一种融合注意力机制的形变LSTM智能代码补全方法
2024-02-27邹海涛于化龙
张 钦,郑 尚,邹海涛,于化龙,高 尚
(江苏科技大学 计算机学院,江苏 镇江 212100)
0 引 言
代码补全已成为集成开发环境的关键功能之一,其主要基于开发人员的输入和已有程序代码,实时预测待补全代码,并为开发人员提供建议列表,有效地提高了软件项目的开发效率.研究表明,在软件开发过程中,开发人员每分钟都会使用一次集成环境的代码补全插件[1].
近年来,随着软件代码和数据规模不断扩大,智能代码补全技术已成为软件工程领域的热门研究方向之一.Hindle[2]等人首次将代码看作自然语言,并且运用了N-gram模型处理代码补全问题.此后,许多研究人员利用N-gram模型研究代码补全任务[2-4].然而,由于直接对代码序列进行建模无法生成语法正确的代码,Liu[5]等人和Li[6]等人通过将目标语言生成抽象语法树(Abstract Syntax Tree,AST)缓解上述问题,Liu和Li等人的工作包含了代码补全中的类型(type)及值(value)预测,其为智能代码补全提供了非常重要的建议.虽然基于自然语言技术的代码补全方法不断改进优化性能,但是仍无法从根本上解决N-gram模型无法获取长距离关系的问题,研究者们仍需新的方法去解决这个问题.
近年来,鉴于深度学习的成功,循环神经网络已经被广泛应用于代码补全,其将代码表征为AST序列,并按照深度优先遍历顺序将其展开成节点序列,进而构建指针网络、LSTM等模型捕获长距离的依赖关系,最后根据给定代码序列,模型通过计算推荐概率最高节点完成补全任务.鉴于AST的每一个节点有两种属性,类别(type)和值(value),因此,多数基于AST的代码补全模型是分别单独对类别(type)补全和值(value)补全,且属于单任务预测.鉴于此,Liu[7]等人构建双向LSTM获取路径信息,以此补充节点序列缺少的结构信息,并提出一种多任务学习(Multi Tasks Learning,MTL)框架,Liu等人通过手动的为两个子任务设置权重参数平衡类别(type)和值(value)的预测,实验结果显示了多任务框架的效果要优于单独训练两个模型.
前人工作从多个角度对代码补全展开研究并已经取得了不错的效果,但是还存在一些问题,主要有如下几个方面:
1)模型获取代码的上下文信息能力有待提高.
2)多任务学习框架中代码补全任务平衡仍有待改进.
因此,为了缓解上述问题对代码补全准确率的影响,本文提出一种新的代码补全方法.其中,通过借鉴与Liu[7]等人工作,本文利用双向长短期记忆网络增加程序的结构信息,同时引入形变LSTM,即Mogrifier-LSTM[8],将其与注意力机制结合增强代码上下文信息表示,并改进Liu[7]等人的多任务学习框架,使模型在训练过程中能够自动调整权重参数,保证代码补全任同步执行.最后,本文方法在预测时进行了参数绑定(weight tying)[9]操作,其通过绑定输出编码矩阵(input embedding)和输入编码矩阵(output embedding),减少模型参数.综上所述,本文的主要贡献如下:
1)首次采用Mogrifier-LSTM模型与注意力机制捕获代码中的长期上下文依赖.
2)提出一种新的多任务学习框架自动平衡两个子任务的权重.
3)输出层使用参数绑定,减少了模型参数.
本文方法在代码补全的标准数据集上进行实验验证,结果表明:与最先进的模型相比,本文模型达到了最好的预测性能.
1 相关概念
1.1 抽象语法树
抽象语法树(AST)是一种树形结构的数据,其包含了源代码的句法信息.图1展示了一段Python示例代码及其抽象语法树.

图1 抽象语法树示例Fig.1 Example of abstract syntax tree
1.2 Mogrifier-LSTM
Gabor[8]等人指出,现有神经网络模型在处理自然语言时受制于泛化能力有限和样本的复杂性.为了提升模型的泛化能力,Gabor等人对长短期记忆网络做了改进.对于给定一个输入序列{x1,x2,…,xt},传统LSTM[10]的计算过程如下:
in=σ(xnWxi+hhi+bi)
(1)
fn=σ(xnWxf+hn-1Whf+bf)
(2)
on=σ(xnWxo+hn-1Who+bo)
(3)
(4)
(5)
hn=on⊙tanh(cn)
(6)
Wxi,Wxf,Wxo,Wxc,Whi,Whf,Who,Whc是参数矩阵;bi,bf,bo,bc为偏执项;xn是第n个时刻的输入,hn-1是上一个时刻的隐藏状态.图2表示了传统LSTM的基本架构.
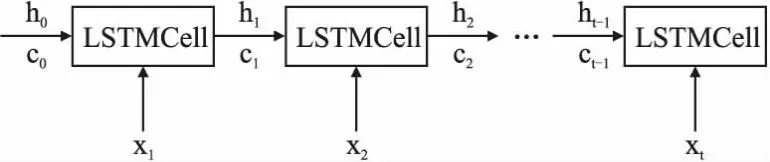
图2 长短期记忆网络Fig.2 Long-short term memory
鉴于传统LSTM的输入和状态只在其内部进行交互,这可能会导致上下文信息的丢失.Mogrifier-LSTM[8]对传统LSTM进行了改进,通过进行输入x与隐藏状态的交互,增强了模型的泛化能力,具体过程如图3所示.
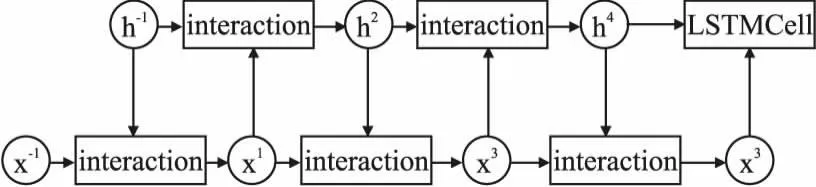
图3 形变长短期记忆网络Fig.3 Mogrifier-LSTM
当x和h输入到LSTM之前已经进行了多轮的交互计算,这个计算过程可通过公式(7)和公式(8)表示:
(7)
其中i为奇数,并且i∈[1,…,r].
(8)
其中i为偶数,并且i∈[1,…,r].
x-1为当前时刻的输入x,h-1为上一个时刻的隐藏状态h,Qi和Ri是可学习的参数矩阵,r为超参数,其代表了输入x与隐藏状态之间交互的次数,⊙是哈达玛积.经前人工作验证,Mogrifier-LSTM比原始的LSTM效果要好.因此,本文将其首次引入代码补全任务进行上下文信息表示.
1.3 注意力机制
注意力机制[11]在一定程度上提升了神经网络处理长序列问题的能力,Li[6]等人将指针网络和注意力机制结合在一起,取得了良好的效果.
鉴于此,本文考虑将注意力机制与Mogrifier-LSTM进行结合,进一步地提升神经网络捕获长期上下文依赖的能力.
1.4 参数绑定
Press[9]等人通过研究神经网络语言模型的权重矩阵,建议绑定输入嵌入和输出嵌入,以此减小神经翻译模型的大小,实验结果表明在不损害其性能的情况下,模型大小为原始大小的一半,具体的过程如下所述.
当词表中的词会被表示为一个向量v,这个向量会被映射到一个稠密的空间,得到向量v1.
v1=UTv
(9)
其中,UT被称为输入编码矩阵.向量v1经过一系列复杂的运算得到向量v2,最终,向量v2会被映射为向量v3,向量v3就代表了词表中的词汇.
v3=Kv2
(10)
其中K被称作输出编码矩阵,在大部分模型中,U和K是两个不同的矩阵,参数绑定强制U=K.
鉴于参数绑定上述的优点,本文将其添加到模型输出,减少所提模型的参数量.
1.5 多任务学习
多任务学习是一种跨任务进行知识迁移的方法,其通过归纳偏置降低过拟合的风险[12].Liu[7]等人首次将多任务学习引入到代码补全任务,其通过手动分别为type和value的预测设置权重参数,实验结果表明多任务学习能够提升代码补全的准确率,但其所提框架不能保证参数同步,即当type预测的参数为最优时,value预测的参数并非最好的.本文受Liebel[13]等人工作的启发,改进了Liu[7]等人所提多任务学习框架的损失函数,自动调整权重参数,不仅提升了代码补全任务的计算效率,同时提高了其准确率.
2 研究方法
本文方法的总体框架如图4所示.主要包含数据预处理、模型构建和模型测试3个工作.其中,数据预处理是将抽象语法树转换为节点和路径序列,模型构建主要是根据处理完的数据,训练代码补全模型.在模型验证阶段,给定一系列抽象语法树节点,训练好的补全模型用于预测下一个节点的类型和值.本节后续内容将分别对各工作进行介绍.

图4 方法总体框架Fig.4 Overall framework of method
2.1 数据预处理
数据处理过程如表1所示.在数据集预处理过程中,本文遵循Li等人[6]的方法,以图1的数据为例,首先按照深度优先遍历将AST展开成序列,分别得到两个由节点属性组成的序列,即{Moudle,FunctionDef,…,decorator_list}和{EMPTY,add,…,EMPTY}两个序列,其中“EMPTY”代表没有值属性的节点,并分别为类别属性和值属性建立词表.鉴于值属性数量庞大,所以本文选择k个出现次数最多的值属性,k={1k,10k,50k},对于未包含的值属性,使用标识符“unk”表示,对于非叶节点,使用“Empty”表示.其次,提取除根节点外节点到根节点的路径,并根据类别属性的词表将路径转换为对应的向量形式.重复上述过程获取所有类别、值以及路径的向量形式序列.

表1 数据处理步骤Table 1 Data processing steps
2.2 模型构建
对于每个AST节点的序列,本文模型将基于前r-1个节点预测其第r个节点的类型或值.为了完成上述任务,本文提出图5所示的代码补全模型,其主要包含context encoder、path encoder和output layer这3个部分,下文将逐一描述.
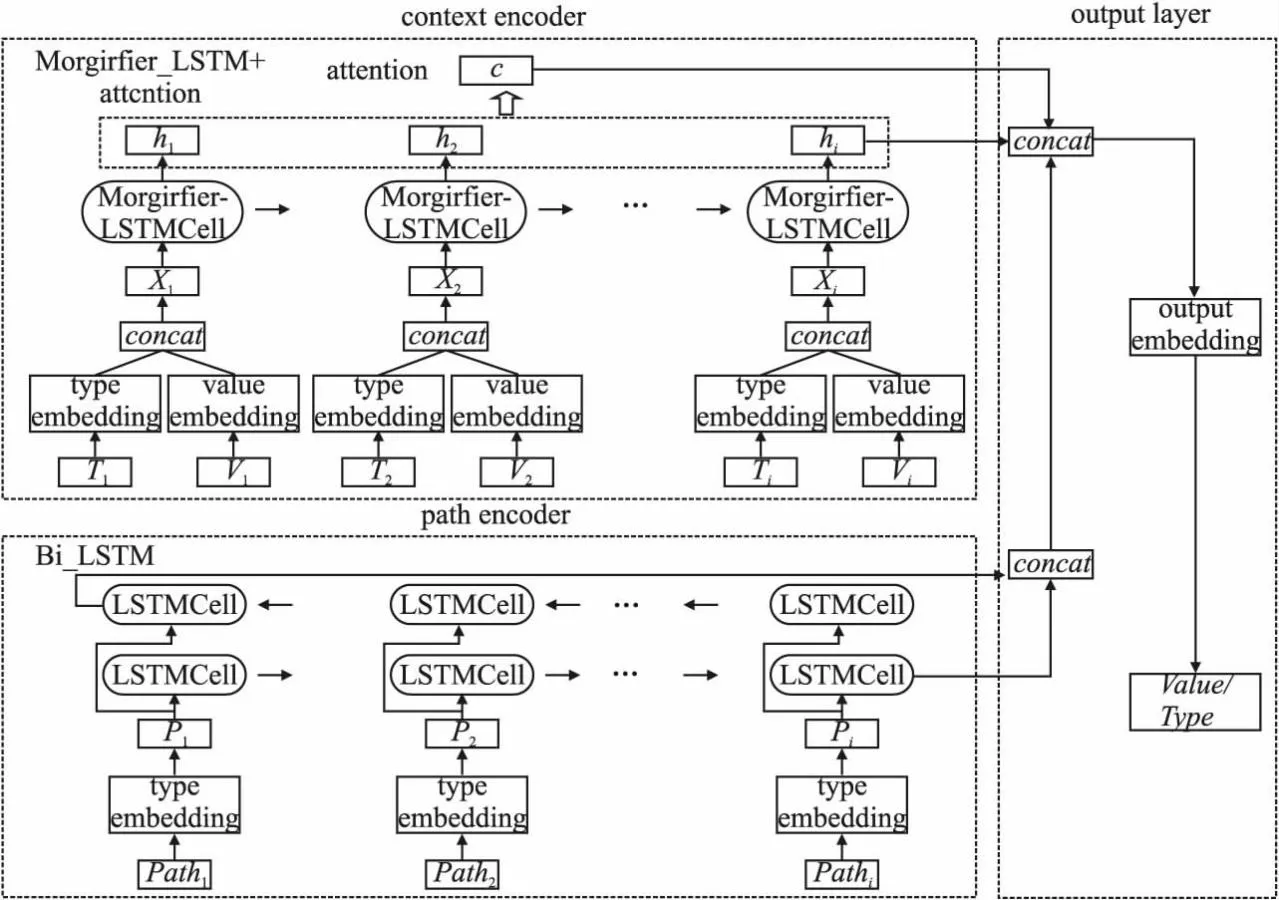
图5 模型总体架构Fig.5 Overall architecture of model
2.2.1 context encoder
context encoder是基于Mogrifier-LSTM和注意力的网络,本文首先利用word2vector将经过数据处理后的类别序列{T1,T2,…,Tt}、值序列{V1,V2,…,Vt}分别生成向量序列A、B,并对A、B中的每一个向量做向量连接,生成向量序列X.然后,本文将序列X{x1,x2,…,xt}输入Mogrifier-LSTM网络中增强代码上下文信息表示.根据Mogrifier-LSTM当前输入xi和上一个时刻的隐藏状态hi-1以及设置的交互次数r,进而计算得到当前时刻的隐藏状态hi.
A=UtypeT
(11)
B=UvalueV
(12)
X=[A;B]
(13)
hi=MogrifierLSTM(xi,hi-1,r)
(14)
其中Utype为类别输入编码矩阵,Uvalue值输入编码矩阵,“;”代表向量连接运算符.
其次,对于每一个时间步i,记录下前l个时间步的隐藏状态Mi=[hi-l,…,hi-1],根据当前隐藏状态hi与前l个时间步的隐藏状态计算注意力.
(15)
αi=softmax(atti)
(16)
(17)
其中,Sm,Sh为可训练的参数,softmax为归一化函数.c为模型抓取的上下文信息向量.
2.2.2 path encoder
path encoder是由双向长短期记忆网络组成,其目的在于利用代码的结构信息.本文首先将经过数据处理后的序列{Path1,Path2,…,Patht},然后利用word2vector模型生成向量序列P,并将序列{p1,…,pt}输入双向长短期记忆网络中,其计算过程如下.
P=Utypepath
(18)
(19)
(20)
(21)
2.2.3 output layer
本文将context encoder和path encoder的输出hi,ci,Pi输入output layer,得到预测的类别(type)和值(value).
βi=[ci,hi,Pi]
(22)
(23)
typehat=Ktypeβi
(24)
valuehat=Kvalue[βi;typehat]
(25)
其中Ktype为类别输出编码矩阵,Kvalue为值输出编码矩阵.为了减少模型参数,本层使用参数绑定强制使类别输入编码矩阵等于类别输出编码矩阵.
2.2.4 损失函数
Liu[7]等人使用的多任务学习的损失函数如下:
(26)
其中N是子任务的数量,ck是子任务的权重参数,但ck需要人工设置,不利于计算效率.受Liebel[13]等人研究工作的启发,本文将其优化的损失函数引入代码补全多任务中,使模型在训练过程中能够自动的优化子任务的权重参数,优化后的损失函数如下:
(27)
3 实验验证
3.1 实验数据集
如表2所示,本文选择前人工作[6,7]所用的Python(PY)和JavaScript(JS)数据集,其中每个数据集包含150000个程序文件和相应的AST,实验选择了10000程序文件作为训练集,50000个程序文件作为测试集.

表2 代码补全数据集Table 2 Code completion datasets
根据2.1节数据预处理所述,本文根据k个出现最频繁的值构建词表,其中k={1k,10k,50k},最终可得到6个数据集:JS1K,JS10K,JS50K,PY1K,PY10K,PY50K.
3.2 评价指标
本文采用前人工作[6,7]提及的准确率作为评价指标,其描述了正确预测的类别(type)或者值(value)占总类别(type)或值(value)的比例.
3.3 实验环境
本文实验所采用的硬件配置为:CPU 11th Gen Intel(R)core(TM)i7-11700k @ 3.60GHz,内存DIMM(64G),显卡Nvidia GeForce RTX 3060;开发环境为:Pycharm.
3.4 实验设置
本文将当前最先进的代码补全方法作为对比方法,其描述如下.
·vanillaLSTM[5]:此方法将源码表征为抽象语法树,并将其输入长短期记忆网络中(Long-short Term Memory)进行模型训练.
·ParentLSTM[6]:其对 vanillaLSTM进行了提升,计算了每一个节点与父节点的注意力.
·PoniterMitureNet[6]:其在ParentLSTM的基础上,计算了当前隐藏状态与先前时间步隐藏状态的注意力.
·GRU[14]:采用GRU作为基本模型替代了长短期记忆网络(Long-Short Term Memory,LSTM).
·Transformer[15]:此方法使用Transformer模型替代了长短期记忆网络(Long-Short Term Memory,LSTM),并且采用双向LSTM提取AST结构信息.
·Transformer-XL[7]:Liu等人采用了Transoformer-XL[16]和双向LSTM作为基本模型,并且结合了多任务学习框架,手动设置两个子任务的参数.
上述Transformer-XL和本文方法属于多任务学习.对于其他方法,值预测和类型预测皆是独立训练的.
3.5 实验分析
为了公平比较,所有方法的参数保持一致,其中embedding_size,hidden_size,batch_size大小都为128,adam[17]作为优化器,学习率为0.001,每一轮迭代后学习率乘以0.6.同时,本文中Mogrifier-LSTM层数默认值为2,交互次数为5.实验结果如表3和表4所示.

表3 不同方法在Python数据集上的准确率结果Table 3 Accuracy results of different methods on the Python datasets

表4 不同方法在 JavaScript数据集上的准确率结果Table 4 Accuracy results of different methods on the JavaScript datasets
由表3、表4的实验结果可知,本文方法的准确率高于对比方法,且类别(type)预测较其它方法提高了8%~9%,值(value)预测较其它方法提高了4.8%~14%.综上,与单任务方法相比,本文方法能够充分利用抽象语法树的结构信息,更好地捕获代码中的上下文依赖关系;与Transformer-XL多任务学习方法相比,本文所提的多任务框架效果更优.
为了阐述本文模型性能较优的原因,鉴于Liu等人[7]已讨论其所提模型优于现有单任务方法,本文则选择transformer-xl作为基线方法进行分析.图6展示了两种方法在训练集和测试集上的损失情况,Transformer-XL方法在测试集上的损失要远大于训练集,而本文模型在训练集和测试集上的损失差距情况要好于Transformer-XL方法,这表明基线模型存在过拟合的风险.同时,由图6结果可知,本文模型在测试集上的每轮迭代的损失都小于基线模型,原因如下:

图6 所提模型与基线模型在训练集和测试集上的交叉熵损失Fig.6 Cross-entropy loss on training and test datasets for the proposed model and baseline model
1)本文模型能够更好地抓取代码中的上下文信息.
2)本文多任务学习方法更有效地利用了type和value子任务之间的联系.
4 讨 论
4.1 模型训练时间和计算时间
为了评估提升的成本,本文计算了模型的参数量和模型训练所需的时间.由表5结果可知,本文模型训练时间多于其他方法,原因如下:

表5 模型参数量及训练时间Table 5 Model parameters and training time
1)本文模型基于Mogrifier-LSTM,需要按照时间步顺序计算.
2)与单任务方法相比,多任务学习框架的参数较多,训练时间也就更多.
3)虽然本文模型的参数和时间高于Transformer-XL多任务,但其所训练的模型并非最优结果,原因在于Transformer-XL的多任务框架需要手动调参,表5仅单纯计算其模型训练时间,而寻找参数的时间分析可见表9.
此外,本文衡量了各模型每一次补全的计算成本,结果如表6所示.同样地,本文所提方法每次补全所需时间略高于其他方法,原因如下:

表6 一次补全所需时间Table 6 Time required for one-time completion
1)本文采用Mogrifier-LSTM作为基本模型,无法并行计算,并且在计算时需要与隐藏状态进行交互.
2)使用了多任务学习框架,同时对type和value进行补全,在计算上要比单任务框架花费更多时间.
然而,由表3和表4的实验结果可知,本文所提模型有助于代码补全准确率的提高,且可以保证1秒内做出预测,这使其能够实时地进行代码补全.
4.2 模型各部件的作用
为了分析所提模型各个组件的作用,本文分别以JS10K和PY10K为例进行实验分析,实验结果如表7所示.

表7 模型各部件的作用Table 7 Effectiveness of each component in the model
表7中-pe、-wt、-MTL依次代表模型分别去掉path encoder、参数绑定(weight tying)、多任务学习(Multi-Tasks Learning,MTL)组件,Full表示本文完整的模型.
表7中第1行是本文模型去掉path encoder的准确率,其较完整模型类别预测低了4.5%(PY10K),5.5%(JS10K),且值预测同时也低了6%(PY10K),5.9%(JS10K),这表明了代码结构信息的重要性.
表7中第2行是去掉参数绑定的准确率,其较完整模型类别预测低了1%(PY10K),4.1%(JS10K),且值预测低了2.6%(PY10K),3.9%(JS10K).同时,本文给出了使用参数绑定前后的参数数量.如表8所示,模型参数在两个数据集上分别减少1%和3%,这将有助于计算资源有限的情况.

表8 模型参数量Table 8 Parameters of the model
表7中第3行为去掉多任务学习准确率,其中单独训练预测类别(type)的模型时,PY10K上的准确率达到了79.58%,较完整模型有0.3%的提升,但值(value)预测的准确率较完整模型低了2.4%.然而,多任务学习能够同时完成代码补全类别和值的预测,其更适用于实际应用.
综上所述,无论移除本文模型中的任一组件,代码补全准确率整体均有下降,这充分地证明了本文模型中各部件的重要性和必要性.
最后,由于Liu等人在训练时也使用了多任务学习,为了进一步验证本文多任务学习框架的优势,本文保证其他组件不变,选择Liu等人提出的多任务学习框架替代本文的多任务学习框架,并进行了实验,实验结果如表9所示.

表9 两种多任务学习对比Table 9 Comparison of two kinds of multi tasks learning
从表9的结果看出,本文基于Liu等人的多任务框架下类别和值的最好结果并不是同一组参数训练得到,且准确率与本文所提多任务框架相比,PY10K的类别(type)预测的准确率低了0.2%、值(value)预测的准确率提了0.3%;而JS10K的类别(type)预测低了0.92%、值(value)预测的准确率低了2.79%.同时,实验中基于Liu等人的多任务框架训练耗时11h,而基于本文所用多任务框架训练耗时3.5h.
综上所述,各个组件均有助于本文模型的提高代码补全多任务的准确率,同时有效地降低了多任务学习的总体时间.
5 结束语
前人工作已在代码补全任务取得了很大的突破,但其对代码上下文表示和多任务学习中子任务平衡处理仍需改进,本文提出了一种融合注意力机制的形变LSTM智能代码补全方法,此方法利用双向长短期记忆网络学习抽象语法树的代码结构信息,同时结合Mogrifier-LSTM与注意力机制提升模型对代码上下文的表示能力,并设计一种新的多任务学习框架自动寻找最优参数.最后,本文在输出层使用了参数绑定,降低了模型规模.实验结果显示,本文方法在Python和JavaScript数据集上的性能优于当前的最先进方法.
在未来工作中,本文将进一步优化所提模型,研究图神经网络在代码补全中的应用,并在更多的真实数据集上进行验证,以及考虑利用迁移学习技术解决小样本代码补全问题.
