数据分布不平衡的课堂参与度自动识别研究
2024-02-27王嘉豪周修庄
王嘉豪,徐 敏,孙 众,周修庄
1(首都师范大学 信息工程学院,北京 100048)
2(北京邮电大学 人工智能学院,北京 100876)
0 引 言
在线课堂是一种不同于传统线下课堂的全新教学形式,它的所有教学活动包括授课、答疑以及作业提交与反馈都转移到互联网上进行.在线课堂最大的优势是不受时空限制,在新冠疫情流行的背景下它逐渐成为了目前的主流教学形式.此外,线上教学还可以提供更为丰富的教育内容,现有的一些MOOC平台包含许多学校的课程资源,学生可以选取适合自己的课程资源进行补充学习.在线课堂相较于传统的线下课堂具有时空不限、多样性和灵活性等诸多优势,因而受到了越来越多的关注.
但是,在线课堂也存在一些明显的问题,例如其缺少传统课堂中师生之间的实时互动,因而学生在线学习过程中容易出现注意力不集中等情况,导致在线教学的教学效果普遍不如传统课堂[1].在面对面的传统课堂里,教师可以时刻关注每一位学生的表情与反应,通过直接观察获取学生的学习专注参与状态[2,3],然后及时调整当前教学节奏、教学方式、教学内容和教学态度.但是,在线课堂上学生不能随着课堂进度实时反馈自身的状态信息,只能在课后通过网络提交方式反馈听课效果,无法实现班级以及学生个性化跟踪与反馈.师生无法面对面交流造成的反馈延时性,是当前在线教学亟待解决的问题[4].
如何应用人工智能和大数据技术助推在线教学,真正形成智能时代教育新模式,还面临着诸多困难与挑战,国内外相关研究仍处于起步阶段.近年来,国内外学者对参与度自动识别问题开展了一些探索和研究.其中,采用人脸表情、肢体姿态和动作行为等情感数据,基于计算机视觉技术和机器学习方法研究参与度评估模型,逐渐成为该领域的主流技术路线.在国外,英国诺丁汉大学、麻省理工学院、英国布鲁尔大学等研究机构为该领域的研究发展做出了重要贡献,包括参与度自动评估视频数据库的建设、参与度自动评估系列挑战赛和研讨会的组织等[5-7].在国内,中国科学院计算技术研究所、中国科学院深圳先进技术研究院、中国科技大学等高校和科研机构,在基于人脸表情、身体姿态动作的学习参与度智能评估方向开展了有益的探索和研究[8].
据统计无论在真实课堂还是在线课堂的教学场景,大部分学生课上都能保持注意力集中,只有少部分学生出现专注度不够和听课走神的情况.这种现象在课堂参与度识别任务中的表现形式是样本类别分布不平衡,即极低参与和低参与的样本数据量非常少,绝大部分样本都属于一般参与和高参与这两个类别.因此,本文使用计算机视觉特征分析相关技术,对学习参与度自动识别这一任务展开了研究,自动实时分析和识别在线课堂的学习参与度.并且,重点针对参与度自动识别任务中样本类别分布不均衡的问题,在模型层面提出方法以改善该问题带来的负面影响.具体地,研究利用双边分支网络模型对特征学习和分类器两个部分解耦,通过发挥两个模块各自优势以提升不平衡类别样本的分类性能.
本文工作主要包含以下内容:
1)采用视频分段的方式,通过VGGFace、C3D网络分别提取视频片段的面部表情特征和身体姿态特征,并提出基于注意力机制的聚合模块CTAB,对视频片段特征进行融合,使得参与度高度相关的帧序列获得更大的权重.
2)针对参与度数据类别不均衡问题,提出基于双边分支网络的课堂参与度识别模型,将特征学习和分类器学习进行解耦,以提升模型对类别不平衡数据的分类能力.
3)在课堂参与度数据集DAiSEE上进行了大量实验,实验结果验证了本文提出方法的有效性,尤其对少样本类别的识别性能提升比较显著.
1 相关研究
学生参与度分析一直以来都是教育领域关注的重点研究内容.早期,对学生参与度评估的传统方法主要包括自身报告和观察评测两种方法.Vanneste等人[9]曾在比利时一所中学通过自身报告的方式对学生参加讲座的参与度进行测评,他们在讲座过程中每隔5~12分钟发送电子弹窗收集学生的参与度水平.Alyuz等[10]收集了17名学生的在线学习数据,邀请三位教育学专家对学生在视频学习过程中的鼠标移动以及学习互动内容进行标注,通过投票等方式形成参与度的评价.但是上述方法依赖于人为主观评价,参与度评价结果不够客观准确.
随着智能设备的普及和机器学习技术的发展,人工智能教育领域开始关注参与度自动识别这个新兴研究方向[11].Monkaresi H等[12]和Khedher AB等[13]使用心率、脑电等生理信号进行参与度的自动识别,但是使用生理信号进行参与度测量需要学生佩戴外部仪器,对学生的活动造成干扰,因而难以应用在教学实践中.计算机视觉领域研究参与度识别任务的方法,主要先通过手工提取的方法进行面部特征提取,然后利用分类器或回归器对特征进行参与度评估.Kamath等人[14]通过提取HOG特征,利用实例加权多核向量机对参与度进行预测.Sanerio等人[15]结合面部活动单元(AUs)、二维面部关键点、三维头部特征以及身体运动姿态等进行参与度分析.Whitehill 等人[16]从受试者视频中进行手工特征提取,并且使用支持向量机SVM 和GentleBoost对参与度进行预测,并且达到了与人工标注相接近的水平.Monkaresi等人[12]结合面部活动、LBP-TOP以及受试者心率等特征构造出分类模型,在小样本数据集中进行参与度识别研究.
近年来随着深度学习技术的深入研究和广泛应用[17],各种计算机视觉任务包括参与度自动识别任务取得了显著进展.Yun等人[18]在儿童参与度自动识别任务中,首先采用预训练的VGG网络提取视频帧的低层视觉特征,然后将连续帧的低层特征输入空间动态模块提取高层特征.该方法通过微调预训练的VGGFace网络,克服参与度训练数据量较少的不足.Wu等人[19]提出一种多特征工程和保守优化的多实例学习方法用于参与度预测,首先从视频中手工提取面部特征和受试者上半身姿态特征,之后结合LSTM和GRU对特征进行分类,检测参与度水平.Khine等人[20]使用预训练的VGG16人脸模型,通过不同的峰值帧和中性帧,提取人脸突出的基本特征并消除不相关的特征,在DAiSEE数据集上的实验结果达到了50%的准确率.Zhang等人[21]对用于动作分类的I3D模型进行了改进和优化,并将其应用于参与度识别任务,在DAiSEE数据集上取得了52.35%的准确率.Liao等人[22]提出了深度人脸时空网络(DFSTN),首先通过预训练的SE-ResNet-50网络进行人脸特征的提取,然后采用基于全局注意力机制的LSTM生成注意力隐藏状态,该方法通过捕获面部时空信息,有助于感知细粒度的参与状态,有效提高了参与度预测性能.Ali Abedi等人[23]提出了一个端到端的由残差网络(ResNet)和时间卷积网络(TCN)组成的混合神经网络架构,其中ResNet网络提取连续视频帧中的空间特征,TCN则分析时间维度的变化,在DAiSEE数据集分类准确率达到了60%以上的准确率.
但是,现有的参与度自动识别公开数据集都存在严重的数据分布不平衡问题.对于解决不平衡样本的分类难题,Mateusz Buda等人[24]和Jona Byrd等人[25]尝试使用过采样策略,对数量较少的样本进行重新采样,但是过度重复的样本在模型训练的过程中容易发生过拟合,降低泛化能力.Cao等人[26]设计了一种对标签分布感知的损失函数,使得在少数样本在训练优化中获得更大的关注.Yin Cui等人[27]以及Ouyang等人[28]尝试使用微调策略解决长尾数据集分类问题,将训练的过程拆分为两个阶段:第1阶段采用传统方法,第2阶段则通过减小学习率并微调网络进行重新平衡,整个训练过程相对复杂.在2020年,由BoyanZhou等人[29]提出了双边分支网络结构(Bilateral Branch Network,BBN),从网络结构的角度解决类别不平衡数据分类,通过增加一条分支达到重平衡;在解决类别分布不平衡的同时,另一条传统学习分支仍然能够在表征学习方面取得较好效果.该方法应用在不同的不平衡数据集上,均获得了显著的效果.
2 本文方法
2.1 特征提取
本文使用预训练的VGGFace,对受试者的面部特征进行特征提取.VGGFace网络包含5个模块,每个模块包含2或3个卷积层和1个最大池化层.输入数据的维度是[16,224,224,3],其中16表示每次输入到模型的图像数量,224和224表示图像的宽与高的像素值,3表示彩色图像RGB颜色的3个通道,网络输出的数据维度为[16,1000],表示16个样本、每个样本的特征维度为1000.VGGFace网络结构如图1所示.

图1 VGGFace网络结构图Fig.1 VGGFace network structure
考虑到课堂参与度特征除了与面部表情有关,受试者的参与度水平与当前的身体姿态也有着密切关联,因此本文使用C3D网络提取受试者的身体姿态特征.由于DAiSEE数据集样本是用视频形式表示的,通过连续的视频帧判定受试者的身体姿态参与度状态,不同于常规的卷积神经网络采取的是2维卷积运算,C3D网络中的3维卷积在2维卷积的基础上增加一个维度,用来对时序信息进行处理.本文使用的C3D网络结构共计包含8个卷积层,5个最大池化层以及2个全连接层.数据的输入维度为[8,16,112,112,3],其中8表示每次训练的样本数量,16表示每个样本包含16帧图像,112和112表示图像的宽和高,3表示图像RGB颜色的3个通道.网络输出是数据维度为[8,1000]的特征向量.C3D网络结构如图2所示.

图2 C3D网络结构图Fig.2 C3D network structure
通过VGGFace网络和C3D网络提取受试者的特征后,将特征向量进行串行拼接,合并为整体的特征.之后将特征输入到视频特征融合模块进行视频特征融合.
2.2 视频特征融合模块
对于特征融合技术,目前主要采用均值融合法[30]和最大融合法[31],但两种方法均存在一些不足.考虑到注意力机制能够对输入信息中的重要部分给予更多的关注.因此,本文引入基于注意力机制的聚合模块,通过加权求和的方式对多个子视频进行视频特征融合.将注意力机制引入视频特征融合模块,对视频中参与度相关度高的部分赋予更大的权值,由此得到的特征有利于在后续的分类任务中获得更好的效果.
Yang等人[32]提出包含特征嵌入和特征聚合的神经聚合网络(NAN).在此研究基础上,本文提出双层级联聚合模块(Cascaded Two Aggregation Blocks,CTAB)对视频特征进行融合,双层级联聚合模块结构如图3所示.

图3 聚合模块CTAB结构图Fig.3 Structure diagram of the aggregation module CTAB
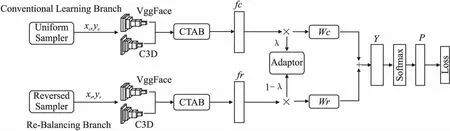
图4 提出的参与度识别网络结构Fig.4 Network architecture for our engagement recognition method

图5 DAiSEE数据集中不同参与度样本示例Fig.5 Examples of different samples from DAiSEE
双层级联聚合模块包含两个相同的子模块,每个子模块包括一个过滤层(Filter kernel)和一个线性层(Linear),模块采用tanh函数作为激活函数.将一组视频特征f=[f1,f2,…,fn]输入到CTAB中,在过滤层中视频特征f与过滤层权值计算内积,经过一个线性层处理,之后使用tanh函数进行非线性映射.
相关计算公式如式(1)~式(3)所示:
(1)
y1=W1a1+b1
(2)
z1=tanh(y1)
(3)
其中h1表示第一个模块中过滤内核的参数,a1表示经过过滤层处理后的结果,y1表示经过线性层后的结果,z1为经过激活函数后的结果.在第2个模块中输入部分替换成第一模块的输出z1,后续计算过程与模块一中的计算过程类似.经过两个模块处理后,将结果输入到Softmax层,得到权值w.将视频特征经过权重w进行融合,最终得到聚合视频特征F,相关计算公式如式(4)和式(5)所示:
(4)
(5)
2.3 数据分布不平衡的参与度识别
在分类任务中,数据集类别分布不平衡会很大程度上影响样本分类的准确性,在多样本的类别分类准确率高,而少样本的分类准确率相对较低.在DAiSEE数据集中4类样本的分布比例约为1∶8∶73∶67,其中参与度较低的样本(标签为0和1)数量明显少于参与度高的样本(标签为2和3).本文采用双边分支网络(BBN),用来解决参与度自动识别任务中样本类别分布不平衡的问题.
在深度学习中,特征学习和分类器学习通常是耦合在一起进行的,在样本极度不平衡的状态下,特征学习和分类器学习的效果均会受到一定程度的干扰.而双边分支网络模型包括了特征学习和分类器学习两条支路,减小了两个部分的相互影响,共同收敛到很好的效果.
本文在双边分支网络的基础上,结合参与度识别具体任务,提出了一种用于自动识别学习参与度的双边分支网络结构.该网络结构包括特征学习、分类器学习和累加学习这3个模块.在特征学习部分,使用均匀采样的方式对数据集进行采样,在均匀采样的过程中,每一类的抽样概率与该类别样本数量成正比,保留了数据原始的分布.在分类器学习部分中,采取反向采样的策略.在反向采样策略中每一类的抽样概率与样本数量的倒数成正比,样本数量越少的类别抽样概率越大,达到重点关注少数类别样本的效果.反向采样公式如式(6)和式(7)所示.其中Nmax表示所有样本的数量,Ni表示第i类样本的数量,pi表示第i类样本被抽样的概率.
(6)
(7)
将从数据集中采集到的数据分别输入到VGGFace网络模型和C3D卷积网络模型中提取特征,之后将特征输入到CTAB聚合模块中进行加权融合,得到了两条支路的特征fc和fr.然后将两条支路的特征通过适配器(Adaptor)进行融合.适配器的融合过程通过控制训练过程中比重λ,对两条支路得到的特征加权.在训练的初期,对特征学习给予更多的关注,在训练的中后期逐渐过渡到分类器部分的学习,在这个过程中会逐渐对分类小样本数据更为有利.总训练周期数表示为Tmax,当前周期表示为T,λ参数的数值随着训练周期的增加而递减,具体计算公式如式(8)所示.
(8)
模型的预测结果Y,计算公式如式(9)所示.Y=[Y1,Y2,…,Yn]T,n为对应的类别数.
(9)
输出的结果Y经过Softmax处理后,得到p=[p1,p2,…,pn]T,模型采用权重相结合的交叉熵函数作为损失函数.损失函数如式(10)和式(11)所示:
(10)
L=λLCE(p,yc)+(1-λ)LCE(p,yr)
(11)
其中LCE(p,y)表示交叉熵损失函数,yi表示的是第i的样本的标签,pi表示经过模型计算输出后第i个结果.最终模型的损失函数L按照适配器参数λ,对两条网络分支计算出的交叉熵损失函数进行分配.
3 实验部分
3.1 数据集
目前面向参与度自动识别研究任务的大规模公开数据集,包括DAiSEE数据集[5]和EmotiW数据集[7],这两个公开数据集的提出为相关研究提供了一个公共的研究平台.
DAiSEE数据集收集了112名受试者在图书馆、宿舍、实验室等场景中进行在线学习的视频,共计包含有9068个时长为10秒钟的视频.该数据集先后采用众包法、以及心理专家制定的黄金分割标准,对无聊、困惑、参与和沮丧4种情感状态的等级进行标注.其中受试者的参与情感状态,共分为极低参与、低参与、一般参与和高参与4个等级,分别对应标签0、1、2和3,每种标签对应的样本数量分别为61、440、4312和3758.
EmotiW(Emotion Recognition in the Wild Challenge)是由ACM多模态交互国际会议(ACM International Conference on Multimodal interaction,ICMI)举办,面向自然环境中不同情感计算任务的挑战赛,其中一个子任务是学生参与度预测(Student Engagement Prediction,EngReco).该任务提供的数据集,收集了78名受试者在实验室、宿舍以及露天场所等地点在线学习的视频记录,共计包含262个时长约为5分钟的视频.每个视频由5名人员共同标注,将学生参与度分为不参与、低参与、高参与和极高参与4种类别,参与度从低到高的四类样本数量分别为:9、45,100和48.
与相比DAiSEE数据集,EmotiW数据集在数据量上明显少于DAiSEE数据集且同样存在数据分布不平衡现象.因此本文的实验部分选择DAiSEE数据集.
3.2 数据预处理
数据预处理阶段主要采用OpenCV库,对DAiSEE数据集中的每个视频大约为300帧,以1/3的采样率进行取样,则每个视频采样100张图片.之后,将单个视频分割为4个子序列,子视频序列之间有2秒的重叠部分,以保证子视频含有时序信息.每个子视频序列长度4秒,每秒采样4帧,则每个子视频包含16帧图像.
3.3 评价指标
在分类任务中常用的评价指标包括混淆矩阵(Confusion Matrix)、准确率(Accuracy)、召回率(Recall)、F1值等.

表1 DAiSEE数据集分类任务混淆矩阵Table 1 Classification confusion matrix on the DAiSEE dataset
准确率表示为预测正确的样本数量在总样本数量的占比.准确率计算公式如式(12)所示:
(12)
对于不平衡样本的分类问题,分类的准确率会受到大样本数据类的影响,难以反映出小样本的分类效果.因此,还需要结合精确率、召回率和F1值对模型进行评估.
精确率表示的是对于每一个类别中分类正确的样本数占所有被分到该类别中的样本的比例.第i类的精确率计算公式如式(13)所示:
(13)
召回率反映的是该类样本中被正确预测的占比.第i类的召回率计算公式如式(14)所示:
(14)
F1值是该类的召回率和精确率的平均值,取值范围在0~1之间.当F1值越大时,模型的分类能力越强.第i类的F1值计算公式如式(15)所示:
(15)
3.4 实验结果与分析
首先,将本文方法与参与度识别主流方法进行了对比实验,具体实验结果如表2所示,其中:

表2 不同算法在DAiSEE数据集的分类准确率Table 2 Classification accuracy of different algorithms on DAiSEE
I3D网络[21]:通过对3维的卷积层和3维的池化层对视频的RGB流进行时序特征的提取,再利用光流进一步提升网络性能.在参与度分类任务中达到52.4%的准确率.
C3D网络[5]:主要采用了3维卷积,更加擅长学习时空特征,使用交叉熵作为损失函数.在DAiSEE数据集的分类准确率达到48.6%.
C3D(Ordinal metric)[33]:在C3D网络的基础上通过引入困难四元组,通过样本对嵌入向量距离与标签距离一致性有序原则,构造出有序度量损失,再与交叉熵损失结合,形成联合优化损失函数.将联合优化损失函数应用在C3D网络中得到58.9%的准确率.
LRCN算法[34]:输入连续16帧图像,首先经过卷积神经网络提取图像特征,之后经过LSTM融合时序信息,得到预测结果.最终在参与度分类问题上的准确率为57.9%.
DFSTN算法[22]:使用MTCNN进行面部的裁剪,使用SE-ResNet-50作为骨干网络进行特征提取,并且采用基于全局注意力的LSTM对面部特征生成隐藏状态.在DAiSEE数据集分类准确率达到58.9%.
DERN算法[35]:采用OpenFace捕获受试者的特征,将特征输入到结合时间卷积、双向LSTM以及注意力机制的模型中.在DAiSEE数据集上参与度分类准确率达到60.0%.
本文方法:训练周期设置为200,动量设置为0.9,学习率设置为0.0001,权重衰减2e-4,采用SGD优化器.在参与度识别任务中达到了63.6%的准确度,相比于其他算法具有一定优势.
其次,为了验证本文提出方法各个模块的有效性,本文以参与度识别的准确率为评价指标设计了一组消融实验,具体实验结果如表3所示.实验A:采用VGGFace+C3D作为实验设置,分类准确率为52.8%.实验B:采用VGGFace+C3D+CTAB作为模型架构,是本文进行验证的网络结构,与最终模型相比没有加入双边分支网络,分类准确率达到54.7%.实验C:采用C3D+BBN的模型结构,是双边分支网络在参与度识别任务中的验证结构,分类准确率达到55.8%.实验D即本文提出参与度自动识别方法,采用VGGFace+C3D+CTAB+BBN的实验设置,准确率达到了63.6%.实验D和以上3种实验设置相比,具有最好的识别性能,进一步验证了各个模块在参与度识别任务中的有效性.

表3 本文方法在DAiSEE数据集的消融实验结果Table 3 Ablation studies on DAiSEE
然后,为了进一步验证提出方法对少数类样本分类能力的提升,本文采用精确率、召回率以及F1值对DAiSEE数据集参与度的每一个类别标签上的分类效果进行更为细致的评估.具体实验结果如表4~表6所示.实验1,只采用单一的C3D网络进行参与度识别.实验2,使用VGGFace和C3D网络对参与度进行识别.实验3,使用VGGFace和C3D网络进行特征提取,聚合模块 CTAB用来特征融合的整体架构.实验4,在实验3的基础上将双边分支网络加入到整体网络架构中,验证该方法对不平衡样本的具体分类效果.

表4 不同方法在DAiSEE数据集的分类精确率Table 4 Precision of different methods on DAiSEE

表5 不同方法在DAiSEE数据集的分类召回率Table 5 Recall of different methods on DAiSEE

表6 不同方法在DAiSEE数据集的分类性能(F1分值)Table 6 F1 score of different methods on DAiSEE
从上述结果可以看出,实验1由于网络结构较为简单,没有对不平衡样本分类进行过特殊设计,因此在标签0和标签1这样的少数类样本的精确率、召回率和F1值都非常不理想.在实验2和实验3中,结果指标总体接近,实验3的结果略优于实验2,两组实验在标签0的识别效果依旧非常不理想,但在标签1的识别效果略有提升,精确率、召回率以及F1值分别达到7.56%、22.64%以及11.34%.实验在实验3的基础上加入了双边分支网络结构,在实验3与实验4的对比中,实验4的精确度、召回率以及F1值相较于实验3的指标高出约10%.实验验证了双边分支网络结构对于提升不平衡样本的分类是有效的.实验结果显示,本文方法不仅提高了参与度识别的准确率,并且对不平衡样本中的低参与度样本(标签0和标签1)的分类效果具有明显的提升作用.
4 总 结
本文提出双边分支网络参与度自动识别模型,将特征学习和分类器训练分开进行,降低传统模型中两部分的相互影响,使得对少数类别样本的分类能力得到提升.通过在DAiSEE数据集上的对比和消融实验,验证了本文提出方法的有效性,为后续参与度自动识别研究提供了新的思路.
然而,目前参与度识别的识别精度仍存在较大的提升空间.首先,本文仅对受教育者的面部表情和身体姿态的时序变化进行研究,后续工作可以结合音频、日志数据等多模态数据对参与度进行研究.其次,在特征提取部分,可以尝试与其它更有效的网络结构相结合,比如时间卷积网络(TCN),以增强对视频时序信息的理解.最后,近年来对比学习方法在众多计算机视觉任务上表现优异,后续将进一步探索对比学习在参与度识别任务中的应用.
