基于对比学习的多特征融合戴口罩人脸识别
2024-02-18陈岸明林群雄刘伟强
陈岸明 林群雄 刘伟强
摘 要:随着计算机视觉技术应用的发展和智能终端的普及,口罩遮挡人脸识别已成为人物身份信息识别的重要部分。口罩的大面积遮挡对人脸特征的学习带来极大挑战。针对戴口罩人脸特征学习困难这一问题,提出了一种基于对比学习的多特征融合口罩遮挡人脸识别算法,该算法改进了传统的基于三元组关系的人脸特征向量学习损失函数,提出了基于多实例关系的损失函数,充分挖掘戴口罩人臉和完整人脸多个正负样本之间的同模态内和跨模态间的关联关系,学习人脸中具有高区分度的能力的特征,同时结合人脸眉眼等局部特征和轮廓等全局特征,学习口罩遮挡人脸的有效特征向量表示。在真实的戴口罩人脸数据集和生成的戴口罩人脸数据上与基准算法进行了比较,实验结果表明所提算法相比传统的基于三元组损失函数和特征融合算法具有更高的识别准确率。
关键词:戴口罩人脸识别; 对比学习; 特征融合; 口罩生成
中图分类号:TP391.1 文献标志码:A 文章编号:1001-3695(2024)01-044-0277-05
doi:10.19734/j.issn.1001-3695.2023.06.0266
Multi feature fusion for masked face recognition based on contrastive learning
Abstract:With the development of computer vision technology and the popularization of intelligent terminals, facial recognition under mask occlusion has become an important part of character identity information recognition. The large area occlusion of masks poses great challenges to the learning of facial features. To solve this problem, this paper proposed a multi feature fusion based masked face recognition algorithm based on contrastive learning. This algorithm improved the traditional face feature vector learning loss function based on the triple relationship. It proposed a loss function based on the multi-instance relationship, which fully excavated the intra-modal and inter- modal correlation between multiple positive and negative samples of the masked face and the full face. Then, the features with high discrimination ability were learnt from the face. Meanwhile, it combined the local features such as eyebrows and eyes, as well as global features such as contours, to learn the effective feature vector representation of the masked face. This paper compared it with the benchmark algorithm on real masked face datasets and generated masked face data. The experimental results show that the proposed algorithm has higher recognition accuracy than the traditional triple loss function and feature fusion model.
Key words:masked face recognition; contrastive learning; feature fusion; mask generation
0 引言
随着计算机视觉技术和硬件设备的快速发展,人脸识别在许多行业和领域都已得到了广泛的应用,尤其是人脸识别作为一种重要的身份验证手段,在许多场景和应用中都发挥了重大作用。传统的人脸识别方法受环境与人为因素的影响,例如被遮挡、光照不强、姿态变化等,其识别性能有待提高,应用效果也受到制约。因此,提高人脸识别方法在有遮挡物的情况下识别的准确性,仍然是当前人脸识别的研究重点。在许多需要进行身份验证的场合,戴口罩人脸识别已经成为一项基础的验证手段,提高戴口罩人脸识别的性能也成为了当前有遮挡人脸识别的一个研究重点。
在无遮挡物的情况下,当前的人脸识别方法已经达到了非常高的准确率。例如ArcFace[1]、CosFace[2]等在 LFW[3]数据集上的准确率已经达到 99.5%以上。然而,针对有遮挡物,尤其是戴口罩的情景,人脸识别的准确率还有较大的提升空间,相关的研究相对传统人脸识别也较少。遮挡物对人脸识别算法带来了极大的挑战,现有的有遮挡人脸识别算法主要面向脸部饰品、眼镜等面积较小的遮挡物[4~6]。口罩是一种面积较大的遮挡物,戴上口罩后鼻梁以下大半个人脸的生物特征信息被遮挡。因此,传统的有遮挡人脸识别算法用于戴口罩人脸识别时,其效果会受到很大影响。戴口罩人脸识别算法需要根据人脸未遮挡局部特征和其他信息进行身份验证。当前,已经产生了一些戴口罩人脸识别算法。这些方法主要分为三类:第一类方法主要研究新型的损失函数用于学习人脸表征向量[7~9],其主要思想是同一个人的人脸特征表示向量应该尽量相似,而不同人之间的人脸特征表示向量应该具有较大的差距;第二类方法从人脸图像中定位口罩区域或者关联的特征元素[10,11],然后将其从图像中裁剪或者从特征域移除,目的在于消除口罩对人脸识别的影响;第三类方法试图修复被口罩遮挡的人脸信息[12,13],这类方法主要利用对抗神经网络等模型,生成被遮挡部分的人脸特征,然后结合生成的特征和人脸局部特征识别人脸身份。
虽然这些方法已经取得了一定的成功,但是还存在一些问题。首先,当前的损失函数主要考虑单个人脸图像对之间的距离关系,忽略了同一类图像之间的关系。例如对于同一个人来说,其戴口罩的图像可以是多个角度、多种光线下的多张图像,未戴口罩情况也是一样。因此,不仅需要不同人之间的图像特征向量具有较大的距离,还需要确保同一个人不同的戴口罩图像特征向量之间的距离较小。同时,通过学习同一人的不同图像特征,可以挖掘出具有较大辨别能力的人脸特征。其次,基于口罩移除和人脸修复的方法很难学习出被遮挡部分的细节特征,从而导致人脸特征向量学习的效果不理想,进而影响人脸身份识别的准确率。在实际中,口罩的形状多样,不同人脸的局部特征有时还会非常相似,这些特点对人脸的修复提出了极大的挑战,进而影响人脸识别的准确率。
针对这些问题,本文提出了一种基于对比学习的多特征融合戴口罩人脸识别方法(CLMF)。对比学习是一种自监督学习方法[14],该方法能有效学习数据集中具有重要辨别能力的隐含特征,尤其是学习跨模态、跨领域数据中的一般特征。本文利用对比学习方法从每个人的不同戴口罩人脸图像以及完整人脸图像中学习出对人脸特征具有重要辨别能力的特征。多个实例对的学习克服了传统的基于单个图像对之间距离的向量学习方法的缺点。同时,为了提高人脸的表征能力,本文方法结合眉眼等未遮挡局部特征和人脸轮廓等全局特征来识别人物身份。针对训练数据稀疏的问题,利用基于对抗网络的风格迁移方法为人脸图像生成戴口罩图像,该方法可减少数据集人工标注的代价,提高训练数据的规模。实验结果表明,本文方法能有效提高戴口罩人脸识别的准确率等指标。
1 相关工作
目前已经有许多关于遮挡人脸识别的研究[15,16],而口罩这种面积较大的遮挡物,对人脸识别提出了更大的挑战,且相关研究还相对较少,主要分为三类。第一类方法通过设计特殊的损失函数来学习具有高区分度的人脸特征,基于学习出的特征向量来判断人脸身份。例如,ArcFace[1]是较早提出的基于深度学习的人脸识别方法,MTArcFace[7]通过结合ArcFace和口罩人脸分类损失函数实现了无遮挡与戴口罩两种情景下的人脸识别。balanced curricular loss [8]损失函数用于在模型训练的过程中自动发现困难样本,以提高人脸特征的区分程度。self-restrained triplet[9]损失函数是在已有的人脸识别模型之上构建的,目的是为戴口罩人脸学习一个与未戴口罩时相似的人脸表征向量。DCR[13]提出了一种域约束的排序算法,该算法把戴口罩人脸图像和未戴口罩人脸图像当作两个域,通过跨域排序来学习人脸特征向量表示。
第二类方法通过感知遮挡的图像区域或特征来降低口罩对人脸识别的影响。例如,LPD[10]利用spatial Transformer network[17]定位人脸未遮挡区域,将其裁剪出来并投影至图像原始大小,替代原图像参与模型的训练。DFL [11]利用 滑动窗口匹配的方法匹配未遮挡部分人脸与完整人脸的特征实现身份识别。PDSN[18]提出了一种掩码学习策略,通过查找人脸遮挡部分在特征中的关联元素并将其丢弃,以降低遮挡部分特征在人脸识别过程中的干扰。DGR[19]提出一个动态图方法,把人脸建模成图结构,然后从图中移除代表口罩信息的图特征,进而减少口罩对人脸识别的影响。
第三类方法尝试修复被口罩遮挡的人脸部分。文献[12]提出了基于半监督学习的人脸遮挡修复方法。文献[20]提出了一种基于对抗网络模型的口罩恢复算法。GFC[21]使用深度生成模型恢复遮挡人脸, 分别使用全局和局部损失来约束生成结果的全局语义一致性和局部语义一致性。虽然这些方法取得了一定的效果,但是主要还是基于单个或者一对图像的特征学习,不能有效学习人脸图像中具有高区分度的特征。
2 本文模型
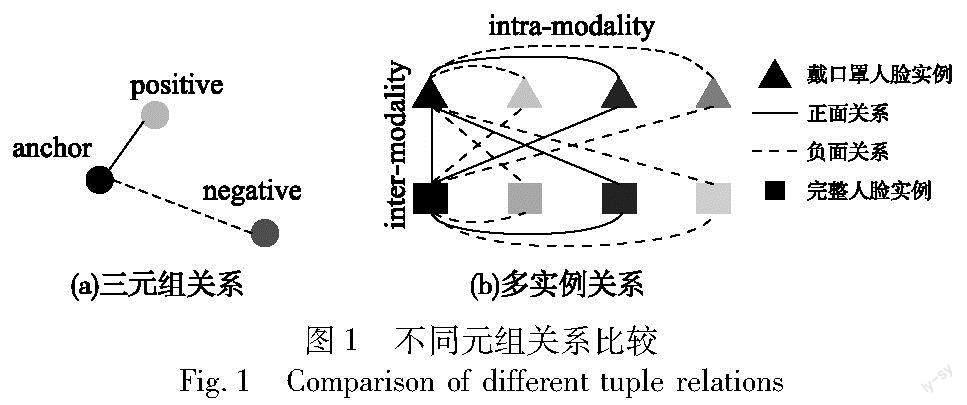
本文基于对比学习方法来学习人脸中具有高区分能力的特征。人脸特征学习的主要目的是使得同一个人物目标人脸图像之间的特征表示向量相似,而不同人的人脸图像特征表示向量之间具有较大的距离。目前,许多方法采用基于正负样本的三元组损失函数[9,18]来学习人脸图像特征向量。如图1(a)所示,在三元组关系中,针对给定的锚样本,从数据集中选取一个和它同标签的样本作为正样本,另选一个不同标签的样本作为负样本,特征学习的目的就是使得学习出的锚样本向量和正样本向量距离尽量小,而与负样本向量的距离尽量大。这种学习方法仅考虑了单个样本对的关系信息。在实际中,由于不同的拍摄角度和拍照光线,人脸的变化形式多样,仅靠单个图像对之间的关系,很难全面反映不同人物人脸图像之间的关系。因此,基于三元组关系学习出的向量难以有效刻画对象的本质特征。本文的对比学习方法能够同时从锚图像的多个正样本实例和负样本实例中挖掘人脸内在特征,提高了特征学习的能力。如图1(b)所示,本文把戴口罩人脸图像和完整人脸图像当做两种模态的数据,属于同一个人的其他图像当做正样本,而属于其他人的人脸图像当做负样本。对于给定的某个模态的锚样本,从数据集中选取同模态的多个正样本和负样本,同时从另一个模态的数据中选取多个正样本和负样本。然后,挖掘同一模态内的多个样本实例之间的关系和跨模态样本之间的关系,进而基于这些关系提高人脸图像特征向量的学习质量。
本文提出的基于对比学习和多特征融合戴口罩人脸识别算法框架如图2所示,其中MLP表示多层感知机、linear layer表示全连接层、masking image classifier表示戴口罩人脸图像分类器、full image classifier表示完整人脸图像分类器。该框架主要包括两个重要的模块。第一个模块为人脸图像编码器,包括戴口罩人脸图像编码器和完整人脸图像编码器。戴口罩人脸图像编码器分别为眉眼区域局部图像和戴口罩全局图像学習两个向量表示,然后融合这两个向量得到戴口罩人脸图像特征向量表示。完整人脸图像编码器可以采用当前的人脸识别系统的编码器,通过人脸特征提取网络得到完整人脸图像的初始特征向量表示。第二个模块为基于对比学习的人脸图像向量学习。该模块将戴口罩人脸图像和完整人脸图像当做两种模态的数据,同时学习同一人物多张戴口罩人脸图像和不同人物完整人脸图像的多实例关系,包括模态内(intra-modality)和模态间(inter-modality)的关系,从而得到具有较强表示能力的戴口罩人脸图像特征向量。最后,学习到的人脸图像特征向量用于分类器学习,以进一步提高人脸图像特征的人物辨别能力。
本文的主要符号定义如下:人脸图像数据集为D=Xm∪Xf,其中Xm={xmi|i=1,…,|Xm|}表示戴口罩人脸数据部分、Xf={xmi|i=1,…,|xf|}表示完整人脸数据部分、上标m和f分别是戴口罩和未戴口罩的标签;y∈{1,…,k}表示第i个人脸图像的身份标签。
2.1 人脸图像编码器
如图3所示,对于戴口罩的人脸图像,本文分别为眉眼区域局部图像和全局戴口罩图像学习两个向量表示,然后对两种向量进行融合,以形成表示戴口罩人脸图像的整体向量。该整体向量既能反映人脸的局部特征,也能反映整体脸部信息,因此,能够有效地识别戴口罩人脸身份。
首先采用Dlib(http://dlib.net/)工具检测人脸图像的68个landmarks,人工选择鼻子上部的landmark作为监督信息,为戴口罩人脸数据学习口罩位置检测器,然后采用反向采样的方法[10]提取戴口罩人脸的眉眼区域。之后,利用ResNet-50[22]的CNN骨干网络学习眉眼区域图像的特征向量aei。其次,对于戴口罩人脸,采用同样的CNN骨干网络提取其特征向量awi,两个CNN骨干网络共享参数以降低模型复杂度。得到眉眼区域图像向量和戴口罩人脸图像向量后,采用仿射变换(biaffine attention)对两者进行融合,得到戴口罩人脸图像的特征表示zmi:
zmi=aeiTWawi(1)
对于完整人脸图像,可以采用现有的人脸特征编码器。与上述方法一样,利用ResNet-50的CNN骨干网络提取完整人脸图像的特征向量zfi;然后,通过MLP和L2_Normarization将戴口罩人脸图像特征向量和完整人脸图像特征向量映射到同一空间中。
rmi=Norm(MLP(zmi))(2)
rfi=Norm(MLP(zfi))(3)
2.2 基于对比学习的人脸特征学习
如前所述,本文将戴口罩人脸图像和完整人脸图像当做两种模态的数据,然后根据两种模态数据的多个实例的模态内(intra-modality)和模态间(inter-modality)关系来学习人脸图像的特征向量。
1)模态内关系学习
模态内的关系主要是通过同种模态的多个实例来学习戴口罩人脸图像和完整人脸图像中能反映其本质的特征,其主要思想是锚图像应和正样本具有更相似的向量表示,而和负样本之间的相似度应尽量小。因此,可以利用同一人的不同角度、不同光线等多张图像来学习人脸的基本特征。模态内的损失函数Lintra包括戴口罩人脸图像损失项LMintra和完整人脸图像损失项LFintra。
Lintra=Lmintra+Lfintra(6)
因此,通过最小化Lintra可以使得模型从多个相关的和不相关的实例中学习模态内人脸图像的不变特性。
2)模态间关系学习
模态内的关系学习只考虑了相同模态数据之间的关系,其目的是使同模态内相似的人脸图像具有相似的向量表示。然而,戴口罩人脸图像识别的主要目的是验证人的身份,还需要同一个人的戴口罩人脸图像和完整人脸图像具有相似的向量表示。因此,需要通过跨模态样本实例之间的关系来学习戴口罩人脸和完整人脸图像之间共同的高区分度特征。本文在同一空间中为戴口罩人脸图像和完整人脸图像学习其特征,从而建立起这两种图像之间的关联。同样地,跨模态损失函数Linter包括戴口罩图像到完整人脸图像的关联损失项Lminter和完整人脸图像到戴口罩图像的关联损失Lfinter。
其中:M、υ和〈,〉和前述公式中的参数一样。整体的跨模态学习损失函数如下:
Linter=Lminter+Lfinter(9)
通过最小化Linter可以学习戴口罩人脸图像表示向量和完整人脸图像表示向量之间内在的一致特征,进一步提高戴口罩人脸图像表示向量表达人脸的性能。
3)特征学习函数
为了学习能够反映人物身份的特征,本文基于前述多实例关系学习的图像表示向量进行人物标签分类学习,分类器学习采用交叉熵损失函数。
这个分类损失函数的一个重要目的是使从戴口罩人脸图像学习的向量和完整人脸图像学习的向量能正确识别任务身份,且两者的识别结果应该一致。然后,完整的分类损失函数为
Lclass=Lmclass+Lfclass(12)
最终,整个图像向量学习的损失函数包括了多实例模态内关系和模态间关系学习损失以及分类损失。
Lclass=αLclass+(1-α)(Lintra+Linter)(13)
3 实验分析
3.1 数据集
本文采用现有常用的人脸识别数据集CASIA-WebFace[24]作为模型的训练,由于该数据集不包含戴口罩的人脸图像,所以本文利用基于对抗网络的图像翻译方法[25]为完整人脸图像生成戴口罩人脸图像,通过人工方法去掉生成的噪声图像。CASIA-WebFace中生成的戴口罩人脸图像如图4所示。这种生成方法不需要戴口罩人脸图像和相应完整人脸图像的成对训练数据,只需要戴口罩人脸和完整人脸兩个数据集就可以学习出戴口罩人脸图像的生成模型。测试数据集包含IJB-C[26]和Masked WHN[23]两个数据集。第一个数据集IJB-C也不包含戴口罩人脸,本文为其生成戴口罩人脸数据;第二个数据集Masked WHN为真实的戴口罩人脸数据集,其中质量不高的图像被过滤掉。各数据集信息如表1所示。
3.2 测试方法
本文的对比方法包括以下几种:
a)ArcFace[1],该方法为传统的人脸识别方法,直接以 ResNet50 为主干特征提取网络提取人脸图像特征。
b)EUM[9],该方法基于三元组关系提出了一种新的损失计算函数,为完整人脸图像学习一个与同一个人戴口罩图像向量相似的向量,该向量同时与其他人的戴口罩人脸图像的向量具有更小的相似度。
c)LPD[10],该方法分别为戴口罩人脸图像和眉眼区域部分图像学习两个向量,通过分类器学习两个向量之间的关系,然后利用简单的线性方法直接合并两个向量得到戴口罩人脸图像的完整向量。
d)ViT[27],该方法直接基于ViT(vision Transformer)和数据增强实现戴口罩人脸图像的分类。
测试方法包括两种:
a)验证。给定一张戴口罩人脸图像和一张完整人脸图像,判断两张图像是否表示同一人,该测试利用准确度accuracy指标来评价。为实现该测试,对图2中戴口罩人脸图像分类器学习的向量和完整人脸图像分类器学习的向量计算一个相似度值,如果相似度值大于设定的阈值,则认为两张图像表示同一人。
b)识别。给定一张戴口罩人脸图像,对候选数据集中完整人脸图像按照相似度进行降序排序,该测试利用排序评价指标rank-1、rank-5、rank-10和mAP来评价。为实现该测试,利用如图2所示的模型对戴口罩人脸图像和完整人脸图像分别学习其向量表示。给定戴口罩人脸查询图像后,计算该图像和数据集中的候选完整人脸图像的相似度值,按照相似度值对完整人脸图像进行排序。
3.3 比较实验
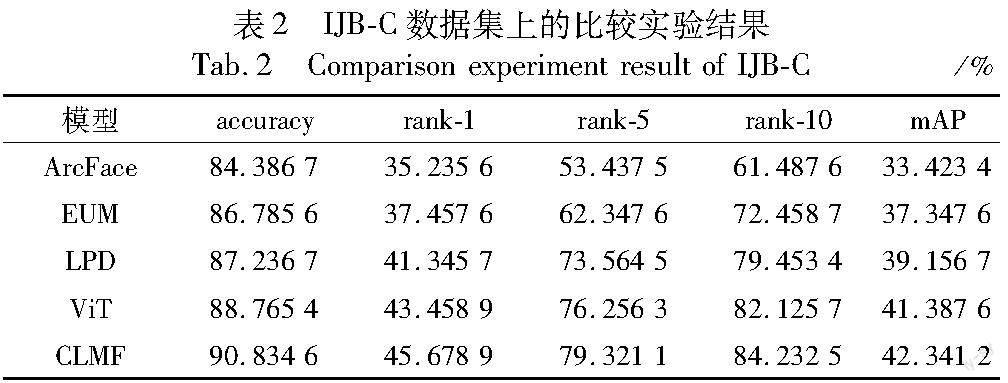
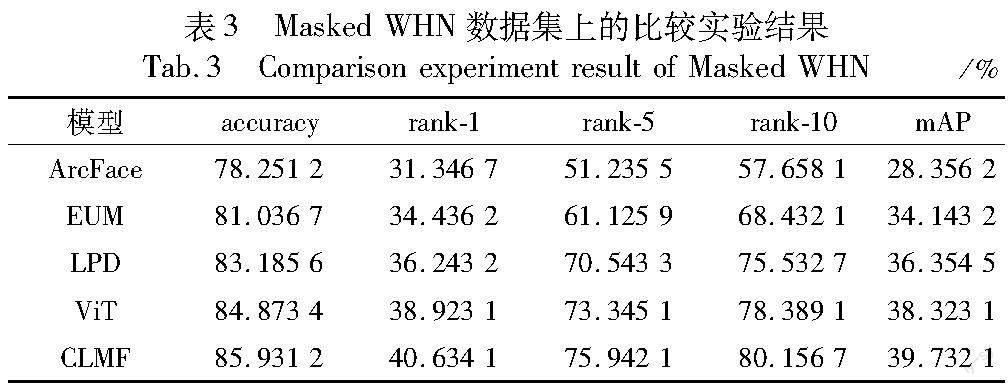
各方法在IJB-C和Masked WHN数据集上的比较实验结果分别如表2和3所示。從表中数据可以得出以下结论。首先,ArcFace性能低于其他算法,表明传统的人脸识别算法在戴口罩人脸识别中,识别性能在一定程度上受到遮挡物的影响。其次,EUM直接基于传统的人脸识别网络结构,再结合三元组关系损失函数学习戴口罩人脸图像和完整人脸图像的特征向量表示。该方法虽然提高了人脸图像特征向量的表示能力,但是仅靠三元组无法有效学习人脸多个角度、多个实例之间的共现特征,造成特征向量对人脸的区分能力不高。LPD融合人脸图像的多种特征进行人脸识别,包括戴口罩人脸全局特征和完整人脸局部特征,然后基于分类损失函数来学习人脸图像特征向量。ViT虽然利用预训练模型提高了图像特征学习的性能,但是该方法直接基于预训练模型的输出进行图像分类,对戴口罩人脸图像的局部特征学习能力有限。CLMF融合了人脸的局部特征和全局特征,并且通过对比学习人脸图像的多个实例来挖掘具有高区分度的特征,从而提高戴口罩人脸识别的性能。
3.4 消融实验
为了分析本文模型CLMF各模块的有效性,设计了CLMF的变异模型。首先,将特征融合模块从CLMF中移除以构建一个新的模型CLMF-f,该模型以戴口罩人脸的全局特征代替原模型中的融合特征,主要用于测试特征融合对戴口罩人脸识别的贡献。另一方面,为了测试对比学习模块在CLMF中的作用,将对比学习模块从CLMF中移除,形成另一个模型CLMF-c,该模型利用三元组损失函数[8]代替原有的多实例学习损失函数。同时,为了验证多实例模态内关系和模态间关系对于人脸特征学习的作用,分别设计了另外两个模型CLMF-cintra和CLMF-cinter,用于移除模态内损失函数Lintra和模态间损失函数Linter。
这些变异模型的实验结果如表4和5所示。从表中的数据可以看出,当移除特征融合模块和对比学习模块后,CLMF的性能都存在不同程度的下降。而且,即使是基于戴口罩全局人脸特征进行对比学习,也比传统的人脸识别模型具有更好的性能。同时,多特征融合加上三元组损失函数也比单纯的三元组损失函数模型具有更好的性能。因此,特征融合和多实例对比学习都对戴口罩人脸识别作出贡献。从表中的数据还可以看出,加入同模态实例间关系学习和跨模态实例间关系学习也会提高模型的特征学习能力。这进一步说明,通过同一个对象的不同角度、不同模态的多个实例间内在关系的学习,可以挖掘出区分度较高的特征,从而提高戴口罩人脸识别的准确性。
3.5 实验案例分析
为了进一步说明本文模型CLMF的性能,表6给出了两个实验结果案例。表中第二行每个样例左侧标识为“戴口罩人脸测试图像”为查询图像,右侧图像表示数据集中戴口罩人脸测试图像所对应的人物ID图像。系统针对提供的查询图像返回与之相似的完整人脸图像,并按照相似度值进行排序。表中下面的每一列表示模型返回的戴口罩人脸图像最相似的5张完整人脸图像。从表中两个例子可以看出,本文模型能够在返回列表的第一位就找到正确结果,而LDP则分别在第3位和第2位才返回正确结果。该案例说明CLMF模型通过多实例关系信息的学习,能提高戴口罩人脸图像向量的表示能力,进而能更有效地反映其与完整人脸图像之间的相似度,提高了戴口罩人脸识别的准确性。
4 结束语
针对口罩遮挡人脸图像有效特征稀疏的问题,本文提出了一个融合人脸眉眼等局部特征与全局特征的口罩遮挡人脸编码学习器。针对单个实例图像特征难以学习、不同人脸图像之间关联复杂的问题,提出了基于对比学习的人脸特征向量学习方法,充分挖掘戴口罩人脸不同图像以及完整人脸不同图像之间的内在关联信息,从而更有效地学习人脸图像的高区分度特征。针对口罩遮挡人脸图像训练数据不足的问题,构建了基于图像翻译模型的口罩产生器,生成虚拟口罩遮挡人脸数据。在真实戴口罩人脸数据集和虚拟口罩遮挡数据集上,与传统的人脸识别方法、基于三元组损失函数和特征融合的戴口罩人脸识别方法进行了比较,实验结果表明,融合局部特征与人脸全局特征以及多实例间关系学习可以提高戴口罩人脸识别的性能。在后续研究中,可加入人脸视觉特征的预训练学习模型,充分利用人脸图像数据提高人脸特征学习的性能。
参考文献:
[1]Deng Jiankang, Guo Jia, Yang Jing, et al. ArcFace: additive angular margin loss for deep face recognition[C]//Proc of IEEE Conference on Computer Vision and Pattern Recognition.Piscataway,NJ:IEEE Press,2019:4690-5274.
[2]Wang Hao, Wang Yitong, Zhou Zheng, et al. CosFace: large margin cosine loss for deep face recognition[C]//Proc of IEEE Conference on Computer Vision and Pattern Recognition.Piscataway,NJ:IEEE Press,2018:5265-5274.
[3]Huang G B, Mattar M, Berg T, et al. Labeled faces in the wild: a database for studying face recognition in unconstrained environments[C]//Proc of Workshop on Faces in ‘Real-Life Images: Detection, Alignment, and Recognition.Piscataway,NJ:IEEE Press,2008:1-8.
[4]Jia Hongjun, Martinez A M. Support vector machines in face recognition with occlusions[C]//Proc of IEEE Conference on Computer Vision and Pattern Recognition.Piscataway,NJ:IEEE Press,2009:136-141.
[5]Wu C Y, Ding J J. Occluded face recognition using low-rank regression with generalized gradient direction[J].Pattern Recognition,2018,80: 256-268.
[6]朱孟剛,郑广海.遮挡人脸识别算法改进方法综述[J].计算机科学与应用,2022,12(6):1569-1579.(Zhu Menggang, Zheng Guanghai. A survey of improved methods of occlusion face recognition algorithms[J].Computer Science and Application,2022,12(6):1569-1579).
[7]Montero D, Nieto M, Leskovsky P, et al. Boosting masked face re-cognition with multi-task ArcFace[EB/OL].(2021).https://arxiv.org/abs/2104.09874.
[8]Feng Tao, Xu Liangpeng, Yuan Hangjie, et al. Towards mask-robust face recognition[C]//Proc of IEEE Conference on Computer Vision.Piscataway,NJ:IEEE Press,2021:1492-1496.
[9]Boutros F, Damer N, Kirchbuchner F, et al. Self-restrained triplet loss for accurate masked face recognition[J].Pattern Recognition,2022,124:108473.
[10]Ding Feifei, Peng Peixi, Huang Yangru, et al. Masked face recognition with latent part detection[C]//Proc of the 28th ACM International Conference on Multimedia.New York:ACM Press,2020:2281-2289.
[11]He Lingxiao, Li Haiqing, Zhang Qi, et al. Dynamic feature learning for partial face recognition[C]//Proc of IEEE Conference on Compu-ter Vision and Pattern Recognition.Piscataway,NJ:IEEE Press,2018:7054-7063.
[12]Cai Jiancheng, Han Hu, Cui Jiyun, et al. Semi-supervised natural face deocclusion[J].IEEE Trans on Information Forensics and Security,2020,16:1044-1057.
[13]Geng Mengyue, Peng Peixi, Huang Yangru, et al. Masked face re-cognition with generative data augmentation and domain constrained ranking[C]//Proc of the 28th ACM International Conference on Multimedia.New York:ACM Press,2020:2246-2254.
[14]He Kaiming, Fan Haoqi, Wu Yuxin, et al. Momentum contrast for unsupervised visual representation learning[C]//Proc of IEEE Conference on Computer Vision and Pattern Recognition.Piscataway,NJ:IEEE Press,2020:9726-9735.
[15]Damer N, Grebe J H, Chen Cong, et al. The effect of wearing a mask on face recognition performance: an exploratory study[C]//Proc of the 19th International Conference on Biometrics Special Interest Group.2020:1-10.
[16]王羿,姚克明,姜紹忠.基于口罩佩戴情况下的人脸识别方法[J].计算机科学与应用,2022,12(3):739-745.(Wang Yi, Yao Keming, Jiang Shaozhong. Face recognition method under the condition of wearing a mask[J].Computer Science and Application,2022,12(3):739-745)
[17]Jaderberg M, Simonyan K, Zisserman A, et al. Spatial Transformer networks[C]//Advances in Neural Information Processing Systems.2015:2017-2025.
[18]Song Yi, Zhen Lei, Liao Shengcai, et al. Occlusion robust face re-cognition based on mask learning with pairwise differential siamese network[C]//Proc of IEEE Conference on Computer Vision.Pisca-taway,NJ:IEEE Press,2019:773-782.
[19]Ren Min, Wang Yunlong, Sun Zhennan, et al. Dynamic graph representation for occlusion handling in biometrics[C]//Proc of AAAI Conference on Artificial Intelligence.Palo Alto,CA:AAAI Press,2020:11940-11947.
[20]Din N U, Javed K, Bae S, et al. A novel GAN-based network for unmasking of masked face[J].IEEE Access,2020,8:44276-44287.
[21]Li Yijun, Liu Sifei, Yang Jimei, et al. Generative face completion[C]//Proc of IEEE Conference on Computer Vision and Pattern Re-cognition.Piscataway,NJ:IEEE Press,2017:3911-3919.
[22]Dosovitskiy A, Beyer L, Kolesnikov A, et al. An image is worth 16×16 words: transformers for image recognition at scale [EB/OL].(2020).https://arxiv.org/abs/2010.11929.
[23]Wang Zhongyuan, Wang Guangcheng, Huang Baojin, et al. Masked face recognition dataset and application[EB/OL].(2020).https://arxiv.org/abs/2003.09093.
[24]Dong Yi, Zhen Lei, Liao Shengcai, et al. Learning face representation from scratch[EB/OL].(2014).https://arxiv.org/abs/1411.7923.
[25]Zhu Junyan, Taesung P, Phillip I, et al. Unpaired image-to-image translation using cycle-consistent adversarial network[C]//Proc of IEEE International Conference on Computer Vision.Piscataway,NJ:IEEE Press,2017:2223-2232.
[26]Bansal A, Nanduri A, Castillo C D, et al. UMDFaces: an annotated face dataset for training deep networks[EB/OL].(2016).https://arxiv.org/abs/1611.01484v2.
[27]Donato J H, Yudistira N, Sutrisno. Mask usage recognition using vision Transformer with transfer learning and data augmentation[EB/OL].(2022).https://arxiv.org/abs/2203.11542v1.
