基于对齐自编码器的变压器声音异常检测研究
2024-02-22刘云辉王昕
刘云辉, 王昕
(上海交通大学 电子信息与电气工程学院 教学发展与学生创新中心,上海 200240)
0 引 言
变压器作为电网中不可或缺的设备,其安全稳定运行是电网可靠供电的重要保障[1]。在变压器运行维护过程中,因为声信号检测具有无电气接触、可实时在线检测等优点,受到了广泛关注[2]。声信号可用于变压器的异常检测,是进行故障识别和故障定位的基础,因而具有重要意义。
声音的异常检测方式包括基于统计量的检测、基于分类的检测和基于生成的检测[3]。基于统计量的检测比较正常序列和异常序列统计信息,实现简单,但检测效果受统计量区分度的影响较大;基于分类的检测一般是训练识别正常样本的分类器,通过划分正常样本边界来实现异常样本的检测;基于生成的检测通过学习正常样本来重新生成近似的样本,再利用模型无法很好拟合异常样本,从而可以检测出异常样本。对变压器声音异常检测而言,因为变压器发生故障概率极低,采集的声音是以正常信号为主,而异常声音所占的比例极小且人工标注的难度大,所以半监督学习和无监督学习是目前异常识别的主要的研究方向[4]。
作为无监督学习的一种,自编码器因为对数据有极好的拟合能力,常用于降维、特征提取和异常检测[5]。文献[6]借鉴了自编码器的结构,利用长短时记忆(long short-term memory, LSTM)网络代替了自编码器的编码器和解码器部分,但是LSTM网络计算量大,无法用于实时检测。文献[7]将两个自编码器串联构成新模型,提高了该模型的精确率、召回率和F1值,但仍没有解决自编码器的时间不敏感问题。
本文设计了一种对齐自编码器用来检测变压器声音异常。首先不同的分帧方式被提出并应用到训练集和测试集,增加了训练样本数量,也加快了检测速度;其次改进了自编码器的激活函数和损失函数,解决了自编码器训练慢和易受噪声干扰的问题;接着提出了对齐自编码器,减少了时延效应对检测精确性的影响;最后采集正常声音和异常声音,通过试验验证了对齐自编码器的有效性。
1 自编码器
基于声信号的变压器故障检测的检测精度依赖于异常声音样本的数量,为了减少获取异常样本的成本,有必要研究异常信号的自动检测。作为一种无监督学习网络,自编码器被广泛用在特征提取、信号去噪和异常检测等领域。
自编码器包括编码器和解码器两部分,设编码器的层数为N1,解码器的层数为N2,则有:
Z1=f(Xe1We1)
(1)
ZN1=g(XeN1WeN1)
(2)
Y1=f(Xd1Wd1)=f(ZN1Wd1)
(3)
YN2=g(XdN2WdN2)
(4)
式中:Xei、Wei、Zi(i=1或N1)分别为编码器第i层神经元的输入、权重和输出;Xdi、Wdi、Yi(i=1或N2)分别为解码器第i层神经元的输入、权重和输出;f(·)、g(·)为激活函数;f为LeakReLU或ReLU;g为Tanh。它们的表达式如式(5)、式(6)所示。
(5)
(6)
(7)
式中:x为神经元无激活函数时输出向量的值;α为激活函数调整参数,一般取0.01。
损失函数常选为均方误差(mean square error, MSE),但当输入存在离群点时,离群点对MSE的影响较大而导致模型对样本的预测存在较大偏差。为减小离群点的影响,结合MSE和平均绝对误差(mean absolute error,MAE)构成Huber损失函数,其定义如式(8)所示。
(8)
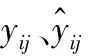
2 对齐自编码器
采集好音频样本后,会先将样本按照一定比例分为训练集和测试集。但是音频为长时间序列,不便于直接进行训练,常采用分帧的方式转化为短时序列。为了充分挖掘分帧的作用,训练集和测试集采用不同的分帧方式:训练集的相邻帧存在重叠,而测试集各帧不重叠。
自编码器训练时,训练样本一般需要打乱顺序,输入样本的起始值对网络的影响较小;而自编码器预测时,为了方便还原预测序列,输入样本一般不打乱顺序,这会对预测结果产生影响。基于上述分析,研究了预测结果中可能存在的时延效应,并改进自编码器形成对齐自编码器。
2.1 时延效应
因为变压器电压的变化会导致声音的异常,所以按照正弦波形式产生用标幺值表示的变压器电压作为正常样本,再将变压器常见的异常样本添加到正常序列中,模拟多种异常的发生。包含8种异常的时间序列如图1所示。

图1 包含8种异常的时间序列
图1中:序列的前一半为正常样本,当作自编码器的训练集;后一半为正常和异常混合样本,当作模型的测试集。测试集中包含8种常见的异常:过载、短暂掉电(电压暂升)、偶谐波畸变、电压高频闪变、轻载、电压低频闪变、短暂掉电(电压暂降)和奇谐波畸变。
先利用正常样本训练自编码器,然后预测带有异常的时间序列,输入序列、输出(预测)结果和预测误差绝对值的变化情况如图2所示。

图2 输入输出序列和预测误差绝对值
图2(a)和图2(b)中起始点的幅值不一样,因此预测序列很可能出现了时延效应。图2中第一种异常的局部放大图如图3所示。

图3 图2中第一种异常的局部放大图
图3中的黑框表示的是异常出现的位置,对比图3(a)和图3(b)的异常信号可知该信号的起始值明显不一样,这说明预测值确实存在一定的时延。即使输入序列中不存在任何异常,时延的存在会导致预测误差的绝对值较大,图3(c)的结果也证实了这一推测。
2.2 异常检出过程
自编码器预测时的时延效应会影响预测结果,因此通过序列对齐来实现对齐自编码器。序列对齐能够提高检测精度,但为了分辨正常和异常信号还需要规定异常检测的阈值,下面分别介绍序列对齐和异常检测阈值。
2.2.1 序列对齐
序列对齐的实现包括时延检测和预测序列反向延时对齐两个步骤。时延检测得到预测序列相对测试输入序列的时延,序列延时对齐则是利用估计的时延来反向移动拼接预测序列首末端的序列。为减少时延检测的计算量,先对测试序列和预测序列进行三电平削波处理,削波函数为:
(9)
式中:x为测试序列或预测序列的样本点;xT为电平选择阈值,默认取0.25。
确定削波函数后,时延修正的步骤如下。
(1) 利用削波函数将测试序列和预测序列转为值为-1、0、1的三电平序列。
(2) 计算转化后序列的时延,即测试序列超前或滞后预测序列多少采样点。
(3) 反向延时补偿预测序列。测试序列超前时,取预测序列尾端与超前采样点数相同长度的序列,序列反转后添至首端;测试序列滞后时,取预测序列首端与滞后采样点数相同长度的序列,序列反转后添至尾端。
(4)重新计算测试序列和预测序列的损失。
2.2.2 异常检测阈值
这里对异常信号作如下规定:设正常信号的均值为μ,标准差为σ,利用“3σ”准则对异常信号进行判断,即信号的幅值如果小于μ-3σ或大于μ+3σ就认为该信号为异常信号。实际操作过程中,将正常信号置0,异常信号置1,再检测异常信号的起止时刻得到最终的检测效果。
2.3 评价指标
为客观展示对齐自编码器的检出效果,指标定义如下:
(10)
(11)
(12)
式中:P为精准率;TP为将正例(异常声音)预测为正例的样本数;FP为将负例(正常声音)预测为正例的样本数;R为召回率;FN为将正例预测为负例的样本数;Fβ为综合评价指标,规定P或R值为0时,Fβ=0;β为权重系数,β=1时,P和R重要性相同,此时Fβ记为F1。式(12)简化为:
(13)
3 试验验证
为验证对齐自编码器的可行性,在实验室利用麦克风采集变压器正常声信号和少量异常声信号。正常声信号为20 s,先将正常声音按照3∶2 的比例分为训练集和测试集。训练集样本保持不变,将异常声音分段添加到测试集中来模拟异常的发生。分帧处理声信号时,分帧窗口取为20 ms,训练集各帧的重叠率为50%,测试集的帧重叠率为0。分帧结束后,训练集含1 199个样本,测试集含400个样本,两者的比例约为3∶1。
除了声音预处理方式,对齐自编码器的层数和每层神经元数目也会对异常检测的效果产生影响。为了避免神经元输入输出维数变化过大,采用逐层缓降维或缓升维的办法确定各层神经元的维数。编码器的神经元输入输出维数和激活函数如表1所示,解码器的神经元输入输出维数和激活函数如表2所示。
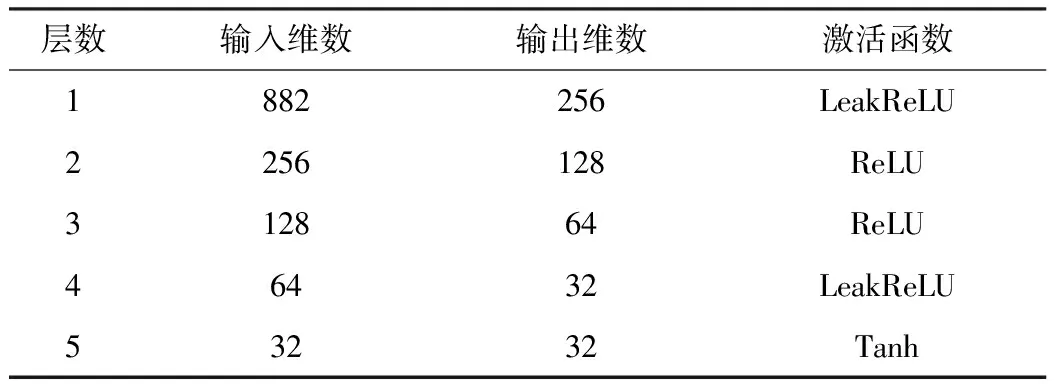
表1 编码器的神经元输入输出维数和激活函数

表2 解码器的神经元输入输出维数和激活函数
由表1、表2可知,编码器和解码器采用了对称的网络结构。对齐自编码器训练过程中误差的变化情况如图4所示。
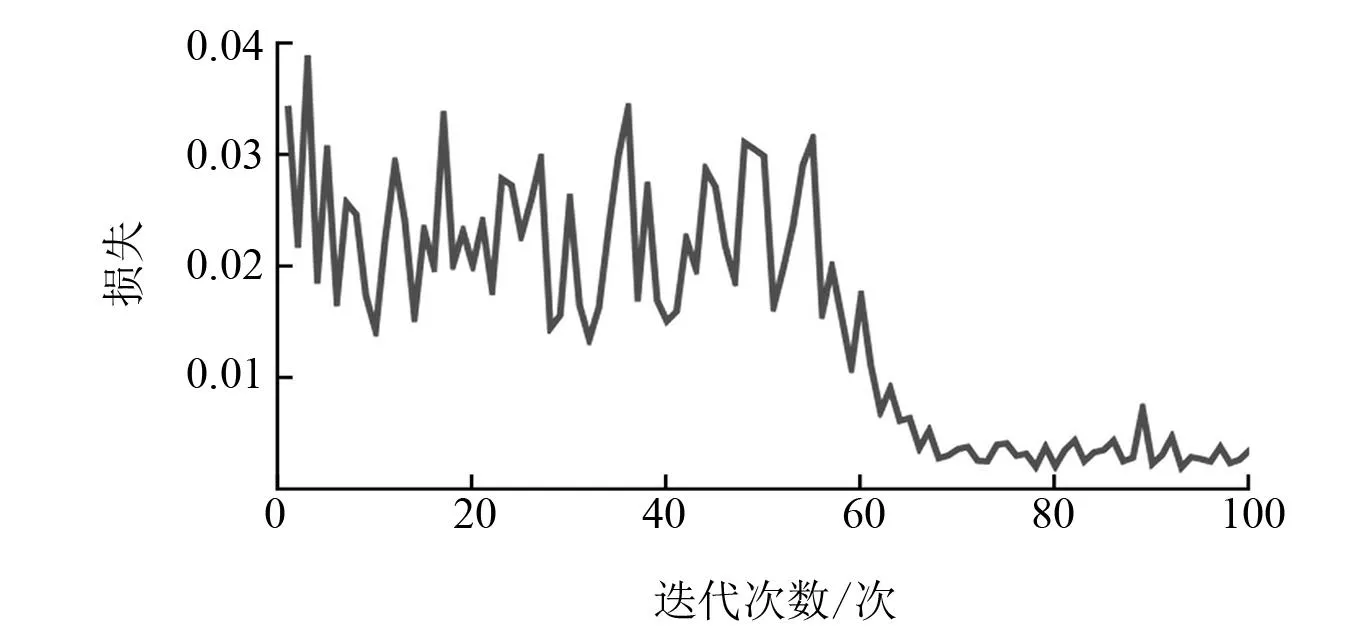
图4 训练误差随训练次数的变化情况
由图4可知,经过了70次左右训练误差就达到了预期效果。模型检测效果如图5所示。

图5 对齐自编码器检测异常声信号效果
图5(a)中声信号由黑框外的正常声信号和两段黑框框住的异常声信号组成:第一段异常声信号为变压器绕组短路的声信号;第二段为变压器过电压的声信号。图5(b)为声信号的预测值,由图可看出黑框中的异常声信号与黑框外的正常声信号存在幅值上的差异,图5(c)的图像也证实了这一点。利用正常声信号和异常声信号预测幅值的差异可以检测出异常声信号的起始时刻,检测过程如图6所示。
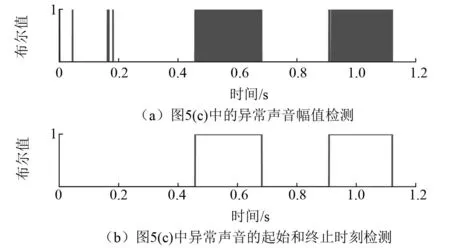
图6 生成信号异常检测过程
图6(a)中的信号只含0和1两种值,当图5(c)的信号在正常信号的“3σ”准则范围内,其值为0,否则为1。图6(b)显示的是异常声音的起始和终止时刻,其中忽略了太短的声音片段。确定起止时刻后,就可以利用评价指标来对比不同模型的异常检测效果,对齐自编码器和其他模型的评价指标计算值如表3所示。
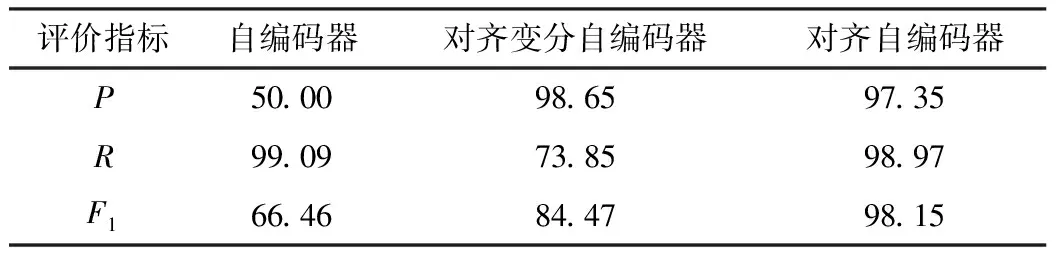
表3 对齐自编码器和其他网络模型的对比 单位:%
由表3可知,对齐自编码器的评价指标较为均衡,各项指标都超过了95%,检测效果优于其他模型,因而能够应用于实际的异常声信号检测。
4 结束语
本文研究了变压器声音的异常检测问题,主要讨论了自编码器结构、时延效应、序列对齐和异常信号的检测过程,结论如下:
(1) 变压器声音训练集和测试集提出了不同的分帧方式,训练集各帧重叠占比较高,增加了样本数量;验证集各帧无重叠,加快了预测速度。
(2) 训练模型改进了损失函数和激活函数,减少了噪声干扰的同时降低了训练次数。
(3) 提出了对齐自编码器,利用序列对齐方法构造了对齐自编码器,试验结果显示该模型的综合评价指标达到了98.15%。
