云制造下小批量定制产品的服务组合双层优选方法
2024-02-21袁伟,郭伟,2,王磊,马剑
袁 伟,郭 伟,2,王 磊+,马 剑
(1.天津大学 机械工程学院,天津 300072;2.天津仁爱学院 机械工程学院,天津 301636)
0 引言
随着信息化技术的发展,各行业也朝着数字化、网络化、智能化的方向前进,我国相继出台了“中国制造2025”和“互联网+”等发展实施战略,旨在促进新一代信息技术与制造业深度融合,推动实体经济转型升级[1-2]。而制造业与信息技术的融合则催生出了更多面向服务的新型制造模式,也将制造行业的焦点聚集在资源使用效率和共享程度问题上,为此李伯虎院士提出了一种网络化制造新模式——云制造[3-4]。云制造模式促进了制造行业整体资源的利用及合作共享,提高了制造企业的市场竞争力,而随着全球市场的发展以及客户多样化个性化动态化的需求扩大,小批量定制产品在市场上获得了越来越多的份额[5]。小批量定制产品能够让客户获得与自身需求相一致的准确产品,但个性化定制在商业运作原理上与大批量生产存在显著差异,其一般采用非标定制模式进行生产,导致制造成本高;而现有企业的生产系统、信息化管理方法以及所具备的生产能力都很难满足这种个性化生产的需要[6-7]。因此,结合云制造模式对小批量定制产品的生产制造进行需求任务的有效分解和制造资源的优选匹配成为了关键途径。云制造模式需同时协调需求方和供应方的相关信息,对于用户复杂的制造需求还需选择多个细粒度的简单云制造服务组合形成粗粒度的复杂云服务,因而云制造服务组合模型的构建及其求解算法决定了所选服务组合方案的优劣[8-9]。
目前,国内外学者已经对云制造模式下服务匹配的相关问题进行了大量研究。为解决云制造环境下拥有确定性子任务加工顺序的服务组合灵活性差的问题,郑炜等[10]提出用于描述加工顺序的工艺逻辑矩阵,将加工顺序交换机制加入算法中并建立基于双层蚁群算法进行求解的服务组合优选模型。针对云制造下服务组合如何满足供需双方偏好的问题,陈友玲等[11]建立了以服务需求方约束和资源提供方约束为基础的双方约束模型,并提出一种改进的快速非支配排序遗传算法进行求解;马仁杰等[12]提出一种基于区间和灰色关联度的云制造服务综合匹配推荐方法,对服务资源类型和质量信息等进行匹配和过滤。针对服务组合优选中的解空间大、求解效率低等问题,ZHOU等[13]构建了以时间、成本、可靠性和可用性为评价指标的评价模型,通过混合人工蜂群算法求解出最佳服务组合;BOUZARY等[14]基于灰狼优化器(Grey Wolf Optimization,GWO),通过更好的交叉变异探索能力提升求解的效率。针对云环境下制造服务供需匹配中双方的动态变化问题,XUE等[15]提出一种基于计算实验的评价框架来验证服务匹配策略性能,以提升服务匹配策略的适应性能力。针对云制造环境下资源组合的地域分散性强、供应复杂化等特征,朱李楠等[16]提出一种改进的差分进化算法,设计了一种最佳运输方案选择策略以解决资源组合的调度问题;王旭亮等[17]提出一种基于切削算法框架并适用于跨企业、多约束、多品种、小批量的有限能力调度算法,为供应链中供需企业的协同生产计划进行寻优,实现生产资源的优化配置。在面向云制造下服务商的供应选择上,SIMEONE等[18]针对服务方和需求方的多样化,建立了深度神经网络为客户提供决策推荐,实现服务匹配中的供应优选。
以上研究聚焦于云制造下的服务组合优选模型和求解算法,在模型上大多选择将多目标优化问题转化为单目标优化问题,在算法层面依靠不同的启发式算法及变异操作提高求解的速率。然而,这类处理一方面忽视了候选集的产生过程,导致算法寻优空间大,求解效率低,这是由于算法的寻优能力不仅依赖于其本身的求解逻辑,还依赖于输入的数据源;另一方面,这类处理对最终的优选模型采用多目标转为单目标的方法,如文献[10]和文献[16],其权重的选取带有较强的主观性。更重要地,在对制造任务进行分解时,如文献[11]~文献[15],多采用粗粒度模式与既定的任务加工顺序,而文献[16]~文献[18]从更广域的云协作视角解决企业间的资源调度问题以及对需求方的资源推荐问题,这类任务分解模式在实际应用中会因分配不够明细而难以完全应对需求来匹配特性企业,企业间的协同交互性低,不利于加工生产的实时调控,更不利于定制化产品的小批量生产特性和对成品的高标准要求。在云制造中,任务的基本粒度是指服务所执行操作的基本单元,可分为产品级、部件级、零件级和工序级等。对于小批量定制化产品而言,应对其需求进行细化分解、逐一分析来实现面向服务的云制造生产模式。因此部分企业建立了区域内加工资源共享平台,特别是长三角一带的模具加工协作集群、高精密航空类零件的协作加工等,其以平台为基础,通过企业资源高度共享与专业化协作分工,实现细粒度加工任务与服务的高精度匹配。但目前却少有文献对细粒度资源服务组合的模式及其优选方法进行分析与建立。
在这种背景下,本文提出了以零件的加工特征作为任务基本粒度,以零件的工艺信息和区域制造资源为基础,建立需求信息模型和制造资源供应信息模型对供需两方进行描述。为充分表达与存储供需信息,本文引入知识图谱技术,结合节点关系以及实例化数据构建利于匹配的需求—特征图谱、制造资源供应图谱,再通过特征级服务排序优选阶段进行供应商初筛,并在该阶段设立了加工合格率、满意度评价值、交付按时率、供应偏好值4个评价指标并依托变异系数法进行赋权求和。最后建立以工艺总成本、工艺总时间及总碳排放作为优化目标、特征间的优先级关系作为约束的多目标优化模型,并通过融入次候选集变异算子的改进遗传算法NSGA-Ⅲ对其进行求解,以获得最佳的制造服务组合方案。
在该方法下,通过将特征作为基本单元进行供应企业优选,优化目标不仅涵盖成本和时间要素,还考虑了以碳排放量为指标的绿色生产要求,响应国家“碳达峰、碳中和”的低碳生产目标的同时,有效地实现了面向服务的制造。该方法可以用在基于云制造的零件全工艺流程的规划管理中,如新研发零件,通过服务组合能够有效利用区域内的优质供应商,实现研发阶段的制造高效化;该方法也可用于部分工艺流程在云制造下进行外协加工的决策管理中,如企业面临对复杂零件加工能力不足的情形。
1 供需信息描述与图谱建立
在高共享的区域云制造模式下,选用合理的匹配粒度构建大数据驱动下的资源优选配置模型,是提高匹配效率、促进生产制造协同化发展的关键点。由此,面向定制需求将工艺规划任务粒度分解至特征层面,再基于零件工艺特征进行需求信息描述与供应信息描述。较传统的加工车间分类或零件加工单元分类该方式粒度更细,分类更有针对性。
1.1 零件的工艺信息描述
1.1.1 零件的工艺信息模型
为便于工艺信息的匹配,本文在建立供需图谱之前,将对零件的相关信息进行定义描述。
零件的加工特征包括零件特定的几何构形,以及具有实际工程意义和满足制造要求等信息集合,是形成零件几何形状和信息模型的基本单元,其知识化描述是工艺路线规划的前提和基础[19]。
在构建零件的信息模型时,可以将工件拆解成若干个加工特征,其在数学上表达为:
(1)
其中:PMF为待加工工件的特征集合,ProM为工序模型,MFi为特征单元。
根据云制造所需的机加工特性表达,工件的特征单元MF又可描述为如下的七元组形式:
MF={ID,FT,SF,MC,AF,PC,PFs}。
(2)
其中:ID表示该特征单元的序列编号,FT表示其加工特征类型,SF表示其尺寸特征,MC表示其材料特征,AF表示其精度特征,PC表示特征单元的加工链,PFs表示该特征单元的先行特征集,即加工顺序更优先的特征单元的序列编号集合。
根据现行标准,综合考虑云制造下的加工要素匹配,可将加工特征类型FT分成16大类[20]。即FT={凸台类,腔孔类,槽类,凸起类,圆角类,外圆类,台阶类,平面类,旋转特征类,球冠类,轮廓类,螺纹类,标记类,滚花类,一般移除体积类,肋顶类}。
1.1.2 加工特征的约束处理
在工艺规划中,由于各工艺工序任务间有优先级关系,受到工序排序规则的约束,需要满足“先粗后精”、“先主后次”、“先基准后其他”等基本条件,故各任务间具有时序性,应在工作流建模的基础上进行任务分解[21]。
为此,整合各条件后将加工特征定义以下约束关系:
(1)先粗后精型约束关系 该约束主要针对各特征级内部的加工方法,加工方法顺序随工艺方案确定,如粗铣—半精铣—精铣。
(2)主次优先型约束关系 主次特征由零部件的应用功能决定,在设计阶段根据用户需求设计零件结构,结合实际功能特性可得到主次优先关系。如同一平面类特征拥有普通精度要求的台阶类特征和高精要求的腔孔类特征,则前者为次要特征,后者为主要特征。
(3)基准优先型约束关系 基准由零部件的设计信息决定,在面向基准特征与其依赖特征的加工时,应优先加工基准特征。
(4)非破坏型约束关系 如“先面后孔”的通用规则等决定的约束关系。
利用以上4类特征约束关系可构建各工艺任务间的关联关系,以优先关系实例化后通过约束矩阵进行量化处理。
1.2 供需信息建模
在区域云制造环境下,为了实现需求与供应的精准匹配,需要构建需求端与供给端的信息模型。
1.2.1 需求信息模型
在需求端,以零件的信息模型为基础,融合需求商所要求的加工数量、成本限额、时间限额等要素,可构建需求层面的任务信息。
需求信息如图1所示,可表达为:

图1 需求信息模型图
DI={PMF(n),PM,TQ,CC,AD}。
(3)
其中:PMF(n)为需求端待加工零件的n个特征单元集合,PM为加工数量,TQ为时间限额,CC为成本限额,AD为需求方位置信息。
1.2.2 供应信息模型
在资源供应端,以企业可提供的闲置加工资源为主,面向需求端通过资源集成与优化配置,完成从面向生产的制造到面向服务的制造的转型,促进区域云制造下加工服务的协同化发展。在企业制造资源供应信息上,以企业的名称代号nE、位置信息adE及制造资源mEs作为供应信息数据,其表达形式为:
SI={nE,adE,mEs}。
(4)
其中:nE为企业代号;adE为服务供应企业的位置信息;mEs为企业所能提供的制造资源集合,mEs包含n个制造资源mE,即
(5)
mE主要包括7类信息,其表达式如下:
mEj={FT,SF,MC,AF,mAbility,mFC,mPlan}。
(6)
其中:FT为可加工特征类型,SF为企业设备在该特征下所能加工的尺寸信息,MC为可加工的工艺材料信息,AF为工艺精度信息,mAbility为该特征类型下供应企业的单位时间生产能力,mFC为该特征类型下供应企业的单位产量加工成本,mPlan为该特征所用设备短期运载情况。
1.3 供需信息知识图谱构建
为充分表达需求信息同时便于检索,本文引入知识图谱技术用以实现多层次多要素信息的结构化表达,构建利于匹配的制造资源供应图谱、需求—特征图谱。知识图谱在逻辑上可分为模式层与数据层两个层次,模式层构建在数据层之上,是工艺知识图谱的核心,主要通过本体库来规范数据层的一系列事实表达[22]。本文在图谱的构建中,为减少数据的冗余,保证索引关系的准确性与一致性,采用自顶向下设计,定义数据模式,根据信息模型并结合实际生产数据凝练构建4类关系如表1所示。将供需信息模型及关系赋予到图谱的模式层,完成其本体化表达。

表1 关系类型及其示例
在模式层实体关系数据的引导下,对工业生产数据进行预处理,得到实例数据的形式化表达,以〈实体,关系,实体〉及〈实体,属性,属性值〉作为基本表达方式构建知识图谱的数据层,并在实际应用中不断扩充。
在数据存储方面,基于实际生产数据的复杂性,采用图数据库的存储形式更有优势。这是由于涉及到多度的关联查询、模糊查询,以及实际运行时的增删改查等操作,基于图数据库的效率会比关系数据库的效率高出数千倍乃至数万倍。本文采用Neo4j图数据进行数据的存储及可视化表达。较其他图数据库,Neo4j遵循属性图数据模型,在大规模数据中检索遍历速度更快,且支持多度关系查询及模糊查询等。
如图2所示为本文构建图谱的整体过程,以及实例化的部分制造资源供应图谱、需求—特征图谱。

图2 供需图谱构建过程
2 面向特征级服务的一层优选过程
在特征级服务优选中,主要分为需求任务发布阶段、信息匹配筛选可用供应资源阶段和特征级服务排序优选阶段3个阶段。
(1)需求任务发布阶段 该阶段由需求方根据需求信息模型DI进行任务描述,如图1所示,DI五元组所包含的加工数量PM、时间限额TQ、成本限额CC、需求方位置信息AD将作为一级任务指标的属性与约束,而DI五元组中的特征集PMF将进一步拆分为若干个特征单元MFi,每个特征单元MFi由七元组{ID,FT,SF,MC,AF,PC,PFs}构成,特征单元MFi将作为二级任务指标进行特征级任务的服务筛选,由此形成完整的需求信息。相关数据以增量形式存入图数据库中完成新需求—特征子图谱的构建,借助于图数据库特有的灵活性与敏捷性,可以对已存在的图结构动态增加新的边及节点。以此实现将总任务拆解成若干个子任务并完成数据的存储。
(2)信息匹配可用供应资源阶段 在匹配可用供应资源时,使用预先构建的制造资源供应图谱,该图谱由各服务供应方将自己可提供的加工服务输入到云制造服务平台后形成。匹配时,以特征级需求任务为单位对企业进行筛选,选择满足该特征级任务下全指标要求的企业作为初步候选服务集。其中序列编号ID作为特征标识、优先工艺集PFs作为特征间顺序约束关系不在筛选中体现。执行该阶段时采用Neo4j的Cypher语言可通过对相关资源及其属性进行多度关系查询,如通过“MATCH(A)-[∶‘include’]-(B)-[r]-(C∶‘FT’)WHEREC.name=‘平面类’RETURNA,B,C”等语句不需建立复杂连接即可检索到满足要求的相关节点及其子节点及属性,提高检索效率。
(3)特征级服务排序优选阶段 根据步骤(2)得到的初步候选服务集作进一步优选,考虑加工合格率PYF、满意度评价值S、交付按时率TL、供应偏好值Bias四个主要因素。
1)加工合格率PYF。指服务供应企业往期加工该特征类型的合格品总量Ne占加工该特征类型总量Ns的百分比。该指标在一定程度上表达了企业对该特征类型的加工能力,即是否能够加工好该特征类型的工件。
(7)
2)满意度评价值S。指服务供应企业的往期客户对该服务企业的综合评价,其中S∈[0,1]。该指标在一定程度上表达了企业的服务能力。
(8)
3)交付按时率TL。指服务供应企业往期在承接任务时,于预定时间内交付的次数Na占总承接的次数NT的百分比。该指标在一定程度上表达了企业自身的项目管理能力和准时性。
(9)
4)供应偏好值Bias。指服务供应企业往期在承接任务时,加工该特征类型的数量Nv占加工所有类型的总数量Nall的百分比。该指标在一定程度上表达了企业在特征加工选型方面的偏好,即是否更倾向于加工该特征类型的工件。
(10)
加工合格率PYF、满意度评价值S、交付按时率TL、供应偏好值Bias四个因素的取值范围都在[0,1]之间。在进行下一步的多目标优化之前,考虑到会因候选服务集过多而难寻优的情况,为降低服务组合优选算法的寻优空间,在本阶段会先进行一轮筛选得到二轮候选服务集,再进行后续求解。
指标权重的确定是多要素综合评价中的关键环节,权重确定的是否合理将直接影响评价结果的可靠性和有效性[23]。在本阶段以特征为粒度的服务筛选中,4类因素的权重确定可以采用主观赋权法或客观赋权法。其中,主观赋权法大多需要依赖专家经验知识,实施难度较大且具有主观性和不确定性,而客观赋权法主要由数据样本的特征决定。为综合考量由4类因素影响力进行的排序优选以实现协同效应,可采用变异系数法进行权重赋值。该方法能够客观地体现指标的区分度,根据各指标在所有被评价对象上观测值的变异程度大小来对其赋权,具体步骤如下:
步骤1数据归一化。因特征级服务排序优选阶段的4类指标取值均在[0,1]内,故无需归一化,可得评价指标的数据矩阵Xe。Xe为含4项评价指标、n个评价对象的4×n的矩阵。
(11)
在矩阵Xe中,PYFi、Si、TLi、Biasi分别表示第i个评价对象的加工合格率、满意度评价值、交付按时率和供应偏好值。
步骤2计算各指标的平均值与标准差。
(12)
(13)
其中S1、S2、S3、S4分别表示4类指标的标准差。
步骤3计算各指标的变异系数。该变异系数反映了各指标的相对变异程度。
(14)
步骤4对变异系数进行归一化处理,得到各指标的权重。
(15)
从而得到最终的指标权重{w1,w2,w3,w4}。以该权重对4项指标进行赋权求和得到供应商特征级服务的综合评估分数Cs。通过在各特征粒度下对供应商的综合评估分数Cs进行排序,设立优选百分比α得到候选集。本文在后续的寻优中,会用到主候选集、次候选集两类,对其分别设立优选比α1、α2。优选比的数值可根据实际情况进行设置,如将α1设为10%,α2设为30%,则排序在前10%的优质企业会被选为主候选集,排序在10%~30%之间的企业会被选为次候选集。主候选集是服务组合模型求解时的主要供应商,次候选集仅作为后续算法在物流层面优化的备选项。
在获取相关统计指标时,可以结合历史存储图谱进行快速查询与计算。对于云平台而言,当历史订单完成后,需求—特征图谱即转为历史数据,通过对历史需求—特征图谱的需求数据与其对接的制造资源数据间的关联关系采用Cypher的聚合函数,可以实现Ne、Nv等指标的快速统计。
3 制造资源服务组合的二层优选过程
3.1 服务组合优选的集成规划模型
为响应“碳达峰、碳中和”的战略目标,制造资源的服务组合不仅考虑到成本和时间要素,同时也对碳排放进行优化选择。因此,在上一阶段筛选出优质供应商后,以工艺总成本、工艺总时间及总碳排放为优化目标建立目标函数,以特征间优先级关系为约束条件构建约束矩阵进行优化求解,实现二层优选。
3.1.1 目标函数
服务组合选型优化目标以成本、时间和低碳为主。成本控制的核心涵盖制造成本和物流成本两大块,工艺总时间包括各任务加工时间和跨企业运输时间,绿色生产主要以控制设备加工中的碳排放量为主。由此构建如下优化目标函数:
(1)工艺总成本目标函数
(16)
式中:PCn为工艺总成本,mFCi为第i类特征单位产量加工成本,adEi为第i类特征加工企业的位置信息,Tc为运输成本因子,PM为加工数量。
(2)工艺总时间目标函数


(17)
其中:TC为工艺总时间,mAbilityi为第i类特征供应企业的单位时间生产能力,adEi为第i类特征加工企业的位置信息,Tc为运输时间因子,PM为加工数量。
(3)加工总碳排放目标函数
碳排放含量的计算参照文献[24]和文献[25],基于本方案的应用背景,为保证合理的粒度计算,将相关过程作合并处理,构造碳排放目标函数如下:
(18)
其中:CE为碳排放总量,Mci为第i类特征供应企业所用设备的碳排放因子,mAbilityi为第i类特征供应企业的单位时间生产能力,PM为加工数量。
3.1.2 约束处理
在工艺规划中,受到工序排序规则的约束,各工艺工序任务间有优先级关系,需要满足先粗后精型约束关系、主次优先型约束关系、基准优先型约束关系、非破坏型约束关系4类特征约束关系。这些条件形成了特征间的优先关系,在需求—特征图谱中可将其表达,如图3所示,MF6与MF7存在先后关系,MF6为MF7的先行特征,须先加工MF6后才可加工MF7;而MF3与MF5为并行关系,可不考虑优先顺序。

图3 特征工艺间关系图
特征之间的优先关系可转化为特征间约束矩阵CMij:
(19)
其中:CMij表示特征MFi与特征MFj之间的优先关系,n为零件的总特征数。CMij根据4类特征约束关系中的规则取得,如下:
3.2 基于NSGA-Ⅲ算法的模型求解
面向服务的组合优选规划模型本质是多目标优化问题,解决此类问题有多种方法,DEB等[26]提出第三代非支配排序遗传算法(fast elitist Non-dominated Sorting Genetic Algorithm,NSGA-Ⅲ),该算法在带精英策略的非支配排序遗传算法(NSGA-Ⅱ)基础上,采用了基于参考点的选择机制进行系统分析而选择优异解。NSGA-Ⅲ是针对高维多目标优化计算代价大,难以挑选Pareto解的情况而开发的,该应用场景适用于本模型,因而本文采用该算法进行求解。为了将细粒度的服务优选模型有效地融入算法中,本文提出一种基于特征粒度的制造资源排序编码方式以及引入一类次候选集变异算子进行遗传进化。
3.2.1 编码方式
服务组合优选问题属于NP-hard问题,尤其是工艺规划上还涉及到广泛的约束问题,为将制造资源信息进行有效编码以提高寻优效率,本文提出一种基于特征粒度的制造资源排序混合编码方式。该方式采取整数编码和排序编码组合的多染色体混合编码,能够完整地表达所选用的制造资源及工艺顺序。
对于需求方所要求待加工的n个特征,本混合编码方式将采用长度为2n的染色体。其中前半段是长度为n的排序型编码染色体,表示各特征的工艺顺序;后半段是长度为n的实数型编码染色体,表示针对已排序的特征所分别选用的制造资源供应企业ID序号。
如图3中的8个待加工特征,编码后的染色体可表达如图4所示,其长度为16,前8个为特征的工艺顺序,后8个为该顺序下各特征选取的制造资源供应企业ID序号。此染色体也可用二元组形式表达为{(1,5),(3,2),(4,4),(2,6),(6,3),(7,3),(5,7),(8,9)},意为特征MF1是第一个加工特征,其选用的供应企业ID为5;MF3为第二个加工特征,其选用的供应企业ID为2,以此类推。

图4 面向制造资源排序的染色体混合编码方式
3.2.2 次候选集变异算子
对于优选模型的求解,核心是挑选出优质且物流服务组合便捷的供应商。在一层选优时形成了主候选集与次候选集,主候选集将作为初始染色体生成与进化的主体。考虑到企业供应能力的差异性与区域运输物流的效益,如企业A在特征集服务MF1上的综合评估分数Cs能够达到前5%,而在特征集服务MF6上的Cs只能达到前30%,当MF1与MF6间不存在断层供应商时,意味着两类加工需求均能在企业A进行,此时可以在遗传算法寻优时以ε的概率将企业A作为MF6的一个次候选集变异算子引入进化过程,让最终的求解结果有更好的适应性。
使用次候选集变异算子产生变异的过程如图5所示,预先设置变异概率Pm与次候选集选择概率ε,对原始染色体的制造资源编码部分进行变异操作,图中为后8位编码。

图5 考虑次候选集的变异操作
变异实施过程为:
(1)对制造资源部分染色体的每一个基因以概率Pm指定其为变异点,如图5中ID为“6”的基因在此次被选为变异点;
(2)该指定变异点将有1-ε的概率会在其基因的主候选集中产生变异,同时有ε的概率会在其次候选集中产生变异。
(3)若在主候选集中产生变异,则从其主候选集中选择企业ID进行变异操作即可;若在其次候选集中产生,则需要先找到该基因的前一个基因,如图5中的“4”,然后在基因为“6”的次候选集中寻找是否有ID为“4”的企业,若有即可选择ID“4”进行变异操作,否则保持原来的基因“6”。
3.2.3 求解过程
基于NSGA-Ⅲ算法的服务组合优选模型求解如图6所示,具体步骤如下:

图6 NSGA-Ⅲ算法流程图
步骤1初始化算法参数,包括总迭代次数、交叉率Pc、变异率Pm、次候选集选择概率ε等。
步骤2以主候选集空间初始化参考点和种群N,输入约束条件。
步骤3对父代种群Pt,通过选择、交叉、带次候选集的变异操作产生子种群Qt,计算个体的适应度,即PCn、TC、CE的函数值。
步骤4混合Pt和Qt得到一个新种群Rt,即Rt=Pt∪Qt,其规模为2N。对Rt进行非支配排序并划分为不同层级的非支配解集合(F1,F2,F3,…,FL,…,FW)。
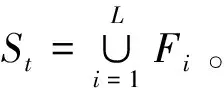
步骤6从St中选择解产生下一代父种群Pt+1。若St的数量等于N,则Pt+1=St,否则,先将St中的集合(F1,F2,F3,…,FL-1)放入Pt+1,然后再从FL中根据基于参考点选择机制选取其余解。
基于参考点的选择方法为:首先找到种群St的理想点Z*=(PCn*,TC*,CE*),其中PCn*,TC*,CE*分别为种群St所有解中各目标函数值的最小值,然后归一化种群和参考点。通过计算St中的每个解到每条参考线的垂直距离,然后用最短的距离连接解与参考点,这样就可以在FL中用一种新的小生境保护方法选择个体。生境数ρj是F1到FL-1层中与第j个参考点相连的个体数。这种小生境技术是为了提高NSGA-Ⅲ的分布性,所以首先需要找到具有最小生境数ρj的参考点i,然后确定FL中有没有个体与参考点i相连。若有个体与参考点i相连,则根据ρj的值选择一个个体进入Pt+1;否则,此次迭代将不考虑这个参考点,而是用另外具有最小生境数的参考点重复上述操作,直到Pt+1的值等于N的值。
步骤7若满足终止条件,则输出最终的解,否则重复步骤2。
4 实例分析
为验证在制造资源组织和服务组合优选任务上本方案的可行性,以某新研发零件为例匹配相应的生产企业,执行如下过程:
(1)面向特征级服务的一层优选
该新研发零件共有9个特征需要进行外协加工,如图7所示,图中DI_new代表其需求数据,包括{PMF(9),PM=500,TQ=230,CC=6.80,AD=(117.348347,38.970762)},即特征单元PMF,加工数量500、时间限额230 h、成本限额6.8万元、需求方位置信息AD(117.348347,38.970762)。9个特征单元的从属特性包括特征类型FT、尺寸特征SF、材料特征MC、精度特征AF、加工链PC、先行特征集PFs,为便于展示,图中仅呈现MF9的相关属性特征,特征单元MF1~MF8的特征类型FT依次为平面类、外圆类、凸起类、旋转特征类、槽类、肋顶类、圆角类、台阶类。

图7 案例的需求—特征图谱
通过图谱中特征间的优先关系可得其约束矩阵为:
根据需求数据对供应方进行信息匹配与质量排序。本次实例名单共328家供应商,每家可提供若干个特征加工服务。通过以特征的工艺需求进行匹配得到满足特征MF1条件的企业有192家,MF2有107家,MF3有132家,MF4有190家,MF5有156家,MF6有171家,MF7有168家,MF8有134家,MF9有114家,特征下各企业的加工合格率PYF、满意度评价值S、交付按时率TL和供应偏好值Bias如表2所示。对4个指标以变异系数法进行赋权求和得到特征下各企业综合评估分数Cs,再以Cs进行排序得到表2中的结果。

表2 特征下各企业的指标排序信息
将排序结果以优选比α计算得到候选集,本文将主、次候选集对应的α1、α2分别设为10%、30%。得到特征单元MF1下的主、次候选集分别为19个、38个,MF2下为11个、22个,MF3下为13个、26个,MF4下为19个、38个,MF5下为16个、32个,MF6下为17个、34个,MF7下为17个、34个,MF8下为13个、26个,MF9下为11个、22个。如表3所示为所得到的部分优质供应商信息。
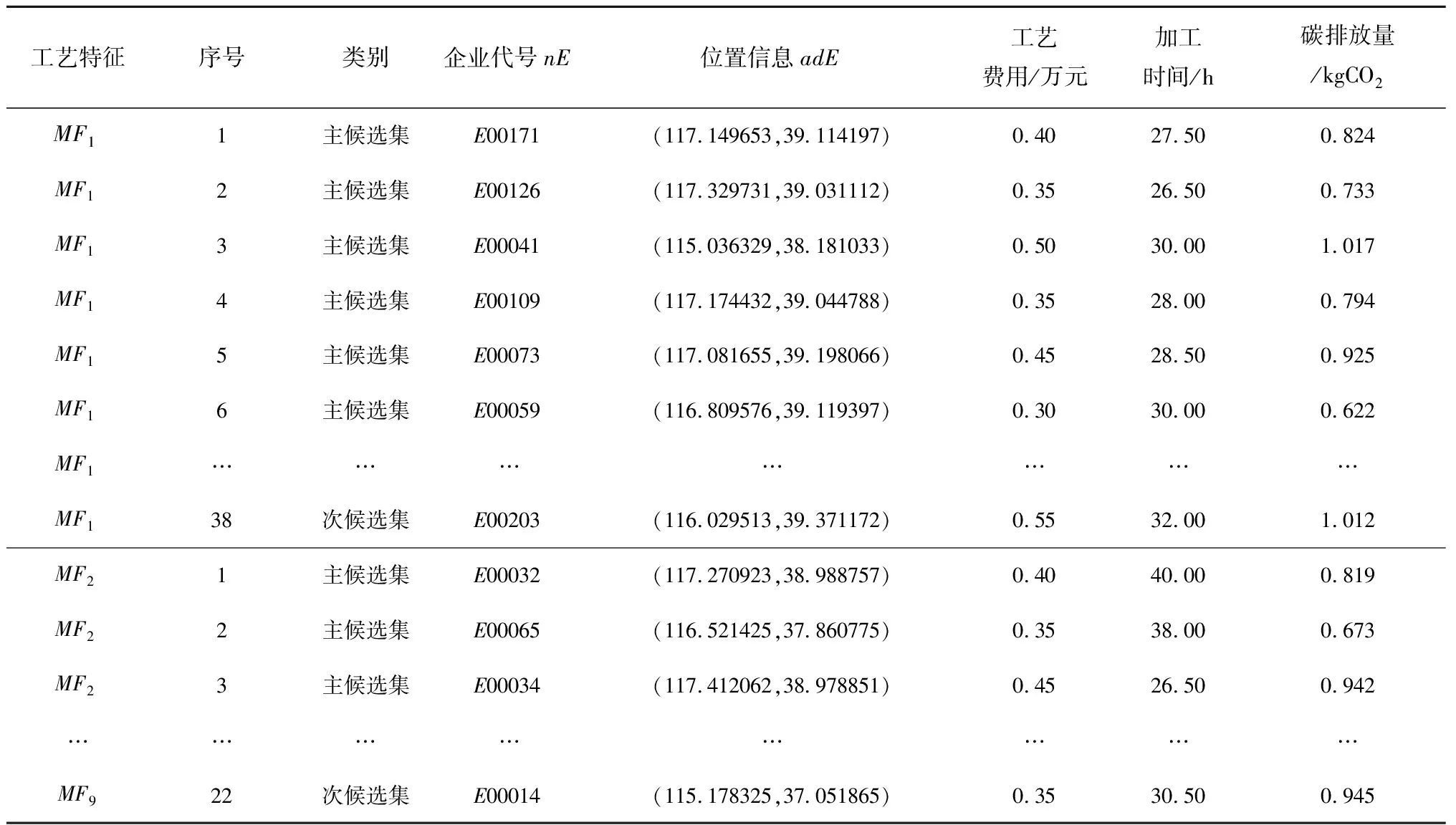
表3 主次候选集部分供应企业信息
(2)资源服务组合的二层优选
对所得到的企业制造资源候选集,依据建立的约束矩阵CM,以3.1节中的3个目标函数为优化目标,基于制造资源排序混合编码方式进行染色体编码,以次候选集变异算子执行进化中的变异操作,在NSGA-Ⅲ算法下寻优。
接下来将从算法求解结果解码到实际方案的可行性、与其他算法对比解集的分布情况、多次实验求解结果的稳定性展开作分析。
1)结果可行性分析。
设置种群规模为175,交叉概率为0.9,变异概率为0.15,次候选集选择概率为0.1,最大迭代次数300,以非支配排序计算得到Pareto解集。如图8所示为该Pareto解集的示意图,对Pareto解集以需求信息中的时间限额TQ230 h,成本限额CC6.8万元进行过滤,取解集中第一条数据进行染色体解码,对其所选择的工艺顺序与加工企业进行分析。

图8 Pareto解集示意图
如图9所示,该结果解码后的工艺流动顺序为(1,3,4,2,6,7,5,8,9),由5个企业协作完成。其中,MF1由一家供应商完成,MF3、MF4由同一供应商完成,MF2、MF6、MF7由同一供应商完成,MF5由一家供应商完成,MF8、MF9由同一供应商完成,且仅有MF2在其次候选集企业中进行加工,其余均在其主候选集中完成。可知,该结果满足约束矩阵CM且供应主体为主候选集。

图9 计算结果解码图
为进一步校验工艺的流动顺序,对主、次候选集进行地址标记,如图10所示,将所选的5家供应商以虚线框于图中圈出,可以发现5家供应商都聚集在同一小区域内。对5家供应商地点与需求方地点进行放大,如图中所示,以箭头标记了工序的流动顺序,可以发现,从需求方地址开始,经过5家供应商后又回到需求方附近,形成了闭环,进一步验证了该结果在物流层面的可行性。

图10 加工路线图
2)与其他算法对比解集的分布情况。
为对比本文所提出的带次候选集变异算子的NSGA-Ⅲ算法(简写为NSGA-Ⅲ-CS)在细粒度制造资源服务组合问题上的求解效果,特设置了对照实验,分别为常规NSGA-Ⅲ算法、带次候选集变异算子的NSGA-Ⅱ算法(简写为NSGA-Ⅱ-CS)、常规NSGA-Ⅱ算法。以1)中的实验参数用上述4类算法进行计算求解,其中常规NSGA-Ⅲ算法与常规NSGA-Ⅱ算法无次候选集选择概率。
将所得结果绘制箱线图,如图11所示。由图中各算法的结果分布情况可以发现,无论是在工艺费用、加工时间还是碳排放量上,NSGA-Ⅲ-CS的求解效果均优于其他3类算法。此外,NSGA-Ⅱ算法在求解时存在少量异常值,在NSGA-Ⅱ同类算法对比中,NSGA-Ⅱ-CS算法的解分布会更优于常规NSGA-Ⅱ算法。
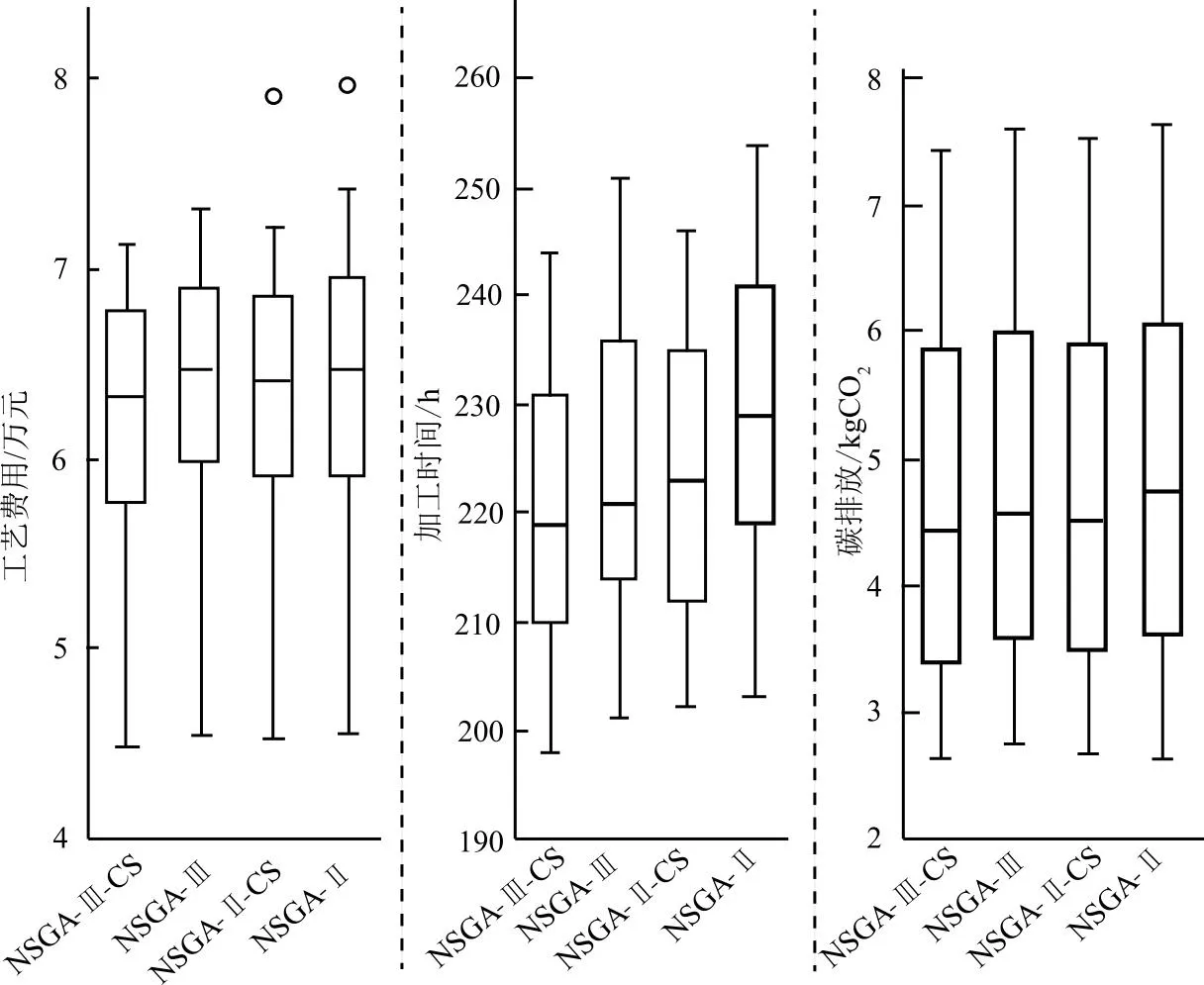
图11 算法对比箱线图
3)多次实验求解结果的稳定性。
为验证该算法求解的稳定性,以1)中实验参数对其运行10次。10次计算速度如图12所示,对每次所得Pareto解集下的工艺费用、加工时间和碳排放量分别计算均值,得到了3个目标下的10次结果,由图中数据及趋势可知,各目标下的实验结果波动较小,证明了该算法在应用时具有一定的鲁棒性。

图12 10次实验结果图
因此,本文所提出的基于特征粒度的制造资源服务组合双层优选方法在应用中能够有效地匹配优质供应商,同时最小化物流成本;在其中使用的带次候选集变异算子的NSGA-Ⅲ算法较其他算法的优化效果更好,且运行稳定。
5 结束语
本文面向小批量定制产品,以区域云制造环境下的任务分配和资源组合优化问题为研究重点,提出将零件的加工特征作为任务粒度进行资源匹配,并建立了需求信息描述模型、制造资源供应信息模型。之后引入知识图谱技术,采用自顶向下设计,完成信息模型的本体化表达与模式层建立,构建需求—特征图谱、制造资源供应图谱,并以图数据库进行存储。在优选匹配时,聚焦需求,以需求任务发布阶段、信息匹配筛选可用供应资源阶段、特征级服务排序优选阶段3个层次完成制造资源的一层优选;将筛选后的优质供应企业以工艺总成本、工艺总时间及总碳排放为优化目标建立目标函数,以特征间优先级关系构建约束矩阵,并基于本文提出的制造资源排序混合编码方式对资源及工艺顺序进行染色体编码,最后通过带次候选集变异算子的NSGA-Ⅲ算法对该多目标优化问题进行求解,实现二层优选。
该方案适用于小批量定制产品的组合生产和企业请求外协加工时的协同生产等情形。通过实例分析验证了该方法的可行性,同时与其他算法相比,本文所提出的带次候选集变异算子的NSGA-Ⅲ算法能够在求解时得到更好的优化结果,多次运行的稳定性较好,能够在匹配优质供应商的同时,最小化物流成本,为细粒度的资源服务组合问题提供一种可靠的解决方法。目前本文构建的图谱主要是用于供需数据的存储与快速检索,以及在匹配中关联关系的实时查询,下一步计划将知识图谱在推理与聚类推荐等方面的优势融入优选方法中,使特征级服务的一层优选能通过过滤和相似度匹配等算法更好地应对大规模数据的需求,提升方法的求解效率。
