基于可逆网络的轻量化图像隐写方案
2024-02-18孙文权刘佳钮可董炜娜陈立峰
孙文权 刘佳 钮可 董炜娜 陈立峰

摘 要:目前,基于深度学习的隐写模型的隐写容量有所提高,但由于网络结构复杂,需要大量的时间来训练。为此,提出轻量化的可逆神经网络结构,并以此设计了高效图像隐写方案,采用基于密集连接的可逆神经网络实现图像的隐藏与恢复,在减少可逆块数量的同时,增加每个可逆块中可逆函数f(·)、r(·)和y(·)的卷积块数量来保证图像质量。这样能够显著降低计算和存储开销,使得模型在计算资源有限的设备上运行更加高效,模型开发和迭代的过程更加高效,有效地节省了宝贵的计算资源。载体图像与秘密图像通过正向隐藏可逆变换生成含密图像,含密图像与随机变量通过反向恢复可逆变换得到恢复图像。实验结果表明,与HiNet算法相比,轻量级网络结构能够得到良好的图像质量且更具安全性,同时训练时间缩短了46%,隐写时间缩短了28%。
关键词:可逆神经网络;隐藏;恢复;隐写效率
中图分类号:TP309.2 文献标志码:A 文章编号:1001-3695(2024)01-042-0266-06
doi:10.19734/j.issn.1001-3695.2023.05.0215
Lightweight image steganography scheme based on invertible neural network
Abstract:At present,the steganographic capacity of deep learning-based steganographic models has been improved,but due to the complexity of the network structure,it requires a lot of time to train.Aiming at this problem,this paper proposed a lightweight invertible neural network structure and used to design an efficient image steganography scheme,which adopted a dense connection-based invertible neural network to achieve image hiding and recovery,and increased the number of convolutional blocks of invertible functions f(·) ,r(·) and y(·) in each invertible block to ensure the quality of the image while redu-cing the number of invertible blocks.It could significantly reduce the computational and storage overheads,making the model run more efficiently on devices with limited computational resources,making the process of model development and iteration more efficient,and effectively saving valuable computational resources.It transformed the cover and the secret image by forward hidden invertible transform to generate the stego image,and transformed the stego image and the random variable by reversing recovery invertible transform to get the recovered image.The experimental results show that compared with HiNet algorithm,the proposed lightweight network structure can achieve good image quality and security,while reducing the training time by 46% and the steganography time by 28%.
Key words:invertible neural network;conceal;recover;steganography efficiency
0 引言
传统的隐写方案通常采用载体修改的方法将秘密信息嵌入到图像的空域[1]或者变换域[2]。为了抵抗专用隐写分析[3,4],载体修改的隐写方法通常仅能保持某一种统计模型不变。基于最小化失真的自适应隐写方法[5],通过定义修改失真代价,试图提高隐写的安全性。然而,随着基于深度神经网络的隐写分析技术的发展[6],基于模型保持和最小化失真代价的隐写方法面臨的安全威胁逐渐增加。
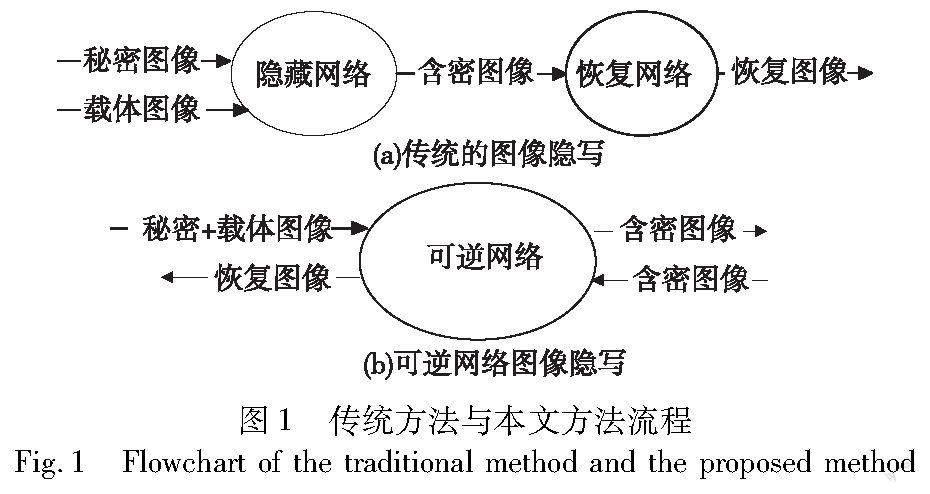
随着深度学习的发展,基于深度神经网络的隐写(deep steganography)方案被提出。Baluja[7,8]首次提出利用深度神经网络将一整张彩色图像隐藏在另一张彩色图像中,基于Encoder-Decoder的预处理网络提取秘密图像的有用特征,然后利用隐藏网络将秘密图像提取的特征融合到载体图像中,最后采用恢复网络来恢复秘密图像。文献[7]对该工作进行了扩展,通过对秘密图像像素的排列来提高隐藏的安全性。文献[9]在文献[7]的基础上增加了一个回归的损耗,保证了端到端联合训练。然而,它们都有颜色失真的问题。Zhang等人[10]通过减少秘密图像的有效载荷,即只嵌入灰度图像来缓解这种影响。深度生成模型也对隐写产生重要影响。Hayes等人[11]提出了一种基于生成对抗网络(GAN)的方法,并利用一个生成器和一个判别器来分别生成和区分含密图像。在此基础上,许多改进的网络结构被提出。毕新亮等人[12]使用Star GAN的判别器作为特征提取器,将提取的特征映射为秘密消息,直接构造了图像和秘密消息的映射关系,但图像质量不高。Hu等人[13]提出了一种无修改隐写方法(SWE),可直接建立噪声与消息之间的映射关系。在此基础上,Liu等人[14]利用图像补全技术构造了一个数字化卡登格子方案,由于采样过程要想获得整个网络最优的参数十分困难,导致无法完全准确地提取消息。Zhang等人[15]使用生成对抗网络优化隐写图像的感知质量。这些方法不易被隐写分析工具检测到,具有良好的隐写安全性,但其容量普遍较小。以上方法的隐藏和恢复过程是由两个独立网络依次实现的,即一个网络用于隐藏,另一个网络用于恢复秘密图像,如图1(a)所示。
Jing等人[16]首次将图像隐藏和图像恢复看作是同一个可逆网络的正向和反向过程,设计了单幅彩色图像的隐藏方案HiNet,如图1(b)所示。Dinh等人[17]首次提出可逆神经网络(invertible neural network,INN),给定一个变量y和正向计算x=fθ(y),可以通过y=f-1θ(x)直接恢复y,其中逆函数f-1θ被设计成与fθ共享相同的参数θ。为了使INN更好地处理与图像相关的任务,Dinh等人[18]在耦合模型中引入了卷积层,并引入了多尺度层,以降低计算成本并提高正则化能力。Kingma等人[19]在INN中引入了可逆的1×1卷积,并提出了Glow算法,该算法对图像的合成和处理具有显著的效果。由于INN的优异表现,在图像压缩[20]、图像缩放[21,22]、图像到图像转换[23]、视频超分辨率[24]、图像生成[25]等领域有着广泛的应用。由于可逆神经网络的优势,目前有一些基于可逆神经网络的图像隐写方案研究[16,26~29]将可逆神经网络应用于图像隐写术。Liu等人[27]提出了一种映射模块,该模块可以压缩实际嵌入的信息,以提高隐写图像的质量和反检测能力。可逆神经网络在隐写图像的视觉质量和安全性方面取得了较好的效果,信息提取准确率达到100%。Xu等人[29]设计了图像质量增强模块,在保持隐写图像不可感知性和大容量的同时,有效地提高了隐写图像的鲁棒性。Lu等人[28]提出在相同大小的彩色图像中隐藏多幅彩色图像,大大增加了图像隐写的隐藏容量。Guan等人[26]在可逆神经网络的基础上增加了重要映射模块,利用当前图像的隐藏结果指导下一幅图像的隐藏,避免了多幅图像隐藏造成的轮廓阴影和颜色失真问题,提高了秘密信息的不可见性。与传统的使用两个网络分别进行嵌入和提取的方法相比,基于可逆神经网络的隐写方案提高了提取精度并具有较好的视觉效果。但上述基于可逆网络的隐写方案[16,26~29]结构比较复杂,神经网络层数过多,增加了计算和存储开销,使模型无法在计算资源有限的设备上高效运行,模型的隐写效率低。因此本文在HiNet[16]的基础上提出了一个高效的图像隐写方案,即轻量化可逆网络结构,其主要贡献如下:
a)与HiNet相比,在保证图像质量和安全性的同时精减了网络结构,减少了网络中可逆块的数量,加快了训练速度,提升了隐写效率。
b)能更有效地提取图像深层次的特征,实现特征重用,提高隐写图像与恢复图像的质量。本文增加可逆函数f(·)、r(·)和y(·)中密集连接的卷积块数量,以抵消可逆块数量减少导致的图像质量下降问题。
c)通过优化低频小波损失的权重参数设置,以达到更好的隐写效果,增加载体图像与含密图像之间的相关性。
1 本文方法
1.1 方案框架
本文提出了一种新型的可逆网络,以实现轻量、高效、安全的图像隐写。传统隐写隐藏与恢复通过两个网络实现,而可逆神经网络能够在运用一个网络的情况下实现图像的处理与恢复。由于可逆神经网络的特点,本文将其应用在隐写过程中,达到通过一个网络实现隐藏与恢复的目的。在隐藏与恢复过程中运用离散小波变换,将图像在进行可逆变换前分成低频和高频小波子带,达到更好的隐写效果。方案整体框架分为前向隐藏过程和反向恢复过程,两个过程完全相同,只是由信息流的方向相反来实现图像的隐藏与恢复。
1)前向隐藏过程 载体图像Xco与秘密图像Xsec共同作为正向网络的输入,首先经过离散小波变换(DWT)对图像进行预处理,然后将特征图(feature map)输入网络的可逆块中,经过8层可逆块变换得到新的特征图,再经过逆小波变换(IWT)处理得到含密图像XSte与损失信息r。在隐藏过程中,网络试图将秘密图像Xsec隐藏到载体图像Xco中。大容量的嵌入不可避免地导致秘密图像在提取时丢失一部分信息,另外,秘密图像的嵌入可能也对原始的载体图像造成影响,丢失的秘密信息和被破坏的载体信息共同构成了损失信息r。假设全部图像的分布为χ,训练过程中的图像都从全部图像中取样,所以(Xsec,Xco)~χ。因为INN的可逆性,XSte和r也应该遵循相同分布,XSte和r的混合分布也应遵循相同分布,例如XSte×r~χ。
2)反向恢复过程 由于网络的可逆性,反向恢复过程需要引入一个随机变量z。变量z是从一个任意高斯分布中随机抽取的,该分布应与r的分布相同,通过在训练时从后面表示的恢复损失学习得到。与前向隐藏过程完全相反,含密图像XSte与随机向量z共同作为反向网络的输入,首先经过离散小波变换(DWT)对图像进行预处理,然后将特征图输入进网络的可逆块中,经过8层可逆块变换得到新的特征圖,经过逆小波变换(IWT)处理得到恢复图像Xsec-rev与恢复的载体图像Xco-rev。
1.2 关键模块
为了保证网络模型的隐写效果,本文采用了小波变换、可逆块变换和密集连接。运用小波变换将图像分解成不同频率的子带(高频与低频),然后将其输入可逆块变换,经过其中运算以及采用密集连接的f(·)、r(·)和y(·)函数,更深层次地将秘密图像Xsec隐藏在载体图像Xco中,生成含密图像XSte。这样能够在保证隐藏容量的同时,保持较高的视觉质量和信息安全性。
1)小波变换 图像隐藏在像素域容易导致纹理复制伪影和颜色失真[3,30]。相比于像素域,频域和高频域更适合于图像隐藏。本文采用小波变换将图像在进行可逆变换前分成低频和高频小波子带,其中高频子带包含图像细节,低频子带则包含图像的整体特征,使网络能更好地将秘密信息融合到载体图像中。相比于在原始图像域直接操作,小波变换具有较好的视觉保真度。小波变换只在少数子带中隐藏信息,对图像整体的影响相对较小,一般难以察觉。此外,小波良好的重构特性有助于减少信息损失,提高图像隐藏性能。经过DWT后,将尺寸(B,C,H,W)的特征图转换为(B,4C,H/2,W/2),其中B为批量大小,H为高度,W为宽度,C为通道数。DWT可以降低计算成本,这有助于加速训练过程。本文采用Haar小波函数实现小波变换和逆变换。由于小波变换也是双向的,所以不会影响网络模型的端到端训练。
2)可逆块变换 如图2所示,隐藏过程和恢复过程具有相同的子模块,共享相同的网络参数,只是信息流方向相反。本文网络结构有8个结构相同的可逆块,构造如下:对于正向过程中的第L个隐藏块,输入为Xlco和Xlsec,输出为Xl+1co和Xl+1sec,如式(1)(2)所示。
Xl+1co=Xlco+r(Xlsec)(1)
其中:σ为激活函数,本文采用LeakyReLU;f(·)、r(·)和y(·)为密集连接网络,最后可逆块的输出Xksec和Xkco再经过IWT变换得到含密图像XSte和损失信息r。
反向恢复过程中的第L个显示块,输入为Xl+1Ste和Zl+1,输出为XlSte和Zl,如式(3)(4)所示。
在反向过程中,与正向过程信息流方向相反,先经过第l+1层再经过第l层。最后经过第一层可逆变换以后,再对其进行逆小波变换(IWT)得到恢复图像Xsec-rev。
3)密集连接 由于网络的可逆性f(·)、r(·)和y(·)可以为任意函数,为了能更有效地提取图像深层次的特征,实现特征重用,提高隐写图像与恢复图像的质量,本文采用密集连接来实现。将前一层的信息直接传递到后一层的所有神经元,更有效地实现信息传递和共享,同时梯度可以更快地传播回较早的层,加速模型的收敛过程,相比于某些传统的全连接网络结构,密集连接可以显著地减少参数数量,提高模型的效率和紧凑性,并节省内存和计算资源。如图3所示,采取实验效果最好的卷积层数量为7的密集连接。
1.3 损失函数
本文提出的损失主要由三部分组成:
a)隐藏损失L隐藏。隐藏损失的目的是保证生成的含密图像XSte与Xco不可区分。
其中:N代表训练样本的数量;c计算载体图像与含密图像之间的差异,本文采用l2范数。
b)低频小波损失L低频。文献[7]验证了隐藏在高频分量中的信息比隐藏在低频分量中的信息更不容易被检测到。为了能更好地应对隐写分析工具的攻击,让信息尽量隐藏在图像的高频区域,本文采用了载体图像与含密图像的低频子带的损失约束,如下所示。
其中:N代表训练样本的数量;f计算载体图像与含密图像之间的低频差异;H(·)ll代表提取图像的低频子带操作。
c)恢复损失L恢复。为保证恢复的秘密图像与嵌入的秘密图像的一致性,最小化恢复图像与秘密图像之间的差异以提升模型准确率,如式(7)所示。
其中:N代表训练样本的数量;r计算恢复图像与秘密图像之间的差异。随机向量z采样的过程是随机的。
总损失函数是隐藏损失、低频小波损失和恢复损失的加权求和:
L总计(θ)=λ1L隐藏+λ2L低频+λ3L恢复(8)
在训练过程中,首先将λ2设为0,即不考虑L低频对网络的影响直接对网络模型进行预训练,使网络模型先获得基本的隐藏-恢复能力。然后再逐渐添加L低频约束项,进一步优化网络模型,将秘密图像隐藏在载体图像的高频区域,以增强模型抵抗隐写分析的能力。
2 实验结果与分析
2.1 实验设置
网络模型使用Python 3.8编码语言,CUDA版本为11.6,使用NVIDIA GeForce RTX2070 GPU进行加速。DIV2K数据集具有多样性、高分辨率和真实性,涵盖了自然风景、人物、动物、建筑等多个领域,与信息隐藏的要求场景十分契合。本文使用DIV2K[30]訓练数据集(800张图像,分辨率为1024×1024)训练网络模型;使用DIV2K验证数据集(100张图像,分辨率为1024×1024)验证网络模型的效果;使用DIV2K测试数据集(100张图像,分辨率为1024×1024)测试网络模型的效果。本文在HiNet代码的基础上不断修改,分别调试可逆块、卷积块数量和参数等进行实验测试。使用Adam优化器,λ1=5,λ2=0.5,λ3=1,learning rate=1×10-4.5,batch size=2来训练网络模型。整个网络模型可逆块数量为8,每个块分别使用三个包含7层卷积块的DenseNet块作为f(·)、r(·)和y(·)。其中可逆块的数量、损失函数的权重和DenseNet中卷积层的数量对网络模型的隐写能力均有影响。
本文采用两个度量标准(隐写效率与图像质量)用于衡量网络模型的隐写能力:
1)隐写效率 模型训练时间(不同模型训练相同的epoch所需的时间)以及不同模型训练完成以后的隐写时间(隐藏与恢复50张图像所需要时间)。
2)图像质量 含密图像质量以及恢复图像质量。含密图像质量是指含密图像与载体图像之间的相似程度,恢复图像质量是指恢复图像与秘密图像之间的相似程度,即PSNR与SSIM值。
2.2 隐写效率
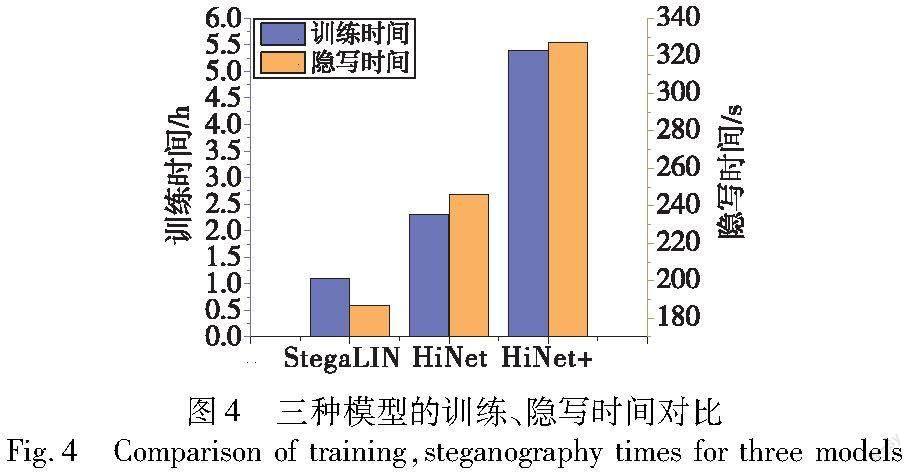
本文对比基于可逆网络的图像隐藏方法HiNet。其中,将HiNet中可逆块数量增加到24层,命名为HiNet+,单独训练,将每个网络模型训练50个epoch,测试本文提出的轻量化模型StegaLIN、HiNet和HiNet+的训练时间与隐写时间。三种模型的隐写效果对比如表1所示。
如图4所示,通过实验发现本文提出的网络模型训练时间最短。由于减少了网络模型中可逆块的数量并精减了网络的整体结构,相比于HiNet训练时间缩短46%,隐写时间缩短28%,提高了网络模型的隐写效率。
2.3 图像质量(PSNR/SSIM)
使用DIV2K验证数据集(100张图像,分辨率为1024×1024)验证三个模型的含密图像质量和恢复图像质量。表1显示了100张图像的平均数值,通过对比可知,经过三个模型得到的含密图像质量与恢复图像质量的平均PSNR/SSIM数值接近,表明StegaLIN能够在实现图像的隐藏与恢复的同时保证图像的质量,满足隐写的要求。
如圖5所示,载体图像与秘密图像在经过三个模型得到的含密图像与恢复图像在视觉效果上无法区别,人类肉眼无法分辨,能够达到混淆对手的目的。
使用DIV2K测试数据集(100张图像,分辨率为1024×1024,50张作为载体图像,50张作为秘密图像)测试本文网络模型。如图6所示,经过StegaLIN模型得到的载体图像/含密图像对和秘密图像/恢复图像对的PSNR/SSIM值发现:秘密图像/恢复图像对PSNR主要集中在34 dB上下波动,SSIM主要集中在0.94上下波动;载体图像/含密图像对PSNR主要集中在32 dB上下波动,SSIM主要集中在0.82上下波动。StegaLIN模型隐写的准确率和安全性方面都表现出优异的效果,能够满足图像隐写的要求,验证了StegaLIN模型的实用性。
2.4 可逆块数量对隐写能力的影响
本文研究了可逆块的数量对隐写能力的影响,本文方案中StegaLIN模型的可逆块数量为8,Hi-Net的可逆块数量为16,HiNet+的可逆块数量为24,随着可逆块数量的增加,图像的PSNR/SSIM数值也有所增加。图7柱状图分别显示出含密图像质量与恢复图像质量,即PSNR/SSIM值。当可逆块数量为24时,图像的PSNR/SSIM值最大,PSNR达到了35 dB左右,SSIM达到了0.94以上。但是综合考虑训练时间成本的成倍增加,当可逆块数量为8时,已经达到图像隐藏对图像质量的要求,表明轻量级网络结构StegaLIN能够在取得良好的图像质量和安全性的同时降低训练的时间成本,提高了模型的隐写效率。
2.5 f(·)、r(·)和y(·)不同结构对网络的影响
由于网络的可逆性,f(·)、r(·)和y(·)可以采用任意函数,本文中f(·)、r(·)和y(·)采用DenseNet。
HiNet中DenseNet采用的卷积块数量为5,但是本文通过实验发现,DenseNet中卷积层的数量对网络的隐写能力有一定的影响。图8中柱状图显示了不同结构的f(·)、r(·)和y(·)对应的含密图像质量与恢复图像质量,分析不同结构对网络模型性能的影响。由图8可以看出,当卷积层为7时效果最好,这也是本文在HiNet上的改进没有延续卷积数为5,而是采用卷积数为7的f(·)、r(·)和y(·)结构的原因。
2.6 λ2值对网络的影响
本文通过实验发现,不同的λ2值对网络模型隐写图像的质量具有一定的影响。如图9所示,固定λ1和λ3数值不变,当λ2=0.5时网络模型的隐写能力最好,PSNR值达到了35.66 dB,SSIM值达到了94.95%。相比于HiNet设置λ2=8时实验结果明显提高,恢复图像的质量增强,PSNR提高了1.5 dB,SSIM提高了3.5%。
2.7 隐写分析
隐写分析结果度量了隐写分析工具[22]区分含密图像和载体图像的可能性。目前主流的隐写分析方法可分为基于统计的传统方法和基于深度学习的新方法两类。
1)传统隐写分析工具 与文献[8]一样,本文使用开源的隐写分析工具StegExpose[31]评价本文网络模型的抗隐写分析能力。从测试集中随机选择50张载体图像和秘密图像,通过本文网络模型生成含密图像XSte。为了绘制(ROC)曲线,实验在很大范围内改变StegExpose中的检测阈值。图10为网络的ROC曲线。ROC曲线一直围绕着随机猜测曲线上下波动,表明检测结果与随机猜测相同。实验证明StegExpose工具无法检测由本文网络模型生成的图像是否为含密图像。
2)基于深度学习的隐写分析工具 SRNet[6]是一种用于图像隐写分析的网络,可区分含密图像和载体图像。SRNet使用Adam优化器,输入图像大小统一调整为256×256,learning rate=0.001,batch size=10,epochs=180。表2给出了不同图像隐藏方法下SRNet的检测精度。其中,检测精度越接近50%(随机猜测),图像隐藏算法性能越好。可以看出,本文网络模型StegaLIN的检测准确率为57.64%,显著优于其他方法[8,32,33]。
2.8 小波变换和L低频损失的有效性
为验证小波变换与小波低频损失对图像安全性的影响,本文设计了三组实验,分别为不进行小波变换、进行小波变换但不考虑低频损失,以及考虑小波低频损失。这种情况下图像的检测率如表3所示,其中隐写分析模型采用了SRNet的方法。
从表3的第二和第三行可以看出,设置小波变换和低频损失显著提高了方法的安全性,检测率从77.28%下降到57.64%,证明了通过设置小波变换与L低频损失来约束网络模型的有效性。
3 结束语
本文提出了一种基于可逆网络的轻量化图像信息隐藏方案,通过将可逆块与密集连接中的卷积块的优势互补,在保持图像质量的同时,缩短了模型的训练与隐写时间,提高了隐写效率。通过仿真实验与隐写分析,说明了本文隐写方案的可行性、安全性以及较高的隐写效率。未来工作可专注于如何对图像进行预处理以实现图像的无损提取。
参考文献:
[1]Tamimi A A,Abdalla A M A,Al-Allaf O N A.Hiding an image inside another image using variable-rate steganography[J/OL].International Journal of Advanced Computer Science and Applications,2013,4(10).http://doi.org/10.14569/JACSA.2013.041004.
[2]Boland F M,ORuanaidh J J K,Dautzenberg C.Watermarking digital images for copyright protection[C]//Proc of the 5th International Conference on Image Processing and Its Applications.Piscataway,NJ:IEEE Press,1995:326-330.
[3]Fridrich J,Goljan M,Du Rui.Detecting LSB steganography in color,and gray-scale images[J].IEEE MultiMedia,2001,8(4):22-28.
[4]黃思远,张敏情,柯彦,等.基于自注意力机制的图像隐写分析方法[J].计算机应用研究,2021,38(4):1190-1194.(Huang Siyuan,Zhang Minqing,Ke Yan.Image steganalysis based on self-attention[J].Application Research of Computers,2021,38(4):1190-1194.)
[5]Pevn T,Filler T,Bas P.Usinghigh-dimensional image models to perform highly undetectable steganography[C]//Proc of International Workshop on Information Hiding.Berlin:Springer,2010:161-177.
[6]Boroumand M,Chen Mo,Fridrich J J.Deep residual network for steganalysis of digital images[J].IEEE Trans on Information Forensics and Security,2019,14:1181-1193.
[7]Baluja S.Hiding images in plain sight:deep steganography[C]//Proc of the 31st International Conference on Neural Information Processing Systems.Red Hook,NY:Curran Associates Inc.,2017:2066-2076.
[8]Baluja S.Hiding images within images[J].IEEE Trans on Pattern Analysis and Machine Intelligence,2020,42(7):1685-1697.
[9]Rehman A U,Rahim R,Nadeem M S,et al.End-to-end trained CNN encode-decoder networks for image steganography[EB/OL].(2017-11-20).https://arxiv.org/abs/1711.07201.
[10]Zhang Ru,Dong Shiqi,Liu Jianyi.Invisible steganography via generative adversarial networks [EB/OL].(2018-10-10).https://arxiv.org/abs/1807.08571.
[11]Hayes J,Danezis G.Generating steganographic images via adversarial training[EB/OL].(2017-07-24).https://arxiv.org/abs/1703.00371.
[12]毕新亮,杨晓元,刘文超,等.载体选择型图像隐写算法研究[J].计算机应用研究,2021,38(8):2465-2468.(Bi Xinliang,Yang Xiaoyuan,Liu Wenchao,et al.Research on cover selection image steganography algorithm[J].Application Research of Computers,2021,38(8):2465-2468.)
[13]Hu Donghui,Wang Liang,Jiang Wenjie,et al.A novel image ste-ganography method via deep convolutional generative adversarial networks[J].IEEE Access,2018,6:38303-38314.
[14]Liu Jia,Zhou Tanping,Zhang Zhuo,et al.Digital cardan grille:a mo-dern approach for information hiding[EB/OL].(2018-05-11).https://arxiv.org/abs/1803.09219.
[15]Zhang K A,Cuesta-Infante A,Xu Lei,et al.SteganoGAN:high capacity image steganography with GANs[EB/OL].(2019-01-30).https://arxiv.org/abs/1901.03892.
[16]Jing Junpeng,Deng Xin,Xu Mai,et al.HiNet:deep image hiding by invertible network[C]// Proc of IEEE/CVF International Conference on Computer Vision.Piscataway,NJ:IEEE Press,2021:4713-4722.
[17]Dinh L,Krueger D,Bengio Y.NICE:non-linear independent components estimation[EB/OL].(2015-04-10).https://arxiv.org/abs/1410.8516.
[18]Dinh L,Sohl-Dickstein J,Bengio S.Density estimation using real NVP[EB/OL].(2017-02-27).https://arxiv.org/abs/1605.08803.
[19]Kingma D P,Dhariwal P.Glow:generative flow with invertible 1×1 convolutions[EB/OL].(2018-07-10).https://arxiv.org/abs/1807.03039.
[20]Wang Yaolong,Xiao Mingqing,Liu Chang,et al.Modeling lost information in lossy image compression[EB/OL].(2020-07-08).https://arxiv.org/abs/2006.11999.
[21]Pan Zhihong.Learning adjustable image rescaling with joint optimization of perception and distortion[C]//Proc of ICASSP IEEE International Conference on Acoustics,Speech and Signal Processing.Pisca-taway,NJ:IEEE Press,2022:2455-2459.
[22]Xiao Mingqing,Zheng Shuxin,Liu Chang,et al.Invertible image resca-ling[EB/OL].(2020-05-12).https://arxiv.org/abs/2005.05650.
[23]Van der Ouderaa T F A,Worrall D E.Reversible GANs for memory-efficient image-to-image translation[C]//Proc of IEEE/CVF Confe-rence on Computer Vision and Pattern Recognition.Piscataway,NJ:IEEE Press,2019:4715-4723.
[24]Zhu Xiaobin,Li Zhuangzi,Zhang Xiaoyu,et al.Residual invertible spatio-temporal network for video super-resolution[C]//Proc of the 33rd AAAI Conference on Artificial Intelligence and the 31st Innovative Applications of Artificial Intelligence Conference and the 9th AAAI Symposium on Educational Advances in Artificial Intelligence.Palo Alto,CA:AAAI Press,2019:5981-5988.
[25]Ardizzone L,Lyuth C,Kruse J,et al.Guided image generation with conditional invertible neural networks[EB/OL].(2019-07-10).https://arxiv.org/abs/1907.02392.
[26]Guan Zhenyu,Jing Junpeng,Deng Xin,et al.DeepMIH:deep invertible network for multiple image hiding[J].IEEE Trans on Pattern Analysis and Machine Intelligence,2022,45:372-390.
[27]Liu Lianshan,Tang Li,Zheng Weimin.Lossless image steganography based on invertible neural networks[J].Entropy,2022,24(12):1762.
[28]Lu Shaoping,Wang Rong,Zhong Tao,et al.Large-capacity image steganography based on invertible neural networks[C]// Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition.Pisca-taway,NJ:IEEE Press,2021:10811-10820.
[29]Xu Youmin,Mou Chong,Hu Yujie,et al.Robust invertible image steganography[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition.Piscataway,NJ:IEEE Press,2022:7865-7874.
[30]Agustsson E.Challenge on single image super-resolution:dataset and study[C]// Proc of IEEE Conference on Computer Vision and Pattern Recognition Workshops.Piscataway,NJ:IEEE Press,2017:1122-1131.
[31]Boehm B.StegExpose:a tool for detecting LSB steganography[EB/OL].(2014-10-24).https://arxiv.org/abs/1410.6656.
[32]Zhu Jiren,Kaplan R,Johnson J,et al.HiDDeN:Hiding data with deep networks[EB/OL].(2018-07-26).https://arxiv.org/abs/1807.09937.
[33]Weng Xinyu,Li Yongzhi,Chi Lu,et al.High-capacity convolutional video steganography with temporal residual modeling[C]//Proc of International Conference on Multimedia Retrieval.New York:ACM Press,2019:87-95.
