融合语义信息和视觉推理特征的视频描述方法
2024-02-27张浩萌
张浩萌,刘 斌
(南京工业大学 计算机科学与技术学院,南京 211816)
0 引 言
随着互联网技术的不断发展,视频已成为人们日常获取信息的主要来源之一,有关视频理解的研究受到越来越多研究者的关注,其中,视频描述作为计算机视觉和自然语言处理的交叉任务,近年来已成为研究热点之一.一方面,视频描述技术的发展可以为视频检索、视频问答等领域进一步研究和优化提供原动力,另一方面,视频描述的研究在人机交互和辅助残障人士理解视频内容等方面也有一定的应用价值.
在早期阶段,视频描述的主要方法是基于模板匹配[2,3],即首先从视频中识别出显著的对象和动作,然后将其填充到预先设定好的句子模板中,这种方式所生成的描述的句法结构单一,缺乏灵活性.随着深度学习在机器翻译领域的成功应用,基于序列学习的编解码结构[4]逐渐成为视频描述的主流技术.
在编码阶段,为了得到更加精准的视觉特征,Yao等[4]引入注意力机制,该机制使得视频描述的效果得到了很大提升.近年来,时空注意力机制[5,6]得到了大家的广泛关注,即分别在时间和空间两个维度提取视觉特征作为解码器的输入,突出了显著区域的时空特征.Tan等[1]利用时空注意力机制构建时空推理模块,实现了生成过程中的可解释性.
另外,在解码阶段,近年来的研究表明,将从训练集的标签中提取到的语义特征作为先验知识融入到解码器中可以提高视频描述的准确性[7-9].Chen等[10]使用mean Average Precision(mAP,平均精度)方法来获得质量更高的语义特征.在考虑视频描述的句法结构方面,一些方法引入了视频描述的词性标签[11,12],来指导解码器生成更符合人类阅读习惯的句子.由标签提取出的语义特征有助于提高视频描述的准确性,但忽视了不同词性的语义特征在句子结构上的不同;句法结构的引入可以帮助编码器生成更符合人类阅读习惯的视频描述,但在单个词语的生成上缺乏准确性.Perez-Martin等[13]虽然提出同时结合词性信息和语义特征来生成描述,但并没有针对性的挑选视觉特征,使该描述生成过程缺乏可解释性,也造成了不相关的视觉特征对生成结果的干扰.
针对上述存在的问题,本文提出了一种兼顾句法结构和描述准确性的方法:采用结合时空注意力机制的模块推理网络[1]提取视觉特征;采用结合Part-of-Speech(POS,词性)损失函数[1]的模块选择网络挑选视觉特征;采用语义检测网络[9]提取语义特征,并使用mAp方法[10]选择语义特征;在解码过程中,尝试并比较3种不同的特征融合网络来结合视觉特征和语义特征.该方法使得在生成过程可解释的前提下,输出兼顾流畅性和准确性的视频描述.
1 相关工作
1.1 视频描述
基于模板匹配的方法[2,3]提取视频中的对象和动作,生成主语、动词和宾语,并填充到预先定义好的句子模板中,这种方式采用了固定的句法结构,只适用于特定领域的视频描述.
在基于深度学习技术的序列学习方法成功应用于机器翻译领域之后,S2VT[14]将序列到序列模型应用于视频描述领域,考虑到了视觉特征的时序信息,实现可变长度的输入和输出.
Yan等[4]采用注意力机制计算每个视频帧的权重得到加权和来预测当前单词.Cherian等[5]在使用时间注意力机制的基础上加入了空间注意力机制,进一步关注视频帧中的显著区域.Tan等[1]提出了一种视觉推理网络,引入对象特征,并使用时空注意力机制完成推理过程.
Pan等[7]通过分析标签文本和视频内容的相关性生成语义特征,使标签除了作为最终损失函数的参数外,在句子生成过程中也发挥作用,但所得到的语义特征是从文本标签中提取出来的整体表示,并没有用于指导描述生成过程中的每个时间点的单词生成.基于此,Pan等[8]将从视频中提取到的静态语义特征和动态语义特征进行融合用于指导解码阶段每个单词的生成;Zhe等[9]提出了一种语义检测网络,人工挑选在训练集和验证集中经常出现的单词,形成了每个视频的语义标签,来指导解码器生成每个单词.为了对语义质量进行评价,Chen等[10]采用mAP的方法选择最合适的语义特征.
在最近的研究中,采用POS信息以提升视频描述的流畅性,Wang等[11]将预测句子的POS信息用于指导解码器生成单词.Hou等[12]则通过推测每个单词的POS标签来选择合适的视觉线索生成单词.
Perez-Martin等[13]同时考虑到了POS信息和语义特征,但使用视频的整体特征作为输入,并没有针对性的挑选视觉特征.因此,本文所提出的视频描述方法中,既结合了语法结构和语义信息,又使用时空推理模块挑选相关的视觉特征,减少了噪音的干扰.
1.2 视觉推理
在视频描述领域,推理方法主要被用来进行常识推理和关系推理[15,16],引入先验知识指导下一个单词的生成,这种推理方式使用单一的推理网络,并没有考虑到语言中不同语法成分的组合.
神经模块网络(NMN,Neural Module Networks)[17-19]由一组神经模块组成,每个模块为推理的一个环节,通过动态组合这些模块得到推理结果.NMN能够对语言描述中不同语法成分进行组合,已成功应用于图像描述领域[20-23].本文使用Tan等[1]所提出的时空推理模块实现视频描述中不同语法成分的视觉推理,并采用动态模块选择器在每个单词的生成过程中挑选相关的视觉推理特征作为解码器的输入,实现了可解释性.
2 方 法
本文提出的方法采用编码器-解码器框架,整体架构见图1.在编码阶段,一方面,采用Tan等[1]提出的特征提取网络、模块推理网络和模块选择网络得到视觉推理特征;另一方面,采用Zhe等[9]提出的语义检测网络和Chen等[10]提出的评价指标得到语义特征.在解码阶段,提出一个语言解码网络,结合视觉推理特征和语义特征进行解码,得到对应视频的描述.本文的创新点在于将视觉推理特征和语义特征结合起来得到兼具流畅性和准确性的视频描述语句,并尝试不同的特征融合网络以达到最优的融合效果.
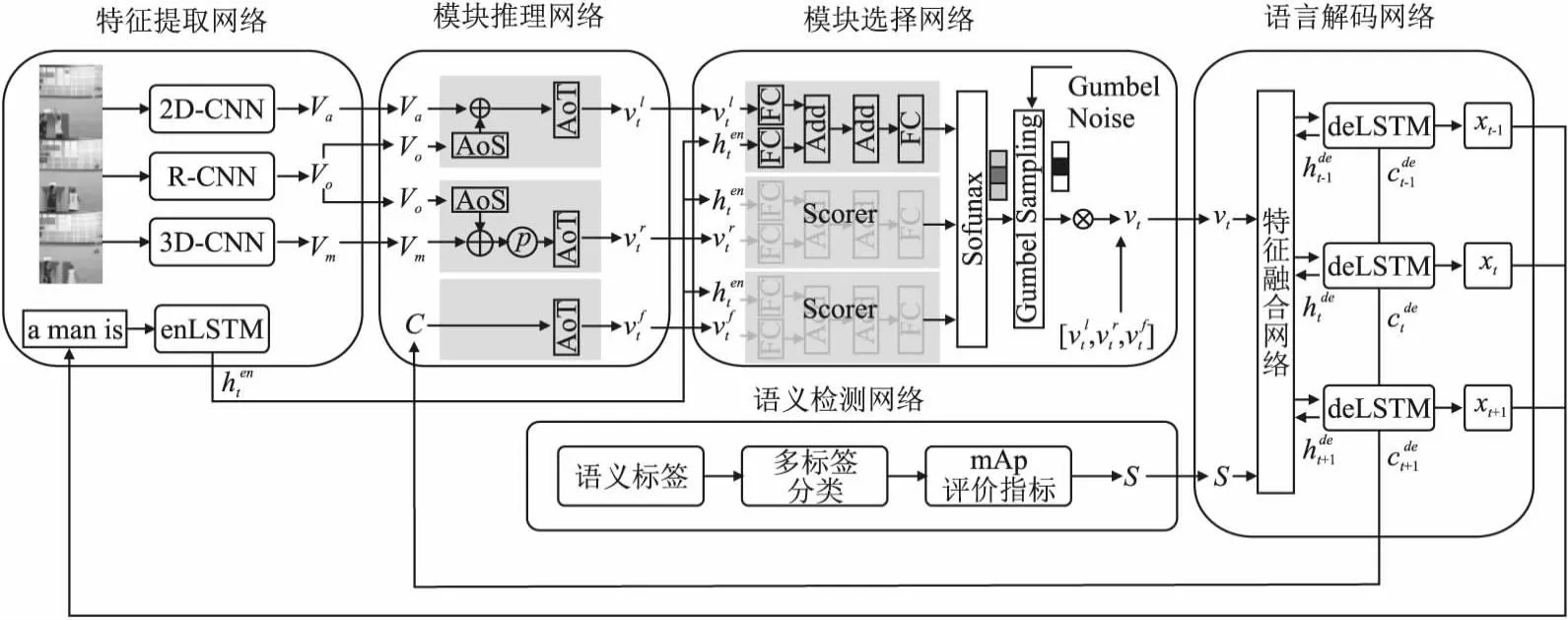
图1 整体框架图Fig.1 Overall frame diagram
2.1 编码
2.1.1 特征提取网络
采用类似于Tan等[1]的方法进行特征提取:使用2D-CNN提取视频帧的静态特征Va,使用3D-CNN提取视频帧的动态特征Vm,使用R-CNN 提取视频帧的对象特征Vo.为了得到视觉特征的动态时间信息,使用双向循环神经网络(Bi-LSTM)分别对静态特征Va和动态特征Vm进行建模,并在对象特征Vo中添加格外的时间和空间信息.
2.1.2 模块推理网络
采用类似于Tan等[1]中的模块推理网络进行特征推理,该网络由LOCATE(视觉属性)模块、RELATE(动作属性)模块、FUNC(关联属性)3个基础的时空推理模块构成,其中LOCATE模块用于生成名词和形容词的视觉特征,例如“man”,“ball”等;RELATE模块用于生成动词的视觉特征,例如“run”、“throw”等;FUNC模块用于生成关联词的特征信息,例如“and”、“the”等.

(1)


(2)
其中,AoT表示时间维度的注意力机制,AoS表示空间维度的注意力机制,⊕表示连接操作.
RELATE模块生成动词的推理过程分为两步:确定动作的发出者;识别发出者位置及形态的变化.推理过程如下:
(3)
(4)
其中P(·,·)表示动态特征的连接函数,即Pij(A,B)=Ai⊕Bj,因为动作的发生通常是一个连续的过程,所以本文考虑两个连续场景生成动态视觉特征.
FUNC模块将句子的各个成分连接在一起.关联词的生成不需要视觉特征信息,只需要考虑过去生成单词的语言信息.推理过程如下:
(5)
(6)
其中,C表示解码过程中deLSTM中的记忆单元,包含已生成单词的历史信息.
2.1.3 模块选择网络
模块选择网络分为两部分[1]:首先,分别计算上述的3个模块的得分来表示该模块被选择的概率,各模块的得分计算公式为:
(7)

其次,挑选得分最高的模块,得到该模块所对应的属性特征vt作为解码器的输入.然而,直接采用argmax函数会导致选择过程不可微,本文采用Gumbel Softmax[25]实现这一过程.
2.1.4 语义检测网络
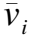
(8)
其中,σ(·)表示sigmoid激活函数,f(·)表示多层前馈神经网络,并使用最小化交叉熵损失函数进行训练.
另外,使用mAP评价训练结果,选择平均精度最高的语义特征作为解码器的输入[10].
2.2 解码
本文在解码阶段提出一个语言解码网络,首先通过特征融合网络结合视觉特征和语义特征,然后使用deLSTM生成视频描述语句.特征融合网络由匹配模块和融合模块组成,解码阶段的整体流程图如图2所示.

图2 解码阶段的整体流程图Fig.2 Overall flow chart of the decoding
2.2.1 匹配模块
本文提出了两种特征匹配模块:语义匹配模块和视觉匹配模块,分别突出所选特征中与语义特征或视觉特征相似的部分.由于视觉特征的选择遵循描述生成语句的语法特性,因此,这两种匹配模块分别满足由语义特征引导的准确性要求和视觉推理特征引导的流畅性要求.下面主要介绍语义匹配模块,如图3所示,视觉匹配模块类似.
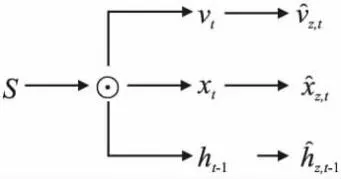
图3 语义匹配模块Fig.3 Semantic matching module
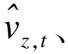
(9)
(10)
(11)
其中,z∈{c,i,f,o},c,i,f,o分别表示记忆单元、输入门、遗忘门和输出门.
2.2.2 融合模块
本文提出了两种特征融合模块:加法融合模块和乘法融合模块.
加法融合模块参照SCN模型[9],如图4所示.
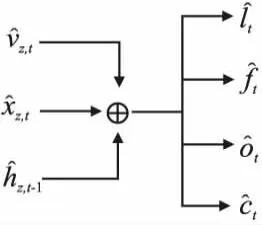
图4 加法融合模块Fig.4 Add fusion module
将匹配模块所得到的3个量相加,作为LSTM的输入,计算方法如下:
(12)
使用deLSTM网络,得到记忆单元ct和隐藏状态ht:
TCP协议的通信过程为:服务器端必须首先通过指定IP地址以及端口名建立侦听,等待客户端响应连接;然后客户端向对应的服务器所设定的IP地址和端口发出连接请求;待服务器与客户端成功建立连接后,双方方可通过读写函数控件收发数据,完成数据传输时,需先从客户端断开连接后服务器才能断开连接。
(13)
(14)
(15)
(16)
(17)
hi=ot×tanh(ct)
(18)
总体来说,加法融合模块以较为公平的方式使各个特征都参与到了视频描述语句的生成.

(19)
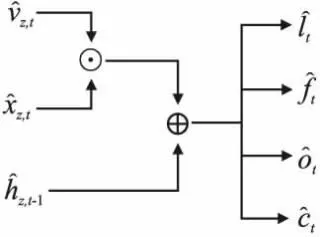
图5 乘法融合模块Fig.5 MutalFusion Module
记忆单元ct和隐藏状态ht的计算方式不变.这种融合模式加强了视觉特征和文本特征之间的相互引导.
2.2.3 特征融合网络
本文提出3种特征融合网络:特征参与的融合网络、特征引导的融合网络和结合权重的融合网络.
特征参与的融合网络由语义匹配模块和加法融合模块组成,在实验阶段表示为“baesline+1”.
特征引导的融合网络由语义匹配模块和乘法融合模块组成,在实验阶段表示为“baseline+2”.

图6 结合权重的融合网络Fig.6 A weighted fusion network
计算方式如下:
(20)
ht=β⊙hs,t+(1-β)⊙hv,t
(21)
ct=β⊙cs,t+(1-β)⊙cv,t
(22)

3种方式的比较结果和具体分析请参照3.3中的消融实验和3.4中的质量分析
2.3 损失函数
除采用传统的交叉熵损失函数外,本文使用POS标签监督模块选择的结果[1],使得所选择的视觉推理特征在某种程度上包含了视频描述的句法结构信息,公式如下:
(23)
(24)
L=Lcap+λLpos
(25)
更多细节请参照文献[1].
3 实 验
3.1 数据集和评价指标
3.1.1 数据集
MSVD[27]数据集包含1970个短视频片段,每个视频片段描述了任意领域的单个活动,并具有多语言标签,本文仅考虑英语标签,每个视频大约包含41个英语句子,1200个视频用于训练,100个视频用于验证,670个视频用于测试.
MSRVTT[28]数据集包含10000个视频片段,内容涉及20多个领域,每个视频有20条不同的英文描述,6513个视频用于训练,497个视频用于验证,2990个视频用于测试.
3.1.2 评价指标
使用在机器翻译和图像描述领域常用的评价指标:BLEU-4[29]、ROUGE[30]、METEOR[31]以及CIDEr[32],分数越高说明生成的描述质量越好.
3.2 过程
3.2.1 数据处理
首先,本文将所有注释转换为小写字母,移除标点符号,设置注释长度为26,对于超出长度的注释部分进行截取,不足的用零填充.MSVD数据集的词汇表大小为7351,MSRVTT数据集的词汇表大小为9732,这里分别忽略出现次数少于两次和5次的单词.
3.2.2 特征提取
本文提取了视觉特征和语义特征,并进行融合来生成视频描述.
采用类似于Tan等[1]的方法进行视觉特征提取,每个视频平均提取26个视频帧,使用在ILSVRC-2012-CLS图像分类数据集[33]中预训练的InceptionResNetV2(IRV2)网络作为2D CNN来提取视频帧的静态特征,使用在Kinetics动作分类数据集[34]中预训练的I3D网络作为3D CNN来提取视频帧的动态特征.使用预训练的Faster-RCNN[35]网络在每个视频帧中提取36个区域特征作为对象特征.
采用Zhe 等[9]的方法进行语义特征的提取,首先从数据集中选择出现频率较高的300个词,并按照2.1.4中的语义检测网络来获取语义特征.
3.2.3 训练细节
模型采用Adam优化器进行优化,初始学习率设置为1e-4.对于MSVD数据集,LSTM的隐藏状态维度为512,学习率每10个周期除以10;对于MSRVTT数据集,LSTM的隐藏状态维度为1300,学习率每5个周期除以3.在测试期间,使用大小为2的波束搜索来生成最终的标题.
3.3 消融实验
3.3.1 MSVD数据集
基模型来自Tan等[1]的方法,在MSVD数据集中验证3种特征融合网络,“Baseline+1”、“Baseline+2”、“Baseline+3”分别表示3种特征融合网络,实验结果见表1.可以看到,3种特征融合网络均优于基模型,证明了本文提出的融合方式的有效性.其中特征参与的融合网络在各个指标上效果最好,因此本文选择该网络进行对比实验.

表1 在MSVD数据集上的消融实验Table 1 Performance of ablated model on MSVD
3.3.2 MSRVTT数据集
基模型来自Tan等[1]的方法,本文在MSRVTT数据集中验证3种特征融合网络.实验结果见表2,可以看到,3种特征融合网络均优于基模型,证明了所提融合网络的有效性,其中特征引导的融合网络和结合权重的融合网络分别在不同指标上达到了最好效果.但与在MSVD数据集上的结果不同,3种融合网络在评价指标上的结果差距并不大,因此本文选择“Baseline+2”、“Baseline+3”两种融合网络进行对比实验.

表2 在MSRVTT数据集上的消融实验Table 2 Performance of ablated model on MSRVTT
3.4 质量分析
表3为3种融合方式所生成的描述的比较结果,其中,前3列为在MSVD数据集中生成的视频描述,后3列为在MSRVTT数据集中生成的视频描述.在MSVD数据集中,特征参与的融合网络所生成的描述与真实描述更为接近;在MSRVTT数据集中,特征引导的融合网络和结合权重的融合网络所生成的描述与真实描述更为接近.该实验结果与上述消融实验中的评价指标大致吻合.

表3 3种融合方式所生成的描述对比Table 3 Description comparison generated by three fusion methods
在两个数据集中出现了不同的描述结果,这是因为与MSVD数据集相比,MSRVTT数据集属于更大范围的视频数据集,在视频长度、视频类别和词汇数量等方面更加丰富和庞大.因此MSRVTT数据集在某种程度上弥补了后两种融合方式在MSVD数据集中的不足:1)在视觉单词的生成过程中,由于MSRVTT数据集视觉元素比较丰富,经过选择后的视觉推理特征所蕴含的特征信息比MSVD数据集更加丰富,因此将视觉推理特征与其他特征进行融合可以帮助其进一步挑选出更适合的特征信息.例如“a man is showing how to fix a car”成功识别出“a man”和“a car”两个视觉对象.而在MSVD数据集中,融合操作扰乱了其原本比较简单的视觉特征信息,导致生成的描述在识别视觉对象和数量上存在误差,例如将“dog”识别为“cat”,将“a dog”识别为“two dogs”等;2)在生成描述的完整性方面,由于MSRVTT数据集中的视频种类更加多样,词汇数量也更多,因此将词向量特征更多地参与到融合过程中,会使得生成的描述更符合人类阅读习惯,也蕴含更加丰富的信息,例如“a woman is applying makeup to her face”成功加入“to her face”描述;“a man is showing how to fix a car”成功生成蕴含更多内容信息的描述;3)在MSVD数据集中,过度考虑词向量信息则会出现过度解析现象,例如将“a dog is playing in water”识别为“a dog is swimming”,将“the dog climbed into the dryer”识别为“a cat is playing in the water”,前者视频中并没有出现“swimming”这个动作,考虑可能是由“water”联系到“swimming”,后者视频中也没有“water”,考虑是由“dryer”联系到“water”,从而生成视频中并没有体现的描述.
3.5 对比实验
在MSVD和MSRVTT数据集中分别与其他模型进行比较,比较结果如表4和表5所示.结果表明,所提的模型在MSVD和MSRVTT数据集中都有良好的表现,证明了本文提出的方法对视频描述任务的有效性.

表4 在MSVD数据集上的对比实验Table 4 Comparing with the state-of-the-art on MSVD dataset

表5 在MSRVTT数据集上的对比实验Table 5 Comparing with the state-of-the-art on MSRVTT dataset
与单独考虑词性信息和语义信息的模型相比:POS[11]和JSRL-VCT[12]模型使用不同的方式引入词性信息来增强生成描述的质量.LSTM-E[7]、LSTM-TSA[8]、SCN[9]、SAMSS[10]4种模型使用不同的方式引入语义信息来增强生成描述的质量,通过比较实验结果,所提的模型在大多数指标上有明显的提升,尤其是在MSVD数据集中,验证了所提出的结合语义信息和词性信息的方法在视频描述任务中的有效性.
与融合词性信息与语义信息的模型相比:将本文提出的模型与SemSynAN[13]模型进行对比,该模型将整体视觉特征参与到解码过程,实验结果表明,本文提出的模型在两个数据集中的CIDEr指标上优于SemSynAN模型,进一步表明所提出的特征推理方法的有效性.
与考虑对象特征的模型相比:将本文提出的模型与STaTS(I3D+FL)[5]、ORG-TRL[6]、HRNAT(IR+I)[36]、OSTG[37]模型进行了对比,上述4种模型均使用对象特征参与到视频描述过程中,但并没有考虑到生成描述的句法结构和准确性问题,实验结果表明,本文的模型在两个数据集中的所有指标上都超过了这4种模型,证明语义信息和词性信息在指导描述生成过程中的有效性.
4 结 论
本文提出了一种结合视觉推理特征和语义特征的视频描述生成方法,既考虑到了描述生成语句中的句法结构,又提高了描述的准确性,在两个常用的数据集上的对比实验验证了所提方法的有效性和先进性.未来可以进一步考虑视频的音频信息和种类特征,来生成更准确且更具有种类特色的描述.
