在保证缺陷准确识别的前提下减少了数据量。
最后,将量化后的特征放入支持向量机中进行学习。当使用支持向量机时,需要一个分类器将类标签附加到提取的特征上。目前,缺陷特征分类的方法多种多样,包括支持向量机、贝叶斯网络、最近邻分类器、深度学习等。但是,上述方法的准确性还有待提高,或者需要的数据量太大。因此,本文提出在基本支持向量机基础上加入粒子群优化算法,提高最终缺陷分类的准确率。
2 图像预处理流程
传统机器视觉需要对缺陷图像进行预处理,为后续特征提取打下基础。如图3 所示,首先利用分段线性灰度级变化的方法对不同区段的灰度值进行不同程度的修正,接着采用双边滤波的方法对图像去噪,然后利用OTSU 阈值分割方法对缺陷图像进行分割,提取缺陷的形状特征、纹理特征以及灰度特征等,最后利用粒子群优化算法优化的支持向量机对缺陷进行分类。

图3 整体思路
2.1 分段线性灰度级变化
带钢表面缺陷种类繁多,针对亮缺陷与暗缺陷的区别,背景对其缺陷特征的影响也不同并且光照不均的金属表面也会使得图像呈现出明暗相间的背景,给金属表面缺陷检测带来较大的干扰,因此本文选择三段式线性拉伸对灰度值进行修正,其公式如下:
当a>c时,低灰度的范围会压缩,灰度值降低,且b<d时,高灰度的范围会压缩,但灰度值增大,整幅图像低灰度更低,高灰度更高,对比度增强;当a<c时,低灰度的范围会拉伸,灰度值增大,且b>d时,高灰度的范围会拉伸,但灰度值降低,整幅图低灰度提升,高灰度降低,对比度降低。随着参数a、b、c、d的不同,每段灰度的变化都不一样,所以,可以根据实际需要灵活设置参数,以实现不同的变换效果。
2.2 双边滤波去噪
双边滤波同时考虑领域内像素的空间邻近性及灰度相似性进行局部加权平均,在消除噪声的同时保留边缘[12]。设输入图像为公式(1)中结果F(x,y),滤波输出图像为g(x,y),双边滤波公式如下:
其中,(x,y)是当前处理点;(i,j)是(x,y)领域内的点;ω(x,y,i,j) 是加权系数。综合考虑了相邻两点的距离和像素差值,如公式(3)所示:
其中,σd和σr分别为空间邻近度和灰度邻近度。由上述公式可知,与高斯滤波相比,在边缘附近,距离较远的像素对应的加权系数第一项取值很小,不会太多影响到边缘上的像素值,这样就可以起到保护边缘的效果。
2.3 基于OTSU 法的图像分割
经过拉伸与滤波后的缺陷图像需要将其缺陷与背景进行分割,本文利用OTSU 阈值分割法通过计算类间方差的最大值来获取最佳分割阈值,是一种自适应的阈值分割方法,相较于其他方法具有简单、稳定、快速的特点。
设灰度级为L,则灰度范围为[0,L-1],其最佳阈值公式如下:
式中,t为最佳分割阈值;pO(t)为目标区域;μO(t)为目标均值;pB(t) 为背景区域;μB(t) 为背景均值;μ为总体灰度均值。经过预处理后的缺陷图像效果如图4~9 所示。

图4 划痕图像分割结果

图6 裂纹图像分割结果

图7 斑块图像分割结果

图8 轧制氧化皮图像分割结果

图9 夹杂图像分割结果
图4~9 为划痕、点蚀表面、划痕、斑块、滚入比例尺和夹杂物。划痕和斑块大多是单个缺陷,而点蚀面、裂纹、轧制氧化物和夹杂物图像缺陷很多。因此,本文也引入了连通域的概念。其中,划痕为光亮缺陷,点蚀表面、裂纹、斑块、轧制氧化皮、夹杂均为暗缺陷,需要对暗缺陷进行反向二进制运算,以便后期提取缺陷特征。
3 缺陷图像特征提取
对特征缺陷进行分类需要对特征缺陷进行量化提取。本文针对带钢表面轧制氧化皮、斑块、裂纹、点蚀表面、夹杂和划痕六种缺陷进行分类,将对预处理后的图像提取其形状特征、灰度特征以及纹理特征,结合三者进行缺陷特征信息提取,以此来保证缺陷信息的完整,提高后期PSO-SVM 模型的准确度。
3.1 形状特征
形状特征是图像的基本特征,图像的几何描述比较直观和简单,但是在缺陷分类问题中起着十分重要的作用。本文对二值化图像提取的形状特征主要为面积、外接矩形面积、周长、矩形度、圆度以及连通域。其中连通域表示一张图像里同类型缺陷所分成不同区域的数量。在统计斑块、划痕、夹杂三种缺陷时统计每一个连通域的属性,而当处理氧化皮、裂纹、点蚀表面三种缺陷时对所有连通域的属性进行平均化处理,取其平均值。
(1)面积Area 反映了缺陷区域的大小,统计属于该区域内的像素个数为:
其中,u( )x,y表示需要统计的像素点的灰度值,二值化图像的灰度值只有0 或者1。
(2)最小外接矩形面积AMER,统计各个连通域的最小外接矩形面积为:
其中,u(x)与u(y)分别代表最小外接矩形的宽度与长度。
(3)边界周长P通过计算边界上的像素得到,其中像用数字1 表示:
(4)矩形度R通常用面积与其最小外接矩形的面积之比来描述,即:
其中,Area 是该区域的面积;AMER表示该区域的最小外接矩形面积。R的值在0~1 之间,当物体为矩形时,R取最大值1。
(5)圆度描述区域呈现圆形的程度,通常用面积与周长的平方比值来衡量,即:
其中,A为区域的面积;P为区域边界的周长。当区域为0 时,F=1;当区域为其他形状时,F<1,区域越偏离圆,F值越小。
3.2 纹理特征
不同于灰度、形状特征,纹理特征反映一个区域中像素灰度级空间分布的属性。灰度共生矩阵法对图像中所有像素进行统计调查的方法来描述图中的灰度分布。设某一个像素点灰度级为m,另一点为n,它们之间的距离为(Δx,Δy),两种灰度在整个图像中出现的概率可以表示为:
其中,m、n=0,1,2,…,N-1,N表示灰度级的数量;x,y=0,1,2,…,L-1,(x,y)是图像坐标;λ表示相邻的像素数量;φ表示相邻的方向。灰度共生矩阵(GLCM)其实就是所有像素可能的组合。本文采用GLCM 法提取缺陷图像的角二阶矩、相关性、对比度、倒数差分矩四个特征值。
(1)角二阶矩也称能量,用来度量图像平滑度:
(2)相关系数反应了图像纹理的一致性:
(3)对比度代表若图像亮度值变化越快,则对比度也会越大,则:
(4)倒数差分矩反应了图像中局部灰度相关性:
3.3 灰度特征
灰度特征反映了图像中缺陷部分的信息,不同的缺陷反映出不同的灰度特征。图像的灰度特征与灰度直方图有关,灰度直方图表达了图像中某一级灰度值像素数与总像素数的关系。公式表示为:
式中,P(ak) 表示第k级出现的概率;G表示图像像素的总数;ak是第k级的灰度值;Nk表示灰度为ak的像素数量。
本文通过灰度直方图提取缺陷图像均值、方差、歪斜度、峰态、能量共计五种特征值。
(1)平均值:
(2)方差:
(3)歪斜度:
(4)峰态:
(5)能量:
4 PSO-SVM 缺陷检测模型
4.1 PSO-SVM 基本原理
目前缺陷检测的方法有与神经网络相关的深度学习、机器学习等,但是大多数的方法需要大量的样本支持,这也会导致计算时间的大幅提升。支持向量机在分析小样本、非线性和高纬数模式下的问题时有很大优势。
支持向量机的主要思想是建立一个分类超平面作为决策曲面,使得正例和反例之间的隔离边缘被最大化。在实际应用当中,SVM 的性能主要依赖惩罚因子c、核函数K(x,xi)以及参数的选择。选取适当的核函数以及参数后,SVM 需要构造并求解最优化问题:
粒子群优化算法是一种基于群体智能的演化计算技术,与遗传算法(GA)相比,PSO 没有选择、交叉、变异的操作,而是通过粒子在解空间追随最优的坐标进行搜索。
假设在D维空间中,粒子的数量为n,则第i个粒子的位置xi和速度vi分别为:
粒子个体经历最优位置pbest 与种群最优位置gbest 分别为:
当个体最优位置pbesti比种群最优位置gbest更为优异时,对后者进行更新。对于任意维度d(1≤d≤D)的粒子的位置与速度均限制在[-xmax,d,xmax,d]与[-vmax,d,vmax,d]内,如果在寻优过程中超过了限制范围,则将其设置为边界值。由此,粒子的速度与位置更新公式如下:
其中,V为粒子的速度;c1和c2是学习因子;rand(0,1)为[0,1]之间的随机数;x为粒子位置;pbestid为个体粒子最优位置;gbestd为全局最优粒子位置。
4.2 PSO-SVM 分类识别模型
建立PSO-SVM 的带钢表面缺陷模型的步骤如下:
(1)选定训练样本和测试样本。本文选取了56 张划痕、60 张斑块、34 张夹杂、42 张点蚀表面、43 张裂纹、65 张轧制氧化皮,共计300 张缺陷图。将其中30%作为训练集,其余70%作为测试集,每种缺陷由15 维向量构成,对应15 种缺陷特征。
(2)选取合适的核函数。表1 是4 种核函数的分类能力。从表中可以看出,RBF 核函数的准确率最高,且RBF 核函数所需要设置的参数相较于其他核函数要少,且更适用于PSO 算法中,因此本文选择使用RGB 核函数。

表1 不同核函数的分类性能对比
RGB 核函数:
(3)在确定RGB 核函数后,为了提高SVM 模型的准确率,采用PSO 算法对其进行参数优化。PSO 算法的主要目的是找到最佳惩罚因子c以及参数g,其参数寻优过程如图10 所示。

图10 PSO-SVM 整体流程
①设置并初始化PSO 中基础参数,并设置惩罚因子c以及参数g的取值范围。
②计算适应度函数。
③经过适应度定标更新个体和群体的极值。
④判断是否超出最大迭代步数,若未超出,则更新公式中的粒子速度和位置坐标并返回步骤③。
⑤若满足终止条件,返回最佳参数,完成最终SVM 模型。
(4)将数据放入最终训练的SVM 模型中进行缺陷分类测试,并得到带钢表面缺陷的最终分类结果。
5 实验结果与分析
5.1 数据处理
本文采用NEU 表面缺陷数据库,选取包括六种缺陷共计300 张图片,其像素大小都为200×200,而实验样本为464 个,因为例如划痕、斑块缺陷图像中可能含有若干个大型独立连通域,因此将其记录为多个实验样本。其中30%数据用来训练PSO-SVM,剩余70% 作为实验分析样本。通过Matlab 软件进行实验。图4~9 中所示6 种缺陷特征的15 个特征向量如表2~4 所示,其中夹杂缺陷图中选取最大缺陷表征。
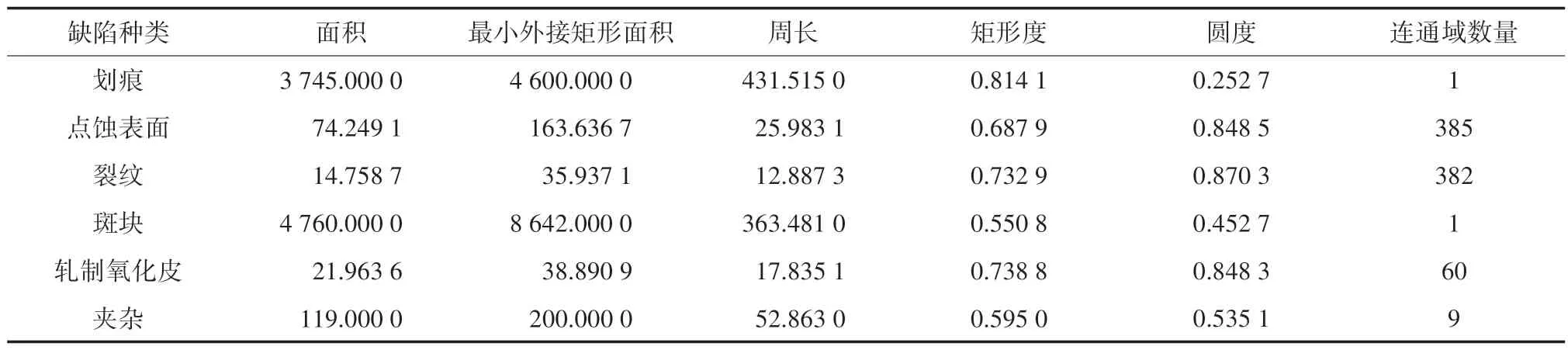
表2 形状特征
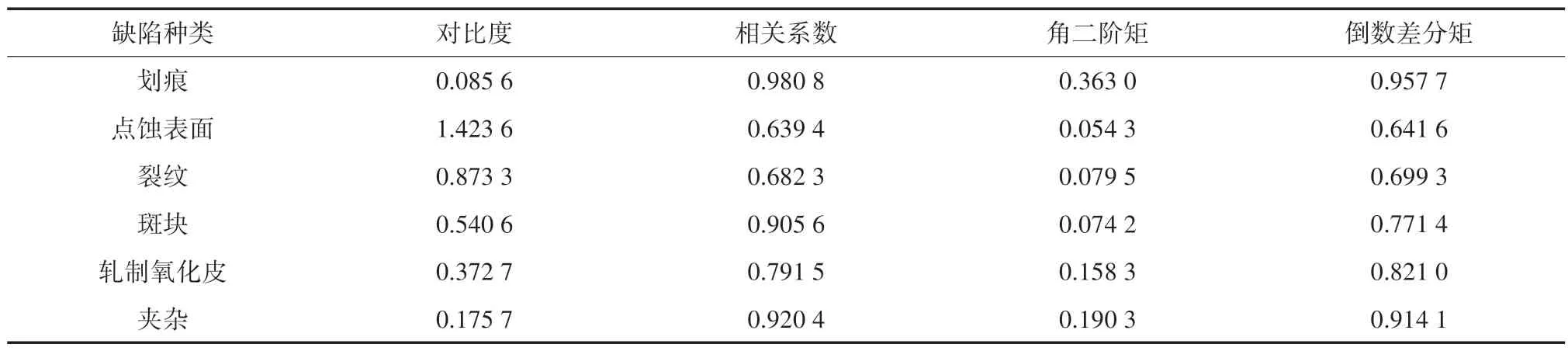
表3 纹理特征
表2 表示了图4~9 中六种缺陷的形状特征,其中包括面积、最小外接矩形面积、周长、矩形度、圆度、连通域数。表3 表示了图4~9 中六种缺陷的纹理特征,其中包括对比度、相关系数、角二阶矩、倒数差分矩。表4 表示了图4~9 中六种缺陷的灰度特征,其中包括平均值、方差、歪斜度、峰态、能量。

表4 灰度特征
5.2 PSO 对SVM 的参数寻优
PSO 初始化为一群随机粒子,在每一次迭代中,粒子会跟踪两个极值并且根据公式(27)更新自己的速度和位置。其中学习因子c1和c2之和一般不超过4,本文设置c1=1.5,c2=1.7,种群数量pop 设置为20,最大进化代数设置为200,c的搜索范围设置为0.1~100,g的搜索范围设置为0.01~1 000,将CV 意义下的准确率作为PSO 中的适应度函数值,以此循环迭代求得最佳惩罚因子c以及参数g,寻优结果如图11 所示,整体趋势趋于稳定,说明PSO-SVM 算法能够有效地优化模型参数,能够得到一个较好的适应度值。

图11 适应度曲线
经过200 次的迭代得出的最优解为c=100,g=1.362 2。该模型的测试集分类结果如图12 所示,分类准确率为99.07%,测试样本中仅有3 个错误,良好的实验结果验证了该支持向量机具有较强的学习能力以及使用价值。

图12 测试集分类结果
为了进一步确定PSO-SVM 模型的分类能力,本文将传统支持向量机、基于网格搜索寻优方法的GS-SVM、基于粒子群算法优化的PSOSVM 以及基于遗传算法参数寻优的GA-SVM 四者进行比较,结果如图13 所示。

图13 四种支持向量机对六种缺陷的识别准确率
如图13 所示,划痕、点蚀表面、裂纹、斑块、轧制氧化皮和夹杂六种缺陷,共300 个实验样本。由图可知四种模型对于划痕、轧制氧化皮、夹杂三种缺陷的识别准确率是一样的,但从另外三种缺陷可知,相对于GS-SVM、GA-SVM,PSO-SVM 的准确率更高。
6 结论
在本研究中,提出了对缺陷图像进行预处理再提取其形状特征,并且加入了连通域概念,可以有效的对含有大量相似缺陷与独立整块缺陷的图像进行区分,能够更好地对缺陷进行分类。通过提取形状特征、纹理特征以及灰度特征共计15 维特征参数,利用结合粒子群优化算法的支持向量机对缺陷图像进行识别分类,结果表明PSO-SVM 模型可以有效识别表面缺陷并将性能提升了12%,且相对于深度学习,本文方法成本低,只需要少量样本进行训练即可实现高精度的识别模型,具体如下:
(1)本文建立了小样本带钢表面缺陷检测模型,首先利用分段线性灰度级变换、双边滤波、OSTU 阈值分割法对图像进行预处理。接着提取预处理后图像的形状特征、纹理特征、灰度特征等15 个特征参数,并选择加入粒子群优化算法(PSO)对原本的支持向量机(SVM)进行性能优化。
(2)通过对线性、多项式、RBF、Sigmoid 4 种核函数的对比,选取RGB 核函数建立SVM 模型。通过PSO 算法得出的最优解c=100,g=1.362 2。将SVM 模型重新训练后,将准确率提升了12%。
(3)通过将传统SVM 模型、GS-SVM 模型、GA-SVM 模型、PSO-SVM 模型的分类结果进行对比可以发现,PSO-SVM 模型的准确率更高,稳定性更好,表明该模型具有一定优势与一定实际应用价值。
