融合知识图谱的学习者个性化学习资源推荐
2024-02-27李春英武毓琦汤志康林伟杰
李春英,武毓琦,汤志康,林伟杰,汤 庸
1(广东技术师范大学 计算机科学学院,广州 510665)
2(广东技术师范大学 广东省知识产权大数据重点实验室,广州 510665)
3(华南师范大学 计算机学院,广州 510631)
0 引 言
后疫情时代在线学习已成为一种常态,在线教育给学习者带来方便快捷的同时,也因学习资源过载导致学习者产生知识迷航或课程选择困难等问题[1].为了解决这些问题,学习资源个性化推荐应运而生.个性化推荐建立在学习者行为数据挖掘基础上,为其提供完全个性化的决策支持和信息服务,良好的个性化推荐服务能够提高在线教育平台用户的粘性和学习兴趣、节省在线课程平台学习者查找资源花费的时间.传统的个性化推荐方法主要包括基于内容的推荐方法、协同过滤推荐方法以及混合推荐方法[2].基于内容的推荐是通过比较学习资源的属性特征和学习者的偏好,找到与学习者偏好最符合的学习资源,如文献[3]在内容推荐中引入深度神经网络并提供学生问答推荐器,利用学习者的学习行为数据来提高推荐的精度.文献[4]通过特征选择模型得到学习资源表征,再依据学习者的理解水平来分类,然后推荐适合学习者的学习资源.文献[5]提出一种基于内容的个性化知识服务推荐优化算法,该方法建立特征向量模型突出关键信息,建立模型捕捉用户的最新偏好.最后将特征向量模型与多个学习者比较以生成推荐列表,解决了因信息扩展使学习者难以检索相关信息的问题.传统的协同过滤方法主要是利用学习者对学习资源的评分矩阵推荐给目标学习者资源.例如:Yang En-yue等[6]提出了一种新颖的通用联邦矩阵分解(FCMF)算法,通过使用不同类型的用户反馈,以隐私感知的方式实现异构协同过滤(HCF).该方法能够在保护用户隐私的前提下,利用异构反馈数据准确估计用户偏好.Lu Qi-bei等[7]提出了六种有关用户的隐私关注因子,如隐私倾向、内部控制点、开放性、外向性、宜人性和社会群体影响力,并根据影响因素提出了隐私关注强度的度量方法,然后将该方法融入协同过滤方法中来获取用户的相似偏好,较好地解决了个性化推荐系统中很少考虑用户隐私的缺陷.文献[8]通过学习者行为生成兴趣模型向量,然后根据资源标签为学习者进行评分,最后根据学习者兴趣模型和资源特性,将满足需求的资源推荐给学习者.混合推荐方法是将多种推荐策略相结合的方法,如Zhang W等[9]将协同过滤和视频基因组合在一起形成混合推荐,该方法将通过k均值聚类得到推荐列表和视频基因遗传得到的推荐列表进行加权平衡来进行推荐.王永贵[10]提出一种新的混合推荐算法,实现了在低维空间分解内容和协同矩阵的同时还保留数据的局部结构.文献[11]提出了一种基于内容推荐和协同过滤推荐的混合方法(OPCR)用于课程推荐,该方法利用动态本体映射将学习者和学习资源等联系起来,使学生能够获得全面的课程知识.上述方法在提供推荐服务的同时难以克服以下2个问题:
1)数据稀疏问题.传统的推荐方法主要依靠学习者对学习资源的评分矩阵,真实数据中学习者很少对资源进行评分,这使得评分矩阵过于稀疏,难以发现与学习者兴趣相同的人,必然导致推荐精度不高.
改革开放以后,随着工业化城镇化进程的推进、大规模频繁的人口流动、老龄化的加剧、平均寿命的延长、由生育政策导致的家庭结构的巨大变迁,以及市场化改革之下单位制度的消解,使得老年人的晚年生活逐渐溢出私人领域和单位福利的范畴,转向一种需要由政府主导、社会部门共同支持的公共服务制度安排。政策作为国家行为的载体,是分析判断国家大政方针走向的重要依据。养老服务政策是指政府为促进养老服务、保证老年人生活而出台的政策,具有导向、调控和分配养老服务资源的功能[2]。
2)冷启动问题.现有推荐系统会随着新的学习者和学习者对资源的需求不断更新内容,但在更新之前对于新加入的学习者或者学习资源,由于没有与他们相关的历史内容记录,使得无法准确地进行推荐.
近年来,利用知识图谱(KG)作为辅助信息的推荐方法为克服上述困难提供了可能.知识图谱是一种用来表达实体间语义关系的知识库工具[12],在推荐系统中加入知识图谱可以丰富学习资源之间、学习者之间以及学习者与资源之间的关联信息,并可借助其语义推理功能提取数据之间的逻辑关系以提高推荐效能.推荐系统中的学习者和学习资源的交互过程可以在知识图谱中从一个实体出发,沿着不同的关系传递到不同类型的实体,从而扩充学习者的潜在兴趣偏好,提高推荐的合理性.Zhang等[13]提出了CKE方法,将协同过滤与嵌入相结合,但其推荐的合理性和逻辑性仍有缺陷;Wang Hong-wei等[14]基于已有的知识图谱提出了RippleNet模型,利用知识图谱实体的语义关系模拟水波波纹传播方式,在节点之间沿着关系进行偏好传播以推理出学习者的潜在偏好,但RippleNet模型未考虑知识图谱中的实体权重,无法突出推荐的重点从而影响推荐的结果[15].此外,就学习者个性化资源推荐而言,因其对不同的课程、教师、学校等信息的关注程度有所差异,所以评价得分函数的计算需要具有不同的权重.曹瑞猛等[16]在协同过滤的基础上加入权重知识图谱并利用循环神经网络来挖掘用户深层次的偏好,提出了基于循环神经网络与权重知识图谱的推荐方法(RNWKG)并将其应用到电影推荐系统中取得了不错的结果.
因此,本文以学习者在线课程平台课程数据为研究对象,提出了一种基于知识图谱的学习者个性化学习资源推荐模型(Learner Personalized Learning Resource Recommendation Model Based on Knowledge Graph,LPRM),LPRM通过挖掘课程属性之间的关系构建课程知识图谱,利用课程知识图谱作为辅助信息缓解传统推荐算法中的数据稀松问题,为充分考虑知识图谱中实体权重对学习资源推荐的影响,设计了实体影响力计算模型并基于偏好传播思想利用知识图谱的来挖掘学习者的潜在偏好,实现基于知识图谱的学习者个性化学习资源推荐的同时也为冷启动用户的推荐提供了依据.

1 相关工作
知识图谱是一个由实体及其链接关系组成的异构网络图,借助知识图谱的推理能力和可解释性可以提高推荐效果.在许多领域都有加入辅助信息来缓解数据稀疏的方法例如:在音乐推荐方法中引入音乐的属性特征、在商品推荐中引入上下文信息、在电影推荐中引入社交网络等[17].因此本文将知识图谱作为辅助信息应用于推荐方法中,有效缓解因学习者数据稀疏等导致的无法为冷启动学习者进行个性化推荐的问题.
鸨鸟肃肃地扇着翅膀,停落在桑树丛。 王家的事没了没完,稻梁全不能种植。 父母拿什么来吃?遥远的苍天呀!何时才能安定?[3]113-114
《韩集考异》的具体操觚者是朱熹弟子方士繇,但此书的体例是由朱熹亲自确定的,成稿以后,朱熹细阅一过,提出修改意见,令方士繇改订。[注] 参看刘真伦:《韩愈集宋元传本研究》,第142页。因此,此书完全可以代表朱熹的学术观点。朱熹《书〈韩文考异〉前》云:
基于知识图谱的推荐方法主要包括:基于嵌入的方法,基于连接的方法以及基于传播的方法[18].基于嵌入的方法是通过图嵌入的方法对实体和关系进行表征用以扩充原有学习者和学习资源的表示.通常包括两个基本部分,一个是图嵌入部分,用于学习知识图谱中实体和关系的表示;另一个是推荐部分,用于估计学习者对具有学习特征的项目学习资源的偏好.根据这两个模块在框架中的关联方式,可以将基于嵌入的方法分为两步学习方法、联合学习方法和多任务学习方法.两步学习方法是对图嵌入模块和推荐模块一一进行训练.第1步,使用 KGE 算法[19]学习实体和关系的表示;第2步,将预训练得到的图嵌入与其他学习者和学习资源一起被输入推荐模块以进行预测如:DKN[20]、KSR[21]、KTGAN[22]算法等.该方法容易实现而且可以在没有交互数据的情况下进行知识图谱的嵌入,因此,大规模交互数据不会增加计算复杂度.但是,KGE 模块和推荐模块是低耦合的,故学习到的嵌入可能不适合推荐任务.基于联合学习方法是将图嵌入模块和推荐模块的目标函数相结合,从而实现端到端的训练,例如CKE、CFKG[23]、SHINE[24]算法等.这种联合学习的方法可以进行端到端的训练,并且可以使用 KG 结构对推荐系统进行正则化.然而,需要对不同目标函数的组合需要进行微调;第3种思路是引入多任务学习框架,通过将图嵌入模块设计成与推荐模块相关而又分离的任务,从而利用图嵌入模块监督推荐模块的训练过程,比如MKR[25]、KTUP[26]、RCF[27]算法等.该方法虽然有助于防止推荐系统过拟合,提高模型的泛化能力.但是,将不同的任务集成到一个框架下是比较不易的.
基于连接的方法主要利用图谱中实体间的连接方式做推荐,该方法大多是将包含学习资源属性的知识图谱与学习者-学习资源的交互矩阵相结合,构建学习者-属性-学习资源图,挖掘学习者和学习资源间的多种连接关系.该方法有两种基本思路,第一种是利用实体间的连接相似性做推荐,通过定义图谱中的基本结构特征,通过计算不同路径下实体间的相关性实现推荐,如Hete-CF[28]、FMG[29]算法,这种方法易于实现,大多数工作都是基于模型复杂度较低的MF技术.然而,元路径或元图的选择需要领域知识,并且这些元结构对于不同的数据集可能会有很大差异.此外,在某些特定场景下可能不适合应用基于元结构的方法.例如,在新闻推荐任务中,属于一个新闻的实体可能属于不同的域,这使得元路径设计变得困难.第二种思路是挖掘用户与物品之间存在的语义路径,学习实体间连接路径的显式表征,将其引入到推荐框架中,以直接建模用户与物品间的连接关系如MCRec[30]、RKGE[31]算法等.基于路径嵌入的方法将学习者-学习资源对或学习资源-学习资源对的连接模式编码为潜在向量,这使得考虑目标学习者、候选资源和连接模式的相互影响成为可能.此外,大多数模型能够通过找到合适的路径来自动挖掘连接模式,而无需预定义的元结构的帮助.因此,它很可能捕捉到富有表现力的连接模式.但是,如果图中的关系很复杂,则图中可能的路径数量可能会增长到很大.
尽管上述两类方法都提升了推荐的精准性,但都没有利用图中所包含的全部信息,比如基于嵌入的方法侧重于学习知识图谱中的语义表示,而基于连接的方法关注知识图谱中实体的连接信息.基于传播的方法结合了上述两大思路,其基本思想是借助知识图谱中实体间的连接路径,将实体语义表征在图中传播,直接建模实体间的高阶关系,从而更合理地挖掘了知识图谱所包含的信息.RippleNet模型是一种基于知识图谱的端到端推荐模型,它将用户-项目作为输入并输出用户参与(例如点击、浏览)项目的概率.RippleNet很好地结合了嵌入和连接的方法,它通过偏好传播自然地将KGE方法纳入推荐;它可以自动发现从用户历史中的项目到候选项目的可能路径,而不需要任何手工设计.但它未考虑知识图谱中的实体权重,从而未将推荐重点放在重要程度较高的实体上,限制了推荐的性能.
合理利用外资。针对于公路养护资金缺口的问题,可通过国际组织及外商投资的方式,加大对公路养护及交通事业的发展。应用企业发行债券,实现对企业短期内资金紧张和不足的解决,积极优化企业的债务结构。了解清楚企业的内部资产和预期收益,盘活存量资金,应用业存量资产获得收益加强公路养护的投入,以及实现合理化投资。针对于养护资金不足的问题,可选择银行贷款解决。除此之外,可引入商业保险资金,应用交通基础设施回报稳定特点,解决养护资金不足。
2 LPRM推荐方法
2.1 课程知识图谱构建
知识图谱的构建方法包括自底向上、自顶向下以及两种方法结合的方式,本文采用自底向上的方法来构建知识图谱,其构建过程如图1所示.首先从在线课程平台获取课程相关结构化数据,得到初始的知识表示;然后经过知识获取得到三元组数据:对所有课程数据进行实体识别、实体分类以及关系抽取得到结构化数据,其中实体识别主要是为了得到课程名称、授课教师、开课的学校、课程的分类等等;实体分类将识别后的实体按类别分类;关系抽取是抽取多个实体之间的联系,然后根据知识抽取以及实体链接技术构建知识图谱的三元组形式,最后利用Neo4j来存储课程知识图谱.

图1 课程知识图谱构建过程图Fig.1 Construction of curriculum knowledge graph
课程知识图谱的结构如图2所示.本文的知识图谱用三元组(h,r,t)来表述,课程相关知识图谱可以定为G:G={(h,r,t)|h,t∈E,r∈R},其中E为学者网数据集中选出的部分与课程相关的实体集合,其中包括课程、教师、学校以及分类等实体.R是通过学者网数据集构造的11种关系集合,其中包括课程与教师、课程与学校、课程与学科类别、课程与点击率、教师与学校、教师与教师等关系.如图2所示当一个学习者的历史选课为:软件工程、离散数学、程序设计基础,在知识图谱中就可以将这些课程关联到其他实体上,再从这些实体又连接到其它课程实体上.

图2 课程知识图谱结构示意图Fig.2 Structure diagram of curriculum knowledge graph
课程知识图谱实质是建立一个从学习者曾经选择的课程到其潜在兴趣课程的连接,这些连接不是由其它学习者的选课历史记录得来的,而是通过不同的实体来进行连接的.相较于传统的协同过滤算法,课程知识图谱提供了课程之外的辅助信息以及比传统方法中的物品之间的相似度计算更加准确的方法,从而提高了课程推荐的精确度.
2.2 节点影响力模型
本文将知识图谱三元组中的实体来看作复杂网络中的节点,实体之间的关系看作复杂网络中的边,从而将知识图谱转化为复杂网络进而来计算其中各个节点的影响力[15].本文分别使用度中心性[32]、H指数中心性[32]以及DH指数中心性来计算知识图谱网络中节点的影响力,为知识图谱中不同的实体赋予不同的权重并从实验结果中分析哪种方法更加有效.
度中心性是根据节点的连边来计算的,一个节点的连边越多那么它的节点影响力就越大,这是网络中刻画节点重要程度最简单的指标.度中心性虽然计算简单、直观但它仅仅考虑了节点的最局部的信息,没有对节点周围的环境如更高阶邻居等进行进一步的研究因而在某些情况下不够精确.
1.将G抽象为无向图根据公式(1)、(2)来计算各个节点的权重Wi
DH指数中心性是由度中心性和H指数中心性两部分组成,在一定程度上继承了H指数中心性与度中心性的优点,而且还弥补了它们的不足.假设存在复杂网络,其中N为所有节点的集合,某个节点i∈N,则该节点的DH指数中心性计算如公式(1)所示:
DH(i)=a*d(i)+(1-a)*H(i)
(1)
在公式(1)中d(i)表示节点i的度中心性,H(i)表示节点i的H指数中心性,a表示平衡参数.为了消除奇异样本数据导致的不良影响,要对DH指数进行归一化,归一化方法如公式(2)所示:
(2)
2.3 LPRM模型
LPRM模型采用知识图谱向量化的传播思想,沿着知识图谱迭代扩展学习者的潜在兴趣,刺激学习者对一组知识实体偏好的传播.因此,由学习者之前选择过的学习资源激活的多个“涟漪”叠加起来,形成学习者相对于候选资源的偏好分布,该分布可用于预测最终的点击概率.因此,LPRM模型的关键是学习者的偏好扩散,模型将每个学习者的历史选课集合作为知识图谱中的一个种子集合,学习者的偏好从种子开始沿着知识图谱的拓扑关系进行传播,扩展学习者的兴趣并挖掘学习者对某个候选节点的潜在兴趣,在扩散的过程中获得学习者对应的偏好集合.比如在图2中,学习者之前选修过《离散数学》、《软件工程》和《程序设计基础》,而《离散数学》是由教师A所教的,教师A还教过《数据结构》;此外《软件工程》是属于工学类的课程,而该类型的课程还有《操作系统》.根据偏好传播的思想,该学习者可能因喜欢老师A的风格而喜欢听老师A的《数据结构》或者因为《软件工程》和《操作系统》属于同一类型而选择该课程.
接下来详细阐述学习者的偏好集合(Ripple set)构建过程:
首先,假设L={l1,l2,l3,…}和C={c1,c2,c3,…}分别表示学习者集合和课程集合,lc表示学习者的历史选课记录.给定知识图谱G,在Ripple中通过循环递归的方法来得到学习者l的相关的集合如公式(3)所示.
(3)
输入:G:课程知识图谱
相关集合可以理解为学习者的偏好沿着知识图谱的延伸,得到相关集合后就可得到学习者的Ripple set集合,LPRM定义了学习者的n-HopRipple set(Hop表示传播次数)如公式(4)所示.
(4)
本文选择学者网(1)https://www.scholat.com/、Book-Crossing(2)http://www2.informatik.uni-freiburg.de/~cziegler/BX/和Academic Social Network(3)https://www.aminer.cn/aminernetwork3个数据集为研究对象.其中学者网数据集包含着学习者、课程以及课程的相关内容.Book-Crossing包括书籍的作者、出版社等与书籍相关的信息.Academic Social Network包含学者、学者相关的论文、学者所属机构以及学者感兴趣的领域等.具体的统计信息和参数设置如表1所示.

图3 LPRM模型Fig.3 Model of LPRM
在每一次的扩散中,都会将Ripples set中头实体的权值Wi与Ripple set的嵌入矩阵ei进行相乘得到hi,如公式(5)所示.
hi=ei*Wi
(5)

(6)
本文主要与RippleNet模型、KGCN模型[33]、KGNNLS模型[34]以及MKR模型进行对比.
(7)
(8)
最后,结合学习者和用户的embedding来计算学习者对课程的点击概率如公式(9)所示.
3.差异性特征。人与人之间都是相互独立存在的,尽管每个人都具有相对独立的八种智能,但是由于人们生存的环境、空间以及受教育程度不相同,进而导致每个人的智能因素存在优势和劣势的差别,然而这种情况将会导致学生在学习和理解知识、处理问题和解决问题方面产生差异性。
(9)
其中:
(10)
综上可以看出LPRM模型在知识图谱的基础上利用偏好传播的思想,以学习者的历史课程为种子集沿着关系向外进行偏好传播,较好的解决了因学习者未对学习资源进行反馈而导致的数据稀疏问题,通过构建课程知识图谱衍生出来的额外连接信息赋予了模型推理和可解释能力再结合偏好传播思想可以挖掘学习者的潜在偏好.例如在图2中将《数据结构》推荐给学习者并不是因为学习者与这门课程之间的联系,而是通过偏好传播思想发现了学习者对该课程具有潜在的偏好.对于学习者和学习资源之间缺少交互而导致的冷启动问题,也可以利用LPRM模型通过知识图谱来扩展它们的语义从而挖掘出它们之间的潜在联系.其次通过计算知识图谱中的实体权重,得到具有不同权重的实体,可以突出推荐的重点从而提升推荐的效果.LPRM的伪代码如下:
算法1.LPRM推荐算法
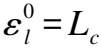
e:嵌入矩阵
c:待推荐课程资源
lc:学习者的历史选课集合
Hop:传播扩散的次数
综上,确定虾油、味精、食盐、白砂糖、干贝素、焦糖色、酵母抽提物和变性淀粉为本产品开发的主要因素,将这8个因素分别设定几个水平,建立L18(2×37)正交表进行实验,以确定最优配方[5],因素水平见表1。
信息计量学中用H指数衡量学者的贡献[32]:如果一个人的所有学术文章中最多有n篇论文分别被引用了至少n次,他的H指数就是n.H指数中心性是利用H指数的概念,通过考虑邻居节点的度来确定节点的中心性.
2.forn∈[1,Hop]do
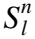
5. 根据公式(5)来得到带权的头实体hi
6. 根据公式(6)来计算相关概率pi
8.endfor
9. 根据公式(8)来得到学习者的embeddingL
10.endfor
对贵铅样品进行测定,并对大量试验数据进行总结。结果发现贵铅样品中主要共存杂质元素的质量分数范围分别如下所示:铅,15.2%~75.5%;锑,1.6%~38.9%;铋,0.4%~19.5%;铁,0.2%~12.4%;铜,1.8%~6.3%;砷,1.9%~4.2%;碲,0.3%~1.8%。
3 实验与分析
3.1 实验数据集
LPRM的整体结构如图3所示,以学习者的历史选课为种子节点向外扩散得到Ripple set的三元组后,通过节点影响力模型计算三元组中头实体headi的权值Wi.在进行embedding时将RippleNet的嵌入矩阵与headi对应的权值矩阵进行相乘,得到带权重的Ripple set embedding.然后按照RippleNet模型进行学习者和课程的embedding,最终通过进行Hop次偏好传播来得到学习者对课程的评分(学习者对学习资源的点击概率).

表1 3种数据集的基本统计和参数设置Table 1 Basic statistics and parameter setting for three datasets
3.2 实验过程与结果分析
3.2.1 实验设置
本文使用ACC(Accuracy)和AUC(Area Under Curve)作为实验的评价指标,用以衡量各个算法的性能,实现本文算法数值表征.
(3)若实际安全支出较计划安全成本节支,且安全保障实际水平大于等于计划水平,说明当前安全保障水平是因为项目管理水平的提高而提高,当月项目安全管理措施落实到位,可以考虑使用节支部分奖励相关人员。
AUC被定义为ROC曲线下的面积,AUC的值越大说明模型的效果越好.
ACC表示预测正确的样本占所有样本的比例,ACC值越大说明模型更加高效,如公式(11)所示:
(11)
其中,TP表示预测类别是P(正例),真实类别也是P;FP表示预测类别是P,真实类别是N(反例);TN表示预测类别是N,真实类别也是N;FN表示预测类别是N,真实类别是P.
(7)畸形攀比。寄宿生盲目攀比,特别是部分孩子家境条件较差,爱与同学比较,又总觉得自己底气不足,于是怨天尤人,不思进取。
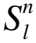
表1给出了LPRM模型的参数设置,其中d表示嵌入维度Dim,H表示扩散的次数Hop,n表示Ripple set的长度.本文将分别对每个数据集进行处理,将整个数据集按6∶2∶2分为训练集、评估集和测试集3个部分.每个数据集进行5次实验并取5次实验的平均值作为最终结果.本文实验用点击率(CTR)对测试集中的每个交互片段进行训练,输出预测的点击概率,并使用AUC和ACC来进行评价.
在此情境中,教师不断设置问题,引导学生分析哪些蛋
