基于视觉传感器采集光流特征的精神疾病识别方法*
2024-03-06陈锐霆徐瑞吉应灵康金润辉毛科技赵永标
陈锐霆,徐瑞吉,应灵康,金润辉,毛科技,赵永标
(1.浙江工业大学计算机科学与技术学院,浙江 杭州 310014;2.杭州惠嘉信息科技有限公司,浙江 杭州 311121;3.浙江工业大学之江学院,浙江 绍兴 312030)
随着现代生活节奏加快,人们感受到来自方方面面的压力。压力的积累导致各种各样的心理健康问题,最后发展到精神疾病。这些精神疾病危害着人们的身心,严重时甚至导致患者做出威胁个人或他人生命安全的行为[1]。世界卫生组织最新报告显示2021 年底全球约13%的人群拥有不同程度的精神疾病问题,每年用于治疗和预防的花费就高达万亿美元,给个人、家庭和社会都造成了巨大的负担和影响[2]。
精神疾病的检测识别一直是一个复杂且耗时的任务。要判定一个人是否正在遭受精神疾病的困扰,不仅需要具备专业的知识、基本掌握个人信息,还需要将目标人群放在一个时间跨度之下观察才能临床确诊。很多拥有轻度精神疾病的人往往无法意识到自己精神状态的异常,也不会主动透露自身情况或寻求治疗,这导致精神疾病的筛查面临巨大的现实困难[3]。
视觉传感器可以准确地获得人的面部表情、手势、姿态、以及头部运动等信息。研究表明,人的面部表情占情感信息量的55%,而声音特征和语义特征分别占情感信息量的38%和7%[4]。因此利用视觉传感器采集面部变化进行精神疾病评估是非常有效的方法。
除了数据采集之外,基于视觉传感器的精神疾病识别方法能为精神疾病的辅助筛查提供了一种成本低廉、便捷、非侵入性的方式。相比传统的临床访谈和问卷评估,采用视觉传感器可以直接采集患者在日常生活中的行为、表情等数据,无需人工干预,因此能够更加客观地反映患者的真实状态。
基于上述分析,本文提出了一个基于视觉传感器采集光流特征的精神疾病识别框架。该算法根据视觉传感器的特点设计了一种光流特征提取方法,能够捕捉患者面部表情变化丰富的局部特征,也能组合局部特征以维持面部拓扑结构的变化,不丢失全局特征信息。算法中使用适用于光流变化特征的网络TSMOSNet 进行训练,从而构建了一个高准确率和鲁棒性的精神疾病识别算法模型。该模型参数体积小,推理速度快,可以与视觉传感器进行整合,开发出一系列精神疾病预警系统,及时监测患者的行为变化,发现异常情况,并及时采取相应的干预措施。这为精神疾病的预防和治疗提供了新的思路和方法。
1 基于视觉传感器的精神疾病识别
1.1 视觉传感器采集
由于通过视觉传感器采集而来的患者视频时间跨度大,且包括房屋背景等无用信息,需要对原始视频做预处理,构建出面部序列单元。本算法中通过HOG 特征描述算子从采集视频中按每帧提取出患者的面部图片。提取到的患者面部图片通过仿射变化进行矫正对齐,并统一图片大小到128×128,以标准化面部图片的分辨率。
其中,仿射变换是一种线性变换,能够保持平行线的平行性和长度的比例不变。它由旋转、缩放、错切和平移四种基本变换组成,可以表示为矩阵乘法的形式,如式(1)所示:
式中:(x,y)是像素点变换前的坐标,(x′,y′)是像素点变换后的坐标,a11和a21分别表示图像在x方向和y方向的缩放因子,a12和a22表示图像在x方向和y方向的错切因子,t1和t2表示图像在x方向和y方向的平移量。
由于精神疾病患者并不会一直正对视觉传感器。偏转角度小的患者面部可以通过仿射变化进行矫正,但是存在偏转角度大,且有物体遮挡等干扰的患者面部图片。对于这些低质量的图片,通过OpenFace[5]中的人脸检测算法,定义置信度来进行清洗。
当置信度设置得比较高时,视觉传感器能采集到的符合要求的面部图片数量会变少,丢失掉一些可用的特征。反之当置信度取到较低值,会存在大量受到污染的面部图片,影响整体方法的效果。对于置信度的设置,通过对比试验,最后设置的置信度阈值为0.95。
因为患者的面部图片是一个时序变化的图片序列,通过对采集到的数据进行分析,发现低置信度的面部图片都是连续的。为了保持时序性,使用低置信度面部图片前出现的最后一张正常面部图片作为填充,而不是直接删除低置信度的面部图片。
最后可以得到有效且高质量的患者面部图片序列,即本文算法中定义的面部序列单元。本节方法流程如图1 中的视觉传感器视频采集模块所示。
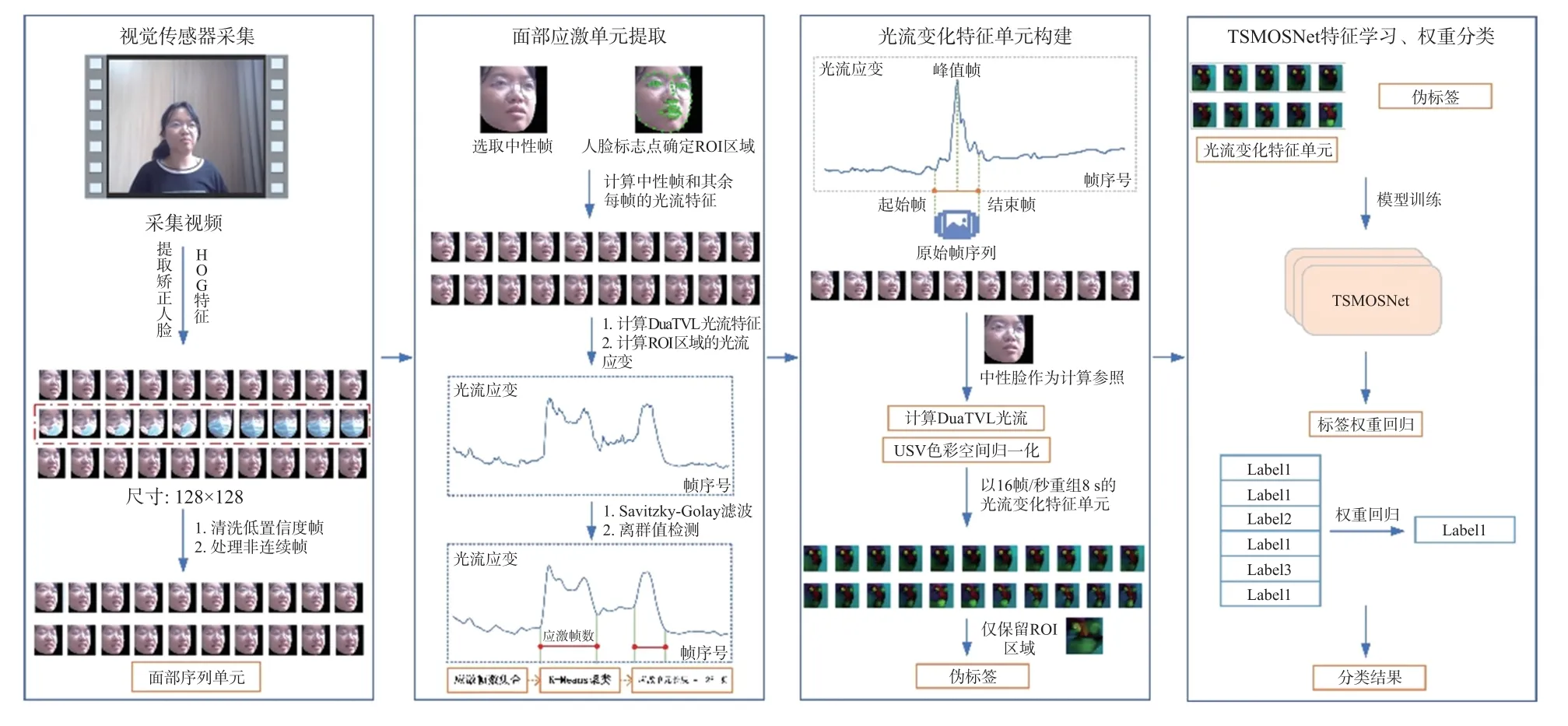
图1 本文的整体算法框架
1.2 面部应激单元提取
精神疾病患者的面部表情变化会被一些特定的内容所激发。其有效特征往往分散在采集而来的视频片段之中。此外,因为采集而来的视频时间不定,直接输入模型训练,存在时序跨度大、干扰信息多、有效特征难以定位等问题。所以,在本文的算法框架中,需要对1.1 节中提取到的面部序列单元进一步处理,提取出受到激发的患者面部图片序列,即面部应激单元。
受到相关研究的启发,光流特征在表情变化分析中能够提取出有效的时空运动信息[6-7]。本算法在患者的面部序列单元中选定一张患者自然状态下的面部图片作为中性帧。然后,计算患者每帧的面部图片和中性帧的光流特征。光流特征的水平分量u和垂直分量v采用TV-L1 光流方法来计算[8]。此外,光流应变采用了无穷小应变理论,可以反映出患者的细微面部形变。光流应变的定义如式(2)所示:
式中:δx为坐标(x,y)的像素点在x轴上的微分,δy为像素点在y轴上的微分,εxx和εyy为正切应变分量,εxy和εyx为剪切应变分量。则光流应变的幅值可以按式(3)进行计算。
在本文的算法中,以光流应变幅值作为量化患者面部运动的程度。而光流特征图为水平分量u、垂直分量v和光流应变ε三个矩阵叠加而成,可视为一张通道数为3 的特征图。
从已有的研究中可知,患者面部的表情变化通常集中在特定区域[9]。在本文算法中,定义了三块ROI 区域,分别为左眼左眉、右眼右眉和嘴部区域。通过面部标志点来区分这些区域,如图2 所示。
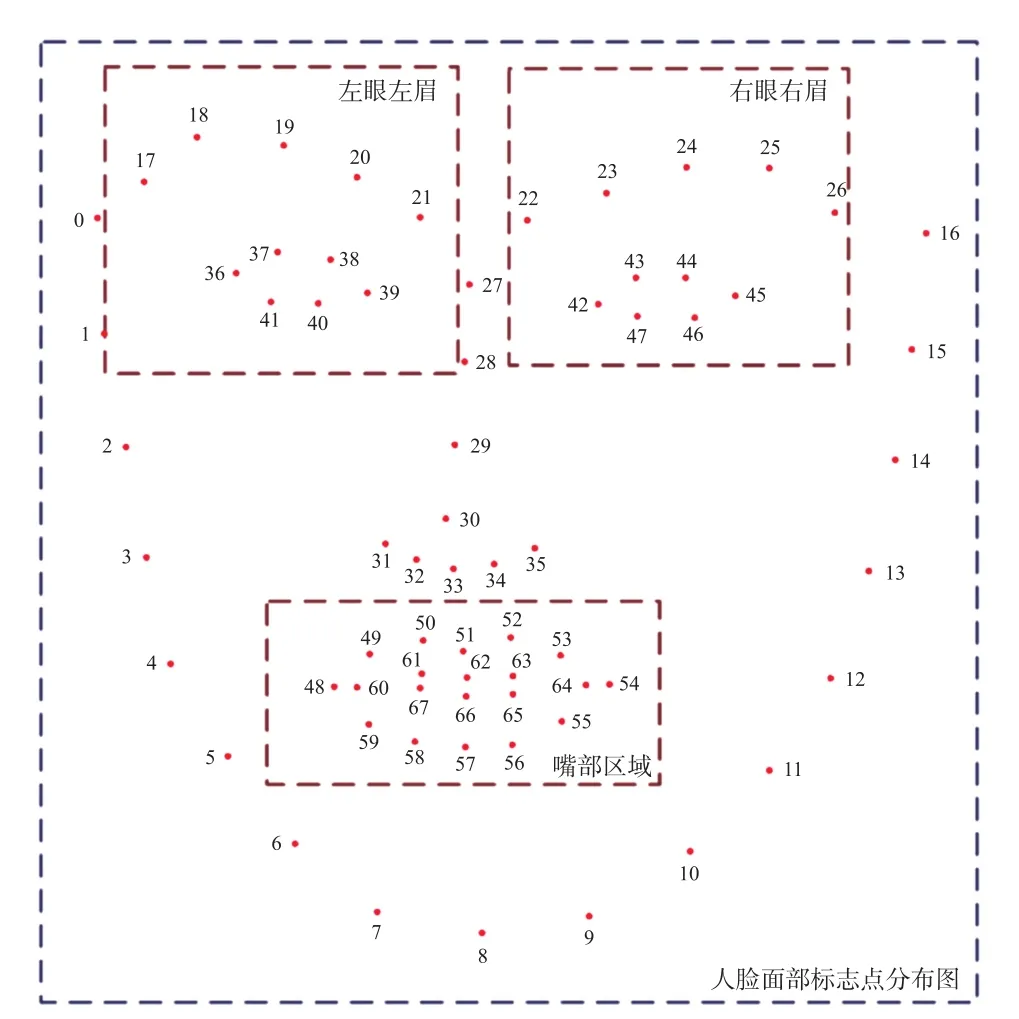
图2 通过面部标志点定义的ROI 区域
在各个ROI 区域之中,以面部标志点的最高点、最低点、最左侧的点和最右侧的点作为基准进行截取。为了保证ROI 区域被完整地截取,不丢失边界的信息,分别在每个方向都扩展12 个像素。算法中将左眼左眉区域定义为ROI 1,右眼右眉的区域定义为ROI 2,嘴部区域定义为ROI 3。
将ROI 1 和ROI 2 的大小都调整为27×27 像素,ROI 3 的大小调整为27×52 像素。最后,将三块ROI 区域拼接在一起,得到54×54 大小的ROI 区域图片。三块ROI 区域的位置关系如图3 所示。

图3 面部ROI 区域位置关系
随后,按照光流应变幅值中提到的方法计算面部序列单元的每一帧面部图片和中性帧的光流特征图。在计算光流特征图时,虽然已经在采集视频的预处理中对患者面部图片进行了矫正对齐。本算法中还选取了鼻子区域的标志点位置,来进一步消除患者头部全局运动对光流产生的影响[10]。
得到光流特征图后,以原始图片上识别出的面部标志点,按上述ROI 区域定义方式,从光流特征图中裁剪拼接得到面部ROI 区域光流特征图。该步骤算法流程如图4 所示。

图4 面部ROI 区域光流特征图构建流程
通过面部ROI 区域光流特征图构建流程中的算法,得到了患者面部序列单元中每帧面部图片的面部ROI 区域光流特征图。然后通过光流应变幅值计算方法,计算出患者每帧面部ROI 区域光流特征图的光流应变幅值。可以得到时序帧和光流应变幅值的峰值关系图,如图5(a)所示。
在原始的峰值关系图中存在着许多噪声元素,这些噪声元素的产生和图片的质量、患者面部本身的过度偏转和视觉传感器的采集环境等因素相关。这导致了在峰值图中存在大量微小的波峰和伪峰,影响后续算法的效果。所以需要对原始峰值图进行去噪以及离群值检测。
在去噪算法的选择中,对比了傅里叶变化,滚动平均值和Savitzky-Golay 滤波。根据消融实验数据,选择Savitzky-Golay 滤波作为本文算法框架中的去噪算法。同样,对于离群值检测算法的选择,对比了基于滚动统计的方法、孤立森林算法和K-Means 算法。在这些方法中,孤立森林算法取得了最好的效果。
经过去噪和离群值检测后,得到处理后的峰值图,如图5(b)所示。处理后的峰值图中减少了大量的微小波峰,也处理了偏离正常趋势的离群点。然后,通过峰值检测器寻找成峰时序段所在的起始帧位置、结束帧位置、峰值帧位置和持续帧长度。
每一个成峰时序段都是一个应激单元。为了后续输入模型的数据长度统一,需要统计所有应激单元的持续帧长度,进行K-Mean 聚类,获得一个最为合适的持续帧长度。
在本文使用的数据集中,聚类得到的时序帧长度为128。
按照本节算法流程可以将视觉传感器采集而来的长时间的患者视频,转化为短时间的应激单元,应激单元中既包含了有效的患者面部表情变化特征,又保持了时序关联性,易于后续模型进行训练。能够有效解决时序跨度大、干扰信息多、有效特征难以定位等问题。
本节整体的算法流程如图1 中面部应激单元提取部分所示。
1.3 光流特征单元构建
以每个成峰时序段所在的峰值帧位置作为基准,对两侧起始帧位置和结束帧位置尽量等额进行扩充或是删除(对于无法扩充前置帧或者后序帧的情况,通过复制帧来解决)。最后,得到标准化后的应激单元,为128 帧的分段面部序列单元。对于每一个标准化后的应激单元,同样利用1.2 小节中介绍的方法,计算每一帧和中性帧的光流特征图,保留指定ROI 区域部分,可以得到128 帧所对应的128张光流特征图。
为了去除人脸个体性的差异,保持光流特征图的时序联系性以及采集环境对图片带来的色泽影响。对光流特征图矩阵基于HSV 色彩空间做归一化[11]。然后以16 frame/s 的规格将128 帧归一化后的光流特征图拼接成8 s 的视频,即本算法中的光流特征单元。
光流特征单元为本算法框架后续模型的数据输入。对于每一个光流特征单元,需要生成一个匹配的标签。针对本文中所使用的数据,设计了一个伪标签函数(线性函数)来对每一个光流特征单元生成标签。伪标签函数的表达形式g(·)如式(4)所示:
式中:label 为输入视频数据对应的标签。
1.4 TSMOSNet 和权重分类
本算法以TSM 网络为基础,结合光流特征单元的特性,设计了新的网络结构TSMOSNet。TSMOSNet的网络结构如图6 所示。
在TSMOSNet 模型的开始,输入的光流特征单元被分割成N个大小相等的片段。在本文的算法中,因为光流特征单元的总帧数已经被控制在128 帧,所以在采样环节使用了更为密集的采样方法。模型中将N值设置为成16,也就是每个片段的大小为8 帧,从输入的光流特征单元中采样出16 帧光流特征图输入后续的网络结构之中,来提高模型的精度。
光流特征图的性质和一般图片不同,为了提高光流特征单元的解码速度,在模型中采用了PyAV作为解码器。
模型的下一部分是光流处理头。光流处理头是针对光流特征图提出的预提取网络,替换了原TSM网络之中的卷积模块。光流处理头的结构如图7 所示。光流处理头将输入的特征图拆分成三个通道分别进行卷积。以维持光流水平分量、垂直分量和光流应变矩阵的独立性。每个卷积层的卷积核通道数分别是3、5、8,来获取不同的感受野,随后是一个最大池化层来减少特征图的大小。然后,将每个流的特征图按照通道堆叠重新组合特征,经过一个平均池化层后输出。

图7 光流提取头的结构
光流提取头能够有效地提取光流特征图的空间信息,送入后续的时序注意力模块。
原TSM 网络通过把特征在时间通道上位移,来获取时序信息。但这种位移方式仅让局部的特征进行交互,缺少对全局时序信息的建模能力。所以,本算法设计的TSMOSNet 在TSM 模块之前,添加了轻量级的LTA 时序注意力模块,可以让后续的网络在全局信息的指导下进行时序位移,进一步提高模型的精度。LTA 时序注意力模块的结构如图8 所示。
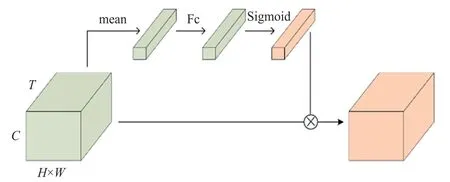
图8 LTA 时序注意力模块
本文提出算法的最后一步便是通过权重分类,让光流变化单元的分类结果回归到视觉传感器采集视频的分类结果之中。设面部序列单元M有l个光流特征单元,第i(0<i≤l)个光流特征单元的模型输出标签记为Li,可表示为M={L1,L2,L3,…,Ll}。其中任意标签Li属于n类伪标签类别集合{P1,P2,…,Pn},表示为Li∈{P1,P2,…,Pn}。则权重分类函数的表达形式如式(5)所示:
式中:LM为权重分类函数计算出的面部序列单元M对应的标签。函数MaxP 取输入参数的最大值所对应的伪标签。函数Count 为计数函数,统计输入参数在M={L1,L2,L3,…,Ll}出现的次数。
通过权重分类函数,可以聚合光流特征单元的输出标签到面部序列单元所对应的标签上,最后得到采集视频的分类结果。
2 实验与分析
为了评估本文提出的精神疾病识别算法框架的有效性,在H7-BDSN 数据集上进行了实验。在本节中,将介绍数据集、实验内容并讨论分析实验结果。
2.1 数据集
H7-BDSN 数据集是本文研究团队和某人民精神医院合作所采集构建的数据集。数据集在真实诊室和问诊流程下使用视觉传感器进行患者问诊流程视频和音频的采集,同时包括了精神疾病专家对患者的评估量表[12-13]。其中包括了抑郁症、双相情感障碍和精神分裂症三种精神疾病以及正常人的样本。
采集到的抑郁症患者病例有130 例,双相情感障碍患者62 例,精神分裂症患者79 例。对于采集到的数据,进行了严格的筛选,去除了其中视频质量低、视频时间短、拍摄角度倾斜大、患者戴有口罩、非初诊病例等情况的视频。
最后保留的有效视频,时间持续在10 min 左右,患者面部清晰可见,表情激发丰富,且有精神疾病专家的详细诊断资料和评估量表。在H7-BDSN数据集中,除了通过视觉传感器采集到的原始视频数据之外,通过OpenFace 提取了面部标志点的2D坐标数据、面部标志点的3D 坐标数据、头部姿态、面部动作单元、眼部注视数据。本文的对比算法也是在该数据上进行。
最后,H7-BDSN 数据集的分布如表1 所示。

表1 H7-BDSN 数据集样本分布表
2.2 实验结果与分析比较
在实验中,本文选用了ResNet-50[14]作为TSMOSNet 的骨干网络。使用在ImageNet 上训练好的ResNet-50 权重作为骨干网络的初始化参数。为了进一步提高模型的精度,引入了DML 蒸馏方法[15]。使用DML 蒸馏方法,无需额外的教师模型,两个结构相同的模型可以互相进行学习,计算彼此输出的KL 散度,完成训练结果。在实验中,便以TSMOSNet 自身为教师模型进行蒸馏,提高了模型的性能。
针对输入的数据,本文在实验中通过VideoMix[16]的方法来进行数据增强。对每个输入的光流特征单元,抽取固定数量的帧,并赋予每一帧相同的权重,然后与另一个光流特征单元叠加作为新的输入。
实验使用的评价指标包括精确率(Precision)、召回率(Recall)和F1 分值。另外,在分析中会对样本假阳和假阴的情况进行分析。评估指标的计算公式如式(6),式(7)和式(8)所示:
式中:TruePositive 表示算法识别结果为精神疾病患者,实际也是精神疾病患者的样本数量,FalsePositive 代表的是算法识别结果为精神疾病患者,实际为非精神疾病患者的样本数量。
在实验中,对置信度阈值的选择进行了消融实验。图9 展示了置信度阈值的消融实验结果。消融实验中置信度从0.8 开始,每隔0.02 进行一次实验,最大值为0.98,以分类准确率为指标。从图9 的数据趋势中进行分析可知,当置信度阈值设置的比较低时,提取出来的面部特征受到一定的污染,导致特征信息少,算法效果差。当置信度设置的过高时,可供使用的面部图片变少,导致模型的准确率也会下降。所以在本文算法的参数设置中,取置信度阈值为0.95。
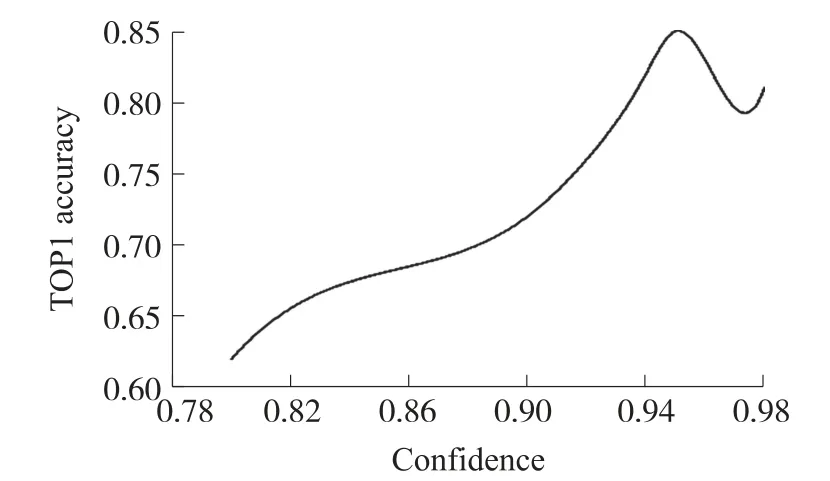
图9 置信度阈值的消融实验结果
图10 和图11 分别展示了面部应激单元提取环节中去噪算法和离群值检测算法的消融实验结果,比较指标也是识别准确率。从消融实验的结果可知,去噪算法中Savitzky-Golay 滤波取得了最好的效果,比傅里叶变换和滚动平均值分别高出了3.79%和12.07%。相比之下,Savitzky-Golay 滤波在平滑数据的同时保留数据的整体趋势和形状,对于处理面部噪声更为合适。

图10 去噪算法的消融实验结果

图11 离群值检测的消融实验结果
在离群值检测算法的消融实验中,孤立森林算法取得了最好的效果,这得益于孤立森林算法不受数据分布的影响,普适性较高,适合于处理视频数据中波动较大的离群值。
表2 给出了本文算法和其他算法在H7-BDSN数据集上的实验结果。算法框架中所使用的数据维度都为视频维度。从表2 中可知,本文算法在精确率、召回率和F1 分值上都取得了最好的结果,分别为0.89、0.80 和0.84。表2 的实验结果证明了本文方法拥有更好的识别效果。
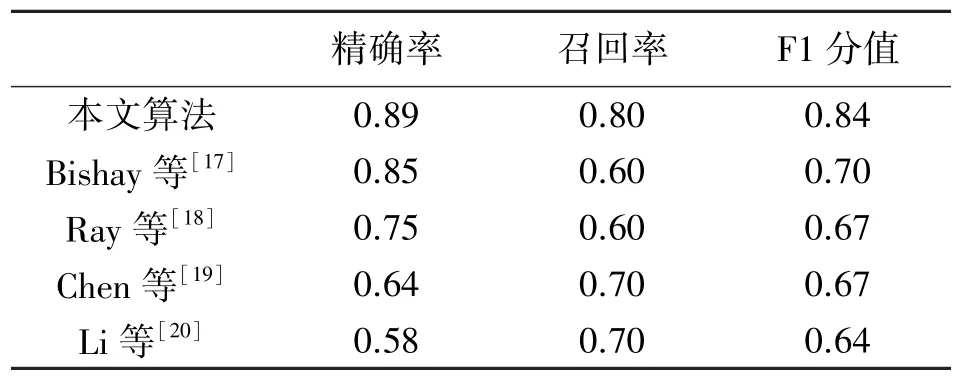
表2 本文算法和其他算法的效果对比
此外,对识别结果的混淆矩阵进行统计分析后发现,本文算法对于样本的误判主要表现为假阳,假阴性样本少。这意味着本文的算法能够更好地检测出患有精神疾病的样本。这对于精神疾病患者的筛查任务而言,有着积极的意义。
表3 给出了本文算法中提出的模型TSMOSNet和常用模型的比较。除了比较各类模型的准确率,还比较了模型的预处理时间和模型的推理时间,以衡量模型的开销。此处时间的单位为ms。

表3 TSMOSNet 和其他模型效果对比
从表3 中可知,TSMOSNet 的准确率指标最高。和基础模型TSM 相比,TSMOSNet 因为加入了光流处理头,LTA 时序注意力等模块,模型预处理时间和推理时间开销都更大,但是准确率分别提升了5%和8%。此外,TSMOSNet 和其他模型相比,在各个指标中都具有很大的优势。其中,虽然VideoSwin在准确率上和TSMOSNet 接近,但是VideoSwin 的预处理时间和推理时间都远高于TSMOSNet。可知,TSMOSNet 相比于其他模型,最适用于本文的算法。
3 总结
在本文的工作中,提出了一种新的基于视觉传感器采集光流特征的精神疾病识别算法。在H7-BDSN 数据集上,本文提出的算法在精神疾病识别任务上取得了最优的结果。其中,算法的准确率为85%,F1 分值为0.84,优于其他方法。此外,TSMOSNet 的规模规模小,推理速度是VideoSwin 的10 倍、SlowFast 的3 倍和TSN 的16 倍,能够和视觉传感器进行整合,利用视觉传感器成本低、非侵入性、客观性高等优势,开发出精神疾病预警系统。
在未来的工作中,会尝试引入更多的传感器,例如使用毫米波雷达来监测体征数据,音频传感器提取声波情绪特征,进行共同建模分析。
