基于改进Yolo v8s-seg的船舶旋转角度检测方法
2024-03-05丁秀清周斌胡波
丁秀清,周斌*,胡波
(1 中南民族大学 a.计算机科学学院;b.国家民委信息物理融合智能计算重点实验室, 武汉 430074;2 武汉东信同邦信息技术有限公司, 武汉 430074)
传统水上收费站通过人眼观察控制船闸的开关,不仅消耗人力而且容易观察失误引起安全事故.近几年兴起的智慧船闸系统引入人工智能技术,将摄像机拍摄的船舶图片自动转化为鸟瞰图,智能控制船闸开关,并且自动识别船闸内外船舶的动向.为了完成上述任务,系统需要能够精准检测航道内船舶的旋转角度.
为了得到船舶的旋转角度,需要先对船舶进行目标检测确定其位置,而传统的目标检测算法如HOG+SVM[1]、Haar Cascades[2]等存在着精度有限、实时性差、不适用于大规模数据的缺点.近几年研究主流的方法是使用基于深度学习的旋转框目标检测方法来检测物体的旋转角度,如RR-CNN[3]、R3Det[4],常应用到遥感图片和航拍图片,这些模型经过大规模的数据训练能够直接输出目标的旋转角度,但是对数据集的要求较高,这些数据集的共同点是图片以较大的俯瞰角度来拍摄,而水上收费站的摄像头高度并不满足该条件.如果直接使用旋转框检测模型对船舶图片进行训练,会导致较大的角度误差.
对于实例分割问题,主流的方法分为三大类:二阶段实例分割、一阶段实例分割、Query-based 实例分割. 二阶段实例分割(如Mask R-CNN[5]、HTC[6]、Cascade Mask R-CNN[7])通常分为两个阶段:第一阶段使用一个目标检测器来检测图像中的对象,第二阶段使用一个分割器来对每个检测到的对象进行像素级的分割,该方法的优点是可以准确地定位和分割多个对象,并且可以在复杂的场景中实现高精度的分割,但是对于小尺寸物体的分割效果不太理想,因为可能会被模型误认为是噪声或背景.
一阶段实例分割(如YOLACT[8]、BlendMask[9]、CondInst[10])不需要先进行目标检测,而是直接在单一的网络中同时进行检测和分割任务.该方法通常采用卷积神经网络(CNN)来实现,可以在速度和精度之间取得平衡,并且实时性好,在实际应用中具有很高的实用性,但是由于该方法需要在单一网络中进行检测和分割任务,因此会出现目标漏检和分割不完整的现象.该方法与二阶段方法相比通常需要更多的训练数据和更高的计算资源,以达到与之相当的准确度.此外,对于复杂场景中的多个对象分割任务,该方法可能会遇到困难.
Query-based 实例分割(如SOLOv2[11])允许用户指定一个查询对象,然后自动检测和分割该对象的所有实例.在该技术中,用户可以通过在图像中选择一个查询对象来指定要检测的对象,然后系统会使用预训练模型来检测和分割所有与查询对象相似的实例.这种方法可以用于许多应用,如自动化图像分析和智能监控系统[12],主要缺点是对于一些复杂场景和多样性对象的识别和分割效果不够理想.由于该方法是基于预先定义的查询对象进行分割的,因此对于未知的、多样性的对象,可能会出现错误的分割结果.
针对以上问题,本文提出一种基于实例分割的船舶旋转角度检测模型,先对船舶进行实例分割提取轮廓坐标点,再使用坐标点计算船舶旋转角度.模型使用实时性更强的one-stage 实例分割方法进行分割并提取坐标,在此基础上引入注意力机制以弥补该方法在分割精度上的不足.在得到坐标后,模型使用轮廓法计算船舶旋转角度.两种方法结合以得到更为精确的船舶旋转角度.
1 船舶旋转角度检测模型的设计与实现
Yolo v8s-seg模型结构如图1所示.

图1 Yolo v8s-seg模型结构Fig. 1 Yolo v8s-seg model structure
Yolo v8s-seg 模型在Yolov8 模型的基础上添加了一个mask 分支用于实例分割,与目标检测同步进行.
本模型命名为Yolo v8s-seg-boat,结构如图2 所示,主要改进方法为:在Yolo v8s-seg 模型的主干网络中添加了CA 注意力机制;在C2f 结构中添加了CA 注意力机制;将IOU 函数替换为Wise-IOU. Yolo v8s-seg-boat 模型主要分为二个阶段:第一阶段使用改进后的网络对船舶图片进行实例分割处理,得到船舶的轮廓点坐标;第二阶段对每组坐标点使用旋转角度计算模块得到船舶的旋转角度并显示在图片上.
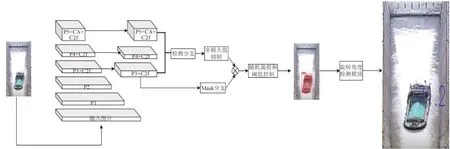
图2 Yolo v8s-seg-boat模型结构Fig. 2 Yolo v8s-seg-boat model structure
P1、P2、P3、P4 和P5 表示网络不同级别的不同特征图,通过一系列卷积层和下采样操作获得.P1是指在骨干网络的第一阶段之后获得的特征图.P2、P3、P4 和P5 是在随后的阶段中获得的,并且具有逐渐降低的分辨率.P3+C2f和P4+C2f表示这些特征图的C2f 结构中添加了注意力机制,P5+CA+C2f 表示该特征图在其C2f 结构中添加了注意力机制的同时,在SPPF层前添加了注意力机制CA.
1.1 Yolo v8s-seg-boat网络
1.1.1 主干网络添加注意力机制CA
Yolo v8s-seg-boat 网络结构借鉴了基于改进的yolact模型[13]结构,使用的分割方法是典型的一阶段实例分割方法,实时性高,但是在分割精度方面有所欠缺.为了得到更高的船舶分割精度,在Yolo v8sseg 网络的基础上添加了CA (Coordinate Attention)注意力机制[14],其backbone结构如图3所示.在特征融合层SPPF 前添加的注意力机制CA,它能根据输入的特征图中的重要区域和上下文信息,对特征进行加权,让SPPF 层能够接收到更加强化的特征表示,从而提升模型特征的表达能力.将CA放在SPPF层之前能够进一步增加特征的感受野,使模型能够更好地捕捉到不同尺度上的关键信息;另一方面,CA 还考虑了特征空间的位置信息,特征在SPPF 层进行融合时,模型能够更加准确地对局部信息和全局信息进行加权,从而提高特征的融合效果.

图3 Yolo v8s-seg-boat的backbone网络结构Fig. 3 Backbone network structure of Yolo v8s-seg-boat
Yolo v8s-seg-boat 的backbone 网络结构主要用于提取船舶图片的特征,用于head 结构的检测和分割,矩形大小代表各个层的参数量,而加入的注意力机制CA 参数量较大,能够加强backbone 网络的特征提取能力.
1.1.2 C2f添加注意力机制CA
模型的C2f 模块参考了Yolo v5 中C3 结构和Yolo v7[15]中ELAN[16]设计思想,结构如图4 所示,让Yolo v8s-seg-boat 网络可以在保证轻量化的同时获得更加丰富的梯度流信息.该模块首先用1 × 1 卷积核对特征进行降维,通过split 模块将特征图分为主干分支和支干分支,再通过瓶颈结构Bottleneck在有效减少参数量的情况下提取特征,最后通过Concat模块进行特征拼接,在此基础上添加了CA注意力机制到Concat 模块后,为特征分配不同的权重,增强模型对重要特征的关注,同时通过对特征图的加权,改善了多尺度特征融合效果.

图4 改进后的C2f结构Fig. 4 Improved C2f structure
C2f 结构中加入的注意力机制CA 同样也起到了加强特征提取的作用,相比于Yolov5中的C3结构检测效果更好.
1.1.3 CIOU损失函数优化
Yolo v8s-seg 使用CIoU 损失函数[17]来计算分割损失,该函数考虑重叠面积、中心点距离、长宽比三个方面,公式如下:
其中:IoU 为交并比,是目标检测中常见的指标,主要用于反映预测检测框与真实检测框的检测效果;v为中心点距离,表示预测框的中心点与实际框中心点之间的距离;α为长宽比,用于衡量预测框与实际框长度和宽度的比例误差.CIoU 计算过程中涉及到反三角函数,计算量较大,尤其是在处理大量数据时,会影响模型的训练速度,此外在处理低质量训练数据时,长宽比的几何度量会加剧对低质量数据的惩罚从而使模型的泛化性能下降,导致出现精度不高的情况.综合以上原因,Yolo v8s-seg-boat 使用Wise-IoU[18](简称为WIoU)代替CIoU 来计算分割损失,公式如下:
其中Wg,Hg是最小预测框的宽度与高度,(xgt,ygt)是目标框中心点坐标.对于低质量锚框,1 - IoU 的值将被显著放大;对于高质量锚框,会显著降低RWIoU.WIoU 取消了长宽比损失项,降低了对数据集中出现的低质量锚框的惩罚,另一方面降低了计算量,加快了模型的训练速度.对于船舶数据集而言,遮挡和噪声现象普遍存在,如果模型使用CIoU 作为损失函数,由于其对低质量锚框的惩罚,会使模型训练时难以收敛.
1.2 旋转角度计算模块
图片在经过Yolo v8s-seg-boat网络进行分割后,对其轮廓点坐标使用边缘法计算旋转角度,算法步骤如下:
(1)通过计算所有轮廓点的坐标的平均值得到船舶的重心坐标,如图5所示;

图5 opencv计算重心Fig.5 Opencv calculates the center of gravity
(2)对于每一个轮廓点,计算该点和船舶重心的连线与x轴的夹角,如图6所示;

图6 计算轮廓点与重心的夹角Fig. 6 Calculate the angle between the contour point and the center of gravity
(3)将所有点的夹角根据不同位置进行加权平均处理,得到船舶的平均夹角;
(4)平均夹角减去90 度得到船舶的旋转角度,如图7所示.

图7 旋转角度显示Fig.7 Rotation angle display
计算船舶的旋转角度时,需要将平均夹角减去90 度,是因为船舶的轮廓点坐标与x轴的夹角是相对于水平方向的,而图片船舶的朝向是垂直于水平方向的,由于船舶生成的轮廓点总数并不完全相同,先将权值根据轮廓点数量平均化,再赋予4 个顶点(离矩形框4 个顶点最近的4 个轮廓点)2 倍于其他点的权值,这是因为顶点对旋转坐标的影响更大.
2 实验结果与分析
2.1 实验数据集
收集的船舶的数据集来自于江苏某个水上收费站多个高清摄像头拍摄的航道内船舶图片,这些船舶图片用于该收费站中智慧船闸系统的人工智能训练.根据航道内船舶的数量、大小和种类采集了4000 张俯视角度图片,图片大小均为640 × 640,将图片按照8∶1∶1 的比例分为训练集、验证集和测试集.相比于航拍和遥感等一系列较高俯视角度的图片数据集,本数据集有着俯视角度较低、船舶位置密集等特点,对模型的检测精度有更高的要求.
2.2 实验评价指标
使用以下指标来衡量Yolo v8s-seg-boat 网络的分割效果:
(1)精确度Precision 表示预测为正样本的数据样本中,真正的正样本所占的比例,公式如下:
其中:TP 表示模型预测为正样本实际也为正样本的数据样本,FP 表示模型预测为正样本实际却为负样本的数据样本.
(2)召回率Recall 表示实际为正样本的数据样本中,真正的正样本所占的比例,公式如下:
其中:FN表示实际为正样本预测为负样本的数据样本;一般来说,数据的召回率越高,它的精确度越低.
(3)AP 与mAP. mAP 是目标检测任务中最常用的评估指标之一,可以用来比较不同模型的性能差异;AP 表示的是模型在一个类别上的优劣程度,它的实际值是图中曲线与横坐标轴、纵坐标轴围成的面积,取值范围在0~1之间.
2.3 实验结果及分析
使用Pytorch 深度学习框架搭建实验环境,通过RTX 3090 24GB显卡进行GPU加速,具体环境如表1所示.

表1 实验环境配置单Tab. 1 Experimental environment configuration sheet
2.3.1 船舶数据集IoU实验结果分析
在船舶数据集训练过程中,输入的图像大小为640 × 640,batch_size、缩放因子、最大迭代轮次、初始学习率分别设为2,0.35,100,0.01. 使用SGD[19]算法优化器调控模型收敛,动量momentum 设置为0.937,用于控制模型参数的更新速度和方向.动态焦点损失权重dfl 设置为1.5,目的是优化动态焦点损失对总损失函数的贡献程度.实验结果与其他IoU函数进行比较,如表2.
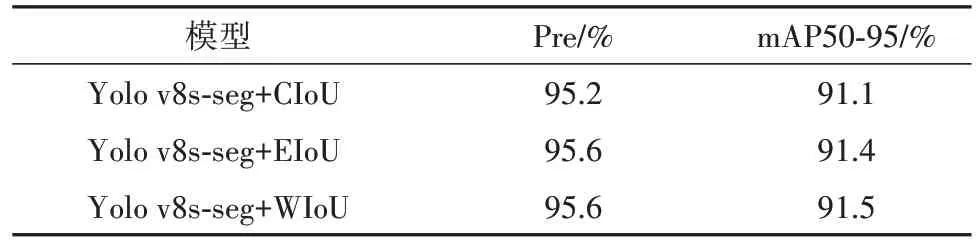
表2 IOU效果对比Tab. 2 IOU effect comparison
对比这3种IoU函数的实验效果可以看出,搭载了WIoU 损失函数的分割模型在船舶数据集上的效果最好.与Yolo v8s-seg 模型自带的CIoU 函数相比较,EIoU[20]在mAP 上提升了0.3%,这说明EIoU 在CIoU 基础上拆分长宽比惩罚项分为长损失和宽损失的操作在船舶数据集上有助于提高分割精度;而WIoU 相比于EIoU 通过考虑预测框和真实框之间的区域来对IoU进行加权,mAP进一步提高了0.1%.前50轮训练不同IoU 函数下模型的分割损失变化如图8所示.
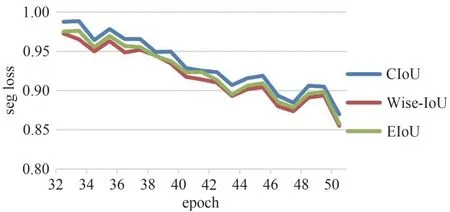
图8 训练过程中不同IoU对模型的分割损失变化Fig.8 Segmentation loss variation of the model with different IOUs during the training process
从图8 中可以看出搭载WIoU 损失函数的模型在训练过程中收敛速度最快,分割损失值最小,这说明了WIoU在CIoU的基础上简化的长损失和宽损失在一定程度上加快了模型的收敛,另一方面减少了低质量框对模型训练的影响,使得分割损失变小.
2.3.2 船舶数据集注意力机制的实验结果分析
在Yolo v8s-seg 的主干网络上添加各种注意力机制进行模型训练,效果对比如表3.

表3 不同注意力机制效果对比Tab. 3 Comparison of the effects of different attention mechanisms
其中FLOPS 是浮点运算数(Floating Point Operations),表示在训练过程中所执行的浮点运算的数量, Parameters 是模型的参数量.在mAP50-95指标上,CA 效果最好,相较于原模型提高了1%,同时分割精准度提高了2.2%;相比于CBAM,CA 提取重要空间信息时主要是依据像素之间的关联性,能够更好地捕捉到局部细节和空间结构,而CBAM 主要专注于对通道关系进行建模,无法完全捕捉像素之间的空间依赖性;另一方面,CA 不仅能够捕获跨通道的信息,还能捕获方向感知和位置感知的信息,在复杂场景中更加适合,如本数据集中,船舶分布密集且存在覆盖的情形.因此CA 在指标Pre 和mAP50-95上最优.
最后12 轮训练中不同注意力机制下mAP 的变化如图9所示.
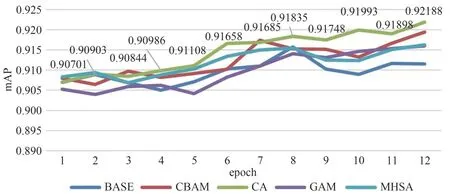
图9 最后12轮训练中不同注意力机制对模型mAP的影响Fig. 9 Effect of different attentional mechanisms on model mAP in the last 12 rounds of training
从图9 中可以看出注意力机制CA 在训练过程中mAP 的上升速度明显超过其他注意力机制,这说明它对模型梯度下降过程起到了促进作用,帮助模型更好地进行拟合.
为了更好地理解CA对本模型的影响,引入热力图来直观感受特征在加入注意力机制前后的变化,打印未加入CA的模型Yolo v8s-seg第9层特征热力图和加入CA后模型Yolo v8s-seg + CA 第10层(加入注意力机制CA的层数)特征热力图作比较,如图10所示.
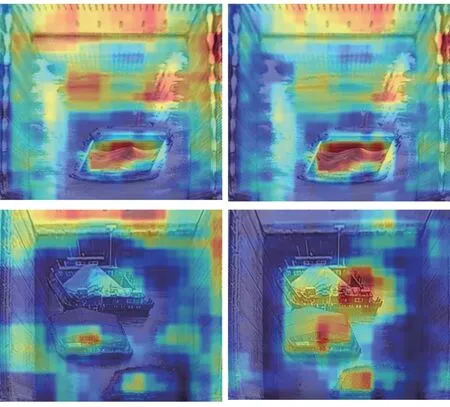
图10 无注意力机制(左)与注意力机制CA(右)的热力图对比Fig. 10 Heat map comparison between no attention mechanism (left)and attention mechanism CA (right)
模型的热力图主要用于显示图像中各个区域的目标物体的位置和置信度,颜色越深的区域表示模型认为该区域存在目标物体的可能性越高.从图10中可以明显看到加入CA 后颜色在船舶区域更深,说明模型在加入注意力机制CA 后对目标检测物船舶的准确率增加;另一方面,非船舶区域的颜色存在不同程度变浅的现象,这说明了模型对特征权重的分配更加合理,降低了检测误差.
2.3.3 消融实验结果分析
为了验证模型中加入的各个模块(注意力机制,IoU)的作用,单独加入CA 或者WIoU 进行实验,实验结果如表4.
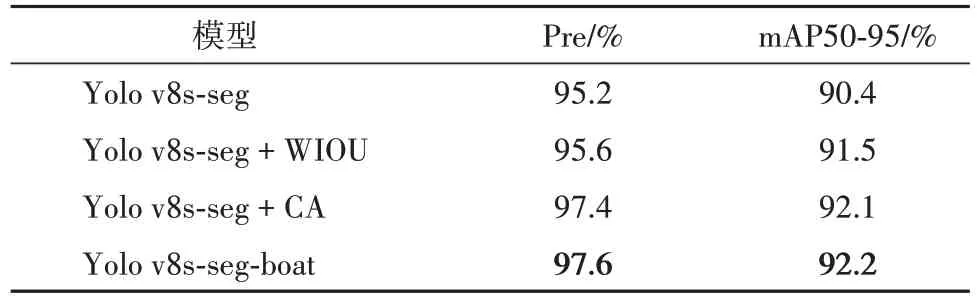
表4 注意力机制与IoU对模型的影响Tab. 4 Attentional mechanisms and the effect of IOUs on modeling
由表4 可见:加入的注意力机制CA 与WIoU 对船舶轮廓分割的准确率有不同程度的提升效果,注意力机制CA 涉及到网络层数的增加,训练参数也进一步增加,而WIoU 对模型的准确率提升效果更高,同时WIoU降低了CIoU带来的计算复杂度,在一定程度上减少了模型的训练时间,加入这两个模块的模型相比于原模型在mAP50-95 指标上提升了1.8%. Yolo v8s-seg 模型与Yolo v8s-seg-boat 模型对船舶轮廓的分割效果对比如图11所示.从图11中可以明显看出:本模型检测的船舶轮廓相比于Yolo v8s-seg模型更加完整,并且在相同置信度下漏检率更低.

图11 Yolo v8s-seg模型(左)与本模型(右)轮廓分割效果对比Fig. 11 Comparison of contour segmentation effect between Yolo v8sseg model (left) and the presented model (right)
船舶角度检测效果如图12 所示.由图12 可知:水上收费站实地考察得到的上述船舶角度为70.9度,这说明Yolo v8s-seg-boat模型在角度检测上更加准确.

图12 Yolo v8s-seg模型(左)与本模型(右)角度检测效果对比Fig. 12 Comparison of angle detection effect between Yolo v8s-seg model (left) and the presented model (right)
3 结语
本文针对船舶旋转角度检测高实时化的需求,提出了基于实例分割的船舶旋转角度检测模型,在Yolo v8s-seg 网络的基础上添加了注意力机制,使用Yolo v8s-seg-boat 网络来得到船舶的轮廓点坐标,再使用旋转角度检测模块来得到船舶的角度.实验结果表明本文提出的改进模型Yolo v8s-seg-boat 相较于Yolo v8s-seg 模型能得到更加完整和精确的船舶轮廓,对船舶角度的检测更加精准,并已在工程上进行了应用.
