多约束边环境下计算卸载与资源分配联合优化
2024-02-27张俊杰黄思进陈哲毅于正欣
熊 兵,张俊杰,黄思进,陈哲毅,于正欣,陈 星
1(福州大学 计算机与大数据学院,福州 350116)
2(福建省网络计算与智能信息处理重点实验室,福州 350116)
3(兰卡斯特大学 计算与通信学院,英国 兰卡斯特 LA1 4YW)
0 引 言
随着通信技术与移动设备的快速发展与普及,各类新兴的应用不断涌现.这些应用通常会收集大量传感数据并伴随着计算密集型的任务以支持其高质量的智能服务,这对移动设备的硬件性能提出了巨大的挑战[1,2].但是,受限于设备尺寸与制造成本,移动设备通常只会配备一定容量的蓄电池与计算能力有限的处理器,这已无法支持新兴应用对高性能可持续处理的需求[3].云计算提供了充足的计算与存储资源,移动设备可以借助云服务来弥补其在硬件性能上不足[4].因此,一种可行的解决方案是将移动设备上计算密集型的任务卸载到资源充足的远程云上执行,完成任务后将结果反馈给移动设备.然而,移动设备与远程云之间的长距离会导致严重的数据传输延迟[5],不能很好地满足延迟敏感型应用的需求,也会显著影响用户的服务体验.
相比云计算,移动边缘计算(Mobile Edge Computing,MEC)将计算与存储资源部署到更加接近移动设备的网络边缘.因此,利用MEC进行计算卸载可以有效避免云计算中出现的网络拥塞的情况,降低网络服务响应时间,同时也能更好地满足用户对隐私保护的基本需求[6,7].相对于云服务器,MEC服务器配备的资源更少,但灵活性更强.因此,如何在资源受限的MEC系统中实现合理的资源分配是一个难点.此外,移动设备往往需要持续运行以支持各类智能应用,但受限于电池容量,任务的计算卸载过程在一定程度上也会受到影响.MEC与基于射频的无线电力传输(Wireless Power Transmission,WPT)的集成最近已成为一种可行且有前途的解决方案,可为无线移动设备的无线电收发器提供按需能量[8].但是,能量与延迟的多约束给边缘环境下的计算卸载与资源分配又带来了新的挑战.因此,需要设计一种有效的计算卸载与资源分配方法.
关于计算卸载与资源分配的经典解决方案通常是基于规则[9]、启发式[10]和控制理论[11].虽然这些方案在一定程度上可以解决计算卸载与资源分配问题,但它们通常利用了MEC系统的先验知识(如,状态转换、需求变化和能量消耗)来制定相应的计算卸载与资源分配方案.因此,这些方案在特定的应用场景中可能会运行良好,但无法完全适应具有多约束条件的动态系统,并且可能由于不合理的计算卸载与资源分配而导致延迟过大和资源浪费情况的出现.此外,这些经典方案需要通过极其多轮的迭代才能找到可行的解,导致了过高的计算复杂度和资源开销.因此,这些经典的解决方案已无法有效地解决动态MEC环境中的计算卸载与资源分配问题.强化学习(Reinforcement Learning,RL)被视为一种具备高适应性和低复杂度新兴可行的方法.但是,传统RL方法在面对复杂MEC环境时无法有效处理高维度状态空间问题.为了解决这个问题,提出了深度强化学习(Deep Reinforcement Learning,DRL),利用深度神经网络(Deep Neural Network,DNN)从高维度状态空间中提取低维表征.尽管目前存在一些基于DRL的计算卸载与资源分配方法,但大多使用的是基于值的DRL方法(如,深度Q网络(Deep Q Network,DQN)和双深度Q网络(Double Deep Q Network,DDQN)等),在处理庞大动作空间时训练效率可能会较低下.这是因为基于值的DRL通过计算每个动作的概率来学习确定性策略.但是,在MEC环境下,资源分配量是一个连续值.因此,动作空间会相当大以满足资源分配的需求,这导致了基于值的DRL可能无法快速收敛至最优策略.
为了解决上述问题,本文提出了一种基于深度强化学习的计算卸载与资源分配联合优化方法(Joint computation Offloading and resource Allocation with deep Reinforcement Learning,JOA-RL).本文的主要贡献概括如下:
1)针对多约束条件下动态的MEC系统设计了一种统一的计算卸载与资源分配模型,并将执行任务的时延与能耗作为优化目标.特别地,本文设计了一种任务优先级预处理机制,能够根据任务的数据量与移动设备的性能为任务分配优先级.相应地,针对DRL框架,定义了MEC环境下计算卸载与资源分配问题的状态空间、动作空间和与奖励函数,并上述优化问题形式化表示为马尔可夫决策过程(Markov Decision Process,MDP).
2)提出了一种基于深度强化学习的计算卸载与资源分配联合优化方法(JOR-RL),以有效地逼近动态MEC环境下计算卸载与资源分配的最优策略.在JOA-RL方法中,critic网络采用基于值函数的单步更新方式,用于评价当前卸载方案与资源调度策略;而actor网络采用基于策略梯度的更新方式,用于输出卸载方案与资源调度策略.同时,JOA-RL方法利用了DNN处理优化问题中存在的高维空间问题,克服了环境的不确定性以逼近目标值.
3)大量仿真实验验证了所提出JOA-RL方法的可行性与有效性.实验结果表明,与其他基准方法相比,JOA-RL方法能够快速地做出计算卸载与资源分配决策,在任务最大时延与设备电量约束下能够在时延与能耗之间取得更好的平衡,且展现出了更高的任务执行成功率.
本文其余部分组织如下.第1节回顾并分析了相关工作.第2节描述了所提出的计算卸载与资源分配模型并形式化定义了相应的优化问题.第3节详细介绍了所提出的JOA-RL方法.第4节评估了所提出的方法并与其他基准方法进行了对比实验.第5节对本文的工作进行了总结.
1 相关工作
近年来,计算卸载与资源分配问题受到了广泛的关注,许多学者都致力于解决这两个重要问题.在本节中,本文将从经典的方法和基于DRL的方法这两个角度回顾与计算卸载与资源分配相关的研究工作.
1.1 经典的计算卸载与资源分配方法
计算卸载与资源分配是MEC中常见的问题,已有许多工作来通过合理的计算卸载与资源分配方案以减少处理任务的延迟和能耗.许多关于计算卸载和资源分配的经典解决方案通常是基于规则、启发式和控制理论.这些传统的优化算法[12,13]制定合适的策略需要大量的迭代,不能满足任务的实时需求.此外,为了减少移动设备在电池容量上的局限性,无线充电技术可视为一种可行的解决方案.Wang等人[14]提出了一种基于拉格朗日对偶的算法以最小化系统任务执行延迟.Mao等人[15]的出了一种基于李雅普诺夫的算法以最小化能耗获得合适策略.Zhang等人[16]研究了NOMA辅助MEC系统中计算卸载和资源分配的联合优化问题,旨在最大限度地减少总能耗.Chen等人[17]提出了一种将惩罚函数与直流变成相结合的迭代搜索算法用于探索最优卸载和资源分配方案.Zhan等人[18]采用了可分离的半定松弛方案来进行类似的联合优化.但是,上述研究没有综合考虑MEC系统种动态的任务到达以及多约束型条件对任务执行的影响.
1.2 基于DRL的计算卸载与资源分配方法
计算卸载与资源分配问题通常是非凸的并且非常复杂难以求解.而基于规则、启发式或控制理论的方法在面对多约束条件下动态的MEC环境时仍然存在明显的局限性.而DRL能够在动态的环境中根据不同系统状态选择合适的动作,因此可作为一种高效可行的解决方案.Huang等人[19]将卸载问题表述为部分可观察的MDP并将博弈论应用于策略梯度方法.Dai等人[20]研究了无线供电MEC系统下的资源分配问题并提出了一种基于DRL的在线学习方法,在训练过程中考虑小部分候选动作来逼近最优策略.Alfakih等人[21]在DRL中结合了动作细化以优化计算卸载和资源分配.Li等人[22]设计一种基于DQN的卸载算法,通过优化每个用户的卸载策略来最小化延迟和能耗的线性组合.Pan等人[23]实现了一个基于DQN的自适应框架以解决MEC中的计算卸载和资源分配问题.Yan等人[24]研究了依赖任务的卸载决策问题,旨在优化应用程序的延迟.Guo等人[25]提出了一种低复杂度的评价网络,以在时变无线衰落信道和随机边缘计算能力下共同确定卸载和资源分配决策.上述工作大多是利用基于值的DRL方法来进行计算卸载与资源分配.当动作空间较大时,算法的训练结果很难接近最优策略.尤其是当资源分配的动作空间连续时,基于值的DRL算法由于离散化的动作采样太少而导致每个时间步学到的动作不是非常准确,导致最后的计算卸载和资源分配性能不理想.
2 系统模型与问题定义
如图1所示,所提出MEC系统由一个基站(Base Station,BS)、一个MEC服务器和N个可充电移动设备(Mobile Devices,MDs)构成,其中,N个MDs记为集合MD={MD1,MD2,…,MDN}.MDs通过5G或LTE方式接入BS,在BS上配备了MEC服务器.此外,所有MDs配备了能量收集(Energy Harvest,EH)组件并由无线电频率(Radio Frequency,RF)信号收集的能量为其提供电力.本节中主要涉及的符号及其定义如表1所示.

表1 符号及其定义Table 1 Symbols and definitions
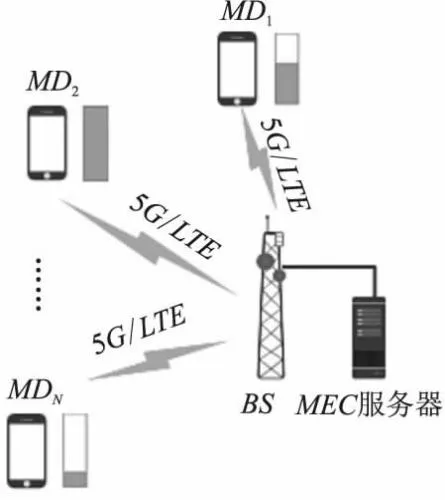
图1 单边缘多移动设备MEC系统Fig.1 Single-edge and multi-device MEC system

图2 时序任务工作流程Fig.2 Workflow of time-series task
2.1 通信模型
(1)

因此,MDi传输计算任务的功率为
(2)

2.2 计算模型
在所提出的MEC系统中,当MDs产生任务时,任务会先被添加到相应MD的任务缓冲队列上,先添加进队列的任务完成之后才能执行后续的任务.由于MDs和MEC服务器都可以提供计算服务,两种计算模式定义如下:
2.2.1 本地计算模式
假设不同MDs的计算能力(即CPU频率)可能是不同的,但在任务执行过程中是不会改变的.因此,本地计算模式的延迟和能耗分别定义为:
(3)
(4)
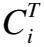
2.2.2 边缘计算模式
当MDs将任务卸载到MEC服务器上执行时,MEC服务器会选择分配部分当前可用的计算资源给MDs,任务执行完成后MEC服务器会将结果返回给MDs.通常,计算结果的数据量非常小,下载任务计算结果的延迟与能耗可忽略不计.因此,边缘计算模式的延迟和能耗分别定义为:
(5)
(6)

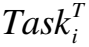
(7)
(8)
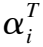
为了能够针对不同任务做出快速的决策找到合适的计算模式,本文设计了一种任务优先级预处理机制,能够根据任务的数据量与移动设备的性能为任务分配优先级.该机制衡量了不同任务上传至MEC服务器执行的合适程度,优先级越高的任务将倾向于卸载至MEC服务器上执行.具体地,上述优先级被定义为:
(9)
2.3 能量收集模型

1)当子时隙t内的任务因决策失败无法在MDi电量可支持范围内顺利完成或当前无任务执行,则在子时隙t内只有无线组件的充电电量变化.因此,在子时隙t+1开始时刻,MDi的电量为:
(10)
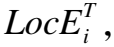
(11)

(12)
基于上述系统模型定义,所提出MEC系统的目标是最小化执行MDs上时序任务所产生的时延与能耗的加权开销之和,可形式化为优化问题P1如:
(13)
其中,w1和w2分别表示执行任务所产生的时延与能耗的权重.C1表示一个任务只能本地或者卸载到MEC服务器上执行.C2表示执行任务产生的能耗不能超过当前设备的可用电量.C3表示任务的执行时间不能超过任务最大容忍时延Td.C4表示为卸载任务所分配上传带宽比例的约束.C5表示为卸载任务所分配MEC服务器计算资源比例的约束.
3 JOA-RL方法
针对优化问题P1,所提出的JOA-RL方法可用于获得最佳的计算卸载与资源分配策略,以最小化MEC系统中时延与能耗的加权开销之和.如图3所示,MEC系统中的计算卸载与资源分配被视为环境,DRL代理通过与环境交互来选择相应的动作.此外,本文为所提出的JOA-RL方法定义了状态空间、动作空间和奖励函数,如下所示.

图3 所提出JOA-RL方法概览Fig.3 Overview of the proposed JOA-RL method

(14)

动作空间:DRL代理根据当前系统状态做出计算卸载与资源分配的动作.动作空间包含卸载决策αt、任务的上传带宽分配wt以及为任务所分配的MEC服务器计算资源pt.因此,在子时隙t时刻的动作可表示为:
at={αt,wt,pt}
(15)

奖励函数:所提出MEC系统的目标是在满足优化问题P1的约束条件下最小化系统时延与能耗的加权开销之和.因此,在子时隙t时刻,系统的即时奖励可表示为:
(16)
其中,w1和w2分别表示执行任务所产生的时延与能耗的权重.F表示归一化函数,用于将时延与能耗的数值归一化到相同数值区间.Pu表示任务失败的惩罚系数.
在多约束MEC环境下的计算卸载与资源分配优化过程中,DRL代理根据策略μ在当前系统状态(包含任务状态和资源使用)st下选择一个动作at(计算卸载与资源分配).环境根据动作at反馈奖励rt并转换到新的系统状态st+1,该过程可表述为MDP过程.
由于难以刻画精确的数学模型来解决具有高动态性的计算卸载与资源分配问题,在所提出的JOA-RL方法中利用了深度确定性策略梯度(Deep Deterministic Policy Gradient,DDPG)用于训练DNN以获取最优的计算卸载和资源分配策略.在JOA-RL方法中,critic网络负责评估每个动作相对应的Q值,actor网络负责在当前系统状态下生成相应的计算卸载与资源分配动作.通过使用critic网络可以有效降低策略梯度的误差,因为critic网络可以引导actor网络学习最优的策略.此外,通过集成DNN,JOR-RL方法可以很好处理高维度状态空间的问题.
JOA-RL方法的关键步骤如算法1所示.第1行:初始化actor网络和critic网络的参数θμ和θQ.第2行:将actor网络参数θμ赋值给目标actor网络参数θμ′并将critic网络参数θQ赋值给目标critic网络参数θQ′.特别地,JOA-RL方法中采用了独立目标网络,减少了数据之间的相关性,并增强了方法的稳定性与鲁棒性.第3行:初始化经验回放池M、训练回合数P以及时间序列长度Tmax.由于DRL代理与环境交互得到的训练样本不是独立同分布的,本文通过引入经验回放机制,降低了数据的相关性.在每个训练回合中,JOA-RL方法将每一步获取的系统环境状态st输入actor网络,在环境中执行actor网络输出动作at,执行相应的卸载计算与资源分配操作(第5~第11行).根据公式(16)计算相应的奖励如,环境反馈该步任务累积执行奖励rt与下一个状态st+1(第12行).
由于MEC环境中的系统状态与资源分配动作是一个连续值,JOA-RL方法考虑状态与动作均为连续值的MDP.JOA-RL方法训练critic网络θQ去拟合Q(st,at),当Q(st,at)确定时,对于固定的st一定存在一个at使得Q(st,at)最大.但是,st~at之间的映射关系十分复杂,给定st后的Q值是一个关于at的高维多层嵌套非线性函数.为解决这个问题,本文利用actor网络θμ去拟合该复杂映射.具体而言,Q(st,at)表示为:
Q(st,at)=Eenvironment[r(st,at)+γQ(st+1,μ(st+1))]
(17)
其中,actor网络θμ根据当前状态st输出Q值的最大动作at,该过程可以表示为:
at=μ(st|θμ)
(18)
在JOA-RL方法中,actor网络的性能目标定义为:
J(θμ)=Eθμ[r1+γr2+γ2r3+…]=Eθμ[Q(st,μ(st|θμ)|θQ)]
(19)
算法1.所提出的JOA-RL方法

输出:任务卸载动作任务的卸载决策αt、卸载任务的上传带宽分配wt以及卸载任务的MEC服务器计算资源分配pt
1. 初始化actor网络θμ和critic网络θQ
2. 初始化目标actor网络θμ′←θμ和目标critic网络θQ′←θQ
3. 初始化经验回放池M、训练回合P、每回合时间序列长度Tmax
4. FORepisode=1,2,…,PDO
5. 获取初始状态s1:s1=env.reset() ;
6. FORt=1,2,…,TmaxDO
7. 获取卸载动作:at=μ(st|θμ)+Nt;
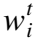
10. ELSE

12. 执行at后获得rt和下一个状态st+1:rt,st+1=env.step(at);
13. 将训练样本存入M:M.push(st,at,rt,st+1);
14. 从M中随机取出N个样本:N*(st,at,rt,s+1)=M.sample(N);
15. 计算累积期望折扣奖励:yt=rt+γQ′(st+1,μ′(st+1|θμ′)|θQ′
18. 更新目标actor网络和目标critic网络的参数θμ′←τθμ+(1-τ)θμ′,θQ′←τθQ+(1-τ)θQ′;
19. END FOR
20. END FOR
当存入M中的训练样本数达到N条时,随机选出N条记录用于训练网络参数(第14行).JOA-RL方法在优化损失函数时面临的一个重要的问题是对含有max表达式进行求导优化时性能很不稳定,更新参数不一定能使得max(st+1,at+1)向理想的方向变化.尤其当动作空间是连续时该情况更为明显,导致了训练Q(st,at)向目标网络移动过程时目标网络本身也在移动.为了解决这个问题,在JOA-RL方法中,本文分别定义了目标actor网络θμ′和目标critic网络θQ′,其中critic网络负责计算当前Q值Q(st,at),并定义了目标Q值yt(第15行).接着,本文定义了critic网络的损失函数(第16行),并使用梯度上升法去最小化critic网络损失函数.接着,使用梯度上升法逼近actor网络的策略最优解,并定义了actor网络损失函数的梯度(第17行).
在每个训练步,目标actor网络与目标critic网络按照更新步伐τ向actor网络与critic网络靠近(第18行).相比于单纯地复制网络参数,这种更新方式可以让JOA-RL方法更加稳定.
4 性能评估
在本节当中,本文通过大量仿真实验评估并分析了所提出JOA-RL方法的性能.
4.1 实验设置
在实验中,所有MDs在AP的覆盖范围内随机分布并共享带宽,且该AP配备了一台MEC服务器.其中,每台MD的计算能力的分布为[1,1.2]GHz/s,MEC服务器的计算能力为20GHz/s.在默认实验设置下,10台MDs共享带宽10MHz,每个时隙T的持续时间为1s,子时隙t的持续时间为0.25s,一个训练回合合计48个时隙T.仿真实验在配备Intel i5-7300HQ的笔记本电脑上开展,其CPU时钟频率为2.5GHz、内存为8GB.模型实现基于Python 3.6并利用开源机器学习框架Pytorch构建和训练神经网络.其中,actor网络的学习率为0.0006,critic网络的学习率为0.006,奖励折扣因子gamma设置为0.95.当JOA-RL方法完成训练后,可适用于多变MEC环境下计算卸载与资源分配的联合优化.具体的仿真参数设置如表2所示.

表2 仿真参数设置Table 2 Settings of simulation parameters
此外,本文将所提出的JOA-RL方法与以下5种基准方法进行了对比:
1)Local:所有任务皆在MDs上执行;
2)MEC:所有任务皆卸载到MEC服务器上执行;
3)Random:任务通过随机的方式在MDs或MEC服务器上执行;
4)Greedy:在满足任务最大容忍时延的前提下,任务优先选择在MDs上执行;
5)DQN:基于值的DRL方法,通过计算每个计算卸载与资源分配动作的概率来学习确定性策略.
4.2 结果分析
如图4(a)所示,本文首先对比了不同方法的收敛性,Local、MEC、Random和Greedy等方法为单步决策,不存在学习和优化的过程.在处理时序任务时,Local、MEC和Random等方法的性能表现不如其他3种方法.这是因为Local、MEC和Random等方法选择任务的方式比较盲目,没有充分考虑当前系统状态与任务特性,这导致了很大一部分任务因为超出时延和电量约束而失败.例如,相比于MEC服务器,MDs受限的计算能力可能会导致任务无法在时延约束条件内完成.而如果将任务频繁地卸载至MEC服务器上执行,MDs的电池电量可能无法支持卸载的过程而导致任务失败.相比于JOA-RL和DQN方法,Greedy方法只看重完成任务能获取的即时奖励,没有很好考虑长期奖励.在训练过程的前期,Greedy方法所表现出来的性能会比JOA-RL和DQN这两种基于DRL的方法来得好.但是,在训练过程的后期,JOA-RL和DQN这两种方法因为考虑了系统的长期奖励,其性能表现超过了Greedy方法.本文所提出的JOA-RL方法整合了基于值的和基于策略的DRL方法,可应对高维连续动作空间且收敛速度更快,使得JOA-RL方法的性能优于DQN方法.如图4(b)所示,本文对比了不同方法成功完成任务的平均消耗能量,MEC方法和Local方法分别展现出了最高和最低的平均任务消耗能量.Greedy方法在满足任务最大容忍时延的前提下优先在本地执行任务,因此其平均任务消耗能量仅高于Local方法.相比于DQN方法,JOA-RL方法收敛之后效果也优于DQN方法.如图4(c)所示,本文对比了不同方法的平均任务等待时间.JOA-RL方法在收敛后的平均任务等待时间上优于其他5种方法,Local方法由于本地计算能力受限,完成任务所需的时间较长,所以平均任务等待时间远高于其他5种方法.如图4(d)所示,本文对比了不同方法的任务成功率.

图4 不同方法的收敛性对比Fig.4 Convergence comparison of different methods
相比于其他5种方法,JOA-RL方法在最大容忍时延与电池电量约束条件下能够达到一种更好的均衡效果,所以其任务成功率高于其他方法.MEC方法的任务成功率是所有方法里面最低的,这是因为如果将所有任务都卸载到MEC服务器上执行,每个任务分配到的网络带宽会很低,这导致了过度的任务上传时间,且很多任务也会因此无法满足时延约束而失败.另外,MEC方法将任务频繁地卸载至MEC服务器上执行,导致MDs的电池电量可能无法完全支持卸载而任务失败.
接着,本文评估了网络带宽对不同方法的影响.如图5所示,Local方法由于不存在计算卸载的过程,所以网络带宽的变化对其没有影响.对MEC方法而言,当网络带宽很低时,每个上传的任务所分配到的带宽就会很低,这导致了大量的任务上传时间,也使得很多任务由于无法满足最大时延迟约束而失败,所以MEC方法反映出来的性能表现较差.随着网络带宽的提升,除Local方法以外的5种方法的性能表现上也呈上升趋势.其中,MEC方法的性能提升最为明显,因为该方法的性能表现非常依赖于网络带宽.本文所提出的JOA-RL方法相比DQN方法能更好地处理连续的资源分配问题,实现更低的时延与能耗.这表明JOA-RL方法在计算卸载与资源分配联合优化问题上更具优势.当网络带宽提升到一定程度时,除Local方法以外的5种方法的性能都基本趋于稳定.这是因为随着网络带宽的提升,在计算卸载过程中因超出时延约束而失败的任务减少了,但由于依然存在MDs电池电量的约束,使得这些方法的性能无法得到进一步的提升.

图5 网络带宽对不同方法的影响Fig.5 Effect of network bandwidth on different methods
然后,本文评估了MEC服务器的计算能力对不同方法的影响.如图6所示,Local方法由于不存在计算卸载的过程,所以MEC服务器计算能力的变化对其没有影响.随着MEC服务器计算能力的增加,除Local方法以外的5种方法的性能表现上也呈上升趋势.本文所提出的JOA-RL方法相比于DQN方法能实现更低的时延与能耗,这是因JOA-RL方法能更好地处理连续的资源分配问题,表明JOA-RL方法在计算卸载与资源分配联合优化问题上更具优势.当MEC服务器的计算能力增加到一定程度时,除Local方法以外的5种方法的性能也都基本趋于稳定.这是因为随着MEC服务器计算能力的增加,在计算卸载过程中因超出时延约束而失败的任务减少了,但存在MDs电池电量的约束,使得这些方法的性能无法得到进一步的提升.
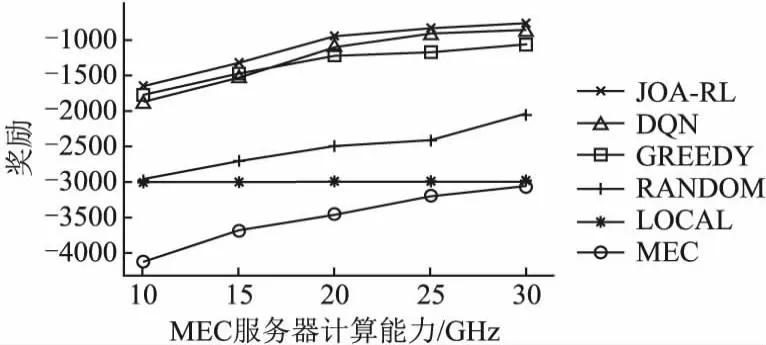
图6 MEC服务器的计算能力对不同方法的影响Fig.6 Effect of computational capability of MEC server on different methods
最后,本文评估了MD蓄电池最大容量对不同方法的影响,如图7所示.对Local方法而言,任务本地计算所消耗的电量低于蓄电池的最大容量,因此MD蓄电池最大容量的增加对Local方法没有影响.对于其他5种方法而言,其任务上传消耗的电量较大,因此当MD蓄电池最大容量较小时,任务往往会因为蓄电池电量不足以支持计算卸载而失败.随着MD蓄电池最大容量的增加,存储的电量能够支持更多的计算卸载,因此这5种方法的性能表现呈上升趋势.当MD蓄电池最大容量增加到一定程度时,因MD蓄电池最大容量不足而导致的计算卸载失败的情况基本消失,这些方法的性能也趋于稳定.本文所提出的JOA-RL方法相比DQN方法能更好地处理连续的资源分配问题,实现更低的时延与能耗.这表明 JOA-RL方法在计算卸载与资源分配联合优化问题上更具优势.

图7 MD蓄电池最大容量对不同方法的影响Fig.7 Effect of maximum battery capacity of MDs on different methods
5 结 论
在本文中,本文首先将多约束动态MEC系统中的计算卸载与资源分配形式化为一个无模型DRL问题.接着,本文提出了一种基于深度强化学习的计算卸载与资源分配联合优化方法(JOA-RL)以提高任务执行的成功率并降低任务执行的时延与能耗.实验结果表明,所提出的JOA-RL方法在提升任务执行成功率以及降低任务执行时延与能耗方面优于其他基准方法.具体而言,随着网络带宽和MEC服务器计算资源的提升,JOA-RL方法的效果也优于其他方法.同时,与先进的DQN方法相比,JOA-RL方法也展现出了更好的收敛效果.
