基于傅里叶卷积的多通道语音增强
2024-03-05孙思雨张海剑陈佳佳
孙思雨,张海剑,陈佳佳
(武汉大学 电子信息学院,湖北 武汉 430072)
0 引言
语音增强问题是语音信号处理领域的研究热点,广泛应用于助听器、远场语音识别等语音通信场景[1-4]。语音增强的目标在于从嘈杂的混合语音中提取出纯净人声信号,抑制背景噪声,从而提高各种语音通信场景下的语音质量和可懂度。语音增强通常分为单通道语音增强和多通道语音增强。与单通道语音增强仅使用混合语音波形或频谱作为算法输入来估计纯净语音不同,多通道语音增强还能利用阵列结构中包含的空间信息来辅助算法提取纯净语音,从而在更复杂的实际声学场景中提升语音质量与清晰度。传统的语音增强技术主要基于波束形成(Beamforming),通过增强来自目标方向的信号并抑制其他方向的信号来实现空间滤波[5],如最小方差无失真响应(Minimum Variance Distortion-less Response, MVDR)波束形成器[6]和广义特征值(Ge-neralized Eigenvalue, GEV)波束形成器[7]等。
随着深度学习在语音信号处理领域的兴起,传统的波束形成器开始结合深度神经网络(Deep Neural Network, DNN)构成了广义的神经波束形成器。得益于单通道语音增强技术的蓬勃发展,许多多通道语音增强技术通常是对单通道语音增强技术的简单扩展。文献[8-9]展示了多通道语音增强技术对每个通道的混合信号应用单通道语音增强网络,来并行预测对应通道的时频掩码,接着利用这些时频掩码来计算空间协方差矩阵,进而利用统计优化准则去推导出MVDR波束权值。由于最终权重估计的准确度显著依赖于第一阶段的掩码估计,在低信噪比、强混响等不利的声学条件下,前一阶段的掩码估计精度会下降,带来的掩码预测误差将会严重影响最终波束权值估计的准确度。另一种多通道增强策略是显式或隐式地将空间信息作为联合特征,喂给网络去直接估计阵列参考麦克风通道对应的掩码,或多个通道的波束权值。一种典型的显式方法是直接利用输入信号的相位来手动提取通道间相位差(Inter-channel Phase Difference, IPD)作为辅助特征,显式地为输入特征添加空间信息[10]。常用的隐式方法是将多通道输入信号经过时频变换后,将得到的复数谱的实部和虚部在通道维度进行堆叠作为输入特征送给网络去预测目标信号的复数时频掩码,这样就将空间信息隐式地引入到输入特征中[11-13]。上述策略本质上仍然沿用了单通道语音增强网络的拓扑结构,没有充分利用传统波束形成方法可以进行空间滤波的优势[14],对于实际中更复杂的声学环境,这些算法的性能将会达到瓶颈。
最近,一些神经波束形成器的范式被提出。一类基于时域处理,如文献[15]提出的FasNet在时域估计滤波器系数进行滤波求和。另一类是在时频域进行处理,如文献[16]提出了一种新的神经波束形成器的范式名为全深度学习的MVDR(All Deep Learning MVDR, ADL-MVDR),ADL-MVDR用不同的网络模块来模拟传统MVDR计算空间协方差矩阵和求解波束权值的过程,并将这些网络模块集成到一个端到端网络中。受该方法的启发,文献[14]提出了一种嵌入波束网络(Embedding and Beamforming Network, EaBNet),与直接显式地计算空间协方差矩阵不同,其在嵌入模块提取包含空间信息和频谱信息的嵌入张量,在波束模块采用网络的形式模拟波束权值计算过程。
尽管EaBNet展示了非常可观的语音增强性能,但起决定性作用的嵌入模块感受野有限,从而导致提取的嵌入张量中包含的频谱和时间上下文信息不足。为解决以上问题,本文在嵌入模块中引入傅里叶卷积[17]来增大频率维度感受野,以及时频卷积模块(Time Frequency Convolutional Module, TFCM)[18]对时间上下文信息进行捕捉。此外添加注意力机制[19],进一步扩大感受野,更好地从输入特征图中提取上下文信息。快速傅里叶卷积(Fast Fourier Convolution, FFC)的全局分支具有整个图像范围的感受野,并在文献[20]中被证明适用于捕捉周期性结构。TFCM的原理与时间卷积网络(Temporal Convolutional Network, TCN)[21]类似,均采用深度扩张卷积来实现对长时时序依赖建模,本文采用TFCM在编解码器中捕获时间上下文信息。在注意力机制方面,本文主要考虑空间注意力和通道注意力[19, 22-23]。基于以上几种算子,本文提出了基于傅里叶卷积的上下文特征提取器,结合FFC全局分支和TFCM的特点,更好地从输入特征图中学习频谱上下文信息。在此基础上同时采用了一种新的卷积循环网络(Convolutional Recurrent Network, CRN)结构来替换EaBNet中的嵌入模块,用来学习包含丰富空间和频谱联合信息的嵌入张量,其编解码器中嵌入了前述上下文特征提取器,并在跳连接部分嵌入卷积注意力模块(Convolutional Block Attention Mo-dule, CBAM)[19],以更好地实现信息在网络中的流通并学习跨通道间的特征。为了在不降低性能的前提下实现更轻量级的模型,采用深度反馈顺序记忆网络(Deep Feedback Sequential Memory Network, DFSMN)作为CRN中的循环模块对长时依赖关系进行建模[24-25]。所提模型在增强性能方面优于原始的EaBNet,并且在2021年远场语音识别比赛官方提供的开发集上达到了最优的效果。下面将详细介绍本文所提出的基于傅里叶卷积的多通道语音增强方法。
1 问题描述
假设混响室内有M个麦克风来记录语音信号,第m个麦克风输出的信号经过短时傅里叶变换(Short-Time Fourier Transform, STFT)后可表示为:
(1)
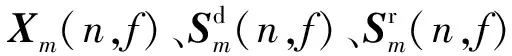
(2)
式中:{·}*表示共轭操作,Wm(n,f)表示第m个通道对应的波束权值。通过对估计得到的目标语谱图进行逆短时傅里叶变换(Inverse STFT, ISTFT)得到最终增强的时域信号。
2 所提多通道语音增强模型
本文所提的多通道语音增强系统如图1所示,其中包含了一个提取嵌入张量的CRN模块和计算波束权值的长短时记忆(Long Short-Term Memory, LSTM)模块以及全连接层。输入噪声谱经过STFT后得到时频域语谱图D∈B×M×F×T,其中B、M、F和T分别表示块大小(batch size)、输入通道数(一般指麦克风个数)、频点个数以及帧数。将实数谱与复数谱在通道维度堆叠得到输入带噪复数谱C∈B×2M×F×T,将输入带噪复数谱作为网络输入估计波束权值。图1中CRN结构用来提取包含空间信息和频谱信息的嵌入张量,接着通过2层堆叠的LSTM结构导出波束权重。估计出的滤波系数用来对对应通道的噪声复数谱按照式(2)进行滤波,最后将每个通道滤波得到的语谱图相加再经过ISTFT得到目标信号。
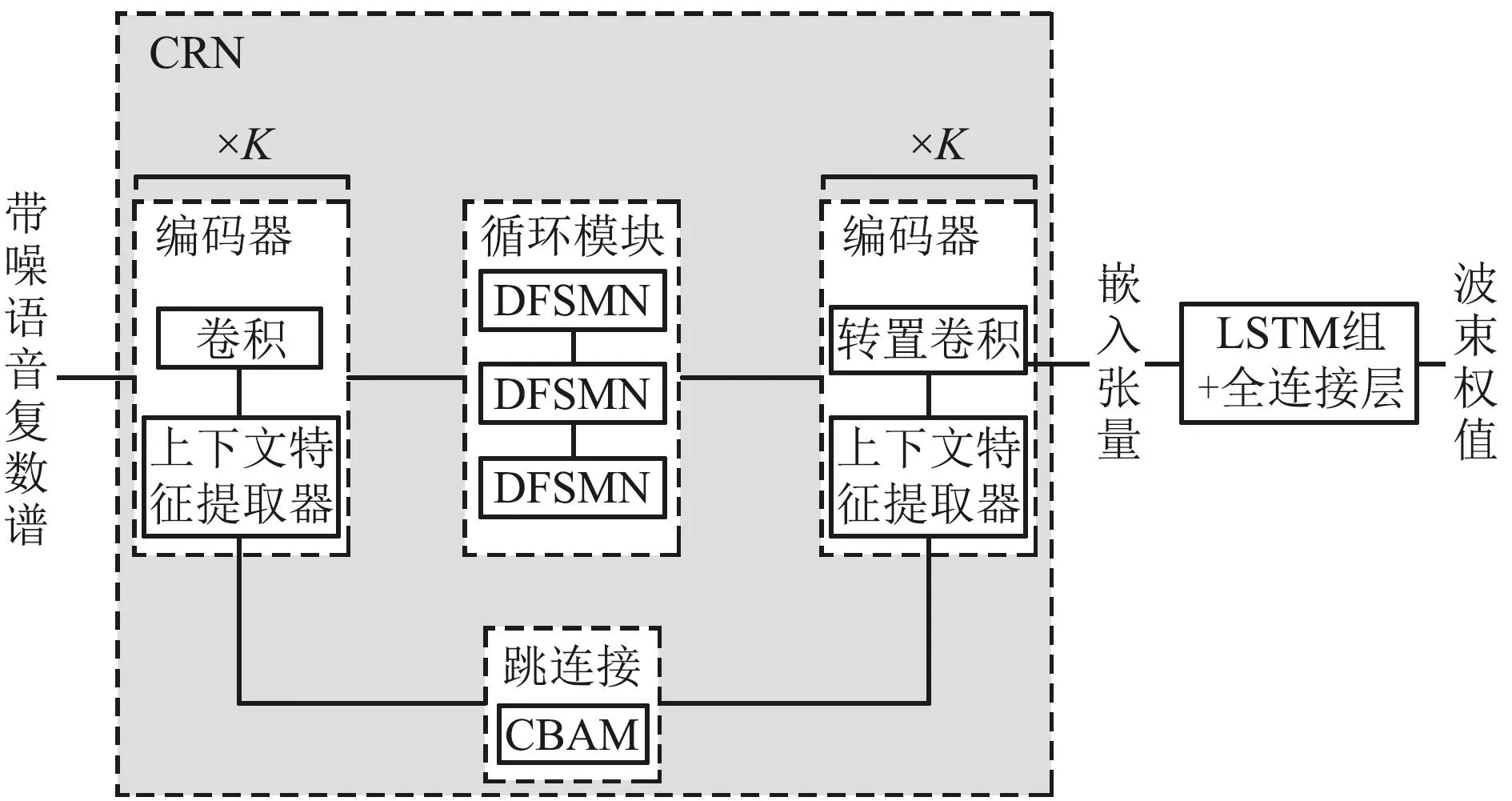
图1 算法流程Fig.1 Flowchart of the proposed algorithm
由于嵌入张量的提取准确度将直接影响最终波束形成权值估计的准确性。因此对于嵌入模块CRN的设置至关重要。经典的CRN结构仅在循环模块中考虑对时间上下文之间的依赖性建模,由于其突出的性能,许多CRN结构被广泛应用于增强任务中[25-28]。经典的CRN结构的编解码器模块常采用简单的卷积结构,对上下文信息的捕捉能力有限,在不利的声学条件下,随着目标语音所受的干扰增加,时间与频率上下文信息对纯净信号的恢复变得至关重要,常用的CRN结构性能将会到达瓶颈。
为了处理常用CRN结构中编解码器捕捉上下文信息能力有限的问题,提出了一种基于傅里叶卷积的大感受野的CRN结构,如图1所示。所提出的CRN结构包含K组编解码器结构、由DFSMN组成的循环模块,以及由CBAM组成的跳连接模块。相比传统的CRN结构,本文所提CRN结构在编解码器模块部分具有较大感受野,能充分从输入特征中捕捉频谱-空间联合信息,用于学习嵌入向量。
2.1 编解码器
本文所提编解码器结构如图2所示,归一化采用二维块归一化(BatchNorm2d),PReLU为激活函数,用来为网络增加非线性映射能力。输入语谱图经过二维卷积映射到高维后,再通过上下文特征提取器捕捉时频上下文特征。设第l个编码器的输入特征为F∈C×F×T,经过卷积模块时的运算过程为:
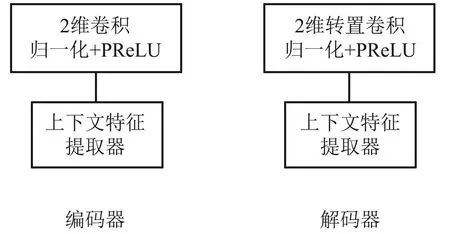
图2 编解码器结构Fig.2 Structure of the encoder and decoder
G=δ(BN(W1F))∈C′×F′×T′,
(3)
式中:C、C′分别为2维卷积的输入通道数和输出通道数,G为上采样后的特征图,W1为该二维卷积的权重,δ(·)为PReLU激活函数,BN(·)表示块归一化。接着将特征图G送入上下文特征提取器进行特征提取。
上下文特征提取器由傅里叶卷积的全局分支和TFCM组成,如图3所示。傅里叶卷积中包含了一个由传统卷积操作组成的局部分支,以及一个对输入特征图进行离散傅里叶变换的全局分支。傅里叶卷积的全局分支具有全图像域的感受野,这是由于离散傅里叶变换(Discrete Fourier Transform, DFT)在变换域上任意一点的更新将会对原始域的信号产生全局影响[17, 20, 29]。因此本文对特征图的频率维度进行傅里叶变换,以在频率特征维度上获得全局感受野。

图3 所提上下文特征提取器Fig.3 Proposed context feature extractor
此外,为了进一步提高对时间上下文信息的捕捉能力,本文引入了TFCM[17]对时序依赖信息进行建模,TFCM与TCN[21]原理类似,均采用深度扩张卷积来实现上下文建模,不同点在于TFCM采用二维深度卷积。
上下文特征提取器采用2个分支对输入特征图G进行并行处理。左分支用傅里叶变换操作来提取频率维度的上下文信息,右分支用TFCM组提取时间上下文信息。
在左分支中,首先将特征图G通过一个CBAM,CBAM由2个门控注意力模块组成,分别为空间注意力模块和通道注意力模块,详见文献[15]。对于一个输入CBAM的特征图G,计算过程为:
Q=SA(CA(G))∈C′×F′×T′,
(4)
式中:
CA(G)=G*σ(W2(δ(Avg(G))+δ(Max(G)))),
(5)
SA(G)=G*σ(W3([Avg(G);Max(G)])),
(6)
SA(·)、CA(·)分别表示空间注意力模块和通道注意力模块,通过对输入特征产生不同的权重,再将这些权重作用于输入特征上,从而从输入特征中提取空间-频谱联合信息;σ(·)表示sigmoid函数,W2、W3分别表示二维卷积权重,Avg(·)、Max(·)分别表示平均池化和最大池化操作。
接着对特征图Q在频率维度做一维实数傅里叶变换,得到一个新的复值特征图:
H=f(Q)∈C′×F′/2×T′,
(7)
式中:f(·)表示一维实数傅里叶变换。接着将复值特征图的实部与虚部在通道维度堆叠得到一个实数值张量H′∈2C′×F′/2×T′,接着用一个1×1卷积模块对变换域的特征H′进行更新:
A=δ(BN(W4H′))∈2C′×F′×T′,
(8)
式中:W4为逐点卷积的权重。接着对特征图A的通道维度进行切分,将其分为两部分作为实部和虚部去组成一个新的复值特征图用于逆傅里叶变换:
Jr,Ji=chunk(A)∈C′×F′/2×T′,
(9)
K=f′(Jr+Ji*i)∈C′×F′×T′,
(10)
式中:chunk(·)表示在通道维度将张量切分为两部分,f′(·)表示一维逆傅里叶变换。
在右分支中,采用一组TFCM连接,通过控制深度扩张卷积中的扩张因子大小来实现时间上下文建模。右分支中包含L个TFCM,扩张因子分别为20,21,…,2L-1。最后将左分支和右分支得到的结果相加再经过逐点卷积得到一个编码器的输出。
左右分支分别提取频率上下文和时间上下文信息,这使得所提出的傅里叶卷积编码器具有较大感受野和较强的特征提取能力。此外,频率维度的全局感受野有助于傅里叶卷积编码器更好地从输入语谱图中学习谐波间的相关信息。
解码器首先采用转置卷积对高维特征图进行下采样,将特征图恢复到低维空间,接着再将其通过所提的上下文特征提取模块对特征图进行恢复。
2.2 循环模块
DFSMN是在前馈全连接层的基础上,在其隐藏层中加入了一个记忆单元,记忆单元的作用是对该隐藏状态的前后单元进行编码,从而捕捉序列的上下文信息,具体可参见文献[23-24]。在本文中,最后一层编码器的输入为M∈C×F×T,将其变换为一组序列S∈(C×F)×T送入DFSMN。对于一个时刻t,对序列st∈C×F处理过程为:
(11)
(12)
(13)
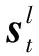
2.3 损失函数
本文采用2种损失函数来衡量增强信号与参考信号的相似度。第一种采用常用的SI-SNR,用来衡量增强信号与参考信号的时域相似度。SI-SNR的计算过程可以表示为[28]:
(14)
(15)
(16)

第二种采用联合幂律压缩谱和非对称损失函数来提升语音识别感知准确度,并防止对噪声过抑制。它主要由压缩幅度谱Lmag、压缩复数谱Lspec以及非对称压缩幅度谱Lasym组成[30]:
L2=Lmag+Lspec+Lasym,
(17)
(18)
(19)
(20)
(21)
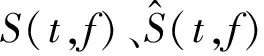
3 实验
3.1 实验数据与设置
实验数据来自2021年远场语音增强比赛所提供的数据集[31]。纯净语音数据选自AISHELL-1[32]、AISHELL-3[33]、VCTK[34]以及LibriSpeech(train-clean-360)[35]四个语料库,从每个数据集中挑选10 000条信噪比大于15 dB的语音段用来生成训练数据,对训练数据填充或剪裁到4 s。噪声数据来自于开源的MUSAN[36]和AudioSet[37]语料库。麦克风阵列设置为间隔为5 cm,包含8个麦克风的均匀线阵,并采用镜像方法[38]生成超过5 000个多通道房间脉冲响应(Room Impulse Response, RIR)。仿真生成的房间长宽高随机设置为3~8 m、3~8 m、3~3.5 m。混响时间随机设置为0.1~0.9 s。语音和噪声的位置随机,与麦克风阵列间的位置间隔随机设置为0.5~5 m,并设置语音与噪声间隔大于20°。目标语音和干扰噪声随机以-5~25 dB的信噪比混合。验证集按照官方提供的纯净语音集和噪声集生成。最后,生成了大约60 000组训练数据集和1 600组噪声数据集。
本文在2021年远场语音增强比赛官方提供的开发集上验证算法的性能。采用4个客观指标对性能进行评估:感知语音质量(Perceptual Evaluation of Speech Quality, PESQ)[39]、短时客观可理解性(Short Time Objective Intelligibility, STOI)[40]、扩展短时客观可理解性(Extended STOI, E-STOI)[41]以及尺度不变信噪比(Scale-invariant SNR, Si-SNR)。
3.2 网络设置
首先将所有的语音信号重采样到16 kHz,训练数据填充或剪裁到4 s,验证数据填充或剪裁到6 s。采用20 ms的汉宁窗对语音段进行分帧,帧移为10 ms。对每帧信号进行512点的STFT变换,将信号从时域变换到时频域。对于所提的CRN结构,其中包含5对编解码器,编解码器中卷积参数设置如表所示。此外,每个编码器中包含5个TFCM。循环模块的DFSMN结构共享网络权值,均包含64个隐藏单元。波束权值推理部分由2个包含64个隐藏单元的LSTM模块堆叠而成。本文采用ADAM优化器对网络模型进行参数优化,初始学习率设置为0.001,如果在验证集上计算的损失值连续2个周期都不下降,则将学习率减半。

表1 编码器卷积参数设置
3.3 实验结果
本文首先在2021年远场语音增强比赛官方提供的开发集上评估了所提方法的性能,损失函数采用L1损失函数,并与4个较优的基线系统进行了比较,方法分别为:oracle MVDR、文献[17]方法、MIMO-Net[10]和EaBNet[12]。其中,oracle MVDR为理想条件下的MVDR波束形成器,利用参考信号估计出目标语音对应的导向矢量,再使用MVDR波束形成器对导向矢量对应的方向进行空间滤波,以估计目标纯净语音;文献[17]的模型在比赛提供的开发集上表现出较好的性能,其在DCCRN[28]的基础上提出了复数空间注意力和通道注意力模块用来提取空间信息;MIMO-Net在2021年远场语音增强比赛中获得第一名,其采用一个简单的因果Unet网络来估计波束权值,采用滤波求和操作实现空间滤波;EaBNet是2022年中科院声学所提出的多通道语音增强模型,是目前一种较为先进的多通道增强方法。表2展示了5个模型在比赛官方提供的开发集上的客观指标。从表2可看出,所提方法大大优于比赛官方所提供的基线系统,也优于其他对比方法,达到了最优性能,这有力地说明了所提方法能有效从输入混合信号中提取频谱和空间联合信息,从而提高增强后的语音质量。同时,与其他方法相比,所提模型参数量较小,进一步说明了所提方法的有效性。
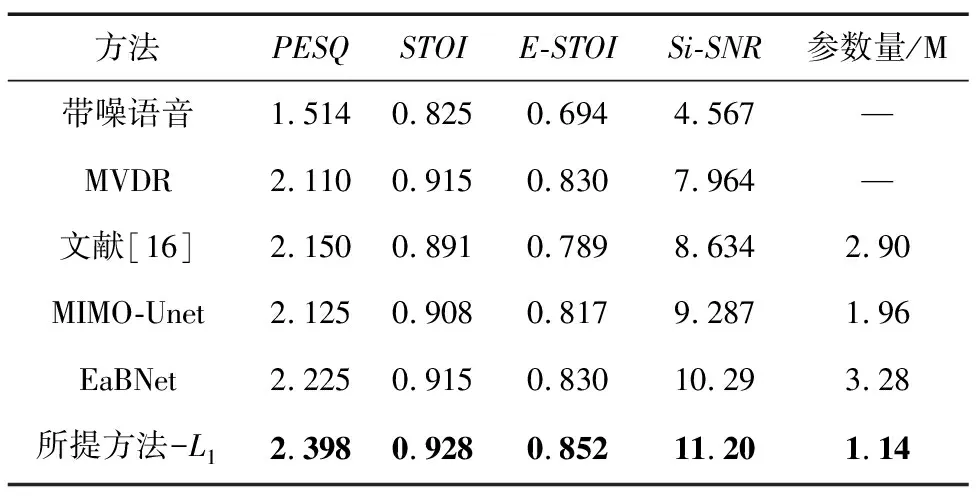
表2 开发集上增强结果
为了更全面地对模型效果进行分析,本文从LibriSpeech数据集中随机抽取与训练集不重合的2 000条语音段作为纯净语音,并从AudioSet中抽取2 000条噪声作为噪声集。将每条噪声和语音填充或剪裁到6 s,分别在-5、0、5 dB的信噪比条件下生成测试数据,验证本文模型在低信噪比环境下的增强效果。其中每种低信噪比条件下仿真生成的RIR混响时间为[0.1, 0.9]s,按照均匀采样的方式随机从上述范围中选择一个混响时间生成每条RIR。表3展示了低信噪比下本文所提方法和对比算法的结果,该实验中采用的模型是使用L1损失函数训练好的模型。从表3整体来看,随着信噪比的降低,所有方法的性能均下降,但所提方法在每种信噪比条件下都展示出最优的性能。此外,随着信噪比降低,所提方法与EaBNet的差距逐渐增加,这表明所提方法能在低信噪比条件下更好地从输入多通道信号中提取重要频谱-空间联合信息用以区分噪声信号和语音信号。
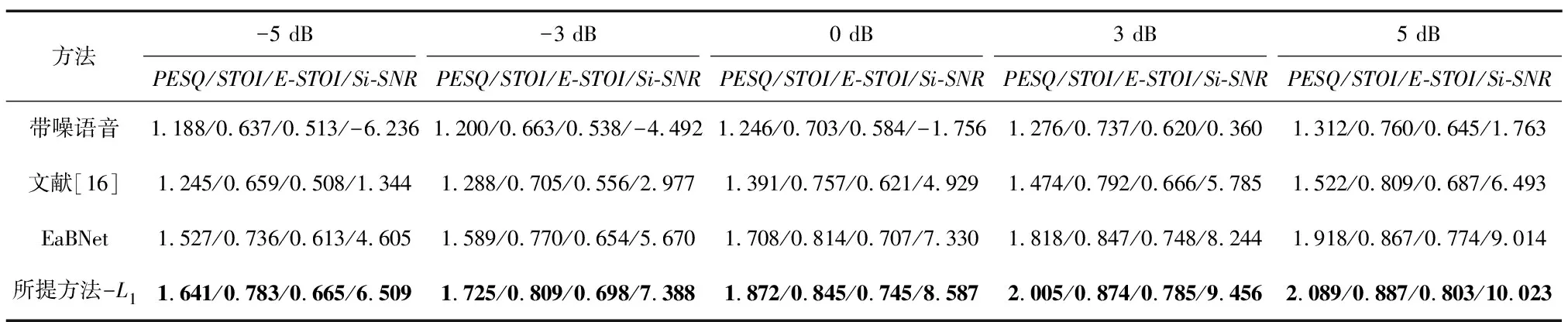
表3 不同信噪比下的客观指标对比
此外,为了验证所提模型在不同混响程度下的增强效果,采用表3实验中抽取的纯净语音和噪声语音分别在[0.1, 0.3]s、[0.3, 0.6]s以及[0.6, 1.0]s三种范围下分别生成1 000条RIR。每种条件下生成RIR时,其混响时间都在所对应的范围内均匀采样获得。生成的RIR与纯净语音和噪声进行卷积得到带噪语音,每条带噪语音的信噪比均为5 dB。表4展示了不同混响时间下所提算法与对比算法的实验结果。从表4可以看出,在混响时间较小时,所提方法与对比方法都展现了较好结果。随着混响时间增加,所有方法的性能都大幅下降,尤其是在混响时间接近0.9 s时,这是由于混响较大时,空间混叠增加,目标语音的空间信息受到较大干扰,从而导致空间信息提取困难,但本文所提方法仍大幅优于其他方法,也证明了本文方法在捕捉空间-频谱信息方面的优越性。

表4 不同混响时间下的客观指标对比
为验证2种损失函数的性能,本文在2021年远场语音增强比赛官方提供的开发集上评估了2种损失函数的性能,结果如表5所示。从表5可以看出,第二种混合损失函数L2整体优于Si-SNR损失函数L1,除了Si-SNR指标,这说明幂律压缩谱损失函数能有效提高增强语音的感知度,故PESQ指标会明显优于L1损失函数。

表5 不同损失函数结果对比
4 结束语
本文针对大多数多通道语音增强网络缺乏对频谱上下文充分学习的问题,提出了一种基于傅里叶卷积编码器的卷积循环编解码器CRN。所提傅里叶卷积编码器以FFC为基础,集成了注意力机制以及TFCM,用来扩大卷积感受野,从而更好地从输入语谱图中捕捉空间-频谱联合信息。此外在所提CRED中采用DFSMN作为循环模块对时间上下文进行建模,大大减小网络整体参数量。实验结果表明,所提方法优于其他基线,且网络参数量更小。此外,本文讨论了2种损失函数的性能,实验结果表明,联合幂律压缩谱损失函数能获得更高的PESQ结果。
