不均衡小样本下的设备状态与寿命预测
2024-02-21刘勤明郑伊寒
陈 扬,刘勤明,郑伊寒
(上海理工大学 管理学院,上海 200093)
0 引言
随着现代社会的发展,我国工业对设备健康状态的预测精度要求越来越高。在实际工业中,一旦企业对设备健康状况进行错误分析很有可能会造成大量财产损失,甚至会危及员工的生命安全[1]。因此及时准确地对设备健康状况进行评估并预测出设备剩余使用寿命已经成为越来越多学者的研究对象。
近年来,随着人工智能的飞速发展,实际工业中的机器计算已经逐渐取代传统的人工计算,而机器学习作为人工智能的一个分支正越来越多地应用于实际工业中。赵广谦等[2]提出一种联合卷积神经网络与双向长短时记忆网络的设备寿命预测模型,并通过滚动轴承数据证明了该模型的有效性。刘文溢等[3]提出一种基于高阶半隐马尔科夫的寿命预测模型,并通过算例证明了该模型的有效性。耿苏杰等[4]利用模糊贝叶斯网络成功对电力设备进行了故障诊断与状态分析。在众多机器学习与深度学习算法中,AdaBoost因其结果准确,对弱分类器效果要求低等特点被广泛运用到人脸检测[5]、大数据处理[6]、音频识别[7]等领域中,但由于AdaBoost迭代次数过多导致其处理时间长,以及在不均衡数据下处理效果差等问题,传统AdaBoost并不能被直接应用在对数据处理结果准确度要求极高的实际工业中。针对上述问题,许多学者对AdaBoost进行改进,其中FRIEDMAN等[8]提出静态权重裁剪法AdaBoost(Static Weight Trimming AdaBoost,SWT-AdaBoost)调整样本在迭代期间的权值分布,通过建立裁剪阈值T(β)过滤部分正确分类的样本,提高SWT-AdaBoost的计算效率。但是合适的T(β)需要根据β的取值决定,而β的取值也是一个十分困扰的问题。贾慧星等[9]在其基础上提出动态权重裁剪法AdaBoost(Dynamic Weight Trimming AdaBoost,DWT-Adaboost),在该算法中,当对样本训练提前停止时,该模型通过减小β后重新训练Weaklearn(弱学习器),虽然该模型一定程度上克服了SWT-AdaBoost的局限性,但是其对β的取值依然存在一定要求,并没有解决β取值偏差会带来的问题。为了规避上述问题,余陆斌等[10]提出了自适应权值裁剪AdaBoost(Adaptive Weight Trimming AdaBoost,AWT-Adaboost)算法,根据样本权值分布和容量大小,引入调节系数建立裁剪阈值,规避了无法对β精准取值的问题,提高了计算效率。袁双等[11]利用主成分分析(Principal Component Analysis,PCA)降维技术去除了样本特征相关性,从而在分类过程中提高精度,同时利用算例证明在加速分类过程的同时也使分类结果更加准确。上述模型一定程度上提升了AdaBoost的计算效率,但是全部都是建立在正确的数据集上的,当遇到不均衡数据的时候,上述算法并不适用。
针对AdaBoost面对不均衡数据处理效果差的问题,WANG等[12]提出一种改进的AdaBoost算法,根据全局错误率和正确分类样本决定加权投票参数,并通过算例证明了该算法的有效性。但是在少数类样本个数过少的情况下,该算法并没有规避可能会出现的过拟合问题。李诒靖等[13]分析数据特征,同时结合集成学习的角度提出一种联合PSO(particle swarm optimization)、KNN(k-nearest neighbor)与AdaBoost的模型以处理样本不均衡的问题,虽然该模型在仿真部分计算出的精度很高,但是却没有提升模型的计算效率,容易花费较多时间解决问题。姚培等[14]在不均衡数据的前提下通过建立代价敏感损失函数并通过建立规则使其最小化,最后通过算例证明在不均衡数据下该算法的有效性。武森等[15]面对不均衡数据将聚类与欠采样方法结合,然后结合AdaBoost对数据进行处理,最后通过算例证明该组合算法拥有更高的精度。文献[13]和文献[14]的方法是建立在样本充足的基础上,当某种类样本个数过少时,该算法不再适用。
基于上述的问题,本文提出一种基于裁剪过采样新增AdaBoost(Clipping Oversampling Add AdaBoost,COA-AdaBoost)算法,基于优化裁剪阈值引入随机生成因子后清洗权值分布,在通过尽可能减少强学习器迭代次数从而提升计算效率的同时规避了传统AdaBoost算法可能会出现的过拟合的问题,使得模型可以应用于实际工业中的小样本不均衡数据,从而有效地分析设备健康状况以及预测设备的寿命发展趋势。
1 问题描述
在实际工业中,及时准确地评估设备健康状况可以在设备维修时节省大量时间与成本,同时也能避免安全事故的发生。但是在实际操作过程中,由于检测设备造成的误差或人工测量误差的影响,收集到的数据往往出现样本匮乏或分布不均衡的问题,而现阶段应用火热的机器学习算法需求的数据往往是相对完备的,因此传统机器学习算法并不能直接应用到实际生活中。同时由于实际工业对设备健康状况判断准确性较高,例如支持向量机[16]、随机森林[17]、K近邻算法[18]等弱学习器并不能满足人们要求。针对上述情况,本文采用强学习器AdaBoost满足对设备健康状况判断的精度要求,将弱学习器集成为强学习器提高计算精度。针对AdaBoost在集成学习过程中出现的处理速率慢的问题,本文提出基于AWT-AdaBoost的改进权值裁剪AdaBoost,通过修改裁剪阈值计算方法规避不均衡数据下AWT-AdaBoost可能会出现的过拟合问题[19],随后根据样本匮乏的情况引入新增权值因子清洗过滤后的权值较高的样本点,克服不均衡数据带来的误差。根据上述思路得到本文的设备健康状况分析模型,如图1所示。
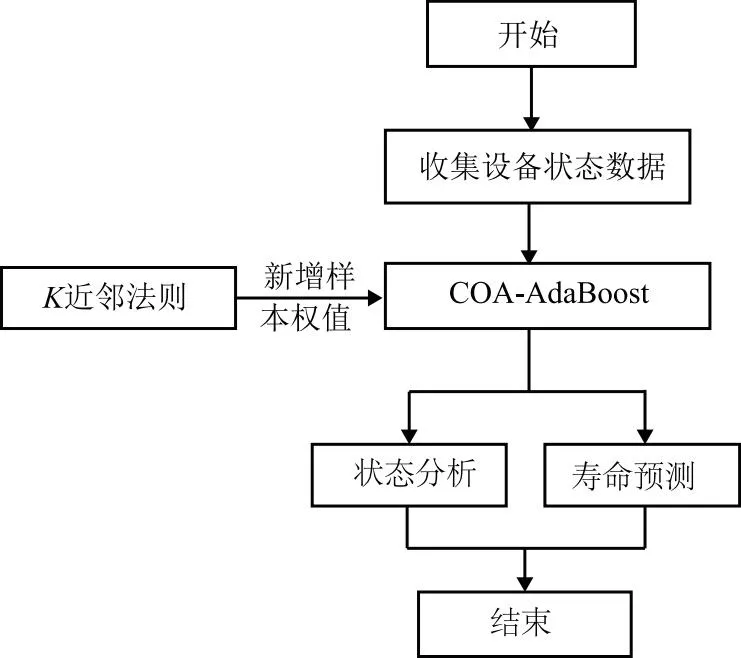
图1 健康状况分析总体流程图
2 AdaBoost算法
2.1 基本原理
AdaBoost是机器学习的一种迭代算法,通过将多个弱学习器进行组合训练得到强学习器,规避弱学习器分类效果差的缺点,从而取得更好的分类效果。AdaBoost算法流程如下:
假设样本集D={(x1,y1),(x2,y2),(x3,y3),…,(xm,ym)},xi∈X(训练样本),yi∈Y={-1,1},样本初始权值d(i)计算如下:
(1)
(1)Forn=1,2,…,N。
(2)基于Dn调用弱学习器hn,hn为传统KNN、SVM、决策树等一系列原理相对简单但是分类效果并不能满足需求的弱分类器。
(3)计算弱学习器在当前分布下的错误率。记hn(xi)≠yi时i的取值为i1,计算如下:
εn=∑dn(i1)。
(2)
若εn>0.5,令N=n-1,停止迭代。
(4)计算分类器hn在最终分类器中的加权系数:
(3)
(5)更新样本分布,其中zn为规范化因子,使得此过程中所有样本权值之和为1:
(4)
(6)输出最终的强分类器如式(5)所示:
(5)
2.2 权值裁剪AdaBoost分析
根据上述流程可以看出,AdaBoost会在首轮迭代赋予每个样本相同的权值,在随后几轮迭代中赋予被错误分类的样本更多的权值。因为AdaBoost由多个分类器组成,所以相比传统机器学习算法,其在处理数据时可能会因为迭代次数的影响花费更多时间。为了尽可能缩短AdaBoost处理时间,文献[6]提出的DWT-AdaBoost根据样本分布与容量设置裁剪阈值T(β),T(β)计算规则如下:
(6)
选择权值大于T(β)的样本作为新样本集Dβ,随后按照式(2)计算当前迭代次数下的错误率εn。
当εn≥0.5且Dβ=D,令N=n-1,迭代停止;当εn≥0.5且Dβ≠D,令β=β/2,转步骤(2)。如此不断循环,最终得到一组强分类器。很显然,DWT-AdaBoost虽然通过裁剪缩减了样本个数从而尝试缩短AdaBoost计算时间,但是由于β的取值无法确定,同时一旦β取值过大可能会导致迭代次数增加,降低计算效率。而一旦β取值过小很有可能会导致错分类样本权值丢失,从而影响最终输出的强分类器。根据上述情况,文献[10]提出AWT-AdaBoost算法,通过引入调节系数,根据样本容量优化裁剪阈值。AWT-AdaBoost裁剪阈值T(maxn)计算公式如下:
(7)
其中K为调节系数,取值范围为5~10,max(dn)为样本权值的最大值,m为样本容量。AWT-AdaBoost算法规则和DWT-AdaBoost规则类似,只对权值大于T(maxn)的样本进行迭代,从而生成新的强分类器。迭代过程中,当εn≥0.5且Dβ=D,令N=n-1,迭代停止;当εn≥0.5且Dβ≠D,令T(maxn)=0,返回至2.1节的步骤(3),随后重复传统AdaBoost输出分类能力较强的强学习器。
上述两个模型都是在完备数据条件下进行权值裁剪,并没有说明数据集的分布特征可能会给弱学习器集成过程带来的影响。由于AWT-AdaBoost是对DWT-AdaBoost进行改进,本文提出的COA-AdaBoost算法着重分析AWT-AdaBoost的不足之处并提出改进。
无论是在哪种工作环境,现阶段得到的数据都存在一定噪声,而在工业背景下,数据寿命数据在大部分情况下也会出现不均衡的情况。由式(7)可知,当调节系数K给定时,由于样本容量m也为定值,在不均衡且存在噪声的数据下该公式可能会导致两个问题:
(1)一旦数据中存在某个权值过大的异常样本,很有可能会导致T(maxn)在对样本进行裁剪时将一部分同样被错误估计的样本裁减掉,这种情况会直接导致最终输出的强学习器计算效率与预期出现偏差。
(2)不均衡数据下少数类样本和多数类样本比例过小导致最后生成的强学习器出现过拟合的情况,不再对训练集之外的其他样本集适用,使得最终输出的结果不具有泛化性。
针对上述两种情况,本文提出改进动态裁剪公式与基于K近邻法则的随机生成权值因子。
3 基于裁剪过采样新增AdaBoost算法
3.1 改进动态裁剪公式
实际工业设备寿命预测中,对设备寿命预测模型的效果评估主要从计算速率与准确度两个方面进行。为了提高预测设备寿命的计算速率,通过对AdaBoost的权值裁剪和迭代停止方式的改进实现。而在权值裁剪过程中,少数类样本匮乏会引起权值分布异常,这会影响AdaBoost的分类效果。文献[8]提出的SWT-AdaBoost、文献[9]提出的DWT-AdaBoost和文献[10]提出的AWT-AdaBoost算法在面对权值异常时也没有给出很好的解决方案。由于AWT-AdaBoost的模型是在SWT-AdaBoost、DWT-AdaBoost基础上进行改进,以下对AWT-AdaBoost不适用场景进行描述:
假设在3次以内的迭代过程中,错分类样本权值derror={d1,d2,…,dm},正确分类样本权值dcorrectness={dn},根据式(7),引出式(8):
(8)
这就是AWT-AdaBoost的局限性所在,若式(8)表达的特殊情况发生,则该学习器会丢失部分权值较小且分类错误的样本点,导致最终输出的分类器分类效果出现误差,同时在实际测量中,出现问题的样本往往占少数,出现少数类样本匮乏的问题会导致式(8)引起的误差进一步加大。因此,在小样本不均衡数据下需要对式(8)进行改进以克服AWT-AdaBoost的局限性,使其可以面向不完备数据并运用在实际工业中。
为了尽可能通过减少迭代次数加快模型计算效率,同时规避上述分析中提到的可能引起误差的情况,本文提取所有迭代过程中被错误分类的样本,尽可能保留错分类样本的特征以保证输出分类结果的有效性,利用该思想可以规避式(8)可能带来的弊端,克服AWT-AdaBoost的局限性,使得最终输出的强学习器更加可靠。根据上述分析,式(8)不再满足计算少数类样本匮乏数据的要求。为了本文算法能兼容样本匮乏的数据,对动态裁剪过程进行改进,改进动态裁剪系数计算如下:
T(maxn)=min (d(i)丨hn(xi)≠yi)。
(9)
在AdaBoost计算过程中,由于正确样本权值较小,且AdaBoost算法原则就是对错分类样本进行分析,为了提高学习器在样本匮乏条件下的泛化能力,改进动态裁剪过程对所有错分类样本进行分析,过滤正确分类的样本,最大程度提高处理效率。过滤后的样本为Derror。
改进动态裁剪过程如下:
(1)输入样本集D={(x1,y1),(x2,y2),(x3,y3),…,(xm,ym)},xi∈X(训练样本),yi∈Y={-1,1},根据式(1)给定样本权值。
(2)基于权值分布调用弱学习器,根据式(2)计算弱学习器的错误率εn,同时得到新的权值分布。
(3)引入改进动态裁剪式(9),过滤正确分类的权值,同时得到新的样本集Derror与新的权值分布。
上述内容指出了目前针对AdaBoost运行速率慢的局限性,并提出了一种新的裁剪法则对其进行优化,克服了AWT-AdaBoost算法的局限性,使得最终输出的强学习器在拥有更高计算效率的同时规避了数据存在问题可能引起的误差。
3.2 误差分析
上述改进方式克服了AWT-AdaBoost存在的问题,同时为了证明改进后算法准确度并没有下降,以下对该算法的误差进行分析。
假设Gm(x)为训练出的分类器,Gm(x)误差率计算公式如下:
(10)
其中训练器误差界为:

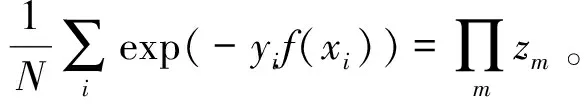
(11)
对于多分类问题,可以将其分为数个二分类问题的组合,因此对于二分类问题,
(12)
其中
(13)
根据式(13),若存在γ>0,则对所有m有γm≥γ,因此可得:

(14)
由式(14)可知,该学习器的误差率随着迭代次数呈指数下降。在式(8)的条件下,式(9)过滤后的样本个数明显大于式(8),因此使用式(9)进行计算需经过更多迭代。由此可得出,本文提出的改进过滤型裁剪方式拥有更小的误差率。
上述步骤虽然依靠过滤正确分类的样本减少了计算机的工作量,但在实际工业中样本不均衡的情况下会导致正确分类样本分布特征被忽略,增加了最终输出的学习器出现过拟合情况的可能性,为了避免这种情况,本文引入过采样随机生成权值因子对不均衡情况下的样本权值分布进行优化。
3.3 基于过采样随机思想生成权值因子
为了解决上述过程中样本匮乏导致AdaBoost迭代过程中可能会出现的过拟合问题,本文根据k近邻思想提出生成随机权值因子法则。k近邻思想是通过判断样本点周围k个样本点的种类,个数较多的类即为该样本点的种类。过程如下:
基于过程(3),此时正确分类的样本已经被过滤,统计每个样本点周围距离最近的k个同类型样本点,其中欧氏距离公式如下:
(15)
根据样本匮乏情况,k为近邻因子,其取值可以自由选择,为了保证随机生成的权值因子在增加模型泛化能力的同时不会影响数据特征,k的取值在3~10之间选择。如需要对k的取值进行准确评估,可以采用贝叶斯思想对其进行计算。

(16)
新增后的样本集为Dnew。
清洗Dnew的权值分布,对Dnew中每个样本点按照如下公式赋予权值:
(17)
其中:derror(i)为Derror中的样本权值;dnew(i)为清洗后每个样本的权值;zn为规范化因子,用于清洗权值,保证当前样本权值之和为1。
对清洗后的权值分布利用AdaBoost进行迭代计算,当εn≥0.5且n>1时停止迭代,取N=n-1时刻的弱分类器组合作为最终输出的结果。
在该集成算法中,错误样本越多,AdaBoost分类效果越好,因此该随机权值因子生成法则下的改进算法拥有更好的泛化性,在面对实际工业生产数据时能体现出更好的分类效果。
基于上述步骤,随机生成的权值因子使得使用改进AdaBoost算法时不再出现由于样本不均衡、少数类样本匮乏[21]而出现各种误差的问题,同时也可以避免因样本数量不足或裁剪错分类样本权值过多影响少数类样本特征,从而导致出现误差。克服这些问题的COA-AdaBoost算法可以应用在实际工业中,准确高效地分析出设备健康状况从而预估设备剩余寿命。
传统AdaBoost一般用于处理二分类问题,但是在实际工业中,设备健康状况分类往往呈现出多分类趋势,因此需要将二分类COA-AdaBoost扩展成为能面向多分类问题的模型。针对分类器不能直接处理多分类问题的缺陷,常用的方法有OAA(one-against-all)法、ECOC(error correcting output codes)法、OAO(one against one)法等。本文采取类似OAO方法克服上述缺陷,将多分类问题两两组合。若本文设备呈现出k个状态,则根据样本构建k(k-1)/2个分类器,即k(k-1)/2个改进AdaBoost模型。
在COA-AdaBoost算法下,通过改进权值裁剪公式使其在二分类情况下拥有更小的误差率,同时为了避免样本过小以及样本不均衡导致分类器分类效果较差等情况,通过设置随机权值因子使得最终输出的分类器在面对不同种类下的实际数据时拥有更高的精度及泛化性。
3.4 基于COA-AdaBoost算法的健康预测流程
基于COA-AdaBoost算法的健康预测流程如图2所示。

图2 基于COA-AdaBoost设备健康预测流程图
具体步骤如下:
步骤1收集设备状态数据作为样本D。
步骤2输入样本D,引入AdaBoost分布样本权值。
步骤3根据权值分布按照式(8)设置裁剪过滤系数T(maxn),过滤被正确分类的样本集,得到新样本集Derror。
步骤4根据样本不均衡情况设置近邻因子k。
步骤5按照式(10)新增权值因子,此时样本集为Dnew。
步骤6按照式(11)清洗Dnew中样本权值,得到一组新的权值分布。
步骤7调用AdaBoost中弱学习器,更新权值分布,计算错误率。
步骤8判断是否满足迭代停止条件,若满足则输出最终结果,若不满足则返回步骤7。
4 算例分析
4.1 数据来源
设备寿命预测方法为观察并采集实验设备或投入工作的设备的关键数据,以此建立关键值分布,并引入人工智能算法对其进行健康状态分析,从而拟合出设备关于时间的寿命预测曲线。本文使用来自美国卡特彼勒公司液压泵的振动状态数据进行研究,以验证COA-AdaBoost算法在实际工业中的有效性。液压泵设备状态主要以每隔10 min进行一次约1 min的振动频率收集的数据体现。其中,设备的振动频率为液压泵各个不同方向上的振动频率,一共针对32个方向进行了长达680 min的数据收集,每10 min对设备的健康成长趋势对进行一次检测。后续的RMS(root mean square)时间节点间隔也为10 min。根据对设备的检测,目前收集到的状态数据有“好”、“中”、“差”、“坏”4个阶段,其中,“坏”状态的设备具有很高的故障风险。为了证明该模型的可用性,本文将收集到的32组数据分为496组二维数据,并随机挑选一组数据进行展示以分析该算法的可行性。
4.2 状态分析
本实验中经过测算和分析,液压泵状态可分为“好”、“中”、“差”、“坏”4个阶段。本文随机选取约2/3的数据用于训练弱分类器KNN模型,其余约1/3的数据用于测试每轮迭代弱分类器正确率。其中每种阶段状态的样本个数如表1所示。

表1 液压泵各状态数据分布情况表
此时一共有68个样本,其中损坏样本个数为10。在实际工业设备状态问题中,处于“坏”状态的设备无法继续服役,因此本文将“好”、“中”、“差”状态的数据归类为1,“坏”状态数据归类为0,以下弱分类器着重对上述样本点进行0-1二分类处理。
对数据进行二分类与训练集分类后的结果如表2所示。

表2 液压泵损坏情况及数据集分布表
进行第一次迭代处理,本文使用处理二分类问题效果较好的KNN算法作为AdaBoost中的弱学习器,k取3,如表3所示为测试集第一次迭代后的结果。
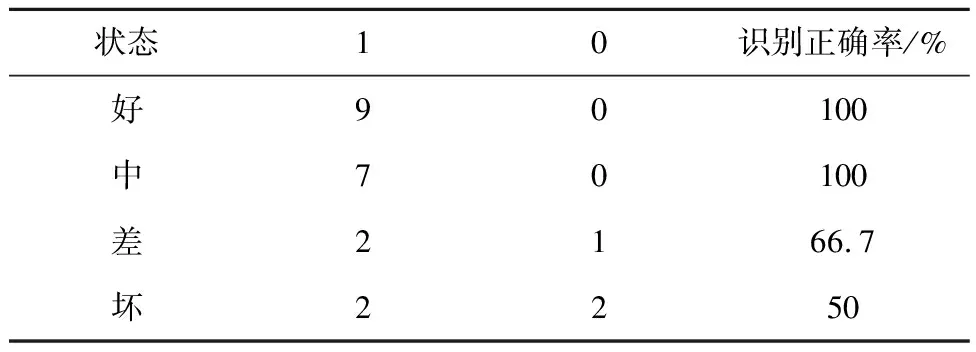
表3 首轮迭代正确率分布表
显然,由于样本匮乏以及数据不平衡的影响,模型在各个阶段的识别正确率很低,无法达到实际工业要求。此时引入AdaBoost更新权值分布,更新后的权值分布如表4所示。
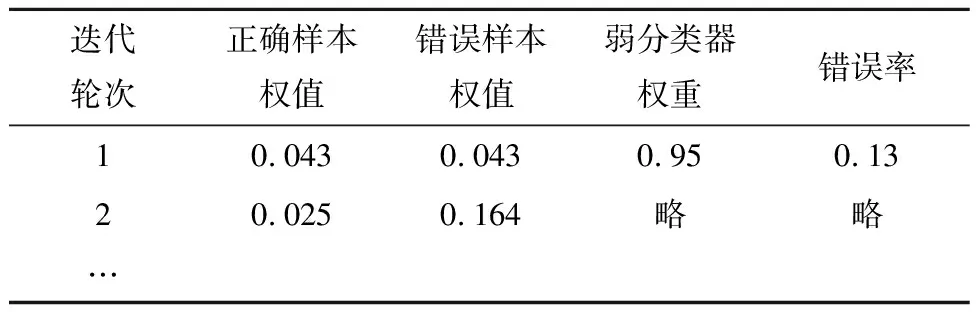
表4 AdaBoost迭代参数分布表
此时根据式(8)可得T(maxn)=0.164,此时Derror={(x1,y1),(x2,y2),(x3,y3)}。
根据式(9)引入新增因子,因此时Derror只有3个样本点,无法将近邻因子k设置为超过2的数,因此需要添加一轮迭代过程。
首先设置近邻因子k=2,样本集更新为D1。在D1内再次根据式(9)新增近邻因子,设置近邻因子k=1,此时生成Dnew,Dnew={(x1,y1),(x2,y2),(x3,y3),…,(x12,y12)}。此时生成新的权值分布,根据式(10),新样本初始权值dnew(i)=0.083,i={1,2,3,…,12}。
重新调用AdaBoost,改进AdaBoost迭代参数如表5所示。
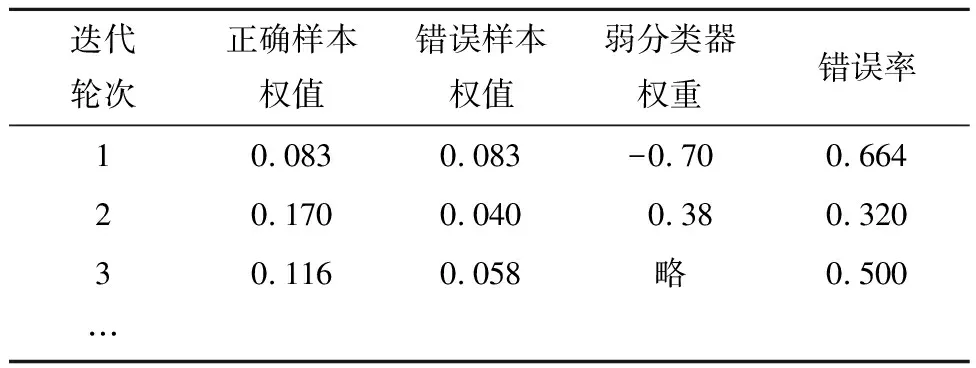
表5 改进AdaBoost迭代参数分布表
此时输出最终改进后的分类器:
(18)
其中an={-0.7,0.38}。
由于文献[8]提出的SWT-AdaBoost、文献[9]提出的DWT-AdaBoost和文献[10]提出的AWT-AdaBoost无法直接处理小样本不均衡数据,本文的结果比较部分无法展示上述算法的优劣性,因此在模型识别准确度比较部分着重展示本文提出的COA-AdaBoost与传统机器学习算法的准确度对比。
由于AdaBoost包含加权系数,错误率并不能用常规方法计算。本文计算AdaBoost与COA-AdaBoost算法错误率遵循以下公式:
(19)
对比结果如表6所示。
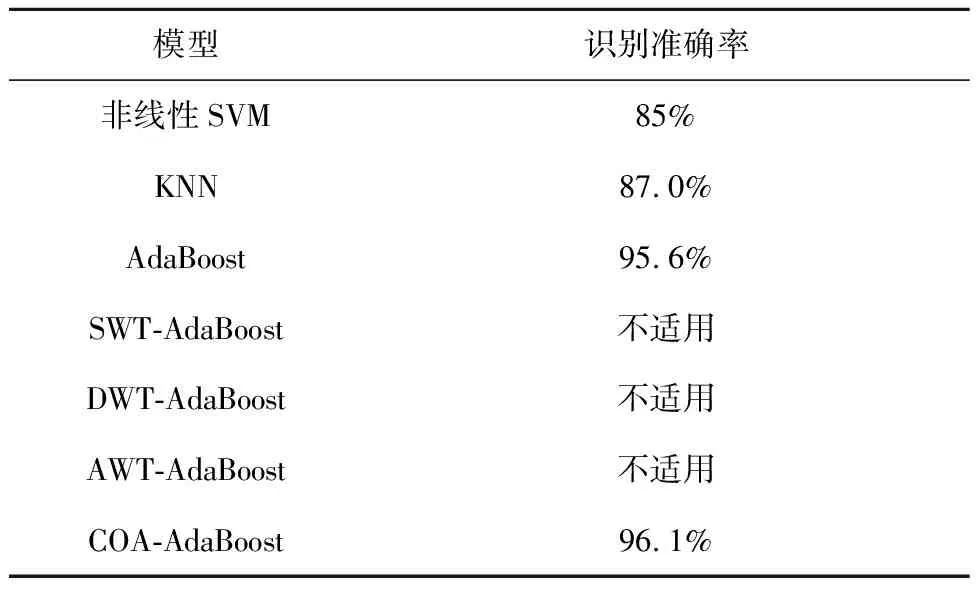
表6 几种模型对设备状态识别准确度比较表

表7 COA-AdaBoost与传统AdaBoost正确率比较表 %
由上述结果可以看出,在该样本数据下集成算法拥有更高的准确度,为了体现COA-AdaBoost算法的优越性,以下在剩下的样本点中随机抽取3组样本使用COA-AdaBoost算法和传统AdaBoost算法进行比较,并将综合正确率进行展示:
COA-AdaBoost算法的计算速率通过迭代次数体现,迭代次数越少,计算速率越快。经过统计,4组数据传统AdaBoost的迭代平均次数为3.25,COA-AdaBoost的平均迭代次数为2,优于传统AdaBoost。
通过上述结果可以计算出,本文提出的COA-AdaBoost在准确性方面优于传统机器学习算法,相比传统AdaBoost正确率提高了2.8%,同时克服了文献[8]的SWT-AdaBoost、文献[9]的DWT-AdaBoost、文献[10]的AWT-AdaBoost无法处理小样本不均衡数据的缺陷。基于上述模型的优点,在计算时间方面,由于本文通过设置改进裁剪阈值并修改了迭代条件,相比传统AdaBoost,本文提出的COA-AdaBoost在计算时经历的迭代次数更少,能在低次数的迭代条件下对小样本不平衡数据进行计算,准确分析出设备目前所处的工作状态以判断设备是否能够继续服役。
4.3 寿命预测
本文的实验数据中,液压泵的振动数据即为能够反映该设备健康状态的关键数据。因此,可以通过记录设备振动数据计算RMS,从而迅速得到服役设备的劳损情况,以判断该设备是否可以继续使用。振动方根均值计算公式如下:
(20)
此时将液压泵状态分析部分挑选的液压泵振动数据代入并计算,如图3所示为该实验设备振动数据的RMS随时间的变化趋势。
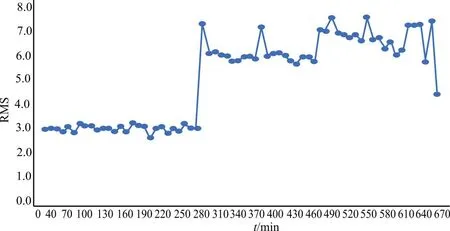
图3 设备数据RMS趋势图
该数据点分布不仅为状态从“好”到“坏”的样本点分布,同时也是遵循设备年龄的时间描述。
根据状态分析部分的实验数据标签以及图3内容可知,处于“坏”状态的样本个数为10,同时这些样本的RMS全部高于7,时间节点为第280 min。因此可以判断,当RMS高于7时,实验设备进入“坏”状态,此时的设备存在故障风险,为设备健康转折点,设备在此时进入健康衰退期。因此,本文提取RMS高于7的点进行寿命预测。此时设备振动点位RMS分布如图4所示。
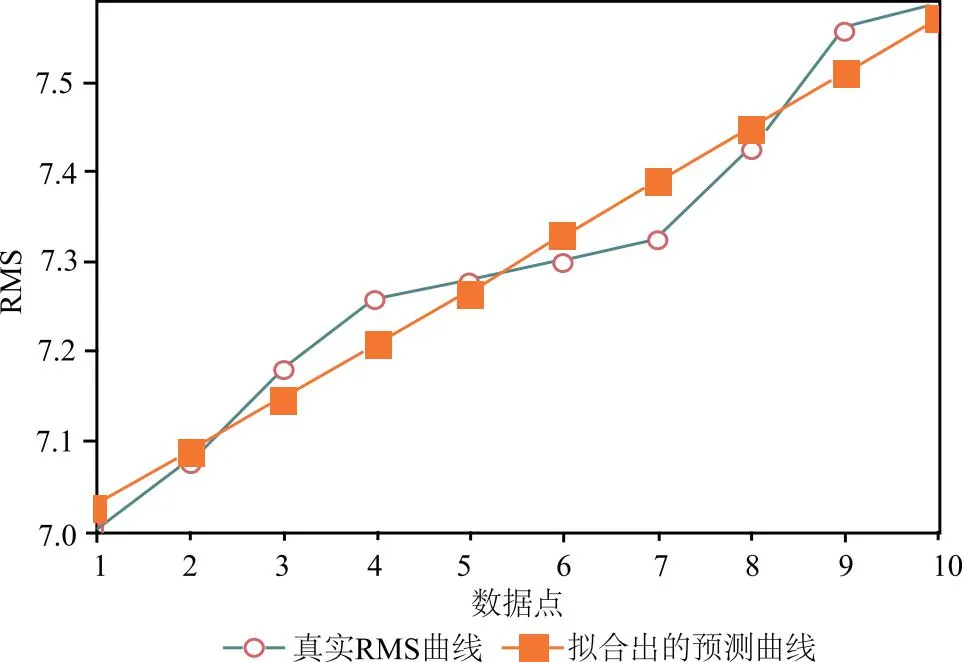
图4 真实RMS与预测值对比图
根据图4所示的RMS数据计算对应数据点下的设备剩余寿命,设备RUL真实值与预测值结果如图5所示。

图5 真实RUL与预测值对比图
根据预测值进行计算可得本文提出的模型对“坏”状态下的RUL预测平均误差值为23.2 min,满足一定条件下实际工业中企业对设备寿命的预判要求。
由图4与图5,通过预测设备RMS发展趋势和设备RUL可知,本文提出的COA-AdaBoost算法面对小样本不均衡数据,不仅在状态分析上优于传统机器学习算法,弥补有些算法无法面向此类数据的问题,同时也可以很好地预测出未来设备寿命曲线。在实际工业生产过程中,根据预测的寿命趋势可以迅速判断设备剩余寿命,为设备是否继续服役以及何时替换提供参考依据。
在本文的设备寿命预测算例中,通过实验可知当设备的RMS超过7.3时,该液压泵振动频率已经超载,因此存在过大故障风险无法继续服役,此时液压泵累计运行时间为560 min,预测寿命剩余约120 min。通过拟合出的设备RUL预测曲线可以得到在RMS大于7.3时设备的剩余寿命发展趋势,为企业何时替换该型号的液压泵提供参考依据。
5 结束语
针对AdaBoost、SWT-AdaBoost、DWT-AdaBoost、AWT-AdaBoost在提升弱学习器计算效率的同时无法处理小样本不均衡数据的问题,通过改进权值裁剪方程减少组合学习器在计算过程中的迭代次数,并结合传统AdaBoost的迭代停止条件最大程度地提高计算速率。针对小样本不均衡数据可能引起的过拟合问题,通过类似k近邻思想引入过采样随机权值生成因子增加迭代过程中弱学习器的泛化能力,后通过引入规范化因子清晰权值以规避该问题的发生。在仿真阶段,分别使用非线性SVM、KNN、AdaBoost以及COA-AdaBoost对4组实验数据的液压泵状态进行分析,计算结果表明,基于COA-AdaBoost的寿命健康预测模型拥有更好的状态分析能力,同时也可以准确预测出设备在未来一段时间的寿命发展趋势。本文提出的改进模型主要目的是克服实际工业生产中可能出现的收集到的样本容量过小、分布不均衡的问题,只面向小样本不均衡数据,在面对大样本分布均衡的数据时并不适用。未来的研究方向是通过联合更多的机器学习算法将COA-AdaBoost适用范围提升到更大规模的样本数据。
