融合自我知识蒸馏和卷积压缩的轻量化人体姿态估计方法
2024-02-27闫忠心李陶深
闫忠心,白 琳,李陶深
(广西大学 计算机与电子信息学院,南宁 530004)
0 引 言
人体姿态估计(Human Pose Estimation,HPE)作为计算机视觉领域的基础任务之一,被广泛应用于人体行为识别、人与物体交互活动识别、人机交互等.人体姿势估计的目的在于给定一张RGB图像识别和定位出所有的人体各个关键点(比如手腕、肘、头部等).Deeppose[1]模型第一次使用卷积神经网络对关键点位置直接进行回归预测,相比于传统基于图结构模型[2-4](Pictorial Structure Module,PSM)的人体姿势估计算法展现出巨大的优越性,自此以深度卷积神经网路为代表的人体姿势估计算法(例如Stack Hourglass[5]、OpenPose[6]、SimpleBaseline[7]、HRNet[8]等)成为主流.然而上述最先进的人体姿势估计算法为了追求更高的准确率,往往模型参数和浮点数计算量庞大,对于资源受限的边缘移动设备来说很难实际部署.为了降低模型计算成本,在网络结构上以MobileNet[9]、ShuffleNet[10]为代表的轻量化网络结构大幅度降低了模型参数和计算量.Bulat等人[11]通过二值化网络的方式转化模型结构,大幅度压缩了模型参数和部署成本,但是模型准确率较差.FPD[12]模型通过离线知识蒸馏的方式来训练学生网络,然而训练教师网络的过程成本较高,并且如何选择一个合适的教师网络也是一个难题.Mirzadeh[13]等人的研究表明,当教师模型和学生模型性能差异过大时,离线蒸馏得到的学生模型效果并不一定好.
为了保持人体姿态估计网络较高检测精度的同时大幅度降低模型参数和浮点数计算量,本文提出了SKDPose模型,模型结构如图1所示.首先对于特征编码器模块(Encoder),设计了协同注意力移动倒置瓶颈模块(CAMBConv)得到改进后的EfficientNet[14]特征编码器,用于提取多层次语义特征;接着,设计了轻量化跨尺度双向融合模块(BFL-FPN)用于融合编码器的不同层次的语义信息;最后,把融合后的多层次信息划分为3个独立的分支,每个分支使用独立的解码器进行人体关键预测,最深层次的解码器作为教师模型其余解码器作为学生模型完成知识的自我蒸馏;此外,针对解码器模块的普通转置卷积参数量过大的缺点,设计了深度可分离转置卷积大幅度降低了解码器模块的参数量.在COCO和MPII数据集上实验结果表明,SKDPose模型在保持高准确率的同时大幅度降低了模型参数和计算量.

图1 基于自我知识蒸馏和卷积压缩的轻量化人体姿态估计网络Fig.1 Lightweight human pose estimation network based on self-knowledge distillation and convolution compression
本文的主要贡献如下:
1)根据文献可考,本文是第一个把自我知识蒸馏用于轻量化人体姿态估计算法研究.
2)针对特征编码器的MBConv模块缺乏空间注意力的缺陷,设计了协同注意力移动倒置瓶颈模块(CAMBConv),提高了编码器的特征提取能力.
3)提出了轻量化上采样解码器模块(DSTC),相比于原始的上采样解码器,DSTC模块大幅度降低了解码器的参数量.
4)提出了轻量化跨尺度双向融合模块(BFL-FPN),可以作为即插即用的模块应用于任何轻量化骨干网路的多尺度特征融合.
1 相关工作
1.1 人体姿态估计
传统的人体姿态估计主要基于图结构表示人体各个关键点之间的关系,但是图结构依赖于手工设计的人体姿态特征比如方向梯度直方图[15](Histogram of Oriented Gradient,HOG),这直接导致了图结构模型的泛化性很差,很难达到商用的地步.随着深度学习的快速发展,2014年Toshev等人首次提出基于卷积神经网络的DeepPose模型直接回归人体关键点坐标,性能超越了经典的图结构方法,之后主流的人体姿势估计模型均采用神经网络架构.根据预测人体关键点坐标的方式可以分为两大类,直接坐标回归和热力图(Heatmap),直接坐标回归方法通过深度神经网络回归出关键点的坐标位置,热力图是通过预测一个近似高斯分布的概率图间接得到关键点的位置坐标.根据人体关键点检测网络的架构来分,可以分为两大类,分别是自顶向下(Top-Down)和自底向上(Bottom-Up).自顶向下的方法通常采用先进的人体目标检测器,例如Faster R-CNN[16]、Yolo[17]等从目标图像中检测出单个人,然后从原始图像中裁剪出单个边界框送入到单人姿态估计网络中进行人体关键点估计,常见的自顶向下的方法有SimpleBaseline、HRNet等.相反,自底向上的方法不需要使用人体目标检测器,而是直接从RGB图像中推断出所有的关键点信息,然后对每个关键点进行分类和分组到不同的人体实例中,常见的自底向上的算法有OpenPose、Higherhrnet[18].Top-Down算法是人体关键点检测中精度最高的架构,缺点是检测速度慢,Bottom-Up算法的优点是推理速度快,缺点是精度相较于Top-Down差一些.
上述最先进的人体姿态估计算法为了追求更高的预测性能,通常设计更深、更宽的卷积神经网络.虽然这些网络性能优越,但是带来的问题是参数量和浮点运算过于庞大,导致模型部署时占用的内存更多,模型推理时间更长,因此对于资源受限的边缘设备比如手机、嵌入式系统等,上述网络模型很难实际部署.
受到卷积压缩和自我知识蒸馏的启发,本文设计一种基于卷积压缩和知识自我蒸馏的轻量化人体姿态估计网络,同时兼顾了模型的准确性和模型复杂度.具体来说,通过设计高效且轻量的CAMBConv和DSTC模块,大幅度降低编码器和解码器参数和计算量;设计轻量化跨尺度双向融合模块用于融合解码器的不同层次语义特征;提出基于多分支架构的自我知识蒸馏方法,提升模型的性能.
1.2 卷积压缩


表1 标准卷积和深度可分离卷积Table 1 Standard covolution and depthwise separable convolution
1.3 知识蒸馏
知识蒸馏作为一种常见的模型压缩技巧,2015年由Hinton教授等人[21]第1次正式定义了知识蒸馏(Knowledge Distillation,KD)并且提出了对应的蒸馏监督训练方法.简单而言,知识蒸馏第1步是训练一个网络规模庞大、性能优越的教师网络(Teacher Network);第2步,利用强大的教师网络和真实标签同时作为模型监督信号,完成从教师网络到学生网络(Student Network)的暗知识(Dark Knowledge,DK)转移,使得学生网络表现性能接近教师网络.为了实现人体关键点检测模型的压缩,FPD模型第一次把知识蒸馏应用在了人体关键点检测模型上,该模型借鉴Hinton教授提出的离线知识蒸馏(0ff Line Knowledge Distillation,OLKD)设计思想,首先训练了一个8层堆叠沙漏(8-Stack Hourglass)为教师网络,然后利用训练好的教师模型通过知识转移的方式训练4层堆叠沙漏(4-Stack Hourglass),使得学生模型的人体姿态估计性能接近教师模型性能,但是学生模型的参数量和GFLOPs远低于教师模型,因此学生模型充分考虑了模型的效率问题.但是FPD模型缺点很明显,这是一个两阶段实现DK转移的过程,即第1个阶段单独训练庞大的教师网络,在第2个阶段利用教师网络辅助训练学生网络,因此模型总体训练成本为教师网络训练成本加上学生网络训练成本.Mirzade等人的研究表明,OLKD的知识转移过程中并不是越强大的教师网络一定能教出更优秀的学生网络,当教师网络和学生网络的性能差异过大时候,基于OLKD训练的学生模型的性能并不好.Zhang[22]等人提出自我知识蒸馏(Self-Knowledge Distillation,SKD),与传统的OLKD不同的是,在模型训练阶段SKD把浅层次的网络作为学生,深层次网络作为教师,在单一网络内部完成知识从教师到学生的转递,在模型部署阶段只保留单个教师或学生模型,SKD方法在训练时间和准确率上都优于OLKD方法.如图1所示,为了解决FPD存在的问题,受到SKD设计思想的启发,本文设计了多分支的解码器结构.具体来说,对于轻量化跨尺度双向融合后的3个特征,使用3个独立的上采样解码器模块进行特征解码,其中分支1、2、3同时接受真实热力图(GroundTrues HeatMap,GTHM)的监督,除此之外分支1、2在训练阶段需要接受教师网络分支3输出特征图的监督.
2 本文方法
本文提出SKDPose模型如图1所示,其设计思路是:采用轻量化的编码器提取多层次语义特征,用多个独立的轻量化解码器对不同层次特征图进行解码,之后通过多尺度特征融合和知识蒸馏提高解码效率.
SKDPose模型的处理流程包含4个阶段.第1阶段使用轻量化特征编码器提取人体图像的多层次语义特征;第2阶段使用轻量化跨尺度特征融合模块对第1阶段的多层次语义特征进行双向融合;第3个阶段对第2个阶段融合后的特征使用3个独立分支的解码器结构对不同层次语义特征进行解码,每个解码器都可以独立进行人体关键点预测;第4个阶段每个分支解码器输出结果同时接受GTHM的监督,除此之外分支1、2解码器还要接受分支3的输出特征监督.
模型整体可以被拆分为4个模块:
1)轻量化特征编码器:图1中Encoder模块是基于EfficientNet改进的多层次特征提取编码器,用于提取不同分辨率语义特征.
2)轻量化上采样解码器:为了降低解码器模块的参数量和浮点数计算量,设计了基于深度可分离转置卷积和协同注意力机制的轻量化上采样解码器(DSTC).
3)轻量化跨尺度双向融合:人体关键点检测属于位置敏感型的密集预测任务,不同层次语义特征对于位置预测均有作用,针对人体关键点检测本文设计了高效且轻量的特征融合模块(BFL-FPN).
4)知识自我蒸馏:3个独立的解码器,其中分支3作为教师网络分支1和分支2作为学生网络,在SKDPose模型内部完成知识的传递.
2.1 改进EfficientNet模型
EfficientNet的主要组成模块MBConv中就使用了SE[23]模块来加强通道注意力特征的提取,SE模块存在的问题是只关注了局部的通道级别的注意力,缺乏全局依赖捕捉和空间位置注意力的获取.本文通过对MBConv引入协同注意力机制得到协同移动倒置瓶颈卷积模块(Coordinate Attention Mobile Inverted Bottleneck Convolution,CAMBConv),协同注意力移动倒置瓶颈卷积模块如图2所示.CAMBConv模块旨在增强轻量级网络的特征学习能力,输入可以是任何中间层特征X=[x1,x2,x3,…,xc]∈RC×H×W,协同注意力模块首先对输入特征的宽和高两个方向维度使用平均池化,结果分别是X-Avg、Y-Avg,产生两个具备方向特征感知的注意力权重.然后对X-Avg,Y-Avg进行Concat操作,之后使用1×1卷积和BatchNorm进行通道级特征压缩,最后利用Split和1×1卷积分别进行X,Y维度特征分割和特征通道提升,类似残差跳跃模块,使用X,Y两个方向的注意力权重乘以原始的特征输出得到最终的协同注意力特征Y=[y1,y2,y3,…,yc]∈RC×H×W.通过协同注意力机制解决了原始MBConv模块缺乏空间注意力和长范围依赖的问题.协同注意力(Coordinate Attention,CA)见图2的Attention模块所示.
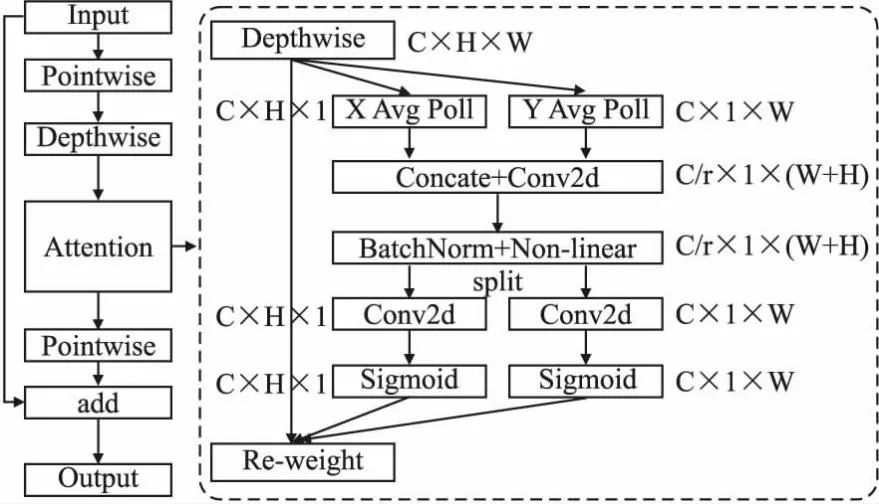
图2 协同注意力移动倒置瓶颈模块Fig.2 Coordinate attention MBConv model
改进后的EfficientNet模型结构如表2所示.其中Stage表示阶段;CAMBConv1,k3×3的1表示CAMBConv的PW卷积通道扩充比例,3×3表示DW卷积核大小;Resolution表示输入特征图分辨率;Channels表示输出特征图通道数;Layers表示当前模块重复次数.

表2 改进EfficientNet网络结构Table 2 Improved EfficientNet network structure
2.2 轻量化上采样解码器


表3 实验软硬件环境Table 3 Experimental software and hardware environment

表3 标准转置卷积和深度可分离转置卷积Table 3 Standard transpose covolution and depthwise separable transpose convolution
(1)
(2)
式(1)和式(2)分别为使用深度可分离转置卷积后DSTC模块参数量和浮点数计算量的压缩比例,其中符号代表的含义和表3相同,DSTC模块转置卷积核K大小为4,并且特征图的输出通道数Co远大于K,且Ci是Co的两倍,因此公式1和2的最终约等于1/16,DSTC模块相比于标准转置卷积来说,在参数量和FLOPs减少了94%.
本文的解码器的DSTC模块把标准转置卷积分成了3步,首先利用深度转置卷积对原始特征的每一个通道进行单独卷积运算,其次利用1×1点卷积融合每个通道的输出结果,在这个过程中可能丢失了部分空间维度和通道维度特征,为了解决这个问题.本文最后在1×1点卷积之后加入了协同注意力模块,在空间维度、通道维度和长距离范围依赖上增强DSTC的特征解码能力.SimpleBaseLine中上采样模块输出通道数维持在256,为了进一步对上采样模块进行压缩,本文对上采样通道数也进行了压缩.
2.3 轻量型跨尺度多层次语义特征融合
现有的人体姿态估计网络通常采用串行高分辨率和低分辨率网络实现特征提取,比如Stack Hourglass,但是缺乏不同层级分辨率特征图的融合.FPN(Feature Pyramid Networks)[24]网络作为一种有效的特征融合网络,主要解决了在目标检测过程中的目标多尺度问题,显著的提升了小目标检测的性能.
受到FPN的启发,针对人体关键点检测模型来说,本文提出轻量化跨尺度双向融合模块(Bidirectional Fusion Lightweight FPN,BFL-FPN),BFL-FPN模块见图3所示.整体思路是首先进行高级语义特征向低级语义特征进行融合,然后从低级语义特征向高级语义特征进行融合.具体来说对于本文的三分支解码器,编码器的中间3层特征图CAMBConv_1、CAMBConv_2、CAMBConv_3分别尺寸为,Feature1=C1×32×32,Feature2=C2×16×16,Feature3=C3×8×8.首先进行高层次语义信息向低层次语义信息进行流动,利用PW卷积,统一调整3个特征图通道数为256,然后分别对Feature3上采样后相加到Feature2,Feature2上采样之后相加到Feature1中.其次使用DWA_1模块分别对自上往下融合结果进行特征通道压缩.最后低层次语义信息向高层次语义信息进行流动,对Branch1,Branch2使用DWA_2模块进行降采样后分别添加到Branch2和Branch3,这样就完成了自底向上的语义特征信息流动,其中DWA_1、DWA_2分别表示DWC模块步长为1、2,DWA模块的结构首先使用深度可分离卷积DWC、然后使用CA注意力机制最后使用点卷积PWC,其中中间层使用批标准化.整个BFL-FPN模块参数量只有原始双向融合FPN网络的十分之一,同时BFL-FPN保持较高的特征融合性能.
(3)

图3 轻量化跨尺度双向融合Fig.3 Bidirectional fusion lightweight FPN
(4)
式(3)和式(4)分别为使用深度可分离卷积后浮点数计算量和参数量的压缩比例,式中符号代表的含义和表1相同,BFL-FPN的卷积模块的输入输出特征图尺寸一样,本文卷积核K大小为3,并且特征图的输出通道数Co远大于K,因此公式(3)、(4)最终约等于1/9,BFL-FPN模块相比于标准卷积来说,参数量和FLOPs减少了8/9.
2.4 知识自我蒸馏模块
知识蒸馏作为一种有效的模型压缩方式,传统的离线蒸馏是一个两阶段的训练方法,先训练一个庞大的教师网络.受到Zhang等人的启发,本文把SKD思想用于轻量化人体姿势估计网络,在编码器进行下采样的CAMBConv_1、CAMBConv_2、CAMBConv_3产生的特征经过BFL-FPN融合之后的特征图Branch1=C1×32×32,Branch2=C2×16×16和Branch3=C3×8×8.Branch1、Branch2和Branch3分别使用1、2、3个轻量化反卷积解码器(DSTC)对特征图进行解码,其中每个DSTC模块的可分离转置卷积的卷积核大小和卷积步长分别为4和2.第1个分支的DSTC模块输出通道数为64;第2个分支的DSTC模块的输出通道数分别是128和64;第3个分支的DSTC模块的输出通道数分别是256、128、64.3个分支解码后的特征图使用3个独立的热力图回归模块进行独立预测.实际测试阶段选择3个解码器中准确度最高的解码器作为最终的预测结果,其余解码器模块从网络结构中删去.对于每个人体关键点k∈{1,2,…,K}使用高斯热力图表示人体关键点位置,热力图使用的高斯函数如式(5)所示,式(5)中所有参数遵循主流模型(例如Simplebaseline模型)的标准配置:
(5)
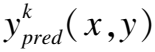
(6)
训练阶段深层次解码器3作为教师模型输出,解码器1和2作为学生模型,使用KL(Kullback-Leibler)离散度作为自我知识蒸馏的损失函数.对教师模型和学生模型输出热力图的每个像素都执行KL离散度计算,最终自我知识蒸馏的损失函数公式(7)所示:
(7)
式(7)中W,H分别代表解码器预测热力图的长、宽,本文在MPII数据集设置W和H均为64,COCO数据集设置W为64,H为48.K表示单张RGB图像中人体关键点个数,T表示学生模型个数,本文T为2.本文的自我蒸馏SKD模型的总损失如公式(8)所示:
Losstotal=Lossmse+αLossSKD
(8)
式(8)中α是平衡两种损失的超参数,本文设置α大小为100,Lossmse是每个解码器和真实热力图之间的均方差MSE损失,LossSKD是学生模型和教师模型之间的KL离散度蒸馏损失.
3 实验过程
3.1 实验软硬件环境和模型参数设置
为了验证本文模型的有效性,在COCO[25]和MPII[26]两个数据集上进行了对比试验和消融实验,实验的软硬件环境如表3所示.
本文的算法模型使用开源深度学习开发框架PyTorch实现,在两张Tesla V100图形处理器(Graphics Processing Unit,GPU)上训练,单张显卡显存为16G,训练阶段采用Adam优化器,每一批次数据大小为32,初始优化器学习率为0.001,迭代到110、170时学习率衰减为原来的1/10,迭代训练200个epoch.
3.2 实验数据集和评价指标
MPII数据集定义了人体16个关键点的位置,从真实人类活动中采集25000张人体图片,包含了超过40000个人体标签.其中29000个人体实例用作训练样本,2900个人体实例用于验证样本.COCO数据集有超过200000张图片,包含了2500000个人体实例,每个人体实例标注了17个人体关键点,人体姿态估计模型在COCO Train2017数据集上进行训练,使用COCO val2017数据集用于验证模型性能.训练阶段从输入图像中裁剪出人体目标框,并且按照检测框长宽比4∶3进行缩放,MPII数据集中把裁剪后的人体目标框统一缩放到256×256尺寸,COCO数据集中把裁剪后的人体框统一缩放到256×192尺寸.每个人体实例图片都进行数据增强,首先对人体实例进行[-30°,30°]角度随机旋转、[0.7,1.3]范围随机缩放和以及水平翻转.
对于MPII数据集,本文采用通用的正确关键点的百分比(Percentage of Correct Keypoints,PCK)作为评价指标,模型预测的人体关键点的坐标和真实坐标像素距离之差小于alr则认为预测正确,其中α阈值为0.5,lr参考的是人体目标检测头部框对角线的长度,本文采用标准的PCKH@0.5作为评价性能指标.对于COCO数据集,本文采用基于目标关键点相似度(Object Keypoint Similarity,OKS)的平均精度(Average Precision,AP)和平均召回率(Average Recall,AR)作为模型性能评价指标.
在测试阶段,对于COCO数据集,采用标准的两阶段测试方法,先使用人体目标检测器检测人体框,然后对单个人进行人体关键点检测.对于MPII数据集,本文采用标准的测试方法,首先进行水平翻转图形,原始图像的预测热力图和翻转后的图像对应预测的热力图进行平均作为最终的热力图.对于人体关键点热力图的估计,本文采用热力图数值最大位置向次大数值位置偏移四分之一作为最终的预测位置.
3.3 实验结果分析
3.3.1 MPII数据集实验结果
表4显示了在MPII数据集上,本文的SKDPose模型和最先进的人体关键点检测模型以及经典的轻量化人体关键点检测模型对比结果.从结果中可以明显看出,SKDPose模型在模型性能、模型参数量和浮点数计算量中取得了极具竞争力的效果.相比于大型网络SimpleBaseline-50来说,在模型参数和FLOPs分别减少了88%和95%,但是准确率只降低了0.7%.与最先进的HRNet-32相比,模型参数和FLOPs上分别减少了85%和93%,但是模型的准确率只降低了2.7%.SimpleBaseline和HRNet重点追求模型的准确性,在网络结构上没有引入轻量化模型压缩技术,SKDPose模型在编码器和解码器等模块借鉴了移动端网络结构设计,同时兼顾模型准确率和模型复杂度.SKDPose和轻量化人体姿势估计模型FLPN-50[27]相比,PCKH@0.5模型精度指标上相同,但是SKDPose在模型参数和FLOPs进一步降低了58%和40%.SKDPose和MobileNetV2、MobileNetV3、ShuffleNetv2、FPD*[12]等模型相比,SKDPose模型以4.2M的模型参数量和0.66G的浮点数运算量,在模型准确率PCKH@0.5指标上达到了87.8,以更低的模型参数量和浮点数运算量完成了更高模型准确率.相比于MobileNetV2、MobileNetV3、ShuffleNetv2、FPD*模型在PCKH@0.5性能指标上分别提升了1.9、3、4.4和0.2个点.上述轻量化模型相比于SKDPose模型缺乏编码器的多尺度特征融合,仅使用高级语义特征,忽略低级语义特征对密集预测任务的重要性.图4显示了SKDPose和其余轻量化人体姿势估计模型在模型准确率和模型参数量的直观对比.FPD*模型为离线蒸馏人体关键点检测模型,虽然FPD*模型参数比SKDPose模型少,但是FPD*模型的训练成本极高,SKDPose模型属于自我知识蒸馏,在单一模型内部进行知识的传递,因此SKDPose模型在模型性能和模型训练成本上整体是优于FPD*.

表4 在MPII验证集上的模型定量比较Table 4 Quantitative comparison of models on MPII validation set
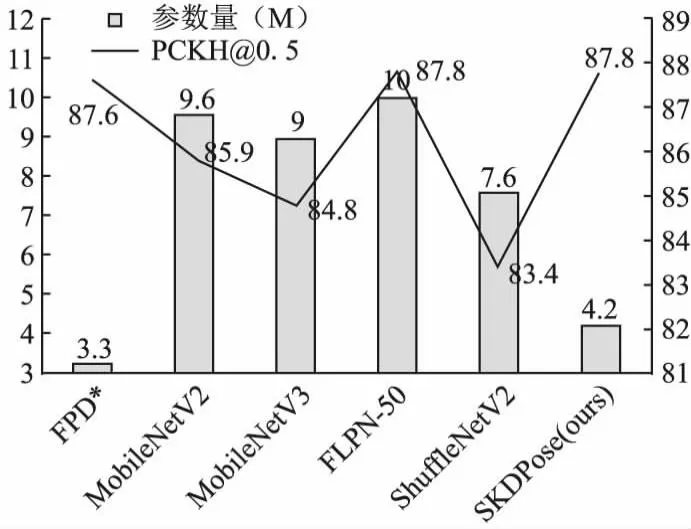
图4 MPII验证集上模型参数量和准确率对比Fig.4 Model complexity and accuracy comparison on the MPII validation set
整体来说,在网络结构上SKDPose模型充分借鉴了移动端小型网络的设计思想,根据公式(1)~公式(4),通过在编码器的多尺度特征融合模块引入深度可分离卷积,解码器模块采用了深度可分离转置卷积,从而大幅度降低了SKDPose模型的参数量和浮点数计算量.为了弥补由于上述模型压缩带来的性能下降,SKDPose模型在编码器和解码器模块都引入了协同注意力机制,增强了轻量化模型特征表达能力.在模型训练方法上,SKDPose利用了自蒸馏的思想,在单一网络内部完成知识的蒸馏传递,在几乎不增加模型训练成本和部署成本的前提下,避免了模型过拟合,提高了模型的泛化能力,实现了轻量化模型性能的提升.根据实验数据和可视化效果来看,SKDPose在模型复杂度和模型准确率上具备极大的优势,在资源受限的边缘设备上应用前景广阔.
3.3.2 COCO数据集实验结果
表5显示在COCO数据集上,SKDPose在不使用ImageNet图像分类的预训练权重的情况下和最先进的人体姿态估计网络以及轻量化人体姿态估计网络的性能对比结果.从对比结果可以看出,SKDPose模型在模型性能、模型参数量和浮点数计算量中取得了极具竞争力的效果.对于输入图像分辨率为256×192,在无ImageNet预训练权重的情况下,SKDPose以0.41GFLOPs极低的计算量和4.2M较少的参数量,平均精度达到69.8.SKDPose相比于大型网络SimpleBaseline-50来说,在模型参数和FLOPs分别减少了88%和95.4%,但是模型准确率只降低了0.8%.相比于经典的堆叠沙漏网络,在参数和浮点数上分别减少了83%和97%,但是模型准确率提升了2.9个点.相比于CPN[28]网络,SKDPose模型的参数和浮点数分别减少了85%和91%,但是模型精度提升了1.2个点.图5显示了SKDPose模型和其余轻量化模型在准确率和GFLOPs上的直观对比结果.从图中可以看出,SKDPose模型相比于MobileNetV2、ShuffleNetV2、DY-MobileNetV2和FLPN-50模型,在浮点数运算量上分别下降了72%、67%、58%、62%,在模型准确率上分别上升了5.2、9.9、1.6、-1.5个点.SKDPose没有在ImageNet上进行预训练,因此相比于使用预训练权重的FLPN-50性能上略有降低.图6显示了SKDPose模型在MSCOCO数据集上的可视化效果图,从图中可以看到SKDPose模型对单人或者多人多物有遮挡的情况都可以有效检测出人体姿态.

表5 在COCO验证集上的模型定量比较Table 5 Quantitative comparison of models on COCO validation set
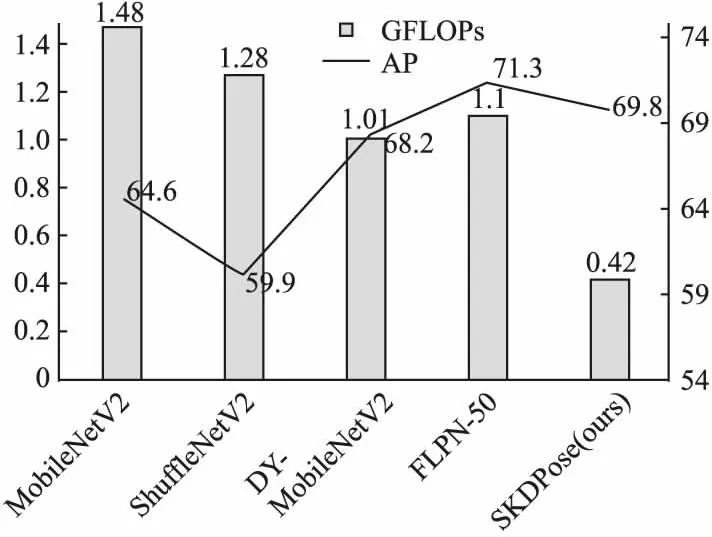
图5 COCO验证集上模型浮点数计算量和准确率对比Fig.5 Model GFLOPs and accuracy comparison on the COCO validation set

图6 本文SKDPose模型在COCO数据集可视化结果Fig.6 Visualization results based on our SKDPose model for MSCOCO validation set
3.3.3 消融实验
为了验证SKDPose模型各个模块的有效性,在MPII公开数据集上进行了一系列消融实验,具体实验结果见表6.其中PCKH@0.5代表模型的预测性能,参数量和GFLOPs反映了模型的部署和浮点数计算成本.具体来说,在控制其余实验配置相同的前提下,表6中SKDPose_0是未改进的EfficientNet编码器模块和普通三层转置卷积,相比于SimpleBaseline-50高通道上采样模块来说,本文对上采样通道数进行进一步压缩;SKDPose_1使用了改进后的EfficientNet编码器;SKDPose_2相比于SKDPose_1使用了DSTC模块替换了普通转置卷积,大幅度降低了解码器模块的模型参数,验证了DSTC模块的有效性;SKDPose_3验证了轻量化跨尺度双向融合模块的有效性;SKDPose相比于SKDPose_3使用了知识自我蒸馏模块,验证了自我知识蒸馏方法的有效性.表7~表11是对表6的更详细的消融实验和结果分析,其中消融实验中wo表示不包含此模块,w表示包含此模块.

表6 MPII验证集上模型组件消融实验Table 6 Ablation experiments of model components on the MPII validation set

表7 编码器CAMBConv模块消融实验Table 7 Encoder CAMBConv module ablation experiment
表7显示了针对MBConv改进后的CAMBConv模块的消融实验,在参数量和浮点数量基本保持不变的情况下,显著提升了模型性能0.4个点,CAMBConv的注意力模块可以捕获通道、空间和远距离范围依赖的注意力特征,加强了编码器模块的特征提取能力.
表8显示了轻量化上采样DSTC模块的有效性,根据公式(1)和公式(2),轻量化上采用模块采用了深度可分离转置卷积,相比于原始的上采样模块,本文上采样模块在模型参数上减少了94%,在浮点数计算量上减少了95%,但是模型准确率只降低了0.3个点,证明了深度可分离转置卷积相比于原始的转置卷积在模型压缩上的有效性,对于资源受限的边缘设备来说,上采样模块在部署成本上更具优势.

表8 轻量化上采样模块消融实验Table 8 Lightweight upsampling module ablation experiment
表9显示了跨尺度双向融合模块的消融实验,其中解码器1、解码器2和解码器3分别代表了3个分支解码器在PCKH@0.5指标上的预测性能.BFL-FPN模块参数量和浮点数运算量分别为0.3M和0.05GFLOPs,因为BFL-FPN模块对于特征特提取主要采用了深度可分离卷积,根据公式(3)和(4),深度可分离卷积相比于普通的卷积参数量和浮点数计算量减少了8/9,因此BFL-FPN以极低的复杂度大幅度提升了3个解码器的性能.使用BFL-FPN后3个原始解码器性能分别提升了22.8、1.8和0.4个点,不同层解码器性能都有提升,主要原因是编码器的不同尺度的语义特征图对人体关键点估计都起到一定作用,浅层特征的空间信息丰富,但是语义信息不足;深层特征则与之相反,跨尺度双向融合可以提升不同分支解码器性能.

表9 跨尺度双向融合模块消融实验Table 9 Cross-scale bidirectional fusion module ablation experiment
表10显示了自我知识蒸馏方案的消融实验,SKD模块在基本不增加模型参数和浮点数计算量的情况下,提升了模型性能0.5个点.主要原因在于模型的训练阶段,通过深层教师分支监督浅层学生网络分支,弱化真实标签对浅层网络的影响,避免了在训练阶段学生模型过度信任真实标签导致模型过拟合.学生分支网络可以从教师分支中获取更多的“暗知识”,从而提升了学生模型的泛化能力.FPD模型在不同模型之间进行知识传递,FPD模型训练时间至少是本文自蒸馏模型训练时间的两倍以上.本文自我知识蒸馏训练阶段增加两个少量参数的分支,在单一网络内部实现知识传递,在最终部署阶段从3个分支中只保留准确率最高的分支,因此本文模型在部署阶段不增加任何参数和浮点数计算量.

表10 自我知识蒸馏消融实验Table 10 Self-distillation knowledge ablation experiment
为了进一步证明基于KL离散度的蒸馏函数相比于FPD模型的MSE蒸馏函数的有效性,表11显示了不同蒸馏损失函数对模型性能的影响.实验结果表明相比于FPD模型的MSE蒸馏损失函数,基于KL离散度的蒸馏损失函数在不增加模型参数前提下,模型性能增加了0.4个点.MSE损失函数更适合于回归任务,而人体关键点热力图是符合高斯分布的概率分布图,KL离散度基于相对熵来衡量两个概率分布之间的差异,因此更能衡量教师模型和学生模型输出之间的差异性.表12显示了公式(8)损失函数中用于平衡MSE损失和SKD损失的参数α的消融实验,从结果中可以看出当权重α≤60或α≥115时,自我知识蒸馏对性能提升0.3个点,这表明教师监督信号确实提升了学生模型的泛化能力,避免学生模型过度信任真实标签的监督信号.观察最终实验结果,经过实验验证,阿尔法α设置为100为最优设置,这表明SKD损失在基本不增加模型复杂度的前提下实现“暗知识”的转移,提升了模型的泛化能力.

表11 不同的蒸馏损失函数比较Table 11 Comparison of different distillation loss functions

表12 损失函数参数消融实验Table 12 Ablation about weights of loss functions
4 结 论
本文提出了一种基于模型压缩和知识自我蒸馏的轻量化人体姿态估计检测算法,旨在解决现有的大型人体关键点检测模型难以在资源受限的设备上部署问题.通过在MBConv模块引入协同注意力机制,增强了解码器在通道、空间和全局范围的注意力特征,在编码器之后引入BFL-FPN结构,实现了多层次特征双向融合,显著提升了网络精度.同时设计了轻量化的上采样模块DSTC,使得解码器在模型参数上大幅度降低.最后利用自我知识蒸馏使得浅层次解码器学习深层次解码器输出特征,提升各层次解码器的性能.在COCO和MPII数据集上实验表明,本文的方法与最先进的大型人体关键检测网络的精度基本相似,但是本文的模型参数量和计算成本极低,对于计算能力受限的边缘设备,本文的模型具备极大的应用前景.希望本文的方法能够在人体关键点检测领域激发更多的灵感,未来,将研究通过引入Transformer架构,进一步提升轻量化人体姿态估计模型的性能.
