HetGNN-3D:基于异构图神经网络的3D目标检测优化模型
2024-02-27汪明明陈庆奎付直兵
汪明明,陈庆奎,2,付直兵
1(上海理工大学 管理学院,上海 200093)
2(上海理工大学 光电信息与计算机工程学院,上海 200093)
0 引 言
自动驾驶是近几年的热点研究领域,而3D感知是其中的核心问题.自动驾驶车辆通过多种传感器感知周围环境,目前常用的车载传感器包括激光雷达、摄像头、毫米波雷达等.激光雷达扫描到的点云数据能提供精确3D位置信息,但在整个空间中分布稀疏且不具备丰富的语义信息.激光束的扇形分布使远处物体的反射点相对较少甚至不足以描述物体大致结构.图像数据缺失具体的物体深度信息,但具有丰富的语义信息.毫米波雷达对外界环境变化(光线、雨雾)不敏感且能获取物体的相对速度,但无法感知到静态物体.传感器融合的目的是综合利用不同种传感器达到更好的检测效果.在3D目标检测任务中,常用的传感器方案为单激光雷达感知、单目视觉感知、双目视觉感知、激光雷达与摄像头融合感知.
融合感知模型存在3个核心问题:融合什么?何时融合?怎么融合?针对这3个问题展开研究即建立融合感知模型.分析常用自动驾驶数据集KITTI[1]与nuScenes[2]的3D目标检测排行榜,可以发现排名靠前的模型使用摄像头和激光雷达传感器较多.激光雷达产生点云数据,摄像头产生图像数据,融合感知在各个传感器单独感知基础上进行,因此,点云[3-6]和图像[7-9]的单传感器感知模型常被直接或间接用在融合模型中.对原始点云与原始图像进行映射融合可以保留更多环境信息,但同时也会引入更多的干扰信息.对点云模型输出和图像模型输出进行融合会损失部分信息,但引入的干扰信息较少.此外,还有多种在模型中间进行融合或交织在一起的深度融合方式等等.
融合模型面临如何找到点云与图像对应关系问题,点云与图像的映射常通过预先对激光雷达和摄像机进行矫正与标定实现,这会引入一部分误差.此外,这种静态标定方式限制了激光雷达与摄像机的相对位置,该预定位置的变化会导致映射偏移的误差.在自动驾驶车辆行驶过程中,路面情况等因素会影响其相对位置,从而引入偏移误差.当前的融合模型基本采用该映射关系把对应位置的点云特征与图像特征进行融合,这些误差会直接导致融合偏差从而影响融合模型检测准确率,过多干扰信息的存在甚至会使融合模型达不到单激光雷达模型的检测效果.此外,这种融合方式要求采集同一时刻的点云与图像数据,不同时刻的数据需要转换到同一时刻,因此,采集时间的不一致与转换误差也会导致映射偏移.图1展示了映射的标准情况与偏移情况,左图为无偏移情况下的点云到图像映射,右图为一定程度偏移下的映射.由于公共自动驾驶数据集[1,2]提供的数据基本为标准状态下采集,不包含映射偏移,因此,当前融合模型[10,11]基本不考虑映射偏移情况进行数据融合与模型设计.

图1 映射偏移示例Fig.1 Example of mapping offset
为缓解通过传感器标定进行点云与图像融合的局限性并降低映射偏移带来的负面影响,本文致力于把融合过程与预先标定得到的传感器映射矩阵解耦合,即不依赖该映射关系进行点云与图像对应.点云与图像是对同一现实场景的不同表达,本质上描述的是同一场景并具有相同的内在联系,通过挖掘潜在的场景关系与上下文可以找到点云与图像之间的对应关系.在同一场景的不同表达中,物体的绝对位置和大小会改变,但物体间相对关系保持一致.此外,同一物体虽然有不同的表达,但其高层特征和周边物体信息可以体现出两种表达间的联系.
为实现上述不依赖于点云到图像映射关系的融合感知模型,本文提出了基于异构图神经网络的3D目标检测优化模型HetGNN-3D.通过传感器标定得到的映射关系把点云中的每个点通过映射矩阵投影到图像,即以点为粒度的融合.而HetGNN-3D模型是把每个场景中的实体在不同传感器下形成的对象作为融合单位,即以对象为粒度的融合.对象粒度可以捕获对象间交互信息及对象本身信息,相对于点粒度更具有特异性并容易挖掘潜在的对象间对应情况,这使本模型在融合过程中可以不依赖前述映射关系.为了得到实体在不同传感器下的对象,HetGNN-3D首先通过点云3D目标检测模型与图像2D目标检测模型得到对应的3D对象与2D对象,包含对象位置、大小、特征等信息.图结构能更好的描述对象间交互信息并表达整个场景且不同传感器提供了不同类型的对象,因此,HetGNN-3D把每个对象作为节点并对节点进行全连接建立包含两种节点与3种边关系的异构图.异构图的处理相对同构图更为复杂,因此,HetGNN-3D针对点云与图像融合感知场景下的异构图设计了模型结构,使用MPNN[12]图神经网络框架建模,包含图初始化、消息传递、图读出3大模块.图初始化模块进行异构图的建立与对象节点初始特征编码.异构图的特殊处理体现在消息传递模块,在消息传递模块,迭代多个“边嵌入-消息聚合-节点更新”子模块进行消息传递,消息聚合子模块根据边类型不同分类聚合同类边消息,节点更新模块分别对各类汇总消息使用不同的GRU[13]门控处理单元更新节点信息.图读出包含用于对象关系预测的边读出与用于3D目标检测优化的同对象子图读出.对象关系预测判断两个对象节点是否属于同一对象,包括同构对象预测(同一类别的两个对象节点)与异构对象预测(不同类别的两个对象节点),其中,异构对象预测达到了点云与图像对准匹配的目的,替代了通过传感器标定进行点云与图像融合.对象级别的数据融合避免了传感器相对位置偏移与时间偏移引入的误差,使模型具有更高的容错性与泛化能力.在去除不存在关系的对象间边后,得到属于同一实体的同对象子图,基于该子图进行3D目标检测得到优化后的3D目标检测结果.对于同一对象,大部分目标检测模型会输出多个对象目标框,常在后处理过程中应用NMS(Non-Maximum Suppression)来去除冗余框,而对对象子图进行读出可以降低模型输出目标框的重复性.
本文的主要贡献点总结如下:
1)本文基于对象粒度建立异构图进行传感器融合感知,提出了新模型HetGNN-3D,该模型使用融合信息提升了3D目标检测模型准确率,给出了基于自动驾驶场景的异构图神经网络解决方案.
2)在模型前向推理过程中,采用对象关系预测模块替代了传感器标定得到的映射关系,为数据融合提供了新视角并提升了融合模型的容错性与鲁棒性.
3)本文在公开的自动驾驶数据集nuScenes上进行实验,实验显示融合感知模型能对单传感器模型的检测结果进行优化.此外,实验验证了基于对象潜在关系的融合方案受传感器映射偏移干扰影响较小.
1 相关工作
1.1 目标检测
基于图像的2D目标检测已经发展的比较成熟,常用的目标检测模型有yolo[14,15]系列,SSD[16]等等.此外,近几年提出的CenterNet[7]把目标物体表示为一个中心点,先检测该关键点再由此推断相关的2D目标框信息.CornerNet[17]检测目标框的左上和右下这对关键点并基于此进行目标检测.CenterNet[7]在Cornernet[17]上进行优化,添加中心点预测并对两个对角线关键点做了限制.ExtremeNet[18]利用沙漏网络为目标的4个极值点和中心点进行检测.
3D目标检测在近几年得到了蓬勃的发展,大量2D目标检测技巧可以应用到3D目标检测中,此外,对3D空间的感知是自动驾驶场景的核心问题.基于激光雷达的3D目标检测模型可以分为3类:基于点的模型、基于体素的模型与基于视图的模型.对于基于点的模型,PointNet[19]与PointNet++[20]模型奠定了这类模型的基石,3DSSD[6]提出了基于特征距离的最远关键点采样且是一种单阶段的模型,Pointrcnn[21]是双阶段的3D目标检测模型.基于体素的模型往往会把不规则的点云数据表示为体素,即把整个3D空间从长宽高角度切割成一个个小立方体,然后用应用3D稀疏卷积[22]来提取点云特征,代表性的模型如VoxelNet[4]等等.基于视图的模型会把3D空间投影到2D平面然后应用2D目标检测模型进行3D目标检测,如Pixor[23]使用了俯视图和PPC[24]使用了摄像机视图.此外,CenterPoint[3]由CenterNet[7]发展而来,把3D目标表示为一个中心关键点并得到相关3D信息.
基于激光雷达与摄像机的融合感知模型可以互相弥补各自传感器的不足从而提升感知精度.F-pointNet[25]先在图像上进行目标检测,然后把目标投影到3D空间形成视锥体进行3D目标检测.PointPainting[10]把图像的目标分割结果投影到点云空间,然后应用点云的3D目标检测模型.EPNet[11]的传感器融合过程交叉在模型的各个阶段,融合程度较深.
1.2 图神经网络
图结构拥有强大的场景表达能力,基于图结构发展而来的图神经网络展现出强大潜力.MPNN[12]对图神经网络模型进行归纳与标准化,提炼出图神经网络的框架,主要包括消息传递、消息更新与读出模块,可以基于此设计具体的图神经网络模型.GCN[26]与GraphSAGE[27]是常见的图神经网络模型,常被用做基础模块来解决基于图的任务.GatedGraphConv[28]应用门控神经网络GRU[13]的思想来进行消息更新.对于异构图,不同性质的节点或边增加了图的复杂性.HyGNN[29]使用不同的网络模块处理不同种类的数据并采用可学习的适配器模块转换不同领域的特征来进行消息传递与聚合.HetGNN[30]同时考虑了节点异构的内容、异构的节点与异构边,使用RWR(Random Walk with Restart)模块采样异构邻居,采用Bi-LSTM[31]对无序的内容进行编码,先对节点的同构信息进行编码与聚合再组合该节点的不同种类的信息.HAN[32]根据不同元路径提取不同的语义信息并为每个元路径分配权重得到语义级注意力,对于同一元路径采样的邻居,使用节点级注意力区分不同邻居的重要性.
2 HetGNN-3D模型
2.1 模型结构与定义
如图2所示,本模型主要分为3大模块,分别是图初始化模块、消息传递模块、图读出模块.图初始化模块的输入为点云3D目标检测模型的输出和图像2D目标检测模型的输出,输出为构建好的基于对象粒度的异构图.消息传递模块基于该异构图进行消息传递与节点信息更新,整个过程分为3个子模块,包括边嵌入、同类边信息聚合、节点更新,迭代多次该过程可以得到获取周边信息后的更新图,该图的节点既包含同构对象信息又包含异构对象信息.图读出模块包含边读出与对象子图读出,边读出目的为预测该边所连接的两个节点是否属于同一对象,属于同一对象的节点及其关系形成对象子图,基于该对象子图得到3D目标检测优化后的预测结果,即为融合点云与图像信息感知到的目标对象.
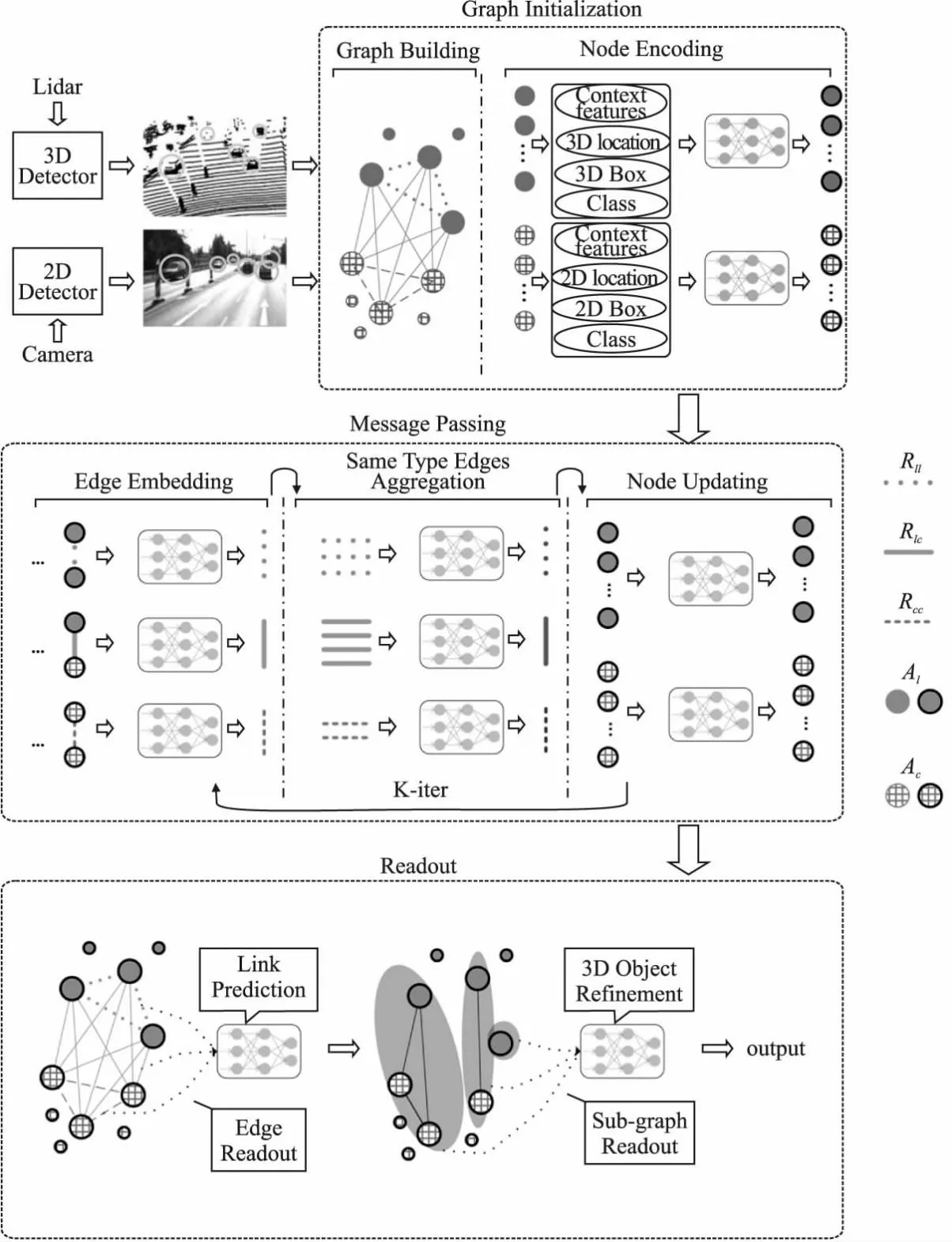
图2 模型结构图Fig.2 Architecture of model
本文利用图神经网络来进行融合感知,因此需要构造图结构.图结构常被定义为G=(V,E)其中V是一系列节点的集合,E是由V中节点形成的边的集合,即E∈V×V.此外,定义节点类型的集合为A,边类型的集合为R.对于V中节点,存在节点类型映射关系φ:V→A与边类型映射关系ψ:E→R.若节点类型大于1或边类型大于1,即|A|+|R|>2,则该图为异构图.由于点云与图像属于异构数据,因此本模型的融合感知也是基于异构图进行的.
2.2 图初始化
图初始化包含节点建立、边建立与节点特征编码.3D目标检测网络和2D目标检测网络输出为对象目标框,本文定义每个目标框为一个对象且把这些对象目标框作为节点建图,即基于对象粒度建图.相对于以点云中点为粒度和以图像中像素点为粒度建图,以对象粒度建图可以把节点数量控制在相对较小的范围内从而提神模型的计算速度并可以统一这两种异构数据中节点的表示方式.此外,这种建图方式可以捕获对象之间的交互关系来对自身对象的信息进行补足与调整,比如同一车道的两辆车的朝向应该类似和图像中对象间的相对位置关系应和点云中对象间的相对位置关系保持一致.
在该自动驾驶场景中,节点类型A={Al,Ac}且|A|=2,其中Al点云中对象节点,Ac表示图像中对象节点.由于对象数量相对点云中激光点的数量较少,本文采用全连接的方式来建立边.此时,边类型R={Rll,Rlc,Rcc}且|R|=3,其中Rll类型的边连接两个点云中对象节点(Rll:Al⟺Al)、Rlc类型的边连接点云中对象节点与图像中对象节点(Rlc:Al⟺Ac)、Rcc类型的边连接两个图像中对象节点(Rcc:Ac⟺Ac).最后,本文可以得到包含异构节点与异构边的混合图Ghybrid=(V,E),这又可以根据边类型分成3个子图Ghybrid={Glidar,Gcamera,Gfuse},其中:
Glidar=(Vl,El),∀v∈Vl,φ(v)∈Al,∀e∈El,ψ(e)∈Rll
(1)
Gcamera=(Vc,Ec),∀v∈Vc,φ(v)∈Ac,∀e∈Ec,ψ(e)∈Rcc
(2)
Gfuse=(Vf,Ef),∀v∈Vf,φ(v)∈A,∀e∈Ef,ψ(e)∈Rlc
(3)


(4)
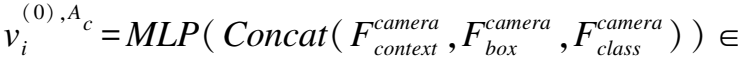
(5)
2.3 消息传递
文献[12]把图神经网络模型归纳出了一个通用框架,即消息传递神经网络(MPNN,Message Passing Neural Network).MPNN主要分为两个步骤,分别为周边信息收集与节点更新,定义为:
(6)
(7)

异构图的消息传递即包含同构消息又包含异构消息.对于点云中的对象节点,点云对象是其同构消息,图像对象是其异构消息.对于图像中的对象节点,图像对象是其同构消息,点云对象是其异构消息.为了获取异构邻居节点的信息并更新当前节点,本文把公式(6)细化为两步来聚合周边信息,分别为边嵌入与同类边信息聚合.
如图2中边嵌入模块所示,本文建立的异构图包含3种类型的边(Rll,Rlc,Rcc),本文根据边类型R的不同分别进行边嵌入,定义为:
(8)
(9)
(10)
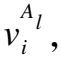
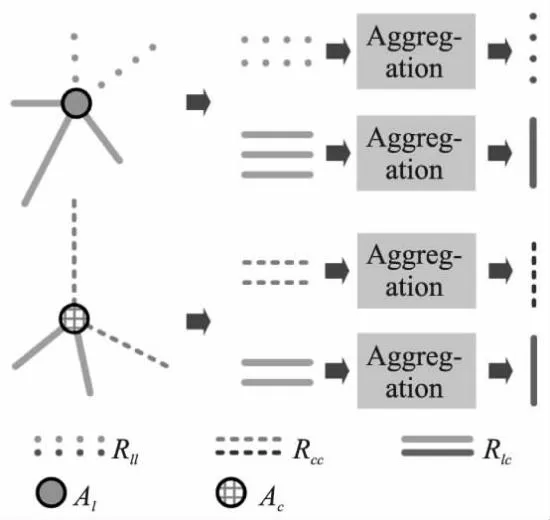
图3 同类边信息聚合模块细节 Fig.3 Detail of same type edges aggregation

(11)
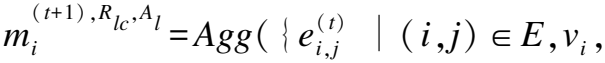
(12)

(13)
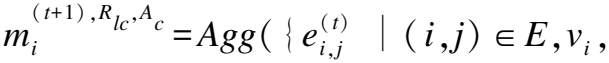
(14)
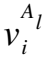
(15)
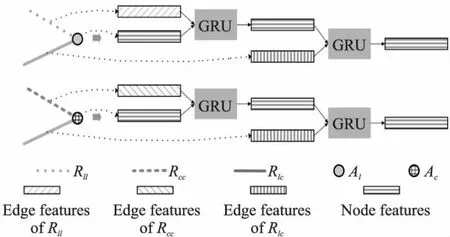
图4 节点信息更新模块细节Fig.4 Detail of node updating
(16)

(17)
(18)
UGRU(·)为基于GRU[13]的节点更新函数,即门控信息更新单元,模型通过门控单元提取出可以合并到当前节点有效信息.
2.4 图读出
如图2中图读出模块所示,本模型的图读出分为两部分:边读出与子图读出.通过边读出预测边两端的节点是否属于同一对象,边ei,j连接两个节点vi与vj,若这两个对象节点属于同一目标对象,则Relationi,j=1,若这两个节点属于不同对象,则Relationi,j=0.对边读出得到边嵌入Fi,j,定义为:
Fi,j=Readout (vi,vj)
(19)
本文采用余弦相似度进行边读出(公式(20))然后经过MLP与sigmoid激活函数σ(·)得到对象关系预测的结果Relationi,j(见公式(21)).
(20)
Relationi,j=σ(MLP(Fi,j))
(21)
当vi与vj属于同一类别节点时,边关系存在即找到了同一对象的冗余目标框;当vi与vj属于不同类别节点时,边关系存在即找到了同一对象的异构传感器数据.所有属于同一对象的节点与边形成对象子图Gobject,对Gobject进行图读出得到对象子图嵌入Fobject,定义为:
1.2.2 对照组 股静脉置管方法:实施股静脉穿刺的护士均为本科室两位住院医师,有1年以上置管经验。选择我国福尼亚公司生产的4 Fr单腔中心静脉导管,穿刺鞘22 G,采用塞丁格技术进行穿刺,对照组导管穿刺长度为18~20 cm,平均为(19.07±0.66)cm。
Fobject=Readout(Gobject)
(22)
图读出使用最大值读出函数,随后通过基于多层感知机的目标分类头和3D目标框回归头得到优化后的3D目标检测结果.
2.5 损失函数
本文的损失函数L分为3个部分,分别为边预测的损失函数Llink、3D目标检测损失函数L3D和对象消息损失函数Lmessage,使用系数β1、β2、β3平衡这3个部分,定义为:
L=(β1×Llink+β2×L3D+β3×Lmessage)
(23)
由于使用全连接来进行异构图的边建立,而同一物体节点对应的连接边相对较少,因此,异构图中的大部分边应被分类为不存在连接(Relationi,j=0),仅少部分边被分类为存在连接(Relationi,j=1).面对样本分布不均衡问题,为了提升模型性能,采用focal loss[33]来进行边关系分类,计算如下:
(24)
α为类别权重因子,γ为调节因子.对于点云对象子图Glidar,模型计算节点对应目标检测模型输出3D框和目标对象真实3D框的IOU来判断这些节点属于哪个目标对象;对于图像对象子图Gcamera,模型计算节点对应目标检测模型输出2D框和目标对象真实2D框的IOU来判断这些节点属于哪个目标对象;对于融合对象子图Gfuse,模型先把点云中3D目标框投影到2D图像中,然后通过投影后的目标框与图像中目标对象的2D框的IOU来判断这些节点属于哪个目标对象.同一对象的所有节点间存在连接,不同对象节点之间不存在连接,这些连接关系作为对象关系预测训练集的真实值.L3D包括3D框回归损失函数和目标分类损失函数,本文采用与3D目标检测模型一致的计算方式.对于同一类别的对象节点,在迭代多次消息传递过程后,所有节点所包含的信息应趋于一致,定义为:
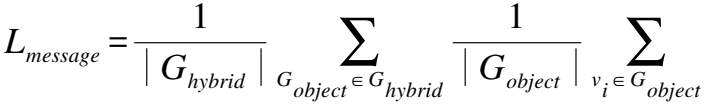
(25)
其中|Ghybrid|为Ghybrid中所有子图数量,|Gobject|为对象子图中所有节点数量,MEAN(Gobject)表示所有节点特征的均值,vi为节点特征.
3 实验及分析
3.1 数据集介绍
本模型在nuScenes[2]数据集进行实验来验证模型有效性,这是一个大规模自动驾驶数据集,包含1000条自动驾驶场景数据段,其中分为700条训练集、150条验证集和150条测试集.数据集由6个摄像机、1个32线激光雷达等传感器采集而来且包含点云位置到图像位置的映射信息.此外,基于该数据集的3D目标检测任务包含10个物体类别.
3.2 实验设置
为了进一步增加数据集的丰富程度,使用平移、翻转、旋转等方式进行数据增广.本模型使用CenterPoint[3](以PointPillars[5]为后端)作为图2中基于点云的3D Detector,使用CenterNet[7]作为图2中基于图像的2D Detector.由于图结构是本文对场景建立的独特表达方式,nuScenes[2]数据集没有直接提供对象关系的真实值,因此,在进行对象关系预测模块训练时,本文采用IOU(交并比)来构造边预测的真实值.若CenterPoint的3D输出框和3D实际框IOU大于阈值,则该3D输出框形成的点云对象节点属于该3D实际框对应的实体.在找到3D实际框对应图像中的2D实际框后,把3D输出框投影到图像平面得到2D投影框,若2D投影框和2D实际框IOU大于阈值,则该2D投影框对应3D输出框形成的对象节点属于该2D实际框对应的实体.同理可以根据CenterNet的2D输出框和图像中的2D实际框找到2D输出框形成的图像对象节点对应的实体.最后,属于同一实体所有对象节点之间的边真实值设为1(边关系存在),其余边真实值设为0(边关系不存在).由于数据集提供的点云到图像映射为标准映射,不包含激光雷达和摄像机相对位置改变造成的偏移误差和传感器采集时间不同步造成的误差,本文在实验中采用不同均值与方差的正态分布模拟了相对位置便宜误差和使用一定时间差采集到的图像和点云进行融合模拟时间误差.本模型的训练环境为一块GTX2080ti显卡.模型使用adam优化器训练.模型的评价指标采用mAP(由P-R曲线得到)和NDS[2](nuScenes提供的3D目标检测评价标准).
3.3 实验结果分析
由于本文需要验证模型在干扰下的检测准确率,而干扰是基于标准数据集模拟而来,因此,本文在nuScenes验证集上进行模型对比.表1展示了模型在nuScenes验证集上的准确率,CenterPoint-P表示使用PointPillars后端的CenterPoint模型,Painted-C-P表示应用PointPainting进行数据融合的CenterPoint-P模型.从表中可以得,相对于单传感器模型,HetGNN-3D平均提升了6.1%mAP和3.8%NDS,体现出本融合模型能有效利用图像信息与点云信息提升3D目标检测准确率,优化单传感器检测模型的输出.其中,“Bicycle”类别准确率提升相对其它类别更明显,这是因为自行车的线形镂空物理结构使激光束反射点较少,采集到的点云不足以描述自行车结构,而图像中的自行车具有丰富语义信息,能很好弥补自行车点云的缺点并使其更易被识别出.表2为在传感器相对位置偏移下融合模型Painted-C-P和本文的HetGNN-3D之间的检测准确率(mAP)对比,位置偏移程度列为模拟偏移像素的正态分布均值(方差为5).表3为在传感器采集时间偏移下的检测准确率(mAP)对比,时间偏移差列为偏移的时间步大小.从表2~表3中可以看出,在基于传感器预先标定的映射关系进行融合的Painted-C-P模型检测准确率随着偏移干扰程度加深而递减时,HetGNN-3D受偏移影响相对不明显.图5展示了本模型3D目标检测结果,第1列为标记的目标框,第2列为融合模型HetGNN-3D输出的目标框.

表1 基于nuScenes验证集的3D目标检测准确率Table 1 Accuracy comparison of 3D object detection on the nuScenes validation set

表2 在传感器相对位置偏移下的模型准确率对比Table 2 Comparison of model accuracy under sensor relative position offset

表3 在传感器采集时间偏移下的模型准确率对比Table 3 Comparison of model accuracy under sensor acquisition time offset
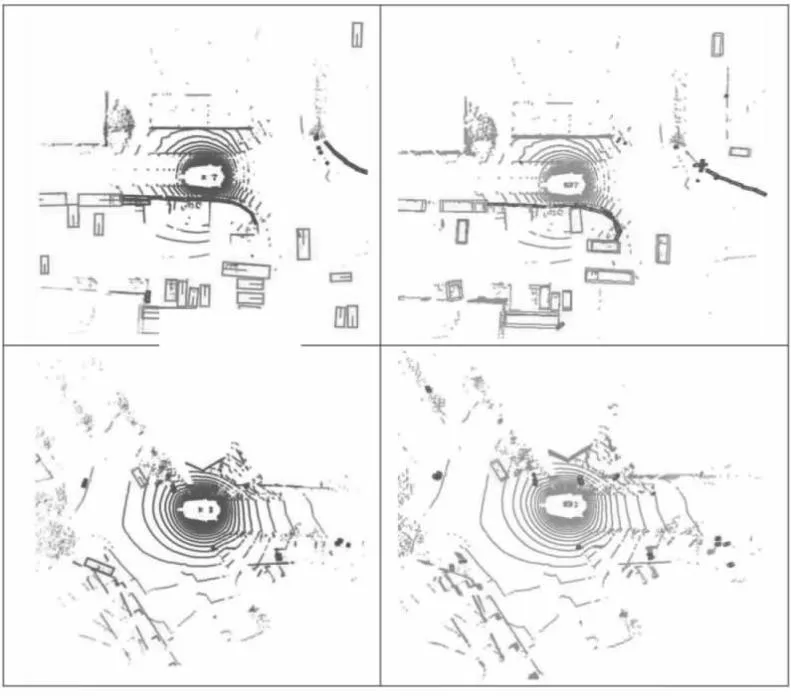
图5 模型3D目标检测结果示例Fig.5 Examples of 3D object detection results of our model
4 消融实验
4.1 IOU阈值对边预测准确率影响
本文在构建对象关系预测真实值时,定义对象框与真实框IOU大于一定阈值为对象属于真实框对应的实体,属于同一实体的所有对象间(包括点云对象与图像对象)边关系值为1,即边存在.图6展示了IOU阈值的设定对边关系预测准确率的影响,随着阈值的增大,对象关系预测的准确率越高,在阈值为0.8时,准确率达到最高,随后准确率随着阈值的增大而下降.因此,本文选择0.8为HetGNN-3D模型的阈值.

图6 IOU阈值对链接预测准确率影响Fig.6 Impact of IOU threshold on link prediction accuracy
4.2 边预测为存在的阈值对边预测准确率的影响
对象关系预测检测头的输出为边存在的概率,若预测值大于阈值,则边存在.从图7可以看出,当阈值设为0.5时,边预测准确率达到高峰,此后随着阈值越接近1,准确率略微下降.当阈值小于0.5时,预测准确率降低明显.因此,本文采用0.5为边关系预测为真的阈值.

图7 边存在阈值对边预测准确率的影响Fig.7 Influence of the edge threshold on the accuracy of edge prediction
4.3 聚合函数对准确率影响
本文对比了3种常用聚合函数(Mean,Max,Sum)对模型的影响,表4展示了在消息传递模块应用各个聚合函数得到的模型预测准确率,实验表明均值聚合相对其余两种聚合函数能达到更高的准确率.累加聚合方式相对表现较差,这是因为每个对象节点对应的有效邻居节点数量不一致,累加的方式无法把特征保持在同一标准尺度,不利于模型训练.综合对比实验结果,本文选择均值聚合方式.

表4 不同聚合函数下模型准确率Table 4 Model accuracy under different aggregation functions
4.4 对象消息损失函数对模型准确率影响
在经过多轮消息传递步骤后,每个节点获取到了足够多的周边信息,同一实体的对象节点对应同一检测目标框真实值,因此,同一实体的对象特征应趋于一致.对象消息损失函数被用来控制同一实体对象特征差别,表5显示,添加该损失函数后模型能达到更高的检测准确率.

表5 对象消息损失函数对模型准确率影响Table 5 Influence of object message loss function on model accuracy
5 总 结
本文把基于图像2D目标检测模型的输出和基于点云3D目标检测模型的输出作为对象,以对象为节点建立异构图并进行对象级传感器融合优化单一传感器模型的检测结果,达到更高的检测准确率.通过异构图描述自动驾驶融合感知场景可以捕获对象间内在联系,对象间边关系预测可以替代传感器标定得到的点云到图像的映射并达到点云与图像对准目的,这使本模型受传感器位置偏移与采集时间偏移影响较小,具有更好的鲁棒性与容错能力.未来可以从以下角度进行研究:1)改进异构图处理网络,使其能更好传递与聚合异构信息;2)进一步改善样本分布不均衡对模型检测准确率的影响;3)简化网络结构使其达到更快的运算速度.
