基于WGKSOM-DRCA自适应即时学习的转炉炼钢终点碳温软测量方法
2024-02-21陈棕鑫陈甫刚刘建勋
陈棕鑫,刘 辉+,陈甫刚,刘建勋
(1.昆明理工大学 信息工程与自动化学院,云南 昆明 650500; 2.昆明理工大学 云南省人工智能重点实验室,云南 昆明 650500;3.云南昆钢电子信息科技有限公司,云南 昆明 650302)
0 引言
钢铁产业作为国民经济的重要支柱,在国家工业和社会经济发展中具有举足轻重的地位,转炉炼钢因为其高效和低成本的优势,是目前世界上采用的主要炼钢方式之一[1]。在转炉炼钢生产过程中,终点控制是实现炼钢的重要环节,而转炉终点的碳含量和温度则是判断转炉中钢液是否达到出钢标准的重要指标。因此,实现对转炉终点碳含量和温度的准确预测对于提高炼钢效率,降低钢铁生产成本以及节能减排、保护环境都有着重要的意义。
传统的转炉炼钢过程是将高炉来的铁水经混铁炉混匀后兑入转炉,并按一定比例装入废钢、石灰石、焦炭等原料,然后以一定的供氧、枪位和造渣制度吹氧冶炼,当达到吹炼终点时,化验钢水成分是否达到目标值范围,达到即可出钢,否则,降下氧枪补充反应物进行再吹。目前,转炉炼钢的方法包括:①传统的人工经验法,即由经验丰富的钢厂工人根据冶炼时间和观察转炉炉口火焰情况判断出钢时机;②副枪检测法[2-3],即利用专门的探头和测量工具直接检测熔池内钢液的成分。随着技术的发展,也出现了诸如火焰图像分析法[4-6],即通过提取拍摄的转炉炉口火焰图像的颜色、纹理、火焰的边界和形状特征完成终点判断,以及光谱图像分析法[7-9],利用光谱分析仪采集火焰光谱图像分析光谱辐射状态等方法,但以上这些方法却存在受人工因素影响大、设备使用和维护成本高、火焰图像关键信息提取困难、光谱设备容易受到现场钢包等高温物体的严重干扰等问题,这些问题都对转炉炼钢生产造成了极大的挑战,也限制了相应技术的推广应用。
实际上,随着近年来计算机技术的发展和工业智能化检测水平的提高,将软测量技术应用于转炉炼钢终点碳温预测成为了可能,通过研究转炉炼钢生产过程中加入的铁水、废钢、吹氧量、石灰石量、焦炭量等过程辅助变量与钢液的终点碳含量和温度之间存在的非线性关系,建立过程辅助变量和终点碳温之间的软测量模型从而完成对终点碳温的预测[10-11]。例如,谢书明等[12]利用径向基神经网络建立终点碳温预测模型,克服了传统方法受限于边界信息确定相关参数的不足;ZHOU等[13-14]结合多输出偏最小二乘支持向量回归方法,实现对于非线性的转炉炼钢终点碳温的预测;QI等[15]提出对转炉生产过程数据进行特征选择以降低数据冗余,保留与终点碳温最相关的特征用于预测,并通过实验验证了该方案的合理性。以上研究对于软测量技术在转炉炼钢终点碳温预测方面进行了有益的探索,但在实际工业生产过程中,由于用于炼钢的原材料品质的不同,数据采集设备的偏差,人工记录的误差等等因素的影响,采集到的转炉炼钢生产过程数据往往存在较大波动,而基于历史数据建立的全局软测量预测模型因为无法进行在线更新,导致在复杂工况下,模型对于终点碳温的预测性能受到极大削弱。
考虑到建立全局软测量模型在解决复杂工业过程数据问题上的局限性,近年来将即时学习(Just-in-Time Learning,JITL)的思想引入到软测量建模中得到了广泛关注[16-19]。JITL作为一种以相似输入产生相似输出原则的建模机制,对任意一个待预测样本,通过从历史库数据中度量与其相似的局部样本构成算法学习集,进而建立局部预测模型完成预测。由此可见,利用即时学习方法建立软测量模型的关键在于构建合适的相似度度量准则。例如,陆荣秀等[20]考虑到输入和输出的相关性,提出了互信息加权的相似性度量方案用于获取更加合理的局部样本建立模型;祁成等[21]针对传统一阶度量方案的不足,提出了二阶相似性度量策略,选择与待测样本更近邻的训练样本;牛大鹏等[22]通过将时间有序性引入到即时学习中用于确定建模邻域以提高模型的预测精度。此外,在已有的研究中,选择在建立即时学习预测模型前使用聚类算法对工业过程历史数据进行聚类,被证明可以较好地克服工业过程数据波动对于模型的影响[23-25]。例如,FAN等[23]通过高斯混合模型对历史数据进行训练并将训练结果用于马氏距离的加权,而后再进行相似性度量;QI等[24]则提出了基于VMF混合模型(Von-Mises Fisher mixture model)和将采用V形函数加权的极限学习机的即时学习模型用于解决转炉炼钢中的时变和数据不平衡问题,并取得了明显效果;刘辉等[25]则将加权灰色关联度与模糊C聚类方法相结合建立即时学习软测量模型,提高了即时学习模型的预测精度。虽然前人对于转炉炼钢的研究进行了一些有益的探索,但传统的即时学习模型依然无法有效克服数据波动对于模型性能的削弱,而采用聚类后建立即时学习模型的方案往往又忽略了标签信息的重要价值,以及从单一类簇中选择固定个数样本构造局部算法学习集对复杂数据的适应性不佳。
针对以上问题,本文提出一种基于加权高斯核自组织映射动态相关成分分析(Weighted Gaussian Kernel Self Organization Map Dynamic Relevant Component Analysis,WGKSOM-DRCA)自适应即时学习的软测量建模方法用于转炉炼钢终点碳温的预测。该方法通过将融入标签信息加权的高斯核函数度量策略与SOM聚类算法结合,实现在聚类过程中有标签信息参与对聚类方向的引导;同时,采用高斯后验概率计算待测样本的隶属度,并引入动态因子构建DRCA度量策略,实现从多个类簇中自适应选择与待测样本匹配的局部算法学习集样本,最终建立预测模型完成预测。实验结果表明,本文所提算法可以在线自适应灵活地选择与当前待测样本更加匹配的样本构成局部算法学习集,并建立局部预测模型,进而实现对于转炉炼钢终点碳温的实时预测,克服了转炉炼钢工业过程数据波动性大造成的传统即时学习软测量模型度量的算法学习集质量差和碳温预测性能的不足,有效提高了模型对转炉炼钢终点碳温的预测精度。
1 WGKSOM-DRCA自适应即时学习软测量建模方法
本文针对转炉炼钢生产过程数据存在的波动性和非线性特点造成传统即时学习策略无法选择到与待测样本匹配的局部算法学习集的问题,提出一种WGKSOM-DRCA自适应即时学习软测量建模方法:首先,通过引入标签信息的WGKSOM算法对历史样本进行聚类,使相似样本聚拢,不相似样本远离,降低类内数据波动性;其次,使用DRCA度量策略,对待测样本进行自适应的样本选择,构建与待测样本更加匹配的算法学习集,并用于局部预测模型的训练,从而实现对转炉炼钢终点碳温的预测。该方法整体思路流程如图1所示。

图1 本文思路流程图
1.1 WGKSOM算法的样本聚类策略
自组织映射(Self Organization Map,SOM)神经网络是一种模拟人类大脑映射学习功能的无监督神经网络聚类算法[26-28],通过在神经元之间进行横向抑制连接,使竞争层神经元根据输入层数据映射特点进行有序调整完成聚类。
实验表明,针对转炉炼钢这类本身具有较强波动性和非线性特点的工业过程数据,目前在SOM算法中普遍使用的线性度量策略,如欧式距离,并不能很好地实现对转炉炼钢生产过程数据的有效度量,因此难以有效完成对过程数据聚类的目的。根据模式识别理论,低维空间线性不可分的数据可以通过非线性映射到高维特征空间从而实现线性可分,利用高斯核函数代替SOM算法中的传统欧式距离可以实现更好的度量,再通过引入转炉标签信息,则可以进一步提升算法的聚类效果。因此,本文在考虑到转炉炼钢过程数据中各维度特征对于终点碳温结果的贡献程度不同的情况下,提出一种融合转炉终点碳温标签信息的加权高斯核度量准则(Weighted Gaussian Kernel,WGK)用于SOM聚类算法的改进,通过强化训练数据中与终点碳温关联度更高的辅助变量,使度量结果更加倾向于与实际标签值更为相关的方向,从而降低数据波动性对度量策略的影响,进而提升其对转炉炼钢生产过程数据的聚类效果,其计算公式如下:
WGK(xi,wk)=exp[-Z(xi,wk)/2δ2];
(1)
(2)
其中:xih表示输入向量xi第h维特征;wkh表示第k个竞争层神经元权值向量的第h维的权值;wgh表示全局加权系数第h维的权值;δ表示高斯核函数的作用范围;WGK(xi,wk)值越大,表明输入样本与竞争层神经元越匹配。
在使用WGK度量准则进行度量时,首先,需要确定WGK度量准则中的全局加权系数wgh,该加权系数使得转炉过程数据中与输出碳温结果更相关的特征得到强化,定义如下:
定义1皮尔逊相关系数加权准则。
(1)计算历史库中样本输入的各维度特征与输出结果之间的皮尔逊相关系数(Pearson Correlation Coefficient,PCCs),则第h维输入特征xh与输出y的计算由式(3)所示:
(3)
其中:cov(xh,y)表示输入样本集X第h维特征xh和输出结果y的协方差,m表示输入样本集的特征维数,σ*表示计算该变量的标准差。
(2)在式(3)的基础上计算输入各维度与终点碳温的相关性,再进一步计算即可得到加权权值wg={wg1,wg2,…,wgm}。
(4)
因此,将所提出的WGK度量准则用于改进SOM算法的最佳匹配神经元的判断过程,强化过程数据中与输出碳温标签结果更相关的特征,使得聚类过程偏向于与实际标签更加接近的方向,从而提升对转炉炼钢生产过程数据进行聚类的效果,WGKSOM算法具体步骤如下:
步骤1随机初始化竞争层每个神经元节点的权值向量wk(k=1,2,…,n),其中n为竞争层神经元节点的数目,同时,每个神经元节点具有与输入数据相同h维的权值wkh;
步骤2在第t次迭代中,从训练集中随机选择一个训练样本x(t)作为输入,计算其与所有竞争层神经元权值向量的相似度,与其最为相似的神经元节点即为获胜节点,记为当前训练样本最佳匹配单元(Best Match Neuron,BMU),其计算公式如下:
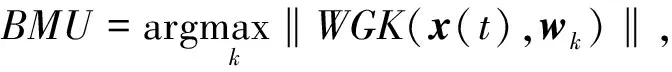
k∈(1,…,n)。
(5)
其中:xi(t)∈X为输入训练样本向量;n为神经元节点数;WGK度量准则的计算如式(1)所示,由于在选择最佳匹配单元时引入了标签信息,使得数据中与标签更相关的特点得到强化,有效克服了数据高维度和波动性造成的度量失效问题,使得WGKSOM算法能够取得更符合实际需求的聚类效果。
步骤3获胜神经元节点及其邻域节点集合记为NBMU(由邻域函数hiBMU判断),然后以训练样本为参照,对NBMU范围内的神经元节点进行权值更新,更新公式如下:
wi(t+1)=
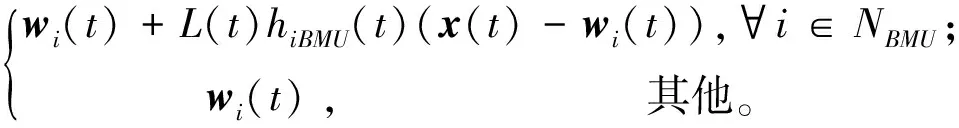
(6)
其中:t表示当前迭代次数,L(t)为当前学习率,hiBMU(t)为邻域函数,学习率L(t)和邻域函数hiBMU(t)均随时间推移单调递减,L(t)的计算如下:
(7)
其中:L0∈[0,1]为初始学习率;T为WGKSOM算法训练迭代次数总和;
hiBMU(t)为在t时刻获胜神经元BMU周围的邻域函数,表示神经元i到获胜神经元BMU的距离,公式如下:
(8)
(9)
其中:Posi表示邻域神经元i的坐标,PosBMU表示获胜神经元的坐标,r(t)为邻域半径,随训练过程单调递减,r0为初始邻域半径。
1.2 基于DRCA度量策略的局部算法学习集样本自适应选择
传统上在聚类结束后,对于待测样本和各聚类类簇的隶属关系,往往单一地与类簇中心进行相似性度量,选择最相似的一个类簇数据作为后续操作的对象,但这种聚类后再从单一类簇中选择固定个数样本子集建立局部模型的策略,往往会因为样本选择的针对性不足的问题(例如:单一类簇的限制、局部算法学习集样本数目固定、待测样本类别判断误差等),造成选择的样本构成的局部算法学习集质量不佳,从而导致模型的预测精度不理想。因此,本文通过计算转炉炼钢待测样本的高斯后验概率并引入动态因子,根据不同待测样本的特点,从多个类簇中进行自适应的样本选择构成算法学习集,使得样本选择更具针对性,从而提升局部训练算法学习集的质量,进而提升模型训练质量和对终点碳温的预测效果,其算法示意图如图2所示。

图2 WGKSOM-DRCA算法图
每个待测样本的自适应算法学习集大小由式(10)确定:
N(xq,X)=Dynum(|Pcc(xq,xi)|≥e),
xi∈X。
(10)
其中:xi∈X,表示历史库中的样本;e为动态因子,用于自适应调节局部算法学习集的规模,e越大,局部算法学习集越小,反之,局部算法学习集越大,Pcc(xq,xi)表示计算xq和xi的皮尔逊相关系数,计算公式如式(3)所示,Dynum(*)函数计算得到待测样本与历史库样本结果满足动态因子条件的样本规模作为该待测样本自适应算法学习集的规模。
算法学习集中的样本从各类簇中进行选择,而各类簇的样本子集规模由式(11)确定:
Nk(xq,Xk)=N×Pk,k∈(1,C)。
(11)
其中:N为待测样本xq对应的局部算法学习集大小(由式(10)计算得到),Pk为xq与第k类样本集的高斯后验概率值,其计算公式如下:
Pk(xq|uk,Σk)=
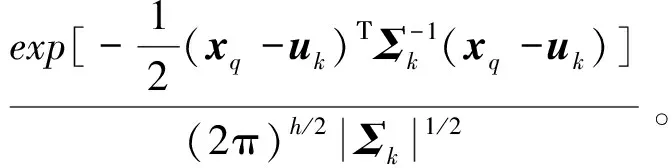
(12)
其中:Pk代表待测样本xq与第k个簇的高斯后验概率,h表示输入样本的特征维数,uk表示第k个簇的均值,Σk表示第k个簇的协方差矩阵。
经过WGKSOM对历史库样本聚类后,每个类簇中样本变化会使各类簇具有不同的特点,而相关成分分析法(Relevant Component Analysis,RCA)作为一种简单有效的度量学习算法,将其用于训练聚类完成后满足不同类簇特点的度量策略,对于提高局部样本质量和模型预报效果将起到积极作用,其计算公式如下:
(13)
(14)

从图2中可以看出,对于一个待测样本xq,通过计算其与每个类簇的高斯后验概率,并与训练得到的局部类簇DRCAk(k=1,2,…,C)度量策略相结合,即可实现根据当前待测样本特点从各个类簇中自适应选择N×Pk(k=1,2,…,C)个样本构成对应待测样本的局部算法学习集,进而用于模型训练,完成对当前待测数据对应终点碳温的预测任务。
2 基于WGKSOM-DRCA的转炉炼钢终点碳温软测量建模
JITL策略的关键在于相似输入产生相似输出的思想,为了选择与待测样本相似的算法学习集,合适的度量策略就显得尤为重要。因此,本文针对转炉炼钢生产过程数据的特点,提出了WGKSOM-DRCA自适应即时学习软测量方法用于转炉炼钢终点碳含量和温度等关键变量的预测。
在离线训练阶段,利用所提出的WGKSOM聚类算法对转炉炼钢历史数据集进行聚类处理,使得聚类结果呈现较好的类内样本距离小而类间样本距离大的状态;当进行在线预测时,通过计算待测样本同各聚类类簇的高斯后验概率,再利用动态因子和相关成分分析构建的DRCA度量策略动态确定当前待测样本所需的局部算法学习集规模,并从各类簇中自适应度量选取最匹配的样本构成局部算法学习集,用于训练极限学习机回归预测模型,最后输出当前待测样本对应的终点碳温预测结果。当有新的待测样本到来时,重复进行在线步骤获取新的局部算法学习集对模型进行训练更新。WGKSOM-DRCA算法的流程如图3所示。
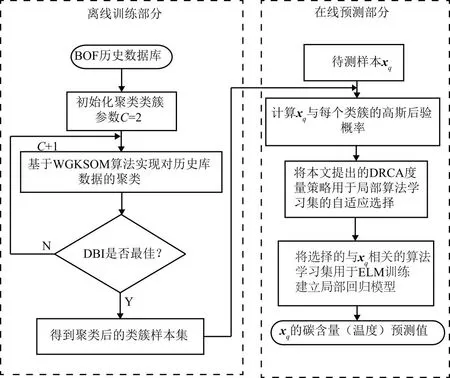
图3 算法流程图
3 实验结果及分析
3.1 实验数据
在转炉炼钢生产过程中,转炉中钢液终点温度和碳含量两个指标决定了转炉是否达到出钢的条件,因此转炉终点碳含量和温度被作为本文所提软测量模型预测的主要对象。本文所使用的转炉炼钢生产过程数据全部来自实际钢厂在生产过程中采集的数据,具有一定的工业过程数据代表性和实际研究价值。原始采集的过程数据包括铁水温度、各种矿物含量、各氧枪吹氧量等共126维辅助变量特征数据,为了构建软测量模型,通过特征选择的方式排除冗余特征,最后得到了与终点碳温最相关的6个辅助变量作为软测量建模的输入特征,输出则对应该炉次的终点碳含量和温度。如表1所示为本次实验所使用的转炉数据,本次实验总共采集了10 400炉次的样本,碳含量和温度各共有5 200炉次的样本,在各自两个类别中,5 000炉次为训练样本,200炉次为测试样本。
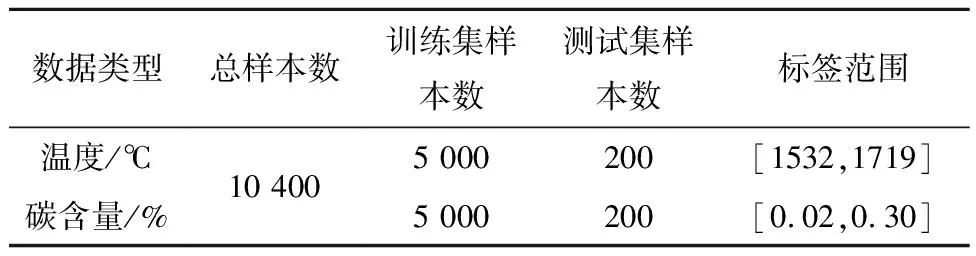
表1 实验数据情况
本文中所有实验均在Windows 10系统的 Python 3.6,Pycharm 2018平台上完成,实验结果都已调整到最优参数。本文所提出WGKSOM-DRCA算法的参数设置如表2所示。
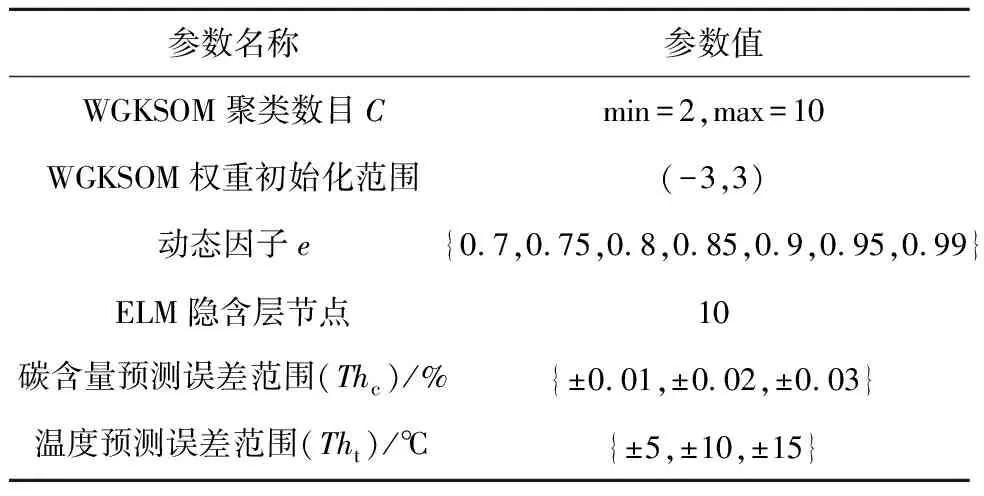
表2 实验参数设置
3.2 评价指标
为了评价本文所提出的WGKSOM-DRCA软测量算法和传统的JITL度量软测量策略[18],JITL-LSSVM[22],GMM-MD[23],WGRA-FCM[25],AP-MKPLS[29]等5个对比算法在转炉炼钢终点碳温上的预测效果,采用均方根误差(RMSE),平均绝对误差(MAE),碳含量和温度预测精度(PA)三个指标进行评价,其中RMSE和MAE的值越小,表明预测结果和实际标签越接近,该软测量模型在转炉终点碳温上的预测效果越好。各指标的计算方法如下:
(15)
(16)
(17)
其中:Ntest为测试样本的数量,ypre和ytest分别表示终点碳温预测值和真实标签值,PE的定义如式(18)所示:
(18)
其中Th为终点碳温预测允许的误差范围,可以根据不同精度要求进行调整,i=1,2,…,Ntest。
3.3 WGKSOM算法最佳聚类参数确定
在实验中,WGKSOM算法作为离线训练的部分,需要确定聚类参数C值,并且由于聚类参数和最终的聚类效果有着密切的关系,根据数据特点确定最佳的聚类参数C值对于后续的软测量模型的建立非常重要。
为了确定本文所提出的WGKSOM算法的最佳聚类参数,本文选择DBI(Davies-Bouldin index),CHI(Calinski-Harabasz index),SC(Silhouette Coefficient)三种聚类评价指标对WGKSOM算法的聚类效果进行评价。如表3所示为WGKSOM算法在不同的聚类参数C值下的聚类评价结果统计,从表中可以看出,DBI指标在碳含量和温度上的最小值分别为0.901和0.403,CHI指标在碳含量和温度上的最大值分别为511.526和543.304,SC指标在碳含量和温度上最接近1的值分别为0.093和0.098,相应结果即为该评价指标下的最佳聚类效果,因此综合以上3个指标结果可以看出,当碳含量和温度的聚类参数C值分别设为4和9时,WGKSOM算法在转炉炼钢生产过程数据上的效果最佳,该聚类结果的类内类间样本数据得到了最好的划分。
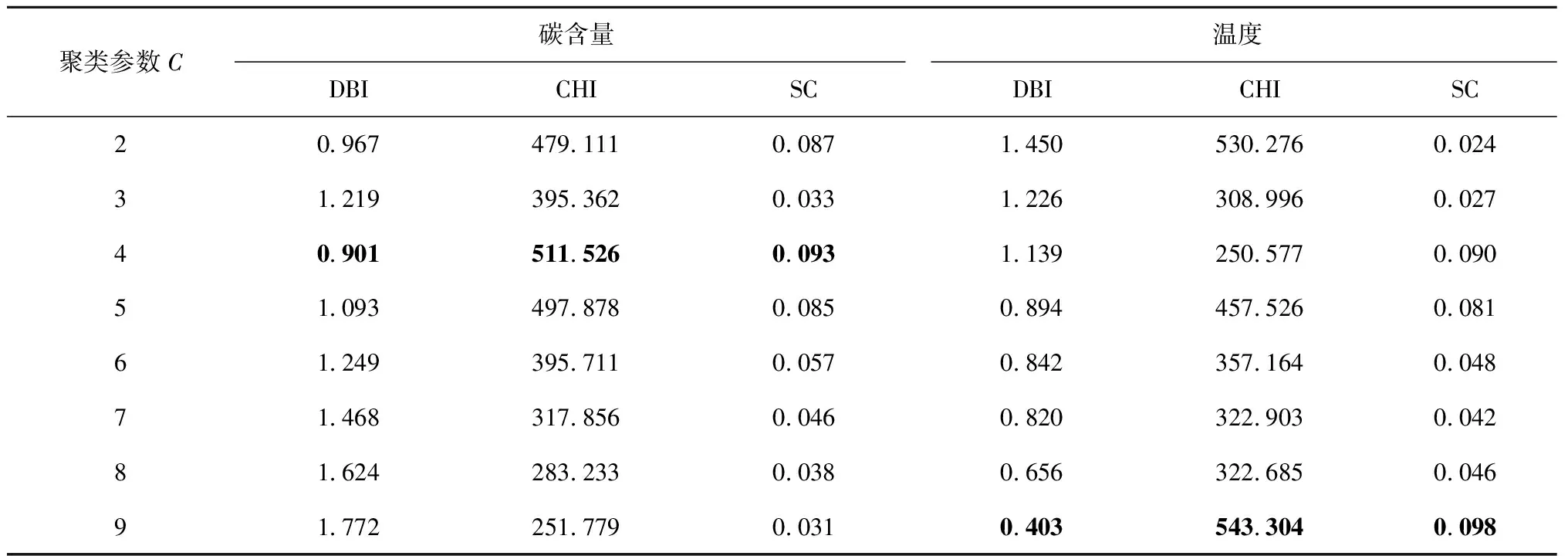
表3 不同聚类参数的聚类效果比较
3.4 动态因子对终点碳温预测结果的影响实验
本文所提出的WGKSOM-DRCA算法在在线预测终点碳温阶段,会根据当前样本的特点自适应确定局部算法学习集规模并建立回归预测模型,如式(10)中的说明,动态因子e对子集规模确定有着重要影响,因此,本节将确定动态因子最优参数。如图4所示,为不同动态因子下本文算法的预测性能展示,可以看出,当动态因子e=0.85时,软测量模型在终点温度的预测结果表现最好,动态因子为0.9时同样也有不错的表现;在碳含量方面,动态因子的设定与温度有所不同,由图中可以看出,当动态因子e=0.95时,模型在终点碳含量的预测结果要远远优于其他参数。
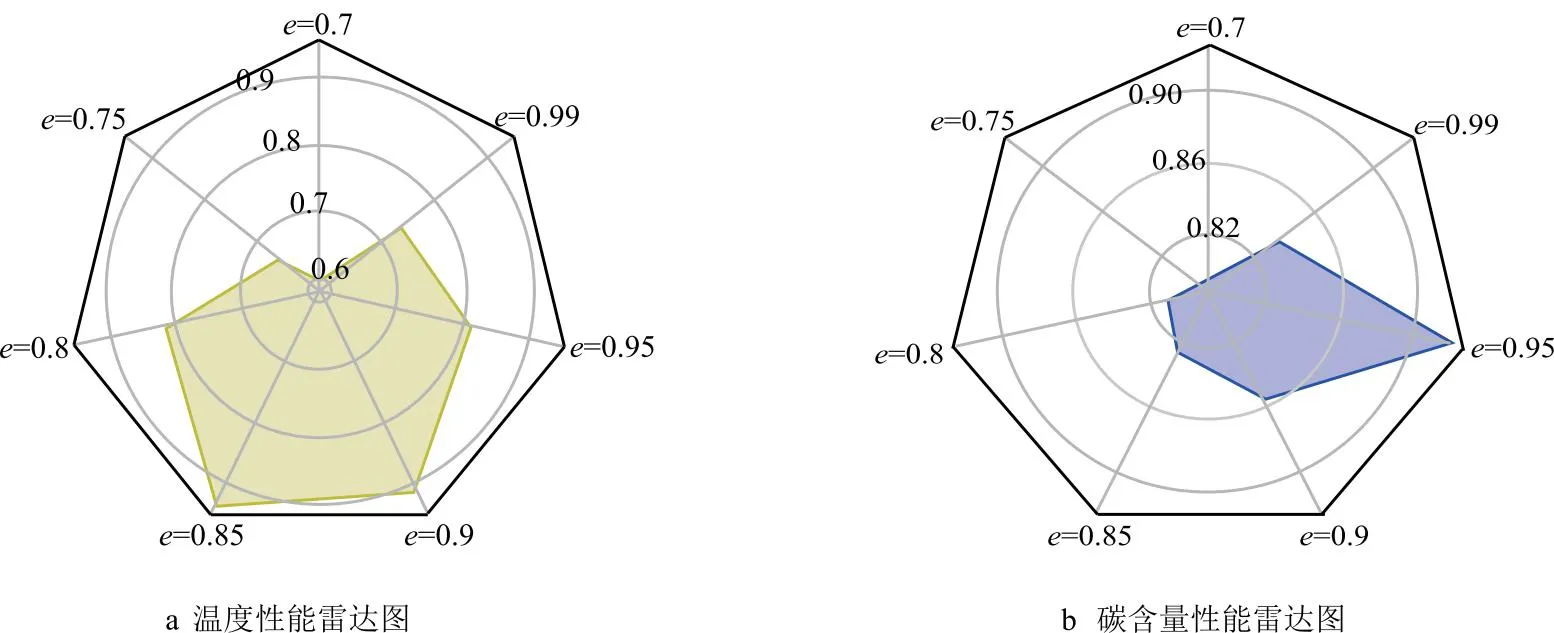
图4 本文方法不同动态因子的性能比较
如表4所示为不同动态因子下对应的终点碳含量和温度的预测评价指标结果。由表中可以看出,当温度的预测误差在±10℃范围内时,调整动态因子后的预测精度达到了93.5%,RMSE和MAE也分别达到了5.493和3.747;同样,在碳含量方面,当调整动态因子到e=0.95的最优参数时,模型能够取得最优的表现,终点碳含量的预测精度达到92%,对应的RMSE和MAE也分别达到了0.013 4和0.010 6。
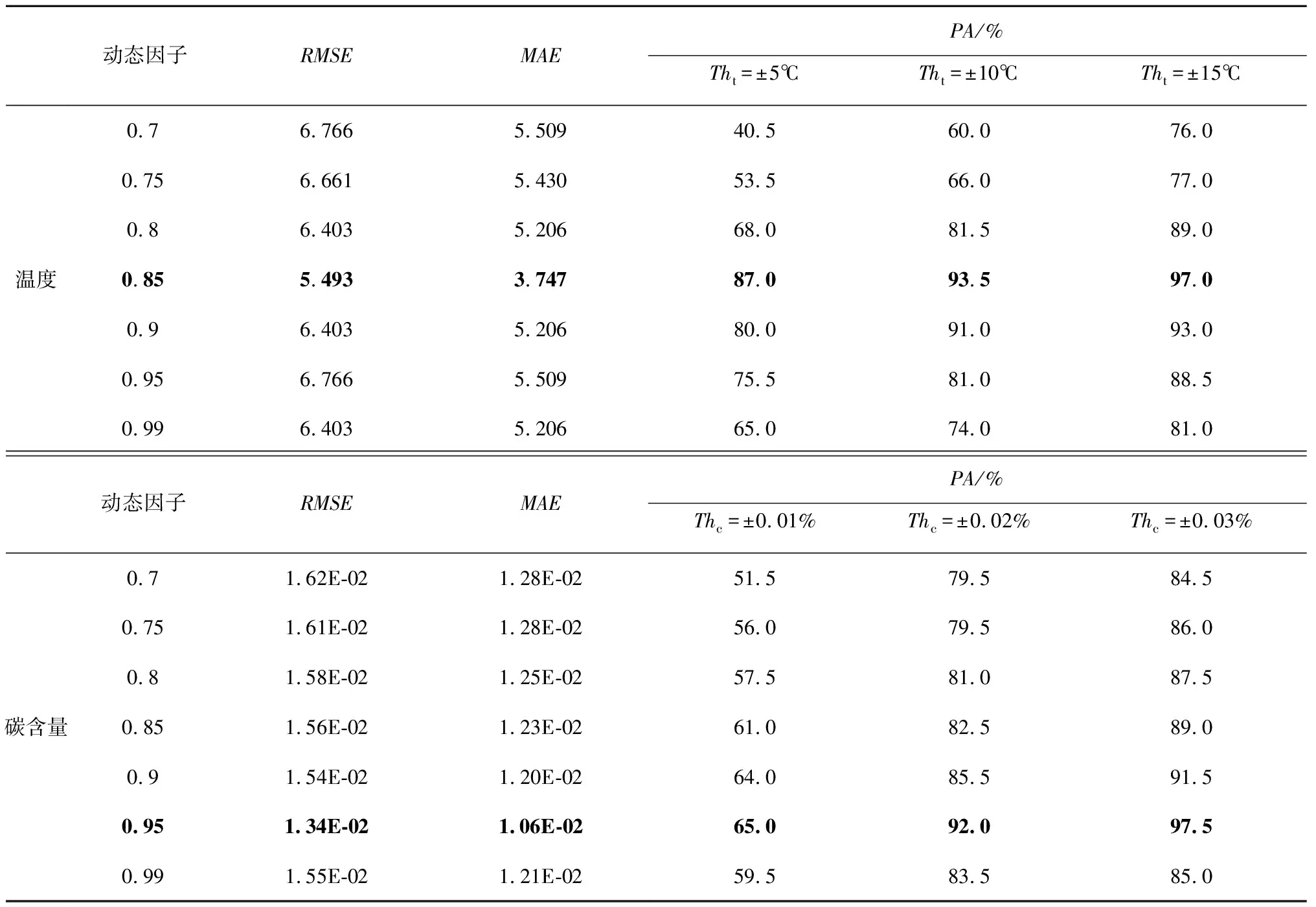
表4 动态因子对终点碳温预测结果的影响
3.5 WGKSOM-DRCA算法的消融对比实验
本文所提出的WGKSOM-DRCA算法针对传统聚类即使学习软测量方法在进行样本选择时存在的局限性问题,分别从聚类和即时学习样本选择两个部分进行了改进,有效提升了算法在进行转炉炼钢局部算法学习集样本选择的质量,进而提升了模型对终点碳温的预测效果。本节旨在通过对WGKSOM聚类算法和DRCA自适应样本选择策略进行消融实验,消融实验中的各个方法都独立运行10次,取其中表现最优的一次结果以及十次结果的平均值分析本文所提出的WGKSOM-DRCA算法的有效性。
如图5和表5所示,分别为本文算法在温度和碳含量上的消融实验结果对比图和预测结果统计对比表。从图中可以看出,所提出的WGKSOM聚类方法在聚类效果上相对于未改进的SOM聚类算法不论是在10次统计结果还是最优结果上都有明显提升,表现为通过对SOM-JITL算法中聚类部分的更新,WGKSOM-JITL算法在终点碳温的预测精度上有明显的提高;同样地,通过采用DRCA自适应样本选择策略,使SOM-DRCA算法在终点碳温的预测效果上提升的更多,说明DRCA自适应样本选择策略在算法的改进中发挥了重要的作用。最后,通过将WGKSOM聚类算法以及DRCA自适应样本选择策略相融合即构成了本文所提出的即使学习软测量方法,从表5中可以看出,其在针对终点碳温预测上的效果是几个方法中表现最好的,碳含量的预测精度相比于SOM-JITL方法的10次统计结果精度上分别提升了10%,16%,13.5%,最优预测精度上分别提升了19%,13%,9.5%,温度预测精度上10次统计结果精度提升了44%,18%,13%,最优预测精度则分别提升了43%,15.5%,10%,说明了本文通过引入标签信息和引入动态因子的自适应样本选择策略所提出的软测量方法在解决转炉炼钢终点碳温预测问题上的有效性,将两部分改进的结合是最佳方案。

表5 WGKSOM-DRCA算法的消融实验性能对比

图5 WGKSOM-DRCA算法的消融实验分析
通过以上实验,可以看出WGKSOM-DRCA软测量算法可以根据不同待测样本的特点,自适应地从不同聚类类簇中选择不同规模的局部样本作为回归模型的训练数据,使得模型更加具有针对性,在终点碳温的预测上的性能也得到最大化的体现。
3.6 与同类算法的性能比较
本节通过对比本文所提出的WGKSOM-DRCA算法与传统JITL度量策略,JITL-LSSVM,AP-MKPLS,WGRA-FCM,GMM-MD等5种软测量模型算法在转炉炼钢生产过程数据上对终点碳温预测的结果,进一步说明本文算法在解决转炉终点碳温预测问题上的有效性。
图6和图7分别为本文方法和对比算法的转炉终点温度和碳含量预测结果图。从图中可以看出,本文所提出的算法在终点碳含量和温度上的预测结果表现都是最好的。相比于改进前的SOM-JITL算法,本文通过引入WGK度量以及采用更符合待测样本的自适应局部样本选择策略,使得在原算法结构基础上的改进有了非常显著的提升,预测结果可以很好地跟随实际碳含量和标签的变化趋势。局部样本的方法有着更加明显的优势,也更加符合转炉炼钢生产过程数据本身的工业特点。

图6 本文方法与对比方法的终点温度预测结果对比
如表6所示为本文算法和对比算法在不同终点碳含量预测和温度预测精度上的3个评价指标的统计结果。由表6可以看出,本文方法在不同误差精度的终点碳温的预测结果上都要明显优于其他软测量建模方法,相对于对比算法中表现最好的GMM-MD,本文算法与其相比在温度的预测精度上分别超出了47%,18%,8%,而在RMSE和MAE两个指标上,本文算法则要更小,说明本文算法的预测结果与实际标签结果更加接近;在终点碳含量预测方面,本文的算法要比表现最优的算法的预测精度分别超出18%,10%,8.5%,在RMSE和MAE指标上,也是所有算法中最小的。因此,可以看到相比于对比算法,本文提出的WGKSOM-DRCA算法在转炉炼钢终点碳含量和温度的预测方面有着更好的性能表现。

表6 本文方法与对比方法在终点碳温预测上的性能对比
为了更直观地说明本文算法在转炉炼钢终点碳温预测上的有效性,本节将本文所提出的WGKSOM-DRCA算法和对比算法中表现前3的算法在测试集上的结果用误差分布图进行了展示,如图8和图9所示。同时为了便于观察,测试集中的200个样本数据按顺序进行了排列(从小到大)。
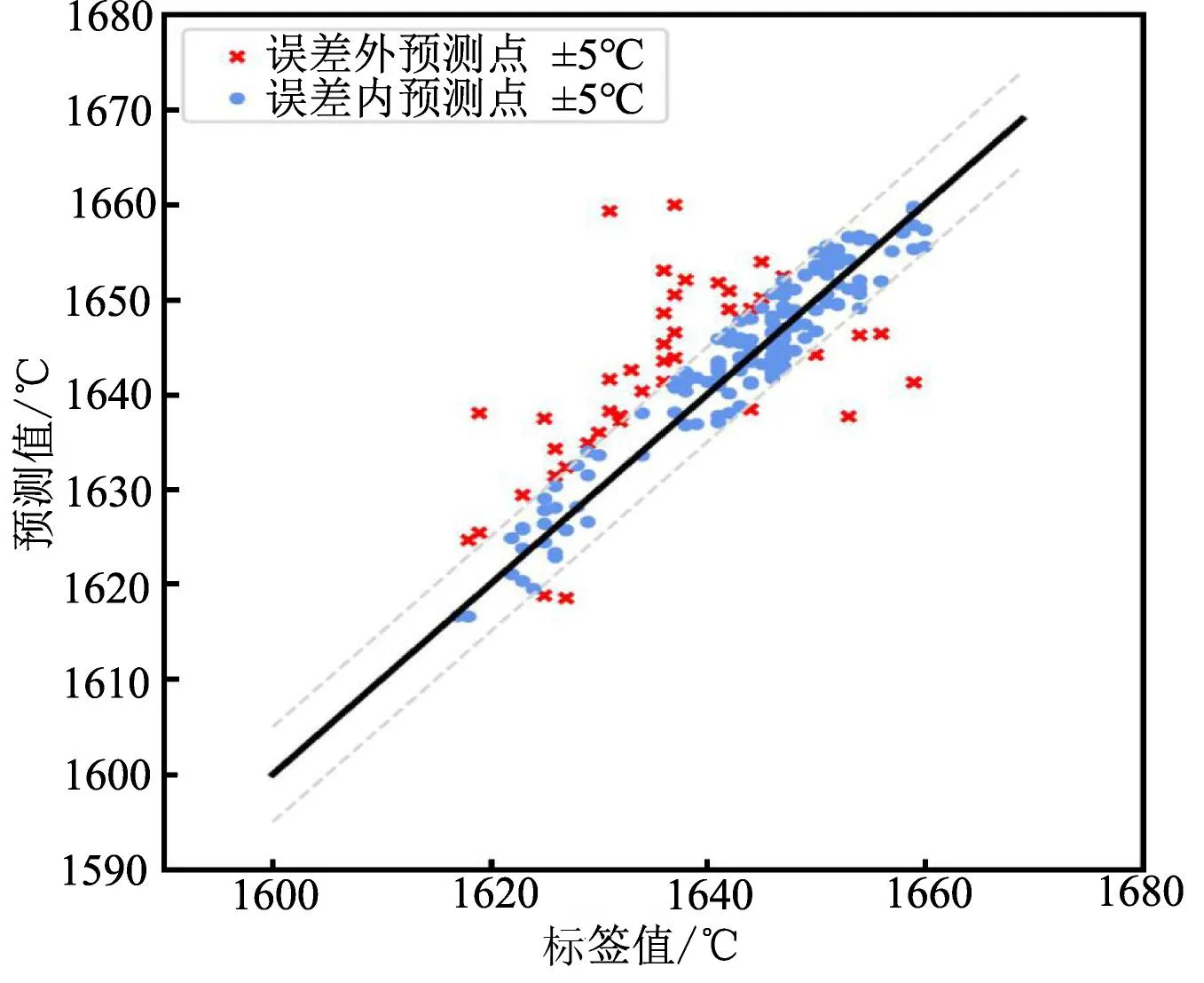
a 本文方法
图8为所有算法在温度上的误差分布图,从图中可以清楚看到,当温度误差范围分别为5度(±5℃),10度(±10℃),15度(±15℃)以内时,WGKSOM-DRCA算法的预测结果更加可靠,预测结果在误差允许范围外的样本点更少;同样地,图9中在终点碳含量预测允许误差范围分别为1个碳单位(±0.01%),2个碳单位(±0.02%),3个碳单位(±0.03%)时,碳含量的预测结果的特点与温度预测结果保持一致。实际上,因为本文算法在聚类阶段有标签信息的引导可以得到比传统无监督聚类算法更符合转炉生产过程数据特点的结果,再加上在局部样本选择阶段,根据待测样本的特点,自适应选择并综合各类簇中与待测样本最为相似的样本,使得建立的即时学习软测量模型更具有针对性,所以在终点碳温的预测上也表现的更具有优势。
综上所述,本文所提出的WGKSOM-DRCA自适应即时学习软测量方法可以有效地实现对于转炉炼钢历史库样本的聚类,并根据待测样本的特点从历史库样本中自适应选择最相似的样本建立局部预测模型,完成对转炉终点碳温的预测。通过与其他软测量方法的对比,结果表明,采用本文的聚类算法和自适应度量策略能够建立更加有效的回归预测模型,完成对转炉终点碳温有效的在线预测。
4 结束语
在转炉炼钢生产过程中,钢液终点碳温的准确预测是判断出钢的重要指标。本文提出一种基于WGKSOM-DRCA自适应即时学习软测量方法实现了对转炉炼钢终点碳温的预测,其主要贡献如下:
(1)提出一种WGKSOM-DRCA自适应即时学习软测量建模方法用于解决转炉炼钢生产过程数据存在波动性大和非线性特点削弱即时学习软测量模型对于终点碳温预测性能的问题。
(2)通过在SOM聚类算法中融入具有标签信息的WGK度量策略,使得WGKSOM算法在用于转炉炼钢历史数据聚类时能够有标签信息引导聚类方向,得到更加符合转炉过程数据特点的聚类结果。
(3)通过引入动态因子和计算待测样本的高斯后验概率构建DRCA度量策略,实现对待测样本的局部算法学习集的自适应选择,使建立的即时学习软测量模型具有更好的针对性和性能表现。
通过本文算法在转炉炼钢生产过程数据上的建模仿真,验证了其在解决转炉炼钢终点碳温预测上的有效性。相关研究成果对于后续与转炉炼钢过程数据具有相似工业特点的研究,具有一定的参考价值。由于转炉炼钢过程本身的复杂性,未来将在软测量建模中自适应地融合与当前炼钢阶段特点更加匹配的特征数据,探索深度学习技术与转炉炼钢终点碳温软测量建模结合,对于相关领域的发展有着重要的研究价值。
