融合多重机制的SAR舰船检测
2024-02-24肖振久林渤翰曲海成
肖振久,林渤翰,曲海成
辽宁工程技术大学软件学院,葫芦岛 125105
0 引言
合成孔径雷达(synthetic aperture radar,SAR)是一种流行的遥感技术,具有全天候、全天时、不受天气影响等成像特点,可提供高分辨率的海面图像,用于检测船舶。SAR图像在航空、海洋、天文等领域有着广泛的应用。然而,在目标检测领域,SAR图像检测面临着较大的挑战,因为SAR 图像中目标的形状和尺寸复杂多变,同时受到杂乱的背景、相干斑噪声、杂波和其他干扰因素的影响(Dalsasso 等,2020)。因此,提高SAR 图像检测的精度是当前研究的热点和难点。
传统的机器学习方法需要大量的人工设计的特征,并且难以捕捉图像中的高级特征。随着深度学习技术的不断发展,基于深度学习的SAR 图像目标检测算法得到了广泛的研究。相比传统的手动设计特征的方法,深度学习算法利用深度神经网络进行端到端的训练,避免了烦琐的手动特征设计过程,因此具有更高的准确性和鲁棒性。基于深度学习的目标检测算法主要分为两类:双阶段和单阶段。
双阶段算法主要是基于Faster R-CNN(faster region-based convolutional neural network)(Ren 等,2017)等框架,通过使用RPN(region proposal net⁃work)生成候选区域,再利用CNN(convolutional neu⁃ral network)分类定位候选区域。
单阶段算法直接将候选区域分类和定位结合在一起,简化了目标检测流程,如SSD(single shot mul⁃tibox detector)算法(Liu 等,2016)、RetinaNet(Lin 等,2017)、CenterNet(Duan 等,2019)以及YOLO(you only look once)系列算法等(Redmon 等,2016)。其中,YOLO 算法思想是将图像划分为多个网格,每个网格预测一个边界框和其所包含物体的类别,然后通过非极大值抑制(non-maximum suppression,NMS)算法消除重叠的边界框。YOLOv2(Redmon 和Farhadi,2017)用Darknet-19 作为基础网络并引入了Anchor 机制。YOLOv3(Redmon 和Farhadi,2018)在此基础上,使用Darknet-53 作为主干网,加入特征金字塔网络(feature pyramid networks,FPN)和空间金字塔池(spatial pyramid pooling,SPP)等模块增强对不同尺度和语义信息的提取能力,同时使用多个输出层对不同尺度的目标检测。YOLOv4(Bochkovskiy等,2020)采用Mish 激活函数,并引入了空间金字塔结构(spatial pyramid pooling,SPP)和特征金字塔结构,这些改进有效提高了模型的语义信息表达和特征提取能力。YOLOv7(Wang 等,2022)引进多分支堆叠模块、创新的过渡模块、重参数化结构和动态标签匹配策略,加强特征提取和语义信息的表达能力。
众多先进的目标检测算法相继提出,检测精度和效率有了很大提升。阮晨等人(2021)引入权重机制,提出了WBAPN(weighted bidirectional attention pyramid network)算法,通过加权双向金字塔特征融合,区分排列紧密的近岸舰船,增强对目标的定位能力,但误检率略高。接着,AR-Net 提升了实时性检测需求和模型的鲁棒性(郭伟 等,2022)。FENDet(feature extraction network)运用三通道混合注意力和含有可变形空洞卷积的骨干网,对目标的细节特征提取和细分类不佳情况进行了改进(龚声蓉 等,2022)。针对移动设备部署效率低下的问题,LMSDYOLO(a lightweight YOLO algorithm for multi-scale SAR ship detection )算法用较少的参数实现了多尺度特征的自适应融合,具有体积小、精度高的优点,但在大尺度场景下的检测效果仍不佳(Guo 等,2022)。FIERNet(feature information efficient repre⁃sentation network)增强了网络特征融合,提取特征细节好,对大尺度图像有较好的处理效果(Yu 等,2022)。ImYOLOv4(improved YOLOv4 based on attention mechanism)引入基于注意力机制的动态特征去噪模块,构建一种新的FPN结构,从而增强网络的表征能力,提升算法精度(Gao 等,2022),但在复杂背景下,仍然存在高漏检率和误检率的问题。这是由于使用CNN 对近岸舰船目标进行检测时容易受到海岸背景杂波的影响。此外,CNN 只能提取规则目标区域的特征,对于近岸停靠的舰船目标,边界框包含了很多海岸背景信息,影响网络特征提取。
基于上述问题,本文将多重机制融入到YOLOv7中。首先,在预处理部分设计U-Net Denoising 模块,抑制噪声对SAR 图像的影响。其次,在网络主干特征提取部分构建MLAN_SC(maxpooling layer aggre⁃gation network that incorporate select kernel and con⁃texual Transformer)结构。在MP(multi-processing)下采样阶段,引入SK(selective kernel)通道注意力机制来增强输入特征图的通道特征。通过信息通道的提取,使网络专注于更多的有效信息,并增强了关键信息的判别能力。这使得本文模型更加关注待检测目标,并进一步提高了其检测精度。为解决下采样结构中上下分支特征不平衡的问题,引入上下文信息提取模块(contextual Transformer block,COT)。该模块利用卷积来提取上下文信息,并将局部信息和全局信息融合,以更有效地提取图像特征。最后,在检测头,将SPD 卷积(space-to-depth convolution,SPDConv)融入方法中,并替换损失函数为WIoU(wise intersection over union),增强对小目标的检测能力。
1 YOLOv7目标检测算法
YOLOv7 网络由输入(input)、主干网络(backbone)、颈部(neck)、检测头(head)4 个主要模块组成。在输入端预处理阶段,通过Mosaic数据增强、自适应锚框计算和自适应图像缩放等操作,将图像缩放至640 × 640像素,使图像符合主干网输入要求。
主干网络由CBS(Conv+BN+SiLU )卷积层、ELAN(efficient aggregation network)模块和MPConv(maxpooling convolution)卷积层组成,其中,CBS 层是由Conv2D、BN(batch normalization )和SiLU(sig⁃moid linear unit)激活函数组成,ELAN 模块为多分支堆叠模块,由多个CBS 层构成,而MPConv 卷积层代替了原来的下采样层,MP1 块在CBS 层的基础上增加了MaxPool 层构成两个分支,上分支使用MaxPool将图像的长度和宽度减半,使用具有128 个输出通道的CBS 将图像通道减半。下分支通过核为1 × 1、stride 为2 × 2 的CBS 将图像通道减半,图像的长度和宽度被核为3 × 3、stride 为2 × 2 的CBS 减半,最后使用concat 操作对两分支提取到的特征进行融合,加强了网络的特征提取能力。最大池化操作扩展了当前特征层的感受野,并将其与普通卷积处理后的特征信息融合,提升了网络的泛化性。
颈部特征融合部分采用传统的 PAFPN(path aggregation feature pyramid networks)结构,包括CBS块、SPPCSPC(spatial pyramid pooling and cross stage partial)结构、扩展高效层聚合网络(efficient layer aggregation network,ELAN)和MaxPool。SPPCSPC 结构通过在空间金字塔池(SPP)结构中引入卷积空间金字塔(cross stage partial,CSP)结构来改善网络的感受野,同时利用大的残差边来辅助优化和特征提取。SPPCSPC 模块在一串卷积中并行添加了多个MaxPool 操作,以避免图像处理操作所造成的图像失真等问题。ELAN-1 层是基于ELAN 的多个特征层的融合,进一步增强了特征提取
检测头部分仍使用anchor-based 结构,输出3 层不同大小的特征图,通过重参数化结构(reparameter⁃ized convolution,RepConv)调整不同尺度特征的通道数。再通过CIOU Loss(complete intersection over union loss)和非极大值抑制(NMS)等处理,得到最终的预测结果。
2 融合多重机制优化的检测方法
本文提出一种综合多重机制优化的SAR 舰船检测方法。该方法的网络结构如图1 所示。红色框线内表示该模块的细节组成结构。

图1 网络整体结构图Fig.1 Diagram of network structure
在将图像输入到主干网络之前,首先进行U-Net Denoising 和 Mosaic 数据增强等预处理。主干网络由 CBS、ELAN_COT 和MLAN_SC 组成,提取3 层特征输出到颈部网络。通过 SPPCSPC、上采样和ELAN对特征进行融合,输出3层不同大小的特征图。在检测头部分,使用SPD-Conv和RepConv block进行图像预测,并输出最终结果。
2.1 U-Net Denoising
由于SAR 成像具有相干性,在复杂背景下可能会出现相干斑噪声,这对于舰船目标检测来说是一个挑战。为了解决这个问题,本文提出了一种名为U-Net Denoising 的图像去噪模块。该模块采用编码器—解码器结构,通过残差块和上下采样操作实现信息传递和尺度变换,运用分层特征映射和跳跃连接的方法,对图像进行重构,获得更清晰的目标。如图2 所示,该模块能够有效地解决复杂场景下由相干斑噪声导致的目标边缘模糊和小目标漏检等问题,从而提高目标检测的准确性。
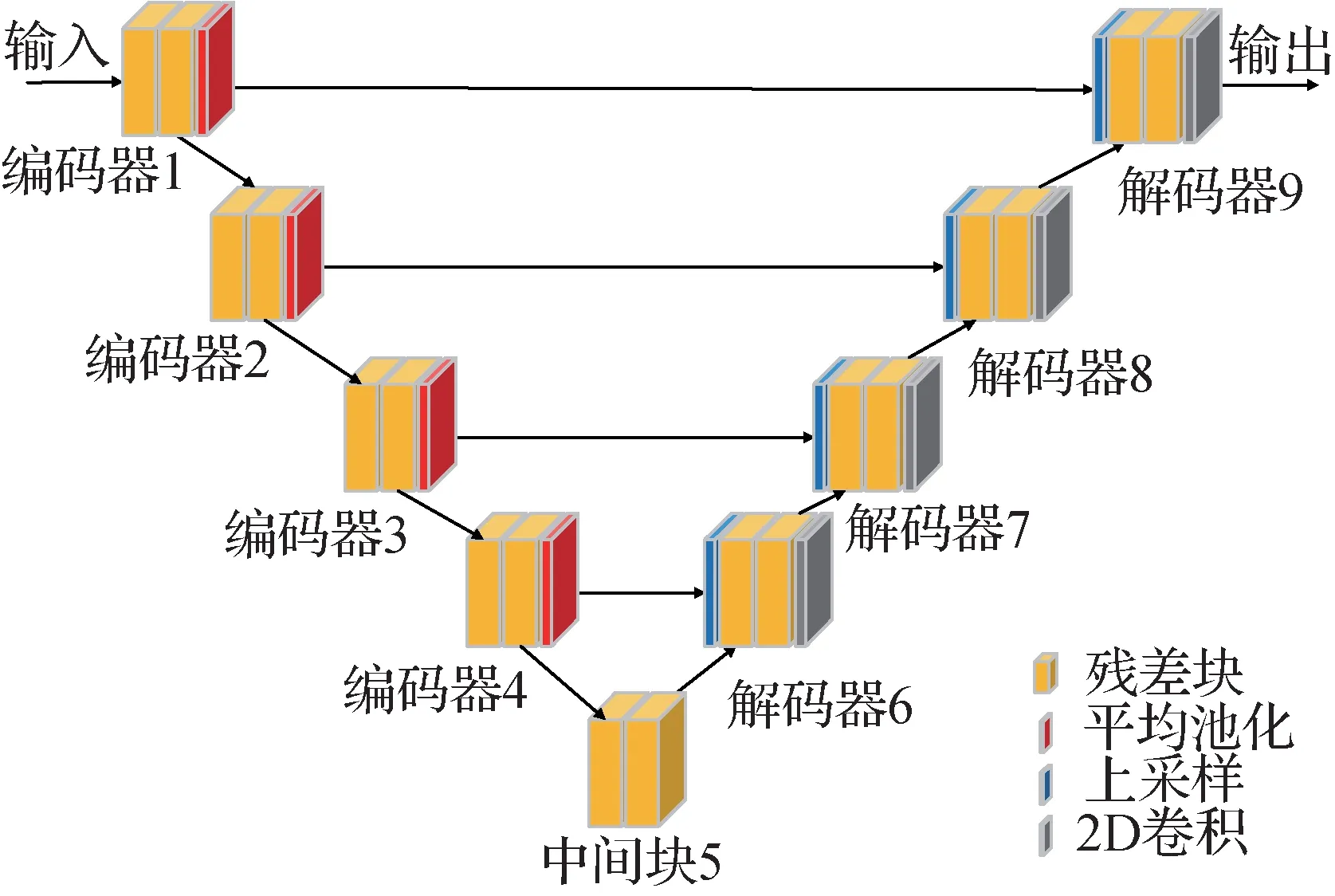
图2 U-Net Denoising模块结构图Fig.2 U-Net Denoising module structure
乘性噪声模型可以用于描述各种随机噪声,包括SAR 图像中的相干斑噪声。为了更好地减轻相干斑噪声的干扰,本文使用乘性噪声表达式来进行建模,进行图像去噪处理。乘性噪声表达式为
式中,Y为噪声图像;Ν为噪声分量,遵循具有单位均值和1/L方差的gamma分布;X为无噪声图像。
式中,P(N)为噪声的概率密度函数,Γ(⋅)为伽马函数,L为参数,影响噪声的方差,即噪声的严重程度。L越大,方差越小,噪声程度越弱。常将L设置为1,但如果本来SAR 图像噪声不严重,L为1 导致会去噪过重,去掉一些图像细节,所以为了更好地适应各种程度的噪声,本文提出将参数设置成1~10比较合适,在训练和测试的时候不用规定L必须是多少,可以称这个过程为盲去噪。
为了进一步验证U-Net Denoising 模块的有效性和普适性,本文对舰船图像数据集进行人工添加噪声处理。图3 展示了去噪效果,图3(a)为数据集内的舰船图像,图3(b)为添加噪声后的图像,图3(c)为去噪后图像。可以看出,经U-Net Denoising 模块的去噪处理后,舰船目标与复杂背景被更清晰地区分。

图3 去噪效果图Fig.3 Removal of noise effects((a)dataset ship image;(b)image after adding noise;(c)image after removing noise)
2.2 MLAN_SC
SAR 舰船检测数据集包含许多小而密集的目标,不易识别。因此,构建一个MLAN_SC 模块来增强对目标的上下文信息提取和特征融合能力。MLAN_SC 模块的前半部分是融入注意力机制的下采样结构,后半部分是上下文关键信息提取和融合结构。图4表示MLAN_SC模块结构。
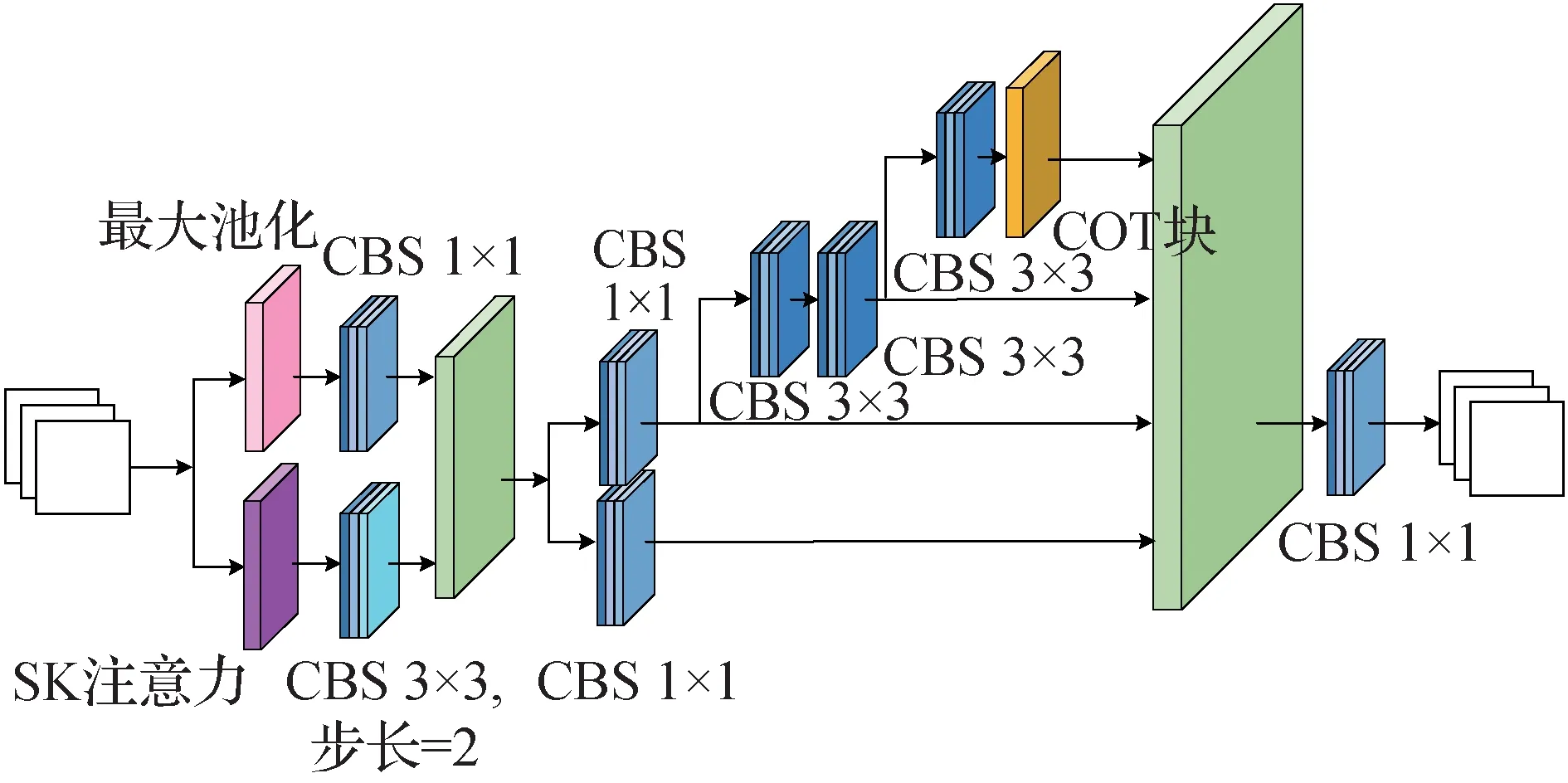
图4 MLAN_SC模块结构图Fig.4 MLAN_SC block structure
2.2.1 特征捕捉采样
由于在下采样过程中,特征图尺寸缩小,会导致一些关键特征丢失。这对小目标检测的定位十分不利。所以尝试在MPConv 结构中加入注意力机制SK进行下采样。对输入特征图中的不同大小物体,自适应选择对应的卷积核来提取特征,生成通道注意力信息,使网络能够自行关注更重要的目标,增强网络结构识别小目标舰船的能力。
相比于SE(squeeze-and-excitation )注意力(Hu等,2018)只是在通道上施加MLP(multi-layer per⁃ceptron)学习权重,SK 注意力可以通过网络自己学习来选择融合不同感受野的特征图信息。SK 注意力机制是一种软注意力机制(Li等,2019),其能在通道维度上对输入特征图进行特征加强,同时保持输出与输入特征图大小的一致性。SK 结构如图5 所示,由3部分组成:Split、Fuse和Select。
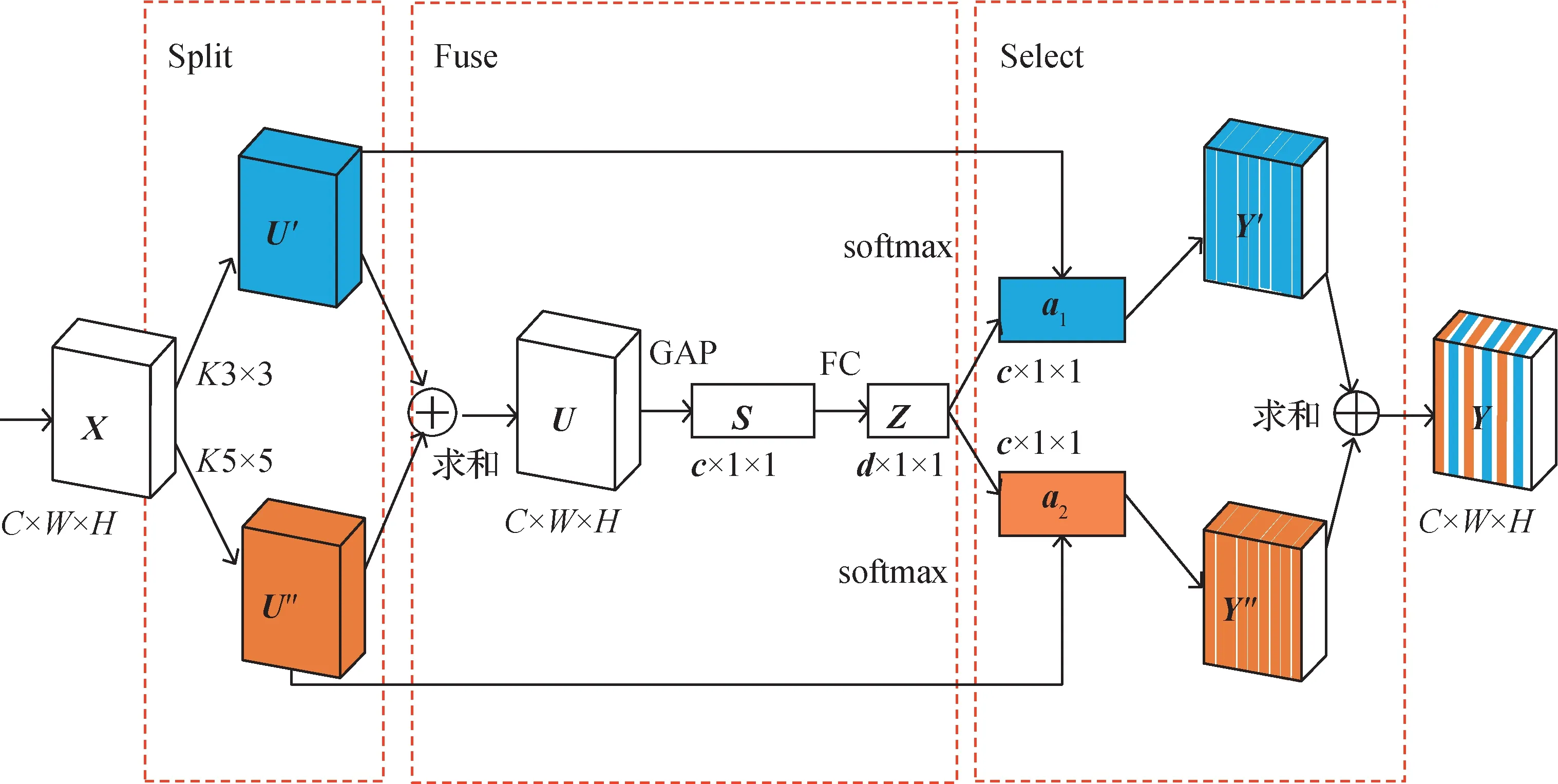
图5 SK注意力机制结构Fig.5 Selective kernel attention mechanism structure
1)Split 部分。分别对输入图像用内核大小为3 × 3 且膨胀大小为2 的膨胀卷积(dilated convolu⁃tion)和内核大小为5 × 5的常规卷积进行卷积操作,得到U′和U″两个特征图。将二者的特征图进行整合,按对应的元素进行相加求和,使融合后的特征图在空间维度上进行一个全局平均池化操作(global average pooling,GAP),得到一个C× 1 × 1 的一维向量SC,将全局信息嵌入到向量A中。通过两层全连接层,提取通道注意力信息,将原来的C维信息降维成更小尺度的d维信息,降低尺寸,提高效率,实现精确控制和自适应选择,完成信息通道维度的提取。具体过程计算为
式中,δ是ReLU激活函数,β是BN批归一化。C是输入特征图的channel,Ws是H×C维的矩阵;r是超参数缩减比,常取16;L为dmin,也是超参数,通常为32。
2)Select 部分。分别对卷积核Α1和Α2与前面的特征图进行卷积操作,从d维升维成原来的C维,运用softmax 函数进行归一化处理,得到每个卷积核对应的通道注意力信息a1、a2,并将其逐通道相乘,与特征图U′和U″结合,得到两个新的特征图Y′、Y″,最后,将Y′和Y″进行信息融合,得到最终的输出图像Y。该过程计算为
式中,σ为经过softmax函数归一化处理。可以看出,输出图像对比于输入图像,经过信息通道的提炼,融合了更多的关键信息,增强了对图像关键信息的提取,使网络更加关注待检测目标。
2.2.2 多分支上下文聚合
为了丰富语义信息并保留更多关键的上下文特征信息,同时缓解下采样分支和注意力分支获取的特征差异,本文提出了一种高效的多分支上下文聚合模块ELAN_COT(efficient layer aggregation net⁃work and contextual Transformer ),它是基于COT 与ELAN 的融合设计而成。该模块能够有效地处理多分支上下文信息,从而提高模型的性能和精度,改善误检情况。ELAN_COT结构如图6所示。
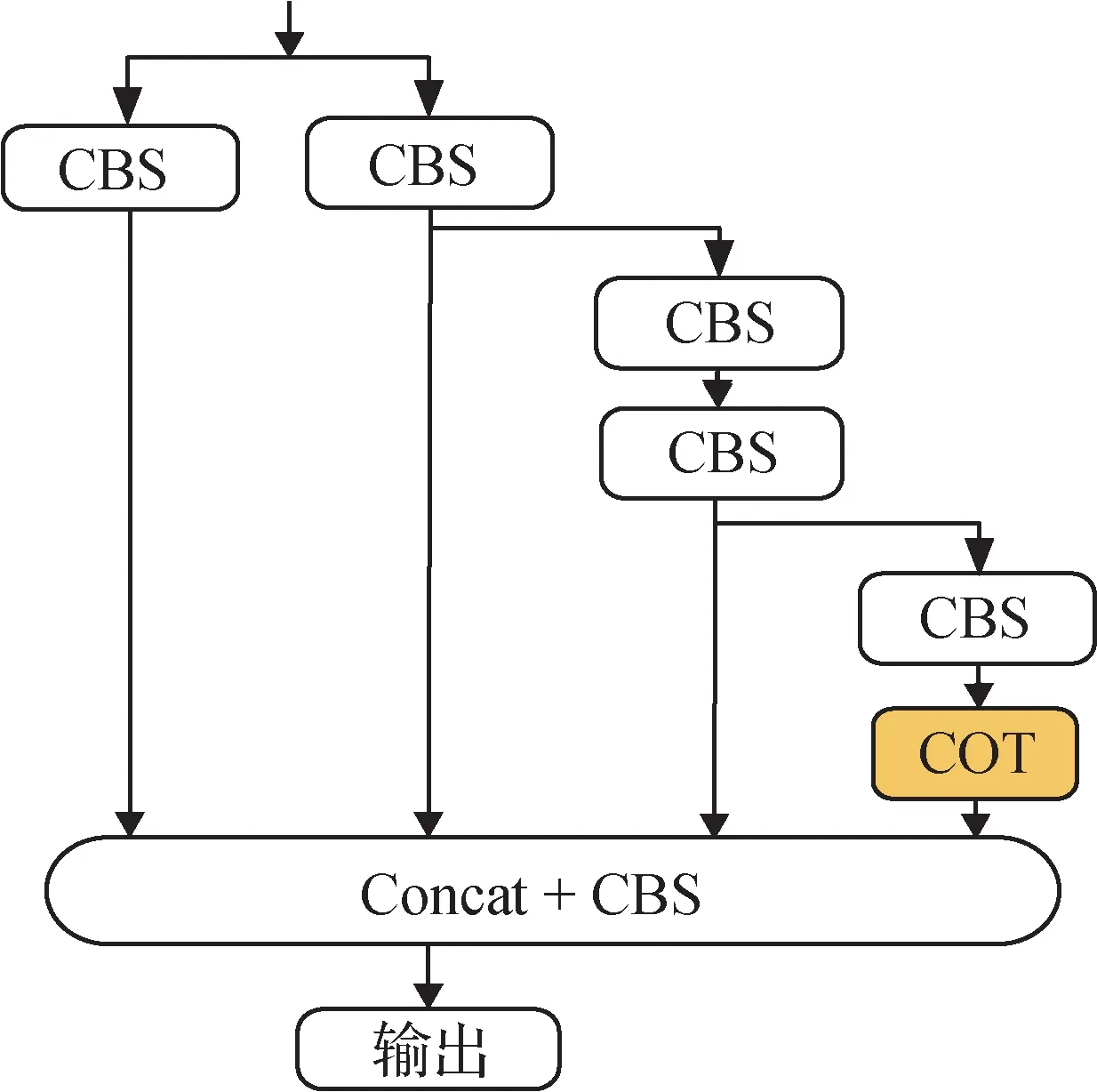
图6 ELAN_COT模块结构图Fig.6 ELAN_COT block structure
为了更好地提取上下文关键信息,采用性能更优的COT 模块替换原有的卷积(CBS)模块。COT 模块所捕获的特征优于CBS 模块,它能够利用相邻输入键之间的上下文信息来指导自注意力学习,COT模块首先捕获相邻键之间的静态上下文,进一步利用它来触发挖掘动态上下文的自我注意。这种方式将上下文挖掘和自注意力学习统一到单一架构中,从而增强了ELAN模块视觉表达能力。
COT 是一种Transformer 风格的结 构(Li 等,2023),是一个统一的self-attention 模块。它利用卷积提取输入特征的上下文信息来增强自注意力机制的学习,将Transformer 捕捉全局信息的能力与CNN捕捉临近局部信息能力相结合(Liu 等,2021),从而提高网络模型的特征表达能力。COT 块结构如图7所示。通过k×k卷积对输入K进行上下文编码,得到K1。K1∈RH×W×C作为输入X的静态上下文表示,自然地反映近邻间的上下文信息。
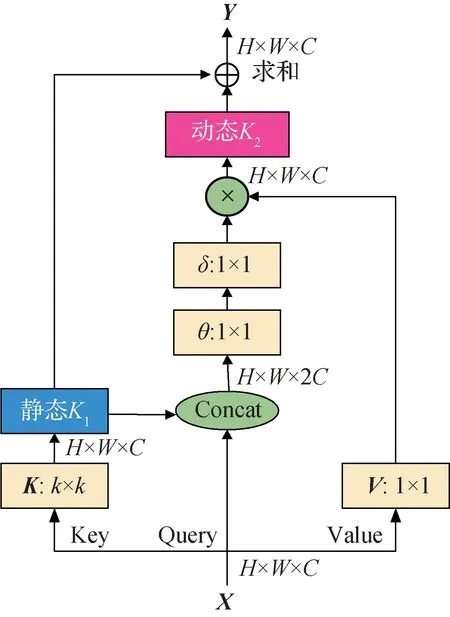
图7 COT块结构图Fig.7 Contextual Transformer block structure
将K1与Q拼接并通过两个1×1卷积计算多头注意力矩阵A,将得到的注意力矩阵A与V相乘得到特征输出K2,称为动态上下文表示。
COT 块最终输出为静态上下文特征映射K1和动态上下文特征映射K2的融合。多头注意力矩阵的计算式为
式中,Wθ和Wδ是学习参数。A是通过Query 矩阵与提取了上下文信息的学习K1得到的,并不是仅通过独立的Query-Key对得到的,通过引入静态上下文表示增强了自注意力机制。
2.3 检测头优化
2.3.1 SPD卷积
SPD-Conv 是一个新的CNN 模块,替代了每个步长卷积和池化层,具有向下采样特征图的优点,不丢失可学习信息(Sunkara 和Luo,2022)。SPD-Conv 由空间到深度(space-to-depth)层和非跨步卷积(nonstrided convolution)层组成,结构如图8所示。

图8 SPD-Conv结构图Fig.8 The structure of SPD-Conv
在SPD 特征变换层部分,定义特征图X大小为S×S×C1,对特征图X切出一系列子特征图,具体为
式中,f0,0,f0,1,f1,0,fscale-1,0,f0,scale-1,fscale-1,scale-1均为特征图X所切出的子特征图。子特征图fx,y由i+x和i+y按比例整除的所有条目x(i+y)形成。因此,每个子图按比例因子对特征图X进行下采样。当scale=2 时,得到4 个子图f0,0,f0,1,f1,0和f1,1,每个子图都具有形状S/2 ×S/2 ×C1并将下采样2 倍;接着,沿通道维度连接这些子图获得X1,这样就在空间维度减少了一个比例因子,而在通道维度增加了比例因子的平 方,即X1的大小为S/scale×S/scale×scale2C1。
由于奇数和偶数行/列的下采样时间不同会发生不对称采样,步长大于1 会导致信息的非歧视性丢失,所以在SPD特征变换层之后,添加一个带有C2滤波器的非跨步卷积层(stride=1),获得X2,大小为S/scale×S/scale×C2,其中C2<scale2C1。
SPD 层采样过程保留了通道维度中的所有信息,非跨步卷积层尽可能保留所有的判别特征信息,因此信息未丢失。SPD-Conv 的引入使得小目标舰船和复杂背景图像模糊情况下的检测有所改善。
2.3.2 WIoU动态聚焦损失函数
YOLOv7 算法的损失函数分别由目标置信度损失、分类损失和坐标损失三者组成,前两者均采用带log 的二值交叉熵损失函数进行计算,后者采用的是CIoU 来进行计算。YOLOv7 采用CIoU_Loss 作为边框损失函数,计算式为
式中,A为真实框,B为预测框,ρ为预测目标框中心点与真实目标框中心点之间的欧氏距离,bgt和b分别为真实目标框的中心点和预测目标框的中心点,C为能够同时包含预测目标框和真实目标框的最小闭包区域对角线距离;wgt和hgt分别表示真实目标框的长和宽;w和h分别为预测目标框的长和宽,a为权重函数,用于平衡参数;v则是用来度量长宽比的相似性。
从式(22)可以看出,当预测框与真实框的长宽比一样大时,v取0,此时长宽比的惩罚项并没有起到作用,CIoU_Loss 得不到稳定表达。因此,针对SAR 图像中大多为较小舰船且呈密集状态分布,本文使用WIoU_Loss 替换原CIoU_Loss(Tong 等,2023)。
RWIoU∈ [1,e)将显著放大普通质量锚框的LIoU。LIoU∈[0,1]将显著降低高质量锚框的RWIoU,并在锚框与目标框重合较好的情况下显著降低其对中心点间距离的关注。构造距离注意,得到具有两层注意力机制的WIoU΄,具体为
式中,Wg和Hg分别表示最小包围框的宽和高。为了防止RWIoU产生阻碍收敛的梯度,∗表示将Wg和Hg从计算图中分离出来的操作,它有效地消除了阻碍收敛的因素。为了使模型更好地关注复杂图像,构造动态非单调注意机制WIoU'',具体为
式中,β为离群度,描述锚框质量;为动量m的滑动平均值;r为非单调聚焦系数;α,δ为超参数,控制β和r的映射。
离群度小意味着锚框质量高,在训练早期阶段,当锚框的离群度β为定值时,锚框将获得最高的梯度增益。由于LIoU是动态的,所以锚框的质量划分标准也是动态的,这使WIoU 可以随时做出最符合当前情况的梯度增益分配策略。在训练的中后期,分配小的梯度增益给低质量锚框以减少有害梯度,同时WIoU''会聚焦普通质量,提高模型定位性能。
3 实验结果及分析
3.1 实验环境
实验环境为Windows11 操作系统,CPU 为i7-12700H,显卡为NVIDIA GeForce RTX 3060,显存为6 GB,在PyTorch1.12.1框架下运行,CUDA 11.6.134。
3.2 实验数据集
本文实验数据选自SSDD(SAR ship detection dataset)(Zhang 等,2021)数据集和HRSID(high reso⁃lution SAR images dataset)数据集(Wei 等,2020)。SSDD 是国内外公开的一个专门用于SAR 图像中舰船目标检测的公开数据集,该数据集包含了1 160幅SAR图像,包含2 456个目标。SSDD数据集的数据主要来源于传感器RadarSat-2、Sentinel-1、TerraSAR-X,分辨率为1 m~15 m,采用HH(水平)、VV(垂直)、HV 和VH 共4 种极化方式,将目标区域裁剪成大小为500 × 500 像素左右,并采用PASCAL VOC(pat⁃tern analysis,statistical modeling and computational learning visual object classes)格式,人工标注舰船目标位置。该数据集中多数为小目标,拥有丰富的近海岸、远海、小尺度和大尺度的特征信息,能有效验证模型的鲁棒性。
HRSID 数据集是电子科技大学在2020 年发布的船舶检测数据集。该数据集中的数据提取自TerraSAR-X、Sentinel-1B 和TanDEM-X 卫星传感器。其中共包含5 604 幅高分辨率SAR 图像和16 951 个船舶实例。HRSID 数据集包含分辨率为0.5 m、1 m、3 m,图像大小为800 × 800像素的SAR 图像,采用horizontal bounding boxes(HBB)标注格式,涵盖不同场景和多种极化生成的图像。
本实验以8∶2 的比例将数据集随机分成训练集和测试集。通过使用ImageNet(a large-scale hierar⁃chical image database)数据集来预训练YOLOv7的权重,并采用SGD(stochastic gradient descent)优化器对网络参数进行迭代更新。动量参数设为0.93,初始学习率设为0.001,批处理大小设为8,训练150个epoch,采用余弦退火方式进行学习率衰减和Warm-Up方法预热学习率。
3.3 评价指标
用精度(precision,P)、召回率(recall,R)、平均精确度(average precision,AP)及加权调和平均F1作为综合评价指标,来表示舰船检测的效果。
3.4 消融实验
为了验证本文改进各模块的有效性,以原始的YOLOv7 网络为基准,在SSDD 数据集上进行多组实验,对比各个机制对检测精度的影响,结果如表1所示。
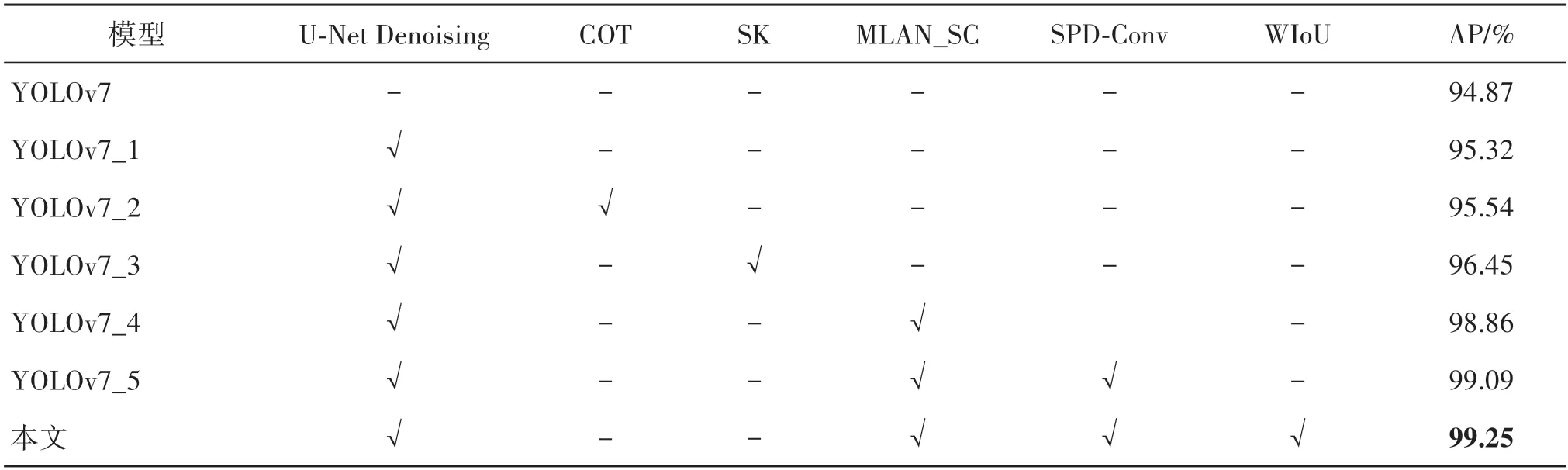
表1 各模块机制的检测精度对比Table 1 Comparison of detection accuracy of each module mechanism
由表1 可见,注意力机制对SAR 图像目标检测的影响比较显著,通过增强深层特征学习表达和关键信息提取,使得误检率降低。U-Net Denoising 的加入使得模型对复杂背景下目标的提取更加明确。这是因为原方法的特征提取不够清晰,受到陆地干扰,将多个密集的目标识别成一个目标,导致漏检。SPD-Conv 的加入,提升了模型对密集小目标的检测能力。WIoU 使网络更好地关注复杂场景图像下的目标,定位性能有所提升,使得最终的检测精度更高。
不同模块融入方法的检测效果如图9 所示。近岸复杂背景图像下,YOLOv7_2 和YOLOv7_5 存在误检,YOLOv7_3 和YOLOv7_4 则漏检率很高,本文算法几乎不存在漏检和误检的情况,并且在密集小目标图像检测中的检测精度高于其他算法。
3.5 对比实验
PR 曲线表示精度和召回率之间的关系,PR 曲线与坐标轴所围成的面积即为模型的AP 值。基于图10 的对比分析,可以看出,相较于基线YOLOv7,本文方法对应的PR曲线呈现出相对平稳的特征,且表现出较为卓越的检测性能。
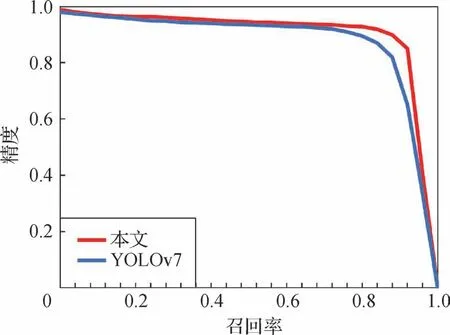
图10 改进前后PR曲线对比Fig.10 Comparison of PR curves before and after improvement
为了进一步验证方法的检测效果,将改进方法与先进的目标检测算法SSD、Faster R-CNN、Reti⁃naNet、CenterNet、YOLOv4-Tiny 以及较新的FENDet、Tan(谭显东和彭辉,2022)方法在准确率、召回率、精度等方面进行比较,精度对比如图11 所示,可直观地看出,本文算法在训练150 epoch达到收敛且AP@0.5最高。
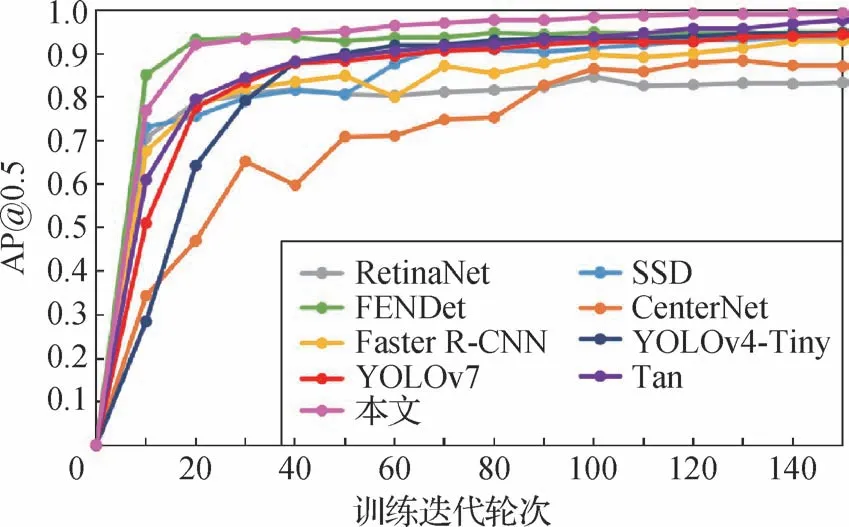
图11 各方法精度对比Fig.11 Comparison of average precision of each method
在SSDD 数据集上的检测结果如表2所示,对比各算法可以看出,本文方法取得了较好的检测精度,在SSDD 数据集上取得了最佳AP@0.5(99.25%)和AP@0.5∶0.95(71.21%),分别比基线YOLOv7 高4.38% 和9.19%;召回率为94.79%,比Faster RCNN 高16.18%;准确率为98.41%,比RetinaNet 高14.45%;本文方法的每秒浮点运算次数(floating point operation per second,FLOPs)为99.1 G,较基线低4.4 G,虽然Tan 方法召回率高于本文方法,但在其他指标上仍劣于本文方法,证明了本文方法的有效性。
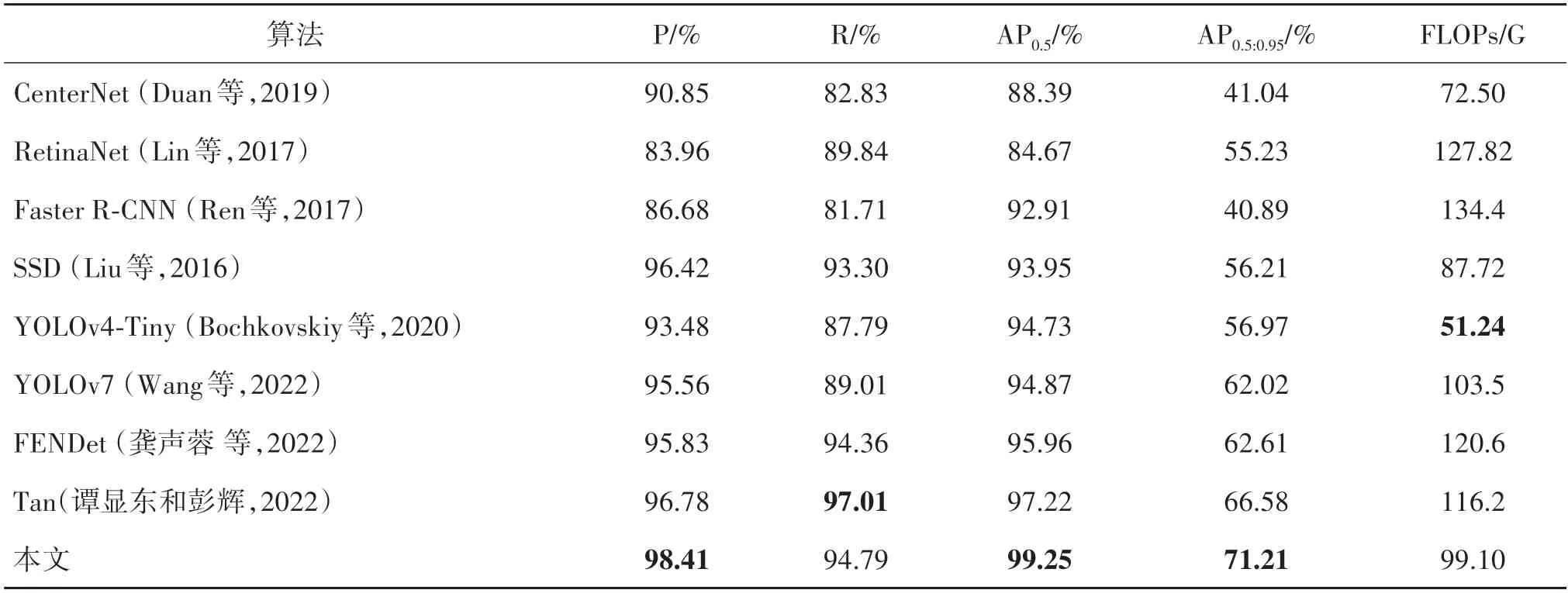
表2 不同检测算法在SSDD数据集上对比Table 2 Comparison of different detection algorithms on the SSDD dataset
为了进一步验证本文方法的有效性及泛化性,在HRSID 数据集上对比各算法的检测效果,如表3所示。可以看出,本文方法取得了最佳的AP(89.73%),比YOLOv7 高2.57%;准确率达到了93.24%;召回率为81.83%;F1为0.872。虽然Tan方法准确率略高于本文方法,但实验结果表明,本文方法的精度和运算量均优于Tan 方法,综合多种评价指标,本文方法效果最佳。
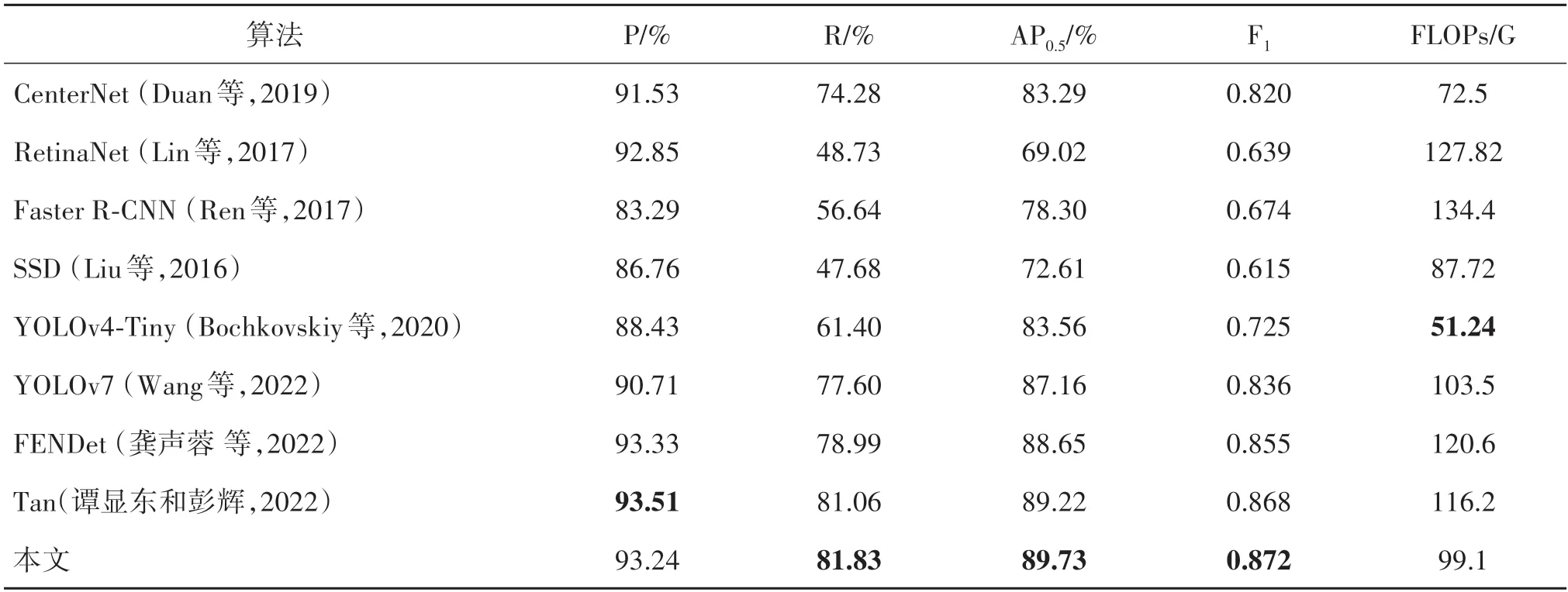
表3 不同检测算法在HRSID数据集上对比Table 3 Comparison of different detection algorithms on the HRSID dataset
为了更加直观地对比上述8 种方法,图12 展示了它们在SSDD 数据集上的检测效果图。其中,黄色框标识漏检舰船,误检舰船用绿色框标识。尽管各种方法都能有效地检测舰船目标,但RetinaNet、CenterNet、Faster R-CNN、SSD 所采用的主干网络泛化能力较差,提取出的目标特征不够完善,特别是在处理密集小目标舰船时,容易出现大量漏检现象。而本文方法通过在检测头处采用SPD 卷积,显著提高了小目标检测的准确率。

图12 不同方法检测效果对比Fig.12 Comparison of detection effects of different methods((a)ground truth;(b)CenterNet;(c)RetinaNet;(d)Faster R-CNN;(e)SSD;(f)FENDet;(g)YOLOv4-Tiny;(h)Tan;(i)YOLOv7;(j)ours)
YOLOv4-Tiny 和FENDet 在检测小目标舰船方面表现良好,但在复杂背景干扰下,对于密集排列且有遮挡的目标定位精度较低,导致漏检率、误检率升高。相较于这些方法,本文通过构建MLAN_SC模块和融入WIoU 损失函数,使网络对舰船目标的特征提取更为充分,定位更加准确,能有效区分重叠目标,从而提高了舰船目标的检测精度。
YOLOv7在模糊背景下的舰船检测中,受到海洋杂波的严重干扰,将复杂的近岸背景检测成舰船,误检严重。可以看出,本文构建的U-Net Denoising模块有效地抑制了复杂背景中噪声的干扰,基本没有产生误检。与此同时,Tan 方法通过改进网络,降低了漏检、误检情况,但无论在近岸复杂背景下还是在密集小目标舰船的检测中,本文方法融合多重机制,使得舰船目标的检测精度明显高于其他方法。
实验结果表明,本文方法在数据集的检测效果图上基本没有误检和漏检情况,在相对复杂的环境下,该方法能够降低误检和漏检概率,同时保持较高的检测精度。因此,本文方法的性能优于对比网络。
4 结论
为解决SAR 图像检测中精度低、漏检误检频繁的问题,本文提出了融合多重机制的SAR 图像舰船检测方法。该方法针对SAR 图像中舰船目标近岸复杂背景遮挡和密集小目标的分布特点,在YOLOv7 基础上融入了多重机制。首先,利用U-Net Denoising 模块抑制背景干扰。引入注意力机制和自注意力块构建MLAN_SC结构,加强特征提取和深层特征判别能力,有效地消除虚假目标的影响,减少误检和漏检情况。通过融合SPD 卷积和WIoU 损失函数以增强网络对小目标的敏感度。在SSDD 数据集与HRSID 数据集上进行实验,改进后的模型AP达到99.25%和89.73%,较对比方法具有更高的检测精度,对于近岸复杂背景和密集小目标舰船的检测效果较好。然而,本文方法在计算资源占用情况上也具有一定的局限性。未来研究可以考虑在提高检测精度的基础上使模型更加轻量化;探索将深度学习技术与传统图像处理方法相结合,进一步提高模型的可解释性和实际应用价值。
