基于字典的压缩加密查询方案研究
2024-02-21田萍芳郭万涛
田萍芳,郭万涛
(1.武汉科技大学 计算机科学与技术学院,湖北 武汉 430065;2.武汉科技大学 智能信息处理与实时工业系统湖北省重点实验室,湖北 武汉 430065)
0 引 言
随着互联网的快速发展,越来越多的组织和个人开始关注RDF数据的组织、管理和共享问题[1]。同时,有许多关于金融、医疗、个人或其他敏感的数据[2],这类数据需要采用数据保护机制,如加密和匿名。为了确保数据的机密性[3],不仅需要在传输过程中加密数据,还需要在静止状态下加密数据。在这种情况下,多个用户对数据的不同部分具有不同的访问权限,用户应该只能访问他们被允许访问的数据。但RDF数据使用方必须面对RDF数据的存储压力,如果不能有效地管理RDF数据集,可能会导致系统性能下降和查询效率降低。随着结构化RDF数据的不断扩展,RDF压缩已成为一个日益重要的研究领域。同样,对于敏感数据数据的安全,如何有效加密以及在密文数据上执行查询也是一个重要的研究领域。
目前国内外一些学者对RDF数据压缩和RDF加密进行了研究。国外的Fernández[4]在2010年提出了HDT压缩方案,Fernández通过将RDF三元组转换成字典、ID三元组,将长的资源描述定位符(Uniform Resource Identifier,URI)转换成短的ID值,有效减少了URI的结构冗余,从而压缩了RDF数据集的大小并且支持对压缩数据的访问。随后基于HDT的优化方案陆续被学者提出,进一步压缩了数据集的大小,如HDT-FoQ[5](HDT Focused on Querying),Waterfowl[6],HDT++[7],RDF-TR[8](RDF Triples Reorganizer)等。Sandra[9]提出一种k2-triples压缩方案,为ID三元组中的每个谓词分配一个矩阵,矩阵中的每个点代表一个(主题,对象),然后用一个四叉树压缩矩阵,实现了RDF数据集的有效压缩。Maneth[10]提出的方案先通过gRePair算法预处理RDF数据集,处理后的数据集再进一步压缩,实现了RDF数据集的有效压缩。Sultana[11-12]提出的另外两种压缩方案也是基于gRePair算法来压缩图的结构,然后再通过k2-tree进一步压缩RDF数据集。国内的彭燊[13]提出的基于关系矩阵的关联数据压缩查询模型HDVM(Header Dictionary Vector Matrix),将ID三元组进行一系列合并,转成主题向量、谓词向量、对象矩阵形式存储,也实现了RDF数据集的有效压缩与查询。国外的Mark[14]提出了一种部分RDF加密的方案PRE(Partial RDF Encryption),其中RDF-graph中的敏感数据针对一组接收者进行加密,而所有非敏感数据仍然公开可读,实现了RDF数据集的加密,保障了RDF数据的安全性。Kasten[15]提出了一种方法,可以在加密数据上执行用户定义的SPARQL(SPARQL Protocol and RDF Query Language)查询。RDF图数据仅部分显示给那些授权执行查询的用户,实现了RDF数据集的加密,保障了RDF数据的安全性。Javier[16]提出的压缩加密方案,使用AES[17](Advanced Encryption Standard)对称加密来加密压缩后的数据,将用户的ID作为对称密钥的唯一标识符,只有对应的用户才能解密密文信息,实现了敏感数据的有效保护。
上述的RDF压缩方案可以有效压缩RDF数据集,但无法保证RDF数据的安全;RDF加密方案提高了RDF数据的安全性,但是,查询加密数据集需要解密所有的数据,然后再对解密后的数据进行查询操作,解密全部数据,相对比较耗时。
鉴于此,该文提出一种综合RDF压缩和RDF加密的方案,即基于字典的压缩加密查询方案(Dictionary Encrypted Query,DEQ),DEQ通过建立字典将原始RDF数据集中地转化成短的ID,将原始三元组转化成ID三元组,形成密文,并将数据的核心部分字典存放在可信区域,把密文ID三元组存放在不可信区域。DEQ不仅可以压缩原始RDF数据集,降低RDF数据集占用的空间,还能防止隐私数据被不可信的第三方破解,而且支持对密文数据的查询。最后通过实验验证了该方案的有效性与可行性。
1 相关理论
1.1 RDF
RDF图G是来自((I∪B)×I×(I∪B∪L)的一组有限三元组(subject,predicate,object)[18],其中I表示URI,B表示空节点、L表示RDF文字。RDF图可以组合在一起管理,组成一个RDF数据集,即一组RDF图[19]。RDF数据集是一个由默认图G和命名图gi组成的集合DS:DS={G,(g1,G1),…,(gn,Gn)},其中gi∈I,gi是图的名字。RDF数据集图示例如图1所示,RDF数据集三元组结构示例如图2所示。
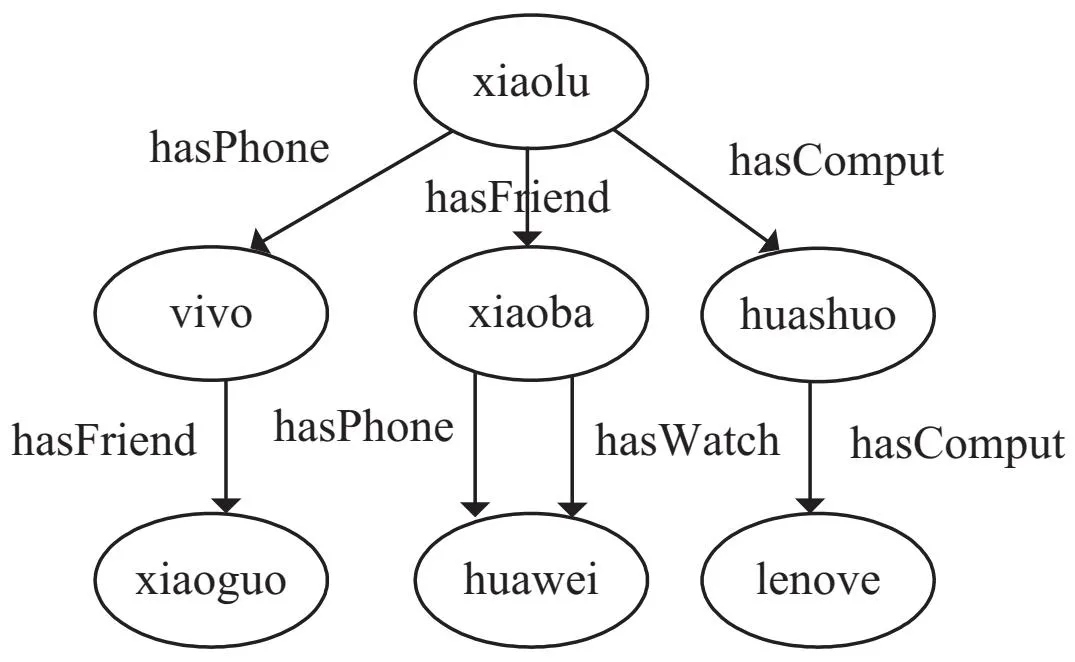
图1 RDF数据集图示例

图2 RDF数据集三元组示例
1.2 HDT
HDT是一种二进制序列化格式,其核心思想是通过字典将RDF数据集中的所有数据换成短的ID,将三元组转化成ID三元组,从而减少结构冗余,来降低RDF数据集占用的空间。HDT通过三个逻辑组件来管理RDF数据集。三个组件分别是:
(1)Header组件:主要包括描述RDF数据集的逻辑和物理元数据,它作为数据集中信息的入口点;
(2)Dictionary:组件提供了数据集中使用的术语集合,并将它们映射到唯一的整数ID。它使术语可以被其相应的ID替换,实现数据的有效压缩;
(3)Triples组件:表示ID替换后底层图的纯结构。
1.3 邻接表
邻接表是一种用于表示图的数据结构。在邻接表中,图中的每个节点都与一个列表相对应,该列表包含与该节点直接相连的所有其他节点。这个列表可以是一个数组、链表或者其他数据结构,其中存储的元素为该节点所连接的节点的标识符或者对象。邻接表是一种紧凑的数据结构,可以有效地表示具有大量节点和边的图。并且在某些图算法中,邻接表也比其他数据结构更有效率。
图1对应的邻接表结构如图3(a)所示,其中每个节点中取的是URI的缩写。在HDT方案中,将原始三元组转换为ID三元组后,通过邻接表形式存储ID值,形式如图3(b)所示,图中的ID是原始RDF三元组经过字典转换得到的唯一ID值。
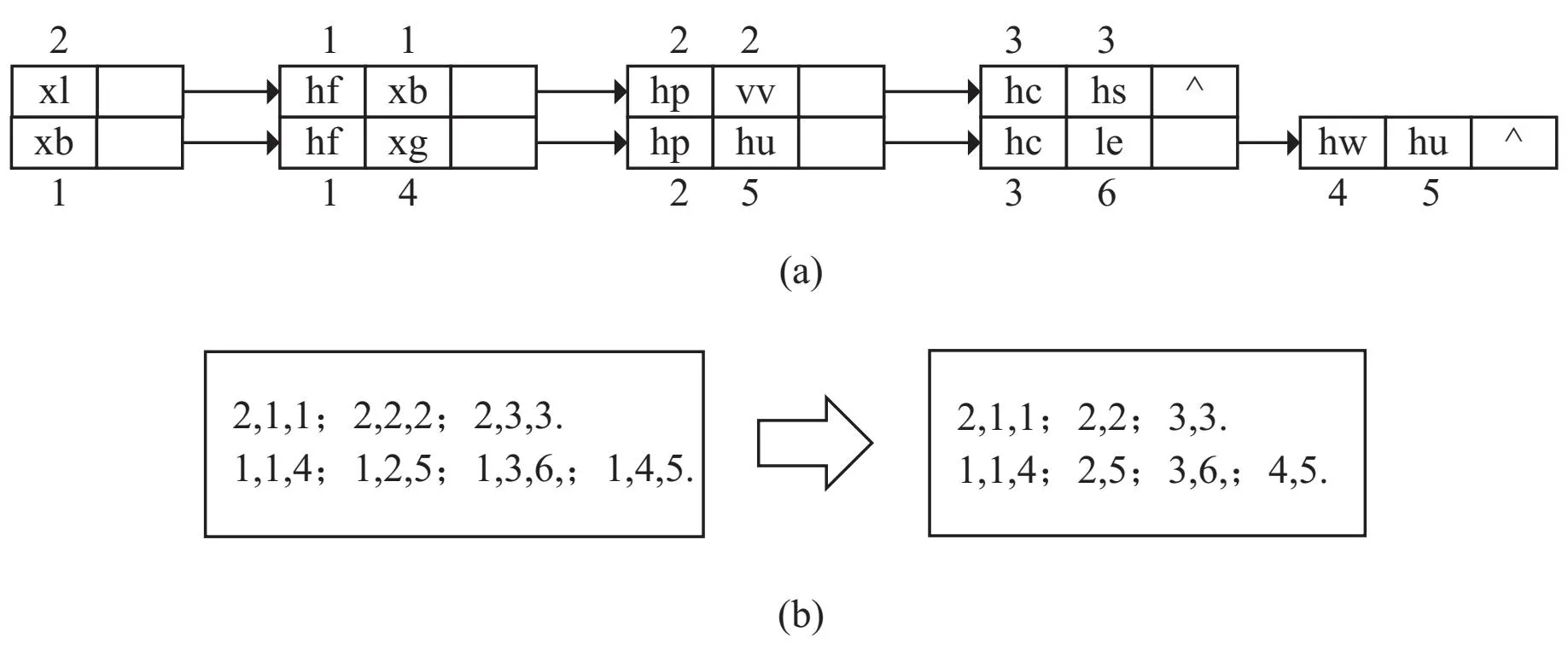
图3 邻接表与ID邻接表结构
2 模型总体架构与技术实现
压缩加密查询模型架构如图4所示。架构包括压缩加密模块、可信区域、不可信区域三个部分。压缩加密模块包括数据压缩(构建字典)和数据加密(生成密文三元组)。字典通过原始RDF数据集中的三元组中的元素生成,字典主要是降低RDF数据集中的URI冗余,并且通过字典建立起URI与短ID的一一映射,降低三元组的大小。密文ID三元组是原始RDF数据集中的三元组通过构建的字典,将原始三元组中的主题、谓词、对象替换成ID值,最终生成ID三元组集,即是密文ID三元组。可信区域包括查询转换器和结果翻译器。查询转换器主要是重写用户的查询语句。查询翻译器主要是将密文结果转化成原始的三元组。不可信区域主要是缓解可信区域的存储压力,存放密文数据,并对密文进行查询。
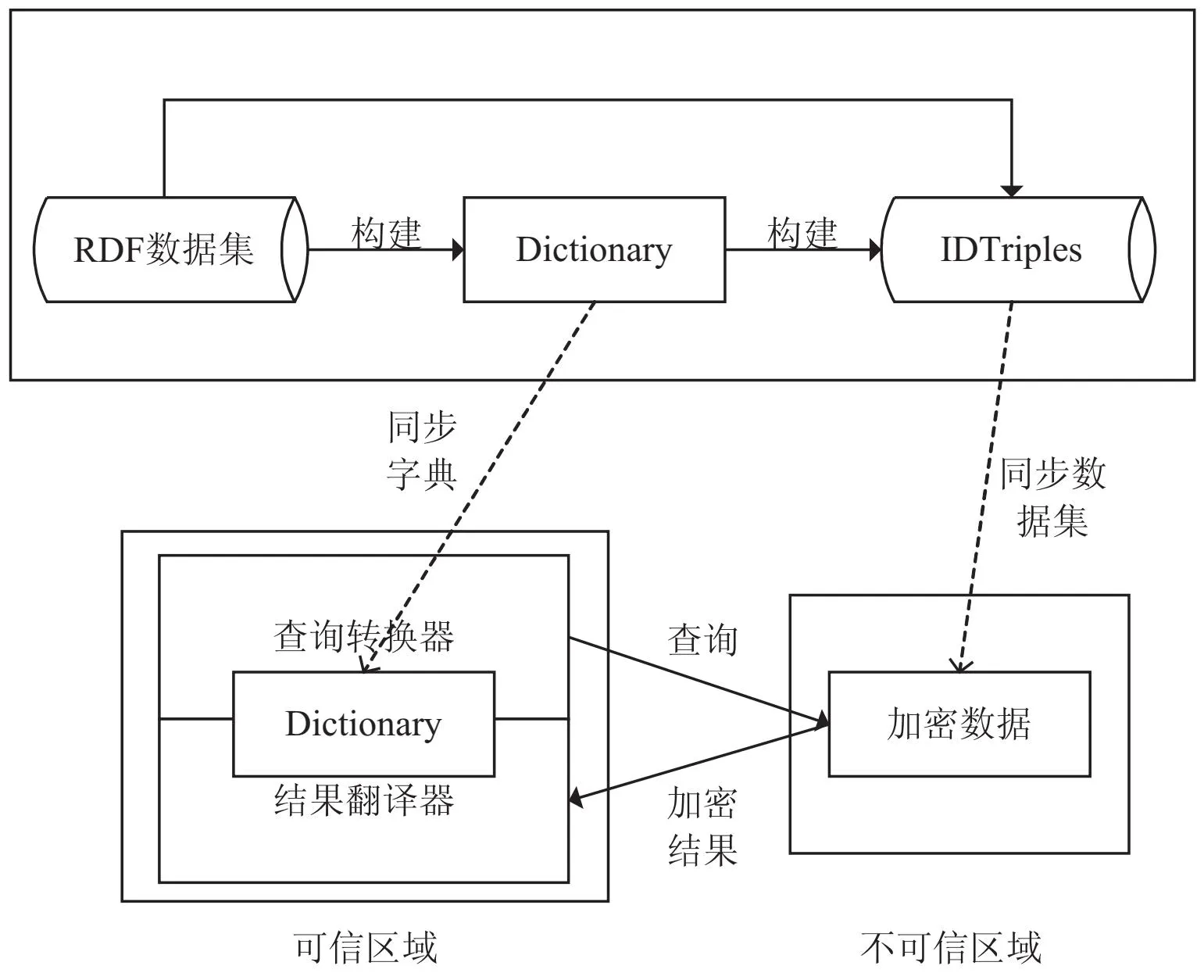
图4 总体架构
2.1 构建字典
构建字典主要是为了减少RDF数据集中URI的冗余,同时为每个不同的URI,不同的RDF文字,空节点生成一个唯一的ID,并在生成密文ID三元组时用ID替换对应的URI(或空节点或RDF文字)。构建字典应该遵循以下规则:
(1)URI是以“<”开头,并以“>”结尾。若当前元素为URI,则获取“<”和“>”之间的内容保存在字典中,并生成对应的ID。例如:“
(2)空节点是以“_:”开头的。如当前元素为空节点,则直接添加到字典中;例如:“_:xiaoyu”是一个空节点,直接将“_:xiaoyu”添加到字典中,并生成对应的ID值2;
(3)RDF文字是通过双引号包起来的数据。如当前元素是RDF文字,则直接将RDF文字添加到字典中,并生成对应的ID。例如:“xiaohua”是一个RDF文字,直接将“xiaohua”添加到字典中,并生成对应的ID值3。
生成字典ID也应该遵循以下规则:
(1)SO字典:对于既出现在主题中,又出现在对象中的URI和空节点,将它们添加到SO字典,并且生成的ID值的范围为[1,|SO|];
(2)S字典:对于只出现在主题中的URI和空节点,将它们添加到S字典,并且生成的ID值的范围为[|SO|+1,|S|];
(3)O字典:对于只出现在对象中的URI、空节点和RDF文字,将它们添加到O字典,并且生成的ID值的范围为[|SO|+1,|O|];
(4)P字典:对于出现在谓词中的URI,将它们添加到P字典,并且生成的ID值的范围为[1,|P|]。
图5所示的是通过RDF数据集构建的字典。
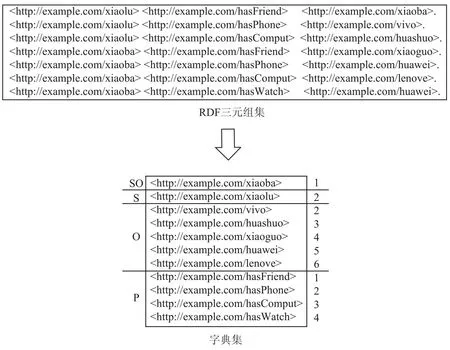
图5 构建字典过程
2.2 生成密文ID三元组
生成密文ID三元组主要结合上一步生成的字典,将RDF数据集中每个原始的三元组转换成密文ID三元组。图1中的RDF数据集生成密文ID三元组的过程如图6所示。
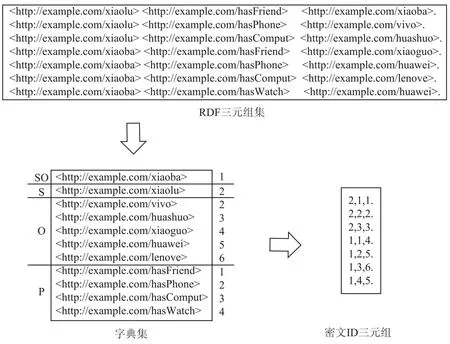
图6 生成密文ID三元组过程
2.3 重写用户查询语句
查询转换器主要负责接收并重写用户的查询语句,并将重写后的查询转发给不可信区域。例如,查询语句“http://example.com/xiaolu http://example.com/hasPhone ?o.”经过查询转换器转换后得到查询语句“2 2 ?o.”。
查询转换算法实现如表1所示。

表1 查询转换算法
2.4 解密解压数据
结果翻译器主要负责将不可信区域返回的密文数据进行转换,转换成真实RDF数据返回给用户。例如,查询返回的密文ID三元组结果为“2 2 2”,经过结果翻译器翻译后得到“http://e-xample.com/xiaolu http://example.com/hasPhone http://exa-mple.com/vivo”。
解密解压算法实现如表2所示。

表2 解密解压算法
2.5 查询加密数据
不可信区域主要存储加密的数据,缓解可信区域的内存空间,并在密文ID三元组中执行查询操作,并将查询的密文结果返回给可信区域中的结果翻译器。例如在不可信区域执行的查询为:“2 2 ?o.”,查询得到的密文ID三元组为“2 2 2”。
密文查询算法实现如表3所示。

表3 密文查询算法
3 实验结果
3.1 实验数据集
在真实数据集和生成的数据集上进行对比实验,来验证提出的压缩加密查询方案。并且为了与Fernández提出的压缩加密方案进行对比,选择相似的数据集。真实数据集是DBpedia,并且使用 Lehigh University Benchmark (LUBM)数据生成器从100所大学(LUBM-100,包括0.13亿三元组)到 400所大学(LUBM-400,包括0.53亿三元组)获得增量大小的合成数据集。LUBM以大学领域的本体为特征,其中大学的所有实体,如学生、教授和课程,都以三元组格式描述。5个数据集按照数据集的大小从低到高排列如表4所示,表中还包括每个数据集的一些统计信息,包括三元组数量、公共主题对象数量、主题数量、对象数量、谓词数量(分别用|Triples|,|SO|,|S|,|O|,|P|表示)。在5个不同数据集上进行了对比实验,主要从压缩加密时间、压缩加密结果、解密解压时间、查询时间四个方面将DEQ压缩加密查询方案与HDTcrypt压缩加密方案进行对比。并从理论上对每个实验做了分析,理论分析结果与实验结果相吻合。
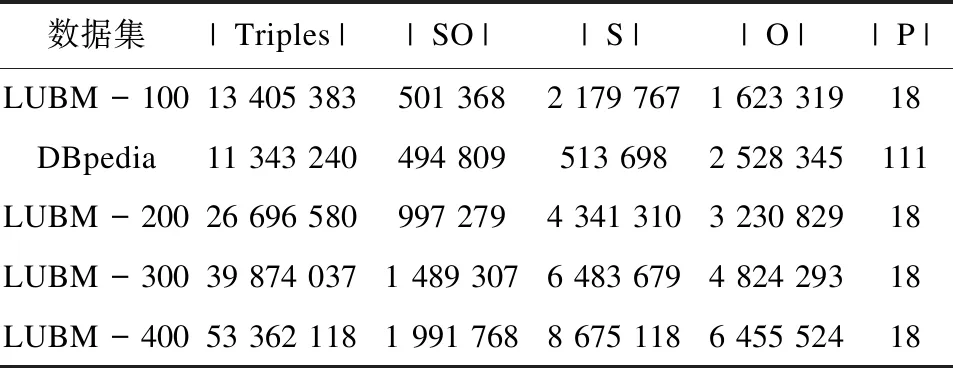
表4 数据集相关信息
3.2 压缩加密时间
压缩加密时间通过执行10次压缩加密操作,10次加密操作,得到10次压缩加密时间,最后取10次压缩加密时间总和的平均值作为最终的压缩加密时间。平均压缩加密时间的计算结果如表5所示。

表5 平均压缩加密时间 min
从理论上分析, DEQ的思想与HDTcrypt的思想一样,都是将原始RDF数据集通过字典转换成字典和ID三元组,所以在压缩数据集方面,两种方案的压缩时间没有很大差别。但是,HDTcrypt需要进一步对字典与ID三元组加密来保证数据的安全性,所以HDTcrypt的压缩加密时间要比DEQ的多,因为对于HDTcrypt来说,原始RDF数据需要经过压缩、加密两个步骤,生成加密数据。DEQ只需要对RDF数据集进行一步处理,就能达到压缩加密的效果。所以在理论上DEQ的压缩加密时间要比HDTcrypt的压缩加密时间更少。
从实验结果来看,HDTcrypt压缩加密RDF数据集的时间是DEQ的2倍以上,随着数据集的增大,DEQ的性能优势越明显。两种方案压缩加密时间都是随着数据集的增大而增大,即压缩加密时间的大小与RDF数据集的大小成正相关。
3.3 压缩加密结果
压缩加密结果比较是通过HDTcrypt方案压缩、HDTcrpty方案加密得到的数据大小与DEQ方案压缩加密得到的数据大小进行比较。HDTcrypt方案压缩、HDTcrypt方案加密与DEQ方案压缩加密后的数据大小如表6所示。表中包括数据集的原始大小,HDTcrypt方案压缩后的文件大小,HDTcrypt方案加密后的文件大小,DEQ方案压缩加密后的文件大小。

表6 压缩加密结果 G
从理论上分析,DEQ的思想与HDTcrypt的思想一样,都是通过构建字典,将RDF数据集中的URI(或空节点或RDF文字)转化成短的ID值,从而降低URI的冗余,进一步达到压缩数据集的目的。所以在压缩方面,两种方案的压缩结果没有很大差别,但是,HDTcrypt需要进一步对字典与ID三元组通过加密算法加密数据来保证数据的安全性,而加密算法加密数据时会破坏压缩后数据的结构,所以会导致数据集变大,所以HDTcrypt的压缩加密结果要好于DEQ,因为DEQ只需要经过字典喜欢换后就形成了密文ID三元组,即同时实现了压缩与加密。
从实验结果来看,DEQ与HDTcrypt中的压缩数据集的性能相当,DEQ压缩加密性能要高于HDTcrypt。DEQ和HDTcrypt的压缩结果表明,当数据集中的URI结构化程度越高,压缩效果也越好。总体来说,DEQ在压缩加密性能上优于HDTcrypt。
3.4 解密解压时间
解密解压时间通过执行10次解密操作,10次解压操作,得到10次解密解压时间,最后取10次解压解密时间总和的平均值作为最终的解压解密时间。平均解压解密时间的计算结果如表7所示。

表7 解密解压时间 s
从理论上分析,DEQ的密文数据解密解压只需要将密文ID三元组通过字典直接转换,即结合字典根据ID值获取对应的URI(或空节点或RDF文字),得到原始的RDF三元组;而HDTcrypt加密得到的密文数据需要经过解密、解压两个步骤。即首先需要将所有的密文数据加载并解密,然后解压所有数据,得到原始的RDF数据集。所以理论上DEQ在密文数据解密解压时间上要优于HDTcrypt。
从实验结果来看,DEQ的解密解压时间更少,所以DEQ解密解压性能更好。通过实验结果可以看出,解密解压的时间会随着数据集的增大而逐渐增长,即解压解密时间的大小与RDF数据集的大小成正相关,这一点在HDTcrypt和DEQ都有体现。
3.5 查询时间
对7种查询模式(SPO,SP?,S?O,S??,?PO,??O,?P?)分别进行查询实验,通过执行10次相同的查询语句,得到10次查询时间,最后取10次查询时间总和的平均值作为最终的查询时间。DEQ和HDTcrypt分别在LUBM-200数据集和DBpedia数据集上进行7种查询模式的对比,平均查询时间如表8所示。

表8 不同数据集上不同查询模式的平均查询时间 s
从理论上分析,对于查询操作,HDTcrypt压缩加密后得到的密文数据必须先获取所有的密文数据,然后解密所有的数据,其次才能执行查询操作,获取满足条件的压缩后的三元组,最后将查询得到的结果中的ID转换成对应的URI(或空节点或RDF文字),才能得到原始的三元组。DEQ首先加载所有的密文ID三元组,然后执行查询操作,获取满足添加的密文ID三元组,最后再将查询的结果中的ID转换成对应的URI(或空节点或RDF文字),得到原始的三元组。所以,理论上DEQ在查询效率上要优于HDTcrypt,主要体现在DEQ比HDTcrypt少了一步解密操作。
从实验结果来看,DEQ在查询效率上要高于HDTcrypt。在LUBM数据集上执行?P?查询模式时,查询时间往往是其他模式的2倍以上,这是由于LUBM数据集的谓词数量只有18个,所以每个谓词相关联的数据非常多,所以?P?查询模式结果转化也会花费比其他查询模式更多的时间,从而增加了?P?查询模式的查询时间。
4 结束语
DEQ综合了RDF压缩方案与RDF加密方案的优点,不仅压缩了原始RDF数据集的大小,而且支持在密文ID三元组上执行查询操作。将密文ID三元组存储在不可信区域,在不可信区域执行查询,将字典数据存储在可信区域,在可信区域执行解密操作,保障了数据的安全性。实验结果表明DEQ有不错的性能,不仅压缩加密后的数据小于HDTcrypt的数据,而且在压缩加密时间、解密解压时间、查询时间上都优于HDTcrypt,验证了DEQ的可行性与有效性。
当然DEQ也存在不足,字典占用的空间比较大,并且密文转换需要加载全部的字典。所以未来将研究如何对字典进行分块存储,从而实现在转换密文ID三元组时,只加载部分字典数据,而不需要加载所有的字典数据。
