面向元余弦损失的少样本图像分类
2024-02-24陶鹏冯林杜彦东龚勋王俊
陶鹏,冯林*,杜彦东,龚勋,王俊
0 引言
深度学习在计算机视觉(He 等,2016)、语音识别(Vaswani 等,2017)和自然语言处理(Rabiner,1989)等领域取得巨大成功。图像分类作为计算机视觉领域的主要任务取得了突破性进展。然而,神经网络模型为获得最优的效果,通常需要在大规模标签数据集中进行训练。现实生活的许多场景,如医学、军事和信息安全等领域,受限于专业知识要求高、保密性强等因素,要获得大规模有标注数据代价昂贵。同时,少量的标注样本训练包含大量参数的深度学习模型,产生严重的过拟合,限制了深度学习的广泛应用。如何使用少量标注样本进行学习(也称“少样本学习”)成为目前机器学习研究者广泛关注的热点问题。少样本学习(few-shot learning,FSL)希望机器具备类似人类解决问题的能力,即通过一两次示范,可以学会一类问题的解决,不需要太多的有标注数据即可“学会”(葛轶洲 等,2022)。
少样本学习方法中,基于度量学习的方法因其简单性,以及在解决少样本学习问题上表现出的卓越性能,而得到广泛应用。基于度量的少样本学习方法通过学习嵌入函数,将样本映射到嵌入空间中,期望在该空间中同一类的样本聚集在一起,不同类的样本相互远离;然后使用简单的度量函数,如欧氏距离和余弦距离等进行计算,便可快速识别出新类样本。度量学习方法利用度量函数在嵌入空间中计算查询集图像与支持集图像间距离进行分类,这一过程绕过了网络学习分类器时在少样本设置下的优化难题,因此,基于度量学习方法的关键往往依赖于学习到一个更丰富、更具判别性以及泛化能力更好的嵌入空间。
更丰富、更具判别性的嵌入空间,要求特征提取器提取到每个样本中最能够充分代表该类的特征。已有的少样本学习研究表明(Luo 等,2022),每幅样本图像包含的信息可分为前景图像和背景图像。前景图像有利于少样本的分类,而背景图像则无助于少样本的分类。因此,希望特征提取器更多地关注样本的前景信息,来尽可能减少背景信息的影响。但是,在少样本设置的限制下,模型很难区分样本的前景和背景图像。如果将每幅图像作为图像的全局特征,那么根据每幅图像随机裁剪的一部分就作为局部特征。局部特征能够提供跨类别的区别性和可迁移性的信息,而这些信息对于少样本学习中的图像分类具有重要意义(Zhang 等,2020)。
一个泛化能力好的嵌入空间要求模型在面对测试的新类任务时,不仅能够将任务中的同类样本聚集在一起,同时不同类的类间距清晰可分,特别是在面对相似类别的样本时。为了达到此目的,越来越多的研究工作关注到语义信息(徐鹏帮 等,2021)。Xing 等人(2019)利用样本的真实标签语义信息,通过结合跨模态的文本特征来增强视觉特征,使得少样本分类的性能得到较大提升。Li 等人(2020)利用不同类别之间的语义相似性来生成类与类之间的自适应间隔,以提升度量学习的泛化能力。
为进一步提升度量学习方法的分类识别能力,本文分别从提取的特征和特征在嵌入空间中的特征分布出发进行研究。为提取每个样本中能够充分反映该类样本的特征,利用全局与局部数据增强相结合,利用图像的局部特征学得每类样本具有区别性以及可转移性的特征,引导模型更多地关注到图像全局特征的前景信息,降低背景信息所带来的影响。为使嵌入空间中的不同类簇之间更具可分性,扩展模型的泛化能力,更好地适应新任务,提出一种不引入额外参数的元余弦损失。在元训练阶段,基于余弦分类器计算样本与类原型之间的相似性,根据查询集的真实标签信息调整类原型,期望模型学会将不同类聚集的簇尽可能拉远,这样面对新任务时泛化性能更强。与已有研究成果使用真实标签的方式不同,元余弦损失(meta-cosine loss,MCL)在元训练过程使用了真实标签,但并不使用其包含的语义信息,单纯使用真实标签查询样本的真实类原型。该方式不引入额外的参数,若要使用真实标签的语义信息就需要建立额外的网络来对文本信息进行提取,将会增加模型复杂度。通过利用样本与真实类原型的余弦相似性和样本与其他类原型的余弦距离之间的差异,调整其余类原型的向量表示,即扩大了样本与其余类原型间的夹角,使类间距更清晰、类更可分。
本文主要贡献如下:1)提出一种不引入额外参数的元余弦损失用于元学习的元训练。基于余弦分类器,在元训练过程中利用查询集的真实标签调整与样本不同类的类原型,扩大类间距。2)提出将图像的全局和局部特征结合起来的特征提取方法。通过全局与局部数据增强,利用局部数据增强提供的区别性以及可转移性的特征引导模型更多关注到图像全局特征中的前景信息,减少背景信息的影响。3)在目前常见的少样本学习标准数据集上进行实验,元余弦损失的少样本图像分类方法(a metacosine loss for few-shot image classification,AMCLFSIC)的实验效果达到了目前少样本图像分类的先进水平,证明了其有效性。
1 相关工作
1.1 少样本学习
目前,少样本学习方法大致可分为3 类。下面将以基于度量学习的方法、基于梯度优化的方法和基于迁移学习的方法分析最新的研究进展。
1.1.1 基于度量学习的少样本学习方法
基于度量学习的方法,通常包含以深度神经网络为架构的特征提取器和以度量函数度量空间距离的分类器。通过神经网络将样本映射到特征空间中,利用度量函数计算类原型和查询集之间的相似性进行分类。Snell 等人(2017)提出了原型网络(proto-typical network),通过支持集的特征均值为每个类构建一个类原型,利用欧氏距离计算查询集到类原型的距离进行分类。基于原型网络,Ye 等人(2020)为了得到更利于当前任务分类的特征,通过引入Transformer得到自适应的特征嵌入,提出FEAT(few-shot embedding adaptation with transformer)方法。Li等人(2020)引入标签语义信息提出一种自适应的类边缘损失,改进分类效果。Gidaris等人(2019)在基于余弦分类器的度量方法中引入自监督方法,提升了余弦分类器的识别率。Sung等人(2018)提出关系网络(relation network),利用卷积神经网络(convo⁃lutional neural network,CNN)构造一个自适应的关系度量模块,将特征向量拼接输入可计算关系得分进行分类。从关系网络出发,余游等人(2019)结合半监督思想构造伪标签混合训练关系网络。Liu 等人(2019)结合转导学习提出标签传播网络(transduc⁃tive propagation network,TPN),从非欧氏距离的角度出发,通过度量特征与特征间的关系构建最邻近图,将标签从支持集数据传播到查询集数据中。
近年来,一系列的工作开始研究图像的局部特征,通常局部特征包括图像的一部分和提取的特征一部分。Zhang 等人(2020)提出DeepEMD引入EMD(earth mover’s distance)距离度量方式,通过寻找各个图块之间的最佳匹配方式来计算距离进行分类;Afrasiyabi 等人(2022)提出Sum-min(a sum the minimum distances),从特征提取器不同层次的特征出发,提取多个特征层特征组成特征集合,计算集合距离进行分类。基于度量学习的方法因其简单且有效的特点,在少样本学习中得到广泛应用,如何提升特征空间的泛化性能以提高分类识别能力是亟需解决的问题。
1.1.2 基于梯度优化的少样本学习方法
基于优化的方法,通常包括两个循环阶段。内循环阶段基模型学习器快速适应于只有少量样本的新任务;外循环阶段元模型学习器学习跨任务的知识以得到好的泛化能力。Finn等人(2017)提出模型无关的元学习方法(model-agnostic meta-learning,MAML),通过在大量任务分布中学习,以找到对于所有任务的最好初始化以实现快速泛化。Baik等人(2020a,2020b,2021)分析了MAML 模型构成,分别从初始化、内循环的学习率和损失函数出发提出了L2F(learning to forget)、ALFA(adaptive learning of hyperparameters for fast adaptation)和MeTAL(metalearning with task-adaptive loss function)模型,通过感知机建立另一个元学习器,来学习适应于每个任务的初始化,更新参数以及损失函数。通过利用多个元学习器自适应地学习每个任务的参数,改善了梯度优化少样本方法分类准确率不高的问题。基于梯度优化的方法目的是使模型学会学习,这种方法新颖且灵活,但是元学习过程元知识遗忘的问题依旧存在,这也导致了该类方法分类识别能力不足。
1.1.3 基于迁移学习的少样本学习方法
基于迁移学习的方法主要在基类数据上学习一个好的特征提取器,再迁移到新类任务中微调一个分类器,以获得好的分类效果。Chen 等人(2020)提出了baseline,在多组数据间的实验发现随着模型提取特征能力的提升,数据集间性能差异越小。Tian等人(2020)提出RFS(rethinking few-shot)模型,利用知识蒸馏优化嵌入网络可进一步提升识别率,发现一个性能好的嵌入网络要比复杂的元学习和度量学习更高效。基于RFS,Rajasegaran 等人(2020)使用自监督学习辅助训练特征提取器,提出SKD(selfsupervised knowledge distillation),进一步提升分类准确率。张睿等人(2022)、吕佳和巫若愚(2023)进一步探索将自监督学习的方法结合到少样本学习中。Yu 等人(2020)提出TransMatch,利用MixMatch(mixup match)(Berthelot 等,2019)半监督方法使用无标签数据。Wang 等人(2020)提出ICI(instance credibility inference),通过线性回归假设和稀疏度排序选择伪标签实例使用无标签数据。通过迁移学习和半监督方法的结合,少样本分类的准确率有了较大的提升。Zhou 等人(2021)提出BML(binocular mutual learning),元训练时考虑每个样本在基类中的全局类别和任务中的局部类别进行训练,提升了分类准确率。基于迁移学习的少样本学习方法实现简单,可以达到不错的分类效果,但是其阈值明显,超过该阈值后分类效果提升不足。
2 元余弦损失的少样本学习模型
本节主要介绍一种用于元余弦损失的少样本图像分类模型。其基本思路是,对于每个输入网络的训练任务,先对任务中的图像进行全局与局部数据增强,使用ResNet12(residual network 12)网络作为特征提取器提取任务特征,然后利用自注意力机制计算数据增强后的特征,最后使用MCL 计算分类损失对模型进行训练。模型总体结构如图1所示。

图1 AMCL-FSIC模型Fig.1 AMCL-FSIC model
2.1 问题定义
目前,少样本学习多是基于元学习架构,通常将多任务作为训练和测试的基本单元。元学习通过学习大量训练任务,使模型获得“元知识”,使其具有快速适应少样本新任务的能力。通常,将数据集分为用于训练的基类数据集Dbase和用于测试的新类数据集Dnovel,设Dbase包含的类为Cbase,Dnovel包含的类为Cnovel。根据元学习定义,基类样本和新类样本需来自不同的类,即满足Cbase∩Cnovel=∅。元学习在处理少样本问题时,采用N-wayK-shot的范式构造任务,即每个任务中包含N个类,从每个类随机抽取K个样本构成支持集,并在对应的N个类的剩余样本中随机抽取M个样本作为查询集。
2.2 元余弦损失函数的构造
基于度量学习的少样本学习方法,核心思想是引导元学习模型去学习一个嵌入函数,通过嵌入函数将图像转换到一个可判别的嵌入空间中,在该空间中可利用简单的判别函数快速准确地分辨不同的类。理想的嵌入空间是类内距小、类与类之间的间距清晰可分,这样将更助于测试样本的识别。为了扩大类间距,得到更优的嵌入空间,本文提出的元余弦损失方法,旨在余弦分类器的元训练过程中利用样本与类原型之间的相似性,结合查询集真实的标签信息,利用余弦相似性的差异将样本与其他类原型间的距离拉远,提升模型的分类效果。
2.2.1 余弦分类器
余弦分类器用于少样本学习中,首先通过嵌入函数fφ(∙),将支持集样本转换为嵌入空间中的M维特征表示,然后求取同一类所有支持集样本的特征表示均值作为每一类的类原型Ck,计算过程表示为
式中,Sk表示支持集第k类的所有样本,φ为特征提取网络的参数。
对于每个按照N-wayK-shot 范式构造的训练任务T,可计算N个类原型,表示为C={c1,c2,…,cN}。余弦分类器中,利用求得的N个类原型进行归一化处理后,作为分类器的参数,即
将所有的类原型经过降维后,可视化为一个三维的嵌入空间,如图2(a)所示,表示一个4-way 的分类任务。对于查询集的样本xj,将其特征表示为wxj,在嵌入空间中通过向量间的夹角进行分类。计算查询样本属于其中一类的概率表示为

图2 原型调整过程图Fig.2 The prototype adjustment process((a)cosine classification;(b)adjust the class prototype)
式中,wa为类原型向量,wxj为样本的特征向量,dcos(∙)表示余弦相似性,令∠(wa,wxj)表示两个向量的夹角,如图2(a),其值表示α。
2.2.2 元余弦损失
余弦分类器采用元学习的方式训练,通过余弦分类产生的损失,使嵌入空间中的同类特征聚类、不同类特征相互远离。元训练的目标是在进行元测试时,希望模型处理每个新任务,能够在嵌入空间中将同类样本聚集在一起,同时不同类的特征簇之间具有可分性。
然而,余弦分类器进行元训练时只聚集了同类样本,没有将不同类样本进行充分拉远操作。因此,元训练的模型在测试具有相似类别的新任务时所具有的泛化能力将减弱,分类识别率降低。基于余弦分类器提出的元余弦损失,可以更好地完成上述优化目标。
在元训练过程中利用余弦分类器计算每个样本与求得类原型的余弦相似性,利用样本的真实标签可查询该样本与其真实类原型间的余弦相似性,计算该样本与其他类原型的余弦相似性的差异值,利用该值作为调整权重,根据平行四边形原则调整其余类原型。模型通过该调整过程学会在每个新任务中将不同类聚集的簇尽可能远离,给模型更多缓冲,面对新的测试任务时能够尽可能拉远不同类簇,提升模型的泛化能力。
如图2(b)所示,一个4-way 分类任务的调整过程如下,其中xj为查询集中的一个样本,其在嵌入空间中的向量表示为wxj,wc表示该样本的真实类原型向量,wa,wb,wd则表示其他类原型向量。令wxj与wc的夹角为θ,则样本与真实类原型的余弦相似性为cosθ,令wxj与wa的夹角为α,则样本与a类的类原型的余弦相似性为cosα。为扩大类间距,将查询集样本与其他类原型的夹角增大,即扩大夹角α。调整过程利用平行四边形法则进行向量的加减法,调整方向如图2(b)中箭头所示,经过归一化,得到调整后的类原型w′a。调整过程为
式中,wk∈{wa,wb,wd}表示类原型向量,ρ∈{α,β,γ}表示查询样本与类原型间的夹角,其中特征向量分别对应相应的角度。
调整类原型后,再次计算查询样本属于其中一类的概率,具体为
对于任务中的一个样本xj∈T,利用交叉熵损失,计算少样本分类损失,具体为
式中,w′k表示wk调整后的类原型,wc表示其真实类原型,φ表示特征提取网络的参数。
2.3 全局与局部数据增强
传统的深度学习在训练图像分类模型时,通常提取输入图像的单个特征向量进行分类。最近的几项少样本学习的工作表明,整幅图像在训练模型时,其模型提取的特征向量包含较多的背景信息。而少样本学习的设定,数据的标注样本较少,基于度量学习的少样本方法通常采用支持集中的标注样本均值作为类原型。这将导致较多的无用信息包含在类原型中,类内距变大,导致类偏差的产生,进而分类准确率降低。
自监督学习的快速发展,表明数据增强有利于模型提取到更优的特征表示。研究表明,图像的局部特征能够提供跨类别的区别性和可迁移性的信息,而这些信息对于少样本学习中的图像分类是有益的。因此,为了得到每个样本更能代表其类别的特征以及其类原型,缩小类内距,本文充分利用图像的数据增强,结合图像的全局和局部数据增强,利用局部信息引导模型更多关注图像的前景信息,缓解背景信息所带来的偏差。图像的全局数据增强,即在原始图像上进行图像处理的变换,将全局数据增强后的特征记为全局特征;图像的局部数据增强,即从原始图像上进行随机的多次裁剪,裁剪后的特征视为局部特征。
2.3.1 全局数据增强
通过全局数据增强后,可以进一步在少样本学习中引入自监督学习方法。因此,针对少样本学习中标签数据少,可使用数据也少的特点,本文主要使用预测旋转角度的自监督方法。即在进行全局数据增强时,本文针对原始图像进行M次旋转,通常设置为4 次,将这M个旋转图像作为该样本的全局特征,变换过程如图3(a)所示。

图3 全局与局部数据增强Fig.3 Global and local data augmentation((a)global data augmentation;(b)local data augmentation)
经数据增强后,在训练分类过程中,可计算一个基于预测旋转角度的自监督损失。对于每个任务T,可计算任务中的自监督损失,具体为
式中,φ表示特征提取网络的参数,Wδ表示旋转预测分类全连接层,δ为全连接层的参数,R={0,1,2,3}表示4种旋转变换,r∈R表示进行其中的一种变换。
2.3.2 局部数据增强
图像的局部特征可提供跨类别的区别性和可迁移的信息,这些信息对于少样本学习中的图像分类具有重要意义。因此,为得到图像的局部信息,在每幅图像上进行局部随机裁剪,将裁剪得到的一部分视为局部特征,经过H个局部数据变换得到H个局部特征。其数据增强方式如图3(b)所示。
2.3.3 自注意力机制
对于每个N-wayK-shot方式抽取的任务,经过提取全局和局部数据增强后,可以得到多个相同结构的任务集。为有效利用这样的多个任务集,本文利用自注意力机制计算全局与局部特征间的关系,利用局部信息引导网络提取更多样本中的具有代表性的信息。
给定一个任务T,可以得到该任务的扩展任务集Ta,计算特征集为Temb,其中Temb={fφ(xi)|(xi,yi,r)∈Temb;r=0,…,M+H;i=1,…,lk+lq},其 中lk=N×K,lq=N×q分别表示支持集和查询集样本数。任务集中的每个任务都是根据任务T进行对应的图像变换得到的新任务,为挖掘不同数据增强样本间的信息,需要对特征集进行组合,令组合后的特征为F∈R(lk+lq)×(M+H)×d,其中d为特征的维度。对于组合后的特征,本文采用基于自注意力机制的结构来计算集成后的特征。首先,根据特征集F得到(F,F,F)作为自注意力机制输入的三元组(Q,K,V)。令Fi表示特征集F中一个样本的特征集,注意力模块的定义为式中,dk=d表示特征维度,WQ、WK和WV表示3 个全连接层的参数,在图1中用ζ表示。每个样本的特征集经过自注意力机制后,求特征集的均值得到每个样本的特征,具体计算为
式中,F(att)∈R(lk+lq)×d表示该任务经过全局和局部数据增强利用注意力机制融合得到的新任务特征。
2.4 总损失
在少样本元训练过程中,模型的训练损失包括构建全局数据增强所带来的自监督损失以及少样本任务训练的监督损失。因此,训练本文所使用模型的总损失Ltotal记为
式中,T为在数据集中随机抽取的一个任务,φ为特征提取网络的参数,δ为全连接层的参数,ζ为自注意力机制中全连接层的网络参数,τ为加权因子。
2.5 算法流程
预训练过程使用样本与不同原型之间的相似性调整其他类原型;元测试过程则直接使用余弦相似性进行调整。本文给出元训练与元测试算法流程如算法1和算法2。
2.5.1 元训练过程
2.5.2 元测试过程
3 实 验
将本文模型与经典以及最新的少样本学习方法在5个常见的少样本经典数据集上进行实验。
3.1 数据集
1)MiniImageNet(Vinyals 等,2016)数据集是从ImageNet(Russakovsky 等,2015)数据集中抽离出来的一个子数据集,用于少样本图像识别。共包含动植物等在内的100个类,每个类包含600幅图像。为了满足少样本学习的需要,通常将100 个类划分为64 个训练类、16 个验证类和20 个测试类,其中所有图像规格都是84 × 84像素。
2)TieredImageNet(Ren 等,2018)数据集与Mini⁃ImageNet 类似,是更大规模的ILSVRC-12(imagenet large scale visual recognition challenge 2012)(Russa⁃kovsky 等,2015)数据集的一个子集,共608 个小类。与MiniImageNet 不同,TieredImageNet 数据集使用了更广泛的类别层次结构,每个类都属于一个更大的类,共34 个大类。在划分数据集时,将20 个大类作为训练集,包含351 个小类,共 448 695 幅图像;将6 个大类作为验证集,包含97 个小类,共124 261 幅图像;将8 个大类作为测试集,包含160 个小类,共206 209幅图像。图像规格同样为84 × 84像素。
3)Cifar100(Bertinetto 等,2019)数据 集包含100 个类,每个类包含600 幅图像,规格为84 × 84 像素的彩色图像。在少样本学习设置中,将数据集划分为64个类训练、16个类验证和20个类测试。
4)FC100(Few-shot Cifar100)(Bertinetto 等,2019)数据集基于Cifar100 数据集,设置了低分辨率和超类,构建更具挑战性的任务,图像规格设置为32 × 32 像素。100 个类分为20 个超类,划分12 个超类包含60 个类用于训练,4 个超类包含20 个类分别用于验证和测试。
5)CUB(Caltech-UCSD Birds-200-2011)(Wah 等,2011)数据集是一个细粒度分类数据集,包含200个不同鸟类的图像,图像规格为84 × 84像素。200个类划分为100个类训练、50个类验证和50个类测试。
3.2 实验细节
3.2.1 实验环境
在Ubantu20.10系统,GeForce RTX 3090(24 GB)GPU,Pytorch(1.7.1)深度学习框架上进行实验。
3.2.2 参数设置
深度学习模型的实验结果很大程度上取决于网络结构模型的设计以及参数初始化。在构造任务时,都是通过在数据集中随机采样图像构造训练任务与测试任务。本文选用常见的ResNet12 网络作为特征提取器进行实验结果对比。同时,在进行元训练之前,利用每个数据集的基类数据对网络结构进行简单的预训练,作为特征提取器的初始化。在训练和测试时,本文按照标准的元学习策略,即NwayK-shot 进行数据集划分,目前主流采用5-way 1-shot 以及5-way 5-shot 的形式。全局数据增强数量M=4,局部数据增强数量H=4,设置权重系数σ=3,加权因子τ=1。从训练基类数据中抽取8 000个任务,每100 个任务作为一个epoch,采用SGD(stochas⁃tic gradient descent)优化器,初始学习率为0.000 2,在第50个循环时学习率减半。测试时从测试新类数据集中采样2 000 个任务,测试时不需进行微调,取全部测试任务的平均Top-1准确率作为最终准确率。
3.3 实验结果与分析
在多个标准数据集上进行的少样本实验结果如表1 和表2 所示。其中,表1 记录了在MiniImageNet和TieredImageNet 标准数据集上的少样本图像分类结果;表2 记录了在Cifar100、FC100 和CUB 标准数据集上的少样本分类结果。
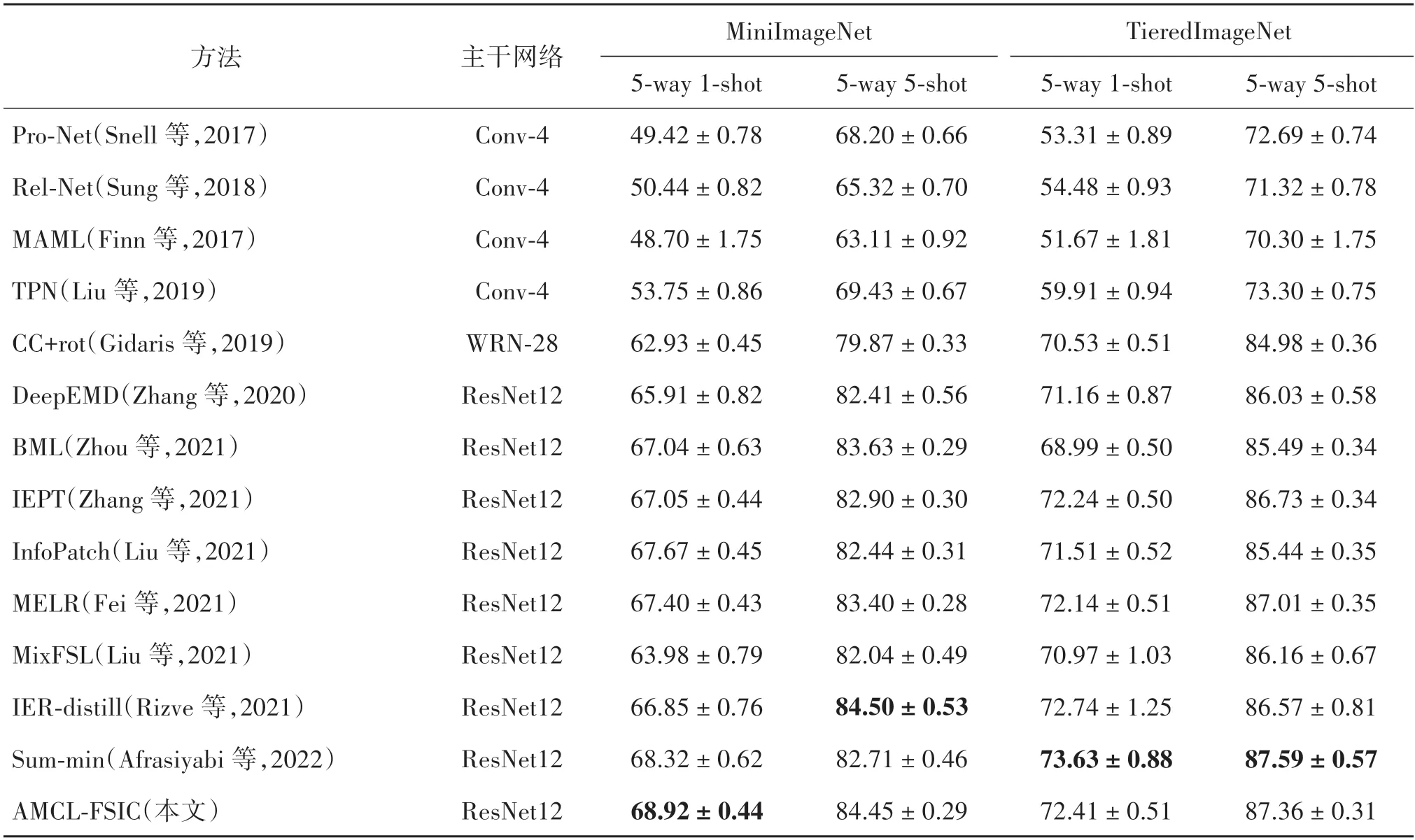
表1 不同方法在MiniImageNet和TieredImageNet数据集上的少样本实验结果比较Table 1 Comparison of few-shot experimental results of different methods on MiniImageNet and TieredImageNet datasets
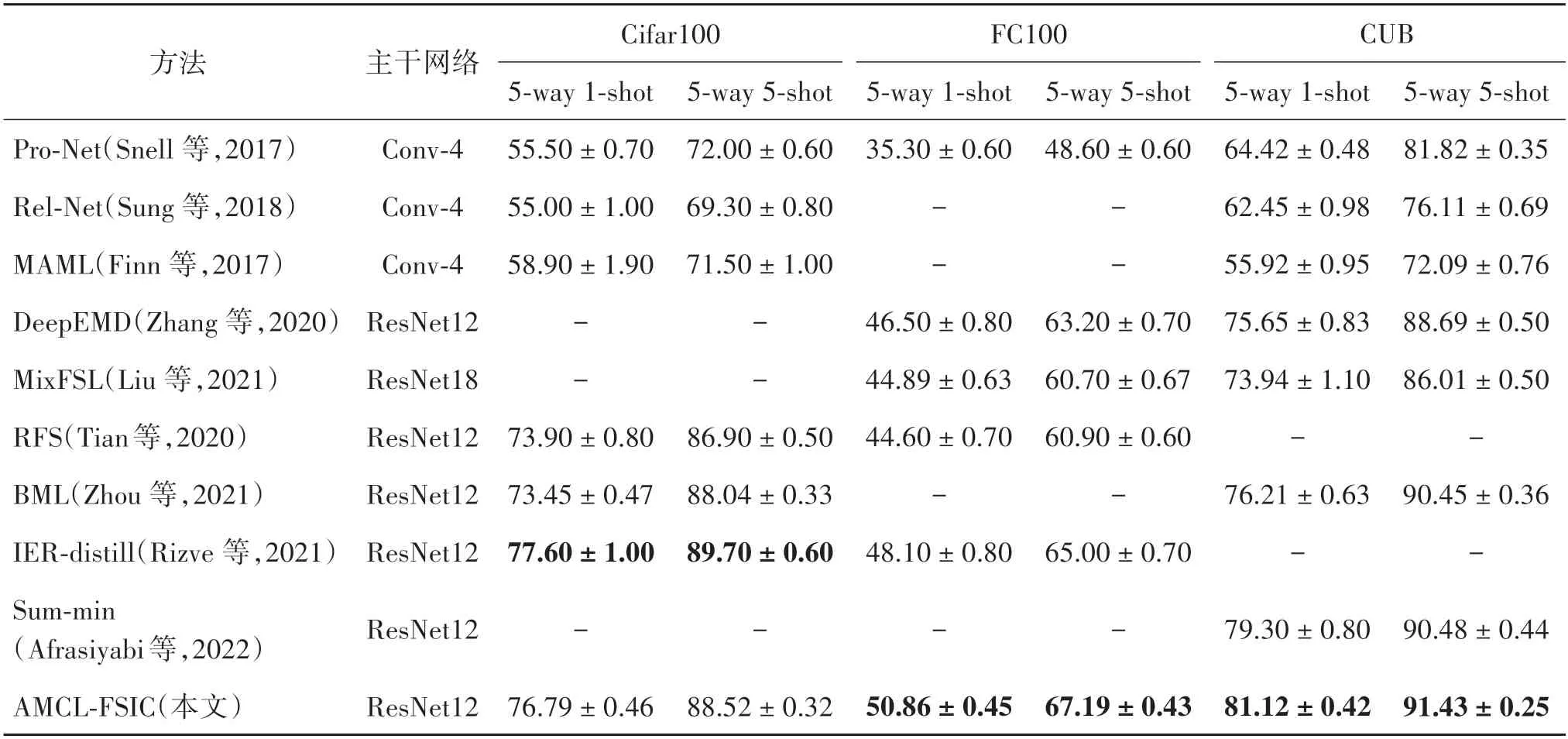
表2 不同方法在Cifar100、FC100和CUB数据集上的少样本实验结果比较Table 2 Comparison of few-shot experimental results of different methods on Cifar100,FC100 and CUB datasets
从表1 可以看出,在MiniImageNet 数据集实验中,AMCL-FSIC 对比同样基于自监督的余弦分类器的少样本分类方法CC+rot(cosine classifiers),在1-shot 和5-shot 上分类准确率有较大幅度的提升。与较先进的BML、IER-distill(invariant and equivariant representations)和Sum-min 等方法相比,在1-shot 上的实验结果已经达到了最好的分类准确率,在5-shot 上与结果最好的分类方法IER-distill 相比仅相差0.05%,已经达到了一流的分类准确率水平。
表1 在TieredImageNet 数据集的实验中,AMCLFSIC 方法的分类准确率与余弦分类方法CC+rot 相比,在1-shot 和5-shot 上分别提升了1.88% 和2.38%,超过了除Sum-min 方法的所有方法。与Sum-min 方法相比,在1-shot 和5-shot 的实验中分类准确率分别低了1.22%和 0.2%。分析认为,Summin 方法通过度量支持集特征集合和查询集特征集合的距离进行分类。该方法更多地专注到图像的细节,这使得Sum-min 方法的训练往往需要更多的数据,而TieredImageNet 数据集比MiniImageNet 数据集的数据量大得多。因此,Sum-min方法在Tiered Ima⁃geNet上的分类准确率更好,AMCL-FSIC在相对更小的数据集MiniImageNet上的分类准确率更好。
从表2的实验结果可以看出,在FC100和CUB数据集的实验中,本文方法均取得了最优的实验结果。其中,在FC100 数据集中,本文方法较IER-distill在1-shot和5-shot上分别提升了2.76%和2.19%;在CUB 数据集中,较Sum-min 在1-shot和5-shot上分别提升了1.82% 和0.95%。在Cifar100 数据集中,AMCL-FSIC 方法实验结果虽未达到当前最优,但超过了除IER-distill 的所有方法,仅比IER-distill 在1-shot和5-shot上分别低了0.81%和1.18%。与BML等方法相比,AMCL-FSIC 已经取得了一流的分类准确率。
从上述实验结果可以看出,本文方法在常见的经典少样本图像数据集上的分类能力与当前最新的少样本方法相当。虽然没有在全部数据集上达到最优的分类能力,但是对比在所有数据集上实验结果的方差,可以发现本文方法在测试新任务时方差都较小,这表明本文方法的鲁棒性强。本文通过全局与局部数据增强获得更丰富、更具判别性的特征表达;通过提出的元余弦损失在余弦分类器的基础上调整类原型,对比基于余弦分类器的CC+rot 方法得到了更有利于余弦分类器进行泛化的嵌入空间。使基于余弦分类器的度量少样本学习方法的分类能力能够与当前最优的少样本学习方法相当,证明了元余弦损失结合全局与局部数据增强的有效性。
3.4 消融实验
3.4.1 探究本文提出的MCL的有效性
为了充分探究本文提出的MCL 所提升的模型表达能力,实验去除所有数据增强方式,即去除其余全局与局部特征对模型提升所带来的影响,只使用图像本身的特征进行对比实验。分别在原型网络、余弦分类器以及本文提出的MCL 上进行实验;分别在MiniImageNet、CUB 以及Cifar100数据集上进行实验。实验结果如表3 所示。从表中结果可以看出,在3 个数据集中,MCL 方法较余弦分类器具有较大提升,在1-shot 上提升了3%~4%,在5-shot 上提升了1%~2%。实验结果证明了MCL 的有效性,表明本文方法的有效性。

表3 MCL有效性实验数据Table 3 Verify the effectiveness of MCL
为进一步表现MCL 对少样本分类效果的提升,本文分别对余弦分类器和提出的元余弦损失所训练的模型,在MiniImageNet 数据集的一个测试任务的特征进行T-SNE(T-distributed stochastic neighbor embedding)降维,然后绘制降维后的散点图,实验结果如图4所示。

图4 T-SNE可视化散点图Fig.4 T-SNE visualizes the scatter plot
根据图4 的可视化图可以看出,在嵌入空间中,引入MCL 元训练的模型与利用余弦分类器训练的模型相比,在测试新任务时同一类样本聚集更明显,同时不同类簇之间的类间距也更加明显,这也进一步证明了MCL对少样本图像分类能力是积极的。
对比表2 中使用全局与局部数据增强后的识别能力,发现在CUB 数据集上不引入额外的数据增强信息,仅仅使用图像数据自身的信息,模型的识别能力相当。分析认为,CUB数据集用于细粒度分类,其中所有类别都属于鸟类,局部数据增强产生的很多局部细节如羽毛、爪等信息区分性较小,导致可区分性降低。
3.4.2 探究局部数据增强的数量影响
为探究局部数据增强对少样本图像分类准确率的影响,尽可能降低全局数据增强所带来的影响,从而反映局部数据增强所带来的分类效果提升。本实验选择每个图像的原始数据,且仅使用一张样本作为全局数据增强,然后从1~10分依次递增1个局部数据增强进行消融实验,通过在FC100 数据集上进行实验,探究并选择最优的局部数据增强的数量。实验结果通过不同局部数据增强的数量选择,进行元训练,测试2 000 个任务的分类准确率的均值,绘制折线图如图5所示。
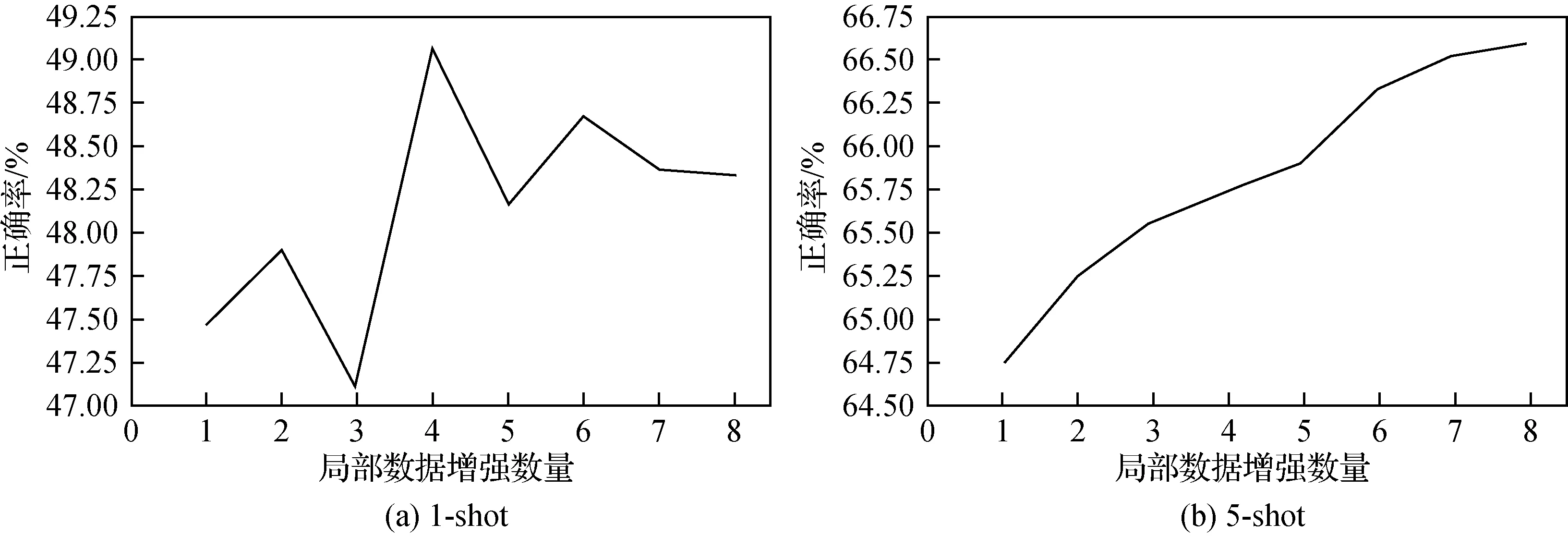
图5 局部数据增强数量对准确率的影响Fig.5 Effect of the number of local data augmentations((a)1-shot;(b)5-shot)
根据图5中的识别率变换曲线,在1-shot的状态下识别率与局部数据增强间的数量关系并不呈现线性变换,在选用4 个局部数据增强时达到最好。在5-shot 的实验设置下则呈现线性的关系,越多的局部数据增强其识别能力越好。然而,局部数据增强的数量越多所需要的运算资源越多,时间成本越高。因此,通过分析两种实验设置下的实验准确率,充分考虑计算成本以及得到最优的模型识别能力,本文最终设置的局部数据特征数量为4,其中表1 和表2所测试的结果都基于此。
3.4.3 探究全局与局部的作用
为探究全局与局部特征对模型识别能力提升的影响,分别选用4 个旋转角度的全局增强、4 个局部数据增强以及它们的组合进行实验。实验设置与之前类似,分别报告2 000 个任务的测试识别率的均值,结果如表4所示。
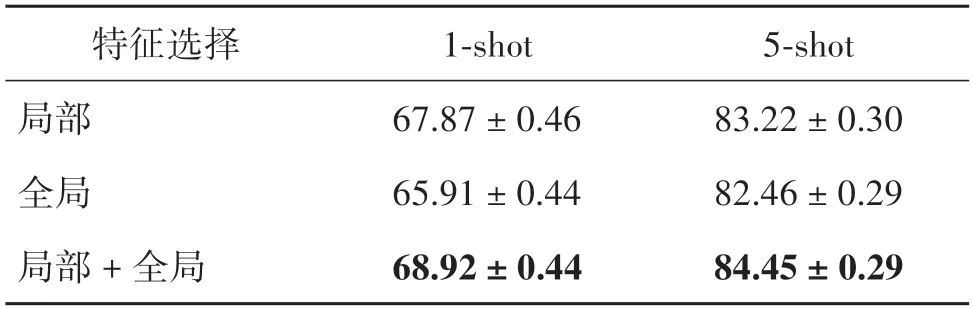
表4 全局与局部特征的作用Table 4 The impact of global and local features
由表4 结果可以看出,单纯使用局部数据增强所具备的识别能力优于单纯使用全局数据增强方式。由此进一步证明,局部数据增强后的样本提供了更多具有跨类别区别性和可迁移性的信息,这些信息更有利于少样本的图像分类。将全局与局部数据增强结合起来,能够达到目前最优的分类准确率,验证了本文方法的有效性。
3.4.4 探究自注意力机制的有效性
本文提出的全局与局部结合的数据增强方式,使得每个样本的特征由8 个数据增强特征组成。因此,需要将这8 个特征组合为一个更具代表性的特征,常使用的方法为特征拼接和求均值等。考虑到每个特征维度为640,8 个特征进行拼接所产生的特征维度太大,因此本实验只考虑求均值的情况,比较使用自注意力机制前后所带来的实验效果提升。在MiniImageNet 和CUB 数据集上进行实验,如表5 所示。从表5 可以看出,引入自注意力机制后,模型的识别能力较直接求均值的方式在所有设置中有1%左右的提升。分析认为,自注意力机制会引导模型将局部特征中学习的有效信息转移到全局特征中,即在全局特征中更多关注图像的前景信息,更利于少样本图像的分类。

表5 自注意力机制的作用Table 5 The role of self-attention
4 结论
本文从样本特征提取和特征簇在嵌入空间中的分布出发,提出了AMCL-FSIC 方法,提升了度量学习方法在少样本图像分类中的分类准确率。为了使模型更多关注图像的前景信息,本文提出将全局与局部数据增强结合起来,利用局部数据增强引导模型更多关注样本前景信息,能够提取到更丰富、更具判别性的嵌入特征。基于余弦分类器,本文提出了一种元余弦损失,通过在元训练的过程中根据样本的真实标签调整其余类原型,扩大不同类之间的类间距,使模型学会在任务中将不同类的样本在嵌入空间中的距离尽可能变大,增强模型在处理新任务的泛化性。通过对样本特征和特征分布的改进,学习的模型对新任务的分类识别能力进一步提升,在5 种少样本数据集上进行实验,与主流的少样本图像分类方法相比已经达到了一流的分类准确率,实验结果验证了AMCL-FSIC的有效性。
然而,本文方法仍然存在不足,基于局部数据增强的方法,实验结果表明进行越多的局部数据增强,所得到的实验结果越好。但是,随着数据的增加,所需要的计算花销也进一步增加,如何进行更有效的局部增强,值得进一步完善。另外,本文采取的全局数据增强是基于预测旋转角度的自监督学习方法。近年来,基于对比学习的自监督学习方法在图像分类识别领域取得较多成果。如何将对比学习用于少样本学习中,并进一步提升其分类识别能力,是下一步进行研究的方向。
