面向图像内补与外推问题的迭代预测统一框架
2024-02-24郭冬升顾肇瑞郑冰董军宇郑海永
郭冬升,顾肇瑞,郑冰,董军宇,郑海永*
1.中国海洋大学信息科学与工程学部,青岛 266100;2.山东浪潮科学研究院有限公司,济南 250101
0 引言
图像内补与外推问题源自数据采集时受到环境遮挡、设备视野限制等带来的图像信息不全面,以及传播过程中图像受损、人为涂抹、添加遮挡等造成的图像内容不完整。这些问题严重影响图像理解及视觉效果,高质量的内补与外推将大大降低图像的认知难度,也有助于为图像理解等后续视觉任务提供完整丰富的数据基础。其中,图像内补(image inpainting)指利用图像内部缺失部分的邻域信息和已知区域整体信息,根据视觉合理性原则对图像中缺失区域进行补充;图像外推(image outpainting)指依据图像已知区域,对图像边界外的内容进行延伸推理与绘制,扩大观察者的感知视野。图像内补与外推方法广泛应用于计算机视觉任务中,如视野扩展(Zhang 等,2013;Wang 等,2014;Shan 等,2014)、纹理合成(Li 和Wand,2016;Xian 等,2018;Slossberg等,2019)、图像编辑(Zhu等,2016;Barnes等,2009)、对象去除(Liu 等,2018;Liu 等,2022;Yu 等,2019)等。
近年来,图像内补(Xiong 等,2019;Sagong 等,2019;Yu 等,2019;Nazeri 等,2019;Ren 等,2019;王倩娜和陈燚,2022)与图像外推(Wang 等,2019;Teterwak 等,2019;Guo 等,2020)方法大多直接将子图像输入到卷积神经网络(convolutional neural net⁃work,CNN)中,通过学习数据集知识合成整幅图像。对图像内补来说,未知区域一般所占面积较小且位于图像内部,因图像相邻像素之间的强相关性,通过卷积未知区域周围的像素可以完成内补缺失像素的问题,这种思路及方法在图像内补任务上可以得到不错的表现(Pathak 等,2016;Yeh 等,2017;Yu 等,2018;Liu 等,2018;Xie 等,2019;强振平 等,2019;Li等,2020)。然而,对于图像外推问题,未知区域通常面积较大且位于已知区域外部,具有可用信息少、合成面积大的特点,使得图像外推任务趋向于难度更大的图像生成问题。因此,当前图像内补与外推方法难以互相适用,图像内补方法较难完成绘制周边大范围未知区域的情况,而图像外推方法也难以处理各种不同形态已知区域的情形(Wang 等,2019;Teterwak等,2019)。
事实上,图像内补与外推本质上都可看做根据已知区域绘制未知区域的问题,从这个角度可以构建解决两个问题的统一框架,进而提升方法通用性。然而,两个问题统一考虑进行处理将带来已知区域形态更加复杂的困难,相对于独立解决内补或外推问题具有更大的挑战性。具体来说,已知区域形态复杂导致语义、纹理等信息更难识别,并且根据已知区域合成真实合理的不同大小、不同形状和不同位置的未知区域内容更加困难。这两个难点要求深度学习模型具备良好的表征已知区域特征、预测未知区域内容以及合成重建整幅图像的能力。表征已知区域特征即识别与提取已知区域有效信息;预测未知区域内容即根据已知区域特征对未知区域部分进行预测;合成重建整幅图像即将预测的未知区域特征映射到图像空间以获得目标图像,其中预测未知区域内容是解决图像内补与外推问题的关键。这3种功能构成当前深度学习模型设计过程,例如两阶段图像内补方法(Xiong 等,2019;Ren 等,2019;Nazeri 等,2019;Li 等,2019;Dong 等,2020)中,首先通过表征和预测来生成一幅辅助图像,如先生成一幅完整的模糊结果、边缘图像、结构图或语义图等,再将此过渡图像合成最终结果。可以说,多数基于深度学习的图像内补与外推方法都隐式地将表征、预测与合成3 部分功能涵盖在网络设计中。在此类网络中,表征主要由卷积神经网络(CNN)编码器实现且相对独立,用于将已知区域映射到特征空间,预测及合成过程主要由后续网络如CNN 解码器实现,这两个过程往往不加区分。考虑到模型在同时解决预测及合成问题时所面临的训练难度必然比单独面对其中任意一个更大,因此将预测与合成进行功能分离并分而治之有望提升图像内补与外推性能。
由于CNN 在解决计算机视觉问题上表现突出,目前图像内补与外推方法通常构建CNN 模型来解决。然而这种方式存在一定的局限性,主要源于CNN 的固有归纳偏置,即局部相关性和空间不变性,前者只能关注到卷积核视野内的空间元素,后者导致不同空间位置的局部空间建模能力受限,无法有效地捕获空间上长距离的关系。因此,对图像内补与外推的预测阶段来说,CNN 归纳偏置对于大范围未知区域建模能力较弱,特别是对于图像外推问题,CNN 仅能利用已知区域边缘处少量信息进行预测,卷积可利用的信息随着外推距离增大而减少,难以有效完成高质量外推。
相较于采用CNN 预测未知区域内容,Trans⁃former(Vaswani 等,2017)因其强大的远距离关系建模能力更具优势。Transformer首先应用于自然语言处理(natural language processing,NLP)领域,近两年作为一种新型网络结构进入计算机视觉领域。如今,Transformer 已被证实在许多计算机视觉问题上成为可替代CNN 的基础网络结构,如图像识别(Dosovitskiy 等,2021)、目标检测(Carion 等,2020;Zhu 等,2021)及低层图像处理(Chen 等,2021;Guo等,2022)问题等。与CNN 不同的是,Transformer 不存在局部相关性与空间不变性归纳偏置,且具备强大捕捉远距离上下文关系的能力。然而,Trans⁃former 在预测问题中大多采用基于自回归的思路(Chen 等,2020),此类方法虽然可解决根据已知区域像素预测未知区域像素的问题,但在如图像外推问题中存在大量像素缺失的情形下,逐个像素预测的方式必然占用大量时间与计算资源。相对于采用自回归的方式,诸如自编码器等可用于图到图合成的网络结构可能更适合高效解决图像内补与外推问题。因此,本文采用自编码器架构并引入Trans⁃former 并行预测的方式来尝试统一解决内补与外推问题。然而,面对大面积未知区域的情况,根据少量已知信息较难准确地同时预测未知区域内容。针对此情况,在并行预测过程中,本文提出掩膜自增策略分散大面积未知区域,将同时预测全部区域拆分为迭代递进预测过程,使得每次预测区域面积相对变小,且可利用前次预测内容作为本次预测依据。通过这种方式,降低了大面积未知区域预测难度,进而提高预测准确性。
综上,本文将图像内补与外推问题的解决过程显式地分解为表征、预测和合成3 个阶段,基于三阶段根据分而治之思想提出CNN 表征合成联合Trans⁃former 迭代预测的统一框架及模型。其中,表征阶段采用CNN 编码器实现,基于Liu 等人(2018)提出的部分卷积法(partial convolution,PC),更好地处理已知区域边缘信息;预测阶段设计Transformer 编码器,配合坐标信息根据已知区域特征预测未知区域特征,并提出掩膜自增策略进行迭代预测;合成阶段使用由残差块与上采样交叠构建的CNN 解码器,将预测特征最终映射为完整图像。
本文主要贡献包括:1)分解图像内补与外推过程并分而治之,提出联合CNN 与Transformer 的框架,统一解决内补与外推问题;2)设计Transformer迭代预测未知区域内容,提出掩膜自增策略,降低同时预测所有未知区域特征难度;3)在多种数据集上进行实验验证,实验结果表明所提模型在内补与外推问题上取得良好效果。
1 统一框架整体架构
按照分而治之思想,图像内补与外推过程可分解为表征、预测和合成3 个阶段。据此,本文构建了图像内补与外推统一框架,表征与合成阶段分别由CNN 编码器与CNN 解码器实现,预测阶段设计Transformer 编码器完成,这样构建了Transformer 与CNN 自编码器联合的网络架构。统一框架整体架构如图1所示。

图1 图像内补与外推统一框架整体架构Fig.1 The architecture of our unified framework dealing with both image inpainting and image outpainting
表征和合成可分别看做图像空间到特征空间以及特征空间到图像空间的映射过程。其中,CNN 编码器将输入的已知区域图像降维到特征空间,特征尺寸为输入图像的1/8 大小。为避免未知区域无效信息引入,表征阶段采用部分卷积替换常规卷积来处理已知区域与未知区域边界信息。另外,在每一层部分卷积后,采用像素归一化方法(Li等,2019)平衡不同位置特征数值,使所有送入预测阶段的特征具有相同数据分布,以便于更充分的模型训练。特征到图像映射过程CNN 解码器采用多个残差块与上采样间隔构成,通过正切函数转换为像素数值输出合成图像,并在最后引入判别网络提升模型性能。
预测阶段是整个模型的核心,此阶段采用Transformer 编码器来设计实现,主要功能为根据所有已知区域特征并行预测未知区域。由于Trans⁃former 设计适用于处理一维序列数据,进出Trans⁃former 编码器的一维数据需与二维特征需要进行转换。考虑到Transformer 处理的维度不宜过大,在进入预测过程前将特征通过1×1 卷积由512 降维到256 维。预测时设计了掩膜自增策略迭代预测未知区域特征,降低并行预测难度。
2 特征迭代预测过程
利用Transformer强大的远程上下文关系建模能力是解决未知区域特征预测问题的关键,下面阐述本文提出的Transformer并行特征预测方法与掩膜自增策略。
2.1 并行特征预测
采用Transformer 处理图像内补与外推问题时,需要将二维数据表示为一维序列数据进行输入,每个序列元素称为令牌(token)。针对图像内补与外推问题,可将涵盖未知区域位置的原始输入按照像素顺序依次排列,以此便可转换为一维序列数据,此时在序列中每一个token由一个像素构成,未知区域像素可填充特殊值加以标注。然而,将图像按照像素转换为一维序列的方法将使得进入Transformer的序列长度过长,如分辨率为256 × 256 像素的图像按照像素拉伸为一维序列之后的长度为65 536,由于Transformer 的计算复杂度是令牌数量的平方,其不仅需要大规模算力,同时也使得模型难以挖掘像素之间的相关性特征。因此,为避免转换后一维序列过长,通常将原始图像降维到特征空间或将图像按照图像块拆分,两者本质上都是将图像中某一区域转换为一个令牌,不同的是,相对于直接将原始图像拆分为多个等大的图像块,降维到特征空间的方法可以进一步提取图像特征。在图像内补与外推问题中,模型通常需要首先解析已知区域内包含的内容,因此本文采用将图像降维到特征空间的方式,之后通过Transformer进行未知区域特征预测。
图2 为本文框架中Transformer 在图像内补与外推任务中进行特征预测的结构图。图中,左侧为输入与输出的二维特征,输入特征未知区域位置使用空白表示(白色方块),通过Transformer 预测特征后填补上空白位置得到输出。在进入Transformer编码器前,输入的二维序列特征将按照从左到右、从上到下的顺序展开,转换为一维序列形式。序列中每个元素为一个令牌,与令牌相应位置编码相加后送入Transformer 编码器进行运算。Transformer 编码器采用N层自注意网络,通过额外的掩码(mask,见图2)对未知区域位置进行标注,使自注意层仅使用已知区域特征预测未知区域,防止未知区域无效信息的引入。

图2 基于Transformer的特征预测结构Fig.2 Feature prediction based on Transformer
本文用I表示输入的特征矩阵,用Ο表示输出的特征矩阵,则此预测过程可以表示为
式中,ψ代表由二维数据转换为一维数据的函数;ψ'代表由一维数据转换为二维数据的函数;TRE(Transformer encoder)表示Transformer 编码器;E表示位置坐标向量,根据特征数量提前设定;M为下采样到与I相同大小的二维掩膜矩阵,使用0标注未知位置,使用1标注已知位置。
通过这种方式可对所有未知区域特征同时进行预测,每个未知区域位置特征都由已知区域所有特征共同预测而来。随着网络层数的加深,已知区域与未知区域关系将被挖掘更深,有助于提升特征预测的准确性。此过程中,位置编码弥补了二维特征转换为一维序列时受损的位置信息,帮助网络提取特征中的二维空间关系,起到不可或缺的作用。
然而,此方案在面对大面积未知区域预测时较为困难,同时进行特征预测固然可降低算力与时间消耗,但仅使用少量已知区域特征预测大量未知区域特征会导致预测准确性降低。因此,下面介绍掩膜自增策略,通过迭代预测的方式有效降低特征预测难度。
2.2 掩膜自增策略
为降低同时预测所有未知区域特征的难度,本文提出掩膜自增(mask growth,MG)的方式迭代预测特征。在预测过程中Transformer编码器将被循环使用,根据预测掩膜指定的未知位置进行每一轮迭代预测。迭代过程中,掩膜将逐步打开未知区域预测位置并指定下一轮迭代预测位置。通过这种迭代预测的方式,每轮仅需预测一部分未知区域,可以避免同时预测大量未知区域特征难点。另外,迭代预测可以利用已预测的未知区域特征进行下一迭代的预测,有助于提升预测准确性。
如图3所示为相邻两轮迭代预测过程。在第1轮中,掩膜只开放部分预测位置,图中掩膜部分白框为开放位置,红色叉号框表示关闭的预测位置;第2 轮中,掩膜将上一轮中关闭位置打开相邻位置继续预测,直到所有未知位置预测完毕。
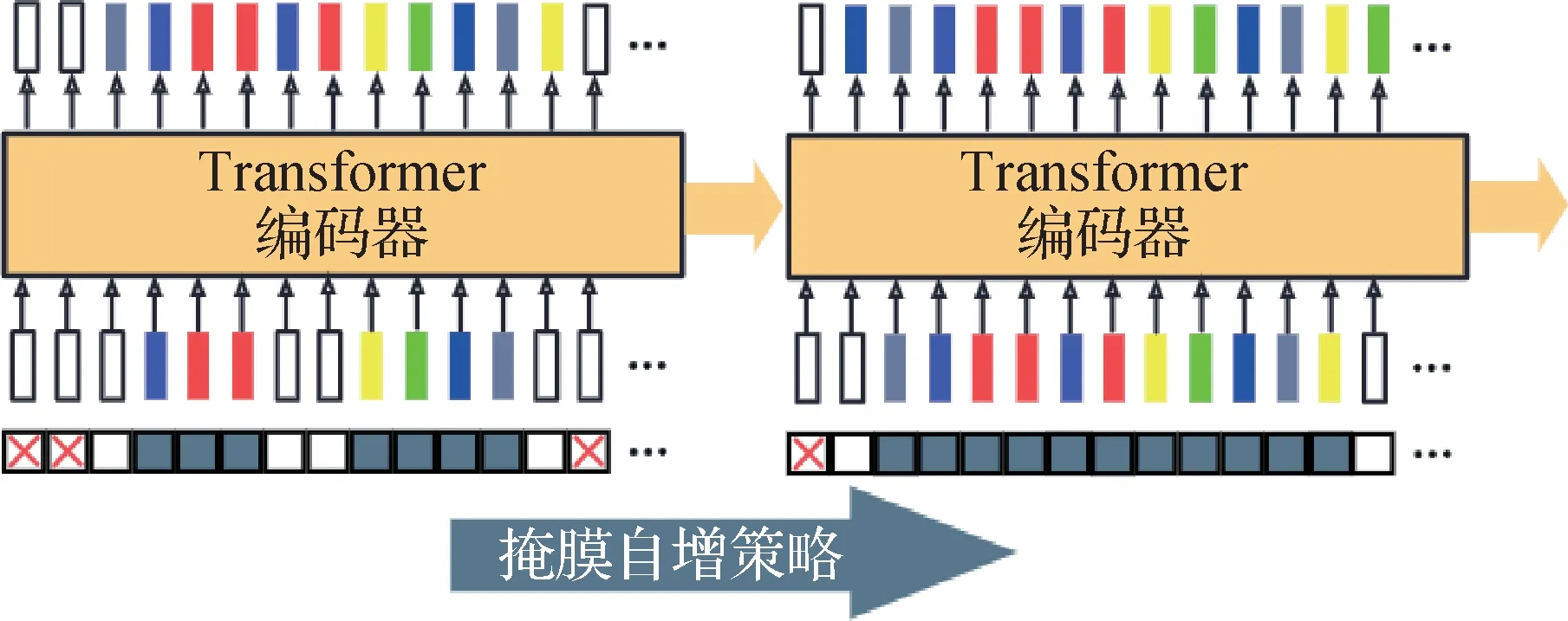
图3 采用掩膜自增策略的迭代预测过程Fig.3 Iterative prediction process using mask growth strategy
在掩膜自增策略中,除了原有标注已知区域与待预测区域位置掩膜M(掩膜中0 标注未知区域,1标注已知区域)外,引入预测掩膜Mp用于标注预测位置(使用0 标注不预测位置,1 标注预测位置)。预测前,使用全1 卷积核对初始位置掩膜M1进行卷积,当卷积结果大于0 时,将该位置标注为1,标注结果即为首轮预测掩膜。进入下一轮时,将前轮预测掩膜赋值给位置掩膜M2继续预测操作,以此类推,直到预测掩膜所有位置均等于1 为止。此过程即
式中,m′表示卷积结果,其将由卷积核标定的邻近区域计算数值表示卷积核视野内的掩膜矩阵。通过这种方式,可引入图像邻近区域强相关性先验,从而利用图像相邻像素强相关的特性。在整个掩膜自增过程中,每轮掩膜自增均在已知区域临边区域进行扩张。实施中默认采用大小为9 × 9的卷积核,观察卷积位置四周临近4 像素区域,若存在已知区域则该位置被标注为待预测区域。
引入掩膜自增策略后,第1 轮特征预测过程表示为
式 中,M1为初始二维掩膜,为M1经过全1 卷积标注的预测掩膜。第2 轮时,位置掩膜Μ2由第1 轮的预测掩膜赋值,即Μ2=,重复式(3)即可输出第2 轮预测结果O2,以此类推,直至预测完毕。
3 实现细节与损失函数
CNN 编码器由3 个步长为2 的部分卷积层组成,每一卷积层之后均后接像素归一化层,最后通过1 × 1 卷积降维到256 维度。预测过程中,Trans⁃former 编码器默认使用4 头6 层的配置。CNN 解码器由5个残差块和3个上采样相间组成,最后接一层正切函数输出到图像空间。对抗损失使用判别网络计算,具体采用多尺度判别网络(Isola 等,2017)实现。CNN编码器、Transformer编码器、CNN解码器和判别网络均使用Adam 优化器(Kingma 和Ba,2017)进行训练,所有网络均采用学习率α=0.000 1 训练,优化器参数设置为β1=0.0和β2=0.9。
整个网络采用3 种损失函数作用到最终的内补与外推输出,包括对抗损失、重建损失和感知损失。
3.1 对抗损失
网络训练时采用判别器D进行优化,用于判断整幅输出图像W与真实图像G的差异,对抗损失函数为
式中,Ladv表示对抗损失函数,EG与EW分别表示对输出图像W与真实图像G求期望;F为该网络表示函数,在训练中被约束为最小化此损失;而D则在训练中被约束为最大化此损失,二者训练中形成对抗。
3.2 重建损失
重建损失通过最小化W与G的距离实现,计算为
式中,LL1表示重建损失函数。
3.3 感知损失
网络采用感知损失来惩罚输出图像与真实图像间的感知差异,通过预训练分类网络激活层距离差计算,具体为
式中,Lprec表示感知损失,Nu是网络第u层的元素总数,σu是第u层的激活图。实施中使用预训练VGG-19(Visual Geometry Group)分类网络获取各层激活图。
3.4 完整损失
整个网络完整损失为以上各损失之和,具体为
式中,λadv、λL1及λperc用来平衡不同损失函数的权重,实验中参考语义重构网络(semantic reconstruction network,SRN)(Wang 等,2019)及螺旋生成网络(spi⁃ral generative network,SpiralNet)(Guo 等,2020)方法进行初始设置,然后在实验中不断调整,得到效果较佳的超参数,最终设置为λadv=0.1,λL1=6,λperc=10。
4 实验结果与分析
实验首先将所提模型在图像内补与外推问题上分别与当前最好方法进行比较,检验模型在两个任务上的表现。之后在图像外推问题上进行消融实验,分析分解模型设计、掩膜自增策略和Transformer结构参数等有效性。性能对比实验涵盖多个数据集与情形,消融实验在多类别花类图像数据集上进行比较分析,因为该数据集可以较好地观察预测准确性。
4.1 实验配置
4.1.1 数据集
实验使用对象类中人脸数据集CelebA-HQ(CelebFaces Attributes Dataset-High Quality)(Karras等,2018)与花类图像数据集Flowers(Nilsback 和Zisserman,2008),以及场景类中多类别场景数据集Places2(Zhou 等,2018)与城市街 景Cityscapes(Cordts 等,2016)来开展实验。其中,图像内补对比评测使用人脸数据集及多类别场景数据集;图像外推对比评测采用以上4 种数据集,分别对四周外推、双边外推及单边外推3 种情形进行评测。图像内补使用掩膜数据集(Liu 等,2018)进行测试,对每幅测试图像使用随机挑选的10 幅掩膜图像进行遮盖,作为已知区域输入到不同对比方法计算平均指标。数据集训练与测试样本数量划分见表1。在训练及测试过程中,图像内补与四周外推图像均等比缩放至256 × 256 像素,双边及单边外推图像等比缩放至512 × 512像素。
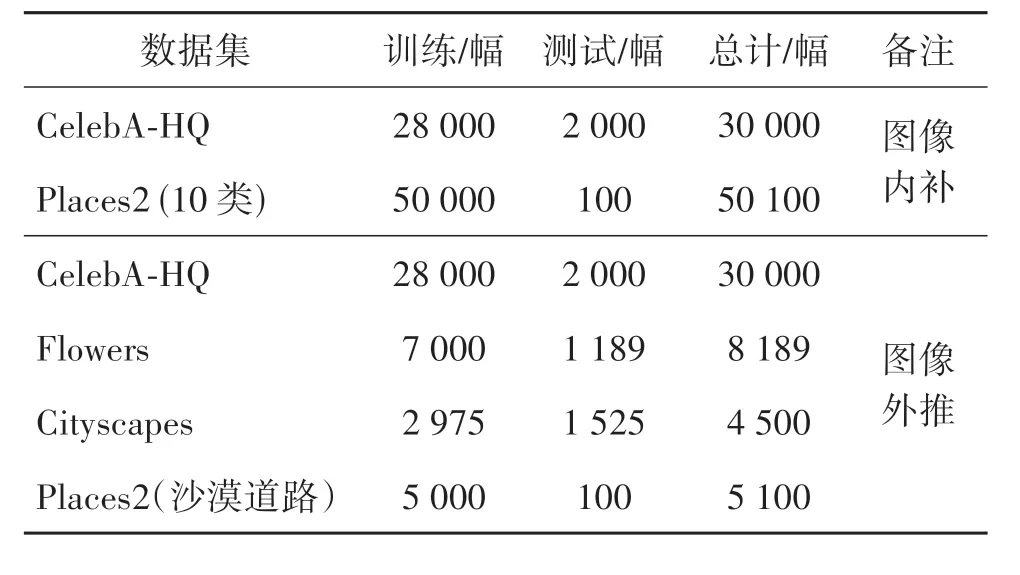
表1 训练及测试数据集划分Table 1 Training and testing dataset split
4.1.2 对比方法
实验选取目前常用和先进的内补与外推方法进行对比,分别为用于图像内补问题的部分卷积法(partial convolution,PC)(Liu 等,2018)、门卷积法(gated convolution,GC)(Yu等,2019)、特征均衡交互编解码器法(mutual encoder decoder with feature equalizations,MEDFE)(Liu 等,2020)及基于图像块的非量化Transformer 法(patch-based un-quantised Trasformer,PUT)(Liu 等,2022);用于图像外推问题的语义辨别网络(Boundless)(Teterwak 等,2019)、语义重构网络(semantic reconstruction network,SRN)(Wang 等,2019)及螺旋生成网络(sprinal generative network,SpiralNet)(Guo 等,2020)。外推方法中Boundless 仅适用于单边外推情况,因此对比方法增加MEDFE(mutual encoder decoder with feature equal⁃izations)用于四周外推情况,其余方法不受限于外推类型。
4.1.3 评价指标
参考前人工作(Yu 等,2019;Liu 等,2020),内补对比实验使用全面的评价指标来对实验结果进行测评,具体为峰值信噪比(peak signal to noise ratio,PSNR)、结构相似度指标(structure similarity index measure,SSIM)、Fréchet 感知距离(FID)、平均绝对误差(mean absolute error,MAE)和均方误差(mean square error,MSE)。外推对比实验采用峰值信噪比(PSNR)、结构相似度指标(SSIM)、Fréchet 感知距离(Fréchet inception distance,FID)以及图像感知相似度指 标(learned perceptual image patch similarity,LPIPS)(Zhang等,2018)作为评测指标。其中,PSNR与SSIM 数值越大代表模型性能越好,其余指标数值越小代表模型性能更优。为了更直观展示指标差异,对SSIM、LPIPS、MAE 及MSE 指标数值均放大100倍。
4.2 实验结果
4.2.1 图像内补
图像内补实验在人脸数据集CelebA-HQ 和场景数据集Places2 上开展,表2 与图4 展示了所提方法与其他方法的对比结果。由表2 可以看出,本文方法在各个指标上均超过其他方法,表明基于Trans⁃former的迭代预测模型具有更好性能。
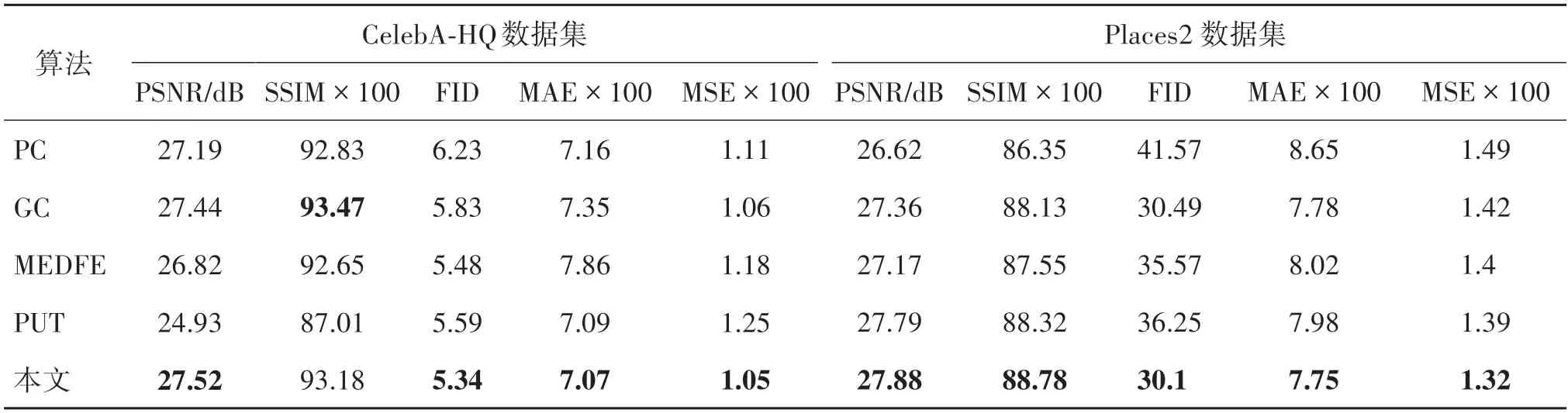
表2 图像内补定量对比实验结果Table 2 Quantitative comparison of image inpainting

图4 图像内补定性对比实验结果Fig.4 Qualitative comparison of image inpainting((a)input images;(b)PC;(c)GC;(d)MEDFE;(e)PUT;(f)ours;(g)ground truth)
如图4所示为各方法的视觉对比结果示例,图中前两行为CelebA-HQ 人脸数据集示例结果,后两行为Places2数据集示例结果,首列为输入子图像,图中最后一列代表对应的真实图像(ground truth,GT)。从图中人脸眼部位及大坝区域可以明显看出本文方法合成结果更加真实,并且没有明显涂抹痕迹。
4.2.2 图像外推
图像外推实验中四周外推情况使用人脸数据集CelebA-HQ 与花类图像数据集Flowers 进行对比,两边外推情况使用城市街景Cityscapes 数据集进行评测,单边外推情况使用场景数据集Places2 沙漠道路场景图像评测。表3 展示了在不同数据集上不同指标不同外推情况的定量评测结果。结果表明,所提方法相对于其他方法在指标上基本均有所提升,证明方法具备更好性能。
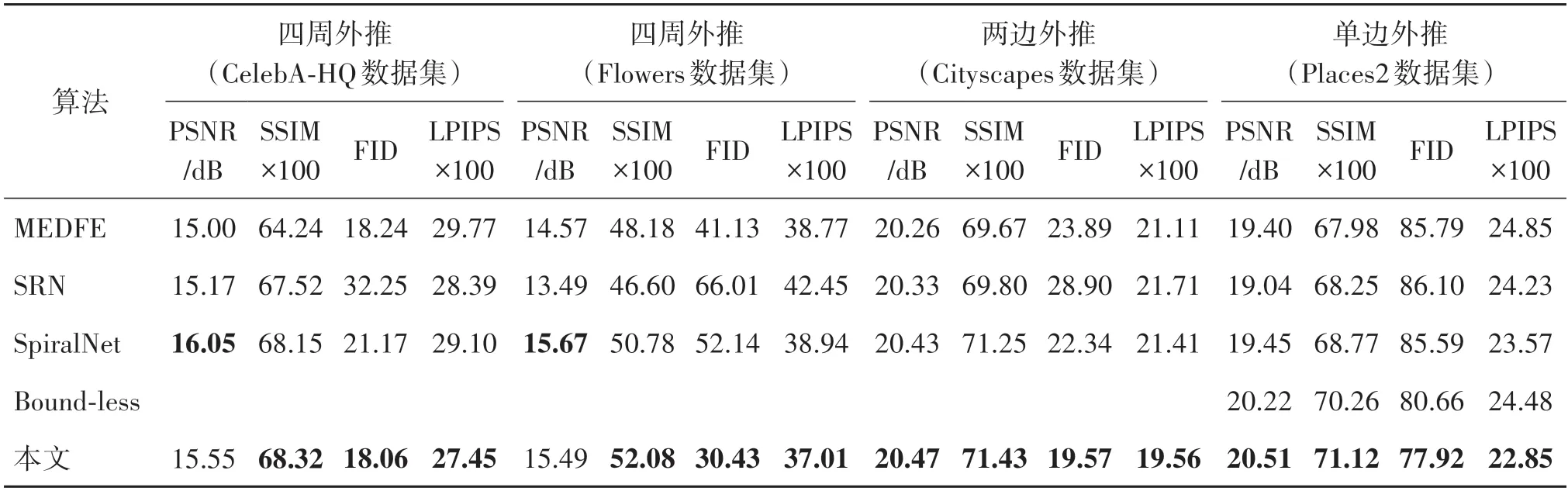
表3 四周、双边及单边外推定量对比实验结果Table 3 Quantitative comparison of four-side,two-side and one-side image outpainting
图5 为四周外推视觉对比结果,首列为输入图像,前两行为CelebA-HQ 人脸数据集示例结果,后两行为Flowers 数据集示例结果。从人脸图像背景及花瓣区域可以明显看出,其他方法出现明显扭曲及杂乱内容,相比较,本文方法结果更加真实合理,无杂乱情况。

图5 图像四周外推定性对比实验结果Fig.5 Qualitative comparison of four-side image outpainting((a)input images;(b)SRN;(c)SpiralNet;(d)ours;(e)ground truth images)
图6 为两边外推视觉对比结果示例,图中红框表示已知区域,红框左右两侧为外推区域。从中可以看出,本文方法两边外推区域更加合理,建筑物、草地等真实性更高,较其他方法效果更好。

图6 图像两边外推定性对比实验结果Fig.6 Qualitative comparison of two-side image outpainting((a)SRN;(b)SpiralNet;(c)ours;(d)ground truth)
图7 展示了单边外推视觉对比结果示例。由图中可以看出,其他方法容易产生混乱、扭曲的内容,SpiralNet 在单边外推问题上存在块效应,而本文方法单边外推结果语义清晰、内容真实,表现最佳。

图7 图像单边外推定性对比实验结果Fig.7 Qualitative comparison of one-side image outpainting((a)input images;(b)Boundless;(c)SRN;(d)SpiralNet;(e)ours;(f)gound truth)
4.3 框架结构消融实验分析
本节对分而治之思路进行消融实验分析,本文三阶段网络分别对应表征、预测与合成3 个过程,实验中依次去除每个过程网络以分析其作用,另外增加仅使用Transformer 预测阶段网络的实验。具体为:
1)移除表征过程(without encoder,w/o EN),即移除CNN 编码器,使用Transformer 与CNN 解码器构建网络,此时针对Transformer的输入,采用直接将原输入图像拆分为8 × 8图像小块的方法,每一个小块通过相同的线性变换由8 × 8 × 3 维转换为256 维,通过这种方式无需调整网络结构;
2)移除预测过程(without Transformer encoder,w/o TRE),即移除Transformer 编码器,使用CNN 解码器直接连接CNN 编码器,这种情形下,预测过程将由CNN解码器实现;
3)移除合成过程(without decoder,w/o DE),即移除CNN 解码器,在这种情形下,使用一层转置卷积对Transformer输出直接将特征映射为图像;
4)移除表征与合成过程(without encoder and decoder,w/o EN &DE),即仅使用Transformer预测过程,没有CNN 编码器与解码器进行表征与合成过程,在此情形下,使用拆分图像块经过线性变换作为输入,以及使用转置卷积输出到图像空间;
5)保留3 个过程(with all processes,w/ all),即本文方法。
对比实验指标结果如表4 所示,从中可以看出,缺少任一部分网络,其性能都将大大降低。其中,对缺失CNN 编码器的情况(w/o EN 与w/o EN &DE),PSNR 及SSIM 指标下降明显,预测准确性降低,表明不使用CNN 编码器而采用图像小块进入Trans⁃former编码器的方式预测难度加大。在缺失CNN 解码器的情况(w/o DE与w/o EN &DE)下,合成的图像FID 与LPIPS 指标明显较差,说明输出图像不真实,表明在没有CNN 解码器的情况下,通过Transformer完成特征到图像的映射具有相当的难度。最后,不使用Transformer进行特征预测的情况(w/o TRE)下,各项指标均不理想,表明难以进行准确合理预测。
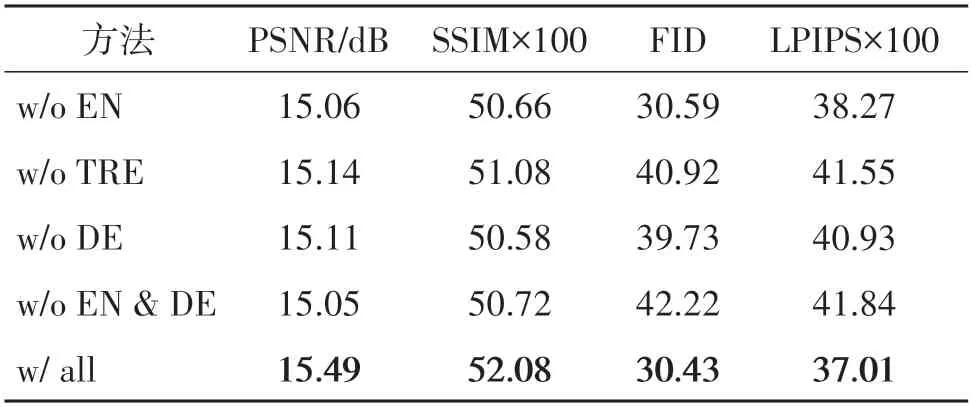
表4 框架结构消融实验定量结果Table 4 Quantitative results of ablation study on framework structures
实验视觉结果示例如图 8 所示,其中第1 列红框表示输入的已知区域。由图8 中可以看出,不使用CNN 编码器的情况(w/o EN 与w/o EN &DE),合成的花瓣不准确(可见第1行上侧花瓣与第3行下侧花瓣),表明CNN 编码器的引入可以帮助Trans⁃former更好地进行预测。在不使用CNN 解码器的情况(w/o DE 与w/o EN &DE)下,输出图像明显模糊,表明CNN 解码器可以起到良好的特征到图像的映射作用。而没有Transformer 进行预测过程的情况(w/o TRE)下,输出图像无法形成合理的花类图像,即难以合理地合成真实图像。在3 部分过程网络都使用的情况(w/ all)下,合成结果最为真实合理。

图8 框架结构消融实验定性结果Fig.8 Qualitative results of ablation study on framework structures((a)w/o EN;(b)w/o TRE;(c)w/o DE;(d)w/o EN &DE;(e)w/ all;(f)ground truth images)
4.4 掩膜自增策略有效性分析
掩膜自增(MG)策略可以迭代地进行特征预测,降低单次预测大面积未知区域的难度,并可利用前次预测未知区域辅助后续特征预测。在此有效性分析中,首先剥离掩膜自增策略而直接使用Trans⁃former 单次对未知区域特征并行预测;然后通过调整掩膜自增策略中使用全1 卷积核尺寸调整需迭代的次数,分析不同迭代次数情况下的外推性能差异。具体如下:
1)无迭代:不使用掩膜自增策略,令Transformer单次并行预测完成未知区域特征预测;
2)2 轮:调整全1 卷积核为17 × 17,此时最多需要2轮迭代完成所有未知区域特征预测;
3)4 轮:调整全1 卷积核为9 × 9,此时最多需要4 轮迭代完成所有未知区域特征预测,该配置为默认方案;
4)8 轮:调整全1 卷积核为5 × 5,此时最多需要8轮迭代完成所有未知区域特征预测。
指标统计结果如表5 所示,从中可以看出,不使用掩膜自增迭代特征预测(无迭代)的情况下各项指标均表现较差。在使用不同次数迭代预测中,适中的迭代次数(4 轮)可以有效提升各项指标,过多(8 轮)或过少(2 轮)的迭代次数均会导致指标降低。这是由于Transformer并行特征预测能力与预测特征数量息息相关,过高将降低预测准确性,过低将可能使前轮次产生的预测错误在后几轮中得以扩大。需要说明的是,本节实验使用4头8层的Transformer结构,在此配置下,4 次迭代的结果相较更好,如若更换其他配置则需根据Transformer 的能力进行适当调整。

表5 掩膜自增策略有效性分析定量实验结果Table 5 Quantitative results of the analysis on mask growth strategy
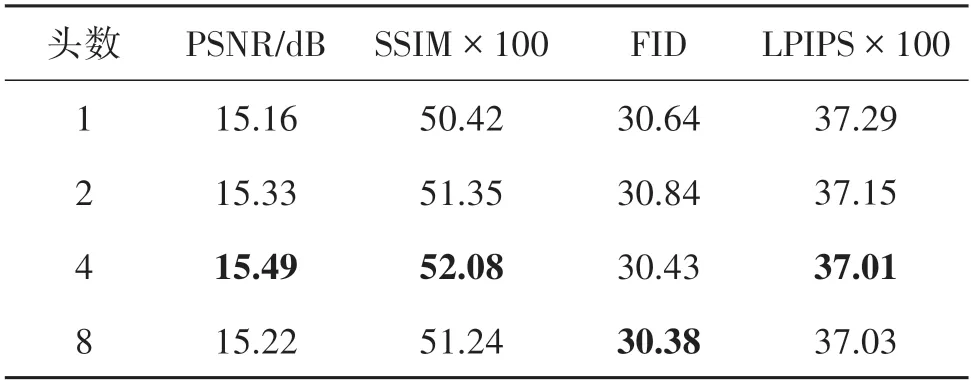
表6 不同头数对Transformer性能影响定量实验结果Table 6 Quantitative results of different head numbers on Transformer
实验视觉结果示例如图9所示,第1列红框表示已知区域。由图中可以看出,不采用掩膜自增迭代特征预测的情况下,预测结果容易产生过度与不合理的结果(见图中第1 列第1 行中下方花朵过度延伸)。过大的迭代次数(8 轮)也可能产生预测结果不合理的情况,而适中的迭代次数(4 轮)则可以进行合理的图像合成。

图9 掩膜自增策略有效性分析定性实验结果Fig.9 Qualitative results of the analysis on mask growth strategy((a)without MG;(b)2 iterations;(c)4 iterations;(d)8 iterations;(e)ground truth)
4.5 Transformer结构参数分析
头数(head)与层数(layer)是Transformer 基本的结构参数,在此实验中使用不同头数与层数进行比较分析,采用固定层数变换头数与固定头数变换层数两种固定变量方式进行。实验具体设置为固定8 层网络结构对1、2、4、8 头数进行对比,以及固定4头对2、4、6、8层数进行对比。
固定8 层Transformer 编码器,采用不同头数的定量对比实验结果如表 6 所示,由表中数据可以看出,使用较大的头数(如4 头或8 头)指标较好,说明将特征分解到不同子空间对未知区域预测来说起正面作用,能够更充分地学习特征间关系。比较4 头与8 头的指标可以看出,过大的头数导致性能略微降低,该现象可能由于头数过大降低了特征的表征能力,从而导致特征预测难度增大,进而导致预测性能降低。
不同头数对Transformer影响的实验视觉结果示例如图10 所示,其中第1 列图中红框表示输入已知区域。图中可以看出,头数过少(1 或2 头)或过多(8 头)都容易产生合成结果不连续的情况(可见第1行已知区域左侧边界位置,花朵难以延伸出去),而适中的4 头可以达到更好的视觉效果,说明头数过少或过多都可能加大Transformer特征预测难度。

图10 不同头数对Transformer影响定性实验结果Fig.10 Qualitative results of different head numbers on Transformer((a)1 head;(b)2 heads;(c)4 heads;(d)8 heads;(e)ground truth)
固定采用4 头Transformer 编码器,采用不同层数的定量对比实验结果如表7 所示。表中可以明显看出,各项指标结果随着层数的增加而提升,本文实验的默认配置选取8 层作为基础配置,以平衡网络复杂度与合成的效果。

表7 不同层数对Transformer性能影响定量实验结果Table 7 Quantitative results of different layer numbers on Transformer
不同层数实验视觉结果示例如图11 所示,可以看出,随着层数加深对花瓣的预测更加细致,如第1行红色花朵与第2 行黄色花朵已知区域下侧花瓣,更多的层数可对挖掘更深的自注意关系起到正向作用,帮助更好地预测特征。考虑到效率问题,本文实验中最多采用8 层作为Transformer 层数,可以预见更深层数的情况下预测效果会有进一步提升的空间。

图11 不同层数对Transformer性能影响定性实验结果Fig.11 Qualitative results of different layer numbers on Transformer((a)2 layers;(b)4 layers;(c)6 layers;(d)8 layers;(e)ground truth images)
5 结论
针对图像内补与外推问题统一处理带来的已知区域复杂性问题,本文提出一种迭代预测统一框架予以解决。其中,本文将内补与外推两个问题的解决过程统一分解为3 个阶段分而治之。针对已知区域表征、未知区域预测及图像合成3 个问题,分别构建网络结构,使模型各部分各司其职、优势互补。其中,已知区域表征采用CNN 编码器,引入部分卷积与像素归一化降低未知区域无效信息引入;未知区域预测是本框架的核心,本文采用Transformer 编码器并行特征预测实现,并提出掩膜自增策略迭代特征预测方法,有效降低并行预测大面积未知区域特征难度;图像合成采用CNN 解码器实现,其以多个卷积残差块与上采样间隔组成,该残差网络结构可降低模型优化难度。
本文通过大量对比实验验证了三阶段分而治之思路的有效性,在多种常用数据集及指标上均明显优于其他方法,表明本文方法取得了先进性能。消融实验中,本文方法验证了三阶段设计均对性能提升有所贡献,显示了迭代预测统一框架及方法在图像内补与外推问题上的应用价值。此外,对迭代预测次数、Transformer网络关键参数的分析实验表明,适中的迭代次数、Transformer 头数及较多的Trans⁃former 层数可进一步提升框架性能,此结论可为各类应用场景提供参考。
本框架的核心是三阶段的网络结构设计与基于Transformer 的迭代预测方法,该思路尚属于初步探索阶段,未来将在任务广度、性能优化等方面深入研究,扩展本文方法的适用范围及模型性能。此外,本文实验主要在图像场景单一、数量较少的数据集上分别进行训练与测试,此方式虽然可以较好地对比评估不同方法性能,但在实际应用中,无法直接应用于复杂场景下的图像内容,因此,如何提高模型适用范围,特别是如何借鉴基于大型数据集的自监督学习技术,使模型具备更强的图像表征能力及多样图像特征预测能力,进一步提升模型鲁棒性,具有非常高的实用价值。
