杂乱场景下小物体抓取检测研究
2024-02-24孙国栋贾俊杰李明晶张杨
孙国栋,贾俊杰,李明晶,张杨
湖北工业大学机械工程学院,武汉 430068
0 引言
随着深度学习技术的快速发展,数据驱动方法应用在机器人技术上展现出巨大的发展潜力,非结构化环境下对未知物体的抓取受到了许多研究者的关注。根据抓取形式可以将抓取分为平面抓取和六自由度抓取。平面抓取限制摄像机必须垂直地观测场景,在杂乱和带有约束的场景中可能会导致抓取失败。相比之下,六自由度抓取没有设置额外的抓取约束,直接从观测的场景中预测抓取配置,近年来应用于非结构化环境下对未知物体的抓取。最近一些基于学习的六自由度抓取工作(Mousavian 等,2019;Sundermeyer 等,2021;Fang 等,2020;Ma 和Huang,2022;Wang 等,2021;Lu 等,2022;Gou 等,2021)展示出良好的抓取表现,但从数据中学习场景中的抓取分布过程仍然存在问题,在小物体上的抓取检测表现较差。
学习小物体上的抓取配置是十分具有挑战性的工作。首先,由于原始点云数据量巨大,为了减少网络的计算复杂度和提高检测效率,需要对场景中的点进行下采样,而先前的采样方法在小物体上采样点较少,导致小物体抓取姿势学习困难。此外,目前市场上的消费级深度相机存在严重噪声,尤其在小物体上获得的点云质量不能保证,虽然一些方法试图通过点补全(Yuan 等,2018)和去噪(Rakotosaona等,2020)来缓解这个问题,但在未知物体上进行点云补全是不可靠的。这些方法都不能泛化到现实场景中的未知物体上,导致网络难以分辨小物体上的像素点属于前景还是背景,一些可行的抓取点被误认为是背景点,进一步削减了小物体上的采样点数量。采样点不足导致网络在小物体上的抓取配置在学习过程中被忽略,因此预测的抓取姿势的数量和质量都表现较差。
针对以上问题,本文建议在训练时对小物体采样足够的点,保证学习过程能够关注到小物体上的抓取分布,在推理时引入一个辅助分割网络获取场景中的物体掩码,然后平等地对待每个物体,采样相同的点以保证小物体上的抓取配置数量充足,其中引入未知物体实例分割网络还能提高对未知物体抓取的泛化性能。先前的方法预测抓取配置时在局部点云上使用固定尺寸的圆柱体分组策略,由于大小物体的尺寸存在显著差别,提取到的特征是不够明确的,因此本文提出多尺度分组策略提取局部点云下不同大小尺寸内的特征信息,整合为物体级别的点云信息,取得了更好的抓取性能。最后,在现实世界中测试了所提方法针对小物体和未知物体的抓取表现,达到较优的抓取效果。
本文的主要创新和贡献包括:1)提出掩码辅助采样方法和推理阶段引入未知物体实例分割网络,提高在小物体和未知物体上的抓取检测表现。2)提出多尺度分组学习策略增强局部点云的抓取形状表示,能够有效提高抓取检测质量。3)在大型基准数据集GraspNet-1Billion 上和现实世界中测试本文方法,大量实验结果表明该方法更具有优势。
1 相关工作
1.1 杂乱场景下的抓取检测
先前的抓取检测方法按照抓取设置可以分为平面抓取和全六自由度抓取。平面抓取(Morrison 等,2018;Chu 等,2018;Xu 等,2022;闫明 等,2022)要求摄像机垂直地观测场景中的物体,输入物体的RGB或深度照片,输出一组平面内带有旋转的包围矩形框。Mahler等人(2019)通过使用物理和几何分析模型的领域随机化在合成数据集上进行训练,提高了平面抓取的准确率。然而,平面抓取由于自由度较低的限制,一些物体上的抓取姿势是不可靠的,例如垂直地抓取一个杯子在抓取过程中容易滑落,并且在杂乱的环境中受到碰撞干扰影响等容易导致抓取失败。相比之下,六自由度抓取设置灵活,能够预测更加丰富的抓取姿势。因此,近年来研究者们致力于研究六自由度抓取来实现通用物体抓取检测。
六自由度抓取检测主流的方法又可以分为两种。第1 种是基于判别的方法(Ten Pas 等,2017;Liang 等,2019;Fischinger 等,2015),这种方法采用抽样—评估策略,首先从场景中收集密集的抓取姿势,然后训练一个深度神经网络对抓取候选人评估打分,推理阶段选择评分较高的抓取候选人作为可行的抓取姿势。Mousavian 等人(2019)提出了一个基于变分编码器的采样—评估网络,抓取采样器网络首先对部分对象点云上可能的抓取姿态进行采样,并由抓取评估器根据其梯度进行迭代细化。
另一种是基于学习的方法(Sundermeyer 等,2021;Fang 等,2020;Wang 等,2021;Ni 等,2020),这种方法采用端到端的学习策略,网络直接输出场景中物体的抓取配置。Fang 等人(2020)提供了一个具有统一评价系统的大规模抓取姿态检测数据集GraspNet-1Billion,为研究者们提供了一个基准数据集以供训练和评估算法。GSNet(graspness-based sampling network)(Wang 等人,2021)提出了一种基于几何线索的质量,可以在混乱的场景中超前搜索可抓区域的方法,进一步提高了抓取检测质量。Ma和Huang(2022)通过引入干净和带噪声的混合增强点云数据,并设计平衡物体尺寸的损失函数提高了在小物体上的抓取检测质量。然而,先前的方法在杂乱场景中的小物体上的抓取检测效果仍然较差。本文为了进一步提高在小物体上的抓取检测质量,在训练阶段引入掩码辅助采样方法,并使用多尺度学习策略增强物体局部几何表示,缓解小尺寸物体学习困难问题,获得了更好的表现。
1.2 点云学习
机器人抓取检测方法的发展离不开点云学习领域的进步,例如Qi 等人(2017a)首先提出了一种基于点的多层感知机(multilayer perceptron,MLP)方法PointNet(point network)(Qi 等,2017a)和后续改进版本PointNet++(Qi 等,2017b),实现了深度网络直接输入3D 点云学习场景中的点云信息,为后面许多基于点云的数据学习方法提供了基础。此外,还有一些基于卷积的方法(Wu 等,2019;Li 等,2018)对经典的卷积网络进行推广,从点云中学习特征。基于Transformer 架构的PT(point transformer)(Zhao等,2021)和Guo 等人(2021)通过更好地捕获点云中的局部上下文,在点云检测和分割领域获得了更好的效果。在本文中,需要从RGB-D 相机中获取的场景点云数据中学习物体的可行抓取姿势,因此采用了学习能力较强的PT 方法,并且借鉴了PointNet++中对局部点云的多尺度学习策略,以提高通过局部点云预测抓取操作参数的能力。
2 方 法
本节将介绍提出的六自由度抓取检测算法,图1 是算法的流程图。类似于先前的方法(Ten Pas等,2017),本节首先定义对物体的抓取表示方法,然后介绍提出的掩码辅助采样和多尺度学习方法,最后设计一个端到端的抓取网络嵌入了提出的采样和学习方法以预测物体抓取姿势。
2.1 抓取姿势表示
基于学习的六自由度抓取算法从带有抓取标注的数据集中学习物体上的抓取分布并扩展到未知物体上,因此良好的抓取姿势表示有利于网络学习到合理的抓取分布。图2 为抓取姿势表示,点O为夹爪坐标系原点,O′点为抓取点,网络预测接近向量V,夹爪围绕轴R的平面内旋转角度,抓取深度D和夹爪打开宽度w。抓取姿势用相机坐标系下夹具的旋转、平移和夹具的打开宽度共同描述,用数学式表示为

图2 抓取姿势示意图Fig.2 Schematic diagram of grasping pose
式中,R∈R3×3表示夹爪在相机坐标系下的方向,t∈R3×1为夹爪中心位置,w∈R 表示夹爪的打开宽度。直接用神经网络回归这些参数是非常困难的,因此,本文遵循先前的工作(Fang等,2020;Wang等,2021),将夹爪的旋转量分解为视角分类和面内旋转预测。视角分类是在相机坐标系下以抓取点为中心的球面区域内选取多个视角,预测这些视角的抓取分数以获得合适的夹爪接近物体方向的向量,即通过分类代替回归降低了神经网络对抓取分布学习的难度,从而得到了更合理的泛化表现。遵循这一定义,提出的网络也针对性地设计了3 个模块,包括可抓点预测模块、接近方向预测模块和夹爪操作预测模块。
2.2 掩码辅助采样
先前的抓取检测方法(Fang 等,2020;Wang 等,2021)存在一个潜在问题,即没有考虑场景中物体尺度差异带来的有偏差的采样点分布,从而导致小物体上的采样点较少。此外,由于相机存在噪声,尤其在小物体上的点云质量较差,网络预测的点的物体性不明确,导致采样点进一步减少。
本文建议使用掩码辅助采样来解决这一问题,具体来说,与基准方法(Wang 等,2021)一样,首先预测场景中的可抓点,这些点是由力闭合分析(Nguyen,1988)计算得到的分数较高的点,抓握时只要关注在这些点上的抓取就能覆盖物体上大部分可行的抓握姿势,详细的定义在GSNet(Wang 等,2021)中可见。然后在训练阶段直接获取场景中的物体掩码,由于输入的点云是有序点云,通过物体掩码可以索引到点云中对应的物体点,解决了点的物体不明确性问题。本文从掩码中去除背景点,剩余的点每一个都分别对应一个物体点,随后在场景中共采样M个点,每个物体上采样相同的点以消除物体尺寸差异影响。如图3所示,使用均匀采样方法得到的采样点主要集中分布在大物体上(高亮的绿色点代表采样点),几乎忽略了像螺钉、小刀这样的小尺寸物体,而通过本文提出的掩码辅助采样方法可以明显改善由物体尺度差异带来的采样点分布不均衡问题,有利于网络进一步学习小物体上的抓取姿势。

图3 采样方法比较Fig.3 Comparison of sampling methods((a)uniform sampling;(b)mask-assisted sampling)
2.3 多尺度学习
先前的方法(Fang等,2020;Wang等,2021)仅用一个较大半径圆柱体采样种子点附近的点,对不同尺寸的物体的局部区域采样是模糊的。多尺度分组采样已经被证明能够更好地提取局部点云特征(Qi等,2017b)。在抓取检测中,采样种子点的局部特征对预测夹爪操作参数至关重要,因此本文使用多尺度分组学习进一步提高抓取检测质量。
具体来说,如图4 所示,本文设置了3 个半径分别为r、0.65r和0.3r的圆柱体,其中r为夹爪的最大打开宽度,分别对应学习大尺寸、中等尺寸和小尺寸物体特征,然后将3 个尺度的特征进行拼接,对拼接后的特征进行自注意层处理,增强局部区域的注意,自注意层只专注于捕获区域范围的上下文信息,其详细信息可参考Zhao 等人(2021)方法。为了避免网络从零开始学习可抓点附近的局部区域特征,本文将上面的特征经过MLP 处理后与种子点特征相加作为局部区域特征,最后预测夹爪的各种操作参数。

图4 多尺度学习示意图Fig.4 Schematic diagram of multi-scale learning
2.4 端到端抓取网络
为了预测物体上的抓取姿势,本文设计了一个端到端的抓取网络,嵌入了提出的采样和学习方法。抓取网主要包括可抓点、接近方向和夹爪操作预测3部分。
2.4.1 可抓点预测
许多网络在预测抓取姿势时直接操纵场景中所有的点,然而从人类抓握经验来看,杂乱场景中物体上只有部分点可以作为可抓取姿势的中心点,抓握时只要关注在这些点上的抓取就能覆盖大部分可行的抓握姿势。GSNet(Wang 等,2021)通过预测可抓点引导后续抓取姿势预测获得了更好的性能,但预测的可抓点仍然受到物体尺度影响导致网络偏向于学习大物体上的抓取。本文进一步使用掩码辅助采样可抓点,能够使小物体也分布较多的可抓点,从而提高了小物体上预测抓取姿势的数量和质量。
2.4.2 接近方向预测
通过掩码均衡采样后的点被认为是杂乱场景下可抓取度较高的点,进一步预测这些点上的抓取姿势来尽量覆盖场景中可行的抓取。抓取的接近方向指夹爪中心轴接近物体的方向,由于物体间存在遮挡和考虑夹爪与场景中物体的碰撞,接近方向通常由场景和物体整体点的特征决定,因此在骨干网输出的包含场景整体信息的点的特征后连接输出头预测抓取的接近方向。具体来说,在点周围的单位圆上使用斐波那契网格采样(González,2010)生成V个方向的视角,由网络预测每个视角的得分,然后选择最高抓取分数对应的视角作为抓取的接近方向。
2.4.3 夹爪操作预测
获得可抓点的接近方向后,还要获得夹爪的一些必要的操作参数才能完成抓取,包括夹爪在垂直接近方向的平面内的旋转角度、夹爪抓取深度和打开宽度。这些操作参数通常与可抓点邻域的局部点分布特征密切相关,因此本文使用提出的多尺度学习策略学习精确的局部几何特征表示,输出尺寸为M×K×C的圆柱组点集特征。获得局部几何特征后,使用共享MLP 和最大池化操作对抓取候选集进行处理,最后使用MLP 输出尺寸为M×(A×D× 2)的抓取参数。其中,A代表平面内旋转角度,D为抓取深度,剩下的两维分别表示抓取分数和夹爪打开宽度,选择抓取分数排名较高的抓取作为杂乱场景下可信度较高的预测抓取姿势。
2.5 训练与推断
本文方法是端到端的,训练阶段采用多任务学习范式制定多任务组合损失函数,具体为
对应上面提到的网络组成部分,Lp,Lv分别代表可抓点预测、接近向量预测损失。Ls,Lw为夹爪操作预测中的抓取分数损失和夹爪打开宽度损失。所有的损失函数都采用回归任务中的Smooth L1函数计算,在计算Lp和Ls时只考虑在物体上的点,物体性由物体掩码显示指定,Lv只在采样的可抓点上计算。α,β和γ为超参数,用于控制不同损失间的大小比例。
训练阶段由于物体掩码已知,不存在点的物体性和可抓点采样模糊。而在推理阶段,由于没有对场景点级掩码的先验知识,需要引入一个额外的未知物体实例分割网络来区分场景中的物体。在本文的实施中,使用Xiang 等人(2021)方法预测的掩码确定场景中的点的物体性并在不同大小的物体上采样相同的可抓点。
3 实 验
3.1 实现细节
3.1.1 骨干网络
抓取姿势预测首先需要从杂乱场景的点云中学习整体和局部点特征,得益于基于Transformer 架构的网络在点云特征学习领域的优秀表现,本文使用PT(point Transformer)(Zhao 等,2021)作为骨干网络提取点特征输入输出头预测抓取姿势。
3.1.2 基准数据集与评估指标
GraspNet-1Billion 提供了一个大规模抓取姿态检测数据集,并为抓取姿态质量评估建立了统一评价系统。这个数据集由两个相机(Kinect 和Realsense)采集的190 个场景、256 个不同的视图共97 280 幅RGB-D 图像组成,包含超过10 亿个抓取姿势。测试场景根据对象类别(见过/相似/未知)分为3 个部分评估,系统通过分析计算(Nguyen,1988)直接报告抓取是否成功,能够评估多种类型的抓取姿势。由于数据集中的抓取姿势与现实场景较为吻合,本文方法在这一数据集下训练和评估。为了公平对比各种方法,统一使用在GraspNet-1Billion中定义的评估指标APµ反映在设置摩擦力为µ下前50 个预测抓取姿势的平均精度(average precision,AP),其中µ设置为0.2~1.2,AP代表APµ的平均值,详细的设置在GraspNet-1Billion(Fang等,2020)中可见。
除了原数据集中对见过、相似、未知对象分类评估外,本文还研究了针对物体尺度的抓取质量评估。具体来说,与Ma 和Huang(2022)的方法类似,根据抓取物体时夹爪的打开宽度,将不同物体划分为小物体、中等物体和大物体,设置0~4 cm、4~7 cm、7~10 cm分别为小尺度、中尺度和大尺度,最后分别使用APS、APM和APL评估在小尺度、中尺度和大尺度物体上抓取姿势的质量。对于场景中的每个物体,选取排名前10 的抓取进行统计,设置µ=0.8 表示抓取成功,使用与GraspNet-1Billion中相同的力闭合评估指标评估各个方法对于不同尺寸物体的抓取精度,详细的设置在Ma 和Huang(2022)提出的评估指标中可见。
3.1.3 参数设置
原始的GraspNet-1Billion 没有提供点的可抓性得分,本文遵循GSNet中的设置,密集标注每个点来自300 个不同视图的抓取质量分数,每个视图包含48 个抓取,即12 个平面内旋转角度和4 个抓取深度类别组合。在网络流程上,骨干网络输出C=256维的特征向量,用于预测可抓点的MLP 尺寸为(256,1),在所有可抓点中选择M=1 024 个种子点,每个种子点采样V=300 个视角打分,预测接近方向的MLP 尺寸为(256,256,300,300)。在圆柱体分组中,设置多尺度圆柱体半径分别为r=0.05 m,0.65r,0.3r,高度范围为[-0.02 m,0.04 m],选择K=16 个种子点预测夹爪操作参数,最后,网络输出A=12 个平面内旋转角度与D=4 个抓取深度类别组合,共48 类的抓取分数与抓取宽度。在损失函数中,设置超参数α=β=γ=10。
3.1.4 训练与推断
本文模型是基于深度学习框架Pytorch 实现的,在单张Nvidia GTX 3090Ti 上使用Adam 优化器训练了18 轮。批大小设置为4,批归一化初始动量设置为0.5,训练时每隔两轮动量衰减一倍。初始学习率设置为0.001,学习率分别在第8、12、16轮衰减为5E-4、5E-5 和5E-6,整个网络大均需要花费30 h收敛。
3.2 消融实验
为了验证本文方法有效提升小尺度和未知物体上抓取数量和成功率,对各个模块进行了消融实验,对APS、APM和APL进行评估,计算平均值来反映各个尺度上的抓取质量。如表1 所示,与之前的两种典型方法(GraspNet-1Billion基准方法和Ma以及Huang(2022)提出的针对小尺寸物体的抓取检测方法)分别在不同尺度的见过、相似和新颖物体上(“见过”代表测试集中的物体在训练集中出现过,“相似”代表测试集中的物体在训练集中未出现过但形状类似,“新颖”代表未出现过且具有很大差异)的抓取质量评估结果进行对比。结果表明,提出的方法在小物体上的抓取指标平均提升了7%,并在所有尺寸的物体上的抓取质量都有明显的改进。然后,分别设置了没有掩码辅助采样和多尺度学习策略的消融实验研究。结果表明,当取消了本文提出的这两种设置,提出的网络在所有指标上的评估结果都有一定程度的下降。由此可见,掩码辅助采样和多尺度学习策略能够帮助改善杂乱场景下物体的抓取检测质量。

表1 消融实验Table 1 Ablation study/%
3.3 结果可视化
为了更加直观地看到提出的方法在小物体上的抓取效果提升,将之前最具代表性的方法GSNet(Wang 等,2021)作为基准方法,可视化了4 个杂乱场景下基准方法和本文方法的抓取检测结果。由于GSNet 仅发布了使用Kinect 相机采集数据训练的网络,因此可视化这些方法的抓取结果是在Kinect 相机上转换的,而本文展示的结果是从RealSense 相机转换的,所以场景点云质量略有不同,但从RealSense 相机上采集的点云数据充斥着更大的噪声,理论上预测的抓取结果质量应当会更差。从可视化结果图5可以看出,GSNet方法倾向于预测场景中大物体上的抓取,在一些小物体上没有显示出合理的抓取姿势(图中用虚线圈出),而本文方法可以准确预测出小物体上的抓取姿势。此外,本文方法学习的是物体上的抓取姿势分布,对物体本身的形状和尺寸没有限定,适用于所有类型的物体,可视化结果也显示了对不同形状的小物体均预测出了合理的抓取姿势。

图5 物体抓取检测结果(使用Open3D(Zhou等,2018)可视化)Fig.5 Object grasping detection results(visualized using Open3D(Zhou et al.,2018))
3.4 与最新的方法比较
将提出的方法与之前代表性的一些方法进行了公平的比较,如表2 所示,所有的测试结果都是在GraspNet-1Billion 数据集上使用RealSense 相机采集的数据上评估得到的。与之前的方法相比,本文方法没有任何后处理手段,但仍在所有测试类别物体的AP指标上处于领先地位,尤其在训练集中未出现的相似和新颖物体上有明显提升。这表明提出的方法不仅改善了在小物体上的抓取检测质量,并且提高了在未知物体上抓取的泛化性能。
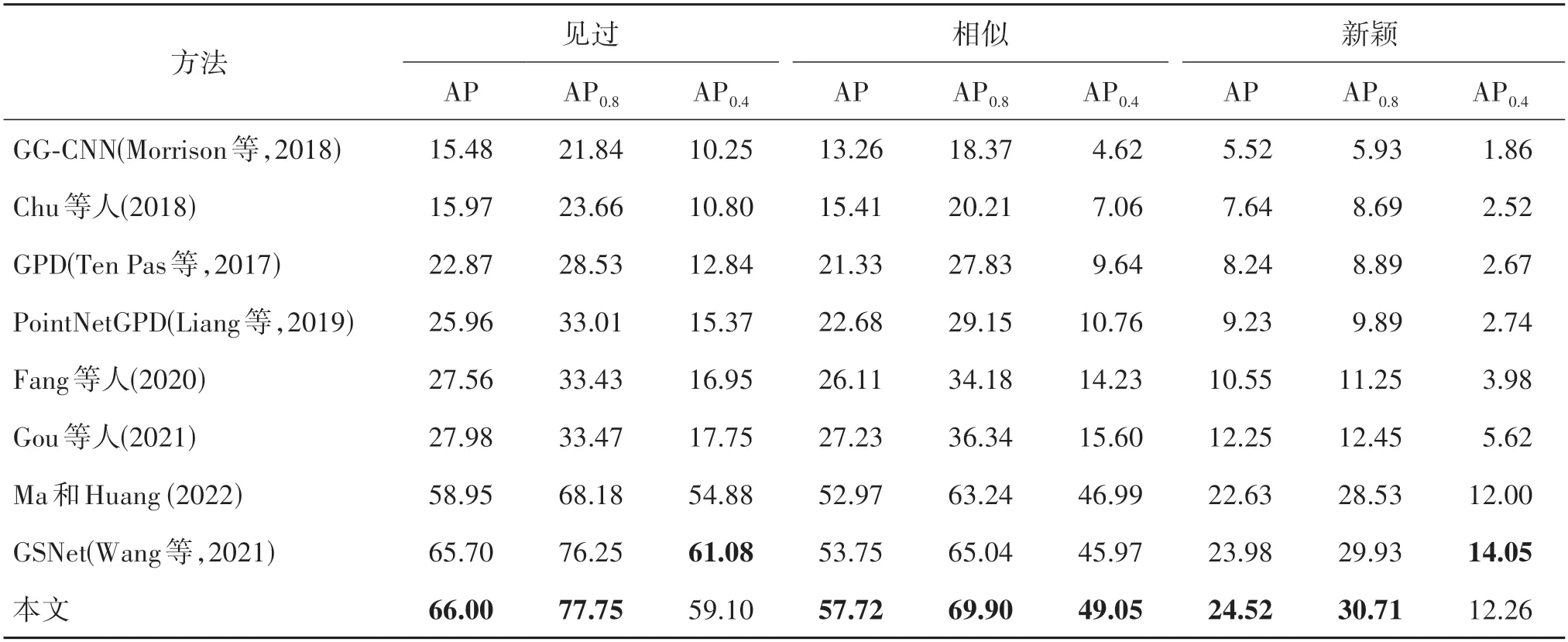
表2 与主流的方法比较Table 2 Comparison with state-of-the-art methods/%
3.5 真实抓取实验
为了验证本文方法的泛化性能,如图6 所示,在现实世界中设置了杂乱场景并进行抓取实验。抓取系统建立在一个搭载RealSense D435i相机和柔性电动夹爪的UR-5 机械臂上,上位机计算资源包括NVIDIA Quadro RTX5000 GPU 和Intel Core i7-9850H CPU。抓取物品包括生活中常见的物体和一些复杂形状的工业零件等共20 种不同尺寸的物体。

图6 现实抓取实验设置Fig.6 Realistic grasping experiment settings
实验中,成功抓取定义为将桌面上的物品抓起并放置到指定的盒子中,每次在桌面上摆放5 件包含各个类别尺寸的物体,夹爪在每个物品上仅有一次抓取机会,总共进行了30 组实验,共150 次抓取。最后,在表3 中报告了基准方法GSNet(Wang 等,2021)与本文方法在实验中的抓取结果,其中单独报告了在小刀和固体胶这种小物体上的抓取成功率以显示提出的方法针对小物体的抓取有效性,在总的抓取成功率上本文方法的表现也优于基准方法。在检测速度方面,本文方法预测每个场景中的全部物体的抓取姿势耗时大约0.12 s,采用的未知物体实例分割网络预测每幅图像的物体实例掩码耗时约0.25 s,因此完整预测流程耗时约0.37 s。

表3 真实抓取实验成功率Table 3 Real grasping experiment success rate/%
4 结论
本文聚焦于小物体上的抓取,提出了一种掩码辅助采样方法嵌入到提出的端到端学习网络中,并引入了多尺度分组学习策略提高物体的局部几何表示,以解决之前的方法中存在的由物体尺度差异引起的学习不均衡问题。通过大量的实验验证了本文方法无论是在广泛使用的数据集上,还是在现实世界的物体抓取实验中都具有优势,能够有效提升在小尺寸物体上抓取质量,并在所有物体上的抓取评估结果都超过了对比方法。
然而,本文方法也有一定的局限性,例如使用带噪声的低质量深度图作为输入时,现有的未知物体实例分割方法预测的物体掩码可能出现错误,导致掩码辅助采样方法失灵。在未来的工作中,准备研究更具鲁棒性的未知物体实例分割方法,能够修复低质量深度图输入下的错误分割结果,获得更加精确的物体实例掩码,提升在杂乱场景下的物体抓取检测能力。
