基于逆向重建和运动轨迹偏移的视频重定向质量评价
2024-03-05卢铭胜唐振华
卢铭胜,唐振华,2*
(1.广西大学 计算机与电子信息学院,广西 南宁 530004;2.广西多媒体通信与网络技术重点实验室,广西 南宁 530004)
0 引言
随着电子显示技术的发展,显示设备的尺寸变得多种多样,当视频的分辨率和尺寸与显示设备不相符时,有可能会造成屏幕资源的浪费,甚至会严重影响用户的观看体验。视频重定向(Video Retargeting)技术会将视频的分辨率和尺寸调整到与显示设备的尺寸一致,同时尽可能地保持视频的重要信息和时间连续性。目前主流的视频重定向方法是基于内容感知的方法,主要有4种[1-2]:变形(Warping)[3-5]、细缝裁剪(Seam-Carving,SC)[6-8]、智能裁剪(Smart Cropping)[9-11]和多操作符(Multi-operator)[12-14],这些方法能很好地保持某一方面的特征。但是在重定向过程中,不可避免地会挤压或删除部分像素点,导致空间和时间失真。空间失真主要是个别帧中的线条、形状或纹理失真和信息丢失,时间失真主要表现为时间上的不一致伪影、播放时的抖动。现有的视频重定向质量评价(Video Retargeting Quality Assessment,VRQA)方法主要分为主观评价和客观评价。
主观评价需要组织一批测试者观看重定向视频,并根据既定的测试原则和流程对重定向视频的质量做出评价,测试者根据主观感知对测试视频进行排序。主观评价存在着固有的缺陷:① 无法对重定向视频的失真进行量化,难以为改进视频重定向算法性提供指导意见;② 评价结果有个人倾向性和随机性;③ 过程费时费力,难以实现实时评价。
视频重定向质量客观评价是利用算法自动地对重定向视频的空间和时间失真进行衡量,自动地生成重定向视频质量评价结果,不需要人为参与;可以通过评价过程及结果分析重定向算法的不足。如今,视频重定向质量客观评价仍处于起步阶段。Li等[15]提出一种评估视频时间连续性的指标,通过测量视觉相邻帧之间映射像素点的坐标差来评估重定向视频的视觉质量,该方法只适用于目标快速运动的视频的时间失真,并且没有提出空间失真的评估。Yan等[16]提出一种针对视频时间抖动的评价方法,主要是利用相邻帧之间对应网格的高度差或宽度差来评估视频的时间抖动,该方法只适用对Warping处理的重定向视频的时间失真进行评估。
Hsu等[17]提出一种基于时空质量分析的视频重定向质量的客观评价方法,该方法提出在空间和时间域中进行尺度不变特征变换(Scale Invariant Feature Transform, SIFT),解决视频尺度不一致的问题。虽然该方法可以评估重定向视频的整体质量,但无法对目标静止的视频的时间失真评估。董伟鑫[18]提出基于逆向重建网格的视频重定向质量客观评价算法,对Niu等[19]提出的视频重定向方法反向应用,但其性能依赖于SIFT-flow[20]稠密匹配的精准度。赵祖翌[21]在董伟鑫[18]的基础上提出了一种基于匹配校验的网格重建的视频重定向质量客观评价算法方法,该算法对SIFT-flow稠密匹配进行校验,对匹配错误的帧进行放大处理,并计算原始帧与重定向帧中对应网格块的感知哈希衡量时间失真。放大处理虽然减少了错误匹配,但是改变了重定向视频的信息量,使得评价结果与原重定向视频不一致。
现存的视频重定向质量客观评价算法均以SIFT-flow稠密匹配为基础。由于原始帧与重定向帧尺寸不一致,SIFT-flow稠密匹配会产生错误,客观评价算法性能下降。为了减少错误匹配,提高客观评价算法的性能,本文修改SIFT-Flow公式中平滑项的权重,并设计一种检测删除黑边的算法,提高了SIFT-flow稠密匹配的准确性。在董伟鑫[18]的基础上,本文提出使用网格损失率(Grid Loss Ratio,GLR),增加对重建网格未匹配区域失真的衡量,实现全面评估重定向视频的质量。本文还提出利用追踪算法追踪网格的运动轨迹,计算原始视频与重定向视频对应相邻网格运动轨迹偏移量的变化来衡量时间连续性失真,减少对SIFT-flow的依赖。
1 问题分析
SIFT-flow的错误匹配会对空间失真衡量产生误差,如图1所示,其中①~⑥行分别是对均匀缩放(Uniform-Scaling,US)、黑边填充(Letterbox)、裁剪(Cropping)、Warping[19]、SC[22]和精确均匀(Refined Homogeneous,RH)[23]6种重定向视频的SIFT-flow匹配关系的说明。图1(b)是在重定向帧划分的均匀网格,图1(c)是在原始帧中的逆向重建网格,图1(d)中无内容区域是原始帧中未匹配的部分,图1(e)是根据映射关系和原始帧中像素值得到的重构图,假设SIFT-flow匹配正确,则重构图应与重定向帧保持一致。如图1①、④、⑤行的(e)和(f)列所示,重构图在方框中均出现了空间内容丢失的情况,这表明SIFT-flow存在错误匹配的情况,会引入不属于重定向操作引起的空间失真,并主要存在Letterbox、Warping和SC方法的重定向视频中。

图1 匹配错误引起空间失真误差说明Fig.1 Illustration of spatial distortion error caused by matching error
SIFT-flow稠密匹配错误还会引入额外的时间失真,如图2所示。图中相邻的重定向帧内容没有明显变化,重定向帧也没有抖动,但相邻2帧的逆向重建网格却有着很大的差别,这说明相邻2帧之间的稠密匹配关系也存在错误匹配的情况。使用相邻2帧逆向重建网格顶点位置来衡量时间连续性失真[18]时,其评价结果会存在较大误差。

图2 匹配错误引起时间失真误差说明Fig.2 Illustration of temporal distortion error caused by matching error
通过对SIFT-flow稠密匹配和相关稠密匹配算法[24-26]的研究,了解到SIFT-flow稠密匹配错误的原因。根据文献[20]给出SIFT-flow的目标函数表达式定义如式(1)所示:
(1)

视频重定向过程会删除像素点或挤压视频内容,使得重定向帧的像素点位置和尺度改变,因此流向量的位移较大;由于删除和挤压像素点,在重定向帧中相邻的像素点,在原始帧中不再相邻,并且位置可能存在较大的距离。使用较大的权重α约束相邻像素的流向量具有相似位移,在建立稠密匹配的时候,会限制匹配范围,使得形变较大区域以及像素严重丢失区域出现匹配点聚合,导致错误匹配。
对于Cropping和RH,由于都使用裁剪操作,裁剪的内容完全保留了原始视频的内容,匹配几乎完全正确;RH是裁剪和变形组合方法,裁剪掉一部分视频内容然后变形,形变程度较低,因此这2种方法匹配正确率较高,如图1③、⑥行所示。逆向重建网格无法覆盖被裁剪掉的内容,所以无法衡量这部分内容丢失带来的空间失真,也会影响最终的评价结果。
2 基于逆向重建和运动轨迹偏移的方法
为了解决上述问题,提高客观评价算法性能,本文提出一种基于逆向重建和运动轨迹偏移的VRQA算法,具体如下:
① 本文通过修改平滑项权重和检测删除黑边尽进行预处理,减少了SIFT-Flow的错误匹配。
② 对于逆向重建网格出现的未匹配区域,提出使用GLR来衡量其空间失真。对于匹配区域的空间失真,仍沿用文献[18]的空间几何失真(Spatial Geometric Distortion,SGD)、空间结构失真(Spatial Structure Distortion,SSD)和局部信息丢失(Local Information Loss,LIL)指标衡量。
③ 提出使用原始帧与重定向帧中相邻网格运动轨迹偏移量的误差来衡量重定向视频的时间连续性失真。
本文算法框架如图3所示,具体步骤如下:

图3 算法框架Fig.3 Algorithm framework
① 检测重定向视频是否为Letterbox重定向得到的,如果是则对重定向视频进行删除黑边的处理,否则直接进入步骤②。
② 对每张重定向视频帧划分尺寸为10×10的均匀规则网格,接着使用SIFT-flow稠密匹配,此处对SIFT-flow的目标函数表达式中的平滑项权重修改为α=0.2,根据稠密匹配关系生成逆向重建网格。
③ 使用SGD、SSD和LIL指标衡量空间失真;
④ 为了衡量逆向重建网格未匹配区域,在SIFT-flow匹配图中划分均匀规则网格,若网格内容被删除超过90%,则认为过度删除,记录网格个数并计算占比,使用网格的重要度值作为每个网格的权重值。
⑤ 对重定向视频帧划分较大的均匀网格,使用SIFT-flow稠密匹配在原始帧生成对应网格。接着使用文献[27]中的方法进行每个网格进行跟踪,得到每个网格的运动轨迹,分别计算原始帧与重定向帧对应相邻网格运动轨迹的偏移量,对比二者偏移量,根据运动轨迹偏移量的变化来衡量时间连续性失真。
⑥ 将所有指标分配权重进行融合,得到最终的客观评价分数。
2.1 平滑项权重设置
对平滑项的权重α减小,观察逆向重建网格的变化。图4是减小α对逆向重建网格的影响,其中①~⑥行分别是对US、Letterbox、Cropping、Warping、SC和RH这6种重定向方法。对于Letterbox、Warping和SC,随着α的减小,逆向重建网格的覆盖区域增大,如图4②、④、⑤行所示。当α=0.2时,逆向重建网格几乎完全覆盖了原始视频帧;当α=0.1时,网格的覆盖区域与α=0.2几乎一致,但是出现了部分网格交叉翻转,根据视频重定向方法的原理,重定向帧的像素点不会出现交叉的情况,网格翻转是由于匹配错误导致的,因此把α减小到0.1也会导致匹配错误。通过对比图4①、③、⑥行,将α减小到0.2对US、Cropping和RH的逆向重建网格影响较小,SIFT-flow稠密匹配仍然正确,因此,接下来仅对Letterbox、Warping和SC进行分析。

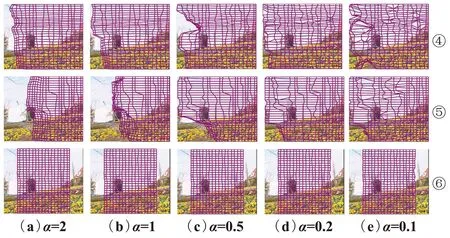
图4 α减小对逆向重建网格的影响Fig.4 Effect of α decrease on reverse reconstructed grid
对重构图与原始帧进行比较,如图5所示,第一、二行分别是SC和Warping在不同权重下的重构图。当权重取2、1、0.5和0.1时,重构图或多或少都会存在部分失真,如图中方框部分。当α=0.2时,重构图几乎与重定向帧相同。
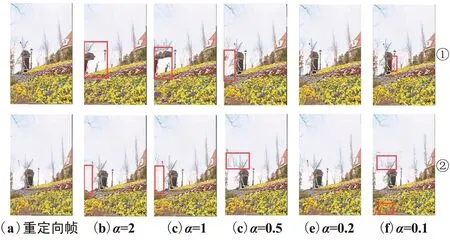
图5 α减小对重构图的影响Fig.5 Effect of α decrease on reconstructed figure
2.2 黑边检测与删除
虽然减小平滑项的权重能较好地解决SC和Warping匹配不准确的问题,但对于Letterbox仍然无法解决黑边匹配的问题,如图6所示。从图6可以看出,逆向重建网格覆盖区域变大,在重构图中,中间部分内容基本上能较好地还原,但是黑边部分仍然无法正确匹配。

图6 减小α对Letterbox的影响Fig.6 Effect of α decrease on Letterbox
为了解决Letterbox无法准确匹配的问题,本文研究了Letterbox重定向方法的原理。其原理是对原始帧进行等比例缩放,保持原始帧的宽高比,当某一边缩放到目标尺寸后,在另一边填充黑色像素点,使其达到与原始帧一样的长度。例如,要将视频的宽度缩放到原来的50%,Letterbox首先将视频的宽度和高度都缩放到原来的50%,接着在缩放视频的上下两部分填充黑色像素点,使其达到原来的高度,对高度缩放同理。黑色像素点在原始视频中是不存在的,所以无法在原始帧当中找到相匹配的点。因此,相对于其他删除或者挤压像素点的重定向方法,Letterbox即使在α=0.2的情况下,黑边部分仍无法匹配。
在进行Letterbox时,填充部分像素的RGB分量均为0,对于宽度缩小的视频,Letterbox在上下两边,对于高度缩小的视频,Letterbox在左右两侧。因此,只要检测重定向视频存在整行或者整列像素的RGB分量为0,就能检测出黑边。由于Letterbox在上下或者左右两侧,视频内容在中间,可以将识别的黑边直接裁剪,保留视频原有的内容。对于Letterbox的重定向视频,首先删除黑边,再进行SIFT-flow稠密匹配,建立逆向重建网格和重定向帧的重构图,结果如图7所示。图7(b)是检测并删除黑边之后的重定向帧,可以看到黑边被完全删除,完整地保留了中间的视频内容,并且网格覆盖全面。通过对比图7(b)和图7(c),重构图与删除黑边后的重定向帧的还原度高,因此,Letterbox删除黑边再进行匹配,能得到较好的匹配结果。

图7 删除黑边对Letterbox的影响Fig.7 Effect of remove blackedges on Letterbox
2.3 空间失真衡量
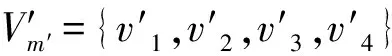
2.3.1 SGD
如果网格内容发生几何变形,则重建网格与原始均匀网格的宽高比就会变化,因此通过计算均匀网格与逆向重建网格的宽高相似度的变化得到SGD,并使用网格的重要度值作为权重。计算均匀网格与逆向重建网格的宽高相似度:
(2)
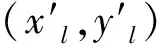
(3)
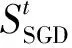
(4)
2.3.2 SSD
在重定向过程中,SSD主要表现为直线发生弯曲,线条断续,本文通过计算逆向重建网格的边在水平和垂直方向的形变来衡量SSD:
(5)
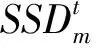
(6)
2.3.3 LIL
在重定向过程中,信息丢失会随着内容删除或挤压而产生,因此信息丢失可以通过计算重建网格的面积变化进行衡量。LIL通过计算,逆向重建网格与原始均匀网格的面积变换来衡量,如式(7)所示,其中N表示均匀网格的尺寸,本文中N=10。
(7)
2.3.4 GLR
为了衡量逆向重建网格无法匹配区域的失真,本文提出了GLR。首先根据SIFT-flow得到匹配关系,在SIFT-flow匹配图上划分均匀网格,大小与重定向帧中的一致,大小为10×10。如果网格的损失达到90%以上时,就认为部分视频内容被过度删减,局部删除的区域越大,内容丢失就越明显,重定向的效果就越差。第t帧的GLR定义如下:
(8)
式中:n是损失达到90%以上的网格数,N是网格的大小,wt是n个网格重要度值占整个原始帧重要度值的比例,H和W分别是原始帧的高和宽。
2.4 基于网格运动轨迹偏移量的时间失真衡量
虽然将平滑项权重减小能够获得较为准确的匹配,重构图的内容与重定向帧的内容几乎保持一致,但是对于内容的细节仍有部分差异,因此通过相邻2帧之间逆向重建网格的顶点坐标的变化来衡量时间失真可能会引入较大的误差,从而影响重定向视频的整体质量分数。保持时间连续性就是保持原始视频与重定向视频内容运动的一致性,避免抖动等时间伪影。如果能保持较好的时间连续性,原始视频与重定向视频对应内容的运动轨迹应该是相似的,相邻轨迹的偏移量变化也应该是一致的,如果2条轨迹之间的偏移随时间改变,这将产生运动伪影和不连贯性,因此使用运动轨迹失真(Motion Trajectory Distortion,MTD)衡量时间失真。为了减少SIFT-flow匹配引入的误差,本文使用目标跟踪算法追踪原始视频和重定向视频对应网格的运动轨迹,并通过计算相邻网格的运动轨迹的偏移量来衡量重定向视频的时间失真,称为MTD。网格跟踪如图8所示。
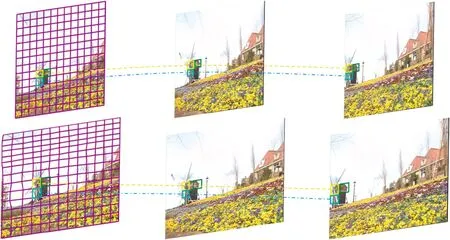
图8 网格跟踪Fig.8 Grid tracking
具体操作步骤如下:
① 首先在重定向视频的第一帧划分规则的均匀网格,并使用SIFT-flow匹配生成原始视频第一帧的跟踪网格。在Multimedia Lab(ML)数据库中,包含3种尺寸的视频,对不同尺寸的视频使用不同大小的网格进行划分,对CIF视频划分网格的大小为20×20,对720P视频划分网格的大小为50×50,对1080P视频划分网格的大小为100×100。
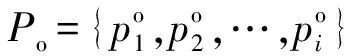
③ 得到跟踪网格的运动轨迹之后,分别计算原始帧和重定向帧中对应网格与其四邻域网格运动轨迹的偏移量,最后计算原始帧与重定向帧网格偏移量的误差,如式(9)所示:
(9)
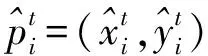
2.5 重定向视频质量客观评价指标融合
空间失真SSD由SGD、SSD、LIL和GLR线性加权得到,如式(10)所示:
SSD=α·SSGD+β·SSSD+χ·SLIL+δ·SGLR,
(10)
式中:SSGD、SSSD、SLIL和SGLR是所有视频帧的SGD、SSD、LIL和GLR的平均值,4个权重分别设置为α=0.2、β=0.2、χ=0.5和δ=0.1。SSD越小,重定向视频的空间质量就越好。
重定向视频的整体质量分数通过融合空间失真分数和时间失真分数得到,根据人眼视觉特性,人们通常更关注视频的抖动和伪影,即更注重时间连续性,因此本文将空间和时间失真的权重分别设置为μ=0.3,λ=0.7,最后融合得到重定向视频的整体质量分数SRVT,如式(11)所示:
SRVT=μ·SSD+λ·SMTD。
(11)
3 实验结果与分析
本文算法在Matlab平台实现,在Windows 10系统、Intel Core i5、12 GB RAM的环境下运行,所有实验均在公开的ML主观数据库[18]中进行。
3.1 测试数据库
ML数据库共有28个经过公认的源视频,这些视频包含了各种各样的场景、内容,其中20个视频分辨率为352 pixel×288 pixel,4个视频分辨率为1 280 pixel×720 pixel,4个视频分辨率为1 920 pixel×1 080 pixel。数据库中的视频重定向算法包括3种传统重定向方法和3种流行的方法,分别是US、Letterbox、Cropping、Warping[19]、SC[22]和RH[23]。使用上述6种重定向算法对源视频进行高度不变,宽度分别缩放50%和75%的重定向操作,得到336个重定向视频,该数据库中共包含392个视频。文献[18]随机邀请43名受试者参加实验,通过双刺激法,每次展示源视频和2种不同的重定向视频受试者根据自己的主观感受和观看感受选择视觉质量更好的结果,收集所有受试者的评价数据,进行统计分析,得到一个重定向视频质量的主观评价数据库。
3.2 实验结果对比
重定向视频的受众是人类用户,其质量的好坏由用户评判,因此主观评价是客观评价的基准,视频重定向质量客观评价结果与主观评价结果越接近,客观评价算法性能越好。本文采用肯德尔相关系数(Kendall Rank Correlation Coefficient, KRCC)[18]来衡量主观评价与客观评价之间的一致性,计算如式(12)所示:
(12)
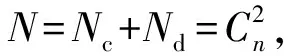
现有完整的重定向视频客观评价算法主要有:Hsu等[17]提出的基于时空质量分析评价方法、董伟鑫[18]提出的基于逆向重建网格的评价算法和赵祖翌[21]提出的基于匹配校验的网格重建评价方法。因为Li等[15]和Yan等[16]提出的方法只能衡量时间失真,所以不做比较,本文实验结果主要与Hsu等[17]、董伟鑫[18]和赵祖翌[21]的算法进行对比。在ML数据库中,将视频分为大显著区域、小显著区域、无显著区域、目标静止和背景静止5类,分别对这5类视频进行性能比较,对比结果如表1所示。其中,整体性能是数据库中所有视频的平均KRCC和KRCC的标准差。
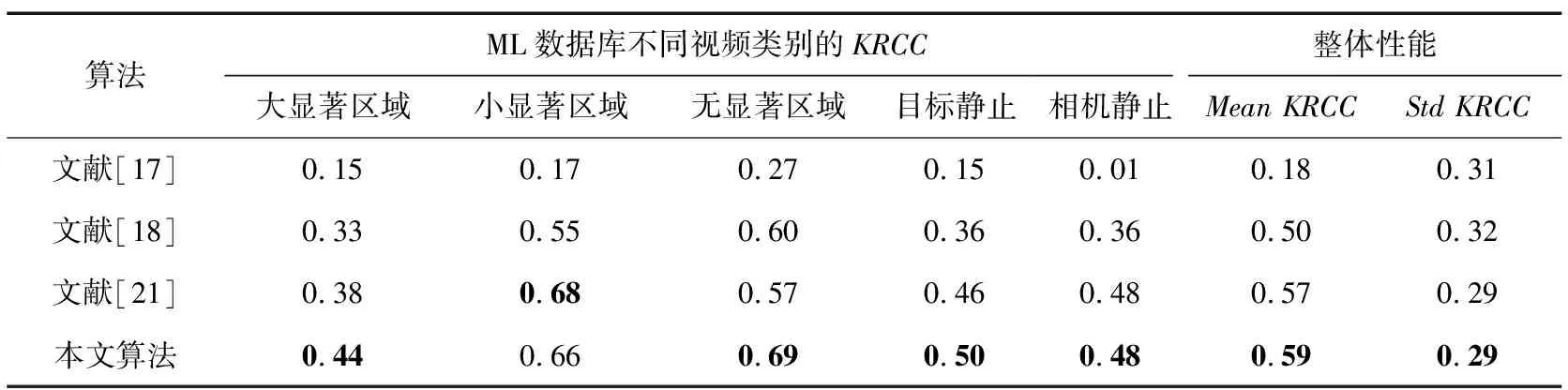
表1 客观质量评价算法性能对比
由表1可以看出,本文方法在ML数据库中,相较于Hsu等[17]和董伟鑫[18]的算法有较大幅度的提升,特别是无显著区域;与赵祖翌[21]的算法相比,本文方法在大显著区域、无显著区域和目标静止类型的视频都高于赵祖翌[21]的算法,小显著区域类视频稍低,但是差距不大;相机静止类视频与赵祖翌[21]持平。本文算法对数据库中所有视频的平均KRCC最高,整体性能和稳定性最好;KRCC的标准差也最小,稳定性较好,与主观评价结果的一致性更高。
3.3 消融实验
为了证明本文提出的预处理、GLR指标和运动轨迹偏移量的有效性,对其进行了消融实验,结果如表2所示。其中,直接匹配(Direct Matching)是在平滑项权重α=2情况下进行SIFT-flow稠密匹配,并计算2.3节中的SGD、SSD和LIL;预处理(Pre-processing)是修改平滑项权重和删除黑边操作,并求出SGD、SSD和LIL;GLR是2.3节提出的GLR指标,MTD是2.4节提出的时间失真衡量指标。在消融实验中设置的权重与2.5节一致。

表2 消融实验
在消融实验中共进行了6组实验:直接匹配+运动轨迹偏移量、直接匹配+GLR、直接匹配+GLR +运动轨迹偏移量、预处理+运动轨迹偏移量、预处理+GLR和预处理+GLR +运动轨迹偏移量。实验在相同的运行环境中进行。
为了证明本文提出的预处理的有效性,本文将第一组和第四组、第二组和第五组,第三组和第六组进行对比,从表2中可以看出,无论从视频类别还是整体性能的角度,预处理的结果均比直接匹配的结果好,这充分表明减小平滑项权重值和删除黑边有着明显的效果,减小了SIFT-flow稠密匹配错误,逆向重建网格能更好地衡量重定向视频的时空失真。
为了证明GLR的有效性,本文将第一组和第三组、第四组和第六组进行比较,第三组的整体平均KRCC比第一组高0.019,第六组的整体平均KRCC比第四组高0.06,这是因为在直接匹配时,稠密匹配错误较大,导致得到的GLR不准确。当进行预处理之后,减小了稠密匹配错误,加入GLR对整体性能有着较大提升。
为了证明本文提出使用运动轨迹偏移量衡量时间连续性失真的有效性,本文将第二组和第三组、第五组和第六组进行比较。通过表2可以看出,第三组的整体KRCC比第二组高0.091,第六组的整体KRCC比第五组高0.124,并且第三和第六组不同视频类别均明显高于第二和第五组。
综上所述,本文提出的算法能有效地评估重定向视频的空间和时间失真,可以为选择重定向方法提供科学参考。
4 结束语
本文提出一种基于逆向重建和运动轨迹偏移的VRQA算法,对文献[18]存在的问题进行了改进。首先,本文将平滑项权重修改为0.2并删除重定向视频的黑边,改善了SIFT-flow的匹配准确性;接着,提出了GLR指标,解决了无法衡量逆向重建网格未匹配区域失真的问题;最后,提出使用原始帧与重定向帧中相邻网格运动轨迹偏移量的误差来衡量时间失真,进一步减少错误匹配对算法性能的影响。实验结果表明,本文算法与ML主观数据库的相关性达到了0.593,与其他算法相比,该算法的性能有了较大提升,能够更加全面准确地衡量重定向视频的客观质量。
本文提出的算法与主观结果的相关性较高,但也存在一些问题,如该算法均在局部上衡量时空失真,忽略了内容全局失真对主观感受的影响。接下来可对重定向视频的全局时空失真做进一步研究。
